加州房价预测项目精细解释
文章目录
- 一、项目概览
- 二、划定问题
- 1、应该认识到,该问题的商业目标是什么?
- 2、第二个问题是现在的解决方案效果如何?
- 开始设计系统
- 三、选择性能指标
- 四、核实假设
- 五、获取数据
- 六、创建测试集
- 七、数据探索和可视化、发现规律
- 1、地理数据可视化
- 2、房价可视化
- 八、查找关联
- 九、属性组合实验
- 十、为机器学习算法准备数据
- (一)数据清洗
- (二)处理文本和类别属性
- (三)特征缩放
- (四)转换流水线
- 十一、选择并训练模型
- (一)在训练集上训练和评估
- (二)使用交叉验证做更好的评估
- (三)模型微调
- 1、网格搜索
- 2、随机搜索
- 3、集成方法
- 4、分析最佳模型和它们的误差
- (四)用测试集评估系统
- (五)启动、监控、维护系统
- 1、启动
- 2、监控
- 3、维护
此处选择StatLib的加州房产价格数据集,该数据集是基于1990年加州普查的数据
一、项目概览
利用加州普查数据,建立一个加州房价模型,这个数据包含每个街区组的人口、收入的中位数、房价中位数等指标。街区组是美国调查局发布样本数据的最小地理单位(600到3000人),简称“街区”。
目标:模型利用该数据进行学习,然后根据其他指标,预测任何街区的房价中位数
二、划定问题
1、应该认识到,该问题的商业目标是什么?
建立模型不可能是最终目标,而是公司的受益情况,这决定了如何划分问题,选择什么算法,评估模型的指标和微调等等
你建立的模型的输出(一个区的房价中位数)会传递给另一个机器学习系统,也有其他信号传入该系统,从而确定该地区是否值得投资。
2、第二个问题是现在的解决方案效果如何?
比如现在截取的房价是靠专家手工估计的,专家队伍收集最新的关于一个区的信息(不包括房价的中位数),他们使用复杂的规则进行估计,这种方法浪费资源和时间,而且效果不理想,误差率大概有15%。
开始设计系统
1、划定问题:监督与否、强化学习与否、分类与否、批量学习或线上学习
2、确定问题:
-
该问题是一个典型的监督学习任务,我们使用的是有标签的训练样本,每个实例都有预定的产出,即街区的房价中位数
-
并且是一个典型的回归任务,因为我们要预测的是一个值。
更细致一些:该问题是一个多变量的回归问题,因为系统要使用多个变量来预测结果
- 最后,没有连续的数据流进入系统,没有特别需求需要对数据变动来做出快速适应,数据量不大可以放到内存中,因此批量学习就够了
提示:如果数据量很大,你可以要么在多个服务器上对批量学习做拆分(使用Mapreduce技术),或是使用线上学习
三、选择性能指标
回归问题的典型指标是均方根误差(RMSE),均方根误差测量的是系统预测误差的标准差,例如RMSE=50000,意味着68%的系统预测值位于实际值的50000美元误差
以内,95%的预测值位于实际值的100000美元以内,一个特征通常都符合高斯分布,即满足68-95-99.7规则,大约68%的值位于1内,95%的值位于内,99.7%的值位于内,此处的,RMSE计算如下:
虽然大多数时候的RMSE是回归任务可靠的性能指标,在有些情况下,你可能需要另外的函数,例如,假设存在许多异常的街区,此时可能需要使用平均绝对误差(MAE),也称为曼哈顿范数,因为其测量了城市中的两点,沿着矩形的边行走的距离:
范数的指数越高,就越关注大的值而忽略小的值,这就是为什么RMSE比MAE对异常值更敏感的原因,但是当异常值是指数分布的时候(类似正态曲线),RMSE就会表现的很好
四、核实假设
最好列出并核对迄今做出的假设,这样可以尽早发现严重的问题,例如,系统输出的街区房价会传入到下游的机器学习系统,我们假设这些价格确实会被当做街区房价使用,但是如果下游系统将价格转化为分类(便宜、昂贵、中等等),然后使用这些分类来进行判定的话,就将回归问题变为分类问题,能否获得准确的价格已经不是很重要了。
此时将回归问题变成了分类问题
五、获取数据
下面是获取数据的函数:
import os
import tarfile
from six.moves import urllibDOWNLOAD_ROOT="https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH="datasets/housing"
HOUSING_URL=DOWNLOAD_ROOT+HOUSING_PATH+"housing.tgz"def fetch_housing_data(housing_url=HOUSING_URL,housing_path=HOUSING_PATH):# os.path.isdir():判断某一路径是否为目录# os.makedirs(): 递归创建目录if not os.path.isdir(housing_path):os.makedirs(housing_path)# 获取当前目录,并组合成新目录tgz_path=os.path.join(housing_path,"housing.tgz") # 将url表示的对象复制到本地文件,urllib.request.urlretrieve(housing_url,tgz_path)housing_tgz=trafile.open(tgz_path)housing_tgz.extractall(path=housing_path)housing_tgz.close()调用fetch_housing_data()的时候,就会在工作空间创建一个datasets/housing目录,下载housing.tgz文件,并解压出housing.csv
然后使用pandas加载数据:
import pandas as pddef load_housing_data(housing_path=HOUSING_PATH):csv_path=os.path.join(housing_path,"housing.csv")return pd.read_csv(csv_path)# csv文件是用逗号分开的一列列数据文件
该函数会返回一个包含所有数据的pandas的DataFrame对象,DataFrame对象是表格型的数据结构,提供有序的列和不同类型的列值
查看数据结构
1、使用head()方法查看前五行
housing=load_housing_data()
housing.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
每一行表示一个街区,共有10个属性,经度、纬度、房屋年龄中位数、总房间数、总卧室数、人口数、家庭数、收入中位数、房屋价值中位数、离大海的距离
2、使用info()方法可以快速查看数据的描述,特别是总行数、每个属性的类型和非空值的数量
housing.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
数据集中有20640个实例,按机器学习的标准来说,该数据量很小,但是非常适合入门,我们注意到总房间数只有20433个非空值,也就是有207个街区缺少该值。
3、使用housing[“ocean_proximity”].value_counts()查看非数值的项,也就是距离大海距离的项包含哪些属性,每个属性包含多少个街区
housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
4、使用housing.describe()方法查看数值属性的概括
housing.describe()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
卧室总数total_bedrooms为20433,所以空值被忽略了,std是标准差,揭示数值的分散度,25%的街区房屋年龄中位数小于18,50%的小于19,75%的小于37,这些值通常称为第25个百分位数(第一个四分位数)、中位数、第75个百分位数(第三个四分位数),不同大小的分位数如果很接近,说明数据很集中,集中在某个段里。
5、另外一种快速了解数据类型的方法是画出每个数值属性的柱状图housing.hist()
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(20,15))
plt.show()
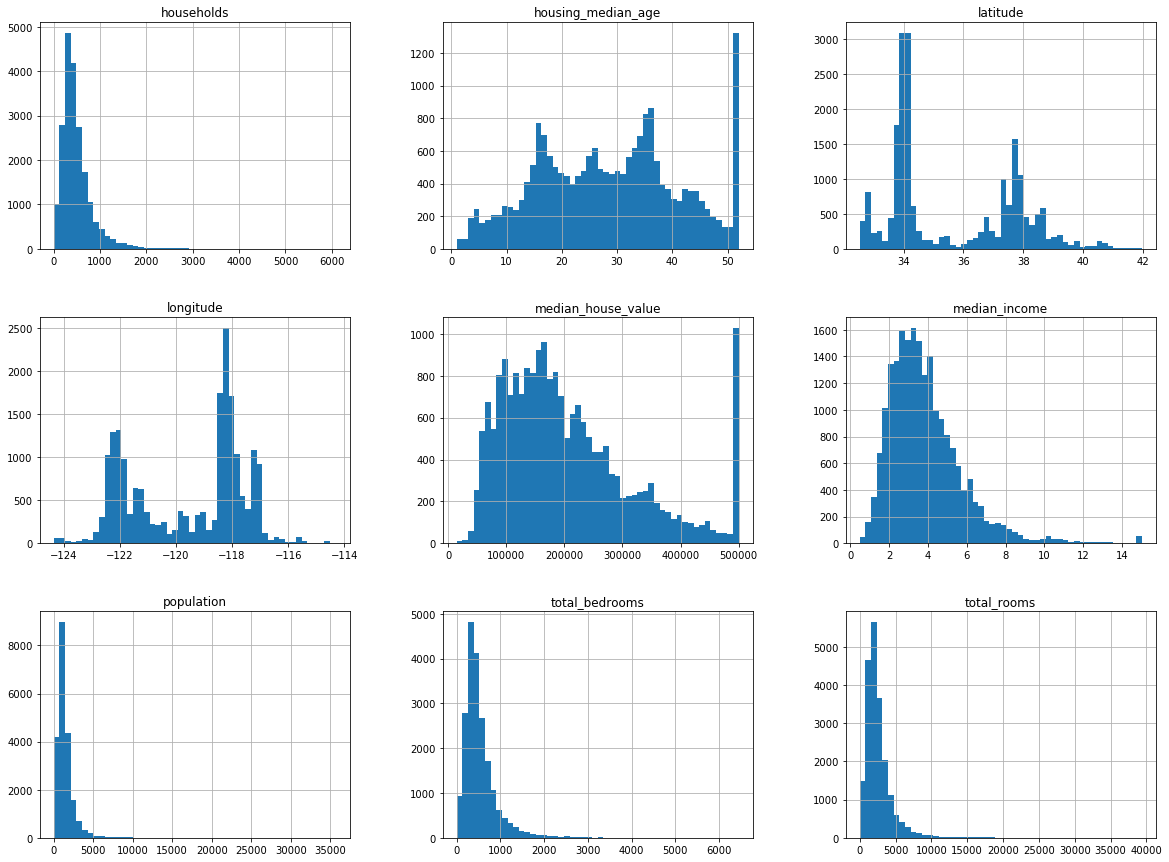
① 收入中位不是美元,而是经过缩放调整的,过高收入的中位数会变为15,过低会变成0.5,也就是设置了阈值。
② 房屋年龄中位数housing_median_age和房屋价值中位数median_house_value也被设了上限,房屋价值中位数是目标属性,我们的机器学习算法学习到的价格不会超过该界限。有两种处理方法:
- 对于设了上限的标签,重新收集合适的标签
- 将这些街区从训练集中移除,也从测试集中移除,因为这会导致不准确
③ 这些属性有不同的量度,会在后续讨论特征缩放
④ 柱状图多为长尾的,是有偏的,对于某些机器学习算法,这会使得检测规律变得困难,后面我们将尝试变换处理这些属性,使其成为正态分布,比如log变换。
六、创建测试集
测试集在这个阶段就要进行分割,因为如果查看了测试集,就会不经意的按照测试集中的规律来选择某个特定的机器学习模型,当再使用测试集进行误差评估的时候,就会发生过拟合,在实际系统中表现很差。
随机挑选一些实例,一般是数据集的20%
from sklearn.model_selection import train_test_split
train_set,test_set=train_test_split(housing,test_size=0.2,random_state=42)
test_set.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 20046 | -119.01 | 36.06 | 25.0 | 1505.0 | NaN | 1392.0 | 359.0 | 1.6812 | 47700.0 | INLAND |
| 3024 | -119.46 | 35.14 | 30.0 | 2943.0 | NaN | 1565.0 | 584.0 | 2.5313 | 45800.0 | INLAND |
| 15663 | -122.44 | 37.80 | 52.0 | 3830.0 | NaN | 1310.0 | 963.0 | 3.4801 | 500001.0 | NEAR BAY |
| 20484 | -118.72 | 34.28 | 17.0 | 3051.0 | NaN | 1705.0 | 495.0 | 5.7376 | 218600.0 | <1H OCEAN |
| 9814 | -121.93 | 36.62 | 34.0 | 2351.0 | NaN | 1063.0 | 428.0 | 3.7250 | 278000.0 | NEAR OCEAN |
上述为随机的取样方法,当数据集很大的时候,尤其是和属性数量相比很大的时候,通常是可行的,但是如果数据集不大,就会有采样偏差的风险,当一个调查公司想要对1000个人进行调查,不能是随机取1000个人,而是要保证有代表性,美国人口的51.3%是女性,48.7%是男性,所以严谨的调查需要保证样本也是这样的比例:513名女性,487名男性,这称为分层采样。
分层采样:将人群分成均匀的子分组,称为分层,从每个分层去取合适数量的实例,保证测试集对总人数具有代表性
如果随机采样的话,会产生严重的偏差。
若我们已知收入的中位数对最终结果的预测很重要,则我们要保证测试集可以代表整体数据集中的多种收入分类,因为收入中位数是一个连续的数值属性,首先需要创建一个收入类别属性,再仔细看一下收入中位数的柱状图
housing["median_income"].hist()
plt.show()
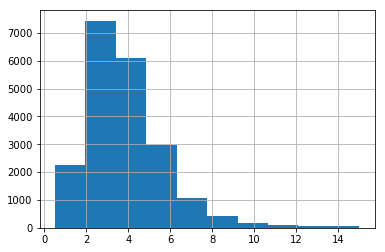
大多数的收入的中位数都在2-5(万美元),但是一些收入中位数会超过6,数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要,否则,对分层重要性的评估就会有偏差,这意味着不能有过多的分层,并且每个分层都要足够大。
随机切分的方式不是很合理,因为随机切分会将原本的数据分布破坏掉,比如收入、性别等,可以采用分桶、等频切分等方式,保证每个桶内的数量和原本的分布接近,来完成切分,保证特性分布是很重要的。
创建收入的类别属性:利用中位数/1.5,ceil()对值进行舍入,以产生离散的分类,然后将所有大于5的分类归类于分类5
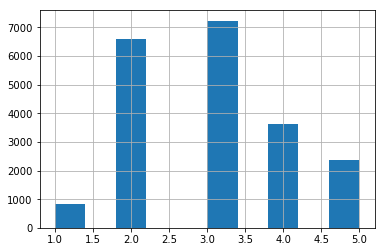
# Divide by 1.5 to limit the number of income categories
import numpy as np
housing["income_cat"]=np.ceil(housing["median_income"]/1.5)
housing["income_cat"].head()0 6.0
1 6.0
2 5.0
3 4.0
4 3.0
Name: income_cat, dtype: float64
# Label those above 5 as 5
housing["income_cat"].where(housing["income_cat"]<5,5.0,inplace=True)
housing["income_cat"].hist()
plt.show()

根据收入分类,进行分层采样,使用sklearn的stratifiedShuffleSplit类
from sklearn.model_selection import StratifiedShuffleSplit
split=StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)for train_index,test_index in split.split(housing,housing["income_cat"]):strat_train_set=housing.loc[train_index]strat_test_set=housing.loc[test_index]
查看分层抽样之后测试集的分布状况
strat_test_set["income_cat"].value_counts()/len(strat_test_set)
3.0 0.350533
2.0 0.318798
4.0 0.176357
5.0 0.114583
1.0 0.039729
Name: income_cat, dtype: float64
len(strat_test_set)
4128
查看原始数据集的分布状况
housing["income_cat"].value_counts()/len(housing)
# .value_counts():确认数据出现的频数
3.0 0.350581
2.0 0.318847
4.0 0.176308
5.0 0.114438
1.0 0.039826
Name: income_cat, dtype: float64
len(housing)
20640
可以看出,测试集和原始数据集的分布状况几乎一致
对分层采样和随机采样的对比:
def income_cat_proportions(data):return data["income_cat"].value_counts()/len(data)train_set,test_set=train_test_split(housing,test_size=0.2,random_state=42)
compare_props=pd.DataFrame({"Overall":income_cat_proportions(housing),"Stratified":income_cat_proportions(strat_test_set),"Random":income_cat_proportions(test_set),}).sort_index()
compare_props["Rand. %error"]=100*compare_props["Random"]/compare_props["Overall"]-100
compare_props["Strat. %error"]=100*compare_props["Random"]/compare_props["Overall"]-100
compare_props
| Overall | Random | Stratified | Rand. %error | Strat. %error | |
|---|---|---|---|---|---|
| 1.0 | 0.039826 | 0.040213 | 0.039729 | 0.973236 | 0.973236 |
| 2.0 | 0.318847 | 0.324370 | 0.318798 | 1.732260 | 1.732260 |
| 3.0 | 0.350581 | 0.358527 | 0.350533 | 2.266446 | 2.266446 |
| 4.0 | 0.176308 | 0.167393 | 0.176357 | -5.056334 | -5.056334 |
| 5.0 | 0.114438 | 0.109496 | 0.114583 | -4.318374 | -4.318374 |
上述表格对比了总数据集、分层采样测试集、纯随机采样测试集的收入分类比例,可以看出分层采样测试集的收入分类比例与总数据集几乎相同,而随机采样数据集偏差严重
housing.head(20)
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | income_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY | 5.0 |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY | 5.0 |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY | 5.0 |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY | 4.0 |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY | 3.0 |
| 5 | -122.25 | 37.85 | 52.0 | 919.0 | 213.0 | 413.0 | 193.0 | 4.0368 | 269700.0 | NEAR BAY | 3.0 |
| 6 | -122.25 | 37.84 | 52.0 | 2535.0 | 489.0 | 1094.0 | 514.0 | 3.6591 | 299200.0 | NEAR BAY | 3.0 |
| 7 | -122.25 | 37.84 | 52.0 | 3104.0 | 687.0 | 1157.0 | 647.0 | 3.1200 | 241400.0 | NEAR BAY | 3.0 |
| 8 | -122.26 | 37.84 | 42.0 | 2555.0 | 665.0 | 1206.0 | 595.0 | 2.0804 | 226700.0 | NEAR BAY | 2.0 |
| 9 | -122.25 | 37.84 | 52.0 | 3549.0 | 707.0 | 1551.0 | 714.0 | 3.6912 | 261100.0 | NEAR BAY | 3.0 |
| 10 | -122.26 | 37.85 | 52.0 | 2202.0 | 434.0 | 910.0 | 402.0 | 3.2031 | 281500.0 | NEAR BAY | 3.0 |
| 11 | -122.26 | 37.85 | 52.0 | 3503.0 | 752.0 | 1504.0 | 734.0 | 3.2705 | 241800.0 | NEAR BAY | 3.0 |
| 12 | -122.26 | 37.85 | 52.0 | 2491.0 | 474.0 | 1098.0 | 468.0 | 3.0750 | 213500.0 | NEAR BAY | 3.0 |
| 13 | -122.26 | 37.84 | 52.0 | 696.0 | 191.0 | 345.0 | 174.0 | 2.6736 | 191300.0 | NEAR BAY | 2.0 |
| 14 | -122.26 | 37.85 | 52.0 | 2643.0 | 626.0 | 1212.0 | 620.0 | 1.9167 | 159200.0 | NEAR BAY | 2.0 |
| 15 | -122.26 | 37.85 | 50.0 | 1120.0 | 283.0 | 697.0 | 264.0 | 2.1250 | 140000.0 | NEAR BAY | 2.0 |
| 16 | -122.27 | 37.85 | 52.0 | 1966.0 | 347.0 | 793.0 | 331.0 | 2.7750 | 152500.0 | NEAR BAY | 2.0 |
| 17 | -122.27 | 37.85 | 52.0 | 1228.0 | 293.0 | 648.0 | 303.0 | 2.1202 | 155500.0 | NEAR BAY | 2.0 |
| 18 | -122.26 | 37.84 | 50.0 | 2239.0 | 455.0 | 990.0 | 419.0 | 1.9911 | 158700.0 | NEAR BAY | 2.0 |
| 19 | -122.27 | 37.84 | 52.0 | 1503.0 | 298.0 | 690.0 | 275.0 | 2.6033 | 162900.0 | NEAR BAY | 2.0 |
现在需要删除income_cat属性,使数据回到最初的状态,利用.drop()来删除某一行/列
for set_ in (strat_train_set,strat_test_set):set_.drop("income_cat",axis=1,inplace=True)
我们通过大量时间来生成测试集的原因是:测试集通常被忽略,但实际上是机器学习非常重要的一部分,还有,生成测试集过程中有很多思路对后面的交叉验证讨论是非常有帮助的。
七、数据探索和可视化、发现规律
目前只是查看了数据,现在需要对数据有整体的了解,更深入的探索数据,现在只研究训练集,可以创建一个副本,以免损伤训练集。
housing=strat_train_set.copy()
1、地理数据可视化
housing.plot(kind="scatter",x="longitude",y="latitude")
plt.show()
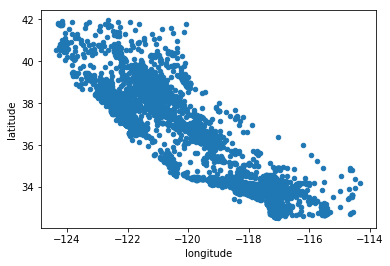
上图看起来很像加州,但是看不出有什么特别地规律,将alpha设为0.1,就可以看出数据点的密度
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)
plt.show()
# 颜色越深,表示叠加越多
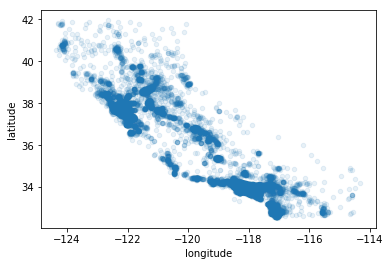
上图可以非常清楚的看到高密度区域,弯区、洛杉矶和圣迭戈,以及中央谷。
2、房价可视化
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing["population"]/100,label="population",c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True,sharex=False)plt.legend()
plt.show()
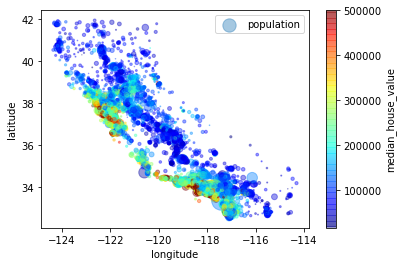
每个圈的半径表示街区的人口(s),颜色代表价格(c),我们用预先定义的名为jet的颜色图(cmap),其范围从蓝色(低价)到红色(高价)
上图说明房价和位置(比如离海的距离)和人口密度联系密切,可以使用聚类的算法来检测主要的聚集,用一个新的特征值测量聚集中心的距离,
八、查找关联
1、person系数:
因为数据集并不是很大,所以可以使用corr()的方法来计算出每对属性间的标准相关系数,也称为person相关系数
corr_matrix=housing.corr()
查看每个属性和房价中位数的关联度
corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64
相关系数的范围是-1~1,接近1的时候强正相关,接近-1的时候,强负相关,接近于0的时候,意味着没有线性相关性。
相关系数只策略线性关系,可能完全忽略非线性关系,下图的最后一行就是非线性关系的例子
from IPython.display import Image
Image(filename='E:/person.png')
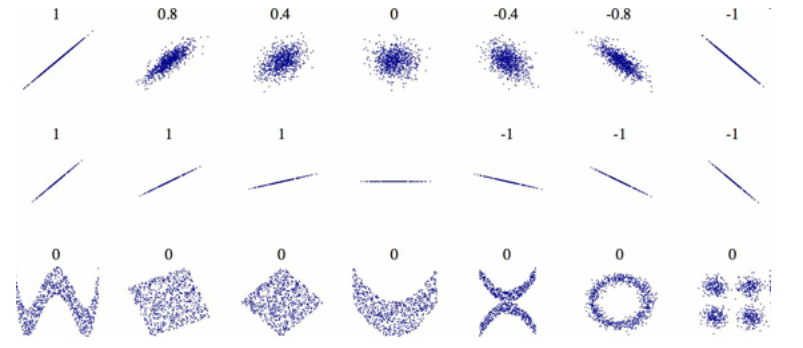
2、scatter_matrix()函数:
可以绘制每个数值属性对每个其他数值属性的图,因为现在有11个数值属性,可以得到张图,所以只关注几个和房价中位数最有可能相关的属性。
from pandas.tools.plotting import scatter_matrixattributes=["median_house_value","median_income","total_rooms","housing_median_age"]
scatter_matrix(housing[attributes],figsize=(12,8))
plt.show()
C:\Anaconda\lib\site-packages\ipykernel\__main__.py:4: FutureWarning: 'pandas.tools.plotting.scatter_matrix' is deprecated, import 'pandas.plotting.scatter_matrix' instead.
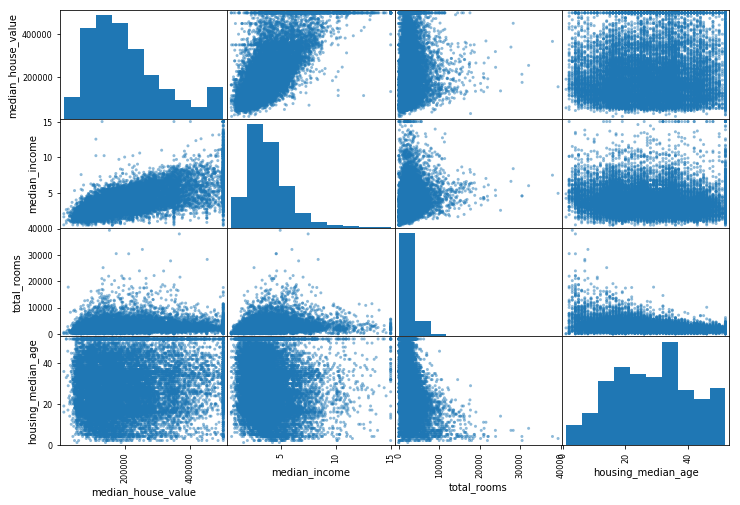
如果pandas将每个变量对自己作图,主对角线(左上到右下)都会是直线,所以pandas展示的是每个属性的柱状图
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大:
housing.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)
plt.show()
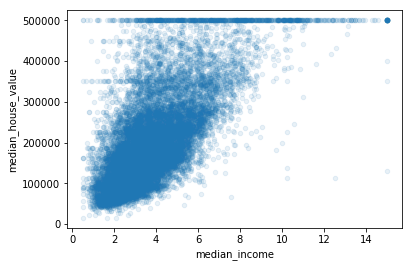
该图说明了几点:
- 首先,相关性非常高,可以清晰的看到向上的趋势,并且数据点不是很分散
- 其次,图中在280000美元、350000美元、450000美元、500000美元都出现了水平线,可以去除对应的街区,防止过拟合
九、属性组合实验
给算法准备数据之前,需要做的最后一件事是尝试多种属性组合,例如,你不知道某个街区有多少户,该街区的总房间数就没有什么用,你真正需要的是每户有几个房间,同样的,总卧室数也不重要,你可能需要将其与房间数进行比较,每户的人口数也是一个有趣的组合,可以创建这些新属性。
housing["roomes_per_household"]=housing["total_rooms"]/housing["households"]
housing["bedrooms_per_rooms"]=housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix=housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)# False:降序
median_house_value 1.000000
median_income 0.687160
roomes_per_household 0.146285
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population_per_household -0.021985
population -0.026920
longitude -0.047432
latitude -0.142724
bedrooms_per_rooms -0.259984
Name: median_house_value, dtype: float64
与总房间数/卧室数相比,新的特征“每个房子中的卧室数 bedrooms_per_room”属性与房价中位数的关联更强,也就是卧室数/总房间数的比例越低,房价就越高,每户的房间数也比街区的总房间数更有信息,也就是房屋越大,房价就越高。
这一步的数据探索不必非常完备,此处的目的是有一个正确的开始,快速发现规律,以得到一个合理的原型。
十、为机器学习算法准备数据
为机器学习算法准备数据,不用手工来做,你需要写一些函数,理由如下:
-
函数可以让你在任何数据集上方便的进行重复数据转换
-
可以慢慢建立一个转换函数库,可以在未来的项目中重复使用
-
在将数据传给算法之前,你可以在实时系统中使用这些函数
-
可以让你方便的尝试多种数据转换,查看哪些转换方法结合起来效果最好
先回到干净的训练集,将预测量和标签分开,因为我们不想对预测量和目标值应用相同的转换(注意drop创建了一份数据的备份,而不影响strat_train_set):
housing=strat_train_set.drop("median_house_value",axis=1)
housing_labels=strat_train_set["median_house_value"].copy()
housing.shape
(16512, 13)
housing_labels
17606 286600.0
18632 340600.0
14650 196900.0
3230 46300.0
3555 254500.0
19480 127900.0
8879 500001.0
13685 140200.0
4937 95000.0
4861 500001.0
16365 92100.0
19684 61500.0
19234 313000.0
13956 89000.0
2390 123900.0
11176 197400.0
15614 500001.0
2953 63300.0
13209 107000.0
6569 184200.0
5825 280900.0
18086 500001.0
16718 171300.0
13600 116600.0
13989 60800.0
15168 121100.0
6747 270700.0
7398 109900.0
5562 159600.0
16121 500001.0...
12380 122500.0
5618 350000.0
10060 172800.0
18067 500001.0
4471 146600.0
19786 81300.0
9969 247600.0
14621 164100.0
579 254900.0
11682 185700.0
245 126800.0
12130 114200.0
16441 101800.0
11016 265600.0
19934 88900.0
1364 225000.0
1236 123500.0
5364 500001.0
11703 321600.0
10356 266000.0
15270 346700.0
3754 190200.0
12166 148800.0
6003 214800.0
7364 174300.0
6563 240200.0
12053 113000.0
13908 97800.0
11159 225900.0
15775 500001.0
Name: median_house_value, Length: 16512, dtype: float64
(一)数据清洗
大多数机器学习算法不能处理缺失的特征,因此创建一些函数来处理特征缺失的问题,前面的total_bedrooms有一些缺失值,有三个解决问题的方法:
- 去掉对应街区,dropna()
- 去掉整个属性,drop()
- 进行赋值(0、平均值、中位数),fillna()
# housing.dropna(subset=["total_bedrooms"]) # 1
# housing.drop("total_bedrooms",axis=1) # 2
# median=housing["total_bedrooms"].median()
# housing["total_bedrooms"].fillna(median) # 3
sample_incomplete_rows=housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | NaN | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | NaN | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | NaN | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | NaN | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | NaN | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
sample_incomplete_rows.dropna(subset=["total_bedrooms"])
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity |
|---|
sample_incomplete_rows.drop("total_bedrooms",axis=1)
| longitude | latitude | housing_median_age | total_rooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True) # option 3
sample_incomplete_rows
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | 433.0 | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | 433.0 | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | 433.0 | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | 433.0 | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | 433.0 | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
sklearn提供了一个方便的类来处理缺失值:Imputer
- 首先,创建一个Imputer示例,指定用某属性的中位数来替换该属性所有的缺失值
from sklearn.preprocessing import Imputer
imputer=Imputer(strategy="median")
- 因为只有数值属性才能算出中位数,需要创建一份不包括文本属性ocean_proximity的数据副本
housing_num=housing.drop("ocean_proximity",axis=1)
- 最后,利用fit()方法将imputer实例拟合到训练数据
imputer.fit(housing_num)
Imputer(axis=0, copy=True, missing_values='NaN', strategy='median', verbose=0)
imputer计算出了每个属性的中位数,并将结果保存在了实例变量statistics_中,虽然此时只有属性total_bedrooms存在缺失值,但我们不能确定在以后的新的数据中会不会有其他属性也存在缺失值,最好的方法是将imputer应用到每个数值:
imputer.statistics_
array([ -118.51 , 34.26 , 29. , 2119.5 , 433. ,1164. , 408. , 3.5409])
housing_num.median().values
array([ -118.51 , 34.26 , 29. , 2119.5 , 433. ,1164. , 408. , 3.5409])
现在就是用该“训练过的”imputer来对训练集进行转换,将缺失值替换为中位数:
X=imputer.transform(housing_num)
结果是一个包含转换后的特征的普通Numpy数组,如果你想将其放回到Pandas的DataFrame中,可以如下操作:
housing_tr=pd.DataFrame(X,columns=housing_num.columns)
housing_tr.loc[sample_incomplete_rows.index.values]
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | |
|---|---|---|---|---|---|---|---|---|
| 4629 | -119.81 | 36.73 | 47.0 | 1314.0 | 416.0 | 1155.0 | 326.0 | 1.3720 |
| 6068 | -121.84 | 37.34 | 33.0 | 1019.0 | 191.0 | 938.0 | 215.0 | 4.0929 |
| 17923 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 13656 | -117.89 | 34.12 | 35.0 | 1470.0 | 241.0 | 885.0 | 246.0 | 4.9239 |
| 19252 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
(二)处理文本和类别属性
前面,我们丢弃了类别属性ocean_proximity,因为它是一个文本属性,不能计算出中位数,大多数机器学习算法喜欢和数字打交道,所以让我们把这些文本标签转化为数字。
sklearn为该任务提供了一个转换器LabelEncoder:
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
housing_cat=housing["ocean_proximity"]
housing_cat.head(10)
17606 <1H OCEAN
18632 <1H OCEAN
14650 NEAR OCEAN
3230 INLAND
3555 <1H OCEAN
19480 INLAND
8879 <1H OCEAN
13685 INLAND
4937 <1H OCEAN
4861 <1H OCEAN
Name: ocean_proximity, dtype: object
housing_cat_encoded=encoder.fit_transform(housing_cat)
housing_cat_encoded
array([0, 0, 4, ..., 1, 0, 3], dtype=int64)
在有多列文本特征的时候要使用factorize()方法来进行操作
housing_cat_encoded,housing_categories=housing_cat.factorize()
housing_cat_encoded[:10]
array([0, 0, 1, 2, 0, 2, 0, 2, 0, 0], dtype=int64)
编码器是通过属性calsses_来学习的(小于1H OCEAN->0,INLAND->1,NEAR BAY->2,NEAR OCEAN->3)
print(encoder.classes_)
['<1H OCEAN' 'INLAND' 'ISLAND' 'NEAR BAY' 'NEAR OCEAN']
这种做法的问题是,ML算法会认为两个临近的值比两个疏远的值更为相似,显然这样不对,因为比如分类0和4比0和1更为相似
要解决该问题,一个常见的方法是给每个分类创建一个二元属性:
当分类为<1H OCEAN,该属性为1(否则为0),当分类为INLAND时,另一个属性为0(否则为1),该方法称为独热编码,因为只有一个属性会等于1,其余都为0.
sklearn提供了一个编码器OneHotEncoder,用于将整数分类值转变为独热向量
fit_transform()用于2维数组,而housing_cat_encoded是一个一维数组,所以要先变形
from sklearn.preprocessing import OneHotEncoder
encoder=OneHotEncoder()
housing_cat_1hot=encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
housing_cat_1hot
<16512x5 sparse matrix of type '<class 'numpy.float64'>'with 16512 stored elements in Compressed Sparse Row format>
这样的输出结果是一个SciPy的稀疏矩阵,而不是numpy数组,当类别属性有数千个分类时,这样非常有用,经过独热编码,我们得到了一个有数千列的矩阵,该矩阵每行只有一个1,其余都是0。使用大量内存来存储这些0非常浪费,所以稀疏矩阵只存非零元素的位置,可以利用toarray(0方法将其变为一个numpy矩阵:
housing_cat_1hot.toarray()
array([[ 1., 0., 0., 0., 0.],[ 1., 0., 0., 0., 0.],[ 0., 1., 0., 0., 0.],..., [ 0., 0., 1., 0., 0.],[ 1., 0., 0., 0., 0.],[ 0., 0., 0., 1., 0.]])
使用类LabelBinarizer,我们可以用一步执行这两个转换(从文本分类到整数分类,再从整数分类的独热向量):
from sklearn.preprocessing import LabelBinarizer
encoder=LabelBinarizer()
housing_cat_1hot=encoder.fit_transform(housing_cat)
housing_cat_1hot
array([[1, 0, 0, 0, 0],[1, 0, 0, 0, 0],[0, 0, 0, 0, 1],..., [0, 1, 0, 0, 0],[1, 0, 0, 0, 0],[0, 0, 0, 1, 0]])
默认返回的结果是一个密集的numpy数组,向构造器 LabelBinarizer传递sparse_output=True,就可以得到一个稀疏矩阵
from sklearn.preprocessing import LabelBinarizer
encoder=LabelBinarizer(sparse_output=True)
housing_cat_1hot=encoder.fit_transform(housing_cat)
housing_cat_1hot
<16512x5 sparse matrix of type '<class 'numpy.int32'>'with 16512 stored elements in Compressed Sparse Row format>
应用sklearn提供的CategoricalEncoder类,用于标签列的转换,添加附加的属性
# cat_encoder=CategoricalEncoder()
# housing_cat_reshaped=housing_cat.values.reshape(-1,1)
# housing_cat_1hot=cat_encoder.fit_transform(housing_cat_reshaped)
# housing_cat_1hot
from sklearn.base import BaseEstimator, TransformerMixin# column index
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6class CombinedAttributesAdder(BaseEstimator, TransformerMixin):def __init__(self, add_bedrooms_per_room = True): # no *args or **kargsself.add_bedrooms_per_room = add_bedrooms_per_roomdef fit(self, X, y=None):return self # nothing else to dodef transform(self, X, y=None):rooms_per_household = X[:, rooms_ix] / X[:, household_ix]population_per_household = X[:, population_ix] / X[:, household_ix]if self.add_bedrooms_per_room:bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]return np.c_[X, rooms_per_household, population_per_household,bedrooms_per_room]else:return np.c_[X, rooms_per_household, population_per_household]attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
housing_extra_attribs = pd.DataFrame(housing_extra_attribs,columns=list(housing.columns)+["rooms_per_household", "population_per_household"])
housing_extra_attribs.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | rooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -121.89 | 37.29 | 38 | 1568 | 351 | 710 | 339 | 2.7042 | <1H OCEAN | 4.62537 | 2.0944 |
| 1 | -121.93 | 37.05 | 14 | 679 | 108 | 306 | 113 | 6.4214 | <1H OCEAN | 6.00885 | 2.70796 |
| 2 | -117.2 | 32.77 | 31 | 1952 | 471 | 936 | 462 | 2.8621 | NEAR OCEAN | 4.22511 | 2.02597 |
| 3 | -119.61 | 36.31 | 25 | 1847 | 371 | 1460 | 353 | 1.8839 | INLAND | 5.23229 | 4.13598 |
| 4 | -118.59 | 34.23 | 17 | 6592 | 1525 | 4459 | 1463 | 3.0347 | <1H OCEAN | 4.50581 | 3.04785 |
(三)特征缩放
数据要做的最重要的转换之一就是特征缩放,除了个别情况,当输入的数值属性量度不同时,机器学习算法的性能都不会好,这个规律也适用于房产数据:
总房间数的分布范围为639320,收入中位数分布在015,注意通常情况下我们不需要对目标值进行缩放。
两种常见的方法让所有的属性具有相同的量度:
-
线性归一化(MinMaxScalar)
-
标准化(StandardScalar)
注意:缩放器之能向训练集拟合,而不是向完整的数据集,只有这样才能转化训练集和测试集
(四)转换流水线
我们已知,数据处理过程中,存在许多数据转换步骤,需要按照一定的顺序进行执行,sklearn提供了类——Pipeline来进行一系列转换
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScalernum_pipeline = Pipeline([('imputer', Imputer(strategy="median")),('attribs_adder', CombinedAttributesAdder()),('std_scaler', StandardScaler()),])
# 'imputer': 数据填充
# 'attribs_adder':变换
# 'std_scaler': 数值型数据的特征缩放
housing_num_tr = num_pipeline.fit_transform(housing_num)pipline构造器需要一个定义步骤顺序的名字/估计器对的列表,除了最后一个估计器,其余都要是转换器,即它们都要有fit_transform()的方法,名字可以随意
当调用流水线fit()方法的时候:会对所有的转换器顺序调用fit_transform()方法,将每次调用的输出作为参数传递给下一个调用,一直到最后的一个估计器,他只执行fit方法。
一个完整的处理数值和类别属性的流水线如下:
from sklearn.pipeline import FeatureUnionnum_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]num_pipeline = Pipeline([('selector', DataFrameSelector(num_attribs)),('imputer', Imputer(strategy="median")),('attribs_adder', CombinedAttributesAdder()),('std_scaler', StandardScaler()),])
# 选择
cat_pipeline = Pipeline([('selector', DataFrameSelector(cat_attribs)),('label_binarizer',LabelBinarizer()),])
# 拼接
full_pipeline = FeatureUnion(transformer_list=[("num_pipeline", num_pipeline),("cat_pipeline", cat_pipeline),])
housing_prepared=full_pipeline.fit_transform(housing)
housing_prepared
array([[-1.15604281, 0.77194962, 0.74333089, ..., 0. ,0. , 0. ],[-1.17602483, 0.6596948 , -1.1653172 , ..., 0. ,0. , 0. ],[ 1.18684903, -1.34218285, 0.18664186, ..., 0. ,0. , 1. ],..., [ 1.58648943, -0.72478134, -1.56295222, ..., 0. ,0. , 0. ],[ 0.78221312, -0.85106801, 0.18664186, ..., 0. ,0. , 0. ],[-1.43579109, 0.99645926, 1.85670895, ..., 0. ,1. , 0. ]])
housing_prepared.shape
(16512, 16)
每个子流水线都以一个选择转换器开始:
通过选择对应的属性、丢弃其他的,来转换数据,并将输出DataFrame转变成一个numpy数组。
sklearn没有工具来处理pd的DataFrame,因此需要一个简单的自定义转换器来做这项工作
from sklearn.base import BaseEstimator,TransformerMixin# creat a class to select numerical or categorical columns
# since sklearn doesn't handle DataFrames yet
class DataFrameSelector(BaseEstimator,TransformerMixin):def __init__(self,attribute_names):self.attribute_names=attribute_namesdef fit(self,X,y=None):return selfdef transform(self,X):return X[self.attribute_names].values
十一、选择并训练模型
前面限定了问题、获得了数据、探索了数据、采样了测试集,写了自动化的转换流水线来清理和为算法准备数据,现在可以选择并训练一个机器学习模型了
(一)在训练集上训练和评估
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(housing_prepared,housing_labels)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
上面是一个线性回归模型,用一些实例来验证:
some_data=housing.iloc[:5]
some_labels=housing_labels.iloc[:5]
some_data_prepared=full_pipeline.transform(some_data)
print("predictions:\t",lin_reg.predict(some_data_prepared))# loc 在index的标签上进行索引,范围包括start和end.
# iloc 在index的位置上进行索引,不包括end.
# ix 先在index的标签上索引,索引不到就在index的位置上索引(如果index非全整数),不包括end.
predictions: [ 210644.60459286 317768.80697211 210956.43331178 59218.98886849189747.55849879]
print("labels:\t\t",list(some_labels))
labels: [286600.0, 340600.0, 196900.0, 46300.0, 254500.0]
可以看出,预测的值和真实的值有较大的偏差,计算一下RMSE:
from sklearn.metrics import mean_squared_error
housing_predictions=lin_reg.predict(housing_prepared)
lin_mse=mean_squared_error(housing_labels,housing_predictions)
lin_rmse=np.sqrt(lin_mse)
lin_rmse
68628.198198489234
结果并不好,大多数街区的房价中位数位于120000-265000美元之间,因此预测误差68628并不能让人满意,这是一个欠拟合的例子,所以我们要选择更好的模型进行预测,也可以添加更多的特征,等等。
尝试更为复杂的模型:
from sklearn.tree import DecisionTreeRegressor
tree_reg=DecisionTreeRegressor()
tree_reg.fit(housing_prepared,housing_labels)
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,max_leaf_nodes=None, min_impurity_split=1e-07,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False, random_state=None,splitter='best')
模型训练好了之后,用训练集来评估:
housing_predictions=tree_reg.predict(housing_prepared)
tree_mse=mean_squared_error(housing_labels,housing_predictions)
tree_rmse=np.sqrt(tree_mse)
tree_mse
0.0
没有误差!
模型不可能完美的,所以该模型可能产生了严重的过拟合,所以要使用训练集的部分数据来做训练,用一部分做验证。
(二)使用交叉验证做更好的评估
评估决策树模型的一种方法是用函数train_test_split来分割训练集,得到一个更小的训练集和一个验证集,然后用更小的训练集来训练模型,用验证集进行评估。
另一种方法是使用交叉验证功能,下面的代码采用了k折交叉验证(k=10),每次用一个折进行评估,用其余九个折进行训练,结果是包含10个评分的数组,
from sklearn.model_selection import cross_val_score
scores=cross_val_score(tree_reg,housing_prepared,housing_labels,scoring="neg_mean_squared_error",cv=10)
scores
array([ -4.69780143e+09, -4.53079547e+09, -5.09684731e+09,-4.76712153e+09, -5.10478677e+09, -5.49833181e+09,-5.11203877e+09, -4.83185329e+09, -5.95294534e+09,-4.98684497e+09])
tree_rmse_scores=np.sqrt(-scores)
注意:sklearn交叉验证功能期望的是效用函数,越大越好,因此得分函数实际上与MSE相反(即为负值),故要在代码计算平方根之前计算-scores
def display_scores(scores):print("Scores:", scores)print("Mean:", scores.mean())print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
Scores: [ 68416.06869621 67700.71364388 70107.46534824 68567.8343617671987.47320813 74458.15245677 70294.48853581 71217.5750103476961.44182696 70069.50630652]
Mean: 70978.0719395
Standard deviation: 2723.10200089
现在决策树看起来就不像前面那样好了,实际上比LR还糟糕
交叉验证不仅可以让你得到模型性能的评估,还能测量评估的准确性,也就是标准差,决策树的评分大约是70978,波动为±2723,如果只有一个验证集就得不到这些信息,但是交叉验证的代价是训练了模型多次,不可能总是这样
我们计算一下线性回归模型的相同分数,来做确保:
lin_scores=cross_val_score(lin_reg,housing_prepared,housing_labels,scoring="neg_mean_squared_error",cv=10)
lin_rmse_scores=np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
Scores: [ 66782.73843989 66960.118071 70347.95244419 74739.5705255268031.13388938 71193.84183426 64969.63056405 68281.6113799771552.91566558 67665.10082067]
Mean: 69052.4613635
Standard deviation: 2731.6740018
pd.Series(lin_rmse_scores).describe()
count 10.000000
mean 69052.461363
std 2879.437224
min 64969.630564
25% 67136.363758
50% 68156.372635
75% 70982.369487
max 74739.570526
dtype: float64
由此可知,决策树模型过拟合很严重,性能比线性回归还差
我们再尝试一个模型:随机森林
from sklearn.ensemble import RandomForestRegressorforest_reg=RandomForestRegressor(random_state=42)
forest_reg.fit(housing_prepared,housing_labels)
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,max_features='auto', max_leaf_nodes=None,min_impurity_split=1e-07, min_samples_leaf=1,min_samples_split=2, min_weight_fraction_leaf=0.0,n_estimators=10, n_jobs=1, oob_score=False, random_state=42,verbose=0, warm_start=False)
housing_predictions=forest_reg.predict(housing_prepared)
forest_mse=mean_squared_error(housing_labels,housing_predictions)
forest_rmse=np.sqrt(forest_mse)
forest_rmse
21941.911027380233
from sklearn.model_selection import cross_val_score
forest_scores=cross_val_score(forest_reg,housing_prepared,housing_labels,scoring="neg_mean_squared_error",cv=10)
forest_rmse_scores=np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
Scores: [ 51650.94405471 48920.80645498 52979.16096752 54412.7404202150861.29381163 56488.55699727 51866.90120786 49752.2459953755399.50713191 53309.74548294]
Mean: 52564.1902524
Standard deviation: 2301.87380392
随机森林看起来不错,但是训练集的评分仍然比验证集评分低很多,解决过拟合可以通过简化模型,给模型加限制,或使用更多的训练数据来实现。
可以尝试机器学习算法的其他类型的模型(SVM、神经网络等)
SVM模型:
from sklearn.svm import SVR
svm_reg=SVR(kernel="linear")
svm_reg.fit(housing_prepared,housing_labels)
housing_predictions=svm_reg.predict(housing_prepared)
svm_mse=mean_squared_error(housing_labels,housing_predictions)
svm_rmse=np.sqrt(svm_mse)
svm_rmse
111094.6308539982
注意:要保存每个实验过的模型,以便后续使用,要确保有超参数和训练参数,以及交叉验证得分,和实际的预测值,可以用python的pickle来方便的保存sklearn模型,或者使用sklearn,.externals.joblib,后者序列化最大numpy数组更有效率。
from sklearn.externals import joblib
joblib.dump(my_model,"my_model.pkl")
my_model_loaded=joblib.load("my_model.pkl")
---------------------------------------------------------------------------NameError Traceback (most recent call last)<ipython-input-96-daecabc707a4> in <module>()1 from sklearn.externals import joblib
----> 2 joblib.dump(my_model,"my_model.pkl")3 my_model_loaded=joblib.load("my_model.pkl")NameError: name 'my_model' is not defined
(三)模型微调
假设现在有了一个列表,列表里有几个希望的模块,你现在需要对它们进行微调,下面有几种微调的方法。
1、网格搜索
微调的一种方法是手工调整参数,直到找到一种好的参数组合,但是这样的话会非常冗长,你也可能没有时间探索多种组合
可以使用sklearn的GridSearchCV来做这项搜索工作:
from sklearn.model_selection import GridSearchCVparam_grid=[{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},]forest_reg=RandomForestRegressor()
grid_search=GridSearchCV(forest_reg,param_grid,cv=5,scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared,housing_labels)
GridSearchCV(cv=5, error_score='raise',estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,max_features='auto', max_leaf_nodes=None,min_impurity_split=1e-07, min_samples_leaf=1,min_samples_split=2, min_weight_fraction_leaf=0.0,n_estimators=10, n_jobs=1, oob_score=False, random_state=None,verbose=0, warm_start=False),fit_params={}, iid=True, n_jobs=1,param_grid=[{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]}, {'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]}],pre_dispatch='2*n_jobs', refit=True, return_train_score=True,scoring='neg_mean_squared_error', verbose=0)
param_grid:
- 首先评估所有的列在第一个dict中的n_estimators和max_features的3x4=12种组合
- 之后尝试第二个dict中超参数的2x3=6种组合,这次会将超参数bootstrap设为False而不是True
总之,网格搜索会探索12+6=18种RandomForestRegressor的超参数组合,会训练每个模型5次,因为是5折交叉验证,也就是总共训练18x5=90轮,最终得到最佳参数组合。
grid_search.best_params_
{'max_features': 8, 'n_estimators': 30}
cvres=grid_search.cv_results_
for mean_score,params in zip(cvres["mean_test_score"],cvres["params"]):print(np.sqrt(-mean_score),params)
64215.557922 {'n_estimators': 3, 'max_features': 2}
55714.8764381 {'n_estimators': 10, 'max_features': 2}
53079.4656786 {'n_estimators': 30, 'max_features': 2}
60922.7203346 {'n_estimators': 3, 'max_features': 4}
52804.3071875 {'n_estimators': 10, 'max_features': 4}
50617.4676308 {'n_estimators': 30, 'max_features': 4}
59157.2838878 {'n_estimators': 3, 'max_features': 6}
52452.1859118 {'n_estimators': 10, 'max_features': 6}
50004.9240828 {'n_estimators': 30, 'max_features': 6}
58781.2418874 {'n_estimators': 3, 'max_features': 8}
51669.9337736 {'n_estimators': 10, 'max_features': 8}
49905.3850728 {'n_estimators': 30, 'max_features': 8}
62068.9023546 {'bootstrap': False, 'n_estimators': 3, 'max_features': 2}
53842.6681258 {'bootstrap': False, 'n_estimators': 10, 'max_features': 2}
59645.8537753 {'bootstrap': False, 'n_estimators': 3, 'max_features': 3}
52778.2491624 {'bootstrap': False, 'n_estimators': 10, 'max_features': 3}
59149.2314414 {'bootstrap': False, 'n_estimators': 3, 'max_features': 4}
51774.2952583 {'bootstrap': False, 'n_estimators': 10, 'max_features': 4}
pd.DataFrame(grid_search.cv_results_)
| mean_fit_time | mean_score_time | mean_test_score | mean_train_score | param_bootstrap | param_max_features | param_n_estimators | params | rank_test_score | split0_test_score | ... | split2_test_score | split2_train_score | split3_test_score | split3_train_score | split4_test_score | split4_train_score | std_fit_time | std_score_time | std_test_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.051744 | 0.002997 | -4.123638e+09 | -1.085049e+09 | NaN | 2 | 3 | {'n_estimators': 3, 'max_features': 2} | 18 | -3.745069e+09 | ... | -4.310195e+09 | -1.033974e+09 | -4.226770e+09 | -1.092966e+09 | -4.107321e+09 | -1.084689e+09 | 0.003708 | 1.784161e-07 | 2.000633e+08 | 2.924609e+07 |
| 1 | 0.158637 | 0.007994 | -3.104147e+09 | -5.766865e+08 | NaN | 2 | 10 | {'n_estimators': 10, 'max_features': 2} | 11 | -2.928102e+09 | ... | -3.164040e+09 | -5.657386e+08 | -2.870879e+09 | -5.780497e+08 | -3.246855e+09 | -5.575573e+08 | 0.002923 | 6.316592e-04 | 1.744069e+08 | 1.341596e+07 |
| 2 | 0.475510 | 0.020981 | -2.817430e+09 | -4.384479e+08 | NaN | 2 | 30 | {'n_estimators': 30, 'max_features': 2} | 9 | -2.660618e+09 | ... | -2.898776e+09 | -4.262299e+08 | -2.680442e+09 | -4.455865e+08 | -2.841348e+09 | -4.247506e+08 | 0.009114 | 6.316710e-04 | 1.312205e+08 | 1.136792e+07 |
| 3 | 0.076122 | 0.002600 | -3.711578e+09 | -9.964530e+08 | NaN | 4 | 3 | {'n_estimators': 3, 'max_features': 4} | 16 | -3.859090e+09 | ... | -3.768976e+09 | -9.693306e+08 | -3.481206e+09 | -9.808291e+08 | -3.687273e+09 | -9.615582e+08 | 0.002916 | 4.913391e-04 | 1.274239e+08 | 3.442731e+07 |
| 4 | 0.264535 | 0.008394 | -2.788295e+09 | -5.126644e+08 | NaN | 4 | 10 | {'n_estimators': 10, 'max_features': 4} | 8 | -2.595457e+09 | ... | -3.006611e+09 | -5.250591e+08 | -2.653757e+09 | -5.306890e+08 | -2.842921e+09 | -5.155992e+08 | 0.010836 | 4.875668e-04 | 1.475803e+08 | 1.558942e+07 |
| 5 | 0.758227 | 0.021578 | -2.562128e+09 | -3.904135e+08 | NaN | 4 | 30 | {'n_estimators': 30, 'max_features': 4} | 3 | -2.461271e+09 | ... | -2.682606e+09 | -3.809276e+08 | -2.406693e+09 | -3.901897e+08 | -2.632748e+09 | -3.904042e+08 | 0.012221 | 1.198738e-03 | 1.077807e+08 | 8.244539e+06 |
| 6 | 0.105495 | 0.002598 | -3.499584e+09 | -9.351743e+08 | NaN | 6 | 3 | {'n_estimators': 3, 'max_features': 6} | 14 | -3.328932e+09 | ... | -3.552107e+09 | -8.665074e+08 | -3.307425e+09 | -8.965413e+08 | -3.742643e+09 | -9.434332e+08 | 0.002332 | 4.902158e-04 | 1.627278e+08 | 5.283697e+07 |
| 7 | 0.360822 | 0.008392 | -2.751232e+09 | -5.049884e+08 | NaN | 6 | 10 | {'n_estimators': 10, 'max_features': 6} | 6 | -2.531694e+09 | ... | -2.870746e+09 | -5.142974e+08 | -2.656673e+09 | -5.181455e+08 | -2.889856e+09 | -4.867869e+08 | 0.021891 | 1.019487e-03 | 1.369522e+08 | 1.149122e+07 |
| 8 | 1.072910 | 0.021977 | -2.500492e+09 | -3.875013e+08 | NaN | 6 | 30 | {'n_estimators': 30, 'max_features': 6} | 2 | -2.392508e+09 | ... | -2.581427e+09 | -3.743052e+08 | -2.319081e+09 | -3.853054e+08 | -2.617236e+09 | -3.857884e+08 | 0.028130 | 6.368153e-04 | 1.209632e+08 | 8.385203e+06 |
| 9 | 0.136064 | 0.002795 | -3.455234e+09 | -9.166040e+08 | NaN | 8 | 3 | {'n_estimators': 3, 'max_features': 8} | 12 | -3.398861e+09 | ... | -3.699172e+09 | -9.026422e+08 | -3.377490e+09 | -9.122286e+08 | -3.322972e+09 | -8.912432e+08 | 0.002989 | 3.984407e-04 | 1.316934e+08 | 2.147608e+07 |
| 10 | 0.445345 | 0.008391 | -2.669782e+09 | -4.952191e+08 | NaN | 8 | 10 | {'n_estimators': 10, 'max_features': 8} | 4 | -2.471795e+09 | ... | -2.820412e+09 | -5.002758e+08 | -2.453341e+09 | -4.994739e+08 | -2.833603e+09 | -5.077587e+08 | 0.005911 | 7.988219e-04 | 1.706287e+08 | 1.055790e+07 |
| 11 | 1.357215 | 0.021979 | -2.490547e+09 | -3.857555e+08 | NaN | 8 | 30 | {'n_estimators': 30, 'max_features': 8} | 1 | -2.302862e+09 | ... | -2.633732e+09 | -3.791579e+08 | -2.319242e+09 | -3.920999e+08 | -2.617032e+09 | -3.848190e+08 | 0.025464 | 6.285092e-04 | 1.476857e+08 | 4.276383e+06 |
| 12 | 0.077519 | 0.003198 | -3.852549e+09 | 0.000000e+00 | False | 2 | 3 | {'bootstrap': False, 'n_estimators': 3, 'max_f... | 17 | -3.777284e+09 | ... | -4.071537e+09 | -0.000000e+00 | -3.962348e+09 | -0.000000e+00 | -3.767083e+09 | -0.000000e+00 | 0.001493 | 3.947991e-04 | 1.422655e+08 | 0.000000e+00 |
| 13 | 0.251147 | 0.009186 | -2.899033e+09 | 0.000000e+00 | False | 2 | 10 | {'bootstrap': False, 'n_estimators': 10, 'max_... | 10 | -2.632424e+09 | ... | -3.030149e+09 | -0.000000e+00 | -2.757032e+09 | -0.000000e+00 | -3.021790e+09 | -0.000000e+00 | 0.005121 | 4.041424e-04 | 1.717383e+08 | 0.000000e+00 |
| 14 | 0.099095 | 0.002999 | -3.557628e+09 | 0.000000e+00 | False | 3 | 3 | {'bootstrap': False, 'n_estimators': 3, 'max_f... | 15 | -3.432197e+09 | ... | -3.772619e+09 | -0.000000e+00 | -3.294494e+09 | -0.000000e+00 | -3.710251e+09 | -0.000000e+00 | 0.001939 | 4.384828e-06 | 1.760192e+08 | 0.000000e+00 |
| 15 | 0.330267 | 0.009987 | -2.785544e+09 | 0.000000e+00 | False | 3 | 10 | {'bootstrap': False, 'n_estimators': 10, 'max_... | 7 | -2.591396e+09 | ... | -2.970489e+09 | -0.000000e+00 | -2.669698e+09 | -0.000000e+00 | -2.952266e+09 | -0.000000e+00 | 0.009467 | 5.289670e-06 | 1.515544e+08 | 0.000000e+00 |
| 16 | 0.120870 | 0.003204 | -3.498632e+09 | 0.000000e+00 | False | 4 | 3 | {'bootstrap': False, 'n_estimators': 3, 'max_f... | 13 | -3.583656e+09 | ... | -3.805470e+09 | -0.000000e+00 | -3.366972e+09 | -0.000000e+00 | -3.362098e+09 | -0.000000e+00 | 0.003027 | 4.020169e-04 | 1.747195e+08 | 0.000000e+00 |
| 17 | 0.408781 | 0.010186 | -2.680578e+09 | 0.000000e+00 | False | 4 | 10 | {'bootstrap': False, 'n_estimators': 10, 'max_... | 5 | -2.459092e+09 | ... | -2.917070e+09 | -0.000000e+00 | -2.614288e+09 | -0.000000e+00 | -2.769720e+09 | -0.000000e+00 | 0.011007 | 4.009604e-04 | 1.541126e+08 | 0.000000e+00 |
18 rows × 23 columns
该例子中,我们通过设定超参数max_features为8,n_estimators为30,得到了最佳方案,RMSE的值为49959,这逼之前使用默认超参数的值52634要好。
2、随机搜索
当探索相对较少的组合时,网格搜索还可以,但是当超参数的搜索空间很大的时候,最好使用RandomizedSearchCV,该类不是尝试所有可能的组合,而是通过选择每个超参数的一个随机值的特定数量的随机组合,该方法有两个优点:
- 如果你让随机搜索运行,比如1000次,它会探索每个超参数的1000个不同的值,而不是像网格搜索那样,只搜索每个超参数的几个值
- 可以方便的通过设定搜索次数,控制超参数搜索的计算量
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randintparam_distribs = {'n_estimators': randint(low=1, high=200),'max_features': randint(low=1, high=8),}forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
RandomizedSearchCV(cv=5, error_score='raise',estimator=RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,max_features='auto', max_leaf_nodes=None,min_impurity_split=1e-07, min_samples_leaf=1,min_samples_split=2, min_weight_fraction_leaf=0.0,n_estimators=10, n_jobs=1, oob_score=False, random_state=42,verbose=0, warm_start=False),fit_params={}, iid=True, n_iter=10, n_jobs=1,param_distributions={'n_estimators': <scipy.stats._distn_infrastructure.rv_frozen object at 0x0000016B8BAD5400>, 'max_features': <scipy.stats._distn_infrastructure.rv_frozen object at 0x0000016B8BAD56A0>},pre_dispatch='2*n_jobs', random_state=42, refit=True,return_train_score=True, scoring='neg_mean_squared_error',verbose=0)
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):print(np.sqrt(-mean_score), params)
49147.1524172 {'n_estimators': 180, 'max_features': 7}
51396.8768969 {'n_estimators': 15, 'max_features': 5}
50798.3025423 {'n_estimators': 72, 'max_features': 3}
50840.744514 {'n_estimators': 21, 'max_features': 5}
49276.1753033 {'n_estimators': 122, 'max_features': 7}
50776.7360494 {'n_estimators': 75, 'max_features': 3}
50682.7075546 {'n_estimators': 88, 'max_features': 3}
49612.1525305 {'n_estimators': 100, 'max_features': 5}
50472.6107336 {'n_estimators': 150, 'max_features': 3}
64458.2538503 {'n_estimators': 2, 'max_features': 5}
3、集成方法
另一种微调系统的方法是将表现最好的模型组合起来,组合之后的性能通常要比单独的模型要好,特别是当单独模型的误差类型不同的时候。
4、分析最佳模型和它们的误差
通过分析最佳模型,可以获得对问题更深入的了解,比如RandomForestRegressor可以指出每个属性对于做出准确预测的相对重要性:
feature_importances=grid_search.best_estimator_.feature_importances_
feature_importances
array([ 6.64328643e-02, 5.98643661e-02, 4.24000916e-02,1.56533506e-02, 1.48014987e-02, 1.48206944e-02,1.44649633e-02, 3.79928190e-01, 5.02997645e-02,1.12321615e-01, 6.19821777e-02, 7.02140290e-03,1.54010053e-01, 5.72379858e-05, 3.35501695e-03,2.58671286e-03])
将重要性分数和属性名放到一起:
extra_attribs=["rooms_per_hhold","pop_per_hhold","bedrooms_per_room"]
cat_one_hot_attribs=list(encoder.classes_)
attributes=num_attribs+extra_attribs+cat_one_hot_attribs
sorted(zip(feature_importances,attributes),reverse=True)[(0.37992818982389415, 'median_income'),(0.15401005285182726, 'INLAND'),(0.11232161543523374, 'pop_per_hhold'),(0.066432864344133563, 'longitude'),(0.061982177702503423, 'bedrooms_per_room'),(0.059864366115520352, 'latitude'),(0.05029976451819948, 'rooms_per_hhold'),(0.042400091599261863, 'housing_median_age'),(0.015653350555796825, 'total_rooms'),(0.014820694351729223, 'population'),(0.014801498682983864, 'total_bedrooms'),(0.014464963325440042, 'households'),(0.0070214028983453629, '<1H OCEAN'),(0.0033550169534377664, 'NEAR BAY'),(0.002586712855893692, 'NEAR OCEAN'),(5.7237985799461445e-05, 'ISLAND')]
有了这些信息,就可以丢弃不是那么重要的特征,比如,显然只有一个ocean_proximity的类型INLAND就够了,所以可以丢弃掉其他的。
(四)用测试集评估系统
调节完系统之后,终于有了一个性能足够好的系统,现在就可以用测试集评估最后的模型了:从测试集得到预测值和标签
运行full_pipeline转换数据,调用transform(),再用测试集评估最终模型:
final_model=grid_search.best_estimator_X_test=strat_test_set.drop("median_house_value",axis=1)
y_test=strat_test_set["median_house_value"].copy()X_test_prepared=full_pipeline.transform(X_test)
final_predictions=final_model.predict(X_test_prepared)
final_mse=mean_squared_error(y_test,final_predictions)
final_rmse=np.sqrt(final_mse)
final_rmse
47997.889508495638
我们可以计算测试的RMSE的95%的置信区间
from scipy import stats
confidence=0.95
squared_errors = (final_predictions - y_test) ** 2
mean = squared_errors.mean()
m = len(squared_errors)np.sqrt(stats.t.interval(confidence, m - 1,loc=np.mean(squared_errors),scale=stats.sem(squared_errors)))
array([ 45949.34599412, 49962.50991746])
也可以手工计算间隔
tscore = stats.t.ppf((1 + confidence) / 2, df=m - 1)
tmargin = tscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - tmargin), np.sqrt(mean + tmargin)
(45949.345994123607, 49962.509917455063)
最后,利用z分位数
zscore = stats.norm.ppf((1 + confidence) / 2)
zmargin = zscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - zmargin), np.sqrt(mean + zmargin)
(45949.960175402077, 49961.945062401668)
评估结果通常要比验证结果的效果差一些,如果你之前做过很多微调,系统在验证集上微调得到不错的性能,通常不会在未知的数据集上有同样好的效果。
最后就对项目的预上线阶段,需要展示你的方案,重点说明学到了什么、做了什么、没做什么、做过什么假设、系统的限制是什么等。
(五)启动、监控、维护系统
1、启动
需要为实际生产做好准备,特别是接入输入数据源,并编写测试
2、监控
需要监控代码,以固定间隔检测系统的实时表现,当发生下降时触发警报,这对于捕捉突然的系统崩溃性能下降十分重要,做监控很常见,因为模型会随着数据的演化而性能下降,除非模型用新数据定期训练。评估系统的表现需要对预测值采样并进行评估,通常人为分析,需要将人工评估的流水线植入系统
3、维护
数据的分布是变化的,数据会更新,要通过监控来及时的发现数据的变化,做模型的优化。
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 【Unity3D】 Photon多人游戏开发教程
一、前言Photon Unity Networking(首字母缩写PUN)是一个Unity多人游戏插件包。它提供了身份验证选项、匹配,以及快速、可靠的通过我们的Photon后端实现的游戏内通信。二、原文原文地址:http://bbs.gameres.com/forum.php?mod=viewthread&tid=797805&extra=page=1&…...
2024/4/21 0:31:21 - 关于电子设计大赛
一年一度的电子设计大赛选拔赛开始了,作为参加两年的选手还是很有感悟,下面我简单从电赛是什么和经验教训谈论一下: 电赛全称全国大学生电子设计大赛,它国赛和省赛交叉进行,是衡量大学生电子设计能力的重要平台,也是用人单位评价别人的基础之一。比赛时间为四天三夜,一般…...
2024/4/20 21:01:33 - 基于visual c++之windows核心编程代码分析(10)实现socket通信
在多台计算机之间实现通信,最常见的方法有两种:Socket通信与UDP通信。Socket是一种基于TCP/IP协议,建立稳定连接的点对点通信,它的特点是安全性高,数据不会丢失,但是很占系统资源。在JAVA中,ServerSocket类和Socket类为我们实现了Socket通信,建立通信的一般步骤是:1。…...
2024/5/1 6:46:51 - 电子设计大赛的赛前反省
这是我第一篇博客,本来计划在这么值得纪念的日子写点什么牛逼哄哄的技术博客o( ̄ヘ ̄o#)但是打开电脑迟迟不知如何开始,可能大家已经猜到了,其实我只是一个技术小白。虽然说可能以前接触过一点,但是完全不够看啊,这让我不由的感叹了,书到用时方恨少!!不过仅仅是这样的…...
2024/5/1 13:13:25 - Unity3D 学习笔记4 —— UGUI+uLua游戏框架
Unity3D 学习笔记4 —— UGUI+uLua游戏框架使用到的资料下载地址以及基础知识 框架讲解 拓展热更过程在这里我们使用的是uLua/cstolua技术空间所以提供的UGUI+uLua的热更游戏框,我也只是把我学习和使用这个框架的笔记记录下来而已。一.资料下载地址以及基础知识:主要使用到的…...
2024/4/20 21:01:29 - 预测分析和数据挖掘服务的好处
预测分析和数据挖掘服务的好处 预测分析是处理各种数据和应用各种数学公式,发现对于给定的情况下最好的决策过程。预测分析给你的公司带来竞争优势,可用于大幅提高投资回报率。这是决策科学,消除猜测出来的决策过程,并套用行之有效的科学准则,以找到正确的解决方案,在…...
2024/4/21 0:31:19 - QT学习笔记17Socket通信
Qt中提供的所有的Socket类都是非阻塞的。 Qt中常用的用于socket通信的套接字类:QTcpServer 用于TCP/IP通信, 作为服务器端套接字使用QTcpSocket 用于TCP/IP通信,作为客户端套接字使用。QUdpSocket 用于UDP通信,服务器,客户端均使用此套接字。1 TCP/IP传统TCP通信过程:在Qt中…...
2024/4/21 0:31:18 - 【Unity3D开发小游戏】《塔防游戏》Unity开发教程
文章目录一、前言二、源码二、版本三、开始1、游戏规则2、艺术风格3、摄像机设置4、光线设置5、地面设置6、建筑物设置7、城堡设置8、怪物设置9、生成怪物10、子弹设置11、防御塔设置12、内容拓展 一、前言 在本教程中,我们将创建一个小的三维塔防御游戏与一个完全独特的图形风…...
2024/4/21 0:31:18 - 2020年大学生电子设计竞赛,又来了!
不知不觉,又临近5月份,疫情下的各个比赛活动都受到了影响,今年是偶数年,暑期应该是各个省份的电子设计竞赛比赛之时。还有三四个月,有想参加的比赛的同学应该可以提前准备了。关于比赛的帖子,之前写过很多篇:「第一弹」电子设计大赛应该准备什么?「第一篇」大学生电子设…...
2024/4/21 0:31:17 - 姜启源《数学模型》笔记
第1章 建立数学模型关键词:数学模型 意义 特点第1章是引入的一章,对数学模型的意义来源,做了很好的解释。其实数学模型也是模型的一种,是我们用来研究问题、做实验的工具之一,只不过它比较“理论”、“摸不着”而已。但通常,数学模型有严谨的特点,而且我们可以根据建模实…...
2024/4/21 0:31:16 - java多线程(2)---基于ExecutorService的socket通信线程池
了解线程池 socket通信,如果服务器端采用的实现方式是:一个客户端对应一个线程。那么,每个新线程都会消耗系统资源:创建一个线程会占用CPU周期,而且每个线程都会建立自己的数据结构(如,栈),也要消耗系统内存,另外,当一个线程阻塞时,JVM将保存其状态,选择另外一个线…...
2024/4/20 0:50:08 - 【Unity3D】Unity3D 场景的淡入淡出效果实现
Unity3d 场景的淡入淡出效果实现 思路用UGUI设计一张全屏的纯色图片 控制图片的Alpha值,来实现淡入淡出的效果效果展示实现先新建一张图片,设置锚点为全屏设置颜色值新建脚本Fade_Controlusing UnityEngine; using UnityEngine.UI;//状态效果值 public enum FadeStatuss {Fad…...
2024/4/21 0:31:13 - 2017年全国大学生电子设计大赛有感
2017年全国大学生电子设计大赛有感作为一个大专生,本本不应该提这个比赛,但是参加了还是提一下吧! 作为一名大专生,我的指导老师有一种惯性,专科生比不过本科生。其实他犯了一个错误。在当时的训练情况无论是大专的题目还是本科的题目,只要没有高手的帮助,我们都赢不了。…...
2024/4/21 0:31:13 - 弹性系数法 预测
什么是弹性系数法弹性系数法在对一个因素发展变化预测的基础上,通过弹性系数对另一个因素的发展变化作出预测的一种间接预测方法。弹性系数法适用于两个因素y和x之间有指数函数关系的情况,式中α为比例系数,b为y对x的弹性系数。 弹性一词来源于材料力学中的弹性变形的概念。弹性…...
2024/4/21 0:31:11 - 【翻译】 Unity3D VR 教程:1.VR概述
Unity VR 入门Unity加入了一些对VR的内置的支持,但是只针对几种特定的VR设备。这个指南会专注于Oculus 系列的VR设备, 特别是 Oculus Rift Development Kit 2 (DK2 ) 和 消费者版本的Gear VR(一种手机外设,需要三星Galaxy s6, s6 Edge, s6 Edge+, 或者 Note 5)。也许以后…...
2024/4/21 0:31:10 - 使用socket连接实现客户端向服务器端的单向通信(socket通信第二弹)
欢迎转载,请注明转载自微信订阅号(安卓编程入门进阶)。 百度云原清晰度地址:http://pan.baidu.com/s/1mhS0H8O 在socket连接状态下实现客户端发送数据到服务器端的功能,需要在客户端编写字符串输出代码,在服务器端编写数据接收代码。每次有输出时启动一次输出线程来完成,…...
2024/4/21 0:31:11 - 什么是开源软件? 什么是免费软件?GNU是什么意思?
商业软件 商业软件是在计算机软件中,指被作为商品进行交易的软件。相对于商业软件,有非商业的专用软件(但专用软件中亦包含有商业软件),可供分享使用的自由软件、共享软件、免费软件等。 共享软件 共享软件是为了促进IT业的发展,软件开发商或自由软件者推出的免费产品,共…...
2024/5/1 2:46:09 - 2018年TI杯大学生电子设计大赛(D题手势识别)
相关简介题主于大二年级下学期参加了2018年TI杯电子设计大赛(辽宁省),选题为D题《手势识别》,最终为省二等奖,在此将比赛过程及代码进行分享,欢迎前来交流,不足之处还望指正。硬件模块模块数量功能FDC22142手势数据采集kinetis k602手势数据训练与判别oled1手势判别结果…...
2024/4/21 0:31:08 - Unity3d游戏引擎Windy系列教程:3D建模系列板块1(unity支持的建模软件)
好开始一个新的板块,对于一个游戏来说没有游戏建模那么这个游戏就不能称作游戏了吧,我们看到的整个游戏世界都是由许许多多的平面构成的。 是不是觉得不可思议,画面上那么逼真的角色竟是一堆的多边形,事实就是这样,你的屏幕里只是被渲染出来的几万个面而已。 首先今天只介…...
2024/4/21 0:31:06 - 【机器学习项目】意大利新型冠状病毒(Covid-19)感染数学模型及预测(Python)
目录一、项目背景二、项目的数据集1、数据集介绍2、数据集链接三、项目分析四、项目步骤1、安装Python和Scipy平台(1)安装Anaconda(2)检查已安装版本2、导入数据(1)导入程序库(2)导入数据集3、数据集准备4、建立和评估模型(1)logistic模型(The logistic model)(2)…...
2024/4/21 0:31:05
最新文章
- 【团体程序设计天梯赛】往年关键真题 L2-036 网红点打卡攻略 模拟 L2-037 包装机 栈和队列 详细分析完整AC代码
【团体程序设计天梯赛 往年关键真题 详细分析&完整AC代码】搞懂了赛场上拿下就稳 【团体程序设计天梯赛 往年关键真题 25分题合集 详细分析&完整AC代码】(L2-001 - L2-024)搞懂了赛场上拿下就稳了 【团体程序设计天梯赛 往年关键真题 25分题合…...
2024/5/1 14:27:28 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - LeetCode 热题 100 题解(二):双指针部分(2)| 滑动窗口部分(1)
题目四:接雨水(No. 43) 题目链接:https://leetcode.cn/problems/trapping-rain-water/description/?envTypestudy-plan-v2&envIdtop-100-liked 难度:困难 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图&am…...
2024/5/1 10:20:40 - Unity核心学习
目录 认识模型的制作流程模型的制作过程 2D相关图片导入设置图片导入概述纹理类型设置纹理形状设置纹理高级设置纹理平铺拉伸设置纹理平台打包相关设置 SpriteSprite Editor——Single图片编辑Sprite Editor——Multiple图片编辑Sprite Editor——Polygon图片编辑SpriteRendere…...
2024/5/1 13:06:24 - Golang Gin框架
1、这篇文章我们简要讨论一些Gin框架 主要是给大家一个基本概念 1、Gin主要是分为路由和中间件部分。 Gin底层使用的是net/http的逻辑,net/http主要是说,当来一个网络请求时,go func开启另一个协程去处理后续(类似epoll)。 然后主协程持续…...
2024/4/30 17:23:41 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/29 23:16:47 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/30 18:14:14 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/29 2:29:43 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/30 18:21:48 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/27 17:58:04 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/27 14:22:49 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/28 1:28:33 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/30 9:43:09 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/27 17:59:30 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/25 18:39:16 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/28 1:34:08 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/29 20:46:55 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/30 22:21:04 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/1 4:32:01 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/27 23:24:42 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/28 5:48:52 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/30 9:42:22 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/30 9:43:22 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/30 9:42:49 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57