AI Studio 飞桨 零基础入门深度学习笔记2-基于Python编写完成房价预测任务的神经网络模型
AI Studio 飞桨 零基础入门深度学习笔记2-基于Python编写完成房价预测任务的神经网络模型
- 波士顿房价预测任务
- 线性回归模型
- 线性回归模型的神经网络结构
- 构建波士顿房价预测任务的神经网络模型
- 1 数据处理
- 1.1 读入数据
- 1.2 数据形状变换
- 1.3 数据集划分
- 1.4 数据归一化处理
- 1.5 封装成load data函数
- 2 模型设计
- 3 训练配置
- 4 训练过程
- 4.1 梯度下降法
- 4.2 计算梯度
- 4.3 使用Numpy进行梯度计算
- 4.4 确定损失函数更小的点
- 4.5 代码封装Train函数
- 4.6 训练扩展到全部参数
- 4.7 随机梯度下降法( Stochastic Gradient Descent)
- **数据处理代码修改**
- **训练过程代码修改**
- 总结
- 作业1-1
- 作业 1-2
- 作业1-3
- 基本知识
- 作业题
波士顿房价预测任务
上一节我们初步认识了神经网络的基本概念(如神经元、多层连接、前向计算、计算图)和模型结构三要素(模型假设、评价函数和优化算法)。本节将以“波士顿房价”任务为例,向读者介绍使用Python语言和Numpy库来构建神经网络模型的思考过程和操作方法。
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
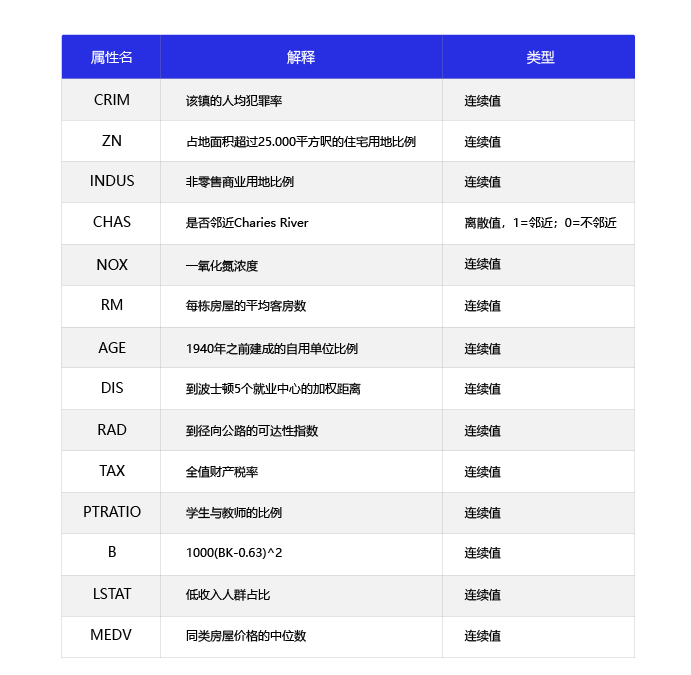
图1:波士顿房价影响因素示意图
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
线性回归模型
假设房价和各影响因素之间能够用线性关系来描述:
模型的求解即是通过数据拟合出每个和。其中,和分别表示该线性模型的权重和偏置。一维情况下, 和 是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
思考:
为什么要以均方误差作为损失函数?即将模型在每个训练样本上的预测误差加和,来衡量整体样本的准确性。这是因为损失函数的设计不仅仅要考虑“合理性”,同样需要考虑“易解性”,这个问题在后面的内容中会详细阐述。
线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络),如 图2 所示。
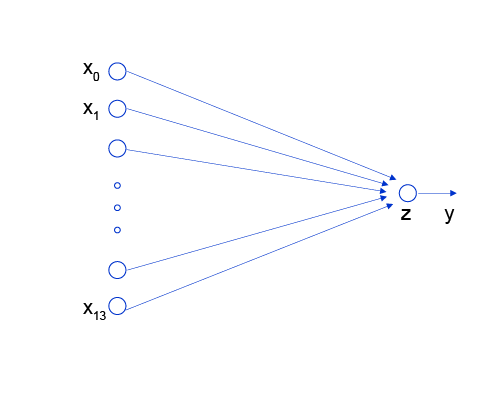
图2:线性回归模型的神经网络结构
构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。
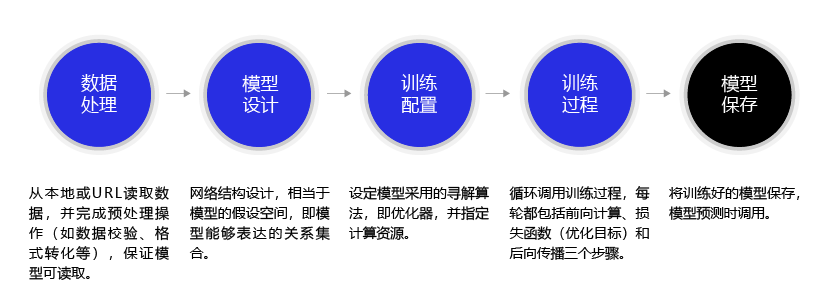
图3:构建神经网络/深度学习模型的基本步骤
正是由于深度学习的建模和训练的过程存在通用性,在构建不同的模型时,只有模型三要素不同,其它步骤基本一致,深度学习框架才有用武之地。
1 数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
1.1 读入数据
我们首先来看一下数据的大致结构。间隔为空格\t

# 导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ') # 以此读取数据存入1维数组中 注意这里是(7084,)
data
np.shape(data)
(7084,)
1.2 数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ] # 给定特征名称 数量 定义
feature_num = len(feature_names)
data = data.reshape([-1, feature_num]) # 这里采用numpy的功能,根据存在的维度计算另一个shape值--给定14,计算出506
print(data.shape)
data[:5,:] # 查看前五行数据
(506, 14)array([[6.3200e-03, 1.8000e+01, 2.3100e+00, 0.0000e+00, 5.3800e-01,6.5750e+00, 6.5200e+01, 4.0900e+00, 1.0000e+00, 2.9600e+02,1.5300e+01, 3.9690e+02, 4.9800e+00, 2.4000e+01],[2.7310e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,6.4210e+00, 7.8900e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,1.7800e+01, 3.9690e+02, 9.1400e+00, 2.1600e+01],[2.7290e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,7.1850e+00, 6.1100e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,1.7800e+01, 3.9283e+02, 4.0300e+00, 3.4700e+01],[3.2370e-02, 0.0000e+00, 2.1800e+00, 0.0000e+00, 4.5800e-01,6.9980e+00, 4.5800e+01, 6.0622e+00, 3.0000e+00, 2.2200e+02,1.8700e+01, 3.9463e+02, 2.9400e+00, 3.3400e+01],[6.9050e-02, 0.0000e+00, 2.1800e+00, 0.0000e+00, 4.5800e-01,7.1470e+00, 5.4200e+01, 6.0622e+00, 3.0000e+00, 2.2200e+02,1.8700e+01, 3.9690e+02, 5.3300e+00, 3.6200e+01]])
1.3 数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。为什么要对数据集进行拆分,而不能直接应用于模型训练呢?这与学生时代的授课和考试关系比较类似,如 图4 所示。

图4:训练集和测试集拆分的意义
上学时总有一些自作聪明的同学,平时不认真学习,考试前临阵抱佛脚,将习题死记硬背下来,但是成绩往往并不好。因为学校期望学生掌握的是知识,而不仅仅是习题本身。另出新的考题,才能鼓励学生努力去掌握习题背后的原理。同样我们期望模型学习的是任务的本质规律,而不是训练数据本身,模型训练未使用的数据,才能更真实的评估模型的效果。
在本案例中,我们将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8 # 定义数据比例
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
(404, 14)
1.4 数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。不理解没关系,这个问题在结束后会再被提及,那时候会更加清楚。
归一化只对训练集进行
归一化方法又称为离差标准化,使结果值映射到[0,1]之间,转换函数如下:

# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \training_data.max(axis=0), \training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]
# 换行时,除非(),[],{}不需添加。其余需加上\ 表示换行标志
# axis = 0 表示沿着从上到下的方向,分别计算各列的值。得到的是一个(14,)的列表
# 对数据进行归一化处理
print(maximums)
for i in range(feature_num):data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 每次得到一列归一化数据
[ 88.9762 100. 25.65 1. 0.871 8.78 100. 12.126524. 666. 22. 396.9 37.97 50. ]
1.5 封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值,平均值maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]# 对数据进行归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])training_data = data[:offset]test_data = data[offset:]return training_data, test_data
# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 查看数据
print(x[0])
print(y[0])
[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923]
[-0.00390539]
2 模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征有13个分量,有1个分量,那么参数权重的形状(shape)是。假设我们以如下任意数字赋值参数做初始化:
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1])
取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w)
print(t)
print(y[0])
[0.03395597]
[-0.00390539]
完整的线性回归公式,还需要初始化偏移量,同样随意赋初值-0.2。那么,线性回归模型的完整输出是,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2
z = t + b
print(z)
[-0.16604403]
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数和。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
为何b给定初值为0,而w为非零值。这里从两个角度解释,实际情况下,每个房间特征至少有一个是对房价有影响否则该问题研究失去意义;数学方面,模型假设是线性方程即 $y=wx + b $
class Network():def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,# 此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn z
基于Network类的定义,模型的计算过程如下所示。
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
print(y1)
[-0.63182506]
[-0.00390539]
3 训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算表示的影响因素所对应的房价应该是, 但实际数据告诉我们房价是。这时我们需要有某种指标来衡量预测值跟真实值之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
上式中的(简记为: )通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数,在后续的章节中会更详细的介绍。对一个样本计算损失函数值的实现如下:
Loss = (y1 - z)*(y1 - z)
print(Loss)
[0.39428312]
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数。
在Network类下面添加损失函数的计算过程如下:
class Network():def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ycost = error * errorcost = np.mean(cost)return cost使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量, ,, , 等均是向量。以变量为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[:3]
y1 = y[:3]
# 选取前三个样本为例
z = net.forward(x1)
# 样本x喂入前向计算模型得到预测值
print('predict: ', z)
loss = net.loss(z, y1)
# 通过训练配置得到损失函数
print('loss:', loss)
predict: [[-0.63182506][-0.55793096][-1.00062009]]
loss: 0.7229825055441156
4 训练过程
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数和的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数尽可能的小,也就是说找到一个参数解和使得损失函数取得极小值。
我们先做一个小测试:如 图5 所示,基于微积分知识,求一条曲线在某个点的斜率等于函数该点的导数值。那么大家思考下,当处于曲线的极值点时,该点的斜率是多少?
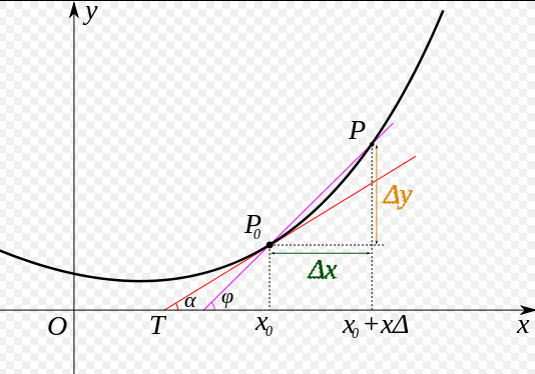
图5:曲线斜率等于导数值
这个问题并不难回答,处于曲线极值点时的斜率为0,即函数在极值点处的导数为0。那么,让损失函数取极小值的和应该是下述方程组的解:
将样本数据带入上面的方程组中即可求解出和的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
4.1 梯度下降法
在现实中存在大量的函数正向求解容易,反向求解较难,被称为单向函数。这种函数在密码学中有大量的应用,密码锁的特点是可以迅速判断一个密钥是否是正确的(已知,求很容易),但是即使获取到密码锁系统,无法破解出正确的密钥是什么(已知,求很难)。
这种情况特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以这样实现:从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点。这种方法笔者称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
训练的关键是找到一组,使得损失函数取极小值。我们先看一下损失函数只随两个参数、变化时的简单情形,启发下寻解的思路。
这里我们将中除之外的参数和都固定下来,可以用图画出的形式。
net = Network(13)
losses = []
# 只画出参数w5和w9在区间[-160, 160]的曲线部分,以及包含损失函数的极值
w5 = np.arange(-160.0, 160.0, 1.0)
w9 = np.arange(-160.0, 160.0, 1.0)
losses = np.zeros([len(w5), len(w9)])# 计算设定区域内每个参数取值所对应的Loss
# 连续给定w5和w9各自321个值即321*321种组合值,并分别计算出各自的损失函数
for i in range(len(w5)):for j in range(len(w9)):net.w[5] = w5[i]net.w[9] = w9[j]z = net.forward(x)loss = net.loss(z, y)losses[i, j] = loss#使用matplotlib将两个变量和对应的Loss作3D图
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)w5, w9 = np.meshgrid(w5, w9)ax.plot_surface(w5, w9, losses, rstride=1, cstride=1, cmap='rainbow')
plt.show()

对于这种简单情形,我们利用上面的程序,可以在三维空间中画出损失函数随参数变化的曲面图。从图中可以看出有些区域的函数值明显比周围的点小。
需要说明的是:为什么这里我们选择和来画图?这是因为选择这两个参数的时候,可比较直观的从损失函数的曲面图上发现极值点的存在。其他参数组合,从图形上观测损失函数的极值点不够直观。
观察上述曲线呈现出“圆滑”的坡度,这正是我们选择以均方误差作为损失函数的原因之一。
图6 呈现了只有一个参数维度时,均方误差和绝对值误差(只将每个样本的误差累加,不做平方处理)的损失函数曲线图。
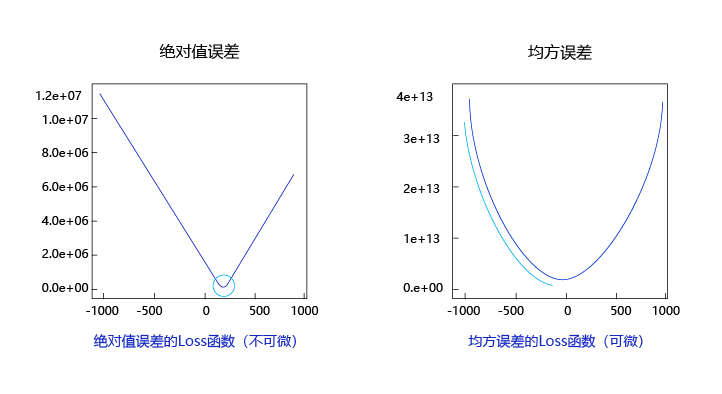
图6:均方误差和绝对值误差损失函数曲线图
由此可见,均方误差表现的“圆滑”的坡度有两个好处:
- 曲线的最低点是可导的。
- 越接近最低点,曲线的坡度逐渐放缓,有助于通过当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而这两个特性绝对值误差是不具备的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
现在我们要找出一组的值,使得损失函数最小,实现梯度下降法的方案如下:
- 步骤1:随机的选一组初始值,例如:
- 步骤2:选取下一个点,使得
- 步骤3:重复步骤2,直到损失函数几乎不再下降。
如何选择是至关重要的,第一要保证是下降的,第二要使得下降的趋势尽可能的快。微积分的基础知识告诉我们,沿着梯度的反方向,是函数值下降最快的方向,如 图7 所示。简单理解,函数在某一个点的梯度方向是曲线斜率最大的方向,但梯度方向是向上的,所以下降最快的是梯度的反方向。
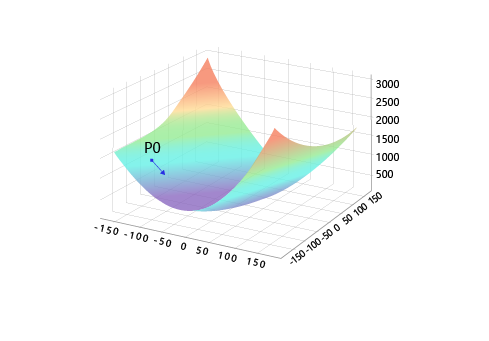
图7:梯度下降方向示意图
4.2 计算梯度
上面我们讲过了损失函数的计算方法,这里稍微加以改写。为了梯度计算更加简洁,引入因子,定义损失函数如下:
其中是网络对第个样本的预测值,表示的是一个样本中的第个特征:
梯度的定义:
可以计算出对和的偏导数:
从导数的计算过程可以看出,因子被消掉了,这是因为二次函数求导的时候会产生因子,这也是我们将损失函数改写的原因。
下面我们考虑只有一个样本的情况下,计算梯度:
可以计算出:
可以计算出对和的偏导数:
选取第一个样本x[0] y[0] 计算梯度
x1 = x[0]
y1 = y[0]
z1 = net.forward(x1)
print('x1 {}, shape {}'.format(x1, x1.shape))
print('y1 {}, shape {}'.format(y1, y1.shape))
print('z1 {}, shape {}'.format(z1, z1.shape))
x1 [-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923], shape (13,)
y1 [-0.00390539], shape (1,)
z1 [-12.05947643], shape (1,)
按上面的公式,当只有一个样本时,可以计算某个,比如的梯度。
gradient_w0 = (z1 - y1) * x1[0]
print('gradient_w0 {}'.format(gradient_w0))
gradient_w0 [0.25875126]
同样我们可以计算的梯度。
gradient_w1 = (z1 - y1) * x1[1]
print('gradient_w1 {}'.format(gradient_w1))
gradient_w1 [-0.45417275]
依次计算的梯度。
gradient_w2= (z1 - y1) * x1[2]
print('gradient_w1 {}'.format(gradient_w2))
gradient_w1 [3.44214394]
写一个for循环即可计算从到的所有权重的梯度,但是计算量很大。这里采用numpy的并行计算。
4.3 使用Numpy进行梯度计算
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
# 直接对1个样本进行梯度计算,得到13个梯度值
gradient_w = (z1 - y1) * x1
print('gradient_w_by_sample1 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample1 [ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.625819172.12068622], gradient.shape (13,)
输入数据中有多个样本,每个样本都对梯度有贡献。如上代码计算了只有第1个样本时的梯度值,同样的计算方法也可以计算样本2和样本3对梯度的贡献。
x2 = x[1]
y2 = y[1]
z2 = net.forward(x2)
gradient_w = (z2 - y2) * x2
print('gradient_w_by_sample2 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample2 [ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.792360812.11028056], gradient.shape (13,)
x3 = x[2]
y3 = y[2]
z3 = net.forward(x3)
gradient_w = (z3 - y3) * x3
print('gradient_w_by_sample3 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample3 [ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.933029470.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.466952292.39363651], gradient.shape (13,)
可能有的读者再次想到可以使用for循环把每个样本对梯度的贡献都计算出来,然后再作平均。但是我们不需要这么做,仍然可以使用Numpy的矩阵操作来简化运算,如3个样本的情况。
# 注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)print('x {}, shape {}'.format(x3samples, x3samples.shape))
print('y {}, shape {}'.format(y3samples, y3samples.shape))
print('z {}, shape {}'.format(z3samples, z3samples.shape))
x [[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923][-0.02122729 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.01684060.14904763 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.0519112-0.06111894][-0.02122751 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.1632288-0.03426854 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.03943037-0.20212336]], shape (3, 13)
y [[-0.00390539][-0.05723872][ 0.23387239]], shape (3, 1)
z [[-12.05947643][-34.58467747][-11.60858134]], shape (3, 1)
上面的x3samples, y3samples, z3samples的第一维大小均为3,表示有3个样本。下面计算这3个样本对梯度的贡献。
# 直接计算出3*13个梯度值
gradient_w = (z3samples - y3samples) * x3samples
print('gradient_w {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w [[ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.625819172.12068622][ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.792360812.11028056][ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.933029470.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.466952292.39363651]], gradient.shape (3, 13)
此处可见,计算梯度gradient_w的维度是,并且其第1行与上面第1个样本计算的梯度gradient_w_by_sample1一致,第2行与上面第2个样本计算的梯度gradient_w_by_sample1一致,第3行与上面第3个样本计算的梯度gradient_w_by_sample1一致。这里使用矩阵操作,可能更加方便的对3个样本分别计算各自对梯度的贡献。
那么对于有N个样本的情形,我们可以直接使用如下方式计算出所有样本对梯度的贡献,这就是使用Numpy库广播功能带来的便捷。
小结一下这里使用Numpy库的广播功能:
- 一方面可以扩展参数的维度,代替for循环来计算1个样本对从w0 到w12 的所有参数的梯度。
- 另一方面可以扩展样本的维度,代替for循环来计算样本0到样本403对参数的梯度。
z = net.forward(x)
gradient_w = (z - y) * x
print('gradient_w shape {}'.format(gradient_w.shape))
print(gradient_w)
gradient_w shape (404, 13)
[[ 0.25875126 -0.45417275 3.44214394 ... 3.49642036 -0.625819172.12068622][ 0.7329239 4.91417754 3.33394253 ... 0.83100061 -1.792360812.11028056][ 0.25138584 1.68549775 1.14349809 ... 0.28502219 -0.466952292.39363651]...[ 14.70025543 -15.10890735 36.23258734 ... 24.54882966 5.5107112226.26098922][ 9.29832217 -15.33146159 36.76629344 ... 24.91043398 -1.2756492326.61808955][ 19.55115919 -10.8177237 25.94192351 ... 17.5765494 3.9455766117.64891012]]
上面gradient_w的每一行代表了一个样本对梯度的贡献。根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
我们也可以使用Numpy的均值函数来完成此过程:
# axis = 0 沿着从上到下的方向进行计算各值 这部分的理解可百度查一下
gradient_w = np.mean(gradient_w, axis=0)
print('gradient_w ', gradient_w.shape)
print('w ', net.w.shape)
print(gradient_w)
print(net.w)gradient_w (13,)
w (13, 1)
[ 1.59697064 -0.92928123 4.72726926 1.65712204 4.96176389 1.180684544.55846519 -3.37770889 9.57465893 10.29870662 1.3900257 -0.301522151.09276043]
[[ 1.76405235e+00][ 4.00157208e-01][ 9.78737984e-01][ 2.24089320e+00][ 1.86755799e+00][ 1.59000000e+02][ 9.50088418e-01][-1.51357208e-01][-1.03218852e-01][ 1.59000000e+02][ 1.44043571e-01][ 1.45427351e+00][ 7.61037725e-01]]
我们使用Numpy的矩阵操作方便地完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而w的维度是(13, 1)。导致该问题的原因是使用np.mean函数时消除了第0维。为了加减乘除等计算方便,gradient_w和w必须保持一致的形状。因此我们将gradient_w的维度也设置为(13, 1),代码如下:
# newaxis 在相应位置增加一个维度 详见 https://m.jb51.net/article/175474.htm
# 如果反复运行此代码,(13,1,1,1...)
gradient_w = gradient_w[:, np.newaxis]
print('gradient_w shape', gradient_w.shape)
gradient_w shape (13, 1)
综合上面的讨论,计算梯度的代码如下所示。
z = net.forward(x)
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_w
array([[ 1.59697064],[-0.92928123],[ 4.72726926],[ 1.65712204],[ 4.96176389],[ 1.18068454],[ 4.55846519],[-3.37770889],[ 9.57465893],[10.29870662],[ 1.3900257 ],[-0.30152215],[ 1.09276043]])
上述代码非常简洁地完成了的梯度计算。同样,计算的梯度的代码也是类似的原理。
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
# 此处b是一个数值,所以可以直接用np.mean得到一个标量
gradient_b
-1.0918438870293816e-13
将上面计算和的梯度的过程,写成Network类的gradient函数,实现方法如下所示。
class Network():def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b)return gradient_w, gradient_b
# 调用上面定义的gradient函数,计算梯度
# 初始化网络
net = Network(13)
# 设置[w5, w9] = [-100., -100.]
net.w[5] = -100.0
net.w[9] = -100.0z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))point [-100.0, -100.0], loss 686.300500817916
gradient [-0.850073323995813, -6.138412364807848]
4.4 确定损失函数更小的点
下面我们开始研究更新梯度的方法。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1
# 定义移动步长 eta
eta = 0.1
# 更新参数w5和w9
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
# 重新计算z和loss
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
# 计算得到下一个梯度
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-99.91499266760042, -99.38615876351922], loss 678.6472185028844
gradient [-0.855635617864529, -6.093226863406581]
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句:
net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适。
如 图8 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
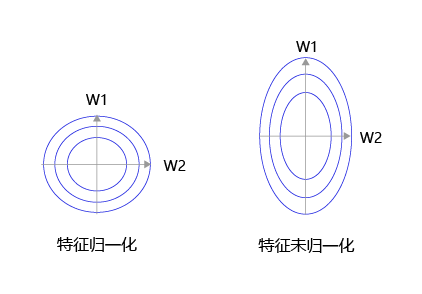
图8:未归一化的特征,会导致不同特征维度的理想步长不同
4.5 代码封装Train函数
将上面的循环计算过程封装在train和update函数中,实现方法如下所示。
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights,1)self.w[5] = -100.self.w[9] = -100.self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, graident_w5, gradient_w9, eta=0.01):net.w[5] = net.w[5] - eta * gradient_w5net.w[9] = net.w[9] - eta * gradient_w9def train(self, x, y, iterations=100, eta=0.01):points = []losses = []for i in range(iterations):points.append([net.w[5][0], net.w[9][0]])z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)gradient_w5 = gradient_w[5][0]gradient_w9 = gradient_w[9][0]self.update(gradient_w5, gradient_w9, eta)losses.append(L)if i % 50 == 0:print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))return points, losses# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 0, point [-99.99144364382136, -99.93861587635192], loss 686.300500817916
iter 50, point [-99.56362583488914, -96.92631128470325], loss 649.2213468309388
iter 100, point [-99.13580802595692, -94.02279509580971], loss 614.6970095624063
iter 150, point [-98.7079902170247, -91.22404911807594], loss 582.543755023494
iter 200, point [-98.28017240809248, -88.52620357520894], loss 552.5911329872217
iter 250, point [-97.85235459916026, -85.9255316243737], loss 524.6810152322887
iter 300, point [-97.42453679022805, -83.41844407682491], loss 498.6667034691001
iter 350, point [-96.99671898129583, -81.00148431353688], loss 474.4121018974464
iter 400, point [-96.56890117236361, -78.67132338862874], loss 451.7909497114133
iter 450, point [-96.14108336343139, -76.42475531364933], loss 430.6861092067028
iter 500, point [-95.71326555449917, -74.25869251604028], loss 410.988905460488
iter 550, point [-95.28544774556696, -72.17016146534513], loss 392.5985138460825
iter 600, point [-94.85762993663474, -70.15629846096763], loss 375.4213919156372
iter 650, point [-94.42981212770252, -68.21434557551346], loss 359.3707524354014
iter 700, point [-94.0019943187703, -66.34164674796719], loss 344.36607459115214
iter 750, point [-93.57417650983808, -64.53564402117185], loss 330.33265059761464
iter 800, point [-93.14635870090586, -62.793873918279786], loss 317.2011651461846
iter 850, point [-92.71854089197365, -61.11396395304264], loss 304.907305311265
iter 900, point [-92.29072308304143, -59.49362926899678], loss 293.3913987080144
iter 950, point [-91.86290527410921, -57.930669402782904], loss 282.5980778542974
iter 1000, point [-91.43508746517699, -56.4229651670156], loss 272.47596883802515
iter 1050, point [-91.00726965624477, -54.968475648286564], loss 262.9774025287022
iter 1100, point [-90.57945184731255, -53.56523531604897], loss 254.05814669965383
iter 1150, point [-90.15163403838034, -52.21135123828792], loss 245.6771575458149
iter 1200, point [-89.72381622944812, -50.90500040003218], loss 237.796349191773
iter 1250, point [-89.2959984205159, -49.6444271209092], loss 230.3803798866218
iter 1300, point [-88.86818061158368, -48.42794056808474], loss 223.39645367664923
iter 1350, point [-88.44036280265146, -47.2539123610643], loss 216.81413643451378
iter 1400, point [-88.01254499371925, -46.12077426496303], loss 210.60518520483126
iter 1450, point [-87.58472718478703, -45.027015968976976], loss 204.74338990147896
iter 1500, point [-87.15690937585481, -43.9711829469081], loss 199.20442646183585
iter 1550, point [-86.72909156692259, -42.95187439671279], loss 193.96572062803054
iter 1600, point [-86.30127375799037, -41.96774125615467], loss 189.00632158541163
iter 1650, point [-85.87345594905815, -41.017484291751295], loss 184.30678474424633
iter 1700, point [-85.44563814012594, -40.0998522583068], loss 179.84906300239203
iter 1750, point [-85.01782033119372, -39.21364012642417], loss 175.61640587468244
iter 1800, point [-84.5900025222615, -38.35768737548557], loss 171.59326591927962
iter 1850, point [-84.16218471332928, -37.530876349682856], loss 167.76521193253296
iter 1900, point [-83.73436690439706, -36.73213067476985], loss 164.11884842217904
iter 1950, point [-83.30654909546485, -35.96041373329276], loss 160.64174090423475
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SkYFP5hd-1597208354737)(output_67_1.png)]](https://img-blog.csdnimg.cn/20200812130232983.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI2NzY1MDk5,size_16,color_FFFFFF,t_70#pic_center)
4.6 训练扩展到全部参数
为了能给读者直观的感受,上面演示的梯度下降的过程仅包含和两个参数,但房价预测的完整模型,必须要对所有参数和进行求解。这需要将Network中的update和train函数进行修改。由于不再限定参与计算的参数(所有参数均参与计算),修改之后的代码反而更加简洁。实现逻辑:“前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值”四个部分反复执行,直到到达参数最优点。具体代码如下所示。
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, x, y, iterations=100, eta=0.01):losses = []for i in range(iterations):z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(L)if (i+1) % 10 == 0:print('iter {}, loss {}'.format(i, L))return losses# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 9, loss 1.898494731457622
iter 19, loss 1.8031783384598723
iter 29, loss 1.7135517565541092
iter 39, loss 1.6292649416831266
iter 49, loss 1.5499895293373234
iter 59, loss 1.4754174896452612
iter 69, loss 1.4052598659324693
iter 79, loss 1.3392455915676866
iter 89, loss 1.2771203802372915
iter 99, loss 1.218645685090292
iter 109, loss 1.1635977224791534
iter 119, loss 1.111766556287068
iter 129, loss 1.0629552390811503
iter 139, loss 1.0169790065644477
iter 149, loss 0.9736645220185994
iter 159, loss 0.9328491676343147
iter 169, loss 0.8943803798194311
iter 179, loss 0.8581150257549611
iter 189, loss 0.8239188186389671
iter 199, loss 0.7916657692169988
iter 209, loss 0.761237671346902
iter 219, loss 0.7325236194855752
iter 229, loss 0.7054195561163928
iter 239, loss 0.6798278472589763
iter 249, loss 0.6556568843183528
iter 259, loss 0.6328207106387195
iter 269, loss 0.6112386712285091
iter 279, loss 0.59083508421862
iter 289, loss 0.5715389327049418
iter 299, loss 0.5532835757100347
iter 309, loss 0.5360064770773407
iter 319, loss 0.5196489511849665
iter 329, loss 0.5041559244351539
iter 339, loss 0.48947571154034963
iter 349, loss 0.47555980568755696
iter 359, loss 0.46236268171965056
iter 369, loss 0.44984161152579916
iter 379, loss 0.43795649088328303
iter 389, loss 0.42666967704002257
iter 399, loss 0.41594583637124666
iter 409, loss 0.4057518014851036
iter 419, loss 0.3960564371908221
iter 429, loss 0.38683051477942226
iter 439, loss 0.3780465941011246
iter 449, loss 0.3696789129556087
iter 459, loss 0.36170328334131785
iter 469, loss 0.3540969941381648
iter 479, loss 0.3468387198244131
iter 489, loss 0.3399084348532937
iter 499, loss 0.33328733333814486
iter 509, loss 0.32695775371667785
iter 519, loss 0.32090310808539985
iter 529, loss 0.31510781591441284
iter 539, loss 0.30955724187078903
iter 549, loss 0.3042376374955925
iter 559, loss 0.29913608649543905
iter 569, loss 0.29424045342432864
iter 579, loss 0.2895393355454012
iter 589, loss 0.28502201767532415
iter 599, loss 0.28067842982626157
iter 609, loss 0.27649910747186535
iter 619, loss 0.2724751542744919
iter 629, loss 0.2685982071209627
iter 639, loss 0.26486040332365085
iter 649, loss 0.2612543498525749
iter 659, loss 0.2577730944725093
iter 669, loss 0.2544100986669443
iter 679, loss 0.2511592122380609
iter 689, loss 0.2480146494787638
iter 699, loss 0.24497096681926714
iter 709, loss 0.2420230418567801
iter 719, loss 0.23916605368251415
iter 729, loss 0.23639546442555456
iter 739, loss 0.23370700193813698
iter 749, loss 0.23109664355154746
iter 759, loss 0.2285606008362593
iter 769, loss 0.22609530530403904
iter 779, loss 0.2236973949936189
iter 789, loss 0.22136370188515428
iter 799, loss 0.21909124009208833
iter 809, loss 0.21687719478222933
iter 819, loss 0.21471891178284028
iter 829, loss 0.21261388782734392
iter 839, loss 0.2105597614038757
iter 849, loss 0.20855430416838638
iter 859, loss 0.20659541288730932
iter 869, loss 0.20468110187697833
iter 879, loss 0.2028094959090178
iter 889, loss 0.20097882355283644
iter 899, loss 0.19918741092814593
iter 909, loss 0.1974336758421087
iter 919, loss 0.1957161222872899
iter 929, loss 0.19403333527807176
iter 939, loss 0.19238397600456975
iter 949, loss 0.19076677728439415
iter 959, loss 0.18918053929381623
iter 969, loss 0.18762412556104593
iter 979, loss 0.18609645920539716
iter 989, loss 0.18459651940712488
iter 999, loss 0.18312333809366155
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WPZna3DJ-1597208354738)(output_69_1.png)]](https://img-blog.csdnimg.cn/20200812145158226.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI2NzY1MDk5,size_16,color_FFFFFF,t_70#pic_center)
4.7 随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗地说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- min-batch:每次迭代时抽取出来的一批数据被称为一个min-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
数据处理代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
# 获取数据
train_data, test_data = load_data()
train_data.shape
(404, 14)
train_data中一共包含404条数据,如果batch_size=10,即取前0-9号样本作为第一个mini-batch,命名train_data1。
train_data1 = train_data[0:10]
train_data1.shape
(10, 14)
使用train_data1的数据(0-9号样本)计算梯度并更新网络参数。
net = Network(13)
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss
[0.9001866101467376]
再取出10-19号样本作为第二个mini-batch,计算梯度并更新网络参数。
train_data2 = train_data[10:19]
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss
[0.8903272433979659]
按此方法不断的取出新的mini-batch,并逐渐更新网络参数。
接下来,将train_data分成大小为batch_size的多个mini_batch,如下代码所示:将train_data分成 个 mini_batch了,其中前40个mini_batch,每个均含有10个样本,最后一个mini_batch只含有4个样本。
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
print('total number of mini_batches is ', len(mini_batches))
print('first mini_batch shape ', mini_batches[0].shape)
print('last mini_batch shape ', mini_batches[-1].shape)
total number of mini_batches is 41
first mini_batch shape (10, 14)
last mini_batch shape (4, 14)
另外,我们这里是按顺序取出mini_batch的,而SGD里面是随机抽取一部分样本代表总体。为了实现随机抽样的效果,我们先将train_data里面的样本顺序随机打乱,然后再抽取mini_batch。随机打乱样本顺序,需要用到np.random.shuffle函数,下面先介绍它的用法。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
print('before shuffle', a)
np.random.shuffle(a)
print('after shuffle', a)
before shuffle [ 1 2 3 4 5 6 7 8 9 10 11 12]
after shuffle [ 7 2 11 3 8 6 12 1 4 5 10 9]
多次运行上面的代码,可以发现每次执行shuffle函数后的数字顺序均不同。
上面举的是一个1维数组乱序的案例,我们再观察下2维数组乱序后的效果。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
a = a.reshape([6, 2])
print('before shuffle\n', a)
np.random.shuffle(a)
print('after shuffle\n', a)
before shuffle[[ 1 2][ 3 4][ 5 6][ 7 8][ 9 10][11 12]]
after shuffle[[ 1 2][ 3 4][ 5 6][ 9 10][11 12][ 7 8]]
观察运行结果可发现,(6,2)数组的元素在第0维被随机打乱即6个数组顺序打乱,但第1维的数字顺序保持不变。例如数字2仍然紧挨在数字1的后面,数字8仍然紧挨在数字7的后面,而第二维的[3, 4]并不排在[1, 2]的后面。将这部分实现SGD算法的代码集成到Network类中的train函数中,最终的完整代码如下。
# 获取数据
train_data, test_data = load_data()# 打乱样本顺序
np.random.shuffle(train_data)# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]# 创建网络
net = Network(13)# 依次使用每个mini_batch的数据
for mini_batch in mini_batches:x = mini_batch[:, :-1]y = mini_batch[:, -1:]loss = net.train(x, y, iterations=1)
训练过程代码修改
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
- 第一层循环,代表样本集合要被训练遍历几次,称为“epoch”,代码如下:
for epoch_id in range(num_epoches):
- 第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”,代码如下:
for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数,这与大家之前所学是一致的,代码如下:
x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x) #前向计算loss = self.loss(a, y) #计算损失gradient_w, gradient_b = self.gradient(x, y) #计算梯度self.update(gradient_w, gradient_b, eta) #更新参数
将两部分改写的代码集成到Network类中的train函数中,最终的实现如下。
import numpy as npclass Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子#np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)N = x.shape[0]gradient_w = 1. / N * np.sum((z-y) * x, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = 1. / N * np.sum(z-y)return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, training_data, num_epoches, batch_size=10, eta=0.01):n = len(training_data)losses = []for epoch_id in range(num_epoches):# 在每轮迭代开始之前,将训练数据的顺序随机打乱# 然后再按每次取batch_size条数据的方式取出np.random.shuffle(training_data)# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]for iter_id, mini_batch in enumerate(mini_batches):#print(self.w.shape)#print(self.b)x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x)loss = self.loss(a, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(loss)print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss))return losses# 获取数据
train_data, test_data = load_data()# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=5, batch_size=20, eta=0.1)# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
Epoch 0 / iter 0, loss = 0.2521
Epoch 0 / iter 1, loss = 0.9664
Epoch 0 / iter 2, loss = 0.5541
Epoch 0 / iter 3, loss = 0.2619
Epoch 0 / iter 4, loss = 0.9227
Epoch 0 / iter 5, loss = 0.5416
Epoch 0 / iter 6, loss = 0.4918
Epoch 0 / iter 7, loss = 0.3090
Epoch 0 / iter 8, loss = 0.6816
Epoch 0 / iter 9, loss = 0.2077
Epoch 0 / iter 10, loss = 0.5822
Epoch 0 / iter 11, loss = 0.4233
Epoch 0 / iter 12, loss = 0.4172
Epoch 0 / iter 13, loss = 0.7366
Epoch 0 / iter 14, loss = 0.3486
Epoch 0 / iter 15, loss = 0.4710
Epoch 0 / iter 16, loss = 0.4661
Epoch 0 / iter 17, loss = 0.4091
Epoch 0 / iter 18, loss = 0.3968
Epoch 0 / iter 19, loss = 0.3975
Epoch 0 / iter 20, loss = 0.1120
Epoch 1 / iter 0, loss = 0.5768
Epoch 1 / iter 1, loss = 0.5322
Epoch 1 / iter 2, loss = 0.9350
Epoch 1 / iter 3, loss = 0.2656
Epoch 1 / iter 4, loss = 0.2300
Epoch 1 / iter 5, loss = 0.2850
Epoch 1 / iter 6, loss = 0.3642
Epoch 1 / iter 7, loss = 0.2121
Epoch 1 / iter 8, loss = 0.3077
Epoch 1 / iter 9, loss = 0.5499
Epoch 1 / iter 10, loss = 0.4342
Epoch 1 / iter 11, loss = 0.2141
Epoch 1 / iter 12, loss = 0.1607
Epoch 1 / iter 13, loss = 0.3346
Epoch 1 / iter 14, loss = 0.4893
Epoch 1 / iter 15, loss = 0.4344
Epoch 1 / iter 16, loss = 0.1179
Epoch 1 / iter 17, loss = 0.4322
Epoch 1 / iter 18, loss = 0.1098
Epoch 1 / iter 19, loss = 0.2725
Epoch 1 / iter 20, loss = 0.0806
Epoch 2 / iter 0, loss = 0.7431
Epoch 2 / iter 1, loss = 0.2790
Epoch 2 / iter 2, loss = 0.5033
Epoch 2 / iter 3, loss = 0.3427
Epoch 2 / iter 4, loss = 0.1945
Epoch 2 / iter 5, loss = 0.2371
Epoch 2 / iter 6, loss = 0.2124
Epoch 2 / iter 7, loss = 0.1284
Epoch 2 / iter 8, loss = 0.2467
Epoch 2 / iter 9, loss = 0.3809
Epoch 2 / iter 10, loss = 0.3818
Epoch 2 / iter 11, loss = 0.1488
Epoch 2 / iter 12, loss = 0.2534
Epoch 2 / iter 13, loss = 0.3322
Epoch 2 / iter 14, loss = 0.1377
Epoch 2 / iter 15, loss = 0.1063
Epoch 2 / iter 16, loss = 0.2039
Epoch 2 / iter 17, loss = 0.2299
Epoch 2 / iter 18, loss = 0.2825
Epoch 2 / iter 19, loss = 0.4077
Epoch 2 / iter 20, loss = 0.2074
Epoch 3 / iter 0, loss = 0.0783
Epoch 3 / iter 1, loss = 0.2755
Epoch 3 / iter 2, loss = 0.2339
Epoch 3 / iter 3, loss = 0.1456
Epoch 3 / iter 4, loss = 0.2915
Epoch 3 / iter 5, loss = 0.4859
Epoch 3 / iter 6, loss = 0.2171
Epoch 3 / iter 7, loss = 0.2782
Epoch 3 / iter 8, loss = 0.2043
Epoch 3 / iter 9, loss = 0.4662
Epoch 3 / iter 10, loss = 0.1965
Epoch 3 / iter 11, loss = 0.2081
Epoch 3 / iter 12, loss = 0.2149
Epoch 3 / iter 13, loss = 0.1411
Epoch 3 / iter 14, loss = 0.2372
Epoch 3 / iter 15, loss = 0.2769
Epoch 3 / iter 16, loss = 0.2567
Epoch 3 / iter 17, loss = 0.1392
Epoch 3 / iter 18, loss = 0.2381
Epoch 3 / iter 19, loss = 0.2093
Epoch 3 / iter 20, loss = 0.0887
Epoch 4 / iter 0, loss = 0.1108
Epoch 4 / iter 1, loss = 0.1123
Epoch 4 / iter 2, loss = 0.1902
Epoch 4 / iter 3, loss = 0.2440
Epoch 4 / iter 4, loss = 0.3204
Epoch 4 / iter 5, loss = 0.2762
Epoch 4 / iter 6, loss = 0.1308
Epoch 4 / iter 7, loss = 0.1404
Epoch 4 / iter 8, loss = 0.1268
Epoch 4 / iter 9, loss = 0.3178
Epoch 4 / iter 10, loss = 0.2440
Epoch 4 / iter 11, loss = 0.0672
Epoch 4 / iter 12, loss = 0.2202
Epoch 4 / iter 13, loss = 0.2206
Epoch 4 / iter 14, loss = 0.2242
Epoch 4 / iter 15, loss = 0.2936
Epoch 4 / iter 16, loss = 0.2797
Epoch 4 / iter 17, loss = 0.0963
Epoch 4 / iter 18, loss = 0.2270
Epoch 4 / iter 19, loss = 0.2134
Epoch 4 / iter 20, loss = 0.0458

观察上述Loss的变化,随机梯度下降加快了训练过程,但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。
说明:
由于房价预测的数据量过少,所以难以感受到随机梯度下降带来的性能提升。
总结
本节我们详细介绍了如何使用Numpy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
- 构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
- 随机选择初始点,建立梯度的计算方法和参数更新方式。
- 从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
作业1-1
-
样本归一化:预测时的样本数据同样也需要归一化,但使用训练样本的均值和极值计算,这是为什么?
-
当部分参数的梯度计算为0(接近0)时,可能是什么情况?是否意味着完成训练?
1.归一化的作用
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
1)在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在[0,1]之间是统计的概率分布,归一化在[-1,+1]之间是统计的坐标分布。
2)奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量),譬如,下面为具有两个特征的样本数据x1、x2、x3、x4、x5、x6(特征向量—>列向量),其中x6这个样本的两个特征相对其他样本而言相差比较大,因此,x6认为是奇异样本数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IOpHdCaZ-1597208354743)(attachment:c5b70a0bee41f65cf33c9f038f865aa.png)]](https://img-blog.csdnimg.cn/2020081213045783.png#pic_center)
具体参考https://blog.csdn.net/zenghaitao0128/article/details/78361038
2.分布参数的梯度为0并不意味着训练结束,只能说明其在对应的维度上,已达到最小
作业 1-2
- 随机梯度下降的batchsize设置成多少合适?过小有什么问题?过大有什么问题?提示:过大以整个样本集合为例,过小以单个样本为例来思考。
- 一次训练使用的配置:5个epoch,1000个样本,batchsize=20,最内层循环执行多少轮?
1.每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的剖面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0278Knoj-1597208354744)(attachment:09efd4057ce83ea6a946e668654cd79.png)]
2.5个epoch即遍历5次全部样本。每个minibatch尺寸为batchsize=20,则有1000/20 = 50个minibatch即遍历1次样本迭代50次,则内循环50 * 5 = 250次
作业1-3
基本知识
1. 求导的链式法则
链式法则是微积分中的求导法则,用于求一个复合函数的导数,是在微积分的求导运算中一种常用的方法。复合函数的导数将是构成复合这有限个函数在相应点的导数的乘积,就像锁链一样一环套一环,故称链式法则。如 图9 所示,如果求最终输出对内层输入(第一层)的梯度,等于外层梯度(第二层)乘以本层函数的梯度。

图9:求导的链式法则
2. 计算图的概念
(1)为何是反向计算梯度?即梯度是由网络后端向前端计算。当前层的梯度要依据处于网络中后一层的梯度来计算,所以只有先算后一层的梯度才能计算本层的梯度。
(2)案例:购买苹果产生消费的计算图。假设一家商店9折促销苹果,每个的单价100元。计算一个顾客总消费的结构如 图10 所示。
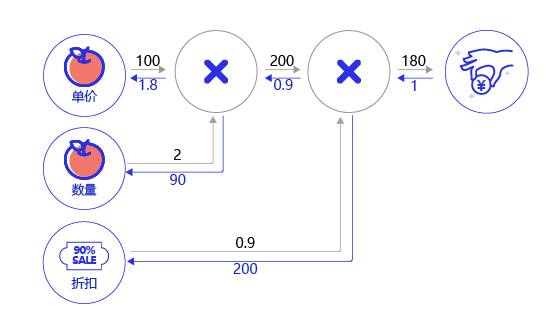
图10:购买苹果所产生的消费计算图
- 前向计算过程:以黑色箭头表示,顾客购买了2个苹果,再加上九折的折扣,一共消费100*2*0.9=180元。
- 后向传播过程:以红色箭头表示,根据链式法则,本层的梯度计算 * 后一层传递过来的梯度,所以需从后向前计算。
最后一层的输出对自身的求导为1。导数第二层根据 图11 所示的乘法求导的公式,分别为0.9*1和200*1。同样的,第三层为100 * 0.9=90,2 * 0.9=1.8。
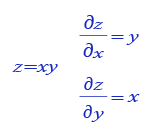
图11:乘法求导的公式
作业题
- 根据 图12 所示的乘法和加法的导数公式,完成 图13 购买苹果和橘子的梯度传播的题目。
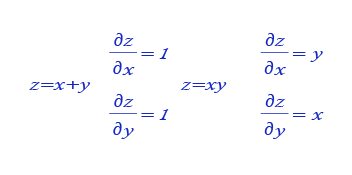
图12:乘法和加法的导数公式
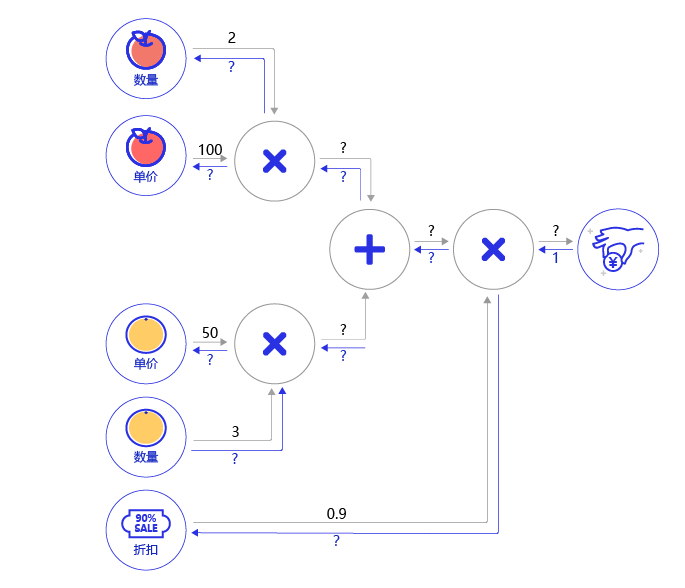
图13:购买苹果和橘子产生消费的计算图
- 挑战题:用代码实现两层的神经网络的梯度传播,中间层的尺寸为13【房价预测案例】(教案当前的版本为一层的神经网络),如 图14 所示。
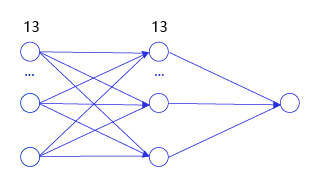
图14:两层的神经网络

2.下节给出
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- vnc客户端下载,四款可以下载的vnc客户端软件
vnc客户端下载不知道大家听说过没有,这是一款什么软件呢?其实它的全称叫做vnc远程连接工具,这是一款远程连接软件。网络上vnc客户端下载软件五花八门,那我们到底该如何选择呢?推荐四款可以下载的vnc客户端软件。 第一款:IIS7服务器管理工具 这个工具里面的VNC功能可以说是…...
2024/5/1 14:07:57 - 三维点云学习(7)2-Feature Detection-harris 3d & 6d
三维点云学习(7)2-Feature Detection-harris 3d & 6d harris 3d解决点云特征点提取问题: 1.点云的点是离散的 2.在点云里一个patch是怎么定义的 3.怎样移动一个patch对一阶导数的优化优化后,能滤除噪声,得到更加平整的平面Respone:Without Intensitydist:点到一阶近似…...
2024/4/29 14:40:49 - realvnc,realvnc软件能干什么?详细介绍
RealVNC Enterprise 是工业标准 VNC 的一个增强版本,提供了核心的 Enterprise Edition 安全增强,包括 2048 位 RSA 服务器验证和 128 位 AES 会话加密术,加上为 Windows 网络量身定做的许多其他的特性。 但是我使用过一款也非常好的vnc工具,名字叫IIS7服务器管理工具。 这个…...
2024/5/1 5:10:51 - 使用Vmware虚拟机装载Linux系统如何联网
1、使用VMware workstation装一个Linux系统,我用的centos系统。2、选择你的虚拟机,然后右击鼠标,最底下的“设置”,在设置里面找到网络适配器,选择NAT模式进行网络连接。3、调好之后保存退出,在最上面的工具栏一项里点击“编辑”,选择虚拟网络适配器。点击NAT模式,在最…...
2024/5/1 7:15:26 - 心动不如行动,基于Docker安装关系型数据库PostgrelSQL替代Mysql
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_171 最近“全栈数据库”的概念甚嚣尘上,主角就是PostgrelSQL,它最近这几年的技术发展不可谓不猛,覆盖OLTP、OLAP、NoSQL、搜索、图像等应用场景,实实在在的全栈性发展。帮助公司解决了数据孤岛、数据平台多、同步一致性、…...
2024/4/29 14:40:39 - 交通部网约车申请连通性测试流程分享
交通部网约车接口目前是2016版最新的技术文档进行对接;交通部网约车申请连通性测试接口共计33个 ,分为32个接口和1个ftp接口32个接口为post数据接口和1个接口ftp,含法人证件照片,车辆照片,驾驶证照片和驾驶员照片信息。我们的计划安排:1、提交申请材料;2、拿到vpn账号,…...
2024/4/29 14:40:34 - Netty集成ProtoBuf开发
Netty集成ProtoBuf开发Netty简介 Netty是业界最流行的NIO框架之,它的健壮性、功能、性能、可定制性和可扩展性在同类框架中都是首屈-指的,它已经得到成百上千的商用项目验证,例如Hadoop的RPC框架Avro就使用了Netty作为底层通信框架,其他还有业界主流的RPC框架,也使 用Nett…...
2024/5/1 10:51:14 - 南京导视VI系统设计,导视标识标牌系统设计分类
导示系统,通常是按其类别进行设计与应用的,但也可组合应用。例如,加油站之间为了营销竞争,有的将其入口处常规导示符号→在其造型上加大,使颜色对比更加鲜明夺目,形成其功能不仅仅是方向上的导示,而扩展为营销手段。既“由此进入”,引深为“‘请’、‘要’由此进入”。…...
2024/5/1 8:47:21 - Python 装饰器warper
参考: https://www.youtube.com/watch?v=5VCywjS8YEA https://foofish.net/python-decorator.html Python装饰器是用来修饰函数的函数 Python函数的理解 在 Python 中万物皆为对象,函数也不例外,函数作为对象可以赋值给一个变量、可以作为元素添加到集合对象中、可作为参数…...
2024/4/29 14:40:26 - 揭秘微信红包:架构、抢红包算法、高并发和降级方案
与传统意义上的红包相比,近两年火起来的“红包”,似乎才是如今春节的一大重头戏。历经上千年时代传承与变迁,春节发红包早已成为历史沉淀的文化习俗,融入了民族的血脉。按照各家公布的数据,除夕全天微信用户红包总发送量达到80.8亿个,红包峰值收发量为40.9万个/秒。春晚直…...
2024/4/29 14:40:22 - Leaflet中文文档【转载】
L.MapAPI各种类中的核心部分,用来在页面中创建地图并操纵地图.使用 example// initialize the map on the "map" div with a given center and zoomvar map = L.map(map, { center: [51.505, -0.09], zoom: 13});构造器构造器使用描述L.Map( <HTMLElement|String…...
2024/5/1 9:59:03 - 解密中老年理财直播热背后的商业逻辑:用户运营/行业趋势/新风口
作者丨何辰开篇:中国是世界上储蓄率最高的国家——据全国中老年网的调查数据,中国老年人人均存款近8万元。老龄化加速,更富裕世代的老年人数量不断增多,越来越多社会资产聚集到中老年人手上,刺激老年人金融/理财服务需求不断增加,要求也越来越高。一方面,以往靠子女养老…...
2024/5/1 6:25:31 - 一对一直播源码一对一直播源码搭建你要知道的功能
一对一直播源码一对一直播源码搭建你要知道的功能2020年初全国疫情使的各方面企业都在停工,经济压力巨大。通过全国人民的努力与积极配合我国疫情得到得到控制并取得巨大的胜利,全国各地都在积极复工复产!大家都在积极开展各种业务。在疫情期间直播行业可以说是火爆市场!有…...
2024/4/29 14:40:10 - Android自定义控件进阶14-特殊控件的事件处理方案
本文带大家了解 Android 特殊形状控件的事件处理方式,主要是利用了 Region 和 Matrix 的一些方法,超级实用的事件处理方案,相信看完本篇之后,任何奇葩控件的事件处理都会变得十分简单。 不得不说,Android 对事件体系封装的非常棒,即便对事件体系不太了解的人,只要简单的…...
2024/4/29 14:40:06 - 区块链扫码溯源防伪直购,重构新零售信任体系建设
目前的电商企业,客户的数据都被存储在为数不多的中心化数据库内,一旦电子商务公司遭受了网络犯罪分子的攻击入侵,大量数据将会被窃取。 但是,基于区块链的电子商务平台,由于区块链平台是分散的,所以实际上不可能遭受这种攻击,反过来也意味着客户数据也是分散的。破解区块…...
2024/4/30 21:47:38 - python 常用面试题目(编程)
#!usr/bin/python # -*- coding: utf-8 -*-# 字符串去重后排序 from functools import reduces = "sheckjffs" str_list = list(set(s)) str_list.sort() s = "".join(str_list) print(s)# 列表扩展 a = [2, 4, 7, 1] b = [4, 6, 8, 3] a.extend(b)# 冒泡排…...
2024/4/29 14:39:58 - EXCAL 分割文本
将图1变成图2- 步骤一: 先选中第一列文本,然后选中工具栏中的 Data -> Text to Columns- 步骤二: 选中Delimited (分隔符) - 步骤三: 选中可以根据 空格 ,分号(英文下),tab键,逗号 (英文下)或者其它自定义的分隔符进行分割,比如 这里分割用的是 /...
2024/4/29 14:39:55 - 听说同学你搞不懂Java的LinkedHashMap,可笑
先看再点赞,给自己一点思考的时间,微信搜索【沉默王二】关注这个有颜值却假装靠才华苟且的程序员。 本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题。同学们好啊,还记得 HashMap 那篇吗?我自己感觉写得非常棒啊,既通俗易懂,又深入源码…...
2024/4/29 14:39:50 - Spring Boot自动配置原理
Spring Boot自动配置的原理在于@SpringBootApplication注解下的@EnableAutoConfiguration,因此我们从这个配置类开始分析,主要分析过程都写在代码中了。@EnableAutoConfiguration这个注解是Spring Boot自动配置的关键,其中Import了另一个DefferedImportSelector的实现类Auto…...
2024/4/29 14:39:45 - 2016年第31届宁波市信息学竞赛复赛试题 D 射击
题目本体 题目描述 不难发现,豆豆能从很多事情中去思考数学,于是豆豆父母决定让他去练习射击,这是项需要集中注意力的运动,相信能够让豆豆暂时脱离数学。学习射击的第一天就让豆豆产生了浓厚的兴趣,射击的靶子是大饼圆,射击枪的子弹近似圆柱,为什么要圆的不能是其他的形…...
2024/4/29 14:39:46
最新文章
- 第11章 数据库技术(第一部分)
一、数据库技术术语 (一)术语 1、数据 数据描述事物的符号描述一个对象所用的标识,可以文字、图形、图像、语言等等 2、信息 现实世界对事物状态变化的反馈。可感知、可存储、可加工、可再生。数据是信息的表现形式和载体,信…...
2024/5/1 14:49:40 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - spark on hive
由于spark不存在元数据管理模块,为了能方便地通过sql操作hdfs数据,我们可以通过借助hive的元数据管理模块实现。对于hive来说,核心组件包含两个: sql优化翻译器,翻译sql到mapreduce并提交到yarn执行metastore…...
2024/5/1 13:24:51 - 17、Lua 文件 I-O
Lua 文件 I/O Lua 文件 I/O简单模式完全模式 Lua 文件 I/O LuaI/O 库用于读取和处理文件。分为简单模式(和C一样)、完全模式。 简单模式(simple model)拥有一个当前输入文件和一个当前输出文件,并且提供针对这些文件…...
2024/4/30 2:48:21 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/1 10:25:26 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/1 13:20:04 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/4/29 18:43:42 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/1 4:07:45 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/4/30 23:32:22 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/4/30 23:16:16 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/1 6:35:25 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/1 11:24:00 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/1 4:35:02 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/4/30 14:53:47 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/4/30 22:14:26 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/1 6:34:45 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/4/30 22:57:18 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/4/30 20:39:53 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/1 4:45:02 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/1 8:32:56 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/1 14:33:22 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/1 11:51:23 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/1 5:23:20 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/4/30 20:52:33 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57