大数据Hadoop集群搭建
大数据Hadoop集群搭建
一、环境
服务器配置:
CPU型号:Intel® Xeon® CPU E5-2620 v4 @ 2.10GHz
CPU核数:16
内存:64GB
操作系统
版本:CentOS Linux release 7.5.1804 (Core)
主机列表:
| IP | 主机名 |
|---|---|
| 192.168.1.101 | node1 |
| 192.168.1.102 | node2 |
| 192.168.1.103 | node3 |
| 192.168.1.104 | node4 |
| 192.168.1.105 | node5 |
软件安装包路径:/data/tools/
JAVA_HOME路径:/opt/java # java为软链接,指向jdk的指定版本
Hadoop集群路径:/data/bigdata/
软件版本及部署分布:
| 组件名 | 安装包 | 说明 | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|---|---|
| JDK | jdk-8u162-linux-x64.tar.gz | 基础环境 | ✔ | ✔ | ✔ | ✔ | ✔ |
| zookeeper | zookeeper-3.4.12.tar.gz | ✔ | ✔ | ✔ | |||
| Hadoop | hadoop-2.7.6.tar.gz | ✔ | ✔ | ✔ | ✔ | ✔ | |
| spark | spark-2.1.2-bin-hadoop2.7.tgz | ✔ | ✔ | ✔ | ✔ | ✔ | |
| scala | scala-2.11.12.tgz | ✔ | ✔ | ✔ | ✔ | ✔ | |
| hbase | hbase-1.2.6-bin.tar.gz | ✔ | ✔ | ✔ | |||
| hive | apache-hive-2.3.3-bin.tar.gz | ✔ | |||||
| kylin | apache-kylin-2.3.1-hbase1x-bin.tar.gz | ✔ | |||||
| kafka | kafka_2.11-1.1.0.tgz | ✔ | ✔ | ||||
| hue | hue-3.12.0.tgz | ✔ | |||||
| flume | apache-flume-1.8.0-bin.tar.gz | ✔ | ✔ | ✔ | ✔ | ✔ |
注:所有的软链接不可以跨服务器传输,应该单独创建;否则会把软链接所指向的文件或整个目录传过去;
二、常用命令
1、查看系统基本配置:
[root@localhost ~]# uname -a
Linux node1 3.10.0-123.9.3.el7.x86_64 #1 SMP Thu Nov 6 15:06:03 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.5.1804 (Core)
[root@localhost ~]# free -mtotal used free shared buffers cached
Mem: 64267 2111 62156 16 212 1190
-/+ buffers/cache: 708 63559
Swap: 32000 0 32000
[root@localhost ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2095.148
BogoMIPS: 4190.29
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-15
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda2 100G 3.1G 97G 4% /
devtmpfs 7.7G 0 7.7G 0% /dev
tmpfs 7.8G 0 7.8G 0% /dev/shm
tmpfs 7.8G 233M 7.5G 3% /run
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/sda1 500M 9.8M 490M 2% /boot/efi
/dev/sda4 1.8T 9.3G 1.8T 1% /data
tmpfs 1.6G 0 1.6G 0% /run/user/1000
2、启动集群
start-dfs.sh
start-yarn.sh
3、关闭集群
stop-yarn.sh
stop-dfs.sh
4、监控集群
hdfs dfsadmin -report
5、单个进程启动/关闭
hadoop-daemon.sh start|stop namenode|datanode| journalnode
yarn-daemon.sh start |stop resourcemanager|nodemanager
三、 环境准备(所有服务器)
1、设置主机名(其它类似)
[root@localhost ~]# hostnamectl set-hostname node1
2、关闭防火墙firewalld并禁止开机自启动和SELINUX
[root@node1 ~]# systemctl disable firewalld.service
[root@node1 ~]# systemctl stop firewalld.service
[root@node1 ~]# systemctl status firewalld.service● firewalld.service - firewalld - dynamic firewall daemonLoaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)Active: inactive (dead)Docs: man:firewalld(1)[root@node1 ~]# setenforce 0
[root@node1 ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
[root@node1 ~]# grep SELINUX=disabled /etc/selinux/config
SELINUX=disabled
3、修改hosts文件
[root@node1 ~]# vim /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 node1
192.168.1.102 node2
192.168.1.103 node3
192.168.1.104 node4
192.168.1.105 node5
4、设置ssh免密登陆,可用ansible
[root@node1 ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@node1 ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@node1 ~]# ll -d .ssh/
drwx------ 2 root root 4096 Jun 5 08:50 .ssh/
[root@node1 ~]# ll .ssh/
total 12
-rw-r--r-- 1 root root 599 Jun 5 08:50 authorized_keys
-rw------- 1 root root 672 Jun 5 08:50 id_dsa
-rw-r--r-- 1 root root 599 Jun 5 08:50 id_dsa.pub# 把其它服务器的~/.ssh/id_dsa.pub内容也追加到node1服务器的~/.ssh/authorized_keys文件中,然后分发
[root@node1 ~]# scp –rp ~/.ssh/authorized_keys node2: ~/.ssh/
[root@node1 ~]# scp –rp ~/.ssh/authorized_keys node3: ~/.ssh/
[root@node1 ~]# scp –rp ~/.ssh/authorized_keys node4: ~/.ssh/
[root@node1 ~]# scp –rp ~/.ssh/authorized_keys node5: ~/.ssh/
也可以node1生成一套密钥,然后把~/.ssh整个目录分发到其它服务器,共用一个密钥
5、修改文件句柄数
[root@node1 ~]# vim /etc/security/limits.conf
#---------custom-----------------------
#
* soft nofile 240000
* hard nofile 655350
* soft nproc 240000
* hard nproc 655350
#-----------end-----------------------
[root@node1 ~]# source /etc/security/limits.conf
[root@node1 ~]# ulimit -n
24000
6、时间同步
ntp服务器设置
# 局域网内设置一台ntp服务器,其它和这台ntp同步即可,云服务器一般默认已同步
[root@node1 ~]# yum install ntp -y # 安装ntp服务
[root@node1 ~]# cp -a /etc/ntp.conf{,.bak}
[root@node1 ~]# vim /etc/ntp.conf
restrict default kod nomodify notrap nopeer noquery # restrict、default定义默认访问规则,nomodify禁止远程主机修改本地服务器
restrict 127.0.0.1 # 这里的查询是服务器本身状态的查询。
restrict -6 ::1
#server 0.centos.pool.ntp.org iburst # 注掉官方自带的网络站点
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server ntp1.aliyun.com # 目标服务器网络位置
server 127.127.1.0 # local clock,当服务器与公用的时间服务器失去联系时,就是连不上互联网时,以局域网内的时间服务器为客户端提供时间同步服务。
fudge 127.127.1.0 stratum 10# 如果计划任务有时间同步,先注释,两种用法会冲突。
[root@node1 ~]# crontab –e
#*/30 * * * * /usr/sbin/ntpdate ntp1.aliyun.com > /dev/null 2>&1;/sbin/hwclock -w# 启动服务并设置开启自启:
[root@node1 /]# systemctl start ntpd.service # 启动服务
[root@node1 /]# systemctl enable ntpd.service # 设置为开机启动
[root@node1 ~]# systemctl status ntpd.service
● ntpd.service - Network Time ServiceLoaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)Active: active (running) since 一 2018-05-21 13:47:33 CST; 1 weeks 2 days agoMain PID: 17915 (ntpd)CGroup: /system.slice/ntpd.service└─17915 /usr/sbin/ntpd -u ntp:ntp -g5月 23 11:41:40 node1 ntpd[17915]: Listen normally on 14 enp0s25 192.168.1.101 UDP 123
5月 23 11:41:40 node1 ntpd[17915]: new interface(s) found: waking up resolver
5月 23 11:41:42 node1 ntpd[17915]: Listen normally on 18 enp0s25 fe80::6a85:bbb1:ad57:f6ae UDP 123
[root@node1 ~]# ntpq -p # 检查时间服务器是否正确同步remote refid st t when poll reach delay offset jitter
==============================================================================
*time5.aliyun.co 10.137.38.86 2 u 468 1024 377 14.374 -4.292 6.377当所有远程服务器(不是本地服务器)的jitter值都为4000,并且reach和dalay的值是0时,就表示时间同步有问题。可能原因有2个:1)服务器端的防火墙设置,阻断了123端口(可以用 iptables -t filter -A INPUT -p udp --destination-port 123 -j ACCEPT 解决)2)每次重启ntp服务器之后,大约3-5分钟客户端才能与服务端建立连接,建立连接之后才能进行时间同步,否则客户端同步时间时会显示no server suitable for synchronization found的报错信息,不用担心,等会就可以了。
其它主机设置,以node2为例
[root@node2 /]# systemctl stop ntpd.service # 关闭ntp服务
[root@node2 /]# systemctl disable ntpd.service # 禁止开机自启动
[root@node2 ~]# yum install ntpdate -y
[root@node2 ~]# /usr/sbin/ntpdate 192.168.1.101
30 May 17:54:09 ntpdate[20937]: adjust time server 192.168.1.101 offset 0.000758 sec
[root@node2 ~]# crontab –e
*/30 * * * * /usr/sbin/ntpdate 192.168.1.101 > /dev/null 2>&1;/sbin/hwclock -w
[root@node2 ~]# systemctl restart crond.service
[root@node2 ~]# systemctl status crond.service
● crond.service - Command SchedulerLoaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor preset: enabled)Active: active (running) since 四 2018-05-31 09:05:39 CST; 11s agoMain PID: 12162 (crond)CGroup: /system.slice/crond.service└─12162 /usr/sbin/crond -n5月 31 09:05:39 node2 systemd[1]: Started Command Scheduler.
5月 31 09:05:39 node2 systemd[1]: Starting Command Scheduler...
7、上传安装包到node1服务器
[root@node1 ~]# mkdir -pv /data/tools
[root@node1 ~]# cd /data/tools
[root@node1 tools]# ll
total 1221212
-rw-r--r-- 1 root root 58688757 May 24 10:23 apache-flume-1.8.0-bin.tar.gz
-rw-r--r-- 1 root root 232229830 May 24 10:25 apache-hive-2.3.3-bin.tar.gz
-rw-r--r-- 1 root root 286104833 May 24 10:26 apache-kylin-2.3.1-hbase1x-bin.tar.gz
-rw-r--r-- 1 root root 216745683 May 24 10:28 hadoop-2.7.6.tar.gz
-rw-r--r-- 1 root root 104659474 May 24 10:27 hbase-1.2.6-bin.tar.gz
-rw-r--r-- 1 root root 47121634 May 24 10:29 hue-3.12.0.tgz
-rw-r--r-- 1 root root 56969154 May 24 10:49 kafka_2.11-1.1.0.tgz
-rw-r--r-- 1 root root 193596110 May 24 10:29 spark-2.1.2-bin-hadoop2.7.tgz
-rw-r--r-- 1 root root 36667596 May 24 10:28 zookeeper-3.4.12.tar.gz
[root@node1 bigdata]#
8、安装JDK
[root@node1 ~]# tar xf /data/tools/jdk-8u162-linux-x64.tar.gz -C /opt/
[root@node1 ~]# [ -L "/opt/java" ] && rm -f /opt/java
[root@node1 ~]# cd /opt/ && ln -s /opt/jdk1.8.0_162 /opt/java
[root@node1 ~]# chown -R root:root /opt/jdk1.8.0_162
[root@node1 ~]# echo -e "# java\nexport JAVA_HOME=/opt/java\nexport PATH=\${PATH}:\${JAVA_HOME}/bin:\${JAVA_HOME}/jre/bin\nexport CLESSPATH=.:\${JAVA_HOME}/lib:\${JAVA_HOME}/jre/lib" > /etc/profile.d/java_version.sh
[root@node1 ~]# source /etc/profile.d/java_version.sh
[root@node1 ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
四、 安装zookeeper
官方文档
1、解压zookeeper
[root@node1 ~]# mkdir -pv /data/bigdata/src
[root@node1 ~]# tar -zxvf /data/tools/zookeeper-3.4.12.tar.gz -C /data/bigdata/src
[root@node1 ~]# ln -s /data/bigdata/src/zookeeper-3.4.12 /data/bigdata/zookeeper# 添加环境变量
[root@node1 ~]# echo -e "# zookeeper\nexport ZOOKEEPER_HOME=/data/bigdata/zookeeper\nexport PATH=\$ZOOKEEPER_HOME/bin:\$PATH" > /etc/profile.d/bigdata_path.sh
[root@node1 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
[root@node1 ~]#
2、配置zoo.cfg文件
[root@node1 ~]# cd /data/bigdata/zookeeper/conf/ #进入conf目录
[root@node1 conf]# cp zoo_sample.cfg zoo.cfg #拷贝模板
[root@node1 conf]# vim zoo.cfg
# The number of millinode2s of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/bigdata/zookeeper/data # 添加
dataLogDir=/data/bigdata/zookeeper/dataLog # 添加
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node1:2888:3888 # 添加
server.2=node2:2888:3888
server.3=node3:2888:3888
3、添加myid,分发(安装个数为奇数)
# 创建指定目录:dataDir目录下增加myid文件;myid中写当前zookeeper服务的id, 因为server.1=node1:2888:3888 server指定的是1,
[root@node1 conf]# mkdir -pv /data/bigdata/zookeeper/{data,dataLog}
[root@node1 conf]# echo 1 > /data/bigdata/zookeeper/data/myid
4、分发:
[root@node2 ~]# mkdir -pv /data/bigdata/
[root@node3 ~]# mkdir -pv /data/bigdata/[root@node1 conf]# scp -rp /data/bigdata/src node2:/data/bigdata/
[root@node1 conf]# scp -rp /data/bigdata/src node3:/data/bigdata/[root@node2 ~]# ln -s /data/bigdata/src/zookeeper-3.4.12 /data/bigdata/zookeeper
[root@node3 ~]# ln -s /data/bigdata/src/zookeeper-3.4.12 /data/bigdata/zookeeper# 在其余机子配置,node2下面的myid是2,node3下面myid是3,这些都是根据server来的
[root@node2 ~]# echo 2 > /data/bigdata/zookeeper/data/myid
[root@node3 ~]# echo 3 > /data/bigdata/zookeeper/data/myid
五、 安装Hadoop
官方文档
- 生产环境:两个主节点只装namenode,不装datanode;
1、解压hadoop
[root@node1 ~]# tar -zxvf /data/tools/hadoop-2.7.6.tar.gz -C /data/bigdata/src
[root@node1 ~]# ln -s /data/bigdata/src/hadoop-2.7.6 /data/bigdata/hadoop# 添加环境变量
[root@node1 ~]# echo -e "\n# hadoop\nexport HADOOP_HOME=/data/bigdata/hadoop\nexport PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node1 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@node1 ~]#
2、配置hadoop-env.sh
[root@node1 ~]# cd /data/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/opt/java # 添加
export HADOOP_SSH_OPTS="-p 22"
3、配置core-site.xml
[root@node1 hadoop]# vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <!--Yarn 需要使用 fs.defaultFS 指定NameNode URI --><property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property><name>hadoop.tmp.dir</name><value>/data/bigdata/tmp</value>
</property>
<property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value><discription>zookeeper客户端连接地址</discription>
</property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value>
</property><property><name>fs.trash.interval</name><value>1440</value><discription>以分钟为单位的垃圾回收时间,垃圾站中数据超过此时间,会被删除。如果是0,垃圾回收机制关闭。</discription>
</property><property><name>fs.trash.checkpoint.interval</name><value>1440</value><discription>以分钟为单位的垃圾回收检查间隔。</discription>
</property><property><name>hadoop.security.authentication</name><value>simple</value><discription>可以设置的值为 simple (无认证) 或者 kerberos(一种安全认证系统)</discription>
</property><!-- 与hue集成所需配置--><property><name>hadoop.proxyuser.hue.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hue.groups</name><value>*</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>
新建指定目录
[root@node1 hadoop]# mkdir -p /data/bigdata/tmp
4、配置yarn-site.xml
[root@node1 hadoop]# vim yarn-site.xml
<?xml version="1.0"?>
<configuration><property><name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name><value>5000</value><discription>schelduler失联等待连接时间</discription></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><discription>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</discription></property><property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>5000</value><description>How often to try connecting to the ResourceManager.</description></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><discription>是否启用RM HA,默认为false(不启用)</discription></property><property><name>yarn.resourcemanager.ha.automatic-failover.enabled</name><value>true</value><discription>是否启用自动故障转移。默认情况下,在启用HA时,启用自动故障转移。</discription></property><property><name>yarn.resourcemanager.ha.automatic-failover.embedded</name><value>true</value><discription>启用内置的自动故障转移。默认情况下,在启用HA时,启用内置的自动故障转移。</discription></property><property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value><discription>集群的Id,elector使用该值确保RM不会做为其它集群的active。</discription></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value><discription>RMs的逻辑id列表,rm管理资源器;一般配两个,一个起作用 其他备用;用逗号分隔,如:rm1,rm2 </discription></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node3</value><discription>RM的hostname</discription></property><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8030</value><discription>RM对AM暴露的地址,AM通过地址想RM申请资源,释放资源等</discription></property><property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8031</value><discription>RM对NM暴露地址,NM通过该地址向RM汇报心跳,领取任务等</discription></property><property><name>yarn.resourcemanager.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8032</value><discription>RM对客户端暴露的地址,客户端通过该地址向RM提交应用程序等</discription></property><property><name>yarn.resourcemanager.admin.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8033</value><discription>RM对管理员暴露的地址.管理员通过该地址向RM发送管理命令等</discription></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8088</value><discription>RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息</discription></property><property><description>The https adddress of the RM web application.</description><name>yarn.resourcemanager.webapp.https.address.rm1</name><value>${yarn.resourcemanager.hostname.rm1}:8090</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node4</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8031</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8032</value></property><property><name>yarn.resourcemanager.admin.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8033</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8088</value></property><property><description>The https adddress of the RM web application.</description><name>yarn.resourcemanager.webapp.https.address.rm2</name><value>${yarn.resourcemanager.hostname.rm2}:8090</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value><discription>默认值为false,也就是说resourcemanager挂了相应的正在运行的任务在rm恢复后不能重新启动</discription></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value><discription>状态存储的类</discription></property><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property><property><name>yarn.resourcemanager.zk-address</name><value>${ha.zookeeper.quorum}</value><discription>ZooKeeper服务器的地址(主机:端口号),既用于状态存储也用于内嵌的leader-election。</discription></property><property><name>yarn.nodemanager.address</name><value>${yarn.nodemanager.hostname}:8041</value><discription>The address of the container manager in the NM.</discription></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>58000</value><discription>该节点上nodemanager可使用的物理内存总量</discription></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>16</value><discription>该节点上nodemanager可使用的虚拟CPU个数</discription></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2</value><discription>任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。</discription></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value><discription>单个任务可申请的最小物理内存量</discription></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>58000</value><discription>单个任务可申请的最大物理内存量</discription></property><property><name>yarn.scheduler.minimum-allocation-vcores</name><value>1</value><discription>单个任务可申请的最小虚拟CPU个数</discription></property><property><name>yarn.scheduler.maximum-allocation-vcores</name><value>16</value><discription>单个任务可申请的最大虚拟CPU个数</discription></property>
</configuration>
5、配置mapred-site.xml
[root@node1 hadoop]# cp mapred-site.xml{.template,}
[root@node1 hadoop]# vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>sjfx:10020</value></property></configuration>
6、配置hdfs-site.xml
[root@node1 hadoop]# vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>dfs.permissions</name><value>true</value><description>If "true", enable permission checking in HDFS.If "false", permission checking is turned off,but all other behavior is unchanged.Switching from one parameter value to the other does not change the mode,owner or group of files or directories.</description></property><property><name>dfs.replication</name><value>2</value><description>保存副本数</description></property><property><discription>持久存储名字空间,事务日志的本地路径</discription><name>dfs.namenode.name.dir</name><value>/data/bigdata/hdfs/name</value></property><property><discription>datanode存放数据的路径,单个节点单配,多个目录逗号分隔</discription><name>dfs.datanode.data.dir</name><value>/data/bigdata/hdfs/data</value></property><property><discription>指定用于在DataNode间传输block数据的最大线程数</discription><name>dfs.datanode.max.transfer.threads</name><value>16384</value></property><property><name>dfs.datanode.balance.bandwidthPerSec</name><value>52428800</value><description>Specifies the maximum amount of bandwidth that each datanodecan utilize for the balancing purpose in term ofthe number of bytes per second.</description></property><property><name>dfs.datanode.balance.max.concurrent.moves</name><value>50</value><description>增加DataNode上转移block的Xceiver的个数上限。</description></property><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:50070</value></property><property><name>dfs.namenode.journalnode</name><value>node1:8485;node2:8485;node3:8485</value><discription>journalnode为了解决hadoop单点故障,给namenode做元数据同步的,奇数个,一般3个或5个</discription></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://${dfs.namenode.journalnode}/mycluster</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_dsa</value></property><property><name>dfs.journalnode.edits.dir</name><value>${hadoop.tmp.dir}/dfs/journal</value></property><property><name>dfs.permissions.superusergroup</name><value>root</value><description>超级用户组名</description></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>开启自动故障转移</description></property>
</configuration>
新建相应目录
[root@node1 hadoop]# mkdir -pv /data/bigdata/tmp/dfs/journal
7、配置capacity-scheduler.xml
[root@node1 hadoop]# vim capacity-scheduler.xml
<configuration><property><name>yarn.scheduler.capacity.maximum-applications</name><value>10000</value><description>Maximum number of applications that can be pending and running.</description></property><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.1</value><description>Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent runningapplications.</description></property><property><name>yarn.scheduler.capacity.resource-calculator</name><value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value><description>The ResourceCalculator implementation to be used to compare Resources in the scheduler.The default i.e. DefaultResourceCalculator only uses Memory whileDominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc.</description></property><property><name>yarn.scheduler.capacity.root.queues</name><value>default</value><description>The queues at the this level (root is the root queue).</description></property><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>100</value><description>Default queue target capacity.</description></property><property><name>yarn.scheduler.capacity.root.default.user-limit-factor</name><value>1</value><description>Default queue user limit a percentage from 0.0 to 1.0.</description></property><property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>100</value><description>The maximum capacity of the default queue. </description></property><property><name>yarn.scheduler.capacity.root.default.state</name><value>RUNNING</value><description>The state of the default queue. State can be one of RUNNING or STOPPED.</description></property><property><name>yarn.scheduler.capacity.root.default.acl_submit_applications</name><value>*</value><description>The ACL of who can submit jobs to the default queue.</description></property><property><name>yarn.scheduler.capacity.root.default.acl_administer_queue</name><value>*</value><description>The ACL of who can administer jobs on the default queue.</description></property><property><name>yarn.scheduler.capacity.node-locality-delay</name><value>40</value><description>Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. Typically this should be set to number of nodes in the cluster, By default is setting approximately number of nodes in one rack which is 40.</description></property><property><name>yarn.scheduler.capacity.queue-mappings</name><value></value><description>A list of mappings that will be used to assign jobs to queuesThe syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*Typically this list will be used to map users to queues,for example, u:%user:%user maps all users to queues with the same nameas the user.</description></property><property><name>yarn.scheduler.capacity.queue-mappings-override.enable</name><value>false</value><description>If a queue mapping is present, will it override the value specifiedby the user? This can be used by administrators to place jobs in queuesthat are different than the one specified by the user.The default is false.</description></property>
</configuration>
8、配置slaves
[root@node1 hadoop]# vim slaves
node1
node2
node3
node4
node5
9、修改$HADOOP_HOME/sbin/hadoop-daemon.sh
[root@node1 hadoop]# cd /data/bigdata/hadoop/sbin/
[root@node1 sbin]# vim hadoop-daemon.sh
#添加:
HADOOP_PID_DIR=/data/bigdata/hdfs/pids
YARN_PID_DIR=/data/bigdata/hdfs/pids# 新建相应目录
[root@node1 sbin]# mkdir -pv /data/bigdata/hdfs/{name,data,pids}
10、修改$HADOOP_HOME/sbin/yarn-daemon.sh
#添加:
[root@node1 sbin]# vim yarn-daemon.sh
HADOOP_PID_DIR=/data/bigdata/hdfs/pids
YARN_PID_DIR=/data/bigdata/hdfs/pids
11、分发
[root@node1 sbin]# scp -rp /data/bigdata/src/hadoop-2.7.6 node2:/data/bigdata/src/
[root@node1 sbin]# scp -rp /data/bigdata/src/hadoop-2.7.6 node3:/data/bigdata/src/
[root@node1 sbin]# scp -rp /data/bigdata/src/hadoop-2.7.6 node4:/data/bigdata/src/
[root@node1 sbin]# scp -rp /data/bigdata/src/hadoop-2.7.6 node5:/data/bigdata/src/[root@node2 ~]# ln -s /data/bigdata/src/hadoop-2.7.6 /data/bigdata/hadoop
[root@node3 ~]# ln -s /data/bigdata/src/hadoop-2.7.6 /data/bigdata/hadoop
[root@node4 ~]# ln -s /data/bigdata/src/hadoop-2.7.6 /data/bigdata/hadoop
[root@node5 ~]# ln -s /data/bigdata/src/hadoop-2.7.6 /data/bigdata/hadoop
六、启动过程
1、启动zookeeper服务:下面两种方法选一
(1) 同时开启所有zookeeper节点
# node1节点
[root@node1 ~]# cd /data/bigdata/zookeeper/bin
[root@node1 conf]# zkServer.sh start# node2节点
[root@node2 ~]# cd /data/bigdata/zookeeper/bin
[root@node2 conf]# zkServer.sh start# node3节点
[root@node3 ~]# cd /data/bigdata/zookeeper/bin
[root@node3 conf]# zkServer.sh start# 相应进程(其它类似)
[root@node1 ~]# jps
23993 QuorumPeerMain
24063 Jps
[root@node1 ~]#
(2) 集群启动
由于zookeeper没有提供同时启动集群中所有节点的执行脚本,在生产中逐个节点启动稍微有些麻烦,自定义一个脚本用来启动集群中所有节点,如下:[root@node1 bigdata]# cat zookeeper_all_op.sh
#!/bin/bash
# start zookeeper
zookeeperHome=/data/bigdata/src/zookeeper-3.4.12
zookeeperArr=( "node1" "node2" "node3" )
for znode in ${zookeeperArr[@]}; dossh -p 22 -q root@$znode \"export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/binsource /etc/profile$zookeeperHome/bin/zkServer.sh $1"echo "$znode zookeeper $1 done"
done# 启动
[root@node1 bigdata]# ./zookeeper_all_op.sh start # 查看: leader为领导者(一台), follower为追随者;
[root@node1 bigdata]# ./zookeeper_all_op.sh status
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
node1 zookeeper status done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader
node2 zookeeper status done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
node3 zookeeper status done
[root@node1 bigdata]#
(3) 启动客户端脚本
[root@node1 bigdata]# ./zookeeper/bin/zkCli.sh -server node2:2181
Connecting to node2:2181
2018-06-13 17:28:21,115 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.12-e5259e437540f349646870ea94dc2658c4e44b3b, built on 03/27/2018 03:55 GMT
2018-06-13 17:28:21,119 [myid:] - INFO [main:Environment@100] - Client environment:host.name=node1
......
省略
......
2018-06-13 17:28:21,220 [myid:] - INFO [main-SendThread(node2:2181):ClientCnxn$SendThread@878] - Socket connection established to node2/192.168.1.102:2181, initiating session
2018-06-13 17:28:21,229 [myid:] - INFO [main-SendThread(node2:2181):ClientCnxn$SendThread@1302] - Session establishment complete on server node2/192.168.1.102:2181, sessionid = 0x20034776a7c000e, negotiated timeout = 30000WATCHER::WatchedEvent state:SyncConnected type:None path:null
[zk: node2:2181(CONNECTED) 0] help
ZooKeeper -server host:port cmd argsstat path [watch]set path data [version]ls path [watch]delquota [-n|-b] pathls2 path [watch]setAcl path aclsetquota -n|-b val pathhistory redo cmdnoprintwatches on|offdelete path [version]sync pathlistquota pathrmr pathget path [watch]create [-s] [-e] path data acladdauth scheme authquit getAcl pathclose connect host:port
[zk: node2:2181(CONNECTED) 1] quit
Quitting...
2018-06-13 17:28:37,984 [myid:] - INFO [main:ZooKeeper@687] - Session: 0x20034776a7c000e closed
2018-06-13 17:28:37,986 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@521] - EventThread shut down for session: 0x20034776a7c000e
[root@node1 bigdata]#
2、启动所有journalnode节点
# node1节点
[root@node1 ~]# cd /data/bigdata/hadoop/
[root@node1 hadoop]# ./sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-journalnode-node1.out
# 相应进程(其它类似)
[root@node1 ~]# jps
23993 QuorumPeerMain
24474 JournalNode # 新启动的进程
24910 Jps
[root@node1 ~]## journalnode我配了3个
# node2节点
[root@node2 ~]# cd /data/bigdata/hadoop/
[root@node2 hadoop]# ./sbin/hadoop-daemon.sh start journalnode# node3节点
[root@node3 ~]# cd /data/bigdata/hadoop/
[root@node3 hadoop]# ./sbin/hadoop-daemon.sh start journalnode
3、格式化namenode目录(主节点node1)
[root@node1 hadoop]# cd /data/bigdata/hadoop
[root@node1 hadoop]# ./bin/hdfs namenode -format18/06/04 14:24:03 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node1/192.168.1.101
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.6
..........................................
省略若干
...........................................
18/06/04 14:24:05 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/06/04 14:24:05 INFO util.ExitUtil: Exiting with status 0
18/06/04 14:24:05 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.1.101
************************************************************/
[root@node1 hadoop]#
4、启动当前格式化的namenode进程(主节点node1)
[root@node1 hadoop]# ./sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-namenode-node1.out
[root@node1 ~]# jps # # 相应进程
25155 Jps
23993 QuorumPeerMain
25050 NameNode # name节点
24474 JournalNode
[root@node1 ~]#
5、在没有格式化的NN上 执行同步命令(副节点node2)
[root@node2 hadoop]# ./bin/hdfs namenode -bootstrapStandby18/06/04 14:26:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node2/192.168.1.102
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.7.6
..........................................
省略若干
...........................................
************************************************************/
18/06/04 14:26:55 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/06/04 14:26:55 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
18/06/04 14:26:55 WARN common.Util: Path /data/bigdata/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
18/06/04 14:26:55 WARN common.Util: Path /data/bigdata/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
=====================================================
About to bootstrap Standby ID nn2 from:Nameservice ID: myclusterOther Namenode ID: nn1Other NN's HTTP address: http://node1:50070Other NN's IPC address: node1/192.168.1.101:8020Namespace ID: 736429223Block pool ID: BP-1022667957-192.168.1.101-1528093445721Cluster ID: CID-9d4854cd-7201-4e0d-9536-36e73195dc5aLayout version: -63isUpgradeFinalized: true
=====================================================
18/06/04 14:26:56 INFO common.Storage: Storage directory /data/bigdata/hdfs/name has been successfully formatted.
18/06/04 14:26:56 WARN common.Util: Path /data/bigdata/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
18/06/04 14:26:56 WARN common.Util: Path /data/bigdata/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
18/06/04 14:26:57 INFO namenode.TransferFsImage: Opening connection to http://node1:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:736429223:0:CID-9d4854cd-7201-4e0d-9536-36e73195dc5a
18/06/04 14:26:57 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
18/06/04 14:26:57 INFO namenode.TransferFsImage: Transfer took 0.00s at 0.00 KB/s
18/06/04 14:26:57 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 306 bytes.
18/06/04 14:26:57 INFO util.ExitUtil: Exiting with status 0
18/06/04 14:26:57 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node2/192.168.1.102
************************************************************/
# 如果不成功,直接把node1节点的/data/bigdata/hdfs/name目录复制过来,即可# 启动从节点
[root@node2 hadoop]# ./sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-namenode-node2.out
6、格式化ZKFC
格式化zkfc,让在zookeeper中生成ha节点,在master上执行如下命令,完成格式化:
[root@node1 hadoop]# ./bin/hdfs zkfc -formatZK
18/06/04 16:53:15 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at node1/192.168.1.101:8020
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Client environment:host.name=node1
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_162
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Client environment:java.home=/opt/jdk1.8.0_162/jre
..........................................
省略若干
...........................................
18/06/04 16:53:16 INFO ha.ActiveStandbyElector: Session connected.
18/06/04 16:53:16 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
18/06/04 16:53:16 INFO zookeeper.ZooKeeper: Session: 0x20034776a7c0000 closed
18/06/04 16:53:16 INFO zookeeper.ClientCnxn: EventThread shut down[root@node1 hadoop]# ./sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-zkfc-node1.out
[root@node1 hadoop]# jps
5443 DFSZKFailoverController # 新进程
4664 JournalNode
23993 QuorumPeerMain
5545 Jps
4988 NameNode
[root@node1 hadoop]## 另一个节点启动zkfc,有namenode运行的节点,都要启动ZKFC
[root@node2 hadoop]# ./sbin/hadoop-daemon.sh start zkfc
7、启动hdfs(datanode)
[root@node1 hadoop]# ./sbin/start-dfs.sh
Starting namenodes on [node1 node2]
node1: namenode running as process 25050. Stop it first.
node2: namenode running as process 30976. Stop it first.
node1: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node2.out
node5: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node5.out
node3: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node3.out
node4: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node4.out
Starting journal nodes [node1 node2 node3]
node1: journalnode running as process 24474. Stop it first.
node3: journalnode running as process 19893. Stop it first.
node2: journalnode running as process 29871. Stop it first.
Starting ZK Failover Controllers on NN hosts [node1 node2]
node1: starting zkfc, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-zkfc-node1.out
node2: starting zkfc, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-zkfc-node2.out
[root@node1 hadoop]# jps
25968 DataNode # 所有节点都有
23993 QuorumPeerMain
5443 DFSZKFailoverController
25050 NameNode
24474 JournalNode
26525 Jps
[root@node1 hadoop]#
8、启动yarn:
[root@node1 hadoop]# ./sbin/start-yarn.sh starting yarn daemons
starting resourcemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-resourcemanager-node1.out
node1: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node1.out
node2: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node2.out
node4: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node4.out
node3: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node3.out
node5: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node5.out
[root@node1 hadoop]# jps
25968 DataNode
23993 QuorumPeerMain
5443 DFSZKFailoverController
25050 NameNode
24474 JournalNode
27068 Jps
26894 NodeManager # 所有节点都有
[root@node1 hadoop]#
9、两台resourcemanager上启动resourcemanager
(1)单独启动
[root@node3 hadoop]# ./sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-resourcemanager-node3.out
[root@node4 hadoop]# ./sbin/yarn-daemon.sh start resourcemanager# 相应进程(其它类似)
[root@node3 ~]# jps
21088 NodeManager
21297 ResourceManager # 此进程
19459 QuorumPeerMain
19893 JournalNode
20714 DataNode
21535 Jps
[root@node3 ~]#
(2)集群启动
生产中一个hdfs集群会有两个ResourceManager节点,若逐个节点启动稍微有些麻烦,自定义一个脚本用来启动集群中所有ResourceManager节点,如下:
[root@node1 bigdata]# pwd
/data/bigdata
[root@node1 bigdata]# cat yarn_all_resourcemanager.sh
#!/bin/bash
# resourcemanager management
hadoop_yarn_daemon_home=/data/bigdata/hadoop/sbin/
yarn_resourcemanager_node=( "node3" "node4" )
for renode in ${yarn_resourcemanager_node[@]}; dossh -p 22 -q root@$znode "export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/binsource /etc/profilecd $hadoop_yarn_daemon_home/ && ./yarn-daemon.sh $1 resourcemanager"echo "$renode resourcemanager $1 done"
done
[root@node1 bigdata]# HDFS和yarn的web控制台默认监听端口分别为50070和8088。可以通过浏览放访问查看运行情况。
例:http://192.168.1.101:50070/http://192.168.1.103:8088/# 停止命令:不操作
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh# 如果一切正常,使用jps可以查看到正在运行的Hadoop服务,机器上的显示结果为:
[root@node1 hadoop]# jps
7312 Jps
1793 NameNode
2163 JournalNode
357 NodeManager
2696 QuorumPeerMain
14428 DFSZKFailoverController
1917 DataNode
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ |
10、验证HDFS的HA功能
在任意一台namenode机器上通过jps命令查找到namenode的进程号,然后通过kill -9的方式杀掉进程,观察另一个namenode节点是否会从状态standby变成active状态。
[root@node1 bigdata]# jps
16704 JournalNode
16288 NameNode
16433 DataNode
23993 QuorumPeerMain
17241 NodeManager
18621 Jps
16942 DFSZKFailoverController
[root@node1 bigdata]# kill -9 16288
然后观察原来是standby状态的namenode机器的zkfc日志,若最后一行出现如下日志,则表示切换成功:
2018-05-31 16:14:41,114 INFOorg.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNodeat hd0/192.168.1.102:53310 to active state
这时再通过命令启动被kill掉的namenode进程
[root@node1 bigdata]# ./sbin/hadoop-daemon.sh start namenode
对应进程的zkfc最后一行日志如下:
2018-05-31 16:14:55,683 INFOorg.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNodeat hd2/192.168.1.101:53310 to standby state
可以在两台namenode机器之间来回kill掉namenode进程以检查HDFS的HA配置!
七、scala
1、配置前准备
scala运行在jvm虚拟机,需要配置jdk;
2、解压
[root@node1 sbin]# tar -zxvf /data/tools/scala-2.11.12.tgz -C /data/bigdata/src
[root@node1 sbin]# ln -s /data/bigdata/src/scala-2.11.12 /data/bigdata/scala# 添加环境变量
[root@node1 ~]# echo -e "\n# scala\nexport scala_HOME=/data/bigdata/scala\nexport PATH=\$scala_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node1 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH
[root@node1 ~]# source /etc/profile
3、查看scala版本
[root@node1 ~]# scala -version
Scala code runner version 2.11.12 -- Copyright 2002-2016, LAMP/EPFL
4、运行scala命令
[root@node1 ~]# scala
Welcome to Scala 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_162).
Type in expressions for evaluation. Or try :help.scala> 1+1
res0: Int = 2scala>
如果以上两步没问题,表示scala已安装和配置成功。
八、 安装spark
官方文档
1、解压spark
[root@node1 conf]# tar -zxvf /data/tools/spark-2.1.2-bin-hadoop2.7.tgz -C /data/bigdata/src/
[root@node1 conf]# ln -s /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 /data/bigdata/spark# 添加环境变量
[root@node1 ~]# echo -e "\n# spark\nexport SPARK_HOME=/data/bigdata/spark\nexport PATH=\$SPARK_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node1 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH
[root@node1 ~]# source /etc/profile# spark
export SPARK_HOME=/data/bigdata/spark
export PATH=$SPARK_HOME/bin:$PATH
[root@node1 ~]#
2、配置spark-env.sh
[root@node1 conf]# cd /data/bigdata/spark/conf/
[root@node1 conf]# cp spark-env.sh{.template,} # 添加:
[root@node1 conf]# vim spark-env.sh
export SPARK_LOCAL_IP="192.168.1.101" # 从节点改为自己的IP(或127.0.0.1 ),或者注掉
export SPARK_MASTER_IP="192.168.1.101"
export JAVA_HOME=/opt/java
export SPARK_PID_DIR=/data/bigdata/hdfs/pids
export SPARK_LOCAL_DIRS= /data/bigdata/sparktmp
export PYSPARK_PYTHON=/usr/local/bin/python3 # 当用python3开发时,配上python3的绝对路径。# 设置内存,本节点可以调用的内存
export SPARK_WORKER_MEMORY=58g
export SPARK_MASTER_PORT=7077
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://mycluster/directory"
# 限制程序申请资源最大核数,本节点可以调用的cpu核数
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=16"
export SPARK_SSH_OPTS="-p 22 -o StrictHostKeyChecking=no $SPARK_SSH_OPTS"
3、配置spark-defaults.conf
[root@node1 conf]# cp spark-defaults.conf{.template,}
[root@node1 conf]# vim spark-defaults.conf
#添加
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/directory# 使用Python3+开发时配置;
park.executorEnv.PYTHONHASHSEED=0
# 新建对应目录
[root@node1 conf]# mkdir -pv /data/bigdata/sparktmp
[root@node1 conf]# hdfs dfs -mkdir /directory
说明:spark.executorEnv.PYTHONHASHSEED=0配置:
如果你使用的是Python3+,并且在Spark集群上使用distinct(),reduceByKey(),和join()这几个函数时,就会触发下面的异常:
Exception: Randomness of hash of string should be disabled via PYTHONHASHSEED
python创建遍历对象对象时会对每个对象进行随机哈希创建索引。然而在一个集群上,每个节点计算时对某一个变量创建的索引值不同,会导致数据索引冲突。因此需要设置PYTHONHASHSEED来固定随机种子,保证索引一致。参见:
Spark集群配置(4):其他填坑杂项
4、配置slaves
[root@node1 conf]# cp slaves{.template,}
[root@node1 conf]# vim slaves
node1
node2
node3
node4
node5
5、分发
[root@node1 conf]# scp -rp /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 node2:/data/bigdata/src/
[root@node1 conf]# scp -rp /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 node3:/data/bigdata/src/
[root@node1 conf]# scp -rp /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 node4:/data/bigdata/src/
[root@node1 conf]# scp -rp /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 node5:/data/bigdata/src/# 分发创建的目录
[root@node1 bigdata]# scp -rp /data/bigdata/{hdfs,sparktmp,tmp} node2:/data/bigdata/
[root@node1 bigdata]# scp -rp /data/bigdata/{hdfs,sparktmp,tmp} node3:/data/bigdata/
[root@node1 bigdata]# scp -rp /data/bigdata/{hdfs,sparktmp,tmp} node4:/data/bigdata/
[root@node1 bigdata]# scp -rp /data/bigdata/{hdfs,sparktmp,tmp} node5:/data/bigdata/# 创建软连接
[root@node2 ~]# ln -s /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 /data/bigdata/spark
[root@node3 ~]# ln -s /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 /data/bigdata/spark
[root@node4 ~]# ln -s /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 /data/bigdata/spark
[root@node5 ~]# ln -s /data/bigdata/src/spark-2.1.2-bin-hadoop2.7 /data/bigdata/spark# 修改$SPARK_HOME/conf/spark-env.sh中的SPARK_LOCAL_IP参数
[root@node2 ~]# vim $SPARK_HOME/conf/spark-env.sh
export SPARK_LOCAL_IP="192.168.1.102"
[root@node3 ~]# vim $SPARK_HOME/conf/spark-env.sh
export SPARK_LOCAL_IP="192.168.1.103"
[root@node4 ~]# vim $SPARK_HOME/conf/spark-env.sh
export SPARK_LOCAL_IP="192.168.1.104"
[root@node5 ~]# vim $SPARK_HOME/conf/spark-env.sh
export SPARK_LOCAL_IP="192.168.1.105"
6、启动spark
[root@node1 bin]# cd /data/bigdata/spark/sbin
[root@node1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-node1.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node1.out
node5: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node5.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node3.out
node4: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node4.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.out
[root@node1 sbin]# jps
5443 DFSZKFailoverController
5684 Master # spark的master
1092 HRegionServer
5846 Worker # spark进程
904 HMaster
4664 JournalNode
23993 QuorumPeerMain
6266 Jps
7227 NodeManager
4988 NameNode
6495 DataNode
web界面:http://192.168.1.101:8080/
[root@node1 sbin]# ./start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-node1.out
[root@node1 sbin]# jps
5443 DFSZKFailoverController
5684 Master # spark的master
1092 HRegionServer
5846 Worker # spark进程
904 HMaster
4664 JournalNode
29366 HistoryServer # spark 保存历史日志记录的
23993 QuorumPeerMain
6266 Jps
7227 NodeManager
4988 NameNode
6495 DataNode
访问WEBUI: http://192.168.1.101:18080/
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ | |||
| Master | ✔ | ||||
| Worker | ✔ | ✔ | ✔ | ✔ | ✔ |
| HistoryServer | ✔ |
九、 安装hbase
Master和Hadoop的NameNode进程运行在同一台主机上,与DataNode通信
以读写HDFS的数据。RegionServer跟Hadoop的DataNode运行在同一台主机上。
参考:
官方文档
hbase 数据库简介安装与常用命令的使用
1、解压hbase
[root@node1 sbin]# tar -zxvf /data/tools/hbase-1.2.6-bin.tar.gz -C /data/bigdata/src
[root@node1 sbin]# ln -s /data/bigdata/src/hbase-1.2.6 /data/bigdata/hbase# 添加环境变量
[root@node1 ~]# echo -e "\n# hbase\nexport HBASE_HOME=/data/bigdata/hbase\nexport PATH=\$HBASE_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node1 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH# spark
export SPARK_HOME=/data/bigdata/spark
export PATH=$SPARK_HOME/bin:$PATH# hbase
export HBASE_HOME=/data/bigdata/hbase
export PATH=$HBASE_HOME/bin:$PATH
[root@node1 ~]#
2、修改$HBASE_HOME/conf/hbase-env.sh,添加
[root@node1 sbin]# cd /data/bigdata/hbase/conf
[root@node1 conf]# vim hbase-env.sh
export JAVA_HOME=/opt/java
export HBASE_HOME=/data/bigdata/hbase
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native/
export HBASE_LIBRARY_PATH=$HBASE_LIBRARY_PATH:$HBASE_HOME/lib/native/
# 设置到Hadoop的etc/hadoop目录是用来引导Hbase找到Hadoop,也就是说hbase和hadoop进行关联【必须设置,否则hmaster起不来】
export HBASE_CLASSPATH=$HADOOP_HOME/etc/hadoop
export HBASE_MANAGES_ZK=false #不启用hbase自带的zookeeper
export HBASE_PID_DIR=/data/bigdata/hdfs/pids
export HBASE_SSH_OPTS="-o ConnectTimeout=1 -p 22" # ssh端口;# jdk1.8及以上版本注掉下面两行
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
3、修改regionservers文件
[root@node1 conf]# vim regionservers
node1
node2
node3
4、修改hbase-site.xml文件
[root@node1 conf]# vim hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://mycluster/hbase</value></property><property><name>hbase.zookeeper.quorum</name><value>node1,node2,node3</value><description>指定集群zookeeper主机名</description></property> <property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><property><name>hbase.master.info.port</name><value>60010</value></property><property><name>hbase.cluster.distributed</name><value>true</value><description>多台hbase开启此参数</description></property>
</configuration>
5、分发
[root@node1 conf]# scp -rp /data/bigdata/src/hbase-1.2.6 node2:/data/bigdata/src/
[root@node1 conf]# scp -rp /data/bigdata/src/hbase-1.2.6 node3:/data/bigdata/src/# 创建软连接
[root@node2 ~]# ln -s /data/bigdata/src/hbase-1.2.6 /data/bigdata/hbase
[root@node3 ~]# ln -s /data/bigdata/src/hbase-1.2.6 /data/bigdata/hbase
6、启动hbase
[root@node1 hadoop]# cd /data/bigdata/hbase/bin
[root@node1 bin]# ./start-hbase.sh
[root@node1 bin]# jps
5443 DFSZKFailoverController
1092 HRegionServer # hbase进程
904 HMaster # hbase主节点
4664 JournalNode
23993 QuorumPeerMain
14730 Master
7227 NodeManager
4988 NameNode
14877 Worker
1917 Jps
6495 DataNode
[root@node1 bin]#
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ | |||
| Master | ✔ | ||||
| Worker | ✔ | ✔ | ✔ | ✔ | ✔ |
| HistoryServer | ✔ | ||||
| HMaster | ✔ | ||||
| HRegionServer | ✔ | ✔ | ✔ |
Hbase web页面http://192.168.1.101:16030
Hbase Master URL:http://192.168.1.101:60010
# 测试
[root@node1 bin]# ./hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/bigdata/src/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/bigdata/src/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017hbase(main):001:0> list # 输入命令list
TABLE
0 row(s) in 0.2670 seconds=> []
hbase(main):002:0> quit
[root@node1 bin]#
十、kafka
官方文档
kafka实战最佳经验
1、解压创建环境变量
[root@node4 conf]# tar -zxvf /data/tools/kafka_2.11-1.1.0.tgz -C /data/bigdata/src/
[root@node4 conf]# ln -s /data/bigdata/src/kafka_2.11-1.1.0 /data/bigdata/kafka# 添加环境变量
[root@node4 ~]# echo -e "\n# kafka\nexport KAFKA_HOME=/data/bigdata/kafka\nexport PATH=\$KAFKA_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node4 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# hbase
export HBASE_HOME=/data/bigdata/hbase
export PATH=$HBASE_HOME/bin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH# spark
export SPARK_HOME=/data/bigdata/spark
export PATH=$SPARK_HOME/bin:$PATH# kafka
export KAFKA_HOME=/data/bigdata/kafka
export PATH=$KAFKA_HOME/bin:$PATH# 生效
[root@node4 conf]# source /etc/profile
2、修改server.properties配置文件:
[root@node4 ~]# cd /data/bigdata/kafka/config/ # 进入conf目录
[root@node4 conf]# cp server.properties{,.bak} # 备份配置文件
[root@node4 conf]# vim server.properties
broker.id=1
listeners=PLAINTEXT://node4:9092
advertised.listeners=PLAINTEXT://node4:9092
log.dirs=/data/bigdata/kafka/logs
zookeeper.connect=node1:2181,node2:2181,node3:2181[root@node4 conf]# mkdir -p /data/bigdata/kafka/logs
3、分发
[root@node4 conf]# scp -rp /data/bigdata/src/kafka_2.11-1.1.0 node5: /data/bigdata/src/# 子节点
[root@node5 ~]# ln -s /data/bigdata/src/kafka_2.11-1.1.0 /data/bigdata/kafka
[root@node5 ~]# mkdir -p /data/bigdata/kafka/logs# 修改每个server.properties文件中的broker.id
[root@node5 ~]# cd /data/bigdata/kafka/
[root@node5 kafka]# vim ./config/server.properties
broker.id=2
listeners=PLAINTEXT://node5:9092
advertised.listeners=PLAINTEXT://node5:9092# 查看
[root@node1 conf]# ansible kafka -m shell -a '$(which egrep) --color=auto "^broker.id|^listeners|^advertised.listeners" ${KAFKA_HOME}/config/server.properties'
4、启动
[root@node4 kafka]# ./bin/kafka-server-start.sh config/server.properties # 单个节点前台运行
[2018-06-05 13:32:35,323] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
[2018-06-05 13:32:35,672] INFO starting (kafka.server.KafkaServer)
[2018-06-05 13:32:35,673] INFO Connecting to zookeeper on node1:2181,node2:2181,node3:2181 (kafka.server.KafkaServer)
[2018-06-05 13:32:35,692] INFO [ZooKeeperClient] Initializing a new session to node1:2181,node2:2181,node3:2181. (kafka.zookeeper.ZooKeeperClient)
[2018-06-05 13:32:35,698] INFO Client environment:zookeeper.version=3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
..........................................
省略若干
...........................................
[2018-06-05 13:33:38,920] INFO Terminating process due to signal SIGINT (kafka.Kafka$)
[2018-06-05 13:33:39,168] INFO [ThrottledRequestReaper-Produce]: Stopped (kafka.server.ClientQuotaManager$ThrottledRequestReaper)
[2018-06-05 13:33:39,168] INFO [ThrottledRequestReaper-Produce]: Shutdown completed (kafka.server.ClientQuotaManager$ThrottledRequestReaper)
[2018-06-05 13:33:39,168] INFO [ThrottledRequestReaper-Request]: Shutting down (kafka.server.ClientQuotaManager$ThrottledRequestReaper)
[2018-06-05 13:33:39,168] INFO [ThrottledRequestReaper-Request]: Stopped (kafka.server.ClientQuotaManager$ThrottledRequestReaper)
[2018-06-05 13:33:39,168] INFO [ThrottledRequestReaper-Request]: Shutdown completed (kafka.server.ClientQuotaManager$ThrottledRequestReaper)
[2018-06-05 13:33:39,169] INFO [SocketServer brokerId=1] Shutting down socket server (kafka.network.SocketServer)
[2018-06-05 13:33:39,193] INFO [SocketServer brokerId=1] Shutdown completed (kafka.network.SocketServer)
[2018-06-05 13:33:39,199] INFO [KafkaServer id=1] shut down completed (kafka.server.KafkaServer)[root@node4 kafka]# ./bin/kafka-server-start.sh -daemon config/server.properties # 后台启动单个节点,其它kafka也要启动,进程名为:Kafka
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ | |||
| HMaster | ✔ | ||||
| HRegionServer | ✔ | ✔ | ✔ | ||
| HistoryServer | ✔ | ||||
| Master | ✔ | ||||
| Worker | ✔ | ✔ | ✔ | ✔ | ✔ |
| Kafka | ✔ | ✔ |
Kafka并没有提供同时启动集群中所有节点的执行脚本,在生产中一个Kafka集群往往会有多个节点,若逐个节点启动稍微有些麻烦,自定义一个脚本用来启动集群中所有节点,如下:
[root@node1 bigdata]# cat kafka_cluster_start.sh
#!/bin/bashbrokers="node4 node5"
KAFKA_HOME="/data/bigdata/kafka"for broker in $brokersdossh $broker -C "source /etc/profile; cd ${KAFKA_HOME}/bin && ./kafka-server-start.sh -daemon ../config/server.properties"if [ $? -eq 0 ]; thenecho "INFO:[${broker}] Start successfully "fi
done
[root@node1 bigdata]#
5、测试
创建主题:(指明要连接的zookeeper)例如主题名称为:TestTopic
[root@node4 kafka]# ./bin/kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --replication-factor 1 --partitions 1 --topic TestTopic
Created topic "TestTopic". # 表示创建成功
查看主题:
[root@node4 kafka]# ./bin/kafka-topics.sh --list --zookeeper node1:2181,node2:2181,node3:2181
TestTopic # 可以看到所有已创建的主题
任选一台,创建生产者:(kafka集群用户)
[root@node4 kafka]# ./bin/kafka-console-producer.sh --broker-list node4:9092,node5:9092 --topic TestTopic
>hi
>hello 1
>hello 2
>
另一台,创建消费者
[root@node5 kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server node4:9092,node5:9092 --from-beginning --topic TestTopic
hi
hello 1
hello 2
生产者输入一些数据,看消费者是否显示生产者所输入的数据。
6、关闭
[root@node4 kafka]# ./bin/kafka-server-stop.sh # 关闭,其它kafka也要关闭,
有时候不管用,显示“No kafka server to stop”,
失败的原因是kafka-server-stop.sh脚本里的ps ax | grep -i 'kafka.Kafka' | grep Java | grep -v grep | awk '{print $1}'命令在我所使用的操作系统中并不能得到Kafka进程的PID:
因此这里将kafka-server-stop.sh脚本查找PID的命令修改如下:#PIDS=$(ps ax | grep -i 'kafka\.Kafka' | grep java | grep -v grep | awk '{print $1}') # 注掉,改为下面命令
PIDS=$(jps | grep -i 'Kafka' |awk '{print $1}')
Kafka也同样没有提供关闭集群操作的脚本。这里我提供一个用来关闭Kafka集群的脚本(可以放在任意一条节点上):
[root@node1 bigdata]# cat kafka_cluster_stop.sh
#!/bin/bashbrokers="node4 node5"
KAFKA_HOME="/data/bigdata/kafka"for broker in $brokersdossh $broker -C "cd ${KAFKA_HOME}/bin && ./kafka-server-stop.sh"if [ $? -eq 0 ]; thenecho "INFO:[${broker}] shut down completed "fidone
[root@node1 bigdata]# chmod +x kafka-cluster-stop.sh
十一、hive
官方文档
1、安装mysql数据库
参考:https://blog.51cto.com/moerjinrong/2092614
# 新建hive用户及metastore库
root@node2 14:37: [(none)]> grant all privileges on *.* to 'hive'@'192.168.1.%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)root@node2 15:14: [(none)]> create database metastore; # 待定
Query OK, 1 row affected (0.01 sec)
2、解压添加环境变量
[root@node2 ~]# tar -zxvf /data/tools/apache-hive-2.3.3-bin.tar.gz -C /data/bigdata/src/
[root@node2 ~]# ln -s /data/bigdata/src/apache-hive-2.3.3-bin /data/bigdata/hive# 添加环境变量
[root@node2 ~]# echo -e "\n# hive\nexport HIVE_HOME=/data/bigdata/hive\nexport PATH=\$HIVE_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node2 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# hbase
export HBASE_HOME=/data/bigdata/hbase
export PATH=$HBASE_HOME/bin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH# spark
export SPARK_HOME=/data/bigdata/spark
export PATH=$SPARK_HOME/bin:$PATH# kafka
export KAFKA_HOME=/data/bigdata/kafka
export PATH=$KAFKA_HOME/bin:$PATH# hive
export HIVE_HOME=/data/bigdata/hive
export PATH=$HIVE_HOME/bin:$PATH"# 生效
[root@node2 ~]# source /etc/profile
3、hdfs上新建目录
在hdfs中新建目录/user/hive/warehouse
首先启动hadoop任务
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hive
hdfs dfs -mkdir /user/hive/warehousehadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse# 将mysql的驱动jar包mysql-connector-java-5.1.46.jar拷入hive的lib目录下面,没有就下载:
wget -P $HIVE_HOME/lib http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.46/mysql-connector-java-5.1.46.jar
4、修改server.properties配置文件:
[root@node2 ~]# cd /data/bigdata/hive/conf/
[root@node2 conf]# cp hive-default.xml.template hive-site.xml
[root@node2 conf]# vim hive-site.xml
# 修改下列属性值(通过/指令寻找,如果第一个定位不正确,n寻找下一个)
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.1.102:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> # mysql没有开启ssl<description>JDBC connect string for a JDBC metastore;'?'符号是在URL后通过get方法传递参数的起始标志,多个参数之间可用'&'符号连接,因为这些字符对于HTML有特殊意义,所以在Java中要用到转义字符使用它,而&在HTML中就会被转义为'&'符号,用于参数连接。</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>Username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property><property><name>hive.metastore.warehouse.dir</name><value>/data/bigdata/hive/warehouse</value></property><property><name>hive.metastore.local</name><value>true</value></property><property><name>hive.exec.local.scratchdir</name><value>/data/bigdata/hive/tmp</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.downloaded.resources.dir</name><value>/data/bigdata/hive/tmp/resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>hive.querylog.location</name><value>/data/bigdata/hive/tmp</value><description>Location of Hive run time structured log file</description></property><property><name>hive.server2.logging.operation.log.location</name><value>/data/bigdata/hive/tmp/operation_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property>
注意:由于HTML格式问题,上面jdbc的URL中的&改为照片中红色下划线的符号
# 创建指定目录
[root@node2 conf]# mkdir -pv /data/bigdata/hive/{tmp/{operation_logs,resources},warehouse}
5、初始化并运行
# 使用schematool 初始化metastore的schema:
[root@node2 conf]# schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/bigdata/src/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/bigdata/src/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://127.0.0.1:3306/metastore?useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
[root@node2 conf]# # 运行hive
[root@node2 conf]# hive # 对应RunJar进程
hive> show databases;
OK
default
Time taken: 1.881 seconds, Fetched: 1 row(s)
hive> use default;
OK
Time taken: 0.081 seconds
hive> create table kylin_test(test_count int);
OK
Time taken: 2.9 seconds
hive> show tables;
OK
Time taken: 0.151 seconds, Fetched: 1 row(s)
hive> quit;
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ | |||
| HMaster | ✔ | ||||
| HRegionServer | ✔ | ✔ | ✔ | ||
| HistoryServer | ✔ | ||||
| Master | ✔ | ||||
| Worker | ✔ | ✔ | ✔ | ✔ | ✔ |
| Kafka | ✔ | ✔ | |||
| RunJar(# 启动hive时才有) | ✔ |
十二、kylin
官方文档
1、安装前准备
安装kylin前确保:hadoop 2.4+、hbase 0.13+、hive 0.98+,1.*已经安装并启动。
Hive需要启动metastore和hiveserver2。
Apache Kylin同样可以使用集群部署,但使用集群部署并不能增加计算速度
因为计算过程使用MapReduce引擎,与Kylin自身无关,而是主要为查询提供负载均衡。本次采用单节点。
2、解压并创建环境变量
[root@node2 ~]# tar zxvf /data/tools/apache-kylin-2.3.1-hbase1x-bin.tar.gz -C /data/bigdata/src/
[root@node2 ~]# ln -s /data/bigdata/src/apache-kylin-2.3.1-bin/ /data/bigdata/kylin# 添加环境变量
[root@node2 ~]# echo -e "\n# kylin\nexport KYLIN_HOME=/data/bigdata/kylin\nexport PATH=\$KYLIN_HOME/bin:\$PATH" >> /etc/profile.d/bigdata_path.sh
[root@node2 ~]# cat /etc/profile.d/bigdata_path.sh
# zookeeper
export ZOOKEEPER_HOME=/data/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH# hadoop
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# hbase
export HBASE_HOME=/data/bigdata/hbase
export PATH=$HBASE_HOME/bin:$PATH# scala
export scala_HOME=/data/bigdata/scala
export PATH=$scala_HOME/bin:$PATH# spark
export SPARK_HOME=/data/bigdata/spark
export PATH=$SPARK_HOME/bin:$PATH# kafka
export KAFKA_HOME=/data/bigdata/kafka
export PATH=$KAFKA_HOME/bin:$PATH# kylin
export KYLIN_HOME=/data/bigdata/kylin
export PATH=$KYLIN_HOME/bin:$PATH"# 生效
[root@node2 ~]# source /etc/profile
3、复制hive的相关jar到kylin
将hive安装目录lib目录中的所有jar包复制到kylin安装目录下的lib目录中。
[root@node2 ~]# cp -a /data/bigdata/hive/lib/* /data/bigdata/kylin/lib/
4、配置Kylin使用的Hive数据库:
[root@node2 ~]# cd /data/bigdata/kylin/conf
[root@node2 conf]# vim kylin.properties
kylin.server.cluster-servers=node2:7070 # kylin集群设置,修改主机名或ip,端口
kylin.job.jar=$KYLIN_HOME/lib/kylin-job-2.3.1.jar # 修改jar包版本及路径
kylin.coprocessor.local.jar=$KYLIN_HOME/lib/kylin-coprocessor-2.3.1.jar # 修改jar包版本及路径# List of web servers in use, this enables one web server instance to sync up with other servers
kylin.rest.servers=node2:7070## 配置Kylin使用的Hive数据库,这里配置在Hive中使用的schema,改为当前用户
kylin.job.hive.database.for.intermediatetable=root
5、如果没有启动https,请关闭
[root@node2 ~]# cd /data/bigdata/kylin/tomcat/conf
[root@node2 conf]# cp -a server.xml{,_$(date +%F)}
[root@node2 conf]# vim server.xml85 maxThreads="150" SSLEnabled="true" scheme="https" secure="true"
改为:
85 maxThreads="150" SSLEnabled="false" scheme="https" secure="false"
如果不关闭,会报如下错误
SEVERE: Failed to load keystore type JKS with path conf/.keystore due to /data/bigdata/kylin/tomcat/conf/.keystore (No such file or directory)
java.io.FileNotFoundException: /data/bigdata/kylin/tomcat/conf/.keystore (No such file or directory)
6、修改$KYLIN_HOME/bin/kylin.sh
[root@node2 conf]# vim ../bin/kylin.sh
export KYLIN_HOME=/data/bigdata/kylin
export CATALINA_HOME=/data/bigdata/kylin/tomcat
export PATH=$CATALINA_HOME/bin:$PATHexport HCAT_HOME=$HIVE_HOME/hcatalog
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.3.3.jar
export HBASE_CLASSPATH_PREFIX=$CATALINA_HOME/bin/bootstrap.jar:$CATALINA_HOME/bin/tomcatjuli.jar:$CATALINA_HOME/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX#使用HDFS超级用户在HDFS上为Kylin创建工作目录,并赋权给服务器登录名
#[root@node2 conf]# hdfs dfs -mkdir /kylin
#[root@node2 conf]# hdfs dfs -chown -R root:root /kylin
7、检查kylin依赖
进入bin目录下分别执行
[root@node2 bin]# cd $KYLIN_HOME/bin
[root@node2 bin]# ./check-env.sh
Retrieving hadoop conf dir...
KYLIN_HOME is set to /data/bigdata/kylin[root@node2 bin]# ./find-hive-dependency.sh
Retrieving hive dependency...[root@node2 bin]# ./find-hbase-dependency.sh
Retrieving hbase dependency...
8、启动kylin服务
在kylin安装根目录下执行
[root@node2 bin]# ./kylin.sh start
Retrieving hadoop conf dir...
KYLIN_HOME is set to /data/bigdata/kylin
Retrieving hive dependency...
Retrieving hbase dependency...
Retrieving hadoop conf dir...
Retrieving kafka dependency...
Retrieving Spark dependency...
Start to check whether we need to migrate acl tables
..........................................
省略若干
...........................................
2018-06-05 17:12:10,111 INFO [Thread-6] zookeeper.ZooKeeper:684 : Session: 0x300346e6b9e000d closed
2018-06-05 17:12:10,111 INFO [main-EventThread] zookeeper.ClientCnxn:512 : EventThread shut down
2018-06-05 17:12:10,210 INFO [close-hbase-conn] client.ConnectionManager$HConnectionImplementation:2068 : Closing master protocol: MasterService
2018-06-05 17:12:10,211 INFO [close-hbase-conn] client.ConnectionManager$HConnectionImplementation:1676 : Closing zookeeper sessionid=0x20034776a7c0004
2018-06-05 17:12:10,214 INFO [close-hbase-conn] zookeeper.ZooKeeper:684 : Session: 0x20034776a7c0004 closed
2018-06-05 17:12:10,214 INFO [main-EventThread] zookeeper.ClientCnxn:512 : EventThread shut downA new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /data/bigdata/kylin/logs/kylin.log
Web UI is at http://<hostname>:7070/kylin[root@node2 bin]#
到目前为止所启动的进程:
| \ | node1 | node2 | node3 | node4 | node5 |
|---|---|---|---|---|---|
| JDK | ✔ | ✔ | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ | ||
| JournalNode | ✔ | ✔ | ✔ | ||
| NameNode | ✔ | ✔ | |||
| DFSZKFailoverController | ✔ | ✔ | |||
| DataNode | ✔ | ✔ | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ✔ | |||
| HMaster | ✔ | ||||
| HRegionServer | ✔ | ✔ | ✔ | ||
| HistoryServer | ✔ | ||||
| Master | ✔ | ||||
| Worker | ✔ | ✔ | ✔ | ✔ | ✔ |
| Kafka | ✔ | ✔ | |||
| RunJar(# 启动hive时才有) | ✔ | ||||
| RunJar(# kylin进程) | ✔ | ✔ |
服务启动后,浏览器访问地址:http://IP:7070/kylin/
用户名:ADMIN
密码:KYLIN
9、配置hive数据源
1.配置数据源
(1)依次选择 Model -> Data Source -> Load Hive Table
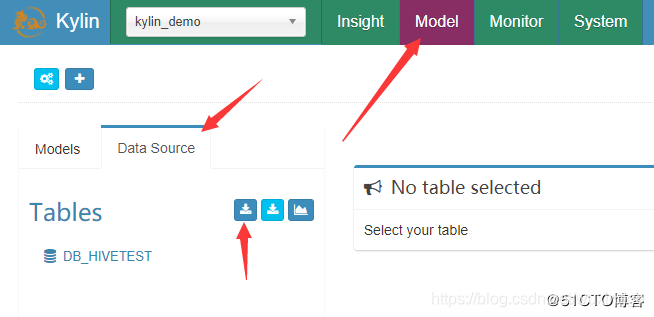
(2)输入 hive 中数据库的表名格式为: 数据库名.数据表名
如:db_hiveTest.student ,然后点击Sync即可。
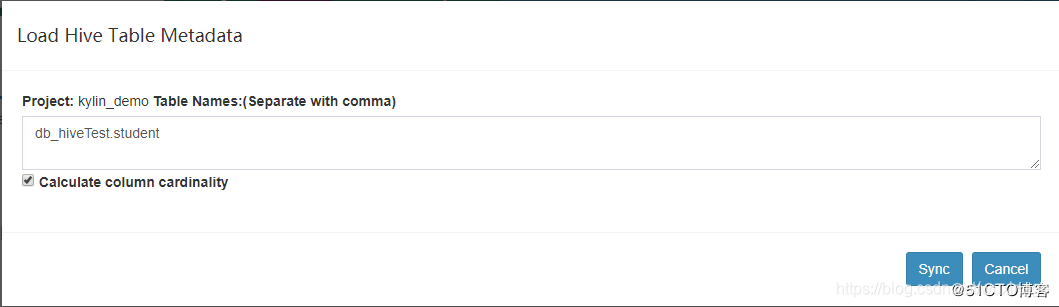
添加成功后,效果如下图:

10、常见错误
1、界面无法同步hive表元数据
解决方法,在kylin安装目录下:
执行命令:vim ./bin/kylin.sh 需要对此脚本做以下修改:
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX# 在路径中添加$hive_dependency。
十三、记一次日常启动
1、zookeeper:
[root@node1 ~]# cd /data/bigdata/
[root@node1 bigdata]# ./zookeeper_all_op.sh start
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
node1 zookeeper start done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
node2 zookeeper start done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
node3 zookeeper start done[root@node1 bigdata]# ./zookeeper_all_op.sh status
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
node1 zookeeper status done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader
node2 zookeeper status done
ZooKeeper JMX enabled by default
Using config: /data/bigdata/src/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
node3 zookeeper status done
可以看到一个leader,其它为follower就可以*
2、hadoop:
[root@node1 bigdata]# cd /data/bigdata/src/hadoop-2.7.6/sbin/
[root@node1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node1 node2]
node1: starting namenode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-namenode-node1.out
node2: starting namenode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-namenode-node2.out
node1: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node2.out
node5: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node5.out
node3: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node3.out
node4: starting datanode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-datanode-node4.out
Starting journal nodes [node1 node2 node3]
node1: starting journalnode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-journalnode-node1.out
node2: starting journalnode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-journalnode-node2.out
node3: starting journalnode, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-journalnode-node3.out
Starting ZK Failover Controllers on NN hosts [node1 node2]
node2: starting zkfc, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to /data/bigdata/src/hadoop-2.7.6/logs/hadoop-root-zkfc-node1.out
starting yarn daemons
starting resourcemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-resourcemanager-node1.out
node1: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node1.out
node3: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node3.out
node5: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node5.out
node2: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node2.out
node4: starting nodemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-nodemanager-node4.out
[root@node1 sbin]# jps
16418 QuorumPeerMain
18196 Jps
17047 NameNode
17194 DataNode
17709 DFSZKFailoverController
17469 JournalNode
17999 NodeManager
[root@node1 sbin]#
没有启动的去相应服务器下单独启动
resourcemanager:需单独启动
[root@node3 sbin]# ./yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-resourcemanager-node3.out
[root@node3 sbin]# jps
15968 Jps
14264 QuorumPeerMain
14872 NodeManager
14634 DataNode
15723 ResourceManager
14749 JournalNode
[root@node3 sbin]# [root@node4 sbin]# ./yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /data/bigdata/src/hadoop-2.7.6/logs/yarn-root-resourcemanager-node4.out
[root@node4 sbin]# jps
2995 NodeManager
4004 ResourceManager
4091 Jps
2813 DataNode
[root@node4 sbin]#
3、spark
[root@node1 sbin]# cd /data/bigdata/src/spark-2.1.2-bin-hadoop2.7/sbin/
[root@node1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-node1.out
node5: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node5.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node1.out
node4: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node4.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node3.out
[root@node1 sbin]# ./start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /data/bigdata/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-node1.out
[root@node1 sbin]#
4、hbase
[root@node1 ~]# cd /data/bigdata/src/hbase-1.2.6/bin/
[root@node1 bin]# ./start-hbase.sh
starting master, logging to /data/bigdata/hbase/logs/hbase-root-master-node1.out
node3: starting regionserver, logging to /data/bigdata/hbase/logs/hbase-root-regionserver-node3.out
node2: starting regionserver, logging to /data/bigdata/hbase/logs/hbase-root-regionserver-node2.out
node1: starting regionserver, logging to /data/bigdata/hbase/logs/hbase-root-regionserver-node1.out
[root@node1 bin]#
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 基于腾讯云服务器部署微信小程序后台服务(Python+Django)
一、部署前准备 1. 购买云主机 开发的微信小程序应用带后台服务的,要考虑购买云主机; 2. 域名申请、解析、备案 A. 域名申请 购买域名,最好是云主机在哪里买,域名就在哪里买,不然要域名转入; B. 域名解析 购买的云主机会有一个公网IP,通过将域名与ip地址绑定,可以实现…...
2024/5/5 7:38:06 - •CachedThreadPool:可缓存的线程池
线程池通过建立池可以有效的利用系统资源,节约系统性能。Java 中的线程池就是一种非常好的实现,从 JDK1.5 开始 Java 提供了一个线程工厂 Executors 用来生成线程池,通过 Executors 可以方便的生成不同类型的线程池。线程池的优点降低资源消耗。线程的开启和销毁会消耗资源,…...
2024/4/24 14:35:27 - Response笔记
笔记内容:HTTP协议:响应消息Response对象ServletContext对象 HTTP协议:请求消息:客户端发送给服务器端的数据数据格式:请求行 请求头 请求空行 请求体响应消息:服务器端发送给客户端的数据数据格式:响应行组成:协议/版本 响应状态码 状态码描述 响应状态码:服务器告诉…...
2024/4/24 14:35:27 - leetcode一周汇总(1)
本周心得vector中,字符串的sort()排序问题(按顺序以字母表比较,前一位优先级高:abc < acb < bca) 数组中的排序sort问题:(sort函数作用范围为 [begin, end) ,不包含最后一位 ) 静态数组:int a[10] = { 9, 0, 1, 2, 3, 7, 4, 5, 8, 6 }; sort(a, a +10); (注…...
2024/5/5 9:55:53 - 前端安全系列(一):如何防止XSS攻击?
前端安全随着互联网的高速发展,信息安全问题已经成为企业最为关注的焦点之一,而前端又是引发企业安全问题的高危据点。在移动互联网时代,前端人员除了传统的 XSS、CSRF 等安全问题之外,又时常遭遇网络劫持、非法调用 Hybrid API 等新型安全问题。当然,浏览器自身也在不断在…...
2024/4/24 14:35:25 - MacBook风扇这么响,原来是因为这些细节没注意!
你有没有发现,你的MacBook风扇总是在不经意间声音特别大?平时我们的Mac需要做一些繁重的工作。例如,当涉及到Web开发,照片修饰和视频编辑时。听到我们的MacBook Pro风扇控制器弹起并且MacBook Pro风扇的噪音增大,因为我们知道它工作很艰辛,所以我们并不感到惊讶。如果您发…...
2024/5/5 4:07:56 - 用python来看语料数据库中人物的关系——python自然语言处理习题
最近几天,我参加了一个会议CLSW,当然由于疫情原因,全程在网上进行。会议包含了汉语教学,词汇语法,还有自然语言处理方面的讨论,听了以后,我心里真是热血沸腾,结果听了一小部分的老公比我还激动,立马叫我开始做NLP的习题,额……翻开那本闲置已久的书,老公唰唰唰翻到习…...
2024/5/5 7:54:37 - H.265的各种帧
本文为博主原创文章,未经博主允许不得转载。(合作洽谈请联系QQ:1010316426) H.265的各种帧各种 NALU-Type关于TRAIL关于TSA和STSA关于BLA关于IDR关于CRA和GOP关于IRAPVPSSPSPPSAUDEOSEOBFDSEI 各种 NALU-Type 下图是ffmpeg-v4.2中定义的所有H.265的NALU枚举,参考的《T-REC…...
2024/4/15 3:09:57 - IDEA 闪退,并在C盘生成文件java_error_in_idea_****.log
问题描述 最近在使用IDEA的时候,打开不到3分钟就莫名其妙退出了,网上类似的问题并不多,有一些博客,但是并没有解决,而且都是差不多的文件,但是解决方式并不相同。通过分析后,我在c盘生成了一个日志文件 java_error_in_idea_5468.log,文件路径:C:\Users\danian\ java_e…...
2024/4/15 3:09:56 - Android 开发技术周报 Issue#285
新闻Android 11共享列表已集成类似AirDrop的功能谷歌为Android开发者提供新选项 免安装即可出售订阅服务Play商城新增“试用并安装”按钮 更直观显示应用的订阅信息类似Airdrop的Android附近分享功能将可跨PC平台使用教程安居客 Android APP 走向平台化Kotlin Vocabulary | 内联…...
2024/4/25 19:43:38 - 城市地铁是怎样建成的?
越来越多的人选择地铁绿色出行,全国已经有39个城市开通城市轨道交通(包括香港、台北、桃园、高雄,大陆是35个城市开通)。当我们享受着轨道交通带来的便利的同时,想必不少小伙伴都想知道,它是如何建成的吧?能在地底,甚至地上高架桥上飞驰 地铁的修建必定是一项非常庞大的…...
2024/4/15 3:09:54 - 安装IntelliJ IDEA
1.浏览器访问https://www.jetbrains.com/idea/ 2.点击DOWNLOAD进入版本选择页选择专业版或社区版下载(如果你是学生可以用学生证注册获得永久免费使用专业版资格或者从网上搜一下IntelliJ IDEA的激活码)。 3.双击下载好的IntelliJ IDEA安装文件,选择合适的安装目录进行安装。…...
2024/4/15 3:09:53 - APPKIT打造稳定、灵活、高效的运营配置平台
一、背景美团App、大众点评App都是重运营的应用。对于App里运营资源、基础配置,需要根据城市、版本、平台、渠道等不同的维度进行运营管理。如何在版本快速迭代过程中,保持运营资源能够被高效、稳定和灵活地配置,是我们团队面临的重大考验。在这种背景下,大众点评移动开发组…...
2024/5/5 7:49:07 - 九九乘法表-C++
九九乘法表 ——C++ 代码: #include <iostream> using namespace std; int main () {for(int i=1;i<10;i++){for(int j=1;j<=i;j++)cout<<i<<"*"<<j<<"="<<i*j<<\t;cout<<endl;}return 0; }...
2024/4/15 3:09:51 - arts003
Algorithm: Review:Data speak decoder: 如果你想让自己的数据更可信,需要注意一下我们常用词语的含义。每个词语其实都有它特定的含义,不能为了逼格而滥用,否则会让数据变得不可信。https://weallcount.com/tools/data-speak-decoder/需要了解术语的含义:Anonymized , bia…...
2024/4/15 3:09:50 - ZJOI2020游记
赛前心态挺平和的. 主要是觉得去年像联赛那样自己吓自己挺不值的(现在还是觉得自我惊吓导致Day2在不会T2证明的情况下优先选择补证明而不去卡常太愚蠢了,到手的AK就这么没了…). 就考两天试也没啥必要把自己折腾得死去活来,不如吃好睡好. 虽然最后也没吃好,因为9:00~14:00的考试…...
2024/4/27 5:49:41 - 基于Centos7系统一键部署EFK服务
导读最近平台EFK版本均作了升级,平台采用EFK(ElasticSearch-7.6.2 + FileBeat-7.6.2 + Kibana-7.6.2)架构。这里建议三个组件主次版本保持一致。考虑到服务器比较多,所以写成脚本来批量部署。脚本内容大家看一下function就行了..架构EFK采用集中式的日志管理架构elasticsearc…...
2024/4/24 14:35:23 - 1+X 云计算平台运维与开发认证(初级)E
下面哪个是软件代码版本控制软件?(10分) A、project B、SVN (正确答案)C、notepad++D、Xshell2 下面哪个阶段不是项目管理流程中的阶段?(10分) A、项目立项 B、项目开发C、项目测试D、项目质保 (正确答案)3 以下哪一项最好地描述了何时完成监控项目过程组?(10分) A、整个项目…...
2024/4/24 14:35:20 - 全链路压测平台(Quake)在美团中的实践
背景在美团的价值观中,“以客户为中心”被放在一个非常重要的位置,所以我们对服务出现故障越来越不能容忍。特别是目前公司业务正在高速增长阶段,每一次故障对公司来说都是一笔非常不小的损失。而整个IT基础设施非常复杂,包括网络、服务器、操作系统以及应用层面都可能出现…...
2024/5/4 3:47:40 - 【学习笔记】Linux基础(2):Linux常用命令1
【学习笔记】Linux基础(2):Linux常用命令11、查看帮助文档1.1 help1.2 man2、文件管理命令2.1 查看文件信息:ls2.2 输出重定向:>2.3 分屏查看:more2.4 管道:|2.5 清屏:clear2.6 切换工作目录:cd2.7 显示当前路径:pwd2.8 创键目录:mkdir2.9 删除目录:rmdir2.10 删…...
2024/4/24 14:35:17
最新文章
- 政安晨:【Keras机器学习示例演绎】(三十五)—— 使用 LayerScale 的类注意图像变换器
目录 简介 导入 层刻度层 随机深度层 类注意力 会说话的头注意力 前馈网络 其他模块 拼凑碎片:CaiT 模型 定义模型配置 模型实例化 加载预训练模型 推理工具 加载图像 获取预测 关注层可视化 结论 政安晨的个人主页:政安晨 欢迎 &#…...
2024/5/5 9:55:30 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 基于深度学习的机场航拍小目标检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:在本博客中介绍了基于YOLOv8/v7/v6/v5的机场航拍小目标检测系统。该系统的核心技术是采用YOLOv8,并整合了YOLOv7、YOLOv6、YOLOv5算法,从而进行性能指标的综合对比。我们详细介绍了国内外在机场航拍小目标检测领域的研究现状、数据集处理…...
2024/5/5 8:14:17 - R语言做两次分类,再做两两T检验,最终输出均值和pvalue
1.输入文件: 2.代码: setwd("E:/R/Rscripts/rG4相关绘图")# 加载所需的库 library(tidyverse)# 读取CSV文件 data <- read.csv("box-cds-ABD-不同类型rg4-2.csv", stringsAsFactors FALSE)# 组合Type1和Type2:通过…...
2024/5/5 8:41:20 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/4 23:54:56 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/4 23:54:56 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/4 23:55:17 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/4 23:55:16 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/4 18:20:48 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/4 23:55:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/4 23:55:06 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/4 23:55:06 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/4 23:55:16 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/4 23:55:01 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57