Kafka的实现原理
如果对kafka的基础知识了解不深,可以看下我的Kafka的基础知识入门,今天这篇博客是来讲解kafka的实现原理,需要有一定的kafka的前置知识,不然可能会很迷茫。
从前面的整个演示过程来看,只要不是超大规模的使用kafka,那么基本上没什么大问题,否则,对于 kafka本身的运维的挑战会很大,同时,针对每一个参数的调优也显得很重要。
据我了解,快手在使用kafka集群规模是挺大的,他们在19年的开发者大会上有提到这篇文章值得推荐一波:
快手万亿级别 Kafka 集群应用实践与技术演进之路
技术的使用是最简单的,要想掌握核心价值,就势必要了解一些原理,在设计这个课程的时候,我想了 很久应该从哪个地方着手,最后还是选择从最基础的消息通讯的原理着手
关于Topic和Partition:
Topic:
在kafka中,topic是一个存储消息的逻辑概念,可以认为是一个消息集合。每条消息发送到kafka集群的 消息都有一个类别。物理上来说,不同的topic的消息是分开存储的,
每个topic可以有多个生产者向它发送消息,也可以有多个消费者去消费其中的消息。
Partition:
每个topic可以划分多个分区(每个Topic至少有一个分区),同一topic下的不同分区包含的消息是不同 的。每个消息在被添加到分区时,都会被分配一个offset(称之为偏移量),它是消息在此分区中的唯 一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个 分区内的消息是有序的。
下图中,对于名字为test的topic,做了3个分区,分别是p0、p1、p2.
Ø 每一条消息发送到broker时,会根据partition的规则选择存储到哪一个partition。如果partition规则 设置合理,那么所有的消息会均匀的分布在不同的partition中,这样就有点类似数据库的分库分表的概 念,把数据做了分片处理。

Topic&Partition的存储:
Partition是以文件的形式存储在文件系统中,比如创建一个名为firstTopic的topic,其中有3个 partition,那么在kafka的数据目录(/tmp/kafka-log)中就有3个目录,firstTopic-0~3, 命名规则是 <topic_name>-<partition_id>
sh kafka-topics.sh --create --zookeeper 192.168.11.156:2181 --replication-factor 1 --partitions 3 --topic firstTopic
关于消息分发
kafka消息分发策略
消息是kafka中最基本的数据单元,在kafka中,一条消息由key、value两部分构成,在发送一条消息 时,我们可以指定这个key,那么producer会根据key和partition机制来判断当前这条消息应该发送并存储到哪个partition中。我们可以根据需要进行扩展producer的partition机制。
代码演示:
自定义Partitioner
public class MyPartitioner implements Partitioner {
private Random random = new Random();
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[]
bytes1, Cluster cluster) {
//获取集群中指定topic的所有分区信息
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(s);
int numOfPartition = partitionInfos.size();
int partitionNum = 0;
if (o == null) { //key没有设置
partitionNum = random.nextInt(numOfPartition); //随机指定分区 }else{
partitionNum = Math.abs((o1.hashCode())) % numOfPartition;
}
System.out.println("key->" + o + ",value->" + o1 + "->send to partition:" + partitionNum);
return partitionNum;
}发送端代码添加自定义分区
public KafkaProducerDemo(String topic,boolean isAysnc){
Properties properties=new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.13.102:9092,192.168.13.103:9092,192.168.13.104:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"KafkaProducerDemo");
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.gupaoedu.kafka.MyPa rtitioner");
producer=new KafkaProducer<Integer, String>(properties);this.topic=topic;
this.isAysnc=isAysnc;
}消息默认的分发机制:
默认情况下,kafka采用的是hash取模的分区算法。如果Key为null,则会随机分配一个分区。这个随机 是在这个参数”metadata.max.age.ms”的时间范围内随机选择一个。对于这个时间段内,如果key为 null,则只会发送到唯一的分区。这个值值哦默认情况下是10分钟更新一次。
关于Metadata,简单理解就是Topic/Partition和broker的映射关系,每一个topic的 每一个partition,需要知道对应的broker列表是什么,leader是谁、follower是谁。这些信息都是存储 在Metadata这个类里面。
消费端如何指定消费的分区:
通过下面的代码,就可以消费指定该topic下的0号分区。其他分区的数据就无法接收
//消费指定分区的时候,不需要再订阅 //kafkaConsumer.subscribe(Collections.singletonList(topic)); //消费指定的分区 TopicPartition topicPartition=new TopicPartition(topic,0); kafkaConsumer.assign(Arrays.asList(topicPartition));
消息的消费原理
kafka消息消费原理演示:
在实际生产过程中,每个topic都会有多个partitions,多个partitions的好处在于,一方面能够对 broker上的数据进行分片有效减少了消息的容量从而提升io性能。另外一方面,为了提高消费端的消费 能力,一般会通过多个consumer去消费同一个topic ,也就是消费端的负载均衡机制,也就是我们接下 来要了解的,在多个partition以及多个consumer的情况下,消费者是如何消费消息的
同时,在上一篇博客,我们讲了,kafka存在consumer group的概念,也就是group.id一样的 consumer,这些consumer属于一个consumer group,组内的所有消费者协调在一起来消费订阅主题 的所有分区。当然每一个分区只能由同一个消费组内的consumer来消费,那么同一个consumer group里面的consumer是怎么去分配该消费哪个分区里的数据的呢?如下图所示,3个分区,3个消费 者,那么哪个消费者消分哪个分区?

对于上面这个图来说,这3个消费者会分别消费test这个topic 的3个分区,也就是每个consumer消费一 个partition。
理论讲解(这一块也可以启动kafka测试看的,但是觉得没有必要,就是一些理论知识):
Ø 创建一个带3个分区的topic
Ø 启动3个消费者消费同一个topic,并且这3个consumer属于同一个组 Ø 启动发送者进行消息发送
演示结果:consumer1会消费partition0分区、consumer2会消费partition1分区、consumer3会消费 partition2分区
如果是2个consumer消费3个partition呢?会是怎么样的结果?
结果:consumer1会消费partition0/partition1分区、consumer2会消费partition2分区
3个partition对应4个或以上consumer?
结果:
仍然只有3个consumer对应3个partition,其他的consumer无法消费消息
通过这个演示的过程,我希望引出接下来需要了解的kafka的分区分配策略(Partition Assignment Strategy)
consumer和partition的数量建议:
如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的, 所以consumer数不要大于partition数
如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配 consumer数和partition数,否则会导致partition里面的数据被取的不均匀。最好partiton数目是 consumer数目的整数倍,所以partition数目很重要,比如取24,就很容易设定consumer数目
如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition 上数据是有序的,但多个partition,根据你读的顺序会有不同
增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的 partition会发生变化
思考:什么时候触发这个策略
当出现以下几种情况时,kafka会进行一次分区分配操作,也就是kafka consumer的rebalance
1. 同一个consumer group内新增了消费者
2. 消费者离开当前所属的consumer group,比如主动停机或者宕机 3. topic新增了分区(也就是分区数量发生了变化)
kafka consuemr的rebalance机制规定了一个consumer group下的所有consumer如何达成一致来分 配订阅topic的每个分区。而具体如何执行分区策略,就是前面提到过的两种内置的分区策略。而kafka 对于分配策略这块,提供了可插拔的实现方式, 也就是说,除了这两种之外,我们还可以创建自己的分 配机制。
什么是分区分配策略(简单介绍下):
通过前面的案例演示,我们应该能猜到,同一个group中的消费者对于一个topic中的多个partition,存 在一定的分区分配策略。
在kafka中,存在三种分区分配策略,一种是Range(默认)、 另一种是RoundRobin(轮询)、 StickyAssignor(粘性)。 在消费端中的ConsumerConfig中,通过这个属性来指定分区分配策略
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG = "partition.assignment.strategy";
RangeAssignor(范围分区)
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字 母顺序进行排序。
其实这是有一个公式计算的,大家了解一下即可:

RoundRobinAssignor(轮询分区)
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进行排序。最后通 过轮询算法分配partition给消费线程。如果所有consumer实例的订阅是相同的,那么partition会均匀 分布。
StrickyAssignor 分配策略
kafka在0.11.x版本支持了StrickyAssignor, 翻译过来叫粘滞策略,它主要有两个目的
1.分区的分配尽可能的均匀
2.分区的分配尽可能和上次分配保持相同
假设n = 分区数/消费者数量
m= 分区数%消费者数量 那么前m个消费者每个分配n+l个分区,后面的(消费者数量-m)个消费者每个分配n个分区
当两者发生冲突时, 第 一 个目标优先于第二个目标。 鉴于这两个目标, StickyAssignor分配策略的具 体实现要比RangeAssignor和RoundRobinAssi gn or这两种分配策略要复杂得多
谁来执行Rebalance以及管理consumer的group呢?
Kafka提供了一个角色: coordinator来执行对于consumer group的管理,当consumer group的第一个consumer启动的时 候,它会去和kafka server确定谁是它们组的coordinator。之后该group内的所有成员都会和该 coordinator进行协调通信
如何确定coordinator:
consumer group如何确定自己的coordinator是谁呢, 消费者向kafka集群中的任意一个broker发送一个 GroupCoordinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置 为coordinator
JoinGroup的过程:
在rebalance之前,需要保证coordinator是已经确定好了的,整个rebalance的过程分为两个步骤,
Join和Sync
join: 表示加入到consumer group中,在这一步中,所有的成员都会向coordinator发送joinGroup的请 求。一旦所有成员都发送了joinGroup请求,那么coordinator会选择一个consumer担任leader角色, 并把组成员信息和订阅信息发送消费者
leader选举算法比较简单,如果消费组内没有leader,那么第一个加入消费组的消费者就是消费者 leader,如果这个时候leader消费者退出了消费组,那么重新选举一个leader,这个选举很随意,类似 于随机算法

protocol_metadata: 序列化后的消费者的订阅信息
leader_id: 消费组中的消费者,coordinator会选择一个座位leader,对应的就是member_id member_metadata 对应消费者的订阅信息
members:consumer group中全部的消费者的订阅信息
generation_id: 年代信息,类似于之前讲解zookeeper的时候的epoch是一样的,对于每一轮 rebalance,generation_id都会递增。主要用来保护consumer group。隔离无效的offset提交。也就 是上一轮的consumer成员无法提交offset到新的consumer group中。
每个消费者都可以设置自己的分区分配策略,对于消费组而言,会从各个消费者上报过来的分区分配策 略中选举一个彼此都赞同的策略来实现整体的分区分配,这个"赞同"的规则是,消费组内的各个消费者 会通过投票来决定
在joingroup阶段,每个consumer都会把自己支持的分区分配策略发送到coordinator coordinator手机到所有消费者的分配策略,组成一个候选集 每个消费者需要从候选集里找出一个自己支持的策略,并且为这个策略投票 最终计算候选集中各个策略的选票数,票数最多的就是当前消费组的分配策略
Synchronizing Group State阶段
完成分区分配之后,就进入了Synchronizing Group State阶段,主要逻辑是向GroupCoordinator发送 SyncGroupRequest请求,并且处理SyncGroupResponse响应,简单来说,就是leader将消费者对应 的partition分配方案同步给consumer group 中的所有consumer

每个消费者都会向coordinator发送syncgroup请求,不过只有leader节点会发送分配方案,其他消费者 只是打打酱油而已。当leader把方案发给coordinator以后,coordinator会把结果设置到 SyncGroupResponse中。这样所有成员都知道自己应该消费哪个分区。
Ø consumer group的分区分配方案是在客户端执行的!Kafka将这个权利下放给客户端主要是因为这 样做可以有更好的灵活性
我们再来总结一下consumer group rebalance的过程
Ø 对于每个consumer group子集,都会在服务端对应一个GroupCoordinator进行管理, GroupCoordinator会在zookeeper上添加watcher,当消费者加入或者退出consumer group时,会修 改zookeeper上保存的数据,从而触发GroupCoordinator开始Rebalance操作
Ø 当消费者准备加入某个Consumer group或者GroupCoordinator发生故障转移时,消费者并不知道 GroupCoordinator的在网络中的位置,这个时候就需要确定GroupCoordinator,消费者会向集群中的 任意一个Broker节点发送ConsumerMetadataRequest请求,收到请求的broker会返回一个response 作为响应,其中包含管理当前ConsumerGroup的GroupCoordinator,
Ø 消费者会根据broker的返回信息,连接到groupCoordinator,并且发送HeartbeatRequest,发送心 跳的目的是要要奥噶苏GroupCoordinator这个消费者是正常在线的。当消费者在指定时间内没有发送 心跳请求,则GroupCoordinator会触发Rebalance操作。
Ø 发起join group请求,两种情况 如果GroupCoordinator返回的心跳包数据包含异常,说明GroupCoordinator因为前面说的几种
情况导致了Rebalance操作,那这个时候,consumer会发起join group请求 新加入到consumer group的consumer确定好了GroupCoordinator以后
消费者会向GroupCoordinator发起join group请求,GroupCoordinator会收集全部消费者信息之 后,来确认可用的消费者,并从中选取一个消费者成为group_leader。并把相应的信息(分区分 配策略、leader_id、...)封装成response返回给所有消费者,但是只有group leader会收到当前 consumer group中的所有消费者信息。当消费者确定自己是group leader以后,会根据消费者的 信息以及选定分区分配策略进行分区分配
接着进入Synchronizing Group State阶段,每个消费者会发送SyncGroupRequest请求到 GroupCoordinator,但是只有Group Leader的请求会存在分区分配结果,GroupCoordinator会 根据Group Leader的分区分配结果形成SyncGroupResponse返回给所有的Consumer。
consumer根据分配结果,执行相应的操作
到这里为止,我们已经知道了消息的发送分区策略,以及消费者的分区消费策略和rebalance。对于应 用层面来说,还有一个最重要的东西没有讲解,就是offset,他类似一个游标,表示当前消费的消息的 位置。
如何保存消费端的消费位置
什么是offset
前面在讲解partition的时候,提到过offset, 每个topic可以划分多个分区(每个Topic至少有一个分 区),同一topic下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺 序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的; 对于应用层的消费来 说,每次消费一个消息并且提交以后,会保存当前消费到的最近的一个offset。那么offset保存在哪 里?
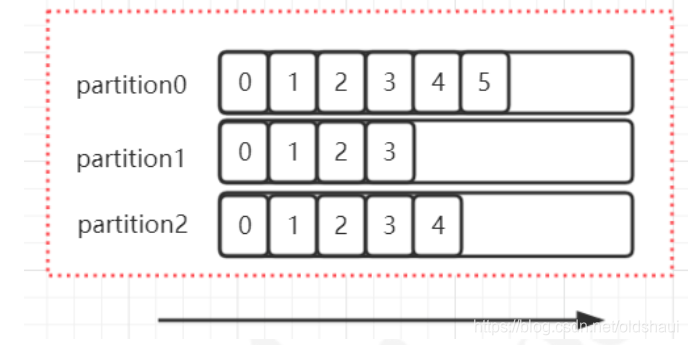
offset在哪里维护?
在kafka中,提供了一个consumer_offsets_* 的一个topic,把offset信息写入到这个topic中。 consumer_offsets——按保存了每个consumer group某一时刻提交的offset信息。 __consumer_offsets 默认有50个分区。
根据前面我们演示的案例,我们设置了一个KafkaConsumerDemo的groupid。首先我们需要找到这个 consumer_group保存在哪个分区中
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaConsumerDemo");
计算公式:
Math.abs(“groupid”.hashCode())%groupMetadataTopicPartitionCount ; 由于默认情况下 groupMetadataTopicPartitionCount有50个分区,计算得到的结果为:35, 意味着当前的 consumer_group的位移信息保存在__consumer_offsets的第35个分区
分区的副本机制
我们已经知道Kafka的每个topic都可以分为多个Partition,并且多个partition会均匀分布在集群的各个 节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个partition来说,都是单点的,当其中 一个partition不可用的时候,那么这部分消息就没办法消费。所以kafka为了提高partition的可靠性而 提供了副本的概念(Replica),通过副本机制来实现冗余备份。
每个分区可以有多个副本,并且在副本集合中会存在一个leader的副本,所有的读写请求都是由leader 副本来进行处理。剩余的其他副本都做为follower副本,follower副本会从leader副本同步消息日志。 这个有点类似zookeeper中leader和follower的概念,但是具体的时间方式还是有比较大的差异。所以 我们可以认为,副本集会存在一主多从的关系。
一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同broker上,当leader副本所在的 broker出现故障后,可以重新选举新的leader副本继续对外提供服务。通过这样的副本机制来提高 kafka集群的可用性。
创建一个带副本机制的topic
* 通过下面的命令去创建带2个副本的topic
sh kafka-topics.sh --create --zookeeper 192.168.11.156:2181 --replication-factor 3 --partitions 3 --topic secondTopic
然后我们可以在/tmp/kafka-log路径下看到对应topic的副本信息了。我们通过一个图形的方式来表达。
针对secondTopic这个topic的3个分区对应的3个副本

如何知道那个各个分区中对应的leader是谁呢?
在zookeeper服务器上,通过如下命令去获取对应分区的信息, 比如下面这个是获取secondTopic第1个
分区的状态信息。
get /brokers/topics/secondTopic/partitions/1/state
{"controller_epoch":12,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1]}
leader表示当前分区的leader是那个broker-id。下图中。绿色线条的表示该分区中的leader节点。其他 节点就为follower

需要注意的是,kafka集群中的一个broker中最多只能有一个副本,leader副本所在的broker节点的 分区叫leader节点,follower副本所在的broker节点的分区叫follower节点
副本的leader选举
Kafka提供了数据复制算法保证,如果leader副本所在的broker节点宕机或者出现故障,或者分区的
leader节点发生故障,这个时候怎么处理呢? 那么,kafka必须要保证从follower副本中选择一个新的leader副本。那么kafka是如何实现选举的呢?
要了解leader选举,我们需要了解几个概念 Kafka分区下有可能有很多个副本(replica)用于实现冗余,从而进一步实现高可用。副本根据角色的不同
可分为3类:
leader副本:响应clients端读写请求的副本
follower副本:被动地备份leader副本中的数据,不能响应clients端读写请求。
ISR副本:包含了leader副本和所有与leader副本保持同步的follower副本——如何判定是否与leader同 步后面会提到每个Kafka副本对象都有两个重要的属性:LEO和HW。注意是所有的副本,而不只是 leader副本。
LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下 一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。另外, leader LEO和follower LEO的更新是有区别的
HW:即上面提到的水位值。对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所 有消息都被认为是“已备份”的(replicated)。同理,leader副本和follower副本的HW更新是有区别的
副本协同机制
刚刚提到了,消息的读写操作都只会由leader节点来接收和处理。follower副本只负责同步数据以及当 leader副本所在的broker挂了以后,会从follower副本中选取新的leader。
写请求首先由Leader副本处理,之后follower副本会从leader上拉取写入的消息,这个过程会有一定的 延迟,导致follower副本中保存的消息略少于leader副本,但是只要没有超出阈值都可以容忍。但是如 果一个follower副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候, leader就会把它踢出去。kafka通过ISR集合来维护一个分区副本信息

一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为 leader;leader负责维护和跟踪ISR(in-Sync replicas , 副本同步队列)中所有follower滞后的状态。当 producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复 制到所有的同步副本。
ISR
ISR表示目前“可用且消息量与leader相差不多的副本集合,这是整个副本集合的一个子集”。怎么去理解 可用和相差不多这两个词呢?具体来说,ISR集合中的副本必须满足两个条件
1. 副本所在节点必须维持着与zookeeper的连接
2. 副本最后一条消息的offset与leader副本的最后一条消息的offset之间的差值不能超过指定的阈值 (replica.lag.time.max.ms) replica.lag.time.max.ms:如果该follower在此时间间隔内一直没有追 上过leader的所有消息,则该follower就会被剔除isr列表
3. ISR数据保存在Zookeeper的 /brokers/topics/<topic>/partitions/<partitionId>/state 节点中
follower副本把leader副本LEO之前的日志全部同步完成时,则认为follower副本已经追赶上了leader 副本,这个时候会更新这个副本的lastCaughtUpTimeMs标识,kafk副本管理器会启动一个副本过期检 查的定时任务,这个任务会定期检查当前时间与副本的lastCaughtUpTimeMs的差值是否大于参数
replica.lag.time.max.ms 的值,如果大于,则会把这个副本踢出ISR集合

消息的存储:
消息发送端发送消息到broker上以后,消息是如何持久化的呢?那么接下来去分析下消息的存储
首先我们需要了解的是,kafka是使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一 个offset值来表示它在分区中的偏移量。Kafka中存储的一般都是海量的消息数据,为了避免日志文件过 大,Log并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的命名规则 是<topic_name>_<partition_id>
消息的文件存储机制
一个topic的多个partition在物理磁盘上的保存路径,路径保存在 /tmp/kafka-logs/topic_partition,包 含日志文件、索引文件和时间索引文件

kafka是通过分段的方式将Log分为多个LogSegment,LogSegment是一个逻辑上的概念,一个 LogSegment对应磁盘上的一个日志文件和一个索引文件,其中日志文件是用来记录消息的。索引文件 是用来保存消息的索引。那么这个LogSegment是什么呢?
LogSegment
假设kafka以partition为最小存储单位,那么我们可以想象当kafka producer不断发送消息,必然会引 起partition文件的无线扩张,这样对于消息文件的维护以及被消费的消息的清理带来非常大的挑战,所 以kafka 以segment为单位又把partition进行细分。每个partition相当于一个巨型文件被平均分配到多 个大小相等的segment数据文件中(每个segment文件中的消息不一定相等),这种特性方便已经被消 费的消息的清理,提高磁盘的利用率。
log.segment.bytes=107370 (设置分段大小),默认是1gb,我们把这个值调小以后,可以看到日志 分段的效果
抽取其中3个分段来进行分析

segment file由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后 缀".index"和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个 segment文件最后一条消息的offset值进行递增。数值最大为64位long大小,20位数字字符长度,没有 数字用0填充
查看segment文件命名规则:
通过下面这条命令可以看到kafka消息日志的内容:
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test- 0/00000000000000000000.log --print-data-log
假如第一个log文件的最后一个offset为:5376,所以下一个segment的文件命名为: 00000000000000005376.log。对应的index为00000000000000005376.index
segment中index和log的对应关系:
从所有分段中,找一个分段进行分析
为了提高查找消息的性能,为每一个日志文件添加2个索引索引文件:OffsetIndex 和 TimeIndex,分 别对应.index .timeindex, TimeIndex索引文件格式:它是映射时间戳和相对offset
查看索引内容:


如图所示,index中存储了索引以及物理偏移量。 log存储了消息的内容。索引文件的元数据执行对应数 据文件中message的物理偏移地址。举个简单的案例来说,以[4053,80899]为例,在log文件中,对应 的是第4053条记录,物理偏移量(position)为80899. position是ByteBuffer的指针位置
在partition中如何通过offset查找message:
查找的算法是
根据offset的值,查找segment段中的index索引文件。由于索引文件命名是以上一个文件的最后 一个offset进行命名的,所以,使用二分查找算法能够根据offset快速定位到指定的索引文件。
找到索引文件后,根据offset进行定位,找到索引文件中的符合范围的索引。(kafka采用稀疏索 引的方式来提高查找性能)
得到position以后,再到对应的log文件中,从position出开始查找offset对应的消息,将每条消息 的offset与目标offset进行比较,直到找到消息
比如说,我们要查找offset=2490这条消息,那么先找到00000000000000000000.index, 然后找到 [2487,49111]这个索引,再到log文件中,根据49111这个position开始查找,比较每条消息的offset是 否大于等于2490。最后查找到对应的消息以后返回
磁盘存储的性能问题
磁盘存储的性能优化
我们现在大部分企业仍然用的是机械结构的磁盘,如果把消息以随机的方式写入到磁盘,那么磁盘首先 要做的就是寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的 扇区;这个过程相对内存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka采用顺序写 的方式存储数据。即使是这样,但是频繁的I/O操作仍然会造成磁盘的性能瓶颈
零拷贝
消息从发送到落地保存,broker维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者 和消费者使用相同的格式来处理。在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存 中的数据原封不动的通过socket发送给消费者。虽然这个操作描述起来很简单,但实际上经历了很多步 骤。
操作系统将数据从磁盘读入到内核空间的页缓存 1应用程序将数据从内核空间读入到用户空间缓存中 2 应用程序将数据写回到内核空间到socket缓存中 3操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出

通过“零拷贝”技术,可以去掉这些没必要的数据复制操作,同时也会减少上下文切换次数。现代的unix 操作系统提供一个优化的代码路径,用于将数据从页缓存传输到socket;在Linux中,是通过sendfile系 统调用来完成的。Java提供了访问这个系统调用的方法:FileChannel.transferTo API
使用sendfile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。所以在这个优 化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的

页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,但凡设计到缓存的,基本都是为了提升i/o性能,所以页 缓存是用来减少磁盘I/O操作的。
磁盘高速缓存有两个重要因素: 第一,访问磁盘的速度要远低于访问内存的速度,若从处理器L1和L2高速缓存访问则速度更快。 第二,数据一旦被访问,就很有可能短时间内再次访问。正是由于基于访问内存比磁盘快的多,所 以磁盘的内存缓存将给系统存储性能带来质的飞越。
当 一 个进程准备读取磁盘上的文件内容时, 操作系统会先查看待读取的数据所在的页(page)是否在页 缓存(pagecache)中,如果存在(命中)则直接返回数据, 从而避免了对物理磁盘的I/0操作;如果没有 命中, 则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存, 之后再将数据返回给进程。 同样,如果 一 个进程需要将数据写入磁盘, 那么操作系统也会检测数据对应的页是否在页缓存中,如 果不存在, 则会先在页缓存中添加相应的页, 最后将数据写入对应的页。 被修改过后的页也就变成了 脏页, 操作系统会在合适的时间把脏页中的数据写入磁盘, 以保持数据的 一 致性
Kafka中大量使用了页缓存, 这是Kafka实现高吞吐的重要因素之 一 。 虽然消息都是先被写入页缓存, 然后由操作系统负责具体的刷盘任务的, 但在Kafka中同样提供了同步刷盘及间断性强制刷盘(fsync), 可以通过 log.flush.interval.messages 和 log.flush.interval.ms 参数来控制。
同步刷盘能够保证消息的可靠性,避免因为宕机导致页缓存数据还未完成同步时造成的数据丢失。但是 实际使用上,我们没必要去考虑这样的因素以及这种问题带来的损失,消息可靠性可以由多副本来解 决,同步刷盘会带来性能的影响。 刷盘的操作由操作系统去完成即可
Kafka消息的可靠性
没有一个中间件能够做到百分之百的完全可靠,可靠性更多的还是基于几个9的衡量指标,比如4个9、5 个9. 软件系统的可靠性只能够无限去接近100%,但不可能达到100%。所以kafka如何是实现最大可能 的可靠性呢?
分区副本, 你可以创建更多的分区来提升可靠性,但是分区数过多也会带来性能上的开销,一般 来说,3个副本就能满足对大部分场景的可靠性要求
acks,生产者发送消息的可靠性,也就是我要保证我这个消息一定是到了broker并且完成了多副 本的持久化,但这种要求也同样会带来性能上的开销。它有几个可选项
1 ,生产者把消息发送到leader副本,leader副本在成功写入到本地日志之后就告诉生产者 消息提交成功,但是如果isr集合中的follower副本还没来得及同步leader副本的消息, leader挂了,就会造成消息丢失
-1 ,消息不仅仅写入到leader副本,并且被ISR集合中所有副本同步完成之后才告诉生产者已 经提交成功,这个时候即使leader副本挂了也不会造成数据丢失。 0:表示producer不需要等待broker的消息确认。这个选项时延最小但同时风险最大(因为 当server宕机时,数据将会丢失)。
保障消息到了broker之后,消费者也需要有一定的保证,因为消费者也可能出现某些问题导致消 息没有消费到
enable.auto.commit默认为true,也就是自动提交offset,自动提交是批量执行的,有一个时间窗 口,这种方式会带来重复提交或者消息丢失的问题,所以对于高可靠性要求的程序,要使用手动提 交。 对于高可靠要求的应用来说,宁愿重复消费也不应该因为消费异常而导致消息丢失
本篇文章的大部分内容可以在 <<深入理解Kafka 核心设计与实践原理>>中找到,如果想要这本电子书的可以留下你的联系方式,我会发给你的哦,邮箱,qq啥的都行的哦。内容知识比较庞大,希望能给大家一点帮助,欢迎大家找出问题,欢迎点赞
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 前缀统计【字典树】
题目描述 给定N个字符串S1,S2…SN,接下来进行M次询问,每次询问给定一个字符串T,求S1∼SN中有多少个字符串是T的前缀。输入字符串的总长度不超过106,仅包含小写字母。 输入 第一行两个整数N,M。接下来N行每行一个字符串Si。接下来M行每行一个字符串表示询问。 输出 对于每个…...
2024/4/15 21:47:38 - RxSwift 介绍与简单使用
文章目录一、 Rx 介绍1、什么是Rx2、RxSwift3、RxCocoa二、Rx 常见用法1、给 button 添加点击事件(RxCocoa)2、事件 + bind + combine3、遵循代理并实现4、闭包回调5、通知6、多任务依赖关系管理7、多任务异步并行三、DisposeBag(清除包)介绍:四、函数式编程介绍参考文献:…...
2024/4/22 4:44:19 - OpenCV C++滑动条插件
OpenCV C++滑动条插件 这个就是Opecv3中文版的例程,做了些注释,以及排坑指南。 #include<opencv2\highgui\highgui.hpp> #include<opencv2\imgproc\imgproc.hpp> #include<iostream>using namespace cv; using namespace std;int g_slider_position = 0;//…...
2024/4/6 3:45:43 - A1069 The Black Hole of Numbers [简单数学]
题目大意:找出黑洞数字并且写出每一步过程。 思路:数字前面补0记得用printf %04d这种很方便。 数字转数组,数组转数字要掌握好。#include<iostream> #include<cstring> #include<algorithm> #include<string> #include<time.h> #include<s…...
2024/4/17 6:24:54 - LeetCode第 315 题:计算右侧小于当前元素的个数(C++)
315. 计算右侧小于当前元素的个数 - 力扣(LeetCode) 暴力法,两层for循环,很简单,但是会超出时间限制。怎么优化呢? 看题目的直觉思路是逆序找,因为左边会包含右边,举个例子: [6,4,5,2,3,1][6,4,5,2,3,1][6,4,5,2,3,1] 对应的count数组为: [5,3,3,1,1,0][5,3,3,1,1,0]…...
2024/4/23 15:39:20 - docker是什么与使用方法
docker介绍 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。 Docker,可以说是一个终端命令行的虚拟机,但更准确的说法…...
2024/4/22 6:27:19 - C语言 学生管理系统
#include <stdio.h> #include <string.h> #define NAME_LEN 64 /* 姓名字符数 */ typedef struct students {long studne_id; /* 学号 */char name[NAME_LEN]; /* 姓名 */char sex[3]; /* 性别 */int age; /* 年龄 */double height…...
2024/4/16 15:23:52 - 高性能MySQL第七章:MySQL高级特性
MySQL从5.0和5.1版本开始引入了很多高级特性,包括分区、触发器等,这些新特性也许不会频繁用到,但对于某些场景下,会给我们更多DB层面优化的选择,所以,了解一下总是有益的。 一、分区表 分区表,通过在创建表时,使用partition by子句来定义每个分区存放的数据,以达到将数…...
2024/4/6 3:45:23 - 566. 重塑矩阵
题目描述自己解法 先把原矩阵转换为一个列表,再依次读入: 时间复杂度O(m∗n)O(m*n)O(m∗n),空间复杂度O(m∗n)O(m*n)O(m∗n) class Solution:def matrixReshape(self, nums: List[List[int]], r: int, c: int) -> List[List[int]]:if r * c != len(nums) * len(nums[0]):…...
2024/4/16 15:28:58 - springboot2.x +rabbitmq使用和源码分析三(消息转换器)
序言:在第一篇和第二篇中,描述了自动装配的过程以及如何发送消息到mq。这里会涉及到将数据转化的工作,也就是如何将我们string或者java对象转化到二进制数据,传输到rabbitmq服务器中(在网络中只能传输二进制数据),而又是如何将到rabbitmq服务器传输的二进制数据转化为监听…...
2024/4/24 7:52:31 - Windows10安装visual studio 2013
https://wenku.baidu.com/view/6f1ba49955270722192ef7a8.html...
2024/4/27 6:40:40 - C++11/14/17常用特性总结
1. C++111.1. nullptr常量 1.2. constexpr关键字 1.3. using类型别名声明 1.4. auto关键字 1.5. 范围for语句 1.6. lambda表达式与std::bind 1.7. =default/=delete 1.8. 右值引用与移动语义 1.9. explicit/override/final/noexcept指示符 1.10. string数值转换函数 1.11. std:…...
2024/4/26 15:49:08 - Linux学习笔记6:文件内容查看与权限
参考书籍:《鸟哥的Linux私房菜:基础学习篇》 文件内容查看 1、几个常用的查看文件内容的命令: 【cat】由第一行开始显示文件内容 【tac】从最后一行开始显示,tac是cat倒着写 【nl】显示的时候,同时输出行号 【more】一页一页的查看文件内容 【less】与more类似,不过可以往…...
2024/4/15 23:58:14 - 由“需求实现”到“价值引领”:新版如流正在让在线办公蜕变
文|曾响铃来源|科技向令说(xiangling0815)后疫情时代,在线办公平台挤满了各路玩家,阿里的钉钉、腾讯的企业微信/腾讯会议,百度“如流”(原名百度Hi)悉数登场,加上很多还算优秀的中小明星产品,以三大平台为主、各玩家各有所长的繁荣盛景已经形成。但随着疫情影响的逐步…...
2024/4/6 3:45:40 - [HIT-FLAA]哈工大2020春形式语言与自动机复习笔记 (3)
文章目录:上下文无关文法和下推自动机1. 上下文无关文法(CFG)1. 上下文无关文法2. 语法分析树3. 二义性4. CFG的化简5. 乔姆斯基范式(CNF)2. 下推自动机(PDA)1. PDA的定义2. 确定的PDA3. PDA的瞬时描述4. PDA接受的语言3. CFG和PDA的等价性1. CFG ⇒\Rightarrow⇒ PDA2. PDA ⇒…...
2024/4/27 13:26:53 - Shell 配置yum源脚本
Shell 配置yum源脚本 #### 配置yum源脚本 #!/usr/bin/bash ##################################################### # yum config # # v1.0 by malele 2020-4.9 # ########…...
2024/4/5 5:50:02 - 七大Join
七大join自然连接 select * from a inner join b on a.key = b.key; 左外连接 select * from a left join b on a.key = b.key;右外连接 select * from a right join b on a.key = b.key;a-ab select * from a left join b on a.key = b.key where b.key is null;b-ab select *…...
2024/4/25 7:55:28 - week15_day01_Maven配置&&Junit&&单例、工厂、代理模式
新阶段的介绍: 课程的情况设计模式(1day)为spring做铺垫 Spring(4days):ioc\di、aop、事务 SpringMVC(4days) Mybatis(4~5days) 持久层框架:用于和mysql数据库做持久化关联的框架,叫持久层框架 持久层就是把数据放在可存储介质中(磁盘) SSM整合(0.5day) Spring Spr…...
2024/4/24 8:56:39 - docker启动mysql后,navicat连接不上mysql的解决方法
1.docker拉取镜像 docker pull mysql2.运行mysql docker run -p 3308:3306 --name mysql01 -e MYSQL_ROOT_PASSWORD=123456 -d mysql容器名称是:mysql 密码:123456 3.查看运行 docker ps -a4.查看日志 docker logs mysql5.但是使用navicat连接数据时,总是出现错误解决方法1)…...
2024/4/24 9:57:37 - SSM整合(二)------CRUD
返回JSON数据当客户端向服务器发送请求的时候,服务器处理完请求,要将页面的数据交给客户端时,如果客户端是安卓或者苹果的话,那样解析服务器传来的数据可能就比较麻烦。所以这里采用一个较为常用的解决方案,那就是让服务器将有效的数据以JSON的形式返回给客户端,这样就可…...
2024/4/28 13:48:46
最新文章
- MYSQL视图 WITH CHECK OPTION 的用法
假设我们有一个名为 "Scores" 的表,用于存储学生的考试成绩,表结构如下: Scores ---------- student_id (学生ID) exam_id (考试ID) score (分数)现在,我们想创建一个视图,只包含某个特定考试…...
2024/4/28 22:26:18 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - LeetCode 热题 100 题解(二):双指针部分(2)| 滑动窗口部分(1)
题目四:接雨水(No. 43) 题目链接:https://leetcode.cn/problems/trapping-rain-water/description/?envTypestudy-plan-v2&envIdtop-100-liked 难度:困难 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图&am…...
2024/4/28 13:37:21 - dp小兰走迷宫
昨天学习了bfs的基本概念,今天来做一道经典习题练练手吧! bfs常用的两类题型 1.从A出发是否存在到达B的路径(dfs也可) 2.从A出发到B的最短路径(数小:<20才能用dfs) 遗留的那个问题的答案- 题目:走迷宫 #incl…...
2024/4/28 3:06:28 - Unity核心学习
目录 认识模型的制作流程模型的制作过程 2D相关图片导入设置图片导入概述纹理类型设置纹理形状设置纹理高级设置纹理平铺拉伸设置纹理平台打包相关设置 SpriteSprite Editor——Single图片编辑Sprite Editor——Multiple图片编辑Sprite Editor——Polygon图片编辑SpriteRendere…...
2024/4/24 7:49:17 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/4/28 4:04:40 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/4/28 12:01:04 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/4/28 16:34:55 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/4/28 18:31:47 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/4/28 12:01:03 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/4/28 12:01:03 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/4/28 12:01:03 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/4/28 16:07:14 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/4/27 21:08:20 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/4/28 9:00:42 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/4/27 18:40:35 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/4/28 4:14:21 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/4/27 13:52:15 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/4/27 13:38:13 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/4/28 12:00:58 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/4/28 12:00:58 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/4/27 22:51:49 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/4/28 7:31:46 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/4/28 8:32:05 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/4/27 20:28:35 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57