Apache Kudu技术实践V1.0
1 APACHE KUDU简述
Apache Kudu是一个针对 Apache Hadoop 平台而开发的列式存储管理器。Kudu 共享 Hadoop 生态系统应用的常见技术特性: 它在 commodity hardware(商品硬件)上运行,horizontally scalable(水平可扩展),并支持 highly available(高可用)性操作。
官方网站:https://kudu.apache.org
1.1 APACHE KUDU架构组成介绍
1.1.1 基本概念
列数据存储 Columnar Data Store
Kudu是一种列数据储存结构,以强类型的列(strong-type column)储存数据。
高效读取
可选择单个列或者某个列的一部分来访问,可以在满足本身查询需要的状态下,选择最少的磁盘或者存储块来访问,相对于基于行的存储,更节省访问资源,更高效。
数据比较
由于给定的某一个列当中都是同样类型的数据,所以对于同一个量级的数据比较时,这种存储方式比混合类型存储的更具优势。
表Table
同理,一种数据设计模式schema,根据primary key来排序组织。一个表可以被分到若干个分片中,称为tablet。
分片Tablet
一个tablet是指表上一段连续的segment。一个特定的tablet会被复制到多个tablet服务器上,其中一个会被认为是leader tablet。每一个备份tablet都可以支持读取、写入请求。
分片服务器 Tablet Server
负责为客户端储存和提供tablets。只有Leader Tablet可以写入请求,其他的tablets只能执行请求。
Master
Master负责追踪tablets、tablet severs、catalog table和其他与集群相关的metadata。另外也为客户端协调metadata的操作。
Raft Consensus算法
类似半数选举机制。例如,如果3个副本中有2个副本或5个副本中有3个副本可用,则可用
Catalog Table
Kudu的metadata的中心位置,存储表和tablet的信息,客户端可以通过master用客户端api来访问。
逻辑复制 Logical Replication
Kudu并是不是在硬盘数据上做复制的,而是采取了逻辑复制的办法,这有以下一些好处:
• 尽管insert和update需要通过网络对数据做transmit,但是delete操作不需要移动任何数据。Delete操作的请求会发送到每一个tablet server上,在本地做删除操作。
• 普通的物理操作,比如数据压缩,并不需要通过网络做数据transmit,但不同于HDFS,每个请求都需要通过网络把请求传送到各个备份节点上来满足操作需要。
• 每个备份不需要同时进行操作,降低写入压力,避免高延时。
随机写入效率
在内存中每个tablet分区维护一个MemRowSet来管理最新更新的数据,当尺寸大于一定大小之后会flush到磁盘上行成DiskRowSet,多个DiskRowSet会在适当的时候做归并操作。 这些被flush到磁盘的DiskRowSet数据分为两种,一种是Base数据,按列式存储格式存在,一旦生成不再修改,另一种是Delta文件,储存Base中有更新的数据,一个Base文件可以对应多个Delta文件。
Delta文件的存在使得检索过程需要额外的开销,这些Delta文件是根据被更新的行在Base文件中的位移来检索的,而且做合并时也是有选择的进行。
此外DRS(Distributed Resource Scheduler)自身也会合并,为了保障检索延迟的可预测性。Kudu的DRS默认以32MB为单位进行拆分,Compaction过程是为了对内容进行排序重组,减少不同DRS之间key的overlap,进而在检索的时候减少需要参与检索的DRS的数量。
1.1.2 整体框架
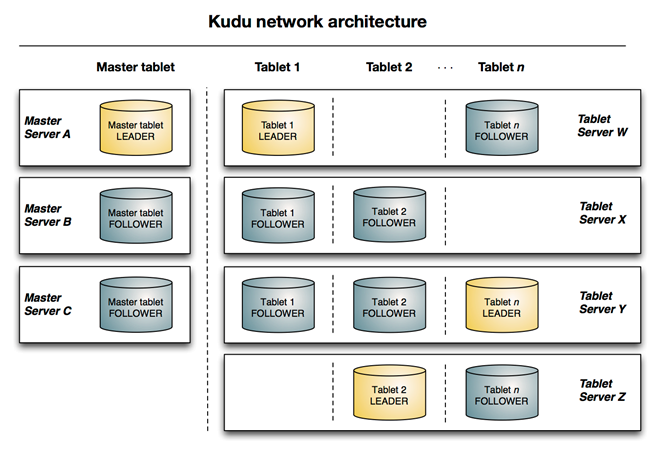
1.2 APACHE KUDU的特点
Kudu的主要特点:
- OLAP工作的快速处理;
- 与MapReduce,Spark和其他Hadoop生态系统组件集成
- 与Apache Impala(incubating)紧密集成,使其与Apache Parquet 一起使用 HDFS 成为一个很好的可变的替代方案;
- 同时运行顺序和随机工作负载的强大性能。
- 高可用性。tablet server和master利用Raft Consensus算法保证节点的可用。例如,如果3个副本中有2个副本或5个副本中有3个副本可用,则可用
- 使用 Cloudera Manager 轻松维护和管理(与impala同为CM开发)
1.3 APACHE KUDU的缺陷
Kudu的优点同时也是Kudu的缺点。只有在与CDH、Impala结合使用的时候,它才能发挥最大的优势,单独摘出来在Apache集群中部署使用的时候,优势会降低很多。
1.4 APACHE KUDU应用场景
- 实时更新的应用。刚刚到达的数据就马上要被终端用户使用访问到。
- 时间序列相关的应用,需要同时支持:
根据海量历史数据查询;
必须非常快地返回关于单个实体的细粒度查询。 - 实时预测模型的应用,支持根据所有历史数据周期地更新模型。
1.5 APACHE KUDU各个端口
| 端口名称 | 默认端口 | 说明 |
|---|---|---|
| ntp | 123 | ntp端口号 |
| Kudu-master | 7051 | 主从机通信他端口号 |
| kudu | 8051 | Kudu Web端口 |
1.6 中间件版本选取
| 中间件名称 | 版本号 |
|---|---|
| CentOS | CentOS 6.8 |
| Java | 1.8.0_121 |
| ntp | 4 |
| Kudu | 1.2.0 |
2 APACHE KUDU部署
2.1 环境准备
本次技术实践安装Kudu集群,安装在3台虚拟机上:hadoop102、hadoop103、hadoop104
由于Kudu在Linux(CentOS或者Ubantu)需要编译,这里我直接下载rpm包进行安装部署。不需要kudu-debuginfo包,已隐去。
本次Kudu的安装规划:
| host | kudu-master | kudu-tserver |
|---|---|---|
| hadoop102 | * | |
| hadoop103 | * | |
| hadoop104 | * |
2.1.1 CentOS6.8
CentOS6.8安过程省略。预先创建用户/用户组zhouchen
预先安装jdk1.8.0_92 +
预先安装ntp
2.1.2 关闭防火墙-root
针对CentOS7以下
1.查看防火墙状态
service iptables status
2.停止防火墙
service iptables stop
3.启动防火墙
service iptables start
2.1.3 ntp
Kudu安装需要用到ntp服务
1.检查ntp服务状态
[root@hadoop102 software]# service ntpd status
ntpd (pid 6014) 正在运行...
2.检查ntp时间
[root@hadoop102 software]# ntptime
ntp_gettime() returns code 0 (OK)time e2b93ca0.4836eb34 Wed, Jul 15 2020 16:28:16.282, (.282088806),maximum error 513259 us, estimated error 10946 us, TAI offset 0
ntp_adjtime() returns code 0 (OK)modes 0x0 (),offset 1012.483 us, frequency -5.592 ppm, interval 1 s,maximum error 513259 us, estimated error 10946 us,status 0x2001 (PLL,NANO),time constant 7, precision 0.001 us, tolerance 500 ppm,
2.2 集群安装
2.2.1 rpm安装
1.主机安装(hadoop102)
主机需要的安装包:
kudu-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-client0-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-client-devel-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-master-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
[root@hadoop102 software]# rpm -ivh --nodeps kudu*
warning: kudu-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID e8f86acd: NOKEY
Preparing... ########################################### [100%]1:kudu-client0 ########################################### [ 25%]2:kudu ########################################### [ 50%]3:kudu-master ########################################### [ 75%]4:kudu-client-devel ########################################### [100%]
2.从机安装(hadoop103/hadoop104)
从机需要的安装包:
kudu-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-client0-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-client-devel-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
kudu-tserver-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm
[root@hadoop103 software]# rpm -ivh --nodeps kudu*
warning: kudu-1.2.0+cdh5.10.0+0-1.cdh5.10.0.p0.56.el6.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID e8f86acd: NOKEY
Preparing... ########################################### [100%]1:kudu-client0 ########################################### [ 25%]2:kudu ########################################### [ 50%]3:kudu-tserver ########################################### [ 75%]4:kudu-client-devel ########################################### [100%]
2.2.2 集群配置
*三台机器都需要修改如下配置:
1.修改Kudu主机配置(hadoop102)
[root@hadoop102 software]# vim /etc/kudu/conf/master.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-master.
--fromenv=rpc_bind_addresses
--fromenv=log_dir--fs_wal_dir=/opt/module/kudu-1.2.0/master
--fs_data_dirs=/opt/module/kudu-1.2.0/master
2.修改Kudu从机配置(hadoop103/hadoop104)
[root@hadoop103 software]# vim /etc/kudu/conf/tserver.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-tserver.
--fromenv=rpc_bind_addresses
--fromenv=log_dir--fs_wal_dir=/opt/module/kudu-1.2.0/tserver
--fs_data_dirs=/opt/module/kudu-1.2.0/tserver
--tserver_master_addrs=hadoop102:7051
3.创建主机目录
[root@hadoop102 module]# mkdir -p /opt/module/kudu-1.2.0/master
[root@hadoop102 module]# chown zhouchen:zhouchen -R kudu-1.2.0/
[root@hadoop102 module]# chmod 777 -R kudu-1.2.0/
4.创建从机目录
[root@hadoop103 module]# mkdir -p /opt/module/kudu-1.2.0/tserver
[root@hadoop103 module]# chown zhouchen:zhouchen -R kudu-1.2.0/
[root@hadoop103 module]# chmod 777 -R kudu-1.2.0/
2.2.3 集群启动
主机启动(hadoop102):
[root@hadoop102 module]# sudo service kudu-master start
Started Kudu Master Server (kudu-master): [确定]
从机启动(hadoop103/hadoop104):
[root@hadoop102 kudu-1.2.0]# ssh hadoop103 sudo service kudu-tserver start
Started Kudu Tablet Server (kudu-tserver): [确定]
[root@hadoop102 kudu-1.2.0]# ssh hadoop104 sudo service kudu-tserver start
Started Kudu Tablet Server (kudu-tserver): [确定]
2.2.4 安装检查
1.界面访问 http://Hadoop102:8051/
2.查看服务状态
主机状态:
[zhouchen@hadoop102 ~]$ sudo service kudu-master status
Kudu Master Server is running [确定]
从机状态:
[zhouchen@hadoop102 ~]$ ssh hadoop103 sudo service kudu-tserver status
Kudu Tablet Server is running [确定][zhouchen@hadoop102 ~]$ ssh hadoop104 sudo service kudu-tserver status
Kudu Tablet Server is running [确定]
3 APACHE KUDU的基本操作
- CREATE/ALTER/DROP TABLE
Impala支持使用Kudu作为持久层创建、修改和删除表。这些表与Impala中的其他表遵循相同的内部/外部方法,允许灵活的数据摄入和查询 - INSERT
可以使用与任何其他Impala表相同的语法(例如使用HDFS或HBase进行持久化的语法)将数据插入Impala中的Kudu表。 - UPDATE/DELETE
Impala支持UPDATE和DELETE SQL命令来逐行或批量修改Kudu表中的现有数据。 选择SQL命令的语法,使其与现有标准尽可能兼容。 除了简单的DELETE或UPDATE命令之外,还可以在子查询中使用FROM子句指定复杂的联接。 - 灵活的分区
与Hive中的表分区类似,Kudu允许您通过哈希或范围将预动态拆分表动态划分为预定义数量的数位板,以便在整个群集中平均分配写入和查询。 您可以按任意数量的主键列,任意数量的哈希和可选的拆分行列表进行分区。 请参阅架构设计。 - 平行扫描
为了在现代硬件上实现最高的性能,Impala使用的Kudu客户端可以并行扫描多个分片。
[zhouchen@hadoop102 lib]$ kudu table list;
Invalid argument: must provide master_addresses
- 高效查询
在可能的情况下,Impala将谓词评估下推至Kudu,以便对谓词的评估尽可能接近数据。 在许多工作负载中,查询性能可与Parquet相当
4 APACHE KUDU与IMPALA
通过Impala使用Kudu可以新建内部表和外部表两种:
• 内部表(Internal Table):事实上是属于Impala管理的表,当删除时会确确实实地删除表结构和数据。在Impala中建表时,默认建的是内部表。
• 外部表(External Table):不由Impala管理,当删除这个表时,并不能从源位置将其删除,只是接触了Kudu到Impala之间对于这个表的关联关系
4.1 创建一个简单的KUDU表
CREATE TABLE my_second_table
(id BIGINT,name STRING,PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses' = 'hadoop102:7051', 'kudu.table_name' = 'my_second_table','kudu.num_tablet_replicas' = '1'
);
建表语句中,默认第一个就是Primary Key,是个not null列,在后面的kudu.key_columns中列出,这边至少写一个。
• storage_handler:选择通过Impala访问kudu的机制,必须填成com.cloudera.kudu.hive.KuduStorageHandler
• kudu.table_name:Impala为Kudu建(或者关联的)的表名
• kudu.master_addresses:Impala需要访问的Kudu master列表
• kudu.key_columns:Primary key列表
4.2 插入数据
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");
Impala默认一次同时最多插入1024条记录,作为一个batch
4.3 更新数据
UPDATE my_first_table SET name="bob" where id = 3;
4.4 删除数据
DELETE FROM my_first_table WHERE id < 3;
4.5 修改表属性
ALTER TABLE my_first_table RENAME TO employee;//重命名ALTER TABLE employee SET TBLPROPERTIES('kudu.master_addresses' = 'hadoop102:7051');//更改kudu master addressALTER TABLE employee SET TBLPROPERTIES('EXTERNAL' = 'TRUE');//将内部表变为外部表
4.6 删除表
由于Kudu是作为存储中间件,而impala只是作为操作中间件,所以需要同时在Kudu与impala删除表。
- Kudu删除表
[zhouchen@hadoop102 lib]$ kudu table delete hadoop102 my_first_table
- Impala删除表
[hadoop102:21000] > drop table my_first_table;
5 APACHE KUDU与SPARK
5.1 SPARK DF操作KUDU
5.1.1 所需依赖
添加kudu依赖jar包
<dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-client</artifactId><version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 -->
<dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-spark2_2.11</artifactId><version>1.7.0</version>
</dependency>
5.1.2 Spark创建Kudu表
import java.utilimport org.apache.kudu.client.CreateTableOptions
import org.apache.kudu.spark.kudu._
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}//创建kudu表
object KuduSparkTest1 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]")val spark = SparkSession.builder().config(sparkConf).getOrCreate()val sparkConetxt = spark.sparkContextval kuduContext = new KuduContext("hadoop002,hadoop003", sparkConetxt)val tableFields = (Array(new StructField("id", IntegerType, false), new StructField("name", StringType)))//id为主键val arrayList = new util.ArrayList[String]()arrayList.add("id")val b = new CreateTableOptions().setNumReplicas(1).addHashPartitions(arrayList, 3)kuduContext.createTable("test_table", StructType(tableFields), Seq("id"), b)}
}
将代码打成jar包 使用集群运行 运行完毕后查看UI界面

成功创建test_table测试表
5.1.3 Spark查询Kudu表
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession//查询kudu
object KuduSparkTest2 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]")val spark = SparkSession.builder().config(sparkConf).getOrCreate()val df = spark.read.options(Map("kudu.master" -> "hadoop001 ", "kudu.table" -> "test_table")).format("org.apache.kudu.spark.kudu").load()df.show()}
}
查询出来返回值是个dataframe,之后就可以使用dataframe api进行操作
5.1.4 Spark增删改Kudu表
object KuduSparkTest3 {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf()val spark = SparkSession.builder().config(sparkConf).getOrCreate()val sparkContext = spark.sparkContextval kuduContext = new KuduContext("hadoop002,hadoop003", sparkContext)val testTableDF = spark.read.options(Map("kudu.master" -> "hadoop001 ", "kudu.table" -> "test_table")).format("org.apache.kudu.spark.kudu").load()val flag = kuduContext.tableExists("test_table") //判断表是否存在if (flag) {import spark.implicits._val tuple = (1, "张三")val df = sparkContext.makeRDD(Seq(tuple)).toDF("id","name")kuduContext.insertRows(df, "test_table") //往test_table表中插入 id为1 name为张三的数据testTableDF.show()val tuple2 = (1, "李四")val df2 = sparkContext.makeRDD(Seq(tuple2)).toDF("id","name")kuduContext.updateRows(df2, "test_table") //将test_table表中主键id为1 的数据name值修改为李四testTableDF.show()kuduContext.deleteRows(df2, "test_table") //将test_table表中的主键id为1 name值为李四的数据删除testTableDF.show()}}
}
效果图
5.2 SPARK STREAMING实时写KUDU例子
注意:spark创建的kudu表在impala里不会显示,但确实存在,在impala创建外部表指定kudu表即可
5.2.1 pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>education-online</artifactId><groupId>com.atguigu</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>com_atguigu_spark_kudu</artifactId><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><scope>provided</scope><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><scope>provided</scope><version>${spark.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><scope>provided</scope><version>${scala.version}</version></dependency><dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-client</artifactId><version>1.10.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.29</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 --><dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-spark2_2.11</artifactId><version>1.7.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><!-- <scope>provided</scope>--><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><scope>provided</scope><version>${spark.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.1</version><executions><execution><id>compile-scala</id><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>test-compile-scala</id><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><configuration><archive><manifest></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin></plugins></build>
</project>
5.2.2 先使用impala创建kudu表
[hadoop003:21000] > CREATE TABLE register_table(> id INTEGER,> servicetype STRING,> count BIGINT,> PRIMARY KEY(id)> )> PARTITION BY HASH PARTITIONS 3> STORED AS KUDU;
5.2.3 准备工具类
package util;import java.io.InputStream;
import java.util.Properties;/**** 读取配置文件工具类*/
public class ConfigurationManager {private static Properties prop = new Properties();static {try {InputStream inputStream = ConfigurationManager.class.getClassLoader().getResourceAsStream("comerce.properties");prop.load(inputStream);} catch (Exception e) {e.printStackTrace();}}//获取配置项public static String getProperty(String key) {return prop.getProperty(key);}//获取布尔类型的配置项public static boolean getBoolean(String key) {String value = prop.getProperty(key);try {return Boolean.valueOf(value);} catch (Exception e) {e.printStackTrace();}return false;}
}package util;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;
import java.io.Serializable;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;/*** 德鲁伊连接池*/
public class DataSourceUtil implements Serializable {public static DataSource dataSource = null;static {try {Properties props = new Properties();props.setProperty("url", ConfigurationManager.getProperty("jdbc.url"));props.setProperty("username", ConfigurationManager.getProperty("jdbc.user"));props.setProperty("password", ConfigurationManager.getProperty("jdbc.password"));props.setProperty("initialSize", "5"); //初始化大小props.setProperty("maxActive", "10"); //最大连接props.setProperty("minIdle", "5"); //最小连接props.setProperty("maxWait", "60000"); //等待时长props.setProperty("timeBetweenEvictionRunsMillis", "2000");//配置多久进行一次检测,检测需要关闭的连接 单位毫秒props.setProperty("minEvictableIdleTimeMillis", "600000");//配置连接在连接池中最小生存时间 单位毫秒props.setProperty("maxEvictableIdleTimeMillis", "900000"); //配置连接在连接池中最大生存时间 单位毫秒props.setProperty("validationQuery", "select 1");props.setProperty("testWhileIdle", "true");props.setProperty("testOnBorrow", "false");props.setProperty("testOnReturn", "false");props.setProperty("keepAlive", "true");props.setProperty("phyMaxUseCount", "100000");
// props.setProperty("driverClassName", "com.mysql.jdbc.Driver");dataSource = DruidDataSourceFactory.createDataSource(props);} catch (Exception e) {e.printStackTrace();}}//提供获取连接的方法public static Connection getConnection() throws SQLException {return dataSource.getConnection();}// 提供关闭资源的方法【connection是归还到连接池】// 提供关闭资源的方法 【方法重载】3 dqlpublic static void closeResource(ResultSet resultSet, PreparedStatement preparedStatement,Connection connection) {// 关闭结果集// ctrl+alt+m 将java语句抽取成方法closeResultSet(resultSet);// 关闭语句执行者closePrepareStatement(preparedStatement);// 关闭连接closeConnection(connection);}private static void closeConnection(Connection connection) {if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}private static void closePrepareStatement(PreparedStatement preparedStatement) {if (preparedStatement != null) {try {preparedStatement.close();} catch (SQLException e) {e.printStackTrace();}}}private static void closeResultSet(ResultSet resultSet) {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}}
}package utilimport java.sql.{Connection, PreparedStatement, ResultSet}trait QueryCallback {def process(rs: ResultSet)
}class SqlProxy {private var rs: ResultSet = _private var psmt: PreparedStatement = _/*** 执行修改语句** @param conn* @param sql* @param params* @return*/def executeUpdate(conn: Connection, sql: String, params: Array[Any]): Int = {var rtn = 0try {psmt = conn.prepareStatement(sql)if (params != null && params.length > 0) {for (i <- 0 until params.length) {psmt.setObject(i + 1, params(i))}}rtn = psmt.executeUpdate()} catch {case e: Exception => e.printStackTrace()}rtn}/*** 执行查询语句* 执行查询语句** @param conn* @param sql* @param params* @return*/def executeQuery(conn: Connection, sql: String, params: Array[Any], queryCallback: QueryCallback) = {rs = nulltry {psmt = conn.prepareStatement(sql)if (params != null && params.length > 0) {for (i <- 0 until params.length) {psmt.setObject(i + 1, params(i))}}rs = psmt.executeQuery()queryCallback.process(rs)} catch {case e: Exception => e.printStackTrace()}}def shutdown(conn: Connection): Unit = DataSourceUtil.closeResource(rs, psmt, conn)
}
5.2.4 Spark Streaming写Kudu
import java.sql.ResultSet
import java.{lang, util}import _root_.util.{DataSourceUtil, QueryCallback, SqlProxy}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kudu.client.KuduPredicate.ComparisonOp
import org.apache.kudu.client.{KuduClient, KuduPredicate}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutableobject KuduSparkTest4 {private val groupid = "register_group_test"private val KUDU_MASTERS = "hadoop102"def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName(this.getClass.getSimpleName).set("spark.streaming.kafka.maxRatePerPartition", "100").set("spark.streaming.stopGracefullyOnShutdown", "true").set("spark.streaming.backpressure.enabled", "true")val ssc = new StreamingContext(conf, Seconds(3))val sparkContext = ssc.sparkContextval topics = Array("register_topic")val kafkaMap: Map[String, Object] = Map[String, Object]("bootstrap.servers" -> "hadoop001:9092,hadoop002:9092,hadoop003:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> groupid,"auto.offset.reset" -> "earliest","enable.auto.commit" -> (false: lang.Boolean))sparkContext.hadoopConfiguration.set("fs.defaultFS", "hdfs://nameservice1") //设置高可用地址sparkContext.hadoopConfiguration.set("dfs.nameservices", "nameservice1") //设置高可用地址val sqlProxy = new SqlProxyval offsetMap = new mutable.HashMap[TopicPartition, Long]()val client = DataSourceUtil.getConnectiontry {sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback {override def process(rs: ResultSet): Unit = {while (rs.next()) {val model = new TopicPartition(rs.getString(2), rs.getInt(3))val offset = rs.getLong(4)offsetMap.put(model, offset)}rs.close() //关闭游标}})} catch {case e: Exception => e.printStackTrace()} finally {sqlProxy.shutdown(client)}//设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) {KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap))} else {KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap))}val resultDStream = stream.mapPartitions(partitions => {partitions.map(item => {val line = item.value()val arr = line.split("\t")val id = arr(1)val app_name = id match {case "1" => "PC_1"case "2" => "APP_2"case _ => "Other_3"}(app_name, 1)})}).reduceByKey(_ + _)resultDStream.foreachRDD(rdd => {rdd.foreachPartition(parititon => {val kuduClient = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build //获取kudu连接val kuduTable = kuduClient.openTable("impala::default.register_table") //获取kudu tableval schema = kuduTable.getSchema//根据当前表register_table 将相应需要查询的列放到arraylist中 表中有id servicetype count字段val projectColumns = new util.ArrayList[String]()projectColumns.add("id")projectColumns.add("servicetype")projectColumns.add("count")parititon.foreach(item => {var resultCount: Long = item._2 //声明结果值 默认为当前批次数据val appname = item._1.split("_")(0)val id = item._1.split("_")(1).toIntval eqPred = KuduPredicate.newComparisonPredicate(schema.getColumn("servicetype"),ComparisonOp.EQUAL, appname); //先根据设备名称过滤 过滤条件为等于app_name的数据val kuduScanner = kuduClient.newScannerBuilder(kuduTable).addPredicate(eqPred).build()while (kuduScanner.hasMoreRows) {val results = kuduScanner.nextRows()while (results.hasNext) {val result = results.next()//符合条件的数据有值则 和当前批次数据进行累加val count = result.getLong("count") //获取表中count值resultCount += count}}//最后将结果数据重新刷新到kuduval kuduSession = kuduClient.newSession()val upset = kuduTable.newUpsert() //调用upset 当主键存在数据进行修改操作 不存在则新增val row = upset.getRowrow.addInt("id", id)row.addString("servicetype", appname)row.addLong("count", resultCount)kuduSession.apply(upset)kuduSession.close()})kuduClient.close()})})stream.foreachRDD(rdd => {val sqlProxy = new SqlProxy()val client = DataSourceUtil.getConnectiontry {val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRangesfor (or <- offsetRanges) {sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)",Array(groupid, or.topic, or.partition.toString, or.untilOffset))}} catch {case e: Exception => e.printStackTrace()} finally {sqlProxy.shutdown(client)}})ssc.start()ssc.awaitTermination()}
}
5.2.5 效果展示
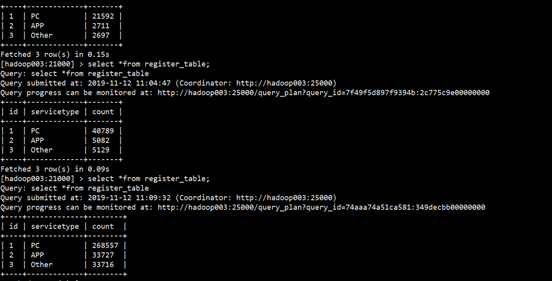
业务为根据设备实时统计count数需要基于历史数据,控制速度每秒1000条
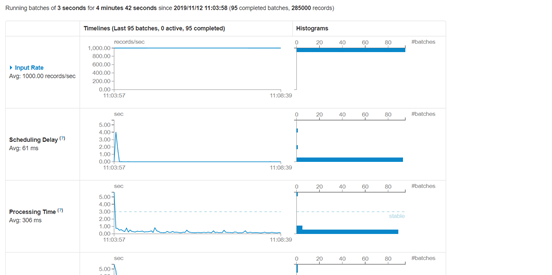
数据无积压
impala查询展示
6 APACHE KUDU常见问题分析
6.1 APACHE KUDU服务启动失败
启动失败:
[zhouchen@hadoop102 ~]$ sudo service kudu-master start
Failed to start Kudu Master Server. Return value: 1 [失败]
[zhouchen@hadoop102 ~]$ ssh hadoop103 sudo service kudu-tserver start
Failed to start Kudu Tablet Server. Return value: 1 [失败]
[zhouchen@hadoop102 ~]$ ssh hadoop104 sudo service kudu-tserver start
Failed to start Kudu Tablet Server. Return value: 1 [失败]
检查ntp服务:
[zhouchen@hadoop102 ~]$ ntptime
ntp_gettime() returns code 5 (ERROR)time e2b95039.ced65000 Wed, Jul 15 2020 17:51:53.807, (.807958),maximum error 16000000 us, estimated error 16000000 us, TAI offset 0
ntp_adjtime() returns code 5 (ERROR)modes 0x0 (),offset 0.000 us, frequency -7.097 ppm, interval 1 s,maximum error 16000000 us, estimated error 16000000 us,status 0x41 (PLL,UNSYNC),time constant 7, precision 1.000 us, tolerance 500 ppm,
问题原因是ntp时间同步失败,重启ntp服务让时间同步正常:
[zhouchen@hadoop102 ~]$ xcall sudo service ntpd stop
要执行的命令是:sudo service ntpd stop
---------------------hadoop102------------------
关闭 ntpd:[确定]
---------------------hadoop103------------------
关闭 ntpd:[确定]
---------------------hadoop104------------------
关闭 ntpd:[确定]
[zhouchen@hadoop102 ~]$ xcall sudo service ntpd start
要执行的命令是:sudo service ntpd start
---------------------hadoop102------------------
正在启动 ntpd:[确定]
---------------------hadoop103------------------
正在启动 ntpd:[确定]
---------------------hadoop104------------------
正在启动 ntpd:[确定]
[zhouchen@hadoop102 ~]$ xcall sudo service ntpd status
要执行的命令是:sudo service ntpd status
---------------------hadoop102------------------
ntpd (pid 6051) 正在运行...
---------------------hadoop103------------------
ntpd (pid 5084) 正在运行...
---------------------hadoop104------------------
ntpd (pid 5081) 正在运行...
再次检查ntp服务:
[zhouchen@hadoop102 ~]$ xcall sudo ntptime
要执行的命令是:sudo ntptime
---------------------hadoop102------------------
ntp_gettime() returns code 0 (OK)time e2b95067.a7b794f0 Wed, Jul 15 2020 17:52:39.655, (.655145271),maximum error 8056622 us, estimated error 983 us, TAI offset 0
ntp_adjtime() returns code 0 (OK)modes 0x0 (),offset -2686.243 us, frequency -7.102 ppm, interval 1 s,maximum error 8056622 us, estimated error 983 us,status 0x2001 (PLL,NANO),time constant 6, precision 0.001 us, tolerance 500 ppm,
---------------------hadoop103------------------
ntp_gettime() returns code 0 (OK)time e2b95067.e1fc6d50 Wed, Jul 15 2020 17:52:39.882, (.882758322),maximum error 8145031 us, estimated error 10565 us, TAI offset 0
ntp_adjtime() returns code 0 (OK)modes 0x0 (),offset 28850.633 us, frequency -2.867 ppm, interval 1 s,maximum error 8145031 us, estimated error 10565 us,status 0x2001 (PLL,NANO),time constant 6, precision 0.001 us, tolerance 500 ppm,
---------------------hadoop104------------------
ntp_gettime() returns code 0 (OK)time e2b95068.272ce888 Wed, Jul 15 2020 17:52:40.153, (.153029112),maximum error 1078291 us, estimated error 10442 us, TAI offset 0
ntp_adjtime() returns code 0 (OK)modes 0x0 (),offset -29306.464 us, frequency -2.542 ppm, interval 1 s,maximum error 1078291 us, estimated error 10442 us,status 0x2001 (PLL,NANO),time constant 6, precision 0.001 us, tolerance 500 ppm,
启动Kudu成功:
[zhouchen@hadoop102 ~]$ sudo service kudu-master start
Started Kudu Master Server (kudu-master): [确定]
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- javascript中实现跨域的方式总结
第一种方式:jsonp请求;jsonp的原理是利用第二种方式:document.domain;这种方式用在主域名相同子域名不同的跨域访问中 第三种方式:window.name;window的name属性有个特征:在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个window.name的,每个页面对win…...
2024/4/15 16:55:58 - makefile中VPATH和vpath
makefile中可以通过VPATH和vpath来设置目标文件和以来文件的搜索路径. 1.VPATH makefile中目标文件和以来文件可以加上路径,但是最好能够让make自动去寻找.通过设置给VPATH变量赋值,当前目录下找不到对应文件时,便会到VPATH设置的路径去寻找.也就是说当前目录搜索的优先级最高…...
2024/4/23 20:43:30 - usleep(0)与sched_yield()
结论:如果你是为了耗掉一个机器周期 ,那直接asm ("nop") ,如果是为了让权,建议把 所有使用 usleep(0) 换成 sched_yield() ;sched_yield() 的man手册:SYNOPSIS#include <sched.h>int sched_yield(void);DESCRIPTIONsched_yield() causes the calling …...
2024/4/20 11:06:30 - Nodejs: redis客户端报错 Redis connection gone from end event
错误的stack trace:Error: Error: Redis connection gone from end event.at RedisClient.flush_and_error (/server/node_modules/redis/index.js:142:13)at RedisClient.connection_gone (/server/node_modules/redis/index.js:475:10)at Socket.<anonymous> (/server/…...
2024/5/7 14:01:32 - C#设置窗体控件自适应
(1)dock或者anchor,命令控件在调整大小时动作的两个属性就是“Dock”和“Anchor”。为每个控件设置anchor是可行的。Dock和Anchor通过将控件连接到它们父窗体的某个位置,而免除了使应用程序具有不可预知界面的麻烦。最好的一点就是设立这些属性不需要任何手写代码。所有事情…...
2024/5/7 15:48:48 - 5. 最长回文子串
5. 最长回文子串 动态规划申请一个二维boolean数组,若s的第i个字符等于第j个字符,那么dp[i][j]=true,由里到外推回文子串,这里就是子问题 我们取两个指针left和right来标记回文串的左右边界index 转移方程:情况1:s.charAt(left)==s.charAt(right)并且dp[left+1][right-1]…...
2024/5/6 0:14:26 - Tensorflow ——tf.slice和tf.gather
Tensorflow ——tf.slice和tf.gathertf.gather 和 tf.slice都可以根据索引寻找相应维度的子集。tf.slice(input,begin,size,name=None) 按照指定的下标范围抽取连续区域的子集,每个维度一一对应。 tf.gather(input,begin,size.name=None) 按照指定的下标集合从 axis=0 中抽…...
2024/4/26 0:57:27 - rosbag filter 根据时间和topic对包进行分割(过滤)
0.前言 本文主要讲解rosbag filter 命令的使用 可以用于对已经记好的包的分割,筛选需要的topic 1.根据topic过滤 1.1过滤单个topic rosbag filter my.bag only-tf.bag "topic == /tf"1.2过滤多个topic rosbag filter input.bag output.bag "topic == /velodyne_…...
2024/5/8 2:44:00 - 2020牛客暑期多校训练营(第六场)(线性代数+找规律)
2020牛客暑期多校训练营(第六场)(线性代数+找规律) 时间限制:C/C++ 2秒,其他语言4秒 空间限制:C/C++ 524288K,其他语言1048576K 64bit IO Format: %lld judge:牛客 题目描述 Roundgod is obsessive about linear algebra. Let A={0,1}A=\{0,1\}A={0,1}, everyday she …...
2024/5/7 21:36:12 - 2019小米IoT安全峰会-曾颖涛《蓝牙安全之第二战场》
此次大会的第六个重磅议题来自小米AIoT安全实验室研究员-曾颖涛,他给大家带来的议题是《蓝牙安全之第二战场》。今天的议题主要想给大家分享一下蓝牙通讯中比较少有人关注到的一些安全隐患。将从四个方面进行探讨,首先是蓝牙设备的设备联动。所谓的设备联动其实是依靠于拥有蓝…...
2024/5/7 16:04:07 - python多进程-异步
python多进程异步 异步队列问题 进程池内部传递数据结构 有一个全局管理的Manager需要声明 异步调用必须使用这个SyncManager 单独开进程是同步的,所以不需要SyncManager注: 队列的put方法和get方法都是阻塞的import multiprocessing import os, time, randomdef worker(que):…...
2024/5/8 3:40:49 - 静态图编程框架keras-学习心得以及知识点总结之keras网络核心层
全连接层,激活层,dropout层,flatten层,input层,reshape层,permute层:http://burningcloud.cn/article/49/index.html 关于层的特殊使用,RepeatVector,Lambda,ActivityRegularization,Masking ,SpatialDropout1(2)(3)D:http://burningcloud.cn/article/50/index.ht…...
2024/5/7 21:04:14 - python excel读写库 xlrd,xlwt用法总结
excel读写xlrd xlrd 使用xlrd import xlrd打开表格 book=xlrd.open_workbook("test.xlsx")#不带路径默认在文件目录下找通过索引和sheet名来打开sheet表 st1=book.sheet_by_index(0)#通过索引 st=book.sheet_by_name("明细")#通过sheet名 print(st)# <x…...
2024/5/7 16:36:35 - python错误--pickle.load--TypeError: a bytes-like object is required, not ‘str‘--python3读取python2文件
在学习开源代码印刷汉字识别(CPS-OCR-Engine)时,采用pickle.load读取汉字数据时存在问题,代码如下: def get_label_dict():f=open(./chinese_labels,r);label_dict = pickle.load(f);f.close();return label_dict;错误信息如下: File "E:/work/系统小工具/ModifyFil…...
2024/4/19 5:24:24 - HTML-表单标签详解
HTML标签:表单标签 * 表单:* 概念:用于采集用户输入的数据的。用于和服务器进行交互。* form:用于定义表单的。可以定义一个范围,范围代表采集用户数据的范围* 属性:* action:指定提交数据的URL* method:指定提交方式* 分类:一共7种,2种比较常用* get:1. 请求参数会在…...
2024/5/7 22:48:38 - FANUC机器人超行程报警时的解决办法
FANUC机器人在手动或自动运行意外出现超行程报警时,可以采取以下两种解决办法(供参考):手动T1模式下,同时按住示教器的安全开关和Shift键,点击reset复位按钮,此时可以看到超行程报警被暂时消除,此时应点动机器人,往超行程的相反方向移动足够距离,使机器人回到安全区域…...
2024/5/3 19:32:41 - Oracle DataGuard 备库启动报ORA-01186 ORA-01122 ORA-01110 ORA-01210
如果使用LVM管理存储,当从生产端往容灾端做完基线后,启动容灾DB到read only状态时,告警日志中报如下错误:Reread of rdba: 0x00400001 (file 201,block 1) found same corrupted dataErrors in file /oracle/db/diag/rdbms/drora01/ drora01/trace/drora01 dbw0_ 12388.trc…...
2024/4/24 0:58:25 - 分享做外包的体会(二)
如果你面临一个当外包的机会,啥都不清楚,看这里;本文我就简单分享下。第一,选择进入什么样的企业当外包还是挺重要的。我推荐你进前沿的互联网大厂(大公司,比如:阿里、腾讯、百度、头条、快手、滴滴、新浪等)。第二,选择入职什么样的外包公司也还算重要。我推荐你入职…...
2024/4/17 6:00:47 - 达内 java培优 第二阶段 web
文章目录unit 01-MySQL数据库概述什么是数据库?什么是关系型数据库?数据库相关概念什么是SQL语言?连接mysql服务器数据库及表操作创建、删除、查看数据库创建、删除、查看表新增、更新、删除表记录查询表记录基础查询WHERE子句查询模糊查询多行函数查询分组查询排序查询分页…...
2024/4/30 10:17:27 - 2020A特种设备相关管理(电梯)考试题及A特种设备相关管理(电梯)作业模拟考试
题库来源:安全生产模拟考试一点通公众号小程序2020A特种设备相关管理(电梯)考试题及A特种设备相关管理(电梯)作业模拟考试,包含A特种设备相关管理(电梯)考试题答案解析及A特种设备相关管理(电梯)作业模拟考试练习。由安全生产模拟考试一点通公众号结合国家A特种设备相…...
2024/5/2 18:30:02
最新文章
- iOS 10权限问题
简单说明 1.注意需要打开info.plist文件添加相应权限以及权限的说明,否则程序在iOS10上会出现崩溃。 2.且添加时注意不要有空格。 3.输入Privacy一般会有提示。 权限说明 iOS 10支持的所有权限类型 Privacy - Bluetooth Peripheral Usage Description 蓝牙权限…...
2024/5/8 5:21:36 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/7 10:36:02 - ArcGIS10.8保姆式安装教程
ArcGIS 10.8是一款非常强大的地理信息系统软件,用于创建、管理、分析和可视化地理数据。以下是ArcGIS 10.8的详细安装教程: 确保系统满足安装要求 在开始安装之前,请确保您的计算机满足以下系统要求: 操作系统:Windo…...
2024/5/7 11:33:48 - 是否有替代U盘,可安全交换的医院文件摆渡方案?
医院内部网络存储着大量的敏感医疗数据,包括患者的个人信息、病历记录、诊断结果等。网络隔离可以有效防止未经授权的访问和数据泄露,确保这些敏感信息的安全。随着法律法规的不断完善,如《网络安全法》、《个人信息保护法》等,医…...
2024/5/5 8:25:55 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/7 19:05:20 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/7 22:31:36 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/8 1:37:40 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/7 14:19:30 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/8 1:37:39 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/7 16:57:02 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/7 14:58:59 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/7 1:54:46 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/7 21:15:55 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/8 1:37:35 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/7 16:05:05 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/7 16:04:58 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/8 1:37:32 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/7 16:05:05 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/8 1:37:31 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/8 1:37:31 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/7 11:08:22 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/7 7:26:29 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/8 1:37:29 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/7 17:09:45 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57