Spark学习笔记(二)——分布式计算原理
Spark分布式计算原理
- Spark分布式计算原理
- 一、Spark WordCount运行原理
- 二、Stage
- 1、stage概念
- 2、为什么划分:
- 3、划分的好处
- 4、RDD之间的依赖关系
- 5、spark中如何划分stage
- 三、DAG工作原理
- 四、Spark Shuffle过程
- 五、RDD持久化
- 六、RDD共享变量
- 1、广播变量
- 2、累加器
- 七、RDD分区设计
- 1、设计概念
- 2、数据倾斜
- 八、数据源装载
- 1、装载CSV数据源
- 2、装载JSON数据源
- 九、基于RDD的Spark应用程序开发
- 1、演练一
- 1、演练一
Spark分布式计算原理
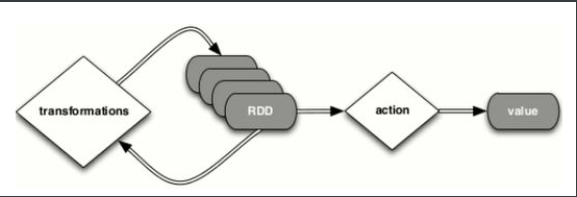
一、Spark WordCount运行原理
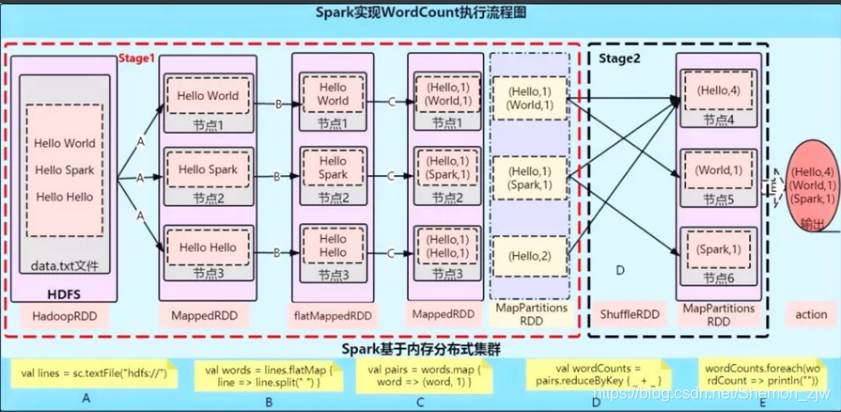
图中过程解析
A:val lines: RDD[String] = sc.textFile("hdfs"://)
//这行代码会生成两个RDD(HadoopRDD、MapPartitionsRDD)
//将内容分词后压平
B:val words: RDD[String] = lines.flatMap(.split(" "))
//这行代码通过flatMap生成一个新的RDD
//将单词和1组合到一起
C:val pairs: RDD[(String, Int)] = words.map((word, 1))
//通过map生成一个新的RDDD:valwordCounts = pairs.reduceByKey(_+_) //这时候就开始了一个ShuffedRDD,开始触发计算E:wordCounts.foreach(wordCount=>println(""))//输出结果
java API实现:
object ScalaWordCount {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName("ScalaWordCount").setMaster("local")//SparkContext,是Spark程序执行的入口val sc = new SparkContext(conf)//通过sc指定以后从哪里读取数据//RDD弹性分布式数据集,一个神奇的大集合val lines: RDD[String] = sc.textFile(args(0))//将内容分词后压平val words: RDD[String] = lines.flatMap(_.split(" "))println(words.collect().toBuffer)//将单词和1组合到一起val wordAndOne: RDD[(String, Int)] = words.map((_, 1))//分组聚合val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)//排序val sorted = reduce.sortBy(_._2, false)/* //保存结果sorted.saveAsTextFile(args(1))*/println(sorted.collect().toBuffer)//释放资源sc.stop()}
}
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
**形成了一个新的RDD MapPartitionsRDD**
sorted.saveAsTextFile(args(1))*/
1.在这个过程中,生成两种类型的RDD,一种是shufferMapTask,另一种是resultTask 。
2.这个代码中生成了四个RDD,有两个阶段,
(1)一个是Shuffer前的相当与MapTask对中间数据进行计算(局部聚合)
(2)一个是Shuffer后的相当于ReduceTask进行计算写入到HDFS.(全局聚合)
(3)每个阶段又有最少两种RDD(map、flatMap、map可以合并),一个是a.txt文件的,另一个是b.txt文件的,所以这个过程生成了四个RDD
二、Stage
1、stage概念
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。Stage的划分,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;
如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage.
会根据RDD之间的依赖关系将DAG图划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中
2、为什么划分:
- 数据本地化
- 移动计算,而不是移动数据
- 保证一个Stage内不会发生数据移动
3、划分的好处
将窄依赖关系的尽量划分到一个Stage里面,来实现流水线计算提高效率。
4、RDD之间的依赖关系
-
Lineage:血统、遗传
- RDD最重要的特性之一,保存了RDD的依赖关系
- RDD实现了基于Lineage的容错机制
-
依赖关系
-
宽依赖(一对多)
宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
- groupByKey,
- join(有shuffle过程)
- partitionBy
-
窄依赖(一对一)
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- map,
- filter,
- union,
- join(无shuffle过程)
- mapPartitions,
- mapValues
-
宽依赖和窄依赖的区别:
首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。
第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
1.宽依赖往往对应着shuffle操作(多对一,汇总,多节点),需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
2.当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
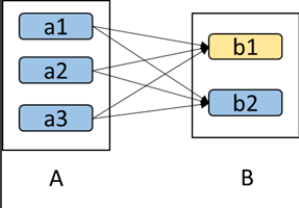
a. 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的; b. 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。 c. 如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
5、spark中如何划分stage
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为
- 一个父RDD的分区对应于一个子RDD的分区
- 两个父RDD的分区对应于一个子RDD 的分区。
宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作
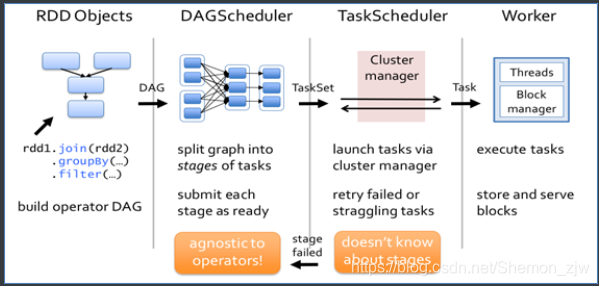
三、DAG工作原理
- 根据RDD之间的依赖关系,形成一个DAG(有向无环图)
- DAGScheduler将DAG划分为多个Stage
- 划分依据:是否发生宽依赖(Shuffle)
- 划分规则:从后往前,遇到宽依赖切割为新的Stage
- 每个Stage由一组并行的Task组成

四、Spark Shuffle过程
- 在分区之间重新分配数据
- 父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
- 中间结果写入磁盘
- 由子RDD拉取数据,而不是由父RDD推送
- 默认情况下,Shuffle不会改变分区数量
五、RDD持久化
-
RDD缓存机制:缓存数据至内存/磁盘,可大幅度提升Spark应用性能
- cache=persist(MEMORY)
- persist
-
缓存策略StorageLevel
- MEMORY_ONLY(默认)
- MEMORY_AND_DISK
- DISK_ONLY
-
缓存应用场景
- 从文件加载数据之后,因为重新获取文件成本较高
- 经过较多的算子变换之后,重新计算成本较高
- 单个非常消耗资源的算子之后
-
使用注意事项
- cache()或persist()后不能再有其他算子
- cache()或persist()遇到Action算子完成后才生效
-
检查点:类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile
- 检查点与缓存的区别
- 检查点会删除RDD lineage,而缓存不会
- SparkContext被销毁后,检查点数据不会被删除
六、RDD共享变量
共享变量出现的原因:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
1、广播变量
广播变量:
允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本,Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个操作分别发送。
val broadcastVar=sc.broadcast(Array(1,2,3)) //定义广播变量
broadcastVar.value //访问方式
注意事项:
1、Driver端变量在每个Executor每个Task保存一个变量副本
2、Driver端广播变量在每个Executor只保存一个变量副本
2、累加器
累加器:只允许added操作,常用于实现计数,调试时对作业执行过程中的事件进行计数
用法:
(1)通过在driver中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
(2)Spark闭包(函数序列化)里的excutor代码可以使用累加器的 += 方法(在Java中是 add )增加累加器的值。
(3)driver程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue() )来访问累加器的值。
object AccumulatorTest {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("accumulator")val sc = new SparkContext(conf)val accumulator = sc.accumulator(0); //创建accumulator并初始化为0val linesRDD = sc.textFile("src/data/hello.txt")val result = linesRDD.map(s => {accumulator.add(1) //有一条数据就增加1s})result.collect();println("words lines is :" + accumulator.value)sc.stop()}
}
//输出结果
words lines is :3
七、RDD分区设计
1、设计概念
- 分区大小限制为2GB
- 分区太少
- 不利于并发
- 更容易受数据倾斜影响
- groupBy, reduceByKey, sortByKey等内存压力增大
- 分区过多
- Shuffle开销越大
- 创建任务开销越大
- 经验
- 每个分区大约128MB
- 如果分区小于但接近2000,则设置为大于2000
2、数据倾斜
-
指分区中的数据分配不均匀,数据集中在少数分区中
- 严重影响性能
- 通常发生在groupBy,join等之后
-
解决方案
- 使用新的Hash值(如对key加盐)重新分区
八、数据源装载
1、装载CSV数据源
- 使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.csv")
val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(","))
val fields = lines.filter(l=>l.startsWith("user_id")==false).map(l=>l.split(",")) //移除首行,效果与上一行相同
- 使用SparkSession
val df = spark.read.format("csv").option("header", "true").load("file:///home/kgc/data/users.csv")
2、装载JSON数据源
- 使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.json")
//scala内置的JSON库
import scala.util.parsing.json.JSON
val result=lines.map(l=>JSON.parseFull(l))
- 使用SparkSession
val df = spark.read.format("json").load("file:///home/kgc/data/users.json")
九、基于RDD的Spark应用程序开发
-
典型开发步骤
-
开发环境
- IDEA+MAVEN+Scala
- pom.xml
1、演练一
- 词频计数
- 需求:统计HDFS上的某个文件的词频
- 数据格式:制表符作为分隔符
- 实现思路
- 首先需要将文本文件中的每一行转化成单词数组
- 其次是对每一个出现的单词进行计数
- 最后把所有相同单词的计数相加
//提交运行
spark-submit
--class com.kgc.bigdata.spark.core.WordCount
--master spark://hadoop000:7077
/home/hadoop/lib/spark-1.0.SNAPSHOT.jar /data/wordcount
VEN+Scala
- pom.xml
1、演练一
- 词频计数
- 需求:统计HDFS上的某个文件的词频
- 数据格式:制表符作为分隔符
- 实现思路
- 首先需要将文本文件中的每一行转化成单词数组
- 其次是对每一个出现的单词进行计数
- 最后把所有相同单词的计数相加
//提交运行
spark-submit
--class com.kgc.bigdata.spark.core.WordCount
--master spark://hadoop000:7077
/home/hadoop/lib/spark-1.0.SNAPSHOT.jar /data/wordcount
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- FPGA中浮点数的定点化笔记
FPGA中浮点数的定点化笔记 关于基本相关知识参考该博客 本文只针对FPGA中相关类型题目的做法思考整理,方便查看和复习,以后有时间再深入研究。 浮点数的定点化 FPGA 1.基础概念 浮点数: 简单来说,就是小数点的位置不是固定的 定点数: 简单来说,小数点的位置是固定的,也就是…...
2024/4/29 9:12:39 - Hbase基本语句
一、 HBase Shell操作1.1 基本操作1.进入HBase客户端命令行[@hadoop102 hbase]$ bin/hbase shell2.查看帮助命令hbase(main):001:0> help3.查看当前数据库中有哪些表hbase(main):002:0> list1.2 表的操作1.创建表hbase(main):002:0> create student,info2.插入数…...
2024/4/29 9:12:34 - 数据链路层CRC循环冗余检测实例
CRC循环冗余检测 目的:接收端通过检测码检测收到的的数据是否有差错,如果有差错,丢弃帧,没有差错,接受帧。 一、例:发送一个数据为1101011011,采用CRC生成多项***式P(X)=x^4+x+1。试求应添加在数据后的余数。 解释: 发送的帧=数据位M(X)+冗余位R(X) 本例子中: 1.数据位…...
2024/4/29 9:12:31 - rancher/ui 路由资源对应表
架构分析主要技术栈基础web框架: Ember.js构建脚手架: Ember CLIember-engines: http://ember-engines.com/国际化: 读配置文件打包工具: WebPackdom操作: jqueryNodejs框架: express生态+http-proxy图表使用的: echarts 和 d3样式: node-sass没有使用大的组件库,只是使用了一…...
2024/4/29 9:12:26 - 高速接口----7系列收发器GTP(1)
1. 前言最近在做以太网相关的东西,其中一个其中想要使用MAC通过光电转换模块来完成数据的收发。在Artix7系列FPGA当中,有GTP这个高速收发器。我手上的板子上的核心芯片是ZYNQ7015,这是一个带一个QUAD的ZYNQ FPGA,上面的收发器是GTP。对于其他稍微高端一点的ZYNQ上带有收发器…...
2024/5/5 6:36:21 - YApi内网部署
YApi内网部署 在showdoc开始收费的前提下,在公司服务器上搭建了YApi,下面记录下搭建的过程及遇到的问题 官方网址 参考地址 遇到的问题 1.点击开始部署后未出现如下页面我这边在安装的过程中卡在安装依赖库的页面,说是node下少了一个文件,我这边以为部署失败,进行重新部署…...
2024/4/29 9:12:17 - java实现单链表的增删改查
java实现单链表的增删改查 public class LinkListOrderTest {public static void main(String[] args) {}}class LinkListByOrder {// 创建一个头结点private HeroNode heroNode = new HeroNode(0, "", "");public HeroNode getHeroNode() {return heroNod…...
2024/5/1 12:06:36 - pip修改镜像源(Ubuntu18.04)
由于网络原因,pip的国外镜像源慢得要命,我们一般都要修改为国内镜像源,最近发现豆瓣镜像源挺不错的,可推荐给大家试试。最近为了学习TensorFlow2.0,安装了一个Ubuntu18.04版本,然后安装了anaconda。环境准备就绪之后,就可以开始敲代码实战,但在过程中,我们往往需要安装…...
2024/4/29 9:12:10 - mysql 查询加强
分页查询 基本语法 select 字段 from 表名 where子句 limit 起始位置,取出多少条记录(偏移量) mysql记录的编号是从 0 开始编号 快速入门案例 按照empno号降序取出3条数据 mysql> select * from emp; +-------+--------+--------...
2024/4/29 9:12:06 - 狂神说java笔记-zgc-ElasticSearch7.6
狂神说java笔记-zgc-ElasticSearch7.6elasticsearch:安装:1 解压,2 bin3 启动 目录:bin 启动文件config 配置文件log4j2 日志配置文件jvm.options java 虚拟机相关的配置elasticsearch.yml elasticsearch 的配置文件! 默认 9200 端口! 跨域!lib 相关jar包logs 日志!modu…...
2024/4/29 9:12:02 - 统计素数并求和
统计素数并求和统计给定整数M和N区间内素数的个数并对它们求和。 输入格式: 输入在一行中给出两个正整数M和N(1≤M≤N≤500)。 输出格式: 在一行中顺序输出M和N区间内素数的个数以及它们的和,数字间以空格分隔。 输入样例: 10 31 输出样例: 7 143本题中采用的判断素数的方法…...
2024/4/29 9:11:59 - leetcode两数之和 C语言
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。方法1:双循环/*** Note: The returned array must be malloced, assume caller …...
2024/4/29 9:11:55 - 快乐的JS正则表达式(三)
?的用途。小任务:匹配一段网址如var str = "http://www.123.com/";注意http也可以是httpsvar str = "http://i.cnblogs.com/"; var reg = /https?:\/\/[a-z]+\.[a-z0-9]+\.[a-z]+\//; console.log(reg.exec(str)); //["http://i.cnblogs.com/"…...
2024/4/29 9:11:51 - 《Java程序设计精典教程》习题答案 编著:胡伏湘,雷军环 清华大学出版社 第三章习题答案
一、简答题 1.类的修饰符包括哪些?各起什么作用? 包括访问控制符(表示被访问权限)、抽象类说明符abstract(说明是否是抽象类)、最终类说明符final(表示是否是最终类)。 2.什么是抽象类?什么是抽象方法?抽象方法与普通方法有什么不同? 以abstract作为关键字,如果有…...
2024/4/29 9:11:45 - 如何在VM中装CentOS系统
下载好Linux镜像,导入安装...
2024/4/30 12:19:44 - ES 基础语法 CRUD
以下语法是在ES7中测试的,低版本可能会有不兼容的问题 创建索引 PUT /article {"mappings": {"properties": {"title":{"type": "text","analyzer": "english"}}} }添加数据 POST article/_doc/1 {&qu…...
2024/4/29 9:11:38 - TCP和UDP协议详解(TCP三次握手和四次断开)
目录1、TCP和UDP协议2、TCP协议:3、TCP/IP三次握手4、TCP/IP四次断开5、常用的端口号:6、UDP协议:7、UDP报文的首部格式8、TCP传输协议和UDP传输协议的区别:1、TCP和UDP协议TCP:传输控制协议;UDP:用户数据报协议。2、TCP协议:TCP是面向连接的、可靠的进程到进程通信的协…...
2024/4/29 9:11:35 - ES6学习与总结(一)
个人总结 这次是我创建博客,第一次开始写博客。目前来讲我写博客的目的有两个 1,学习的总结。2,个人文档能力的提升。 话不多说开始 学习总结 一, ES6的全称ECMAScript6 二,变量的声明 1,let变量声明 a,let变量是局部变量(只在最近的一个{}中作用) b,let变量不能重复声…...
2024/4/29 9:11:31 - Java学习随笔——Java的语言基础
1.主类结构 主类:含有main()方法的类称为主类,方法中的属性成为局部变量,在通常的情况中我们将*类的属性成为类的全局变量(成员变量)*局部变量声明在方法体中,全局变量声明在类体中。 package Number; public class First{ //创建类sta…...
2024/4/29 2:38:02 - vue记录根据出生日期换算出年月日格式
...
2024/4/29 9:11:26
最新文章
- 进程的环境变量
进程的环境变量是进程中一组变量信息,包括系统环境变量、用户环境变量和进程环境变量。系统有全局的环境变量,在进程创建时,进程会继承系统的全局环境变量、当前登录用户的用户环境变量和父进程的环境变量。进程也可以有自己的环境变量。 环…...
2024/5/6 7:05:24 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 面试 Java 基础八股文十问十答第二十二期
面试 Java 基础八股文十问十答第二十二期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)ArrayList和Linked…...
2024/5/4 4:48:19 - 汽车疲劳测试试验平台技术要求(北重厂家)
汽车疲劳测试试验平台技术要求通常包括以下几个方面: 车辆加载能力:测试平台需要具备足够的承载能力,能够同时测试多种车型和不同重量的车辆。 动力系统:测试平台需要具备稳定可靠的动力系统,能够提供足够的力和速度来…...
2024/5/3 8:56:17 - 大数据学习十三天(hadhoop基础2)
一: MapReduce概述(了解) MapReduce是hadoop三大组件之一,是分布式计算组件 Map阶段 : 将数据拆分到不同的服务器后执行Maptask任务,得到一个中间结果 Reduce阶段 : 将Maptask执行的结果进行汇总,按照Reducetask的计算 规则获得一个唯一的结果 我们在MapReduce计算框架的使用过…...
2024/5/2 21:17:01 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/5 18:19:03 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/5 12:22:20 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/5 19:59:54 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/4 23:54:44 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/5 15:25:47 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/6 6:01:13 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/4 23:54:44 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/6 1:08:53 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/5 18:50:00 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/6 0:27:44 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/5 2:25:33 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/4 21:24:42 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/5 13:14:22 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/4 13:16:06 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/5 17:03:52 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/5 21:10:50 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/5 3:37:58 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/4 23:54:30 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/5 17:03:21 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/5 15:25:31 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57