【今日CV 计算机视觉论文速览 第95期】Fri, 5 Apr 2019
今日CS.CV 计算机视觉论文速览
Fri, 5 Apr 2019
Totally 57 papers

Interesting:
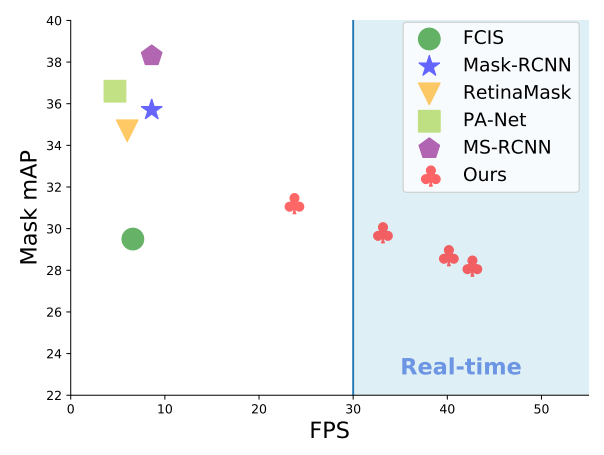
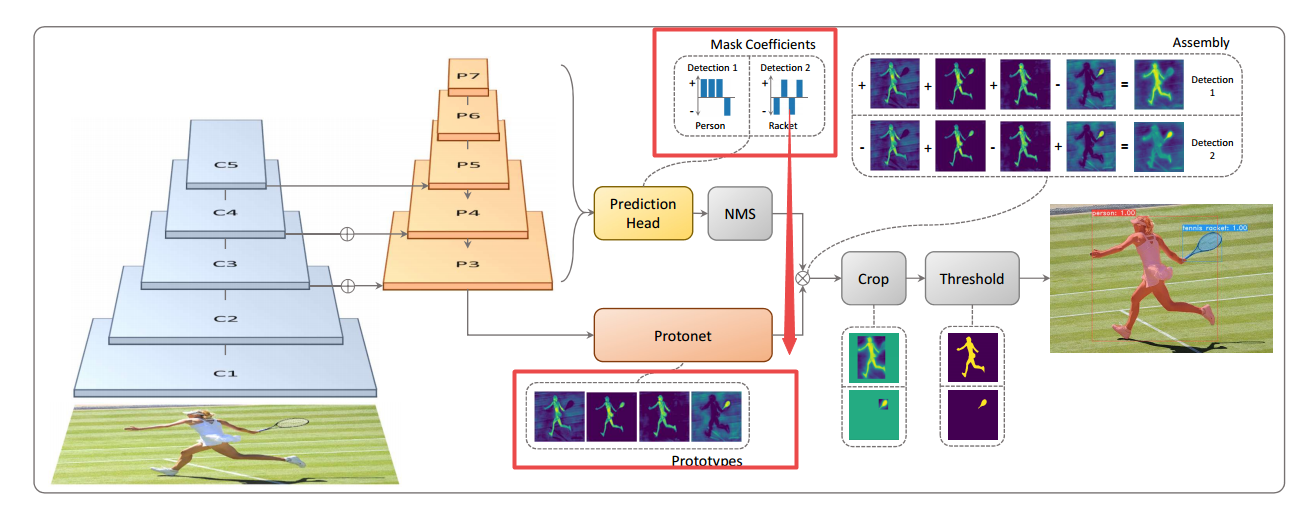
?YOLACT:1You Only Look At CoefficienTs, 实时实例分割系统,在COCO上实现了33fps,29。8的mAP。目前最快的实例分割系统。通过一系列原型mask生成,。并为每一个实例预测mask系数,最终将原型mask和系数线性结合得到最终的实例mask。这种方法不依赖与repooling,使得生成的mask质量和稳定性得到了保证。最后研究人员还提出了Fast NMS来替代NMS实现加速。(from 加州大学戴维斯分校)
COCO上 test-dev的效果:
模型如下所示:
效果如下所示:

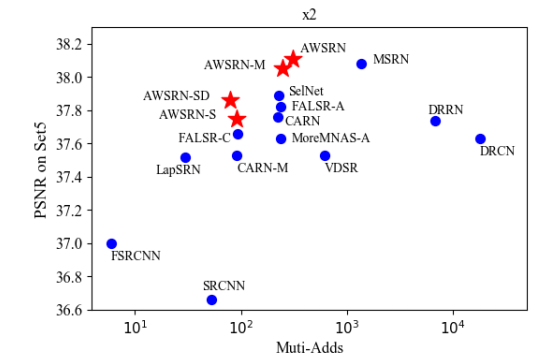
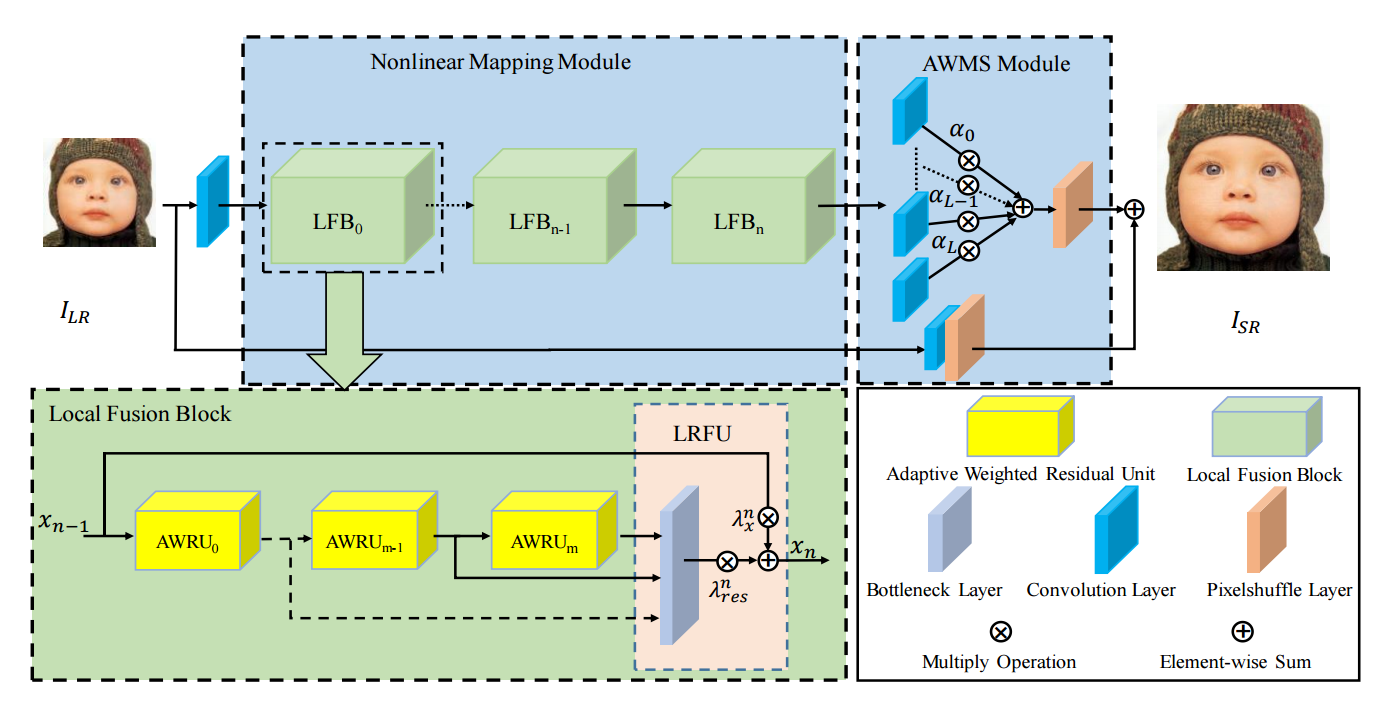
?AWSRN: Adaptive Weighted Super-Resolution Network,基于自适应权重学习网络的轻量级图像超分辨, 新颖的局域融合设计使得AWSRN具有高效的残差学习能力,其中包含了自适应残差单元和局域残差融合单元。此外还加入了多尺度模块来充分利用重建层中的特征(from 上海大学)
取得的成果如下:
网络架构如下如所示:
在不同尺度上的表现如下:
code:https://github.com/ChaofWang/AWSRN
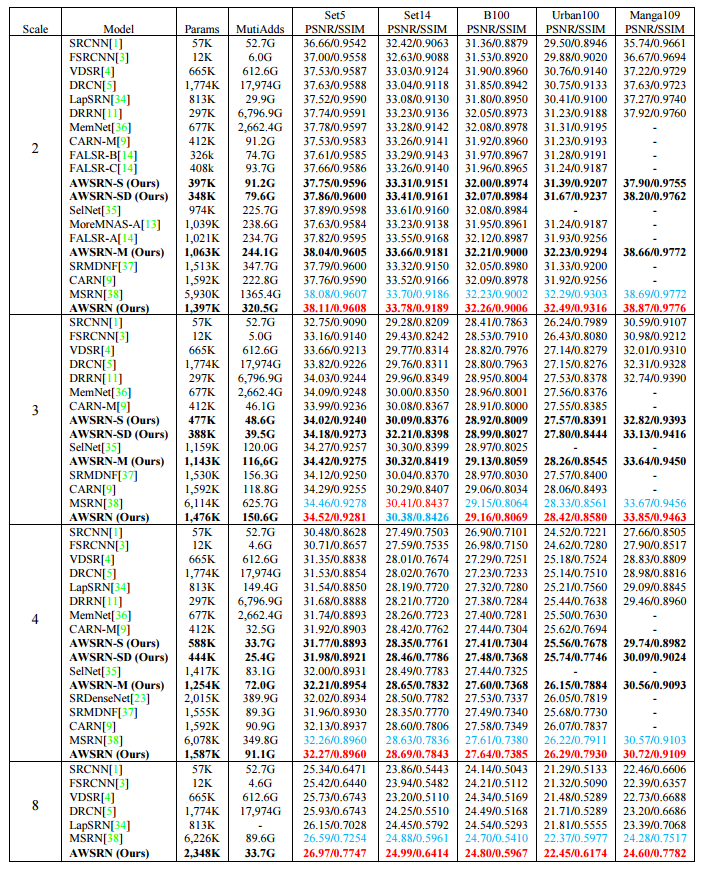
?基于单张图片估计人与物体的3D位姿和相互作用力, (from PSL Research University)
数据集:CMU MoCap data ] CMU Graphics Lab Motion Capture Database. http://mocap.cs.cmu.edu.
ref:求解优化问题的http://ceres-solver.org/
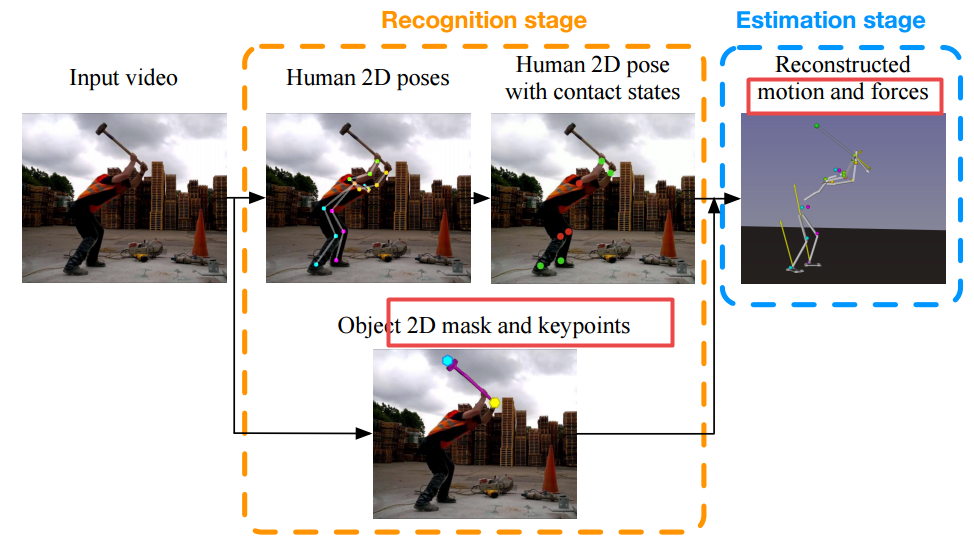
?T-Net,基于单高阶张量的参数化全卷积网络。 (from 三星剑桥AI研究中心 )
得到的一些结果:
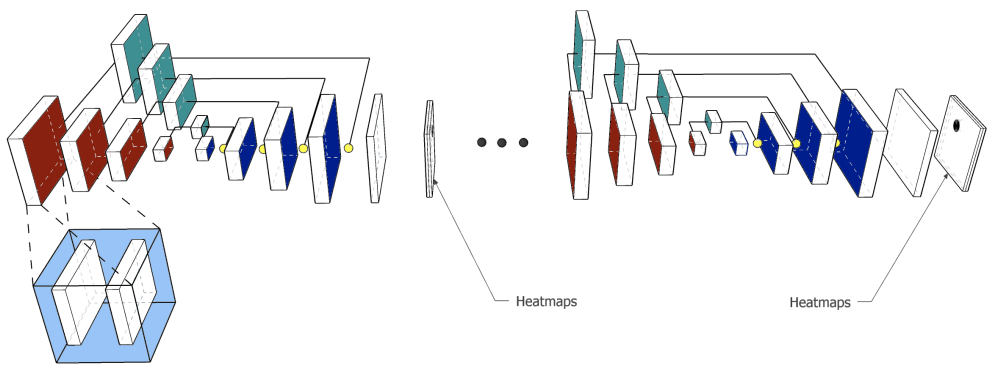


?MMED, 提出了一个多模态、多域的时间数据集,包含了对于412个事件的76516张来自Flickr图片和25165篇各大网站的新闻,可以用太过于事件发展的描述、跨域和交叉模态的研究。(from 广东工业大学)
热点事件的一些相关数据:
Daily Computer Vision Papers
| Libra R-CNN: Towards Balanced Learning for Object Detection Authors Jiangmiao Pang, Kai Chen, Jianping Shi, Huajun Feng, Wanli Ouyang, Dahua Lin 与模型体系结构相比,训练过程对于检测器的成功也是至关重要的,在对象检测中受到的关注相对较少。在这项工作中,我们仔细地重新审视了探测器的标准训练实践,发现探测性能往往受到训练过程中不平衡的限制,一般包括三个级别的样本级别,特征级别和目标级别。为了减轻由此引起的不利影响,我们提出了Libra R CNN,这是一种简单但有效的物体检测平衡学习框架。它集成了三个新颖的组件IoU平衡采样,平衡特征金字塔和平衡L1损耗,分别用于减少样本,特征和目标水平的不平衡。受益于整体平衡设计,Libra R CNN显着提高了检测性能。没有花里胡哨,它在MSCOCO上分别比FPN Faster R CNN和RetinaNet的平均精度AP高2.5分和2.0分。 |
| T-Net: Parametrizing Fully Convolutional Nets with a Single High-Order Tensor Authors Jean Kossaifi, Adrian Bulat, Georgios Tzimiropoulos, Maja Pantic 最近的研究结果表明,过度参数化虽然对成功训练深度神经网络至关重要,但也引入了大量冗余。张量方法有可能通过利用这种冗余来有效地对完整表示进行参数化。在本文中,我们提出用单个高阶,低秩张量完全参数化卷积神经网络CNN。以前关于网络张量化的工作主要集中在仅对卷积或完全连接的各个层进行参数化,并分别逐层执行张量化。相反,我们建议通过用单个高阶张量参数化来共同捕获神经网络的完整结构,其中的模式表示网络的每个架构设计参数,例如,卷积块数,深度,堆栈数,输入特征等。该参数化允许规范整个网络并大大减少参数的数量。我们的模型是端到端可训练的,并且施加在权重张量上的低秩结构充当隐式正则化。我们研究了具有丰富结构的网络的情况,即完全卷积网络FCN,我们建议用单个8阶张量进行参数化。我们表明,我们的方法可以在较小的压缩率下实现卓越的性能,并且在人体姿态估计的挑战性任务中获得高压缩率且精度下降可忽略不计。 |
| YOLACT: Real-time Instance Segmentation Authors Daniel Bolya, Chong Zhou, Fanyi Xiao, Yong Jae Lee 我们提出了一个简单的完全卷积模型,用于实时实例分割,在单个Titan Xp上以33 fps在MS COCO上实现29.8 mAP,这比以前的竞争方法快得多。此外,我们只在一个GPU上训练后获得此结果。我们通过将实例分段分成两个并行子任务1来实现这一点,该子任务生成一组原型掩码,并且每个实例掩码系数预测2个。然后我们通过将原型与掩模系数线性组合来生成实例掩码。我们发现因为这个过程不依赖于重新制作,所以这种方法可以产生非常高质量的掩模,并且可以免费显示时间稳定性。此外,我们分析了原型的紧急行为,并表明他们学会了以翻译变体方式自己本地化实例,尽管是完全卷积的。最后,我们还建议使用快速NMS,标准NMS的更换速度降低12 ms,仅具有边际性能损失。 |
| Estimating 3D Motion and Forces of Person-Object Interactions from Monocular Video Authors Zongmian Li, Jiri Sedlar, Justin Carpentier, Ivan Laptev, Nicolas Mansard, Josef Sivic 在本文中,我们介绍了一种自动重建与单个RGB视频中的对象交互的人的3D运动的方法。我们的方法估计人和肢体的3D姿势,接触位置,以及由人肢驱动的力和力矩。这项工作的主要贡献是三倍。首先,我们介绍一种方法,通过建模联系人及其相互作用的动态来联合估计人在被操纵物体上的运动和驱动力。这被视为大规模轨迹优化问题。其次,我们开发了一种方法,用于从输入视频中自动识别人与物体或地面之间的接触的位置和定时,从而显着简化优化的复杂性。第三,我们在最近的MoCap数据集上验证了我们对地面真实接触力的方法,并在一个新的互联网视频数据集上展示了它的表现,显示人们在不受约束的环境中操纵各种工具。 |
| UU-Nets Connecting Discriminator and Generator for Image to Image Translation Authors Wu Jionghao 对抗生成模型已成功地在图像合成中表现出来。然而,性能恶化和不稳定,因为鉴别器比发生器稳定,并且很难控制两个模块之间的游戏。通过添加或限制损失函数,已经引入了各种方法来解决诸如WGAN,相对论GAN及其后继者的问题,这肯定有助于平衡最小最大游戏,但是他们都关注于忽略内在结构限制的损失函数。我们提出了一个UU Net架构,其灵感来自U net桥接编码器和解码器,UU Net由两个U Net喜欢的模块组成,分别用作发生器和鉴别器。由于U网中的模块是对称的,因此它在所有四个组件之间容易共享权重。由于UU网络模块具有相同和对称的特性,我们不仅可以将内部发生器编码器的功能传送到其解码器,还可以传送到鉴别器的编码器和解码器。通过这种设计,它为我们提供了更多的控制和条件灵活性,可以干预发生器和鉴别器之间的过程。 |
| Deep Multi-class Adversarial Specularity Removal Authors John Lin, Mohamed El Amine Seddik, Mohamed Tamaazousti, Youssef Tamaazousti, Adrien Bartoli 我们提出了一种新的学习方法,采用完全卷积神经网络CNN的形式,通过生成其漫射分量,自动且一致地从单个图像中去除镜面高光。为了训练生成网络,我们在GAN框架中定义判别网络上的对抗性损失,并将其与内容丢失相结合。与现有的GAN方法相比,我们将鉴别器实现为多类分类器而不是二元分类器,以找到更多约束特征。这有助于网络通过提供两个更多的梯度项来精确定位漫反射歧管。我们还提供了一个合成数据集,旨在帮助网络很好地概括。我们展示了我们的模型在各种合成和真实图像中表现良好,并且在一致性方面优于现有技术。 |
| Algebraic Characterization of Essential Matrices and Their Averaging in Multiview Settings Authors Yoni Kasten, Amnon Geifman, Meirav Galun, Ronen Basri 基本矩阵平均,即在校准的多视图设置中恢复相机位置和方向的任务,是从运动到欧几里德结构的全局方法的第一步。基本矩阵平均的常用方法是分别求解摄像机方向和随后的摄像机位置。本文介绍了一种同时解决相机方向和位置的新方法。我们提供了代数条件的完整表征,可以从n 2个基本矩阵的集合中对n个摄像机进行独特的欧几里德重建。我们接下来使用这些条件来制定基本矩阵平均作为约束优化问题,允许我们恢复一组一致的基本矩阵,给定可能部分的一组测量的基本矩阵,这些基本矩阵是针对图像对独立计算的。我们最终使用恢复的基本矩阵来确定n个摄像机的全局位置和方向。我们在常见的SfM数据集上测试我们的方法,与现有方法相比,证明了高精度,同时保持了效率和稳健性。 |
| On Direct Distribution Matching for Adapting Segmentation Networks Authors Georg Pichler, Jose Dolz, Ismail Ben Ayed, Pablo Piantanida 分布匹配损失的最小化是图像分类环境中域适应的原理方法。然而,在适应分段网络时,它在很大程度上被忽视,目前分区网络主要是对抗模型。我们提出了一类损失函数,它们鼓励在网络输出空间中进行直接的核密度匹配,直到从未标记的输入计算出一些几何变换。我们的直接方法不是使用中间域鉴别器,而是在一次丢失中统一分布匹配和分段。因此,它通过避免额外的对抗步骤简化了分段适应,同时提高了培训的质量,稳定性和效率。我们通过网络输出空间中的对抗训练将我们的方法与最先进的分段自适应并置。在针对不同磁共振图像MRI模态调整脑分割的挑战性任务中,我们的方法在准确性和稳定性方面实现了明显更好的结果。 |
| Siamese Encoding and Alignment by Multiscale Learning with Self-Supervision Authors Eric Mitchell, Stefan Keselj, Sergiy Popovych, Davit Buniatyan, H. Sebastian Seung 我们提出了一种将源图像与目标图像对齐的方法,其中变换由密集矢量场指定。这两个图像由暹罗卷积网编码为特征层次结构。然后,对齐器模块的层次结构计算粗略到精细递归的变换。每个模块接收由上述级别的模块计算的变换作为输入,将源和目标编码对齐在层次结构的同一级别,然后使用卷积网络计算对变换的改进近似。编码器和对准器网络的整个架构以自我监督的方式训练,以最小化对准后剩余的源和目标之间的平方误差。我们表明,暹罗编码可以实现比SPyNet的图像金字塔更准确的对齐,这是以前深度学习到粗略到精确对齐的方法。此外,与强监督的SPyNet不同,即使没有目标值,自我监督也适用。我们还表明,我们的方法优于单次对准方法,因为当位移很大时,后一种方法中的精细路径可能无法有助于对准精度。如前一次拍摄方法所示,自监督学习的良好结果要求损失函数另外惩罚非平滑变换。我们证明在不连续点附近屏蔽惩罚函数导致非平滑变换的正确恢复。我们的声明得到了使用来自脑组织的连续切片电子显微镜图像的经验比较的支持。 |
| Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection Authors Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, Anton van den Hengel 深度自动编码器已广泛用于异常检测。对正常数据进行训练,预计自动编码器对异常输入产生比正常输入更高的重建误差,这被用作识别异常的标准。但是,这种假设并不总是在实践中存在。已经观察到,有时自动编码器概括得很好,以至于它也可以很好地重建异常,导致异常的未命中检测。为了减轻基于自动编码器的异常检测器的这个缺点,我们建议用存储器模块来增强自动编码器,并开发一种称为存储器增强自动编码器的改进的自动编码器,即MemAE。给定输入,MemAE首先从编码器获得编码,然后将其用作查询以检索用于重建的最相关的存储器项。在训练阶段,更新存储器内容并鼓励它们表示正常数据的原型元素。在测试阶段,学习的存储器将被固定,并且从正常数据的一些选定的存储器记录获得重建。因此,重建将倾向于接近正常样本。因此,异常的重建误差将被加强以进行异常检测。 MemAE没有对数据类型的假设,因此通常适用于不同的任务。各种数据集的实验证明了所提出的MemAE的优异推广和高效性。 |
| Clinically Accurate Chest X-Ray Report Generation Authors Guanxiong Liu, Tzu Ming Harry Hsu, Matthew McDermott, Willie Boag, Wei Hung Weng, Peter Szolovits, Marzyeh Ghassemi 通过医疗射线照片自动生成放射学报告具有在操作和临床上改善患者护理的巨大潜力。许多先前的工作集中在这个问题上,采用来自计算机视觉和自然语言生成的先进方法来产生可读报告。然而,这些工作通常不能解释放射学领域的特定细微差别,特别是在生成的报告中临床准确性的重要性。在这项工作中,我们提出了一个领域感知自动胸部X射线放射学报告生成系统,该系统首先预测将在报告中讨论哪些主题,然后有条件地生成与这些主题相对应的句子。根据提出的临床相关奖励评估,考虑到可读性和临床准确性,使用强化学习对所得系统进行微调。我们在两个数据集Open I和MIMIC CXR上验证了该系统,并证明我们的模型在语言生成指标和CheXpert评估的准确性方面都提供了显着的改进,可用于各种竞争基线。 |
| A Learned Representation for Scalable Vector Graphics Authors Raphael Gontijo Lopes, David Ha, Douglas Eck, Jonathon Shlens 生成模型的巨大进步已经导致人工渲染的面部,动物和自然界中的其他物体的近摄影质量。尽管取得了这些进步,但对于视觉和图像的更高层次的理解并不是从对象的详尽建模中产生的,而是识别最能概括对象方面的更高级别的属性。在这项工作中,我们尝试通过构建矢量图形的顺序生成模型来模拟字体的绘制过程。该模型的好处是为图像提供尺度不变表示,其潜在表示可以被系统地操纵和利用来执行样式传播。我们在大型字体数据集上演示了这些结果,并重点介绍了这种模型如何捕获此数据集的统计依赖性和丰富性。我们设想我们的模型可以用作图形设计师的工具,以方便字体设计。 |
| An End-to-End Baseline for Video Captioning Authors Silvio Olivastri, Gurkirt Singh, Fabio Cuzzolin 在视频和语言等不同模式中建立对应关系,最近在许多视觉识别应用中变得至关重要,例如视频字幕。受机器翻译的启发,最近的模型使用编码器解码器策略来解决此任务。视频编码器传统上是卷积神经网络CNN,而用于语言生成的解码是使用递归神经网络RNN完成的。然而,现有技术方法分别训练编码器和解码器。 CNN在对象和/或动作识别任务上预先训练,并用于编码视频级功能。然后,在这些静态特征上优化解码器以生成视频描述。对于输入视频输出描述映射,这种不相交的设置可以说是次优的。 |
| Signal-to-Noise Ratio: A Robust Distance Metric for Deep Metric Learning Authors Tongtong Yuan, Weihong Deng, Jian Tang, Yinan Tang, Binghui Chen 深度度量学习,其学习用于处理图像聚类和检索任务的判别性特征,近年来引起了广泛关注。已经提出了许多深度量度学习方法,其确保相似的示例彼此接近地映射并且不同的示例被更远地映射,已经提出构建用于损失函数的有效结构并且已经显示出有希望的结果。在本文中,与学习损耗结构的方法不同,我们提出了一种基于信噪比SNR的鲁棒SNR距离度量,用于测量深度量学习的图像对的相似性。通过从几何空间和统计理论的角度探索我们的SNR距离度量的属性,我们分析了度量的属性,并表明它可以保留图像对之间的语义相似性,这很好地证明了它对深度度量学习的适用性。与欧几里德距离度量相比,我们的SNR距离度量可以进一步共同减少类内距离并扩大学习特征的类间距离。利用我们的SNR距离度量,我们提出基于深度SNR的度量学习DSML来生成判别性特征嵌入。通过对三个广泛采用的基准测试的广泛实验,包括CARS196,CUB200 2011和CIFAR10,我们的DSML显示出其优于其他最先进方法的优势。此外,我们将SNR距离度量扩展到深度哈希学习,并在两个基准上进行实验,包括CIFAR10和NUS WIDE,以证明我们的SNR距离度量的有效性和一般性。 |
| Sampling Limits for Electron Tomography with Sparsity-exploiting Reconstructions Authors Yi Jiang, Elliot Padgett, Robert Hovden, David A. Muller 电子断层扫描ET已成为纳米级材料的3D表征的标准技术。诸如加权反投影的传统重建算法遭受具有不充分投影的破坏性伪像。通过压缩感知推广,稀疏度开发算法已应用于实验ET数据,并显示出改善重建质量或减少应用于样本的总束剂量的前景。然而,在ET应用的背景下,对这些方法的理论界限的研究较少。在这里,我们进行数值模拟,以研究在各种成像条件下l 1范数和总变差TV最小化的性能。从36,100种不同的模拟结构中,我们的结果显示具有更复杂结构的样本通常需要更多的投影来进行精确重建。然而,一旦获得足够的数据,将光束剂量除以更多的投影就没有提供类似于传统剂量分数定理的改进。此外,75或更小的有限倾斜范围可导致在利用重建的稀疏性中扭曲伪影。还讨论了优化参数对重建的影响。 |
| 3D Face Reconstruction Using Color Photometric Stereo with Uncalibrated Near Point Lights Authors Zhang Chen, Yu Ji, Mingyuan Zhou, Sing Bing Kang, Jingyi Yu 我们提出了一种新的彩色光度立体CPS方法,可以一次性恢复高质量,详细的3D面几何。我们的系统使用三个不同颜色的未校准近点灯和一个摄像头。我们首先利用3D可变模型3DMM和面部部件的语义分割来实现光源的稳健自校准。然后,我们通过将反照率共识,反照率相似性和代理先验纳入统一框架来解决光谱模糊问题。我们避免了对反照率的空间恒定性的需要,并使用基于反照率范数轮廓的反照率相似性的新度量。实验表明,我们的新方法在具有高保真几何形状的单个图像中产生最先进的结果,其包括诸如皱纹的细节。 |
| Towards 3D Human Shape Recovery Under Clothing Authors Xin Chen, Anqi Pang, Yu Zhu, Yuwei Li, Xi Luo, Ge Zhang, Peihao Wang, Yingliang Zhang, Shiying Li, Jingyi Yu 我们提出了一种基于学习的方案,用于在穿着的3D人体扫描中稳健且准确地估计服装适合度以及人体形状。我们的方法将穿着的人体几何图形映射到我们称之为穿着的GI的几何图像。为了使穿着的GI在不同的衣服下对齐,我们扩展了参数化的人体模型,并采用骨架检测和翘曲来实现可靠的对齐。对于穿着的GI上的每个像素,我们提取包括颜色纹理,位置,法线等的特征向量,并使用全面的3D服装训练用于每像素适应度预测的修改的条件GAN网络。我们的技术显着提高了人体形状预测的准确性,特别是在宽松和合身的服装下。我们进一步展示了使用我们的结果进行人类服装细分和虚拟衣服的高度视觉真实感。 |
| Geometry of the Hough transforms with applications to synthetic data Authors Mauro C. Beltrametti, Cristina Campi, Anna Maria Massone, Maria Laura Torrente 在用于检测图像中的曲线的霍夫变换技术的框架中,我们提供了用于在识别算法中成功优化累加器函数的霍夫变换的数量的界限。这种界限是几何论证的结果。当应用于受噪声强烈扰动的合成数据集时,我们还显示结果的稳健性。附录中讨论的代数方法在确切的情况下导致理论兴趣的更好界限。 |
| Segmentation of the Prostatic Gland and the Intraprostatic Lesions on Multiparametic MRI Using Mask-RCNN Authors Zhenzhen Dai, Eric Carver, Chang Liu, Joon Lee, Aharon Feldman, Weiwei Zong, Milan Pantelic, Mohamed Elshaikh, Ning Wen 前列腺癌PCa是美国男性中最常见的癌症。多参数磁共振成像mp MRI已被许多研究人员用于靶向前列腺活检和放射治疗。然而,对mp MRI的评估可能是主观的,计算机辅助诊断系统的发展以自动描绘前列腺和前内部病变ILs对于促进放射科医师在临床实践中变得重要。在本文中,我们首先研究Mask RCNN模型的实现,以分割前列腺和ILs。我们对来自两个不同患者群的120名患者进行了模型训练和评估。我们还使用2D U Net和3D U Net作为分割前列腺的基准,并比较了模型的性能。使用该算法的ILs的轮廓可变性也与19名患者的两个不同放射肿瘤学家之间的观察者间变异性进行了基准比较。我们的结果表明,Mask RCNN模型能够在前列腺分割中达到最先进的性能,并且在ILs分割中优于几个竞争基线。 |
| Noise-Level Estimation from Single Color Image Using Correlations Between Textures in RGB Channels Authors Akihiro Nakamura, Michihiro Kobayashi 我们提出了一种估算单色图像噪声水平的简单方法。在大多数图像去噪算法中,准确的噪声水平估计导致良好的去噪性能,然而,难以从单个图像估计噪声水平,因为它是一个不适合的问题。我们通过使用纹理在RGB通道之间高度相关并且噪声与其他信号不相关的先验知识来解决这个问题。我们还扩展了RAW图像的方法,因为它们几乎适用于所有数码相机,并且经常在实际情况下使用。实验表明,该方法在合成噪声图像中具有较高的噪声估计性能。我们还将我们的方法应用于包括RAW图像的自然图像,并且实现了比传统方法更好的噪声估计性能。 |
| Generic Multiview Visual Tracking Authors Minye Wu, Haibin Ling, Ning Bi, Shenghua Gao, Hao Sheng, Jingyi Yu 视觉跟踪的最新进展极大地改善了跟踪性能。然而,诸如遮挡和视图变化等挑战仍然是现实世界部署中的障碍。对这些挑战的自然解决方案是使用具有多视图输入的多个摄像机,尽管现有系统主要限于特定目标,例如人体,静态相机和/或相机校准。为了突破这些限制,我们提出了一种通用的多视图跟踪GMT框架,它允许相机移动,同时既不需要特定的物体模型也不需要相机校准。我们框架中的一个关键创新是交叉相机轨迹预测网络TPN,它隐式地和动态地编码相机几何关系,因此解决了诸如遮挡之类的缺失目标问题。此外,在跟踪期间,我们跨不同相机组装信息以动态更新新颖的协作相关滤波器CCF,其在相机之间共享以实现对视图改变的鲁棒性。这两个组件集成到相关过滤器跟踪框架中,其中使用现有的单视图跟踪数据集离线训练要素。为了进行评估,我们首先提供一个新的通用多视图跟踪数据集GMTD,仔细注释,然后在GMTD和PETS2009数据集上进行实验。在两个数据集上,所提出的GMT算法显示出优于现有技术的明显优势。 |
| DeCaFA: Deep Convolutional Cascade for Face Alignment In The Wild Authors Arnaud Dapogny, K vin Bailly, Matthieu Cord 面部对齐是一个活跃的计算机视觉领域,它包括本地化多个不同数据集的面部标志。现有技术的面部对齐方法或者包括端到端的回归,或者从初始猜测开始以级联的方式细化形状。在本文中,我们介绍了DeCaFA,一种用于面部对齐的端到端深度卷积级联架构。 DeCaFA使用完全卷积阶段来保持整个级联的全空间分辨率。在每个级联阶段之间,DeCaFA使用具有空间softmax的多个链式转移层来为几个标志性对齐任务中的每一个生成具有里程碑意义的注意力图。加权中间监督以及阶段之间的有效特征融合允许学习以端到端方式逐步细化关注图。我们通过实验证明,DeCaFA在300W,CelebA和WFLW数据库上的表现明显优于现有方法。此外,我们表明DeCaFA可以使用粗略注释的数据从非常少的图像中以合理的准确度学习精确对齐。 |
| Deep Multi-scale Discriminative Networks for Double JPEG Compression Forensics Authors Cheng Deng, Zhao Li, Xinbo Gao, Dacheng Tao 由于JPEG是最广泛使用的图像格式,盲目取证中JPEG图像的篡改检测的重要性是不言而喻的。在该领域中,从JPEG图像中提取有效的统计特征以进行分类仍然是一个挑战。有效的功能是通过传统方法手动设计的,这表明需要进行大量耗费劳力的研究和推导。在本文中,我们提出了一种基于深度多尺度判别网络MSD网络的图像篡改检测方法。多尺度模块被设计为从JPEG图像的离散余弦变换DCT系数直方图中自动提取多个特征。该模块可以捕获不同尺度空间中的特征信息。另外,当第一压缩质量QF1高于第二压缩质量QF2时,还利用判别模块来改善网络在那些困难情况下的检测效果。该模块中的特殊网络旨在区分这些情况下真实区域和篡改区域之间的小的统计差异。最后,可以获得概率图,并使用最后的分类结果来定位特定的篡改区域。大量实验证明,与现有技术方法相比,我们提出的方法在定量和定性指标方面具有优势。 |
| Unsupervised Learning of Eye Gaze Representation from the Web Authors Neeru Dubey, Shreya Ghosh, Abhinav Dhall 自动眼睛注视估计已经对研究人员感兴趣了一段时间。在本文中,我们提出了一种用于估计眼睛注视区域的无监督学习方法。为了以自我监督的方式训练提议的网络Ize Net,我们收集了包含来自网络的1,54,251个图像的野外数据集。对于数据库中的图像,我们基于基于瞳孔中心定位的自动技术将凝视划分为三个区域,然后使用基于特征的技术来确定凝视区域。通过微调Ize Net的结果来评估平板凝视和CAVE数据集的性能,用于眼睛注视估计的任务。所学习的特征表示还用于训练用于眼睛注视估计的传统机器学习算法。结果表明,所提出的方法学习了丰富的数据表示,可以针对任何眼睛注视估计数据集进行有效微调。 |
| Active Transfer Learning Network: A Unified Deep Joint Spectral-Spatial Feature Learning Model For Hyperspectral Image Classification Authors Cheng Deng, Yumeng Xue, Xianglong Liu, Chao Li, Dacheng Tao 深度学习最近在高光谱图像HSIs分类领域引起了极大的关注。然而,有效的深度神经网络DNN的构建主要依赖于大量可用的标记样本。为了解决这个问题,本文提出了一个统一的深度网络,结合主动转移学习,只需使用最少标记的训练数据就可以很好地训练HSIs分类。更具体地,首先通过分层堆叠稀疏自编码器SSAE网络提取深联合频谱空间特征。然后利用主动转移学习将预训练的SSAE网络和有限的训练样本从源域转移到目标域,其中SSAE网络随后使用从源域和目标域中选择的有限标记样本通过相应的活动进行微调。学习策略。我们提出的方法的优点是三重1,在新的主动学习策略的帮助下,仅使用有限的标记样本可以有效地训练网络2网络灵活且可扩展到足以在各种传输情况下运行,包括交叉数据集和图像内3学习的深联合光谱空间特征表示比许多联合光谱空间特征表示更通用和鲁棒。广泛的比较评估表明,我们提出的方法在三个流行的数据集上明显优于许多最先进的方法,包括传统和深度网络方法。 |
| Resource Efficient 3D Convolutional Neural Networks Authors Okan K p kl , Neslihan Kose, Ahmet Gunduz, Gerhard Rigoll 最近,具有3D内核3D CNN的卷积神经网络在计算机视觉社区中非常流行,这是因为与2D CNN相比,它们在视频帧内提取空间时间特征的能力更强。尽管最近在考虑存储器和功率预算的情况下构建资源有效的2D CNN架构已经取得了很大的进步,但是对于3D CNN几乎没有任何类似的资源有效架构。在本文中,我们已将各种众所周知的资源有效的2D CNN转换为3D CNN,并根据不同复杂度级别的分类准确度评估了它们在三个主要基准上的性能。我们已经对1 Kinetics 600数据集进行了实验,以检查其学习能力,2 Jester数据集检查其捕获手部运动模式的能力,以及3 UCF 101检查转移学习的适用性。我们已经在单个GPU和嵌入式GPU上评估了每个模型的运行时性能。这项研究的结果表明,这些模型可用于不同类型的实际应用,因为它们提供了具有相当精确度和内存使用的实时性能。我们对不同复杂度级别的分析表明,为了节省复杂性,资源有效的3D CNN不应设计得太浅或太窄。本工作中使用的代码和预训练模型是公开的。 |
| Inferring Dynamic Representations of Facial Actions from a Still Image Authors Siyang Song, Enrique S nchez Lozano, Linlin Shen, Alan Johnston, Michel Valstar 面部动作本质上是时空信号,因此它们的建模关键取决于时间信息的可用性。在本文中,我们专注于在没有明确的时间信息可用时,即从静止图像中推断出面部动作的这种时间动态。我们提出了一种新方法来捕捉这种时间动态的多个尺度,并应用于面部动作单元AU强度估计和尺寸影响估计。特别地,我们提出了一个框架,它从静止图像中推断出动态表示DR,它捕获以输入图像2为中心的短时间窗口内的双向时间流,我们表明我们可以在不需要的情况下训练我们的方法。显式地生成目标表示,允许网络更广泛地表示动态,并且我们建议应用多时间尺度方法,其针对来自静止图像的不同窗口长度MDR推断DR。我们凭经验验证了我们的方法在帧排序任务中的价值,并展示了我们提出的MDR如何在AU4强度估计的BP4D和SEMAINE上获得最先进的结果,用于尺寸影响估计,在测试时仅使用静止图像。 |
| Generalizing discrete convolutions for unstructured point clouds Authors Alexandre Boulch 点云是非结构化和无序数据,而不是图像。因此,为图像开发的大多数机器学习方法不能直接转移到点云。它通常需要数据转换,例如体素化,从而导致可能的信息丢失。在本文中,我们提出了能够处理稀疏输入点云的离散卷积神经网络CNN的推广。我们用连续的内核替换离散内核。配方简单,不设置输入点云大小,可以像2D CNN一样轻松地用于神经网络设计。我们提出了与现有技术竞争的实验结果,用于大规模云的形状分类,部分分割和语义分割。 |
| Architecture Search of Dynamic Cells for Semantic Video Segmentation Authors Vladimir Nekrasov, Hao Chen, Chunhua Shen, Ian Reid 在语义视频分割中,目标是在图像帧上获得一致的密集语义标记。为此,最近的方法依赖于在静态语义分段网络之上应用的手动布置的操作,其中最突出的构建块是能够提供关于场景动态的信息的光流。与此相关的是关于通过用更便宜的替代品近似其昂贵部分来加速静态网络的研究,同时传播来自先前帧的信息。在这项工作中,我们尝试提出这些方法的概括,而不是手动设计连接每帧输出的上下文块,我们提出了一种神经架构搜索解决方案,其中操作的选择连同它们的顺序排列由一个预测分离神经网络。我们展示了这种泛化可以在常见基准测试中获得稳定和准确的结果,例如CityScapes和CamVid数据集。重要的是,所提出的方法仅花费2个GPU天,找到高性能单元并且不依赖于昂贵的光流计算。 |
| Template-Based Automatic Search of Compact Semantic Segmentation Architectures Authors Vladimir Nekrasov, Chunhua Shen, Ian Reid 自动搜索各种视觉和自然语言任务的神经架构正在成为一个突出的工具,因为它允许在任何感兴趣的数据集上发现高性能结构。然而,在更困难的领域,例如密集的每像素分类,当前的自动方法由于其对现有图像分类器的强烈依赖而在其范围上受到限制,它们倾向于仅搜索少数具有仍然包含大量的发现的体系结构的附加层。参数。相比之下,在这项工作中,我们提出了一种新颖的解决方案,能够从预训练的分类网络的仅几个块开始找到轻量级和准确的分段架构。为此,我们逐步建立一种依赖于操作集模板的方法,预测每个步骤应该应用哪个模板和多少次,同时还生成连接结构和下采样因子。所有这些决定都是由一个递归的神经网络做出的,该神经网络根据保持集上发射的体系结构的得分进行奖励,并使用强化学习进行训练。一个发现的架构在CamVid上达到63.2平均IoU,在CityScapes上达到67.8,只有270K参数。 |
| Spatiotemporal CNN for Video Object Segmentation Authors Kai Xu, Longyin Wen, Guorong Li, Liefeng Bo, Qingming Huang 在本文中,我们提出了一个统一的,端到端可训练的VOS时空CNN模型,它由两个分支组成,即时间相干分支和空间分割分支。具体地,从未标记的视频数据以对抗方式预训练的时间相干分支被设计为捕获视频序列的动态外观和运动提示以指导对象分割。空间分割分支侧重于基于所学习的外观和运动提示准确地分割对象。为了获得准确的分割结果,我们设计了粗到精的过程,以便在多尺度特征图上顺序应用设计的注意模块,并将它们连接起来以产生最终预测。以这种方式,强制执行空间分割分支以逐渐集中于对象区域。这两个分支以端到端的方式联合微调视频分段序列。对三个具有挑战性的数据集进行了若干实验,即DAVIS 2016,DAVIS 2017和Youtube Object,以表明我们的方法在对抗现有技术方面取得了良好的性能。代码可在 |
| Lightweight Image Super-Resolution with Adaptive Weighted Learning Network Authors Chaofeng Wang, Zheng Li, Jun Shi 深度学习已成功应用于单图像超分辨率SISR任务,近年来表现出色。然而,大多数基于卷积神经网络的SR模型需要大量计算,这限制了它们的实际应用。在这项工作中,为SISR提出了一个名为自适应加权超分辨率网络AWSRN的轻量级SR网络来解决这个问题。在AWSRN中设计了一种新颖的局部融合块LFB,用于有效的残差学习,其由堆叠的自适应加权残差单元AWRU和局部残余融合单元LRFU组成。此外,提出了一种自适应加权多尺度AWMS模块,以充分利用重建层中的特征。 AWMS由几个不同的尺度卷积组成,并且可以根据AWMS中自适应权重对轻量网络的贡献来移除冗余尺度分支。在常用数据集上的实验结果表明,所提出的轻量级AWSRN在x2,x3,x4和x8比例因子上实现了对具有相似参数和计算开销的现有技术方法的优越性能。代码可以在 |
| Multi-View Intact Space Learning Authors Chang Xu, Dacheng Tao, Chao Xu 假设单个视图不足以进行有效的多视图学习是切合实际的。因此,多视图信息的集成既有价值又必要。在本文中,我们提出了多视图完整空间学习MISL算法,该算法将编码的互补信息集成在多个视图中,以发现数据的潜在完整表示。尽管每个视图本身都不够,但我们从理论上证明,通过结合多个视图,我们可以获得有关潜在完整空间学习的丰富信息。采用Cauchy损失作为误差测量的统计学习中使用的技术增强了对异常值的鲁棒性。我们提出了一种新的多视图稳定性定义,然后推导出基于多视图稳定性和Rademacher复杂度的泛化误差界限,并表明多视图之间的互补性有利于稳定性和泛化。使用新颖的迭代重量残差IRR技术对MISL进行了有效优化,从理论上分析了其收敛性。对合成数据和现实世界数据集的实验表明,MISL是一种有效且有前景的实际应用算法。 |
| Feature Pyramid Hashing Authors Yifan Yang, Libing Geng, Hanjiang Lai, Yan Pan, Jian Yin 近年来,基于深度网络的散列已成为大规模图像检索的主要方法。大多数深度哈希方法使用高层来提取强大的语义表示。然而,这些方法对于细粒度图像检索的能力有限,因为从高层提取的语义特征难以捕获细微的差异。为此,我们提出了一种新颖的两个金字塔散列体系结构,以学习细粒度图像搜索的语义信息和细微外观细节。受卷积神经网络特征金字塔的启发,提出了一个垂直金字塔来捕捉高层特征,一个水平金字塔将多个低层特征与结构信息相结合,以捕捉细微的差异。为了融合低级特征,提出了一种新的组合策略,称为共识融合,以捕获来自几个低层的所有细微信息,以便更精细地检索。对两个细粒度数据集CUB 200 2011和Stanford Dogs的广泛评估表明,与现有技术基线相比,所提出的方法实现了显着的性能。 |
| Modified Distribution Alignment for Domain Adaptation with Pre-trainedInception ResNet Authors Youshan Zhang, Brian D. Davison 深度神经网络已广泛用于计算机视觉。有几个训练有素的深度神经网络用于ImageNet分类挑战,它在图像识别中发挥了重要作用。然而,很少有工作探索预训练的神经网络用于域适应中的图像识别。在本文中,我们是第一个从训练有素的Inception ResNet模型中提取更好的代表特征以进行领域适应。然后,我们使用提取的特征呈现用于分类的修改的分布对齐方法。我们使用Office Caltech 10,Office 31和Office Home三个基准数据集测试我们的模型。广泛的实验证明了相对于现有技术的分类精度的显着改进4.8,5.5和10。 |
| Comparison Network for One-Shot Conditional Object Detection Authors Tengfei Zhang, Yue Zhang, Xian Sun, Hao Sun, Menglong Yan, Xue Yang, Kun Fu 目标检测的当前进展取决于大规模数据集以获得良好的性能。然而,在许多场景中可能并不总是有足够的样本,这导致对少量镜头检测以及其极端变化一次检测的研究。在本文中,单击检测已经被公式化为条件概率问题。通过这种见解,已经提出了一种新颖的一次性条件对象检测OSCD框架,称为比较网络比较网络。具体地,通过Siamese网络提取查询和目标图像特征作为边缘概率的映射度量。引入用于OSCD的两级检测器以将提取的查询和目标特征与可学习度量进行比较以接近优化的非线性条件概率。一旦经过训练,ComparisonNet就可以在没有进一步训练的情况下检测看到和看不见的类的对象,这也具有包括类不可知,对看不见的类免费训练以及没有灾难性遗忘的优点。实验表明,所提出的方法在Fashion MNIST和PASCAL VOC的数据集上实现了最先进的性能。 |
| Improved Inference via Deep Input Transfer Authors Saied Asgari Taghanaki, Kumar Abhishek, Ghassan Hamarneh 尽管在使用卷积神经网络的图像分割领域已经进行了许多改进,但是这些改进中的大多数依赖于具有较大数据集,模型架构修改,新颖损失函数和更好的优化器的训练。在本文中,我们提出了一种新的分段性能提升范例,它依赖于最优地修改网络输入而不是网络本身。特别地,我们利用训练的分割网络相对于输入的梯度将其转移到分割精度提高的空间。我们在三个公开可用的医学图像分割数据集上测试了所提出的方法:ISIC 2017皮肤病变分割数据集,深圳胸部X射线数据集和CVC ColonDB数据集,我们的方法在平均值上实现了5.8,0.5和4.8的改进骰子分数。 |
| A Training-free, One-shot Detection Framework For Geospatial Objects In Remote Sensing Images Authors Tengfei Zhang, Yue Zhang, Xian Sun, Menglong Yan, Yaoling Wang, Kun Fu 基于深度学习的对象检测取得了巨大成功。然而,这些监督学习方法是数据耗费且耗时的。这种限制使它们不适合有限的数据和紧急任务,特别是在遥感应用中。受到人类从极少数例子中快速学习新视觉概念的能力的启发,我们提出了一种用于遥感图像的免费训练一次性地理空间物体检测框架。它由1个具有遥感领域知识的特征提取器,2个多级特征融合方法,3个新颖的相似性度量方法和4个2阶段目标检测流水线组成。污水处理厂和机场检测实验表明,该方法取得了一定的效果。我们的方法可以作为训练免费一次性地理空间物体检测的基线。 |
| Cost-Sensitive Feature Selection by Optimizing F-Measures Authors Meng Liu, Chang Xu, Yong Luo, Chao Xu, Yonggang Wen, Dacheng Tao 通过从高维特征中提取信息子集,特征选择有益于改善一般机器学习任务的性能。传统的特征选择方法通常忽略类不平衡问题,因此所选择的特征将偏向于多数类。考虑到F度量是一种比不平衡数据的准确性更合理的性能度量,本文提出了一种有效的特征选择算法,通过优化F度量来探讨类不平衡问题。由于F度量优化可以分解为一系列成本敏感的分类问题,我们通过严格的理论指导为每个类生成和分配不同的成本来研究成本敏感的特征选择。在解决了一系列成本敏感的特征选择问题之后,将选择与最佳F度量相对应的特征。这样,所选特征将完全代表所有类的属性。在流行的基准和具有挑战性的现实世界数据集上的实验结果证明了成本敏感特征选择对于不平衡数据设置的重要性,并验证了所提出方法的有效性。 |
| Gated-GAN: Adversarial Gated Networks for Multi-Collection Style Transfer Authors Xinyuan Chen, Chang Xu, Xiaokang Yang, Li Song, Dacheng Tao 风格转移将图像语义内容的呈现描述为不同的艺术风格。最近,生成对抗性网络GAN已经成为一种有效的风格转移方法,通过对抗训练发生器来合成令人信服的假冒伪劣。但是,传统的GAN存在模式崩溃问题,导致训练不稳定,难以保证风格转移质量。此外,GAN生成器仅与一种风格兼容,因此必须训练一系列GAN,以便为用户提供转移多种风格的选择。在本文中,我们专注于解决这些挑战和限制,以改善风格转移。我们建议对抗门控网络Gated GAN在单个模型中传输多种样式。生成网络有三个模块,一个编码器,一个门控变换器和一个解码器。通过将输入图像传递到门控变压器的不同分支可以实现不同的样式。为了稳定训练,编码器和解码器被组合为自动编码器以重建输入图像。辨别网络用于区分输入图像是程式化还是真实图像。辅助分类器用于识别转移图像的样式类别,从而帮助生成网络以多种样式生成图像。此外,Gated GAN通过调查从艺术家或流派中学习的风格,探索新风格。我们的广泛实验证明了所提出的多元素转移模型的稳定性和有效性。 |
| StereoDRNet: Dilated Residual Stereo Net Authors Rohan Chabra, Julian Straub, Chris Sweeny, Richard Newcombe, Henry Fuchs 我们提出了一种系统,该系统使用卷积神经网络CNN来估计来自立体对的深度,然后进行预测深度图的体积融合以产生场景的3D重建。我们提出的深度细化架构,预测视图一致的视差和遮挡贴图,帮助融合系统产生几何一致的重建。我们在我们提出的成本过滤网络中利用3D扩张卷积,与现有的成本过滤架构相比,产生更好的滤波,同时几乎减半计算成本。对于特征提取,我们使用Vortex Pooling架构。所提出的方法在KITTI 2012,KITTI 2015和ETH 3D立体基准测试中实现了最先进的结果。最后,我们证明了我们的系统能够产生高保真3D场景重建,其性能优于最先进的立体声系统。 |
| Unpaired Thermal to Visible Spectrum Transfer using Adversarial Training Authors Adam Nyberg, Abdelrahman Eldesokey, David Bergstr m, David Gustafsson 热红外TIR相机由于能够在低光照条件下操作而在许多计算机视觉应用中越来越受欢迎。由TIR相机产生的图像通常难以在视觉上感知人,这限制了它们的可用性。通过将TIR图像转换为逼真的可见光谱VIS图像,提出了文献中的几种方法来解决该问题。然而,现有的TIR VIS数据集遭受TIR VIS图像对之间的不完全对准,这降低了监督方法的性能。我们通过使用无监督的生成对抗网络GAN来学习这种转换来解决这个问题,该无人监督的生成对抗网络GAN训练未配对的TIR和VIS图像。当在KAIST MS数据集上进行训练和评估时,我们提出的方法显示出比现有技术监督方法产生明显更逼真和更清晰的VIS图像。此外,我们提出的方法在新环境的新数据集上进行评估时显示出很好的推广。 |
| Hyperbolic Image Embeddings Authors Valentin Khrulkov, Leyla Mirvakhabova, Evgeniya Ustinova, Ivan Oseledets, Victor Lempitsky 计算机视觉任务,如图像分类,图像检索和少量镜头学习目前由欧几里德和球形嵌入主导,因此关于类所有物或相似程度的最终决定是使用线性超平面,欧几里德距离或球面测地距离余弦进行的。相似性。在这项工作中,我们证明了在许多实际场景中,双曲线嵌入提供了更好的选择。 |
| Revisiting Visual Grounding Authors Erik Conser, Kennedy Hahn, Chandler M. Watson, Melanie Mitchell 我们重新审视了一种特殊的视觉接地方法,使用Johnson等人的场景图IRSG系统进行图像检索。 2015年。我们的实验表明系统没有有效地使用其学习对象关系模型。我们还仔细研究了IRSG数据集,以及广泛使用的视觉关系数据集VRD。我们发现这些数据集表现出偏差,允许忽略关系的方法相对较好地执行。我们还描述了IRSG数据集的其他几个问题,并使用数据集的子集报告实验,其中消除了偏差和其他问题。我们的研究有助于更好地理解将语言和视觉实际结合起来的机器学习方法以及流行数据集实际测试的内容。 |
| DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation Authors Hanchao Li, Pengfei Xiong, Haoqiang Fan, Jian Sun 本文介绍了一种非常有效的CNN架构,名为DFANet,用于资源约束下的语义分割。我们提出的网络从单个轻量级骨干网开始,分别通过子网和子级级联聚合判别特征。基于多尺度特征传播,DFANet大大减少了参数的数量,但仍然获得了足够的感受野,提高了模型学习能力,在速度和分割性能之间取得了平衡。 Cityscapes和CamVid数据集上的实验证明了DFANet的优越性能,其FLOP的8倍,比现有的实时语义分割方法快2倍,同时提供相当的精度。具体来说,它在Cityscapes测试数据集上实现了70.3平均IOU,在一张NVIDIA Titan X卡上只有1.7 GFLOP和160 FPS的速度,而在更高分辨率的图像上推断时具有3.4 GFLOP的71.3平均IOU。 |
| Semantics-Aware Image to Image Translation and Domain Transfer Authors Pravakar Roy, Nicolai H ni, Volkan Isler 图像到图像的转换是将图像从源域转移到目标域的问题。我们提出了一种新的方法来转移图像的底层语义,即使这两个域中存在几何变化。具体来说,我们提出了一种生成性对抗网络GAN,它可以传输作为分割掩码呈现的语义信息。我们的主要技术贡献是基于编码器解码器的生成器架构,它共同编码图像及其底层语义,并同时转换到目标域。此外,我们提出了保留底层语义标签映射的对象变换和跨域语义一致性损失。我们通过定性和定量实验证明了我们的方法在多目标变形和域转移任务中的有效性。结果表明,我们的方法在传递图像语义方面优于现有技术图像到图像翻译方法。 |
| PaintBot: A Reinforcement Learning Approach for Natural Media Painting Authors Biao Jia, Chen Fang, Jonathan Brandt, Byungmoon Kim, Dinesh Manocha 我们提出了一种新的自动数字绘画框架,基于通过强化学习训练的绘画代理。为了合成图像,代理选择表示原始绘画笔划的连续值动作序列,其累积在数字画布上。动作选择由给定的参考图像引导,代理尝试根据动作空间和代理的学习策略的限制进行复制。使用近端策略优化强化学习的变体来确定绘画代理策略。在训练期间,我们的代理人会看到从一组参考图像中采集的补丁。为了加速培训融合,我们采用课程学习策略,根据使用当前政策的挑战程度对参考补丁进行抽样。我们尝试了不同的损失函数,包括像素和感知损失,这对学习策略产生不同的影响。我们证明了我们的绘画代理可以学习一种有效的策略,其具有高维连续动作空间,包括笔压力,宽度,倾斜度和颜色,适用于各种绘画风格。通过粗略到精细的细化过程,我们的代理可以按照所需的样式绘制任意复杂的图像。 |
| 3D-BEVIS: Birds-Eye-View Instance Segmentation Authors Cathrin Elich, Francis Engelmann, Jonas Schult, Theodora Kontogianni, Bastian Leibe 最近的深度学习模型通过直接在非结构化点云上运行,在3D场景分析任务上取得了令人瞩目的成果在对象分类和语义分割领域取得了很多进展。但是,实例分割的任务较少探索。在这项工作中,我们提出了3D BEVIS,一种用于点云上的3D语义实例分割的深度学习框架。遵循先前提议的自由实例分割方法的思想,我们的模型学习特征嵌入并将获得的特征空间分组为语义实例。通过单独处理场景的局部子部分,基于当前点的方法与点的数量线性地缩放。但是,要通过群集执行实例分段,需要全局一致的功能。因此,我们建议将局部点几何与来自中间鸟瞰图表示的全局上下文信息组合。 |
| Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning Authors Chaohui Yu, Jindong Wang, Yiqiang Chen, Zijing Wu 深度无监督域适应UDA最近受到研究人员越来越多的关注。然而,由于大多数工作采用的卷积神经网络CNN的计算成本,现有方法是计算密集的。到目前为止,还没有有效的网络压缩方法来加速这些模型。在本文中,我们提出了一种统一的传输通道修剪TCP方法来加速UDA模型。 TCP能够通过修剪不太重要的通道来压缩深度UDA模型,同时通过减少跨域分布差异来学习可转移特征。因此,它减少了负转移的影响,并保持了对目标任务的竞争性能。据我们所知,TCP是第一种旨在加速深度UDA模型的方法。 TCP在具有两个公共骨干网VGG16和ResNet50的两个基准数据集Office 31和ImageCLEF DA上得到验证。实验结果表明,TCP实现了与其他比较方法相当或更好的分类精度,同时显着降低了计算成本。更具体地说,在VGG16中,我们在修复ResNet50中的26个浮点运算FLOP后获得更高的精度,在修剪12个FLOP后,我们也可以在一半任务上获得更高的精度。我们希望TCP为未来加速转移学习模型的研究打开一扇新的大门。 |
| Constrained Generative Adversarial Networks for Interactive Image Generation Authors Eric Heim 生成性对抗网络GAN受到了极大的关注,部分原因是最近成功地从视觉域生成原始的高质量样本。然而,大多数当前方法仅允许用户通过有限的交互来指导该图像生成过程。在这项工作中,我们开发了一种新颖的GAN框架,允许人类处于图像生成过程的循环中。我们的技术迭代地接受形式的相对约束生成图像更像图像A而不是图像B.在给出每个约束之后,向用户呈现来自GAN的新输出,通知下一轮反馈。该反馈用于约束GAN的输出相对于潜在的语义空间,该语义空间可以被设计为模拟各种不同的相似性概念,例如,类,属性,对象关系,颜色等。在我们的实验中,我们展示了我们的GAN框架能够生成与等效无监督GAN具有可比质量的图像,同时满足用户提供的大量约束,有效地将GAN转换为允许用户交互控制图像生成的GAN不牺牲图像质量。 |
| A Robust Learning Approach to Domain Adaptive Object Detection Authors Mehran Khodabandeh, Arash Vahdat, Mani Ranjbar, William G. Macready 在现实世界的对象检测应用中,域移位是不可避免的。例如,在自动驾驶汽车中,目标域由无约束的道路环境组成,其不可能在训练数据中都被观察到。同样,在监控应用中,由于隐私法规,可能缺乏足够代表性的培训数据。在本文中,我们从强健学习的角度解决了领域适应问题,并表明该问题可能被制定为具有噪声标签的训练。我们提出了一种强大的对象检测框架,该框架可以抵抗边界框类标签,位置和大小注释中的噪声。为了适应域移位,使用由仅在源域中训练的检测模型获得的一组噪声对象边界框在目标域上训练模型。我们评估了我们在各种源目标域对中的方法的准确性,并证明该模型显着改善了SIM10K,Cityscapes和KITTI数据集上多域适应方案的现有技术水平。 |
| MMED: A Multi-domain and Multi-modality Event Dataset Authors Zhenguo Yan, Zehang Lin, Min Cheng, Qing Li, Wenyin Liu 在这项工作中,我们构建并发布了一个多域和多模态事件数据集MMED,其中包含从数百个新闻媒体网站收集的25,165篇文本新闻文章,例如Yahoo News,Google News,CNN News。和Flickr社交媒体上共享的76,516个图片帖子,根据412个真实世界事件进行注释。收集数据集以探索组织由不同数据域中的专业人员和业余爱好者贡献的异构数据的问题,以及将从一个数据域获得的事件知识传递到异构数据域的问题,从而总结具有不同贡献者的数据。我们希望MMED数据集的发布可以激发对相关挑战性问题的创新研究,例如事件发现,交叉模态事件检索和视觉问答等。 |
| Summit: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations Authors Fred Hohman, Haekyu Park, Caleb Robinson, Duen Horng Polo Chau 深度学习越来越多地用于决策任务。然而,了解神经网络如何产生最终预测仍然是一项基本挑战。解释图像的神经网络预测的现有工作通常集中于解释单个图像或神经元的预测。由于预测通常基于数百万个权重来计算,这些权重是针对数百万个图像进行优化的,因此这种解释很容易错过更大的图像。我们提出了Summit,这是第一个可扩展和系统地总结和可视化深度学习模型已经学习的特征以及这些特征如何相互作用以进行预测的交互式系统。 Summit介绍了两种新的可扩展摘要技术1激活聚合发现重要神经元,2神经元影响聚合识别这些神经元之间的关系。 Summit结合这些技术创建了新的归因图,揭示并总结了有助于模型结果的关键神经元关联和子结构。 Summit可扩展到大数据,例如具有1.2M图像的ImageNet数据集,并利用神经网络特征可视化和数据集示例来帮助用户将大型复杂的神经网络模型提炼为紧凑的交互式可视化。我们提出了神经网络探索场景,其中Summit帮助我们发现了对最先进的图像分类器的学习表示的多个令人惊讶的见解,并通知未来的神经网络架构设计。 Summit可视化在现代Web浏览器中运行,并且是开源的。 |
| Towards a Robust Aerial Cinematography Platform: Localizing and Tracking Moving Targets in Unstructured Environments Authors Rogerio Bonatti, Cherie Ho, Wenshan Wang, Sanjiban Choudhury, Sebastian Scherer 无人机在空中电影摄影中的应用彻底改变了几个需要实时和动态摄像机视点的应用和行业,如娱乐,体育和安全。然而,在拍摄移动目标时安全地控制无人机通常需要多个专业的操作人员因此需要自主摄影师。当前的方法具有严重的现实生活限制,例如需要可以离线解决的脚本场景,高精度运动捕捉系统或用于定位目标的GPS标签,以及环境的先前地图以避开障碍物并计划遮挡。 |
| Continuous Direct Sparse Visual Odometry from RGB-D Images Authors Maani Ghaffari, William Clark, Anthony Bloch, Ryan M. Eustice, Jessy W. Grizzle 本文报道了RGB D图像的视觉测距的新颖配方和评价。假设静态场景,所开发的理论框架概括了广泛使用的直接能量公式光度误差最小化技术,以获得将两个重叠RGB D图像对准连续公式的刚体变换。通过功能性处理问题并在再现内核Hilbert空间中表示RGB D图像上的过程模型来实现连续性,因此,配准不限于特定的图像分辨率,并且框架是完全分析的,具有闭合形式的推导。梯度。我们通过最大化RGB D图像上定义的两个函数之间的内积来解决问题,而刚体运动李群的连续动作通过相应李代数中的流的积分来捕获。基于能量的方法非常成功,本文中开发的框架共享许多所需的属性,例如CPU和GPU上的并行结构,稀疏性,半密集跟踪,避免计算上昂贵的显式数据关联,以及可能的扩展同步本地化和映射框架。对实验数据的评估以及与基于能量的问题的公式的比较证实了所提出的技术的有效性,尤其是当环境中缺乏结构和纹理时。 |
| Decomposing Temperature Time Series with Non-Negative Matrix Factorization Authors Peter Weiderer, Ana Maria Tom , Elmar Wolfgang Lang 在铸造部件的制造期间,通常自动记录和累积传感器数据以用于过程监控和缺陷诊断。由于铸造是一个具有许多相互作用过程参数的热过程,因此根本原因分析往往是单调乏味且无效的。我们展示了基于知识的初始化策略引导的基于非负矩阵分解NMF的分解如何能够从热制造过程中收集的温度时间序列中提取物理有意义的源。该方法假设时间序列由几个同时作用的组件过程的叠加产生。 NMF能够反转叠加并识别隐藏的组件过程。后者可以与持续的物理现象和过程变量相关联,这些变量无法直接监控。我们的方法提供了对基础物理学的新见解,并提供了一种工具,可以帮助诊断缺陷原因。我们通过将其应用于现实世界数据来展示我们的方法,这些数据是在汽车工业的铸件的批量生产过程中在铸造厂中收集的。 |
| Linearly Converging Quasi Branch and Bound Algorithms for Global Rigid Registration Authors Nadav Dym, Shahar Ziv Kovalsky 近年来,已经提出了几种分支定界BnB算法来全局优化刚性配准问题。在本文中,我们提出了一个改进BnB方法的通用框架,我们将其命名为Quasi BnB。准BnB用二次拟下界代替BnB算法中使用的线性下界,二次拟下界基于全局最小值附近的能量的二次行为。虽然准下界不是真正的下界,但是准BnB算法是全局最优的。实际上,我们证明它表现出线性收敛,它在O log 1 epsilon时间内实现了epsilon精度,而其他刚性配准BnB算法的时间复杂度在1 epsilon中是多项式的。我们的实验证实,准BnB比现有技术的BnB算法明显更有效,特别是对于需要高精度的问题。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pixels.com

如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 面试问题
1.事件冒泡,阻止冒泡(事件轮询) 何为事件冒泡: HTML DOM模型是个树形结构,元素之间有相互嵌套的关系,比如<div><a href"new_url">Click Me</a> </div>中div是父元素而…...
2024/4/20 20:45:28 - C# - 缓存OutputCache(二)缓存详细介绍
C# - 缓存OutputCache(二)缓存详细介绍本文是通过网上&个人总结的 1.缓存介绍 缓存是为了提高访问速度,而做的技术。 缓存主要有以下几类:1)客户端缓存Client Caching 2)代理缓存Proxy Caching 3)方向代理缓存Reverse Proxy Caching 4)服务器缓存Web Server Cach…...
2024/4/20 20:45:26 - [论文笔记] 人脸关键点检测方向系列论文
Face Alignment 被翻译为面部对齐,即对所检测的人脸图像进行旋正使其符合标准要求,但是往往也包含 Facial Landmark Detection,这两者往往容易混为一谈。以下为两者的定义: Face Alignment : Face alignment is the task of ident…...
2024/4/20 20:45:25 - 【01背包求方案数】HDU4815-Little Tiger vs. Deep Monkey
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid4815 Problem DescriptionA crowd of little animals is visiting a mysterious laboratory – The Deep Lab of SYSU.“Are you surprised by the STS (speech to speech) technology of Microsoft Rese…...
2024/4/20 16:34:19 - Thiago2(TPO AI.ROSTO):集成式AI换脸软件(Autodesk Flame)
如标题一样,Thiago2 是一款集成式AI换脸软件(TPO AI.ROSTO),需要与Autodesk Flame结合使用,从demo来看完成度还是很高的,算是一种完全GUI版的DeepFaceLab AI换脸工具,但不知道具体实际使用起来会怎样。 视频链接&#…...
2024/5/3 20:50:15 - 视线估计(Gaze Estimation)简介概述
©PaperWeekly 原创 作者|俞雨单位|瑞士洛桑联邦理工学院博士研究方向|视线估计、头部姿态估计本文七个篇章总计涵盖 29 篇论文,总结了自深度学习以来,视线估计领域近五年的发展。概述1.1 问题定义广义的 Gaze Es…...
2024/4/29 11:36:37 - 人脸识别(7)---国内人脸识别技术 十大算法公司排名
国内人脸识别技术 十大算法公司排名 科技特讯11月18日讯:1、云从科技 背靠“计算机视觉之父”,中科院实验室创业团队创立云从科技 云从科技团队成员除了来自中科大的校友外,还来自中国科学院各大研究所、UIUC、IBM、NEC、MicroSoft等全球顶…...
2024/4/21 1:20:59 - [机器学习] 实验笔记 - 表情识别(emotion recognition)
前言 [机器学习] 实验笔记系列是以我在算法研究中的实验笔记资料为基础加以整理推出的。该系列内容涉及常见的机器学习算法理论以及常见的算法应用,每篇博客都会介绍实验相关的数据库,实验方法,实验结果,评价指标和相关技术目前的…...
2024/4/21 1:20:59 - 人脸美颜技术
人脸美颜技术(2019.10.8) 一、美颜技术发展现状和应用场景 美颜美颜”,顾名思义,对图片里的人脸进行美化。在图片类、短视频类和直播类的APP中,都存在“美颜”的影子:图片类的APP中,最具代表性…...
2024/5/3 18:54:00 - 活体检测笔记总结
活体检测 PAD(presentation attack detection) 动作配合式活体检测:给出指定动作要求,用户需配合完成,通过实时检测用户眼睛,嘴巴,头部姿态的状态,来判断是否是活体。H5视频活体检…...
2024/4/21 1:20:56 - 图像处理(九)人物肖像风格转换-Siggraph 2014
人物肖像风格转换 原文地址:http://blog.csdn.net/hjimce/article/details/45534333 作者:hjimce 一、前言 对于风格转换,2014年siggraph上面出了一篇比较不错的paper:《Style Transfer for Headshot Portraits》 ࿰…...
2024/4/21 1:20:56 - 图像处理与机器视觉行业分析
一 行业分析 数字图像处理是对图像进行分析、加工、和处理,使其满足视觉、心理以及其他要求的技术。图像处理是信号处理在图像域上的一个应用。目前大多数的图像是以数字形式 存储,因而图像处理很多情况下指数字图像处理。此外,基于光学理论的…...
2024/5/3 18:55:20 - 研究8
701CCAI | 香港中文大学张胜誉:个性化推荐和资源分配在金融和经济中的应用 https://mp.weixin.qq.com/s?__bizMzI0ODcxODk5OA&mid2247487605&idx4&sna71f903b7b8295a95eba1afe23221d4f&chksme99d238cdeeaaa9a335a7f2461288298f70d48d2d027793a5ad…...
2024/4/25 19:18:26 - Generative Adversarial Nets[pix2pix]
本文来自《Image-to-Image Translation with Conditional Adversarial Networks》,是Phillip Isola与朱俊彦等人的作品,时间线为2016年11月。 作者调研了条件对抗网络,将其作为一种通用的解决image-to-image变换方法。这些网络不止用来学习从…...
2024/4/21 1:20:53 - 神码ai人工智能写作机器人_AI启动协变量AI为机器人构建通用AI
神码ai人工智能写作机器人One could be excused for confusing the Investor’s list on the Covariant.ai website with the all-star lineup for a top AI conference. The names include 2018 Turing Award winners Geoffrey Hinton and Yann LeCun, Google AI lead Jeff De…...
2024/4/21 1:20:51 - DeepFaceLab使用教程(1)
鸽了好久,打算简单写两篇关于DeepFaceLab的文章,尽可能帮助新手小白容易上手。 DeepFaceLab使用教程(1)(本文)和 DeepFaceLab使用教程(2) 首先说明一下,本文是针对Githu…...
2024/4/28 20:45:07 - 换脸算法之DeepFaceLab
论文:DeepFaceLab: A simple, flexible and extensible face swapping framework Github:https://github.com/iperov/DeepFaceLab 论文提出了一个简单,灵活,可扩展的换脸框架DeepFaceLab。 使用DeepFaceLab进行换脸的,…...
2024/4/28 13:21:17 - DeepFaceLab中英双语版,熟肉来了!
我一向都很喜欢看好莱坞大片,但是由于听力水平有限,所以必须等“熟肉”,最喜欢的字幕当然是中英双语版咯。同理,不少人想要使用换脸软件,但是苦于英语不好,迟迟没有上手。好吧,那我就出个双语版…...
2024/4/28 3:40:08 - DeepFaceLab坑之ffmpeg
DeepFaceLab DeepFaceLab是一款支持视频或图片的换脸开源软件,其使用非常简单,有官方的juptyer notebook案例,这里不做过多的教程介绍。 在使用过程中遇到的一点问题,在这里记录一下。DeepFaceLab的详细步骤分为五步:…...
2024/4/28 0:17:02 - ASPX页面的缓存OutputCache
使用@ OutputCache 指令,能够实现对页面输出缓存。 使用OutputCache 指令两个必要属性 1.Duration 表示缓存的时间,单位为秒。 2.VaryByParam 不使用缓存的参数,其值为用分号分隔的字符串列表。 <%@ OutputCache Duration="60" VaryByParam="none" %…...
2024/4/28 19:55:04
最新文章
- 关于链表带环问题为什么要用快慢指针
判断链表是否带环 题目描述 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连…...
2024/5/4 14:05:02 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 54.螺旋矩阵
题目描述 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。示例 1:输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5] 示例 2:输入:matrix …...
2024/5/1 21:57:57 - 黑客(网络安全)技术自学——高效学习
01 什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...
2024/5/3 11:12:59 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/1 17:30:59 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/2 16:16:39 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/29 2:29:43 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/3 23:10:03 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/27 17:58:04 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/27 14:22:49 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/28 1:28:33 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/30 9:43:09 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/27 17:59:30 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/2 15:04:34 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/28 1:34:08 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/29 20:46:55 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/30 22:21:04 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/1 4:32:01 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/4 2:59:34 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/28 5:48:52 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/30 9:42:22 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/2 9:07:46 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/30 9:42:49 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57