BIGDATA-redis
01.NoSQL入门概述
1.互联网时代背景下大机遇,为什么用NoSQL
1.单机MySQL的美好年代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。
在那个时候,更多的都是静态网页,动态交互类型的网站不多。
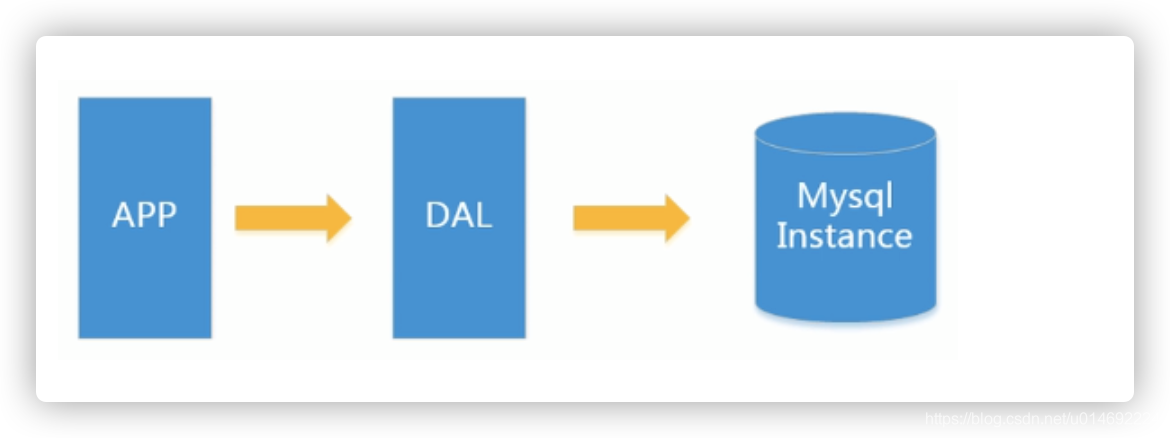
DAL dal是数据访问层的英文缩写,即为数据访问层(Data Access Layer)
上述架构下,我们来看看数据存储的瓶颈是什么?
1. 数据量的总大小一个机器放不下时
2. 数据的索引(B+ Tree)一个机器的内存放不下时
3. 访问量(读写混合)一个实例不能承受
如果满足了上述1or3个,进化…
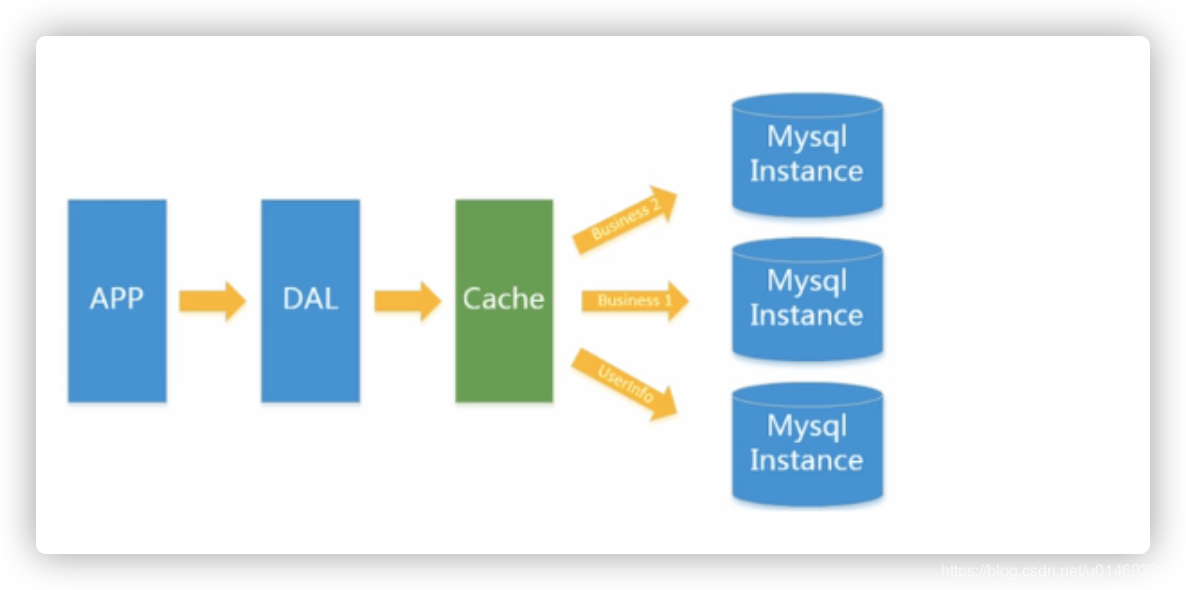
2.Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。
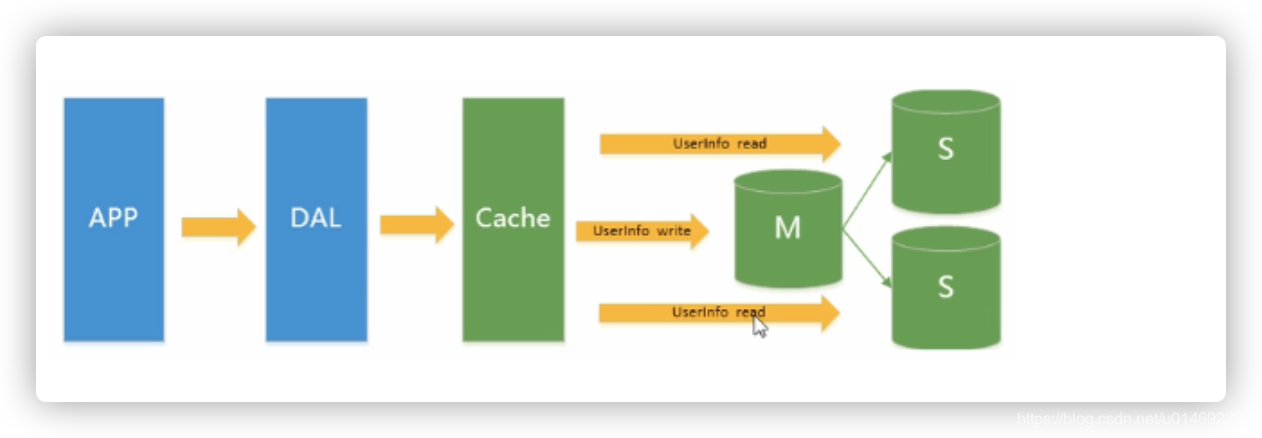
3.Mysql主从读写分离
由于数据库的写入压力增加,Memcached 只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模 式成为这个时候的网站标配了
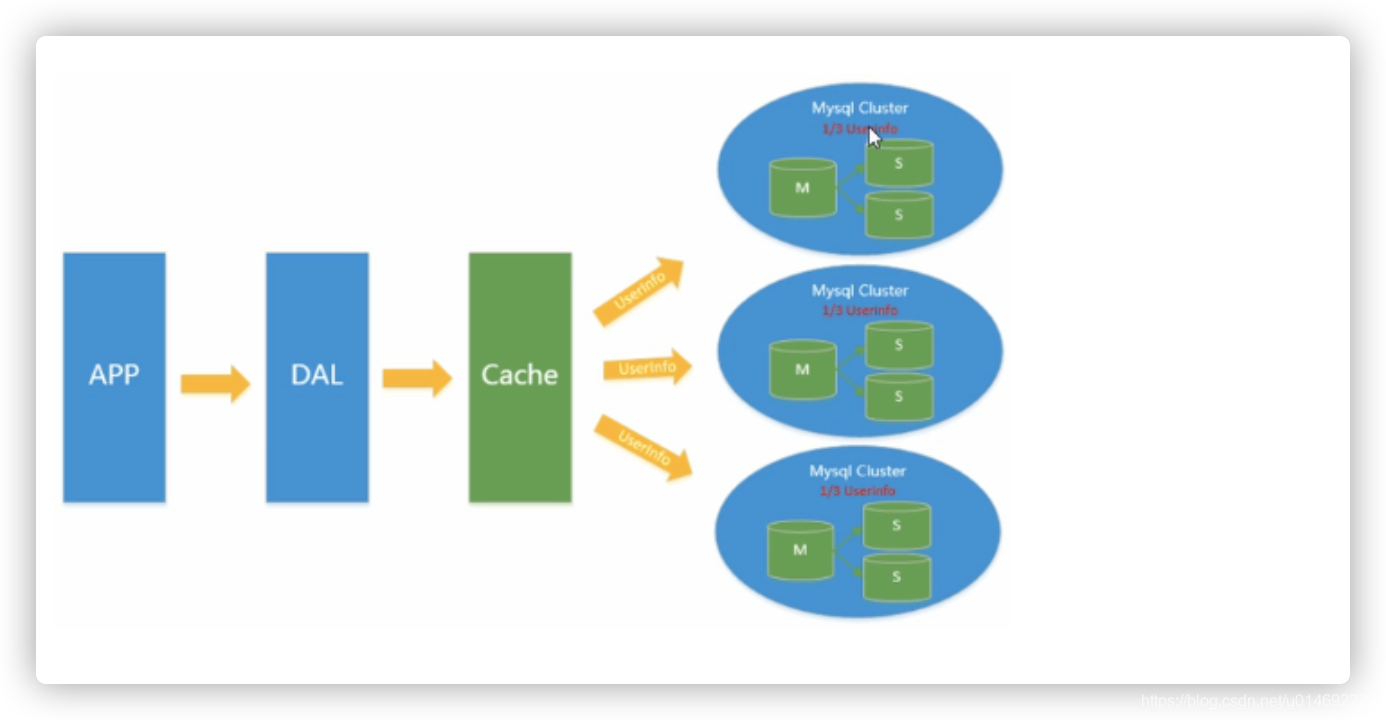
4.分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制, 读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
5.MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小, 如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySOL的开发人员面临的问题。
6.今天是什么样子? ?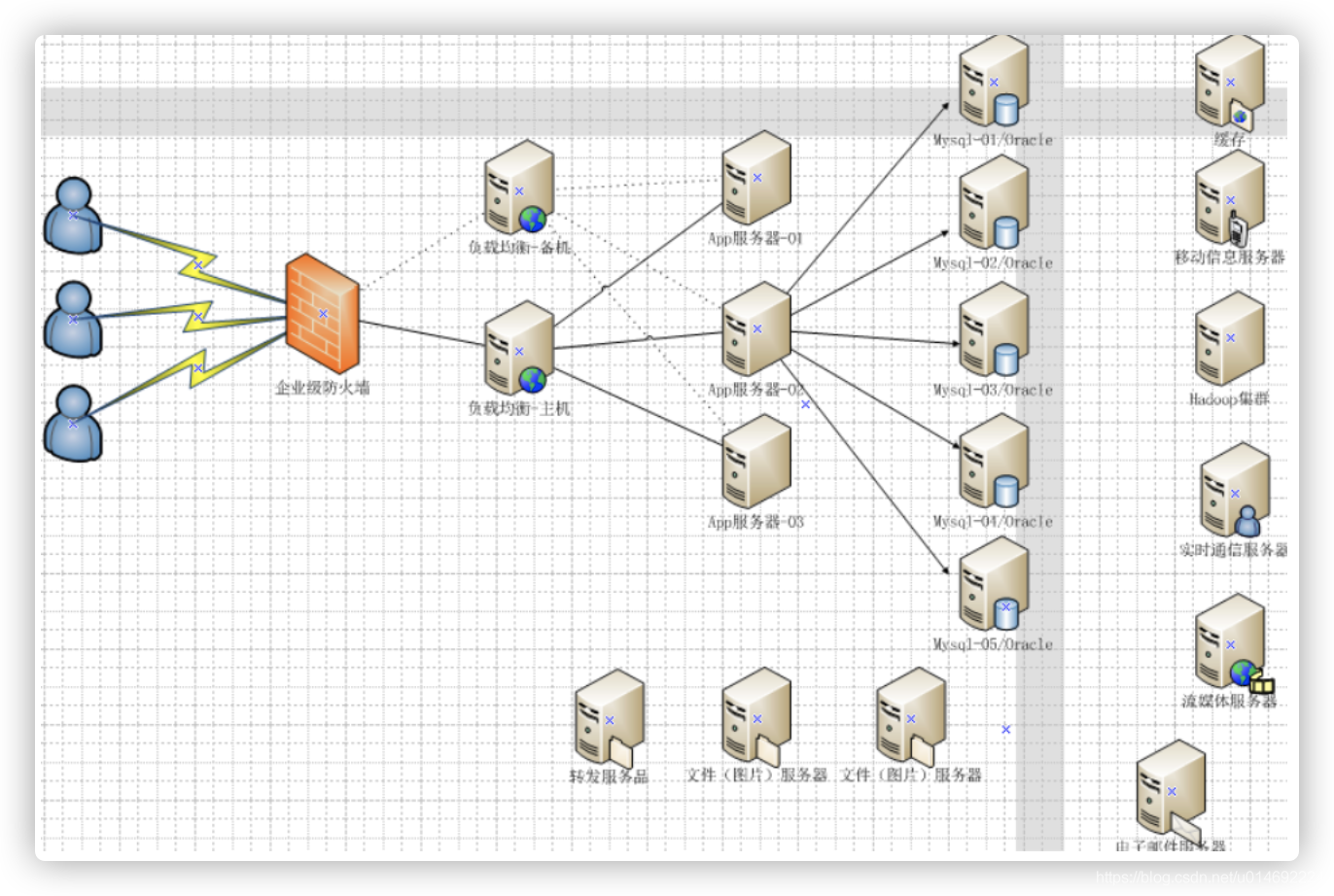
7.为什么用NoSQL
今天我们可以通过第三方平台( 如: Google,Facebook等) 可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了,NoSQL数据库的发展也却能很好的处理这些大的数据。
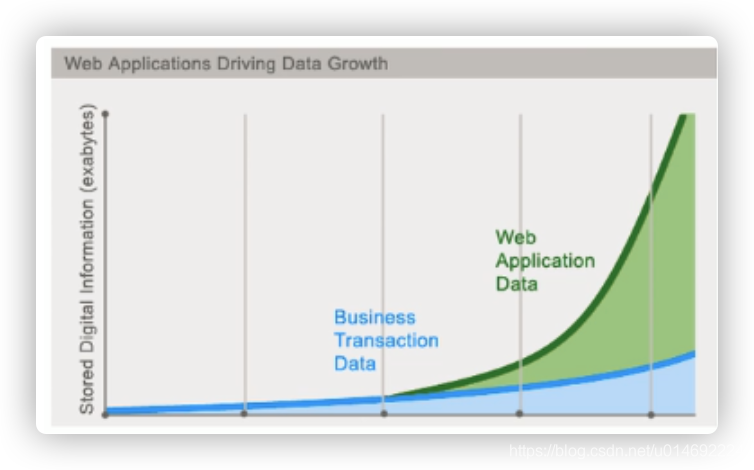
2.是什么
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL 数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
3.能干嘛
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量高性能
- NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
- 这得益于它的无关系性,数据库的结构简单。
- 一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。
- 而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
多样灵活的数据模型
- NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
- 而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
传统RDBMS VS NOSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键-值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据:
- CAP定理
- 高性能,高可用性和可伸缩性
4.有哪些NoSQL
- Redis
- Memcached
- MongDB
5.怎么玩
- KV
- Cache
- Persistence
02.NoSQL入门概述
3V + 3高
大数据时代的3V:
海量Volume
多样Variety
实时Velocity
互联网需求的3高:
高并发
高可括
高性能
03.当下NoSQL应用场景简介
SQL和NoSQL双剑合璧
Alibaba中文站商品信息如何存放
看看阿里巴巴中文网站首页以女装/女包包为例
架构发展历程:
-
演变过程
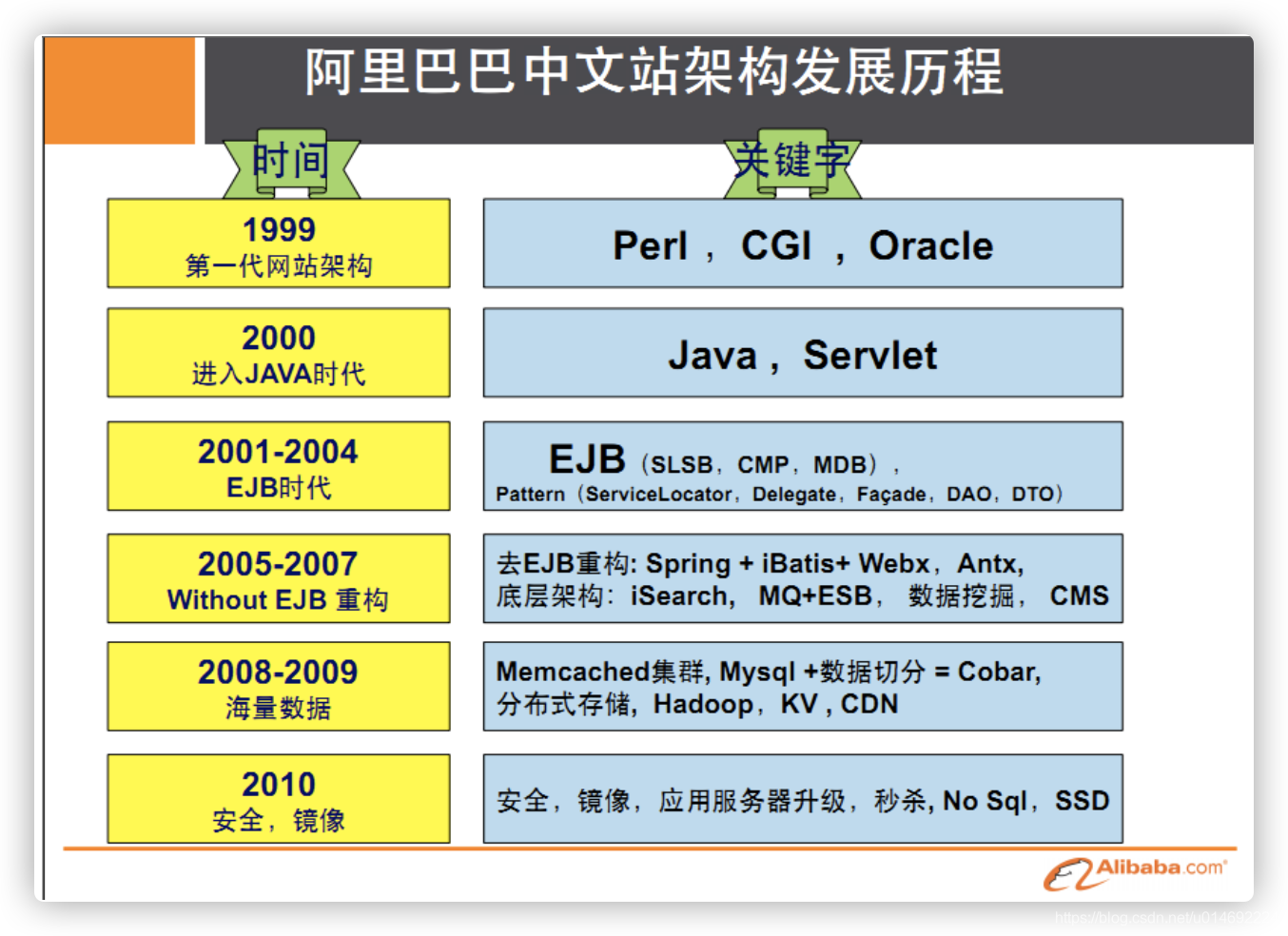
-
第5代

-
第5代架构使命

和我们相关的,多数据源类型的存储问题
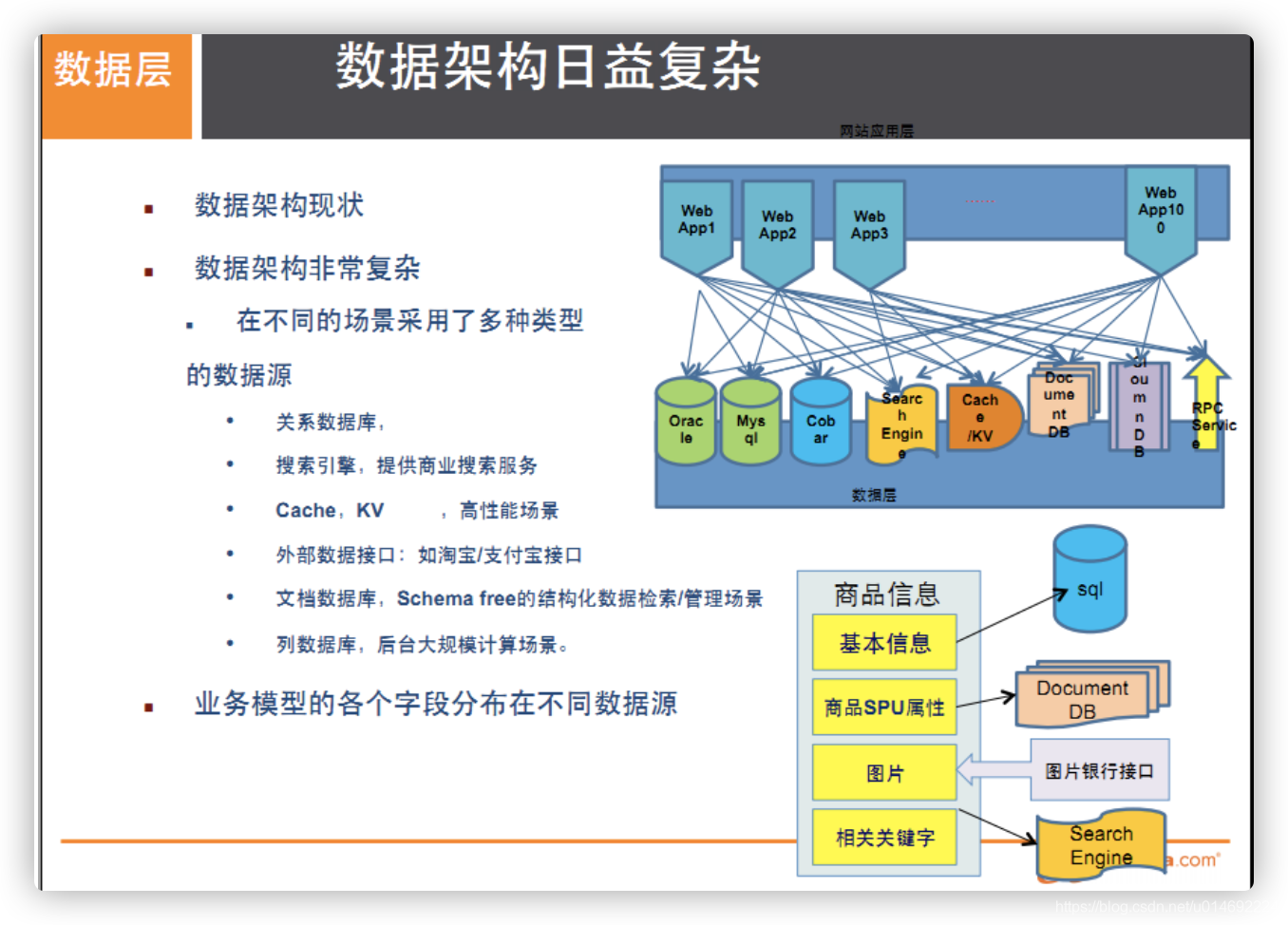
商品信息的存储方案
-
商品基本信息
- 名称、价格,出厂日期,生产厂商等
- 关系型数据库,mysql/oracle目前淘宝在去O化(也即拿掉Oracle),注意,淘宝内部用的 Mysql是里面的大牛自己改造过的. 为什么去IOE(在IT建设过程中,去除IBM小型机、Oracle数据库及EMC存储设备) 简 而意之,可不用穿脚链跳舞。
-
商品描述、详情、评价信息(多文字类)
多文字信息描述类,IO读写性能变差
文档数据库MongDB -
商品的图片
- 商品图片展现类
- 分布式的文件系统中
淘宝自家TFS
Google的GFS
Hadoop的HDFS
-
商品的关键字
淘宝自家
ISearch -
商品的波段性的热点高频信息(如,情人节的巧克力)
内存数据库
Tair、Redis、Memcache -
商品的交易、价格计算、积分累计
外部系统,外部第3方支付接口
支付宝
总结大型互联网应用(大数据、高并发、多样数据类型)的难点和解决方案
- 难点
数据类型多样性
数据源多样性和变化重构
数据源改造而数据服务平台不需要大面积重构 - 解决方法
EAI
UDSL 统一数据平台服务层
- 是什么
-
- 什么样
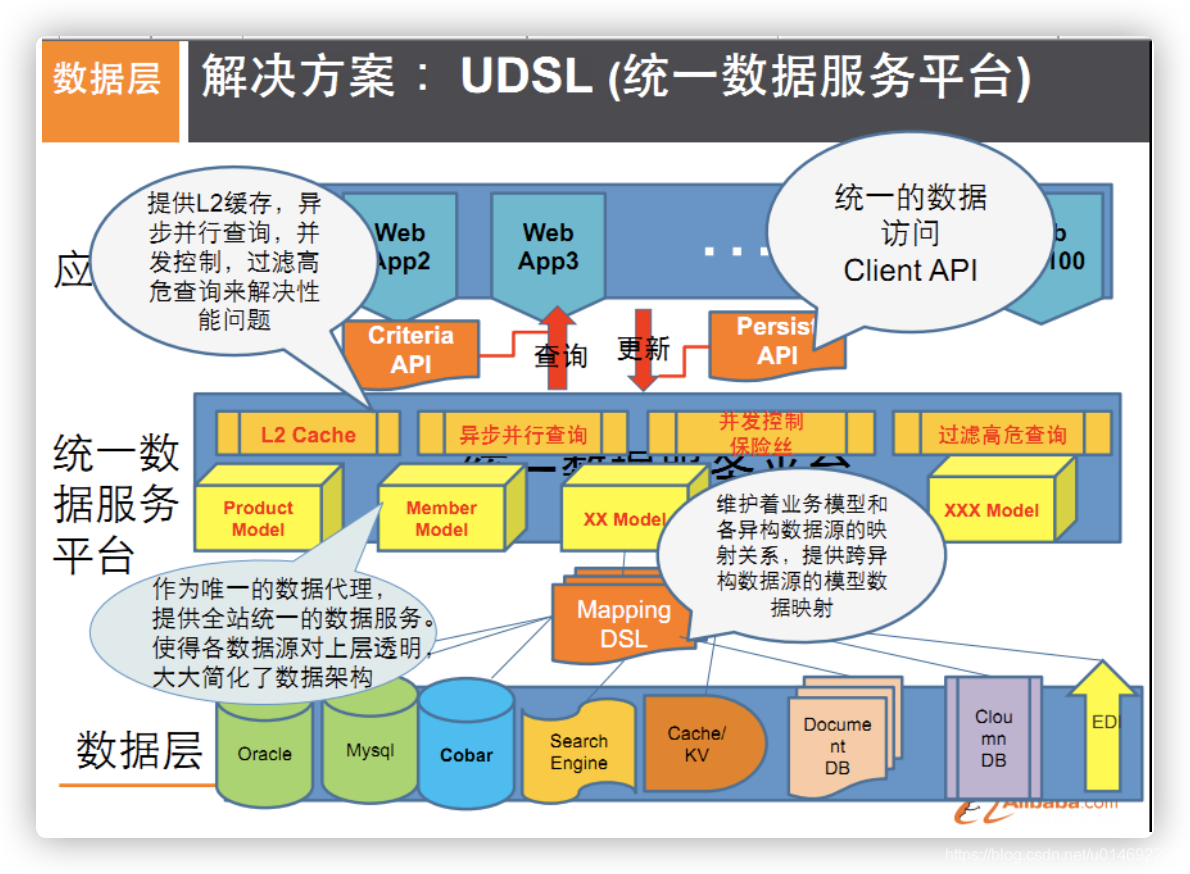
- 映射

- API

- 热点缓存
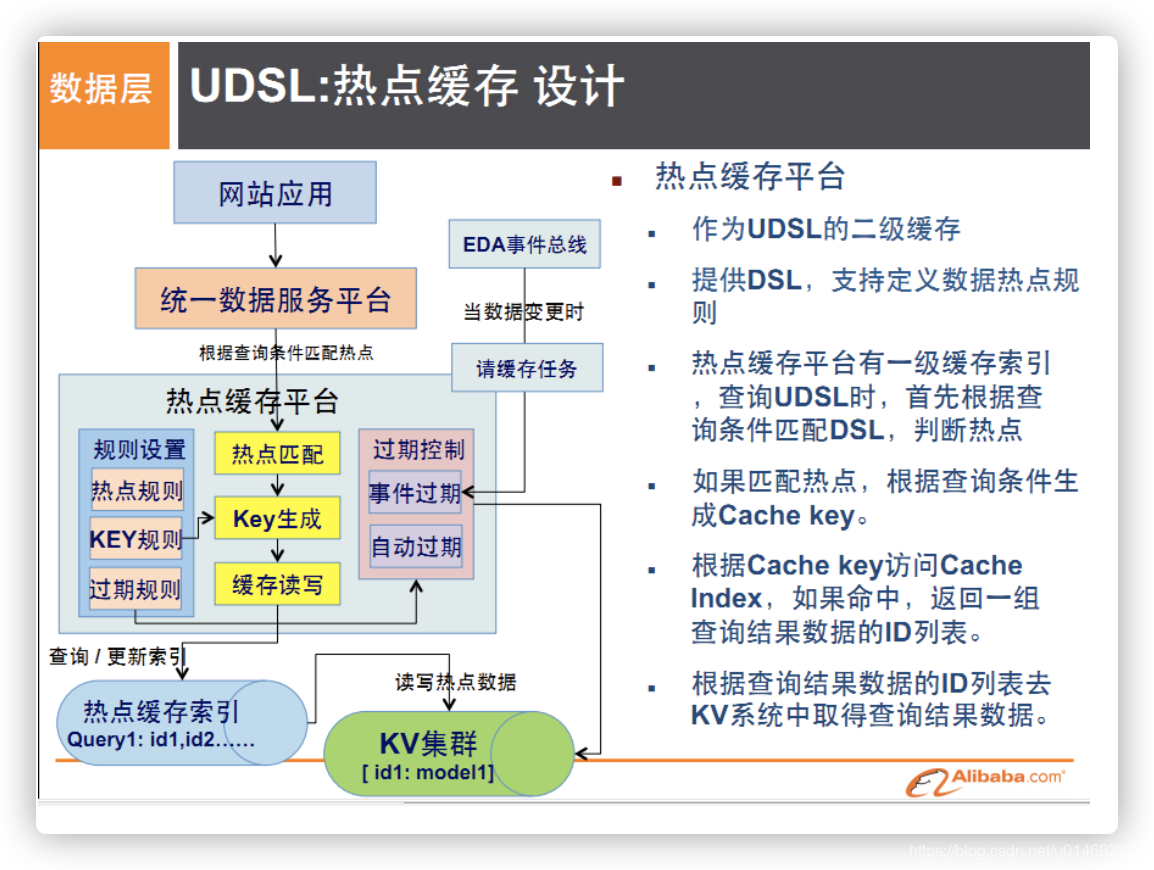
04.NoSQL数据模型简介
以一个电商客户、订单、订购、地址模型来对比关系型数据库和非关系型数据库
- 传统关系型数据库如何设计
- ER图(1:1、1:N、N:1)主外键等
- NOSQL如何设计
- BSON ()是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象
- 两者对比,问题和难点
- 问题和难点
- 为什么用聚合模型来处理
- 高并发的操作是不太建议用关联查询的,互联网公司用冗余数据来避免关联查询
- 分布式事务是支持不了太多的并发的
聚合模型
- KV
- BSON
- 列族
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一 列或者某几列的查询有非常大的IO优势。
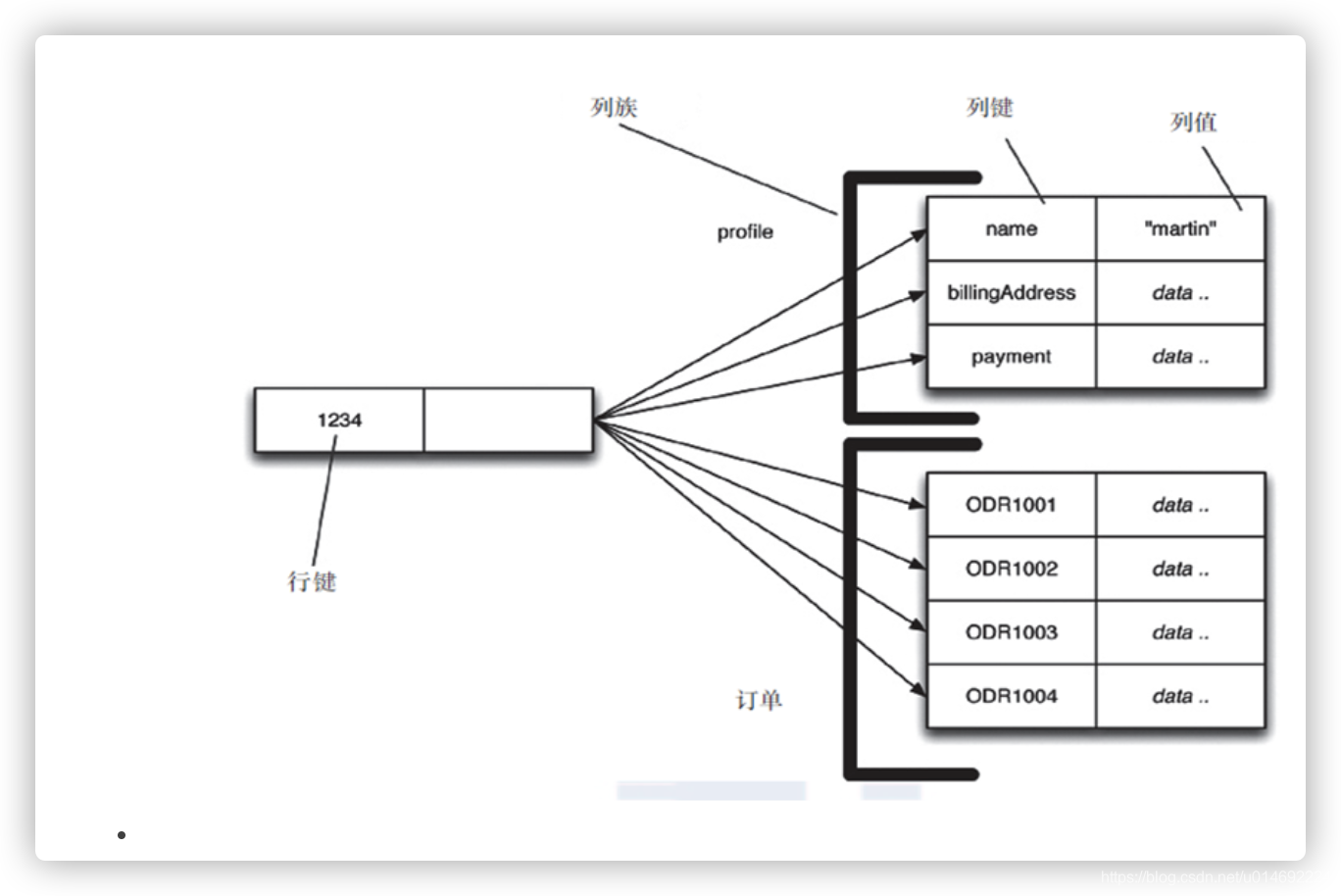
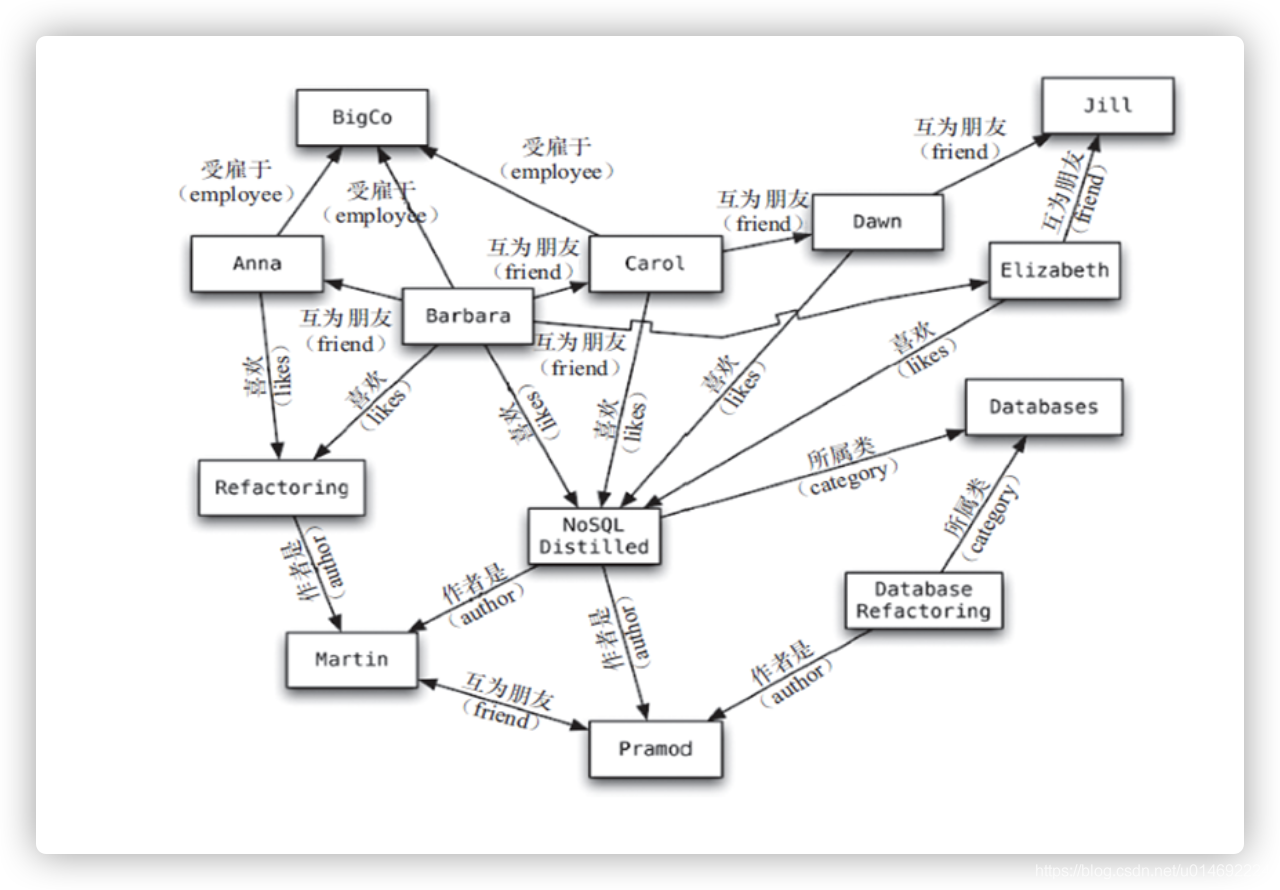
- 图形
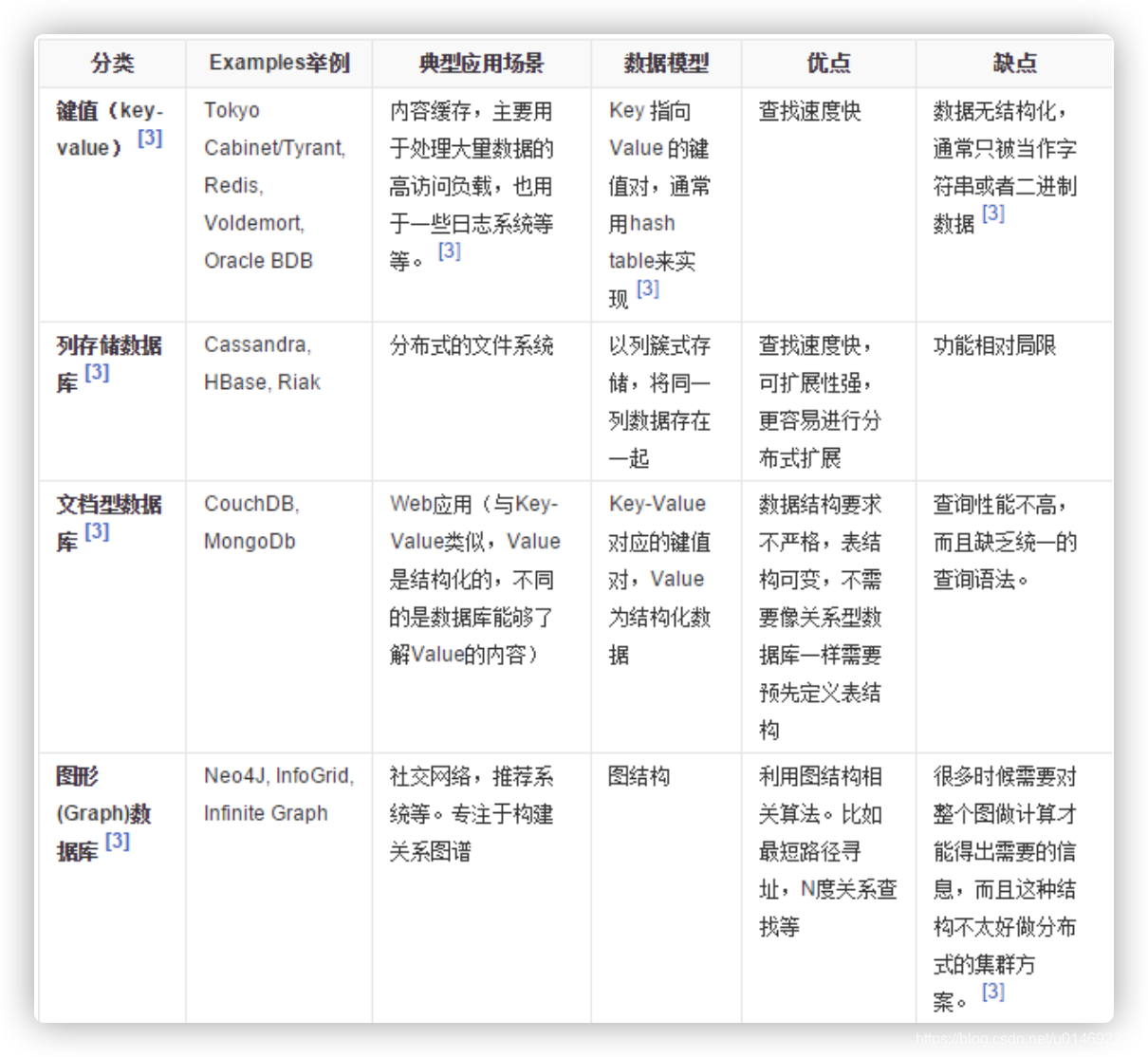
05.NoSQL数据库的四大分类
-
KV
新浪:BerkeleyDB + Redis
美团:Redis + tair
阿里、百度:memcache + Redis -
文档型数据库(bson格式比较多)
- CouchDB
- MongoDB
- MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提 供可扩展的高性能数据存储解决方案。
- MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
-
列存储数据库
- Cassandra、HBase
- 分布式文件系统
-
图关系数据库
它不是放图形的、放的是关系比如:朋友圈社交网络、广告推荐系统
社交网络、推荐系统。专注于构建关系图谱
Neo4j、InfoGrid
四者对比
06.分布式数据库CAP原理
传统的ACID分别是什么
- A (Atomicity) 原子性
- C (Consistency) 一致性
- I (Isolation) 独立性
- D (Durability) 持久性
关系型数据库遵循ACID规则,事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
**1、A (Atomicity) 原子性 原子性很容易理解,**也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
**2、C (Consistency) 一致性 一致性也比较容易理解,**也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
**3、I (Isolation) 独立性 所谓的独立性是指并发的事务之间不会互相影响,**如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的
**4、D (Durability) 持久性 持久性是指一旦事务提交后,**它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
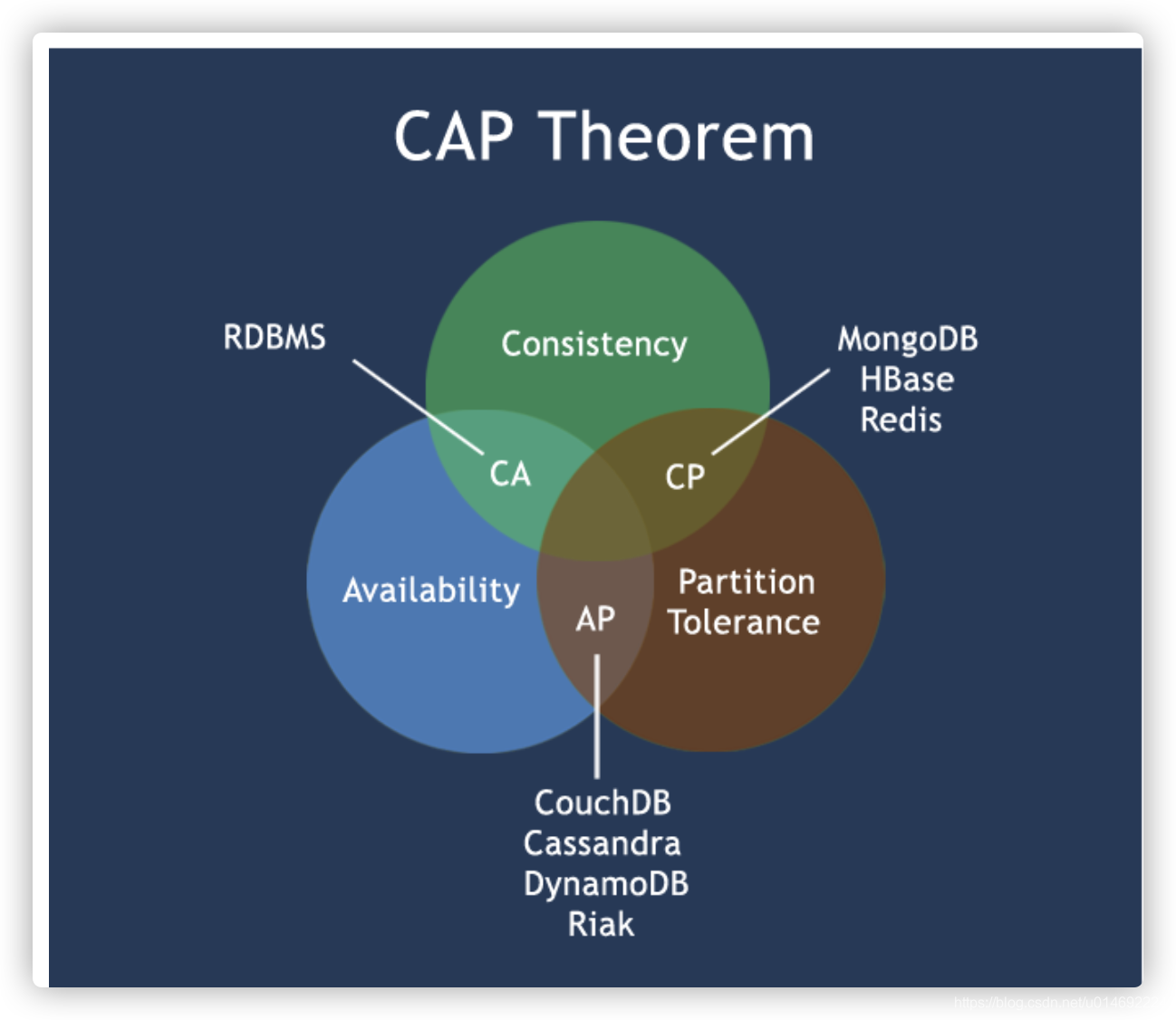
CAP
- C:Consistency(强一致性)
- A:Availability(可用性)
- P:Partition tolerance(分区容错性)
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。
而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
- CA 传统Oracle数据库
- AP 大多数网站架构的选择
- CP Redis、Mongodb
注意:分布式架构的时候必须做出取舍。
一致性和可用性之间取一个平衡。多余大多数web应用,其实并不需要强一致性。因此牺牲C换取P,这是目前分布式数据库产品的方向。
一致性与可用性的决择
对于web2.0网站来说,关系数据库的很多主要特性却往往无用武之地
数据库事务一致性需求
很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低, 有些场合对写一致性要求并不高。允许实现最终一致性。
数据库的写实时性和读实时性需求
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说在微博发一条消息之后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询,特别是SNS类型的网站,从需求以及产品设计角 度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大的弱化了。
经典CAP图
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
BASE
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
BASE其实是下面三个术语的缩写:
- 基本可用(Basically Available)
- 软状态(Soft state)
- 最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法
分布式+集群简介
分布式系统(distributed system)
由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。分布式系统可以应用在在不同的平台上如:PC、工作站、局域网和广域网上等。
简单来讲:
- 分布式:不同的多台服务器上面部署不同的服务模块(工程),他们之间通过Rpc/Rmi之间通信和调用,对外提供服务和组内协作。
- 集群:不同的多台服务器上面部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。
07.安装
入门概述
redis是什么
Redis:REmote DIctionary Server(远程字典服务器)是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行 并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,也被人们称为数据结构服务器。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
- Redis支持数据的备份,即master-slave模式的数据备份
能干嘛
- 内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
- 取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
- 模拟类似于HttpSession这种需要设定过期时间的功能
- 发布、订阅消息系统
- 定时器、计数器
去哪下
redis官网
redis中文官网
怎么玩
- 数据类型、基本操作和配置
- 持久化和复制,RDB/AOF
- 事务的控制
- 复制(主从关系)
Redis的安装
Linux版安装
略
Windows版安装
redis for windows
mac 安装
mac安装
大多数企业是使用Linux的Redis,Windows仅供学习。
08.HelloWorld
- 打开cmd
- 输入cd C:\Program Files\Redis-x64-3.2.100,进入Redis的主目录
- 输入redis-server.exe redis.windows.conf,打开Redis服务端
- 另外打开cmd
- 输入cd C:\Program Files\Redis-x64-3.2.100,进入Redis的主目录
- 输入redis-cli.exe -h 127.0.0.1 -p 6379,打开Redis客户端
- 在Redis客户端输入set hello world回车,再输入get hello回车便返回world。
- 在Redis客户端输入exit回车、退出客户端。
C:\Program Files\Redis-x64-3.2.100>redis-cli.exe
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379>09.启动后杂项基础知识
- C:\Program Files\Redis-x64-3.2.100>redis-benchmark.exe 测试redis在机器运行的效能
- 单进程
单进程模型来处理客户端的请求。对读写等事件的响应 是通过对epoll函数的包装来做到的。Redis的实际处理速度完全依靠主进程的执行效率
Epoll是Linux内核为处理大批量文件描述符而作了改进的epoll,是Linux下多路复用IO接口select/poll的增强版本, 它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。 - 默认16个数据库,类似数组下表从零开始,初始默认使用零号库,可在配置文件配置
- select命令切换数据库
- dbsize查看当前数据库的key的数量
- flushdb:清空当前库
- flushall;通杀全部库
- 统一密码管理,16个库都是同样密码,要么都OK要么一个也连接不上
- Redis索引都是从零开始
- 为什么默认端口是6379
10.常用五大数据类型简介
Redis的五大数据类型
String(字符串)
- string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
- string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
Hash(哈希,类似java里的Map) - Redis hash 是一个键值对集合。
- Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
List(列表) - Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
它的底层实际是个链表
Set(集合) - Redis的Set是string类型的无序集合。它是通过HashTable实现实现的
Zset(sorted set:有序集合) - Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。 - redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
- 哪里去获得redis常见数据类型操作命令
redis命令参考
redis官网参考
11.Key关键字
常用的
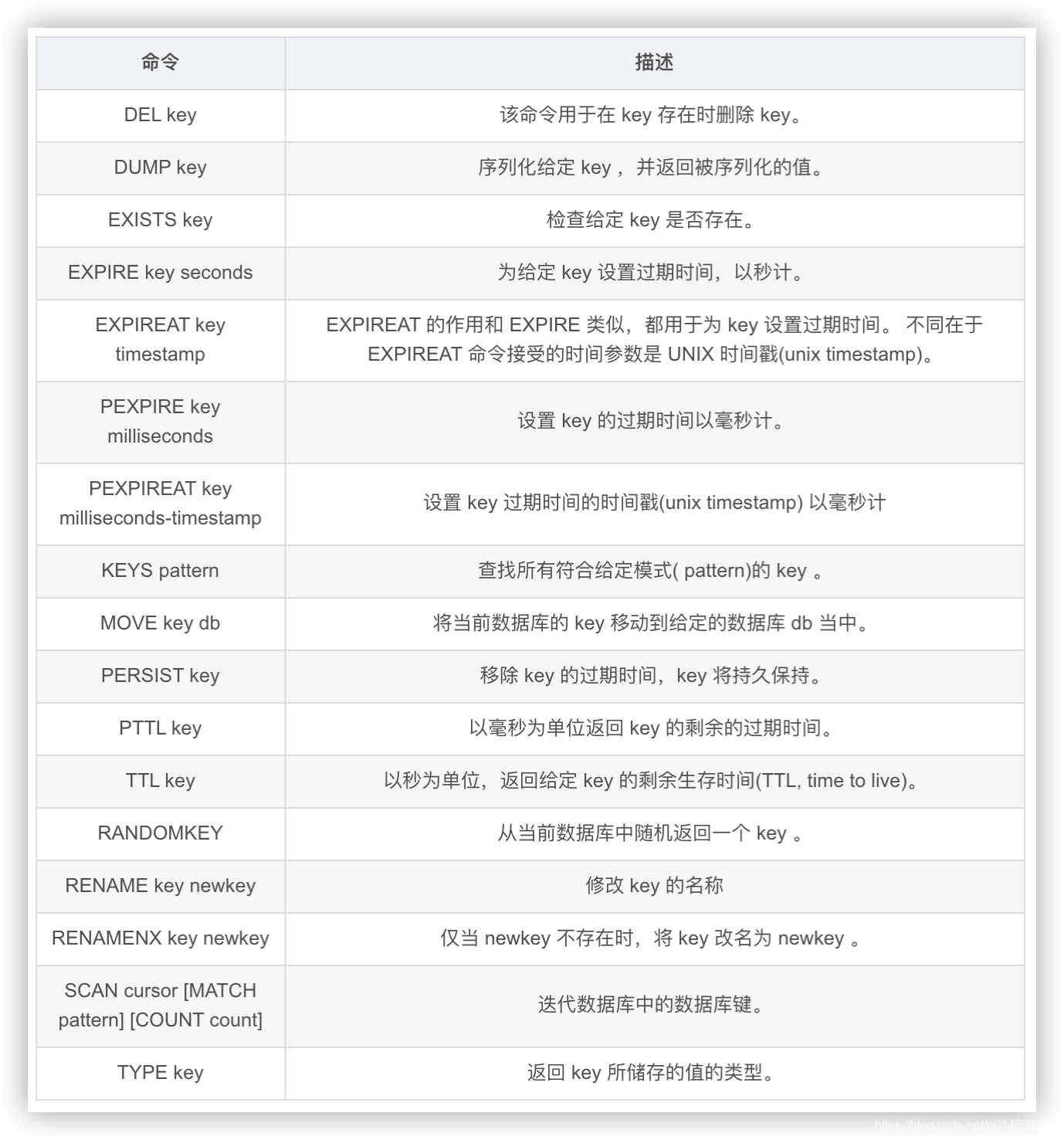
案例
- keys *
- exists key的名字,判断某个key是否存在
- move key db —>当前库就没有了,被移除了
- expire key 秒钟:为给定的key设置过期时间
- ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
- type key 查看你的key是什么类型
12.String
单值单value
常用
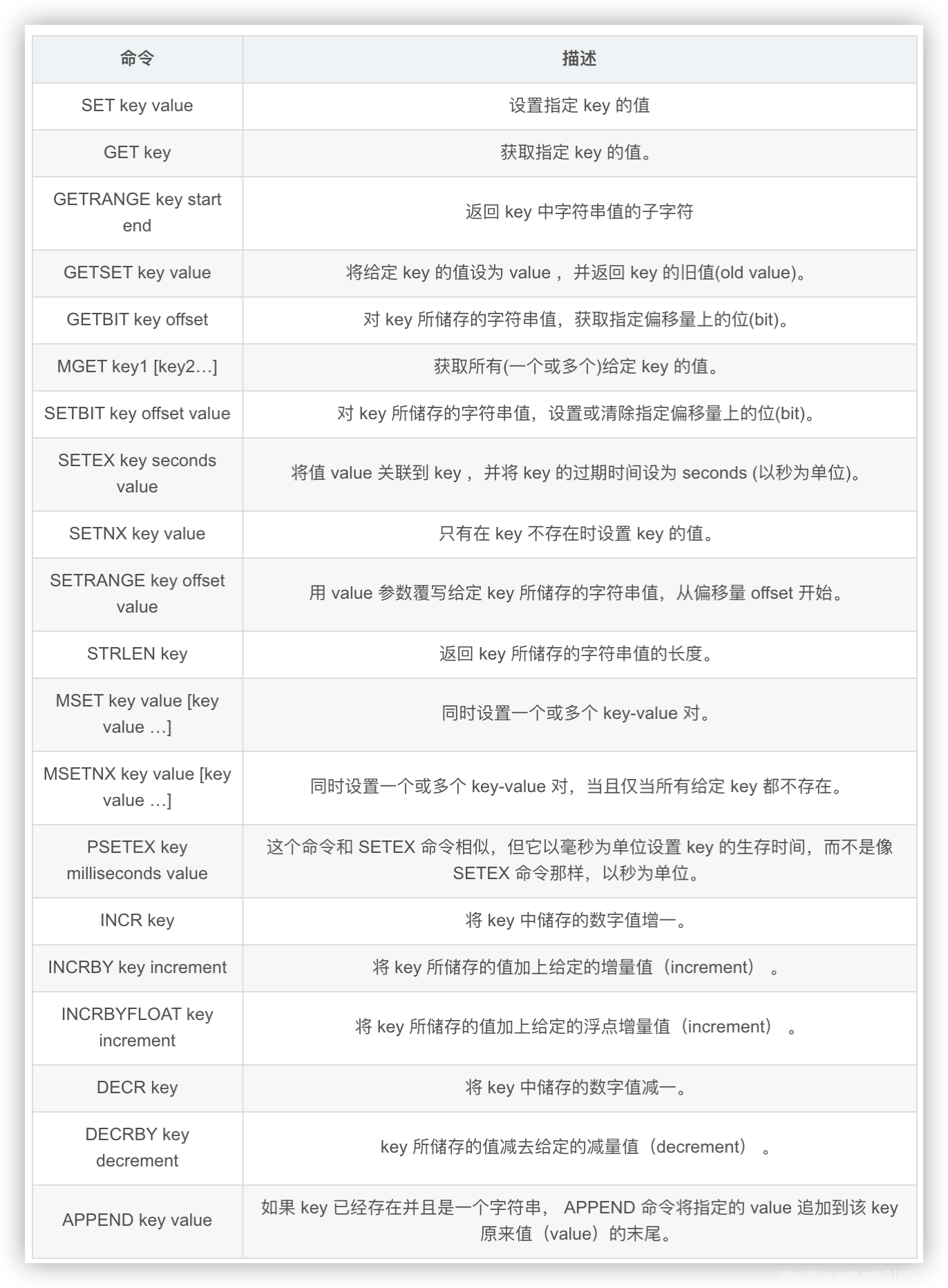
案例
- set/get/del/append/strlen
- Incr/decr/incrby/decrby,一定要是数字才能进行加减
- getrange/setrange
- setex(set with expire)键秒值/setnx(set if not exist)
- mset/mget/msetnx
- getset(先get再set)
示例
set key value 将字符串值 value 关联到 key ,如果 key 已经持有其他值, SET 就覆写旧值,无视类型。
get key 取key的值value
del key 删除key:删除操作成功 返回(integer)1;删除操作失败 返回(integer)0
演示案例
127.0.0.1:6379> set a 123 <!--新建key: a 并且赋值为123-->
OK
127.0.0.1:6379> get a <!--获取key: a 的值-->
"123"
127.0.0.1:6379> set a 1234 <!--修改key: a 赋值,会覆盖之前的值123,此时 a 的新值为1234-->
OK
127.0.0.1:6379> get a <!--获取修改后的key: a 的值-->
"1234"
127.0.0.1:6379> del a <!--删除key: a-->
(integer) 1(2) 高级命令
mset k1 v1 k2 v2 k3 v3 ... 一次性添加或修改多个键值对
mget k1 k2 k3... 一次性获取k1 k2 k3...的value
strlen k 获取k对应的v的字符串长度
append k v 往k对应的v尾部追加数据,如果不存在就新建,这时候相当于set k v
演示案例
127.0.0.1:6379> mset a 1 b 2 c 3 <!-- 一次性添加a、b、c三个key,键值分别为1、2、3-->
OK
127.0.0.1:6379> mget a b c <!-- 一次性获取a、b、c三个key的值-->
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> strlen a <!--获取a对应的v的字符串长度-->
(integer) 1
127.0.0.1:6379> append a 23 <!--往a对应的v的字符串后面追加23字符串-->
(integer) 3
127.0.0.1:6379> get a <!--查询追加23字符串后的a的值-->
"123"
(3) 其它命令
① 自增自减操作控制数据库主键
incr key 对应的value加1decr key 对应的value减1incrby key increment 对应的value+incrementdecrby key increment 对应的value-incrementincrbyfloat key increment 对应的value+一个浮点数演示案例
127.0.0.1:6379> set a 6 <!--新建k: a 的值为 6-->
OK
127.0.0.1:6379> incr a <!--自增1-->
(integer) 7
127.0.0.1:6379> incr a <!--自增1-->
(integer) 8
127.0.0.1:6379> decr a <!--自减1-->
(integer) 7
127.0.0.1:6379> decr a <!--自减1-->
(integer) 6
127.0.0.1:6379> incrby a 2 <!--对应的value + 2-->
(integer) 8
127.0.0.1:6379> incrby a 3 <!--对应的value + 3-->
(integer) 11
127.0.0.1:6379> decrby a 2 <!--对应的value - 2-->
(integer) 9
127.0.0.1:6379> decrby a 3 <!--对应的value - 3-->
(integer) 6
127.0.0.1:6379> incrbyfloat a 1.5 <!--对应的value + 1.5-->
"7.5"
**注意:**按数值进行的操作,如果原始数据不能转换为数字,或者超过了redis的数值上限,操作会报错,其中数值上限是java中long的最大值。
<!--对应的b的值为a,加减运算不能自动转为数字,会报错-->127.0.0.1:6379> set b a
OK
127.0.0.1:6379> incr b
(error) ERR value is not an integer or out of range
127.0.0.1:6379>② 设置数据的生命周期
setex key seconds value 将值 value 关联到 key ,并将 key 的生存时间设为 seconds (以秒为单位)。如果 key 已经存在, SETEX 命令将覆写旧值。psetex key milliseconds value 将值 value 关联到 key ,并将 key 的生存时间设为 seconds (以毫秒为单位)。如果 key 已经存在, SETEX 命令将覆写旧值。演示案例
127.0.0.1:6379> setex a 60 123 <!--新建key: a ,生存时间为60秒,value为123-->
OK
127.0.0.1:6379> psetex b 60 1234 <!--新建key: a ,生存时间为60毫秒,value为1234-->
OK注意: 如果setex一个k后,再set这个k,那么定时的k会被清除,变成不定时的。
2、应用场景
(1) 在Redis中为CSDN用户设定用户信息,以用户主键和属性值作为key,后台设置定时刷新策略
user:id qq_41918166:fans -> 123456
user:id qq_41918166:blogs -> 2333
(2) 存json数据
set user: id:12345 {id:12345,fans:123456,blogs:2333,focus:666}
(3) 数据库的热点数据key命名规范:
13.List
单值多value
案例
- lpush/rpush/lrange
- lpop/rpop
- lindex,按照索引下标获得元素(从上到下)
- llen
- lrem key 删N个value
- ltrim key 开始index 结束index,截取指定范围的值后再赋值给key
- rpoplpush 源列表 目的列表
- lset key index value
- linsert key before/after 值1 值2
性能总结:
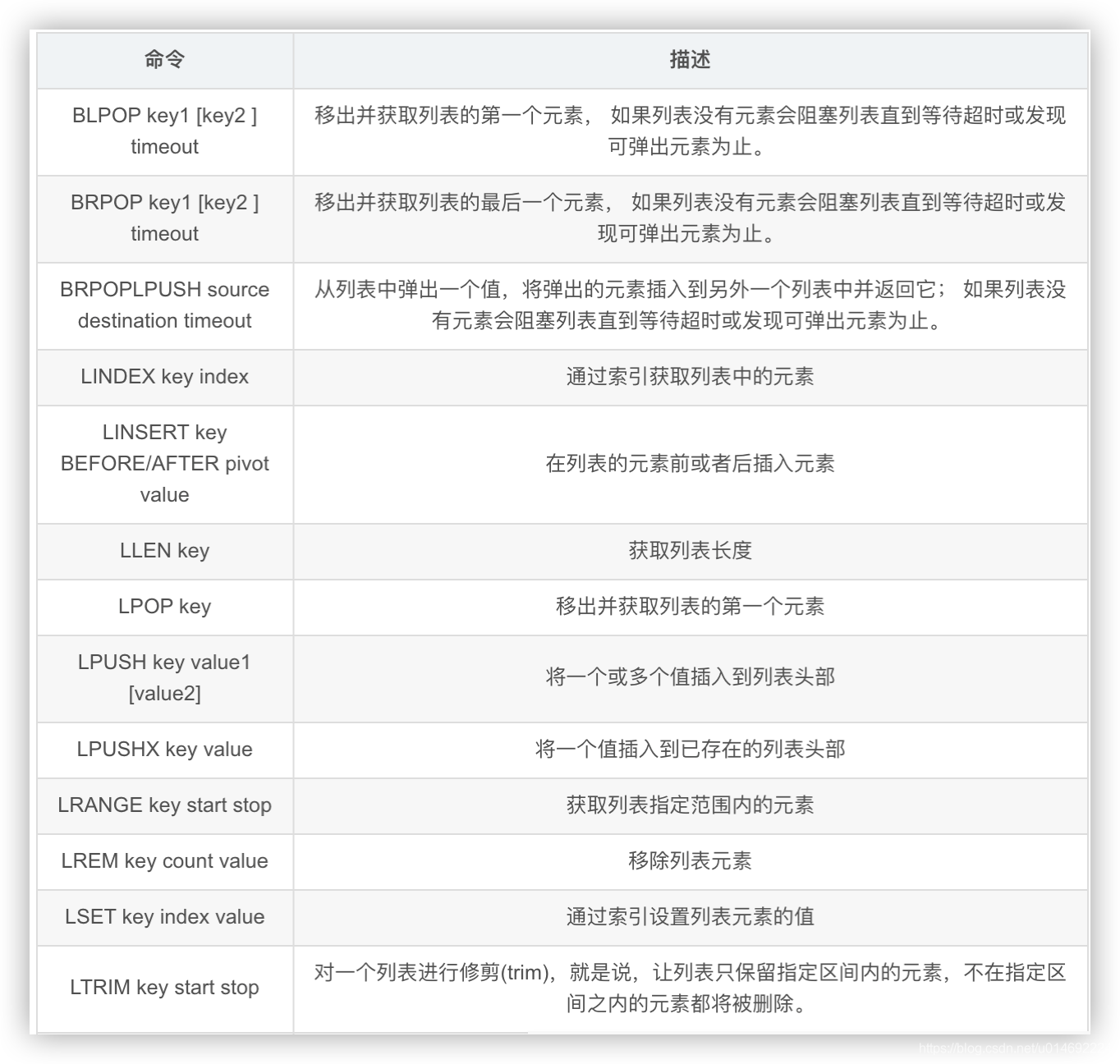
- 它是一个字符串链表,left、right都可以插入添加;
- 如果键不存在,创建新的链表;
- 如果键已存在,新增内容;
- 如果值全移除,对应的键也就消失了。
- 链表的操作无论是头和尾效率都极高,但假如是对中间元素进行操作,效率就很惨淡了。
1、ArrayList与LinkedList的区别
(1) ArrayList使用数组方式存储数据,所以根据索引查询数据速度快,而新增或者删除元素时需要设计到位移操作,所以比较慢
(2) LinkedList使用双向链表方式存储数据,每个元素都记录前后元素的指针,所以插入、删除数据时只是更改前后元素的指针指向即可,速度非常快。然后通过下标查询元素时需要从头开始索引,所以比较慢,但是如果查询前几个元素或后几个元素速度比较快
示例
示例
(1) 基本命令:
lpush key value1 value2 ... 左侧插入
rpush key value1 value2 ... 右侧插入
lrange key start stop 从start开始到stop结束的下标的数据,引从0开始,如果是负数结束,比如stop=-1,那就是截止到倒数第一个
lindex key index 找到index位置的数据
lpop key 移除并返回第一个元素
rpop key 移除并返回最后一个元素
llen 获取列表中元素个数
lrem key count value 删除list列表中number个value(因为list元素可以重复,所以要指定count)1)当count>0时, lrem会从列表左边开始删除2)当count<0时, lrem会从列表后边开始删除3)当count=0时, lrem删除所有值为value的元素
ltrim key start stop 只保留列表中start开始到stop结束之间指定片段的数据
linsert key before|after pivot value 该命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入到该元素的前面还是后面rpoplpush source destination 将元素(左侧第一个元素)从一个列表转移到另一个列表中(左侧插入),并且返回被移入的元素,新列表destination不存在的话,会自动新建列表destination 演示案例
127.0.0.1:6379> lpush list:1 1 2 3 <!--从左侧插入1、2、3-->
(integer) 3
127.0.0.1:6379> rpush list:1 4 5 6 <!--从右侧插入4、5、6-->
(integer) 6
127.0.0.1:6379> lrange list:1 0 2 <!--从右侧取出下标为0~2之间的元素-->
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lrange list:1 0 -1 <!--取出所有元素-->
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"
127.0.0.1:6379> lindex list:1 3 <!--获取下标为3的元素-->
"4"
127.0.0.1:6379> lpop list:1 <!--移除并返回第一个元素3-->
"3"
127.0.0.1:6379> rpop list:1 <!--移除并返回最后一个元素6-->
"6"
127.0.0.1:6379> llen list:1 <!--获取list中的元素个数-->
(integer) 4
127.0.0.1:6379> lrange list:1 0 -1 <!--获取list中的元素,验证上步的执行-->
1) "2"
2) "1"
3) "4"
4) "5"
127.0.0.1:6379> lrem list:1 1 2 <!--从左侧删除1个2-->
(integer) 1
127.0.0.1:6379> lrem list:1 -1 5 <!--从右侧删除1个5-->
(integer) 1
127.0.0.1:6379> lrange list:1 0 -1 <!--获取list中的元素,验证上步的执行-->
1) "1"
2) "4"
127.0.0.1:6379> lrem list:1 0 1 <!--删除list中所有的1-->
(integer) 1
127.0.0.1:6379> lrange list:1 0 -1 <!--获取list中的元素,验证上步的执行-->
1) "4"
127.0.0.1:6379> linsert list:1 after 4 1 <!--在4后面添加元素1-->
(integer) 2
127.0.0.1:6379> lrange list:1 0 -1 <!--获取list中的元素,验证上步的执行-->
1) "4"
2) "1"
127.0.0.1:6379> rpoplpush list:1 newlist <!--将list:1列表左侧第一个元素 1 移入列表 newlist中,并且返回被移入的元素 1-->
"1"
127.0.0.1:6379> lrange newlist 0 -1 <!--获取newlist中的元素,验证上步的执行-->
1) "1"
127.0.0.1:6379> lrange list:1 0 -1 <!--获取list中的元素,验证上上一步的执行-->
1) "4"
127.0.0.1:6379> rpoplpush list:1 newlist <!--将list:1列表左侧第一个元素 4 移入列表 newlist中,并且返回被移入的元素 4 -->
"4"
127.0.0.1:6379> lrange newlist 0 -1 <!--获取newlist中的元素,验证上一步的执行,是从newlist列表左侧插入的-->
1) "4"
2) "1"(2) 扩展操作 :
① 规定时间内获取并移除元素。阻塞式数据获取。
② 如果本来没元素了,但是timeout时间内等到了元素(有其他人插入),就返回
blpop key timeout
brpop key timeout14.Set
单值多value
常用
案例
- sadd/smembers/sismember
- scard,获取集合里面的元素个数
- srem key value 删除集合中元素
- srandmember key 某个整数(随机出几个数)
- spop key 随机出栈
- smove key1 key2 在key1里某个值 作用是将key1里的某个值赋给key2
- 数学集合类
差集:sdiff
交集:sinter
并集:sunion
示例
sadd key value1 value2 ... 添加数据smembers key 获取全部数据scard key 获取数据总量sismember key value 判断value是否是key集合内的数据 srem key value 删除数据
演示案例
127.0.0.1:6379> sadd set1 1 2 3 <!--新建一个集合set1,集合中放入数据1、2、3-->
(integer) 3
127.0.0.1:6379> smembers set1 <!--获取集合set1中的所有数据-->
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> scard set1 <!--获取集合set1中的数据数量-->
(integer) 3
127.0.0.1:6379> sismember set1 2 <!--判断数据 2 是否是集合set1中的数据-->
(integer) 1
127.0.0.1:6379> sismember set1 4 <!--判断数据 4 是否是集合set1中的数据-->
(integer) 0
127.0.0.1:6379> srem set1 3 <!--删除集合set1中的数据 3 -->
(integer) 1
127.0.0.1:6379> smembers set1 <!--获取集合set1中的所有数据验证上步操作-->
1) "1"
2) "2"
(2) set 运算命令
sinter set1 set2 ... 求多个集合的交集:属于set1且属于set2的元素构成的集合sunion set1 set2 ... 求多个集合的并集:属于set1或者属于set2的元素构成的集合sdiff set1 set2 ... 求多个集合的差集:属于set1并且不属于set2 的元素构成的集合sinterstore des set1 set2 ... 求多个集合的交集,并且把交集存入集合des中sunionstore des set1 set2 ... 求多个集合的并集,并且把交集存入集合des中sdiffstore des set1 set2 ... 求多个集合的差集,并且把交集存入集合des中smove src des value 将指定数据value从源集合src移动到目标集合des演示案例
127.0.0.1:6379> sadd setA 1 2 3 <!--新建set集合 setA,存入数据 1、2、3-->
(integer) 3
127.0.0.1:6379> sadd setB 2 3 4 <!--新建set集合 setB,存入数据 2、3、4-->
(integer) 3
127.0.0.1:6379> sinter setA setB <!--求集合setA与setB的交集-->
1) "2"
2) "3"
127.0.0.1:6379> sunion setA setB <!--求集合setA与setB的并集-->
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> sdiff setA setB <!--求集合setA与setB的差集-->
1) "1"
127.0.0.1:6379> sdiff setB setA <!--求集合setB与setA的差集-->
1) "4"
127.0.0.1:6379> sinterstore setC setA setB <!--求集合setA与setB的交集,并且把交集存入集合setC中-->
(integer) 2
127.0.0.1:6379> smembers setC <!--获取集合setC中的数据,验证上一步操作-->
1) "2"
2) "3"
127.0.0.1:6379> sunionstore setD setA setB <!--求集合setA与setB的并集,并且把并集存入集合setD中-->
(integer) 4
127.0.0.1:6379> smembers setD <!--获取集合setD中的数据,验证上一步操作-->
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> sdiffstore setE setA setB <!--求集合setA与setB的差集,并且把差集存入集合setE中-->
(integer) 1
127.0.0.1:6379> smembers setE <!--获取集合setE中的数据,验证上一步操作-->
1) "1"
127.0.0.1:6379> smove setE setF 1 <!--将指定数据 1 从集合setE 中 移动到 集合setF 中-->
(integer) 1
127.0.0.1:6379> smembers setF <!--获取集合setF中的数据,验证上一步操作-->
1) "1"3、注意事项
(1) set不允许重复。如果重复添加,会添加失败
(2) set虽然结构上是hash,但是存储值的空间无法启用
① hash: key-{field:value}
② set: key-{value:nil}
(3) Redis最好只提供基础数据,别提供校验结果
(4) set的特征进行同类型数据快速去重
15.Hash
KV模式不变,但V是一个键值对
常用
案例
- hset/hget/hmset/hmget/hgetall/hdel
- hlen
- hexists key 在key里面的某个值的key
- hkeys/hvals
- hincrby/hincrbyfloat
- hsetnx
**提出原由:**假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下: 保存、更新 。 User “{“username”:”gyf”,”age”:”80”}”
思考:如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,接下来的hash可以很好的解决这个问题。
1、hash介绍
(1) 基本概念:hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。
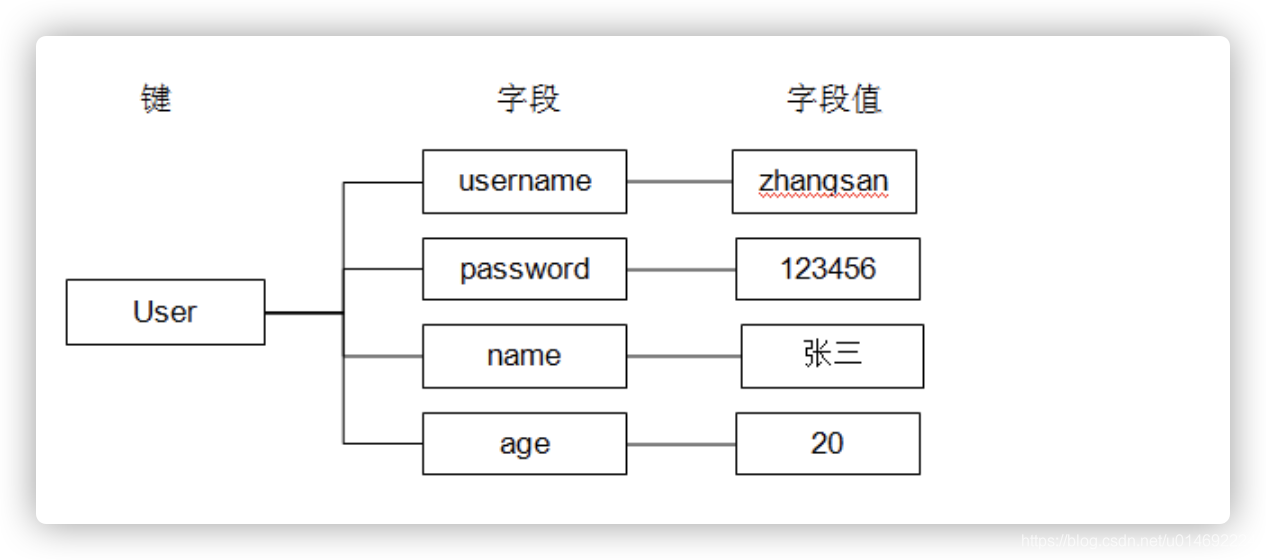
(2) 格式:一个存储空间(key)存储多个键值对,底层通过哈希表进行存储。
key -- {filed1 - v1, filed2 - v2,...}
注意:如果filed数量较多时,会被优化为类数组的结构,如果filed数量多,就是HashMap。
2、命令
(1) 基本命令:
hset key field value 新增/修改某个field的v,新增时返回1,修改时返回0
hsetnx key field value 如果key中没有field字段则设置field值为value,否则不做任何操作
hget key field 获取某个field的vhgetall key 获取这个key的所有f-vhdel key field 删除某个field,可以删除一个或多个,返回值是被删除的字段个数 del key 删除整个key
演示案例
127.0.0.1:6379> hset user username zhangsan <!--新增 user username属性,value为 zhangsan-->
(integer) 1
127.0.0.1:6379> hset user age 20 <!--新增 user age属性,value为 20-->
(integer) 1
127.0.0.1:6379> hset user sex man <!--新增 user sex属性,value为 man-->
(integer) 1
127.0.0.1:6379> hsetnx user age 30 <!--user中有age字段则不做任何修改,age 的值还是20-->
(integer) 0
127.0.0.1:6379> hget a age <!--验证上一步hsetnx没有做任何修改,age 的值还是20-->
"20"
127.0.0.1:6379> hget user username <!--获取 user username属性,value为 zhangsan-->
"zhangsan"
127.0.0.1:6379> hgetall user <!--获取 user 所有的属性和value-->
1) "username"
2) "zhangsan"
3) "age"
4) "20"
5) "sex"
6) "man"
127.0.0.1:6379> hdel user age sex <!--删除 user age与sex属性-->
(integer) 2
127.0.0.1:6379> del user <!--删除 user 的所有属性即属性的value-->
(integer) 1
(2) 一次性多个数据的操作
hmset key f1 v1 f2 v2 f3 v3 ... 新增/修改某个field的f1、f2、f3,值分别为v1、v2、v3hmget key f1 f2 f3... 获取某个field的f1、f2、f3 的值hlen key 获取key的字段数量,就是field的数量hexists key field 判断key中是否存在field这个字段演示案例
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0
16.ZSet
在set基础上,加一个score值。 之前set是k1 v1 v2 v3, 现在zset是k1 score1 v1 score2 v2
常用
案例
- zadd/zrange
Withscores - zrangebyscore key 开始score 结束score
withscores
( 不包含
Limit 作用是返回限制
limit 开始下标步 多少步 - zrem key 某score下对应的value值,作用是删除元素
- zcard/zcount key score区间/zrank key values值,作用是获得下标值/zscore key 对应值,获得分数
- zrevrank key values值,作用是逆序获得下标值
- zrevrange
- zrevrangebyscore key 结束score 开始score
示例
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0演示示例
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0(2) 按条件操作数据命令
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0演示示例
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0(3) 交并操作
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0(3) 获取排名(索引)
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 0
演示案例
127.0.0.1:6379> hmset user name lisi age 20 <!--新增 user name属性value为 lisi,age 为 20-->
OK
127.0.0.1:6379> hmget user name age <!--获取 user name和age属性的value-->
1) "lisi"
2) "20"
127.0.0.1:6379> hlen user <!--获取user的字段数量-->
(integer) 2
127.0.0.1:6379> hexists user name <!--判断user中是否存在name字段-->
(integer) 1
127.0.0.1:6379> hexists user sex <!--判断user中是否存在sex字段-->
(integer) 017.配置文件介绍
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf(Windows 名为 redis.windows.conf)。
你可以通过 CONFIG 命令查看或设置配置项。
语法
Redis CONFIG 命令格式如下:
redis 127.0.0.1:6379> CONFIG GET CONFIG_SETTING_NAME
实例
redis 127.0.0.1:6379> CONFIG GET loglevel1) "loglevel"
2) "notice"参数说明
配置命令可以参考官网或参考这个地址参考配置
redis.conf 配置项说明如下:
注意,下面配置项说明并不全,了解更多请检阅redis.conf。
1 daemonize no Redis 默认不是以守护进程的方式运行,可以通过该配置项修改,使用 yes 启用守护进程(Windows 不支持守护线程的配置为 no )
2 pidfile /var/run/redis.pid 当 Redis 以守护进程方式运行时,Redis 默认会把 pid 写入 /var/run/redis.pid 文件,可以通过 pidfile 指定
3 port 6379 指定 Redis 监听端口,默认端口为 6379,作者在自己的一篇博文中解释了为什么选用 6379 作为默认端口,因为 6379 在手机按键上 MERZ 对应的号码,而 MERZ 取自意大利歌女 Alessia Merz 的名字
4 bind 127.0.0.1 绑定的主机地址
5 timeout 300 当客户端闲置多长秒后关闭连接,如果指定为 0 ,表示关闭该功能
6 loglevel notice 指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 notice
7 logfile stdout 日志记录方式,默认为标准输出,如果配置 Redis 为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给 /dev/null
8 databases 16 设置数据库的数量,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id
9 save
Redis 默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示 900 秒(15 分钟)内有 1 个更改,300 秒(5 分钟)内有 10 个更改以及 60 秒内有 10000 个更改。
指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
10 rdbcompression yes 指定存储至本地数据库时是否压缩数据,默认为 yes,Redis 采用 LZF 压缩,如果为了节省 CPU 时间,可以关闭该选项,但会导致数据库文件变的巨大
11 dbfilename dump.rdb 指定本地数据库文件名,默认值为 dump.rdb
12 dir ./ 指定本地数据库存放目录
13 slaveof 设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动从 master 进行数据同步
14 masterauth 当 master 服务设置了密码保护时,slav 服务连接 master 的密码
15 requirepass foobared 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH 命令提供密码,默认关闭
16 maxclients 128 设置同一时间最大客户端连接数,默认无限制,Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients reached 错误信息
17 maxmemory 指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区
18 appendonly no 指定是否在每次更新操作后进行日志记录,Redis 在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis 本身同步数据文件是按上面 save 条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为 no
19 appendfilename appendonly.aof 指定更新日志文件名,默认为 appendonly.aof
20 appendfsync everysec 指定更新日志条件,共有 3 个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用 fsync() 将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折中,默认值)
21 vm-enabled no 指定是否启用虚拟内存机制,默认值为 no,简单的介绍一下,VM 机制将数据分页存放,由 Redis 将访问量较少的页即冷数据 swap 到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析 Redis 的 VM 机制)
**22 vm-swap-file /tmp/redis.swap 虚拟内存文件路径,**默认值为 /tmp/redis.swap,不可多个 Redis 实例共享
**23 vm-max-memory 0 将所有大于 vm-max-memory 的数据存入虚拟内存,**无论 vm-max-memory 设置多小,所有索引数据都是内存存储的(Redis 的索引数据 就是 keys),也就是说,当 vm-max-memory 设置为 0 的时候,其实是所有 value 都存在于磁盘。默认值为 0
24 vm-page-size 32 Redis swap 文件分成了很多的 page,一个对象可以保存在多个 page 上面,但一个 page 上不能被多个对象共享,vm-page-size 是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page 大小最好设置为 32 或者 64bytes;如果存储很大大对象,则可以使用更大的 page,如果不确定,就使用默认值
25 vm-pages 134217728 设置 swap 文件中的 page 数量,由于页表(一种表示页面空闲或使用的 bitmap)是在放在内存中的,,在磁盘上每 8 个 pages 将消耗 1byte 的内存。
26 vm-max-threads 4 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
27 glueoutputbuf yes 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
28 hash-max-zipmap-entries 64
hash-max-zipmap-value 512 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
29 activerehashing yes 指定是否激活重置哈希,默认为开启(后面在介绍 Redis 的哈希算法时具体介绍)
30 include /path/to/local.conf 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
18.持久化之RDB
RDB(Redis DataBase)
是什么
- 在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
- Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
- rdb 保存的是dump.rdb文件
- 相关配置在配置文件的位置 - 在redis.conf搜寻### SNAPSHOTTING ###
如何触发RDB快照
- 配置文件中默认的快照配置dbfilename dump.rdb
- 冷拷贝后重新使用
- 可以cp dump.rdb dump_new.rdb
- 冷拷贝后重新使用
命令save或者是bgsave
Save:save时只管保存,其它不管,全部阻塞
BGSAVE:Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。可以通过lastsave 命令获取最后一次成功执行快照的时间
执行flushall命令,也会产生dump.rdb文件,但里面是空的,无意义
如何恢复
- 将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
- CONFIG GET dir获取目录
优势与劣势
- 优势
适合大规模的数据恢复
对数据完整性和一致性要求不高 - 劣势
在一定间隔时间做一次备份,所以如果redis意外down掉的话,就 会丢失最后一次快照后的所有修改
Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
如何停止
动态所有停止RDB保存规则的方法:redis-cli config set save ""
小结
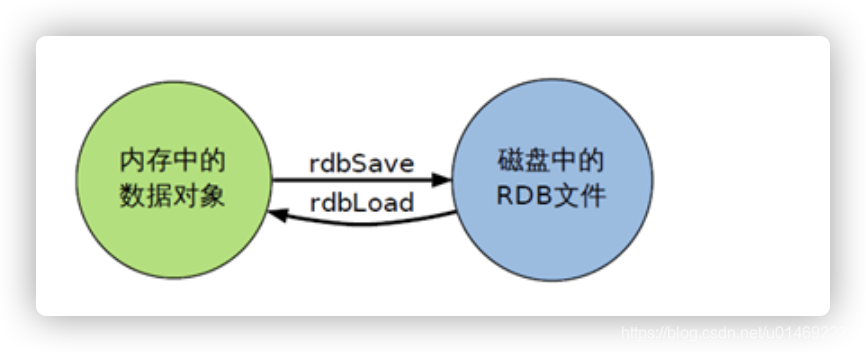
- RDB是一个非常紧凑的文件。
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他I0操作,所以RDB持久化方式可以最大化redis的性能。
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一一些。
- 数据丢失风险大。
- RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候fork的过程是非常耗时的吗,可能会导致Redis在一些毫秒级不能回应客户端请求。
19.持久化之AOF
AOF(Append Only File)
是什么
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
AOF配置
相关配置在配置文件的位置 - 在redis.conf搜寻### APPEND ONLY MODE ###
aof保存的是appendonly.aof文件(在配置文件可修改文件名)
AOF启动/修复/恢复
正常恢复
- 启动:设置Yes
- 修改默认的appendonly no,改为yes
- 将有数据的aof文件复制一份保存到对应目录(config get dir)
- 恢复:重启redis然后重新加载
异常恢复
- 启动:设置Yes
- 修改默认的appendonly no,改为yes
- 备份被写坏的AOF文件
修复:
- Redis-check-aof --fix进行修复
- 恢复:重启redis然后重新加载
rewrite
是什么:
- AOF采用文件追加方式,文件会越来越大。为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, **只保留可以恢复数据的最小指令集。**可以使用命令bgrewriteaof
重写原理
- AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename), 遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件, 而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
触发机制
- Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。AOF采用文件追加方式,文件会越来越大。为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集。可以使用命令bgrewriteaof
重写原理
- AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename), 遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件, 而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
触发机制
- Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
优势与劣势
优势
每修改同步:appendfsync always 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
每秒同步:appendfsync everysec 异步操作,每秒记录 如果一秒内宕机,有数据丢失
不同步:appendfsync no 从不同步
劣势
相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
Aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
小结
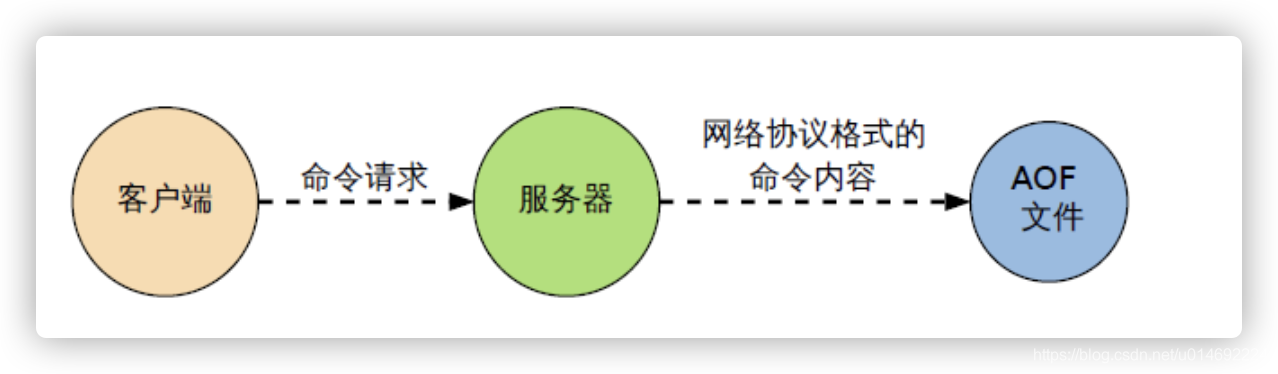
- AOF文件时一个只进行追加的日志文件
- Redis可以在AOF文件体积变得过大时,自动地在后台对AOF进行重写
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此AOF文件的内容非常容易被人读懂,对文件进行分析也很轻松
- 对于相同的数据集来说,AOF文件的体积通常要大于RDB文件的体积
- 根据所使用的fsync 策略,AOF的速度可能会慢于RDB
20.事务
是什么
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。
能干嘛
一个队列中,一次性、顺序性、排他性的执行一系列命令。
使用
常用命令

Case
正常执行
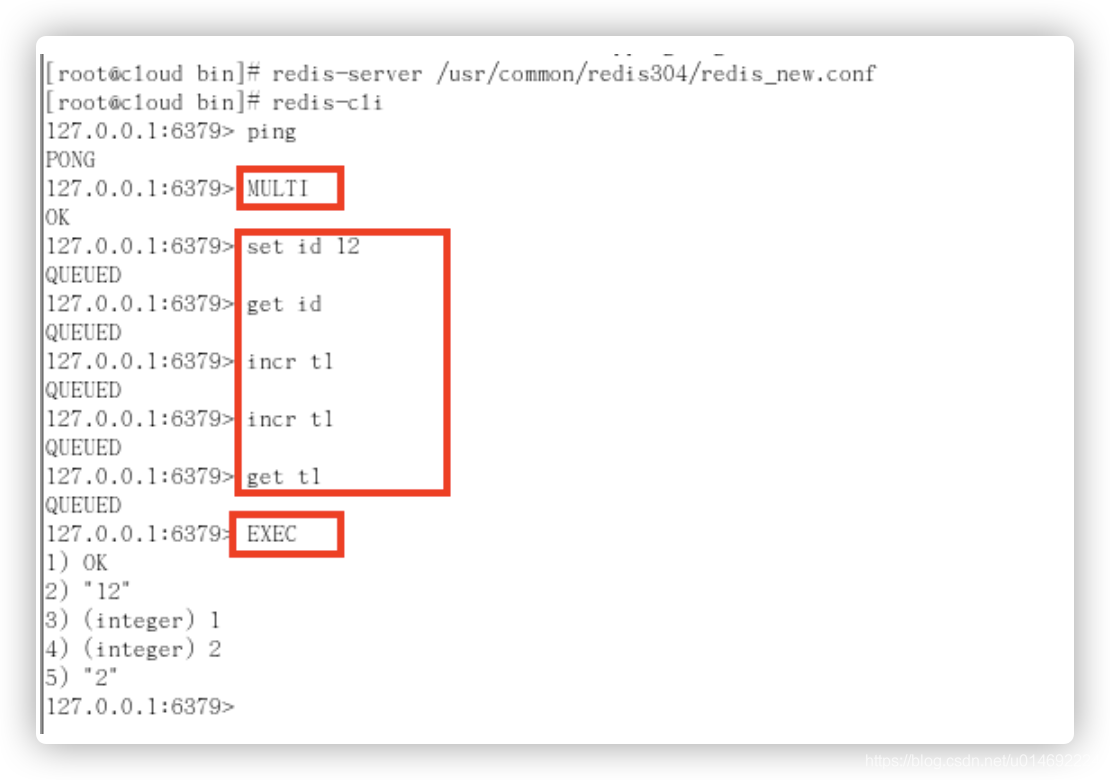
放弃事务

全体连坐

类似Java编译异常
冤头债主
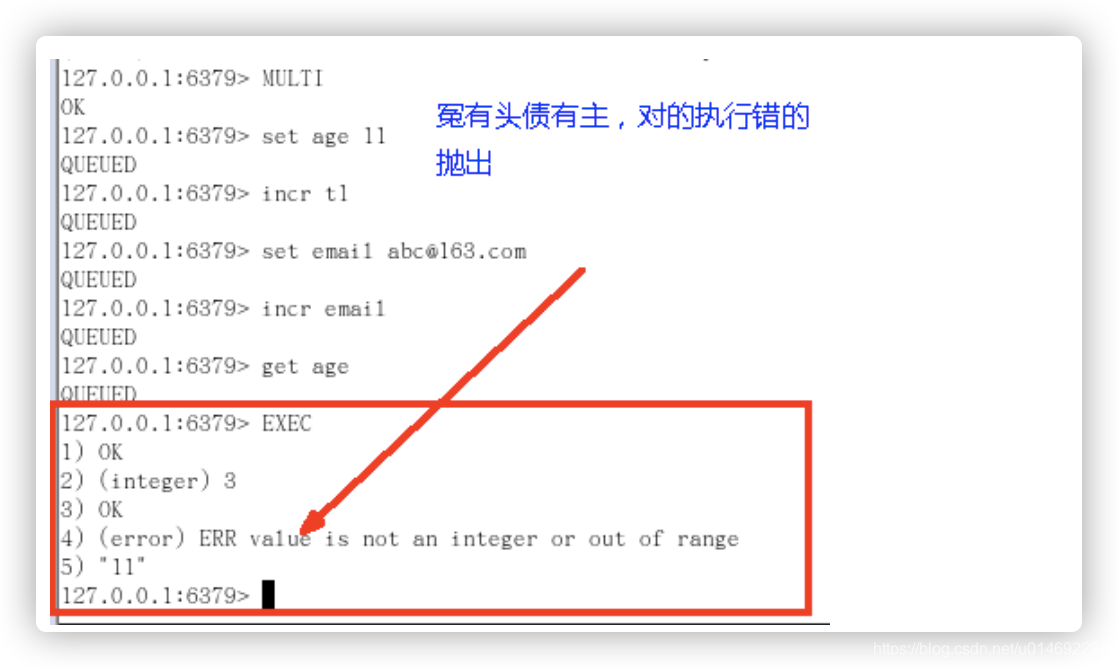
类似Java运行异常
watch监控
悲观锁/乐观锁/CAS(Check And Set)
悲观锁
- 悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁
- 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。
乐观锁策略:提交版本必须大于记录当前版本才能执行更新
- CAS
信用卡可用余额和欠额
- 初始化信用卡可用余额和欠额
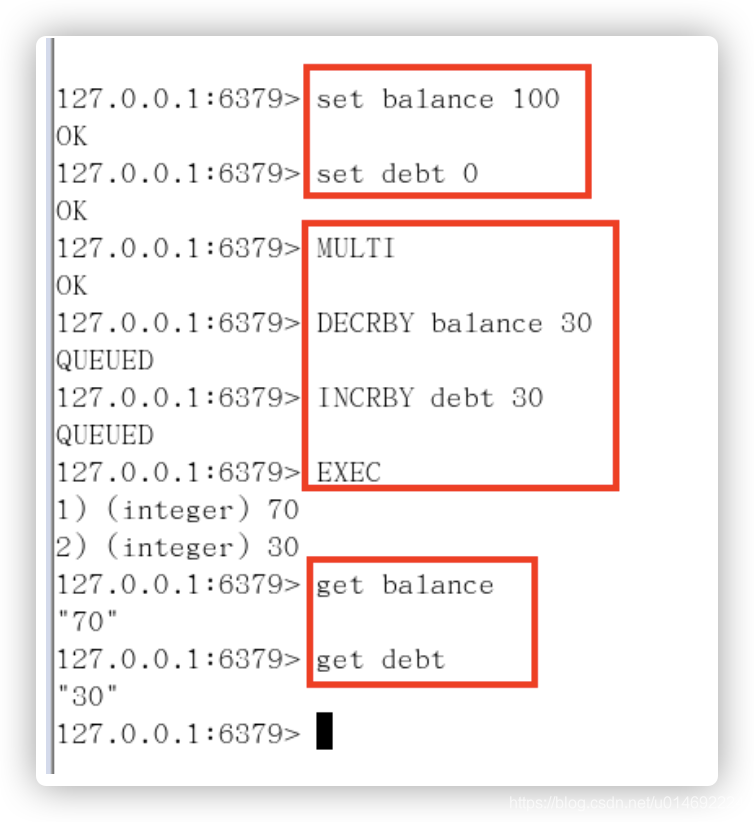
无加塞篡改,先监控再开启multi, 保证两笔金额变动在同一个事务内

- 有加塞篡改
- 监控了key,如果key被修改了,后面一个事务的执行失效
-
- 监控了key,如果key被修改了,后面一个事务的执行失效
- unwatch
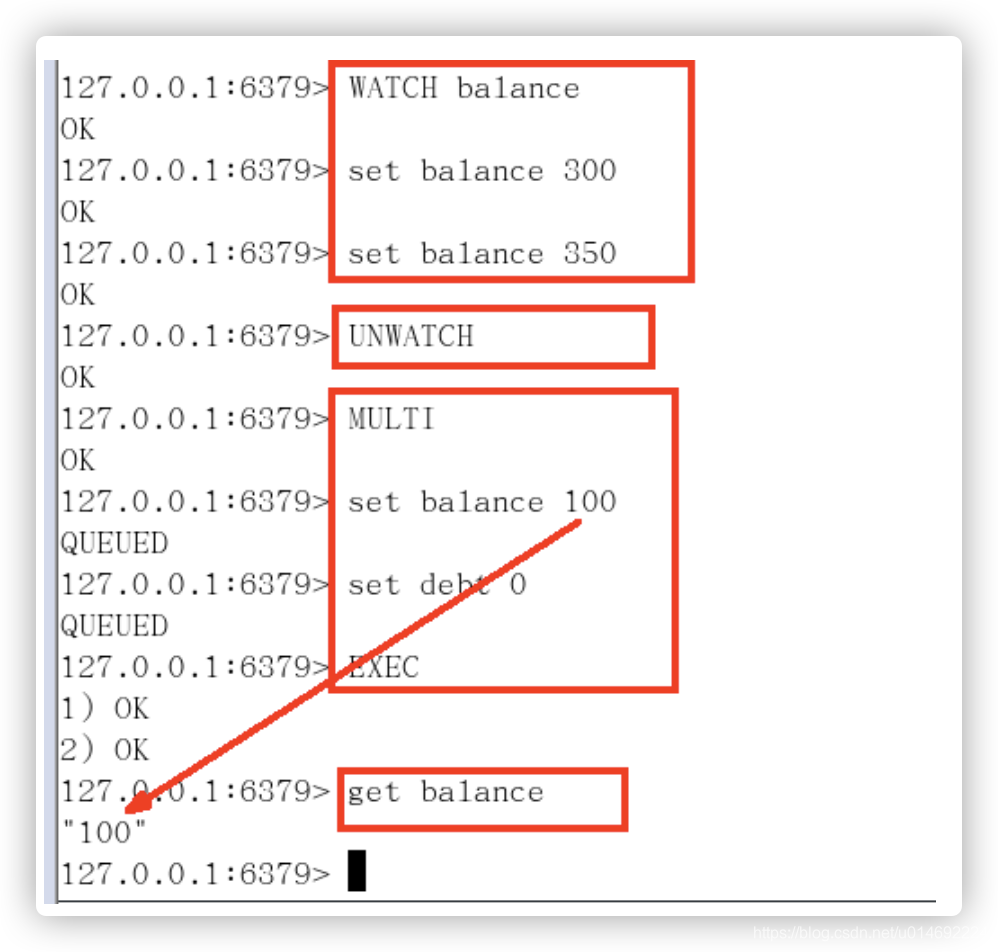
一旦执行了exec之前加的监控锁都会被取消掉了(一次性)
小结
- Watch指令,类似乐观锁,事务提交时,如果Key的值已被别的客户端改变, 比如某个list已被别的客户端push/pop过了,整个事务队列都不会被执行
- 通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化, EXEC命令执行的事务都将被放弃,同时返回Nullmulti-bulk应答以通知调用者事务执行失败
3阶段
开启:以MULTI开始一个事务
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
执行:由EXEC命令触发事务
3特性
**单独的隔离操作:**事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行, 也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
不保证原子性::redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
不遵循传统的ACID中的AI
21.消息订阅发布简介
用观察者模式理解学习
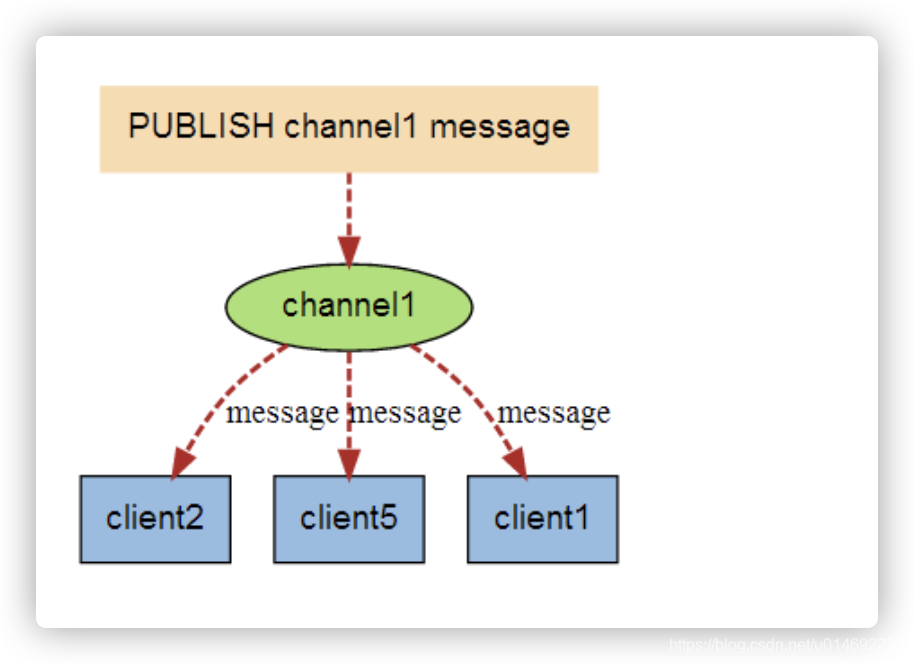
进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
常用命令

实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
redis 127.0.0.1:6379> SUBSCRIBE redisChatReading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
redis 127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"(integer) 1redis 127.0.0.1:6379> PUBLISH redisChat "Learn redis by runoob.com"(integer) 1# 订阅者的客户端会显示如下消息
1) "message"
2) "redisChat"
3) "Redis is a great caching technique"
1) "message"
2) "redisChat"
3) "Learn redis by runoob.com"订阅多个通配符 *
PSUBSCRIBE new*收取消息,
PUBLISH new1 redis2015
22&23.主从复制
是什么
行话:也就是我们所说的主从复制,主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
能干嘛
- 读写分离
- 容灾恢复
怎么玩
准备工作
- 配从(库)不配主(库)
- 从库配置命令:slaveof 主库IP 主库端口
- 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件(具体位置:redis.conf搜寻#### REPLICATION ####)
- info replication
- 修改配置文件细节操作
- 拷贝多个redis.conf文件,按’redis[port].conf’重命名
- 开启daemonize yes
- pid文件名字
- 指定端口
- log文件名字
- dump.rdb名字
常用3招
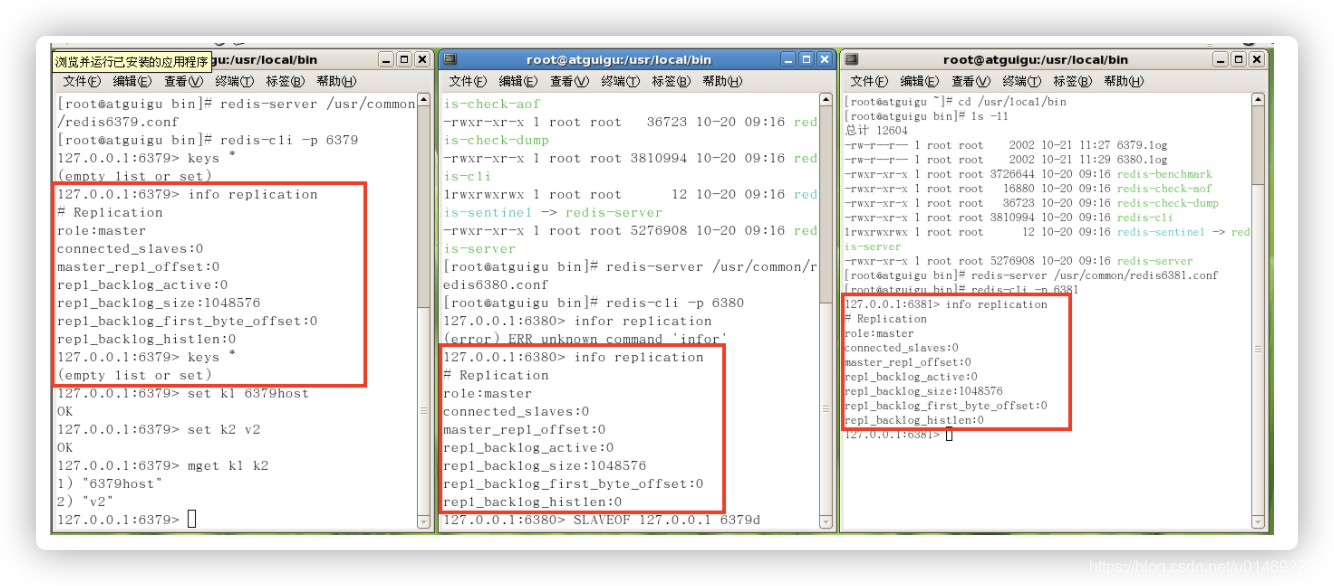
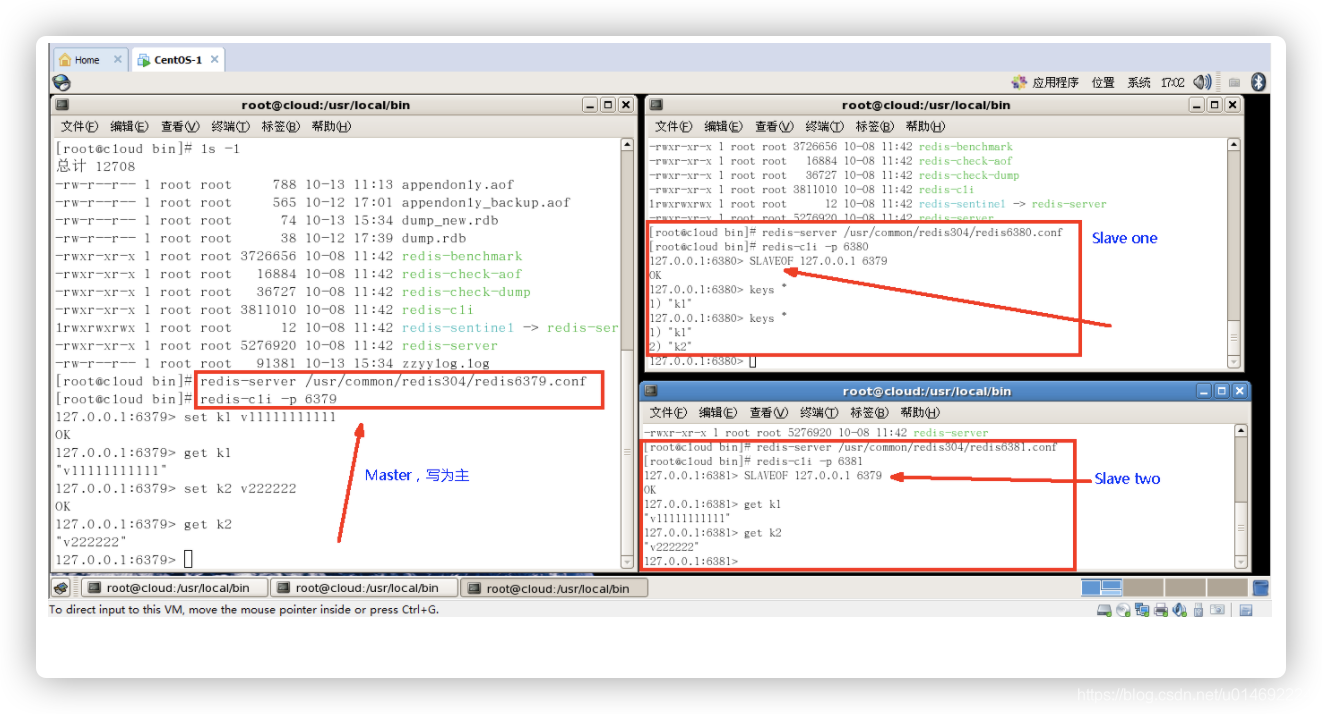
一主二仆
- init
- 一个Master两个Slave
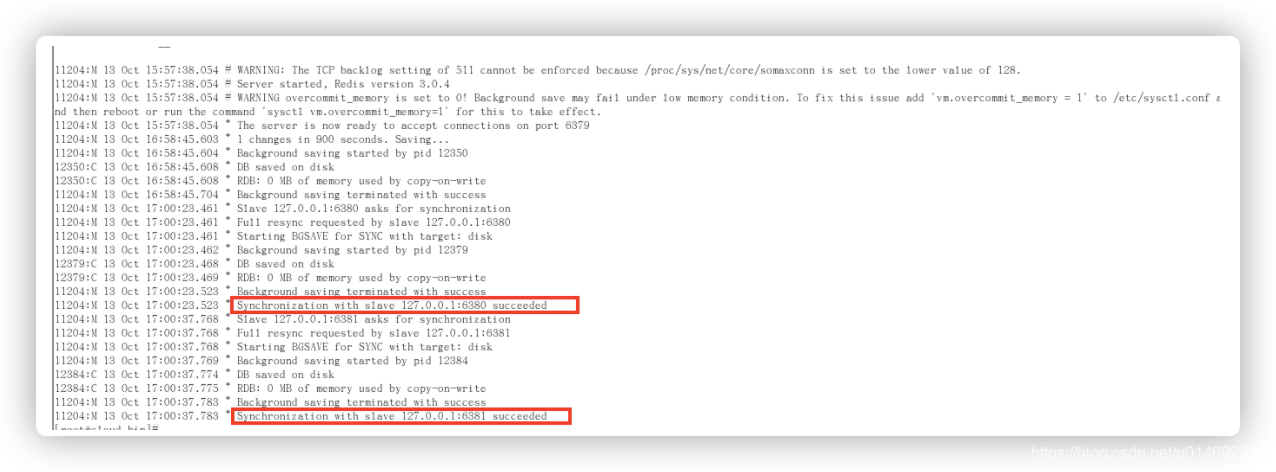
日志查看
主机日志
- 备机日志
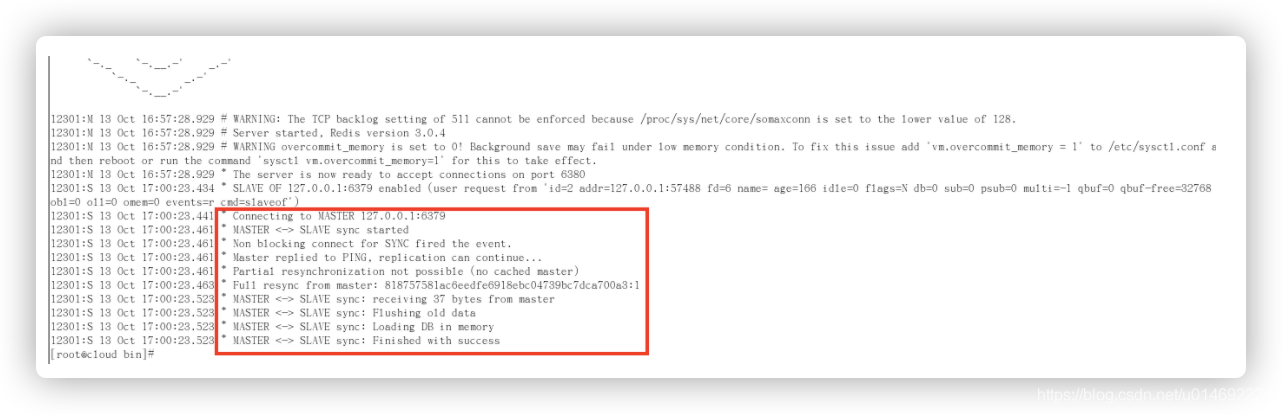
info replication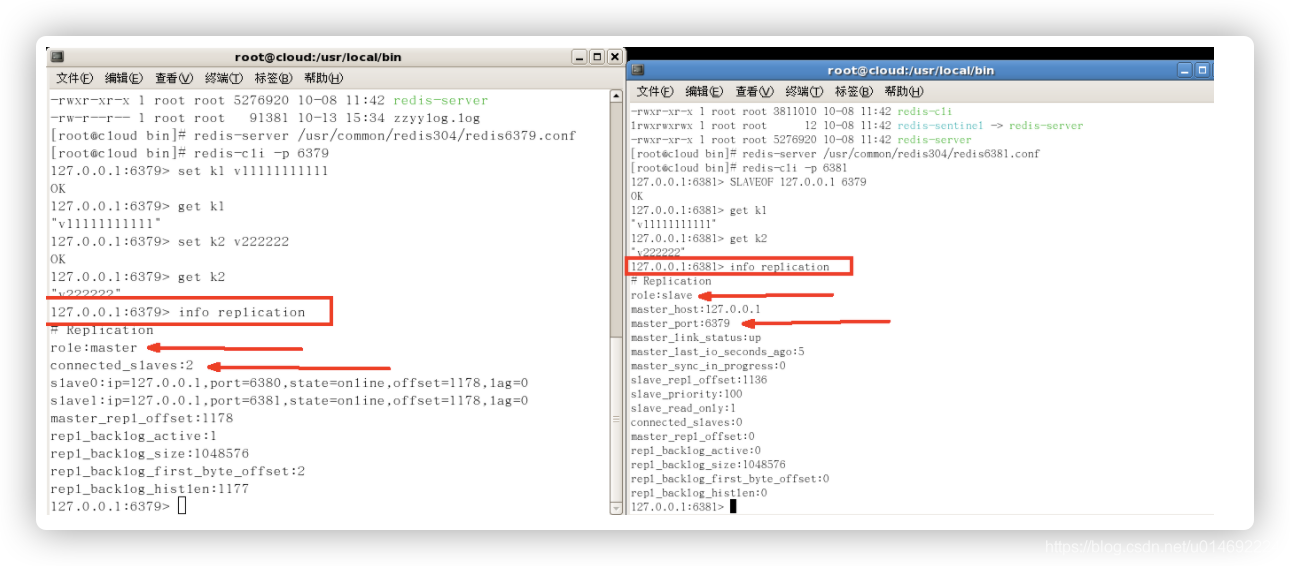
- 主从问题演示
- 切入点问题?slave1、slave2是从头开始复制还是从切入点开始复制?比如从k4进来,那之前的123是否也可以复制?
- 答:从头开始复制;123也可以复制
-
从机是否可以写?set可否?
答:从机不可写,不可set,主机可写 -
主机shutdown后情况如何?从机是上位还是原地待命
答:从机还是原地待命(咸鱼翻身,还是咸鱼) -
主机又回来了后,主机新增记录,从机还能否顺利复制?
答:能 -
其中一台从机down后情况如何?依照原有它能跟上大部队吗?
答:不能跟上,每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件(具体位置:redis.conf搜寻#### REPLICATION ####)
薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力(奴隶的奴隶还是奴隶)
中途变更转向:会清除之前的数据,重新建立拷贝最新的
slaveof 新主库IP 新主库端口
反客为主
SLAVEOF no one
使当前数据库停止与其他数据库的同步,转成主数据库
复制原理
- slave启动成功连接到master后会发送一个sync命令
- master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
哨兵模式(sentinel)
一组sentinel能同时监控多个master
是什么
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
怎么玩(使用步骤)
-
调整结构,6379带着6380、6381
-
新建sentinel.conf文件,名字绝不能错
-
配置哨兵,填写内容
- sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
- 上面最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机(PS. 跟官网的描述有出入,下面有官方文档说明)
-
启动哨兵
- redis-sentinel /sentinel.conf(上述目录依照各自的实际情况配置,可能目录不同)
-
正常主从演示
-
原有的master挂了
-
投票新选
-
重新主从继续开工,info replication查查看
问题:如果之前挂了的master重启回来,会不会双master冲突?
答: 不会,原master,变成slave
sentinel monitor
For the sake of clarity, let’s check line by line what the configuration options mean:
The first line is used to tell Redis to monitor a master called mymaster, that is at address 127.0.0.1 and port 6379, with a quorum of 2. Everything is pretty obvious but the quorum argument:
The quorum is the number of Sentinels that need to agree about the fact the master is not reachable, in order to really mark the master as failing, and eventually start a failover procedure if possible.
However the quorum is only used to detect the failure. In order to actually perform a failover, one of the Sentinels need to be elected leader for the failover and be authorized to proceed. This only happens with the vote of the majority of the Sentinel processes.
So for example if you have 5 Sentinel processes, and the quorum for a given master set to the value of 2, this is what happens:
If two Sentinels agree at the same time about the master being unreachable, one of the two will try to start a failover.
If there are at least a total of three Sentinels reachable, the failover will be authorized and will actually start.
In practical terms this means during failures Sentinel never starts a failover if the majority of Sentinel processes are unable to talk (aka no failover in the minority partition).
Source
复制的缺点
复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
24.Jedis_测试联通
- 在Eclipse创建普通Maven工程
- pom.xml引入下面关键依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.1.0</version>
</dependency>
- 创建新类,测试连通,源码如下:
TestPing.java
package com.lun.shang;import redis.clients.jedis.Jedis;public class TestPing {public static void main(String[] args) {Jedis jedis = new Jedis("127.0.0.1",6379);//输出PONG,redis连通成功System.out.println(jedis.ping());}
}
25.Jedis_常用API
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;import redis.clients.jedis.Jedis;public class TestAPI {public static void main(String[] args) {Jedis jedis = new Jedis("127.0.0.1", 6379);// keySet<String> keys = jedis.keys("*");for (Iterator iterator = keys.iterator(); iterator.hasNext();) {String key = (String) iterator.next();System.out.println(key);}System.out.println("jedis.exists====>" + jedis.exists("k2"));System.out.println(jedis.ttl("k1"));// String// jedis.append("k1","myreids");System.out.println(jedis.get("k1"));jedis.set("k4", "k4_redis");System.out.println("----------------------------------------");jedis.mset("str1", "v1", "str2", "v2", "str3", "v3");System.out.println(jedis.mget("str1", "str2", "str3"));// listSystem.out.println("----------------------------------------");// jedis.lpush("mylist","v1","v2","v3","v4","v5");List<String> list = jedis.lrange("mylist", 0, -1);for (String element : list) {System.out.println(element);}// setjedis.sadd("orders", "jd001");jedis.sadd("orders", "jd002");jedis.sadd("orders", "jd003");Set<String> set1 = jedis.smembers("orders");for (Iterator iterator = set1.iterator(); iterator.hasNext();) {String string = (String) iterator.next();System.out.println(string);}jedis.srem("orders", "jd002");System.out.println(jedis.smembers("orders").size());// hashjedis.hset("hash1", "userName", "lisi");System.out.println(jedis.hget("hash1", "userName"));Map<String, String> map = new HashMap<String, String>();map.put("telphone", "13811814763");map.put("address", "atguigu");map.put("email", "abc@163.com");jedis.hmset("hash2", map);List<String> result = jedis.hmget("hash2", "telphone", "email");for (String element : result) {System.out.println(element);}// zsetjedis.zadd("zset01", 60d, "v1");jedis.zadd("zset01", 70d, "v2");jedis.zadd("zset01", 80d, "v3");jedis.zadd("zset01", 90d, "v4");Set<String> s1 = jedis.zrange("zset01", 0, -1);for (Iterator iterator = s1.iterator(); iterator.hasNext();) {String string = (String) iterator.next();System.out.println(string);}}
}26.Jedis_事务
日常
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Response;
import redis.clients.jedis.Transaction;public class Test03 {public static void main(String[] args) {Jedis jedis = new Jedis("127.0.0.1", 6379);// 监控key,如果该动了事务就被放弃/** 3 jedis.watch("serialNum"); jedis.set("serialNum","s#####################");* jedis.unwatch();*/Transaction transaction = jedis.multi();// 被当作一个命令进行执行Response<String> response = transaction.get("serialNum");transaction.set("serialNum", "s002");response = transaction.get("serialNum");transaction.lpush("list3", "a");transaction.lpush("list3", "b");transaction.lpush("list3", "c");transaction.exec();// 2 transaction.discard();System.out.println("serialNum***********" + response.get());}
}加锁
TestTX.java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;public class TestTX {public boolean transMethod() throws InterruptedException {Jedis jedis = new Jedis("127.0.0.1", 6379);int balance;// 可用余额int debt;// 欠额int amtToSubtract = 10;// 实刷额度jedis.watch("balance");// jedis.set("balance","5");//此句不该出现,讲课方便。模拟其他程序已经修改了该条目Thread.sleep(7000);balance = Integer.parseInt(jedis.get("balance"));if (balance < amtToSubtract) {jedis.unwatch();System.out.println("modify");return false;} else {System.out.println("***********transaction");Transaction transaction = jedis.multi();transaction.decrBy("balance", amtToSubtract);transaction.incrBy("debt", amtToSubtract);transaction.exec();balance = Integer.parseInt(jedis.get("balance"));debt = Integer.parseInt(jedis.get("debt"));System.out.println("*******" + balance);System.out.println("*******" + debt);return true;}}/*** 通俗点讲,watch命令就是标记一个键,如果标记了一个键, 在提交事务前如果该键被别人修改过,那事务就会失败,这种情况通常可以在程序中 重新再尝试一次。* 首先标记了键balance,然后检查余额是否足够,不足就取消标记,并不做扣减; 足够的话,就启动事务进行更新操作,* 如果在此期间键balance被其它人修改, 那在提交事务(执行exec)时就会报错, 程序中通常可以捕获这类错误再重新执行一次,直到成功。* * @throws InterruptedException*/public static void main(String[] args) throws InterruptedException {TestTX test = new TestTX();boolean retValue = test.transMethod();System.out.println("main retValue-------: " + retValue);}
}27.Jedis_主从复制
6379,6380启动,先各自先独立
主写,从读
TestMS.java
import redis.clients.jedis.Jedis;public class TestMS {public static void main(String[] args) {Jedis jedis_M = new Jedis("127.0.0.1", 6379);Jedis jedis_S = new Jedis("127.0.0.1", 6380);jedis_S.slaveof("127.0.0.1", 6379);jedis_M.set("class", "1122V2");String result = jedis_S.get("class");//可能有延迟,需再次启动才能使用System.out.println(result);}
}28.Jedis_JedisPool
JedisPoolUtil
获取Jedis实例需要从JedisPool中获取
用完Jedis实例需要返还给JedisPool
如果Jedis在使用过程中出错,则也需要还给JedisPool
JedisPoolUtil.java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class JedisPoolUtil {private static volatile JedisPool jedisPool = null;private JedisPoolUtil() {}public static JedisPool getJedisPoolInstance() {if (null == jedisPool) {synchronized (JedisPoolUtil.class) {if (null == jedisPool) {JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxActive(1000);poolConfig.setMaxIdle(32);poolConfig.setMaxWait(100 * 1000);poolConfig.setTestOnBorrow(true);jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);}}}return jedisPool;}public static void release(JedisPool jedisPool, Jedis jedis) {if (null != jedis) {jedisPool.returnResourceObject(jedis);}}}运行测试
TestPool.java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;public class TestPool {public static void main(String[] args) {JedisPool jedisPool = JedisPoolUtil.getJedisPoolInstance();JedisPool jedisPool2 = JedisPoolUtil.getJedisPoolInstance();System.out.println(jedisPool == jedisPool2);Jedis jedis = null;try {jedis = jedisPool.getResource();jedis.set("aa", "bb");} catch (Exception e) {e.printStackTrace();} finally {JedisPoolUtil.release(jedisPool, jedis);}}
}
配置总结
JedisPool的配置参数大部分是由JedisPoolConfig的对应项来赋值的。
maxActive:控制一个pool可分配多少个jedis实例,通过pool.getResource()来获取;如果赋值为-1,则表示不限制;如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted。
maxIdle:控制一个pool最多有多少个状态为idle(空闲)的jedis实例;
whenExhaustedAction:表示当pool中的jedis实例都被allocated完时,pool要采取的操作;默认有三种。
WHEN_EXHAUSTED_FAIL --> 表示无jedis实例时,直接抛出NoSuchElementException;
WHEN_EXHAUSTED_BLOCK --> 则表示阻塞住,或者达到maxWait时抛出JedisConnectionException;
WHEN_EXHAUSTED_GROW --> 则表示新建一个jedis实例,也就说设置的maxActive无用;
maxWait:表示当borrow一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛JedisConnectionException;
testOnBorrow:获得一个jedis实例的时候是否检查连接可用性(ping());如果为true,则得到的jedis实例均是可用的;
testOnReturn:return 一个jedis实例给pool时,是否检查连接可用性(ping());
testWhileIdle:如果为true,表示有一个idle object evitor线程对idle object进行扫描,如果validate失败,此object会被从pool中drop掉;这一项只有在timeBetweenEvictionRunsMillis大于0时才有意义;
timeBetweenEvictionRunsMillis:表示idle object evitor两次扫描之间要sleep的毫秒数;
numTestsPerEvictionRun:表示idle object evitor每次扫描的最多的对象数;minEvictableIdleTimeMillis
minEvictableIdleTimeMillis:表示一个对象至少停留在idle状态的最短时间,然后才能被idle object evitor扫描并驱逐;这一项只有在timeBetweenEvictionRunsMillis大于0时才有意义;
softMinEvictableIdleTimeMillis:在minEvictableIdleTimeMillis基础上,加入了至少minIdle个对象已经在pool里面了。如果为-1,evicted不会根据idle time驱逐任何对象。如果minEvictableIdleTimeMillis>0,则此项设置无意义,且只有在timeBetweenEvictionRunsMillis大于0时才有意义;
lifo:borrowObject返回对象时,是采用DEFAULT_LIFO(last in first out,即类似cache的最频繁使用队列),如果为False,则表示FIFO队列;
其中JedisPoolConfig对一些参数的默认设置如下:
testWhileIdle=true
minEvictableIdleTimeMills=60000
timeBetweenEvictionRunsMillis=30000
numTestsPerEvictionRun=-1
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 使用Vue-draggable组件实现表格拖拽效果
1.安装组件 npm install vuedraggable -S 2.引入组件 完整代码:helloWorld.vue <template><div class"hello"><el-button click"getData()">加载数据</el-button><table class"dataTabble" v-for"…...
2024/4/25 2:42:51 - 最硬核的方式找女朋友:用 VS Code 找对象?还是不看脸的那种?!
转自:量子位(ID:QbitAI) VS Code现在居然可以用来谈恋爱了。 为了用最硬核的方式找到男(女)朋友,23岁的程序员Ben Awad在VS Code里打造一个约会软件VSinder。 顾名思义,VSinder VS…...
2024/4/28 2:41:33 - JVM学习纪要(一)
JVM学习纪要一、内存区域的划分程序计数器虚拟机栈局部变量表本地方法栈Java堆方法区二、对象创建过程内存布局对象头实例数据对齐填充对象访问三、垃圾与垃圾回收引用对象的死亡判定引用计数引用可达死亡与清理方法区的回收类的回收垃圾收集器理论与实现理论三种实现思路实现根…...
2024/3/28 22:19:08 - 搭建PXE服务及实现安装银河麒麟桌面操作系统
搭建PXE服务及实现安装银河麒麟桌面操作系统 一、安装PXE服务器前的准备 服务器操作系统:银河麒麟高级服务器操作系统V10 SP1 服务器IP地址:em1 172.17.31.163 用于连接外网,可以进行yum安装相关服务 em2 192.168.1.1 用于DHCP服务网段的配…...
2024/4/28 12:48:45 - 阿里2021年版十亿级并发系统设计+java性能优化实战文档
前言 快过年了,不知道大家回家了吗? 说也奇怪,快过年了疫情竟然严重了,又到了全民戴口罩做防护的时候。 好多人都是在隔离, 在待业,在家里面已经开始思索,为2021年的发展做计划,怎样才能让自…...
2024/4/28 1:59:18 - 【小白必备】IP编址的干货,你值得拥有!
【温馨提示】需要资料或者需要进群交流划到最底部 点分十进制 在学习编址之前,我们首先来了解一下IP地址。现在所使用的IP地址为版本4,一共32bit,二进制组成。 如果用二进制直接去表示IP地址,那么32个0和1对于人类来说识别起来过…...
2024/3/7 1:14:37 - 七大步骤、备战60天,4面拿下字节跳动offer:时间规划+知识点+画脑图+做笔记+看书+看视频+刷题刷题
前言 5年前,BAT冲到了风口浪尖,美国上市的阿里成为中国体量最大的互联网公司,腾讯借助微信成为移动互联网的霸主,外企开始撤离中国,国企的光环也慢慢褪去。 到了近年,应届毕业生心中最炙手可热的公司换成…...
2024/3/30 0:30:31 - 盘点一款好用的App免邀请码的渠道统计工具
1、Xinstall功能介绍 Xinstall是一款集智能传参、快速安装、一键拉起、多维数据统计等功能,帮住企业提高APP拉新转化率、安装率和多元化精确统计渠道效果的产品,同时免费提供Universal Link配置功能,提升应用转化效果。 传递智能参数&#…...
2024/4/28 6:04:38 - springcloud 学习记录-2020
参考文章: https://www.coder4.com/homs_online/ 从0到1实战微服务架构 https://www.iteye.com/blog/youyu4-2405976 分布式应用雪崩效应 springcloud 概念 微服务架构 优点:微服务低耦合、易维护、适合团队协作、测试起来成本更低,也更易于…...
2024/3/7 1:14:35 - 为什么黑客用“脚”都能黑进去的小网站,也开始用SSL证书了?
为什么黑客用“脚”都能黑进去的小网站,也开始用SSL证书了? 像蔚可云这样专业的云产品和服务提供平台,对数据安全有刻骨铭心的了解,因此在建站之初,就早早地启用了https站点。 但不知道从什么时候开始,一…...
2024/3/7 1:14:33 - Dependency ‘ commons-io: commons-io:2.6‘ not found
问题如下,使用idea2019配置maven3.6.0,第一次创建,使用maven导入jar提示如下 对比maven的setting.xml文件后,发现是jak配置写错了一个单词,这是修改后的,我在上传一份正常配置完的setting.xml文件 <?xm…...
2024/3/7 1:14:32 - 长虹电视安装第三方软件2021最新方法!
长虹电视安装第三方软件2021最新方法! 听说长虹电视装不了软件?教你隐藏小技巧,破解长虹电视不能安装u盘app...
2024/3/14 12:47:28 - vivo X60 Pro+观察:影像性能正成为vivo手机的核心竞争力
1月21日,X60系列中的超大杯X60 Pro正式亮相。作为同样注重成像素质的影像旗舰产品,vivo X60 Pro较X60、X60 Pro有全方位的提升。 X60 Pro在影像上都有怎样的提升?我们一起来看看。 01 从vivo X60系列强悍的影像性能说起 2020年12月29日&a…...
2024/3/6 17:53:14 - python爬虫原理和运营商SDK数据建模抓取的区别
当今是个不折不扣的大数据时代,大数据贯穿了我们的衣食住行,可以这么说,大数据是目前最宝贵的数据宝藏! 什么是Python爬虫? Python爬虫又叫网络爬虫 关于Python爬虫,我们需要知道的有: Python基…...
2024/3/6 17:53:11 - 半导体功率器件的发展及测试
近年来,全球半导体功率器件的制造环节以较快速度向我国转移。目前,我国已经成为全球最重要的半导体功率器件封测基地。如IDM类(吉林华微电子、华润微电子、杭州士兰微电子、比亚迪股份、株洲中车时代半导体、扬州杨杰等);模块类&a…...
2024/3/6 17:53:10 - Android程序员如何平稳度过35岁的坎?
一、你以为的人生 刚入行时,拿着傲人的工资,想着好好干,以为我们的人生是这样的: 等真到了那一天,你会发现,你的人生很可能是这样的: 二、一次又一次的伤害 某为很早就爆出来要裁员34岁以上员…...
2024/4/23 8:57:07 - 2021-01-25 vue中的scoped及穿透方法
scoped的由来 css一直有个令人困扰的作用域的问题:即使是模块化编程下,在对应的模块的js中import css进来,这个css仍然是全局的。为了避免css样式之间的污染,vue中引入了scoped这个概念。 在vue文件中的style标签上,有…...
2024/4/20 9:45:09 - IPFS矿机Filecoin挖矿火热进行中,Filecoin市场供需与流动性趋势分析!
自10月主网上线以来,Filecoin已经成为市场上最大的去中心化存储项目之一。Filecoin上线后,FIL代币解锁/释放主要来自投资者、官方、矿工。解锁/释放的FIL,可以但并不一定会立即进入2级市场流通,可能被长期持有、用于抵押挖矿&…...
2024/3/25 20:54:59 - DCDC电源PCB布局
DCDC电源PCB布局 虽然开关电源有高效率、宽动态范围等诸多优点,但同时带来了较为严重的开关干扰。这些干扰如果不采取一定的措施进行抑制、消除和屏蔽,就会严重地影响整机的正常工作。 像Maxim等一线厂商都提供了设计工具来帮助客户加快设计进程&#x…...
2024/4/9 6:44:18 - vue项目中使用sortablejs实现拖拽表格
1.首先install一下sortablejs npm install sortablejs --save 2.引入 import Sortable from "sortablejs"; 完整代码如下: HelloWorld.vue <template><div class"hello"><el-collapse v-model"activeNames">…...
2024/4/27 5:11:51
最新文章
- MMSeg搭建自己的网络
配置结构 首先,我们知道MMSeg矿机的配置文件很多,主要结构如下图所示。 在configs/_base_下是模型配置、数据集配置、以及一些其他的常规配置和运行配置,四类。 configs/all_config目录下存放,即是将四种配置聚合在一起的一个总…...
2024/4/28 13:31:53 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 零基础 HTML 入门(详细)
目录 1.简介 1.1 HTML是什么? 1.2 HTML 版本 1.3 通用声明 2.HTML 编辑器 3.标签的语法 4.HTML属性 5.常用标签 5.1 head 元素 5.1.1 title 标签 5.1.2 base 标签 5.1.3 link 标签 5.1.4 style 标签 5.1.5 meta 标签 5.1.6 script 5.2 HTML 注释 5.3 段落标签…...
2024/4/22 16:14:13 - javaWeb网上零食销售系统
1 绪 论 目前,我国的网民数量已经达到7.31亿人,随着互联网购物和互联网支付的普及,使得人类的经济活动进入了一个崭新的时代。淘宝,京东等网络消费平台功能的日益完善,使得人们足不出户就可以得到自己想要的东西。如今…...
2024/4/27 19:08:10 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/4/28 4:04:40 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/4/28 12:01:04 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/4/27 12:24:35 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/4/27 12:24:46 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/4/28 12:01:03 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/4/28 12:01:03 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/4/28 12:01:03 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/4/27 12:44:49 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/4/27 21:08:20 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/4/28 9:00:42 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/4/27 18:40:35 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/4/28 4:14:21 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/4/27 13:52:15 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/4/27 13:38:13 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/4/28 12:00:58 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/4/28 12:00:58 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/4/27 22:51:49 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/4/28 7:31:46 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/4/28 8:32:05 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/4/27 20:28:35 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57