ML特征工程+优化方法+评估方法(2万+字总结...持续补充中)
文章目录
- 1. 特征工程有哪些?
- 1.1 数据处理
- 异常值处理
- 缺失值处理
- 1.2 特征归一化
- 线性函数归一化(Min-Max Scaling)
- 零均值归一化(Z-Score Normalization)
- 1.3 类别型特征
- 序号编码
- 独热编码(one-hot)
- 二进制编码
- 1.4 高维组合特征的处理
- 1.5 文本表示模型
- 词袋模型和N-gram模型
- 主题模型
- 词嵌入与深度学习模型
- 1.6 数据分桶
- 1.7 特征构造
- 1.8 特征选择
- 过滤式
- 包裹式
- 嵌入式
- PCA降维技术
- 1.9 特征工程脑图
- 2. 机器学习优化方法
- 2.1 常用损失函数
- 平方损失函数
- log损失函数
- Hinge损失函数
- 2.2 什么是凸优化
- 2.3 正则化项
- 2.4 常见的几种最优化方法
- 梯度下降法
- 牛顿法
- 拟牛顿法
- 共轭梯度法
- 2.5 降维方法
- 2.5.1 线性判别分析(LDA)
- 2.5.2 主成分分析(PCA)
- 2.5.3 比较这两种方法
- 3. 机器学习评估方法
- 3.1 准确率(Accuracy)
- 3.2 精确率(Precision)
- 3.3 召回率(Recall)
- 3.4 F1值(H-mean值)
- 3.5 ROC曲线
- 3.6 余弦距离和欧式距离
- 3.7 A/B测试
- 3.8 模型评估方法
- Holdout检验
- 交叉检验
- 自助法
- 3.9 超参数调优
- 3.10 过拟合和欠拟合
- 防止过拟合:
- 防止欠拟合:
- 4. 检验方法
- 4.1 KS检验
- 4.2 T检验
- 4.3 F检验
- 4.4 Grubbs检验
- 4.5 卡方检验
1. 特征工程有哪些?
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数 据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
主要讨论以下两种常用的数据类型:
- 结构化数据:结构化数据类型可以看作关系型数据库的一张表,每列都有清晰的定义,包含了数值型、类别型两种基本类型;每一行数据表示一个样本 的信息。
- 非结构化数据:非结构化数据主要包括文本、图像、音频、视频数据, 其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
1.1 数据处理
异常值处理
- 常用的异常值处理操作包括BOX-COX转换(处理有偏分布),箱线图分析删除异常值, 长尾截断等方式, 当然这些操作一般都是处理数值型的数据。
- box-cox转换,一般是用于连续的变量不满足正态的时候.
缺失值处理
由于我们的特征矩阵由两种类型的数据组成:分类型和连续型,因此我们必须对两种数据采用不同的填补缺失值策略。
传统地,如果是分类型特征,我们则采用众数进行填补。如果是连续型特征,我们则采用均值来填补
关于缺失值处理的方式, 有几种情况:
- 不处理(这是针对xgboost等树模型),有些模型有处理缺失的机制,所以可以不处理
- 如果缺失的太多,可以考虑删除该列
- 插值补全(均值,中位数,众数,建模预测,多重插补等)
- 分箱处理,缺失值一个箱。
下面整理几种填充值的方式:
# 删除重复值
data.drop_duplicates()
# dropna()可以直接删除缺失样本,但是有点不太好# 填充固定值
train_data.fillna(0, inplace=True) # 填充 0
data.fillna({0:1000, 1:100, 2:0, 4:5}) # 可以使用字典的形式为不用列设定不同的填充值train_data.fillna(train_data.mean(),inplace=True) # 填充均值
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
train_data.fillna(train_data.mode(),inplace=True) # 填充众数train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值"""插值法:用插值法拟合出缺失的数据,然后进行填充。"""
for f in features: train_data[f] = train_data[f].interpolate()train_data.dropna(inplace=True)"""填充KNN数据:先利用knn计算临近的k个数据,然后填充他们的均值"""
from fancyimpute import KNN
train_data_x = pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
1.2 特征归一化
- 为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。例如,分析一个人的身高和体重对健康的影响,如果 使用米(m)和千克(kg)作为单位,那么身高特征会在1.6~1.8m的数值范围内,体重特征会在50~100kg的范围内,分析出来的结果显然会倾向于数值差别比较大的体重特征。想要得到更为准确的结果,就需要进行特征归一化 (Normalization)处理,使各指标处于同一数值量级,以便进行分析。
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种:
线性函数归一化(Min-Max Scaling)
- 它对原始数据进行线性变换,使 结果映射到[0, 1]的范围,实现对原始数据的等比缩放。归一化公式如下,其中X为原始数据,Xmax,Xmin 分别为数据最大值和最小值。
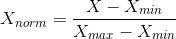
零均值归一化(Z-Score Normalization)
- 它会将原始数据映射到均值为 0、标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为
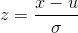
优点:训练数据归一化后,容易更快地通过梯度下降找到最优解。
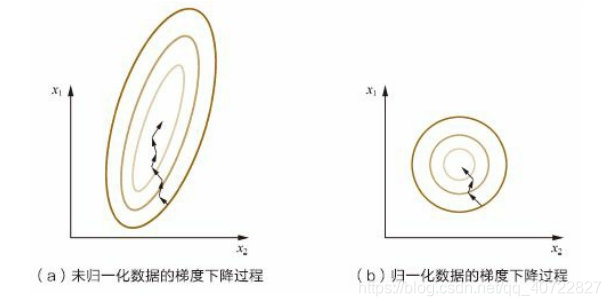
注意:数据归一化并不是万能的。在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用。
1.3 类别型特征
类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、 AB、O)等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
序号编码
- 序号编码通常用于处理类别间具有大小关系的数据。例如成绩,可以分为 低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
独热编码(one-hot)
- 独热编码通常用于处理类别间不具有大小关系的特征。例如血型,一共有4个 取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0, 1, 0),O型血表示为(0, 0, 0, 1)。对于类别取值较多的情况下使用独热编码。
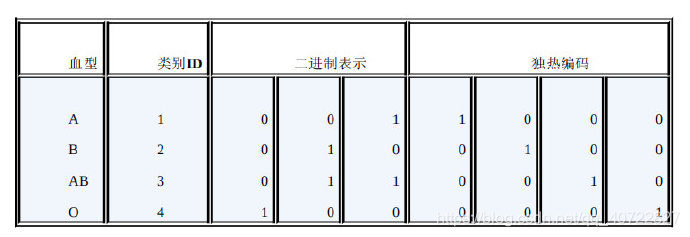
二进制编码
- 二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后 将类别ID对应的二进制编码作为结果。以A、B、AB、O血型为例,下图是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为 010;以此类推可以得到AB型血和O型血的二进制表示。
1.4 高维组合特征的处理
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。
- 以广告点击预估问题为例,原始数据有语言和类型两种离散特征,第一张图是语言和类型对点击的影响。为了提高拟合能力,语言和类型可以组成二阶特征,第二张图是语言和类型的组合特征对点击的影响。

1.5 文本表示模型
文本是一类非常重要的非结构化数据,如何表示文本数据一直是机器学习领域的一个重要研究方向。
词袋模型和N-gram模型
- 最基础的文本表示模型是词袋模型。顾名思义,就是将每篇文章看成一袋子词,并忽略每个词出现的顺序。具体地说,就是将整段文本以词为单位切分开, 然后每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重。
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
主题模型
- 主题模型用于从文本库中发现有代表性的主题(得到每个主题上面词的分布特性),并且能够计算出每篇文章的主题分布。
词嵌入与深度学习模型
- 词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间(通常K=50~300维)上的一个稠密向量(Dense Vector)。K维空间的每一 维也可以看作一个隐含的主题,只不过不像主题模型中的主题那样直观。
1.6 数据分桶
连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性。数据分桶的方式:
- 等频分桶
- 等距分桶
- Best-KS分桶(类似利用基尼指数进行二分类)
- 卡方分桶
最好将数据分桶的特征作为新一列的特征,不要把原来的数据给替换掉。
1.7 特征构造

在特征构造的时候,需要借助一些背景知识,遵循的一般原则就是需要发挥想象力,尽可能多的创造特征,不用先考虑哪些特征可能好,可能不好,先弥补这个广度。特征构造的时候需要考虑数值特征,类别特征,时间特征。
- 对于数值特征,一般会尝试一些它们之间的加减组合(当然不要乱来,根据特征表达的含义)或者提取一些统计特征
- 对于类别特征,我们一般会尝试之间的交叉组合,embedding也是一种思路
- 对于时间特征,这一块又可以作为一个大专题来学习,在时间序列的预测中这一块非常重要,也会非常复杂,需要就尽可能多的挖掘时间信息,会有不同的方式技巧。当然在这个比赛中涉及的实际序列数据有一点点,不会那么复杂。
1.8 特征选择
特征选择主要有两个功能:
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合
- 增强对特征和特征值之间的理解
通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
过滤式
- 主要思想: 对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关。相当于先对特征进行过滤操作,然后用特征子集来训练分类器。
- 主要方法:
- 移除低方差的特征:比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无论接下来的特征工程要做什么,都要优先消除方差为0的特征。
- 相关系数排序:分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
- 利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
- 互信息,利用互信息从信息熵的角度分析相关性。
- 卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。
- 卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断的边界,具体如下:

- 从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。
为什么随机森林运行如此之快?为什么方差过滤对随机森林没很大的有影响?
- 这是由于两种算法的原理中涉及到的计算量不同。
- 最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。
- 但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。这其实很容易理解,无论过滤法如何降低特征的数量,随机森林也只会选取固定数量的特征来建模;而最近邻算法就不同了,特征越少,距离计算的维度就越少,模型明显会随着特征的减少变得轻量。因此,过滤法的主要对象是:需要遍历特征或升维的算法们,而过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本。
提供一些有价值的小tricks:
- 对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
- 根据与目标的相关性等选出比较相关的特征(当然有时候根据字段含义也可以选)
- 卡方检验一般是检查离散变量与离散变量的相关性,当然离散变量的相关性信息增益和信息增益比也是不错的选择(可以通过决策树模型来评估来看),person系数一般是查看连续变量与连续变量的线性相关关系。
包裹式
- 单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
- 主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
- 主要方法:递归特征消除算法, 基于机器学习模型的特征排序
- 优缺点:
- 优点:从最终学习器的性能来看,包裹式比过滤式更好;
- 缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
嵌入式
-
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器 训练过程中自动地进行特征选择。嵌入式选择最常用的是L1正则化与L2正则化。在对线性回归模型加入两种正则化方法后,他们分别变成了岭回归与Lasso回归。
-
主要思想:在模型既定的情况下学习出对提高模型准确性最好的特征。也就是在确定模型的过程中,挑选出那些对模型的训练有重要意义的特征。
-
主要方法:简单易学的机器学习算法–岭回归(Ridge Regression),就是线性回归过程加入了L2正则项。
-
L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择
-
L2正则化在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参 数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性 回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移 得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
PCA降维技术
- 通过上面的特征选择部分,可以选出更好的分析特征,但是如果这些特征维度仍然很高怎么办?
- 如果数据特征维度太高,首先计算很麻烦,其次增加了问题的复杂程度,分析起来也不方便。这时候就会想是不是再去掉一些特征就好了呢?但是这个特征也不是凭自己的意愿去掉的,因为盲目减少数据的特征会损失掉数据包含的关键信息,容易产生错误的结论,对分析不利。
- 所以想找到一个合理的方式,既可以减少需要分析的指标,而且尽可能多的保持原来数据的信息,PCA就是这个合理的方式之一。 但要注意一点, 特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,而PCA,将已存在的特征压缩,降维完毕后不是原来特征的任何一个,也就是PCA降维之后的特征我们根本不知道什么含义了。
PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
1.9 特征工程脑图
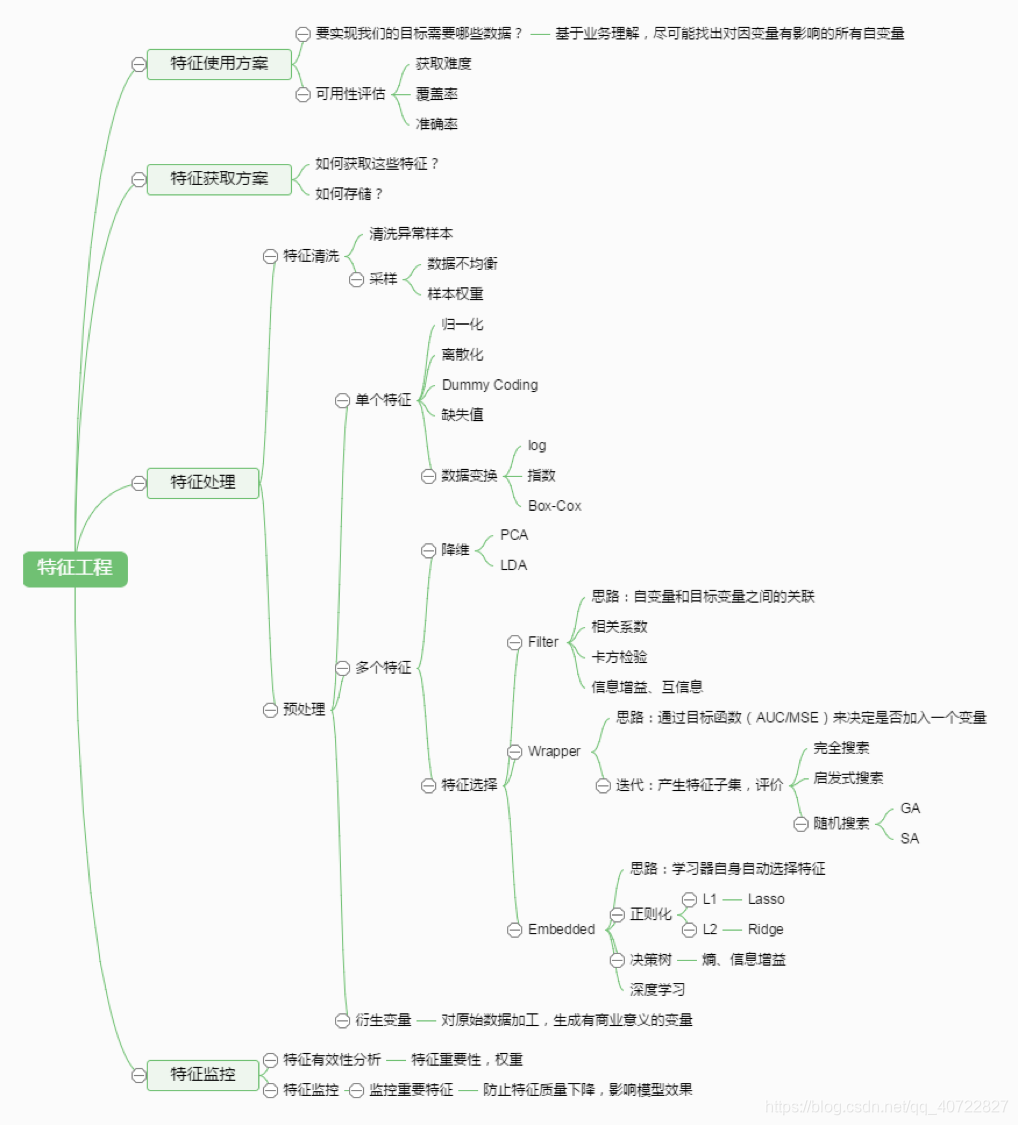
2. 机器学习优化方法
优化是应用数学的一个分支,也是机器学习的核心组成部分。实际上,机器学习算法 = 模型表征 + 模型评估 + 优化算法。其中,优化算法所做的事情就是在 模型表征空间中找到模型评估指标最好的模型。不同的优化算法对应的模型表征 和评估指标不尽相同。
2.1 常用损失函数
损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的准确性就越好。常见的损失函数如下:
平方损失函数
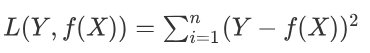
- Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值(注:该式子未加入正则项),也就是最小化残差的平方和。而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:
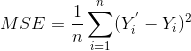
- 该损失函数一般使用在线性回归当中。
log损失函数

-
公式中的 y=1 表示的是真实值为1时用第一个公式,真实 y=0 用第二个公式计算损失。为什么要加上log函数呢?可以试想一下,当真实样本为1是,但h=0概率,那么log0=∞,这就对模型最大的惩罚力度;当h=1时,那么log1=0,相当于没有惩罚,也就是没有损失,达到最优结果。所以数学家就想出了用log函数来表示损失函数。
-
最后按照梯度下降法一样,求解极小值点,得到想要的模型效果。该损失函数一般使用在逻辑回归中。

Hinge损失函数

SVM采用的就是Hinge Loss,用于“最大间隔(max-margin)”分类。

2.2 什么是凸优化
- 凸函数的严格定义为,函数L(·) 是凸函数当且仅当对定义域中的任意两点x,y和任意实数λ∈[0,1]总有:
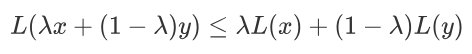
- 该不等式的一个直观解释是,凸函数曲面上任意两点连接而成的线段,其上的任意一点都不会处于该函数曲面的下方,如下图所示所示。

- 凸优化问题的例子包括支持向量机、线性回归等线性模型,非凸优化问题的例子包括低秩模型(如矩阵分解)、深度神经网络模型等。
2.3 正则化项
使用正则化项,也就是给loss function加上一个参数项,正则化项有L1正则化、L2正则化、ElasticNet。加入这个正则化项好处:
- 控制参数幅度,不让模型“无法无天”。
- 限制参数搜索空间
- 解决欠拟合与过拟合的问题。
2.4 常见的几种最优化方法
梯度下降法
- 梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。
- 一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。
- 梯度下降法的搜索迭代示意图如下图所示:
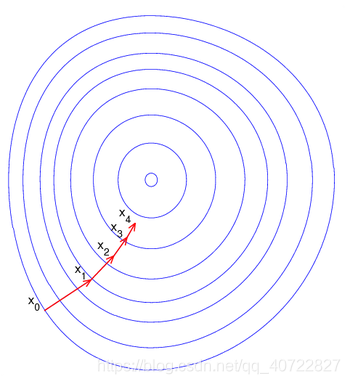
缺点:靠近极小值时收敛速度减慢;直线搜索时可能会产生一些问题;可能会“之字形”地下降。
牛顿法
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。具体步骤:
-
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ’ 表示函数 f 的导数)。
-
然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
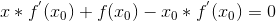
-
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法搜索动态示例图:
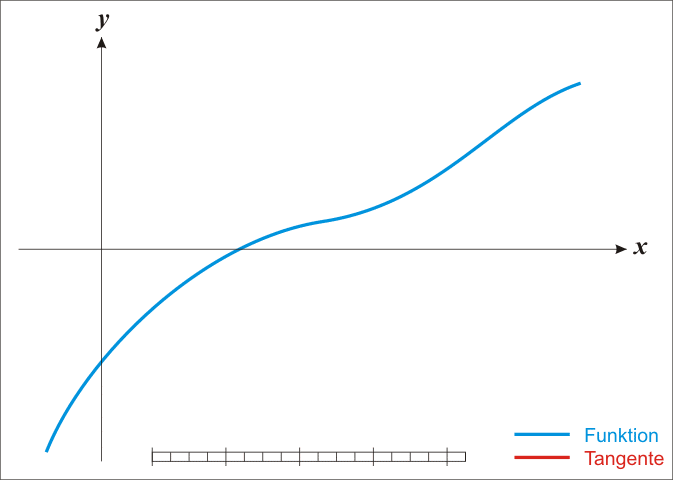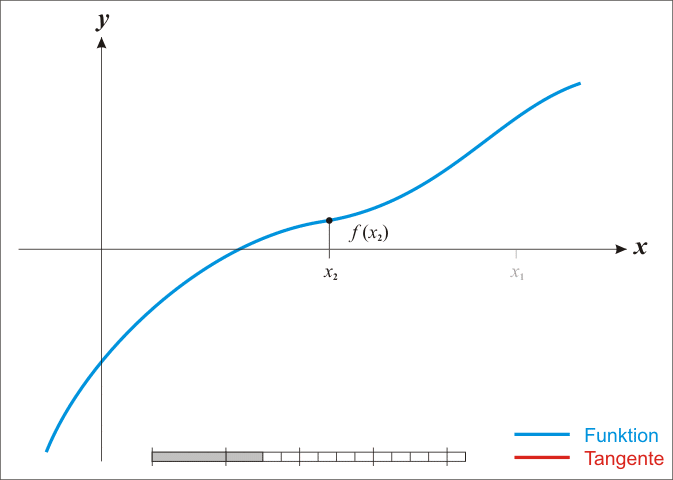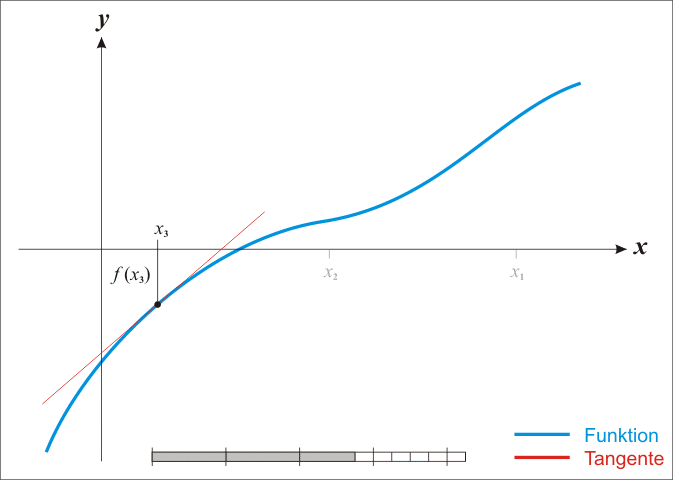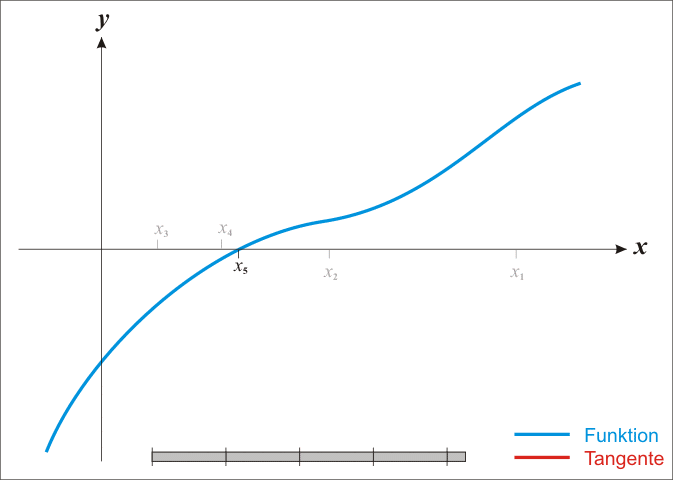
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。缺点:
- 牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
- 在高维情况下这个矩阵非常大,计算和存储都是问题。
- 在小批量的情况下,牛顿法对于二阶导数的估计噪声太大。
- 目标函数非凸的时候,牛顿法容易受到鞍点或者最大值点的吸引。
拟牛顿法
- 拟牛顿法是求解非线性优化问题最有效的方法之一,本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。
- 拟牛顿法和梯度下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于梯度下降法,尤其对于困难的问题。
- 另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
共轭梯度法
- 共轭梯度法是介于梯度下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。
- 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
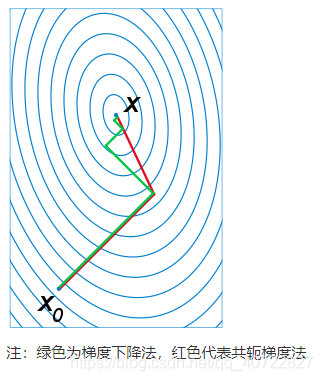
2.5 降维方法
2.5.1 线性判别分析(LDA)
- 线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的降维方法。和主成分分析PCA不考虑样本类别输出的无监督降维技术不同,LDA是一种监督学习的降维技术,数据集的每个样本有类别输出。
LDA分类思想简单总结如下:
- 多维空间中,数据处理分类问题较为复杂,LDA算法将多维空间中的数据投影到一条直线上,将d维数据转化成1维数据进行处理。
- 对于训练数据,设法将多维数据投影到一条直线上,同类数据的投影点尽可能接近,异类数据点尽可能远离。
- 对数据进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定样本的类别。
如果用一句话概括LDA思想,即“投影后类内方差最小,类间方差最大”。
假设有红、蓝两类数据,这些数据特征均为二维,如下图所示。我们的目标是将这些数据投影到一维,让每一类相近的数据的投影点尽可能接近,不同类别数据尽可能远,即图中红色和蓝色数据中心之间的距离尽可能大。
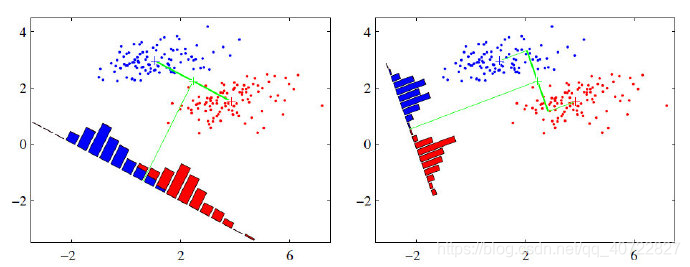
左图和右图是两种不同的投影方式。
- 左图思路:让不同类别的平均点距离最远的投影方式。
- 右图思路:让同类别的数据挨得最近的投影方式。
从上图直观看出,右图红色数据和蓝色数据在各自的区域来说相对集中,根据数据分布直方图也可看出,所以右图的投影效果好于左图,左图中间直方图部分有明显交集。
以上例子是基于数据是二维的,分类后的投影是一条直线。如果原始数据是多维的,则投影后的分类面是一低维的超平面。
优点
- 可以使用类别的先验知识;
- 以标签、类别衡量差异性的有监督降维方式,相对于PCA的模糊性,其目的更明确,更能反映样本间的差异;
缺点
- LDA不适合对非高斯分布样本进行降维;
- LDA降维最多降到分类数k-1维;
- LDA在样本分类信息依赖方差而不是均值时,降维效果不好;
- LDA可能过度拟合数据。
2.5.2 主成分分析(PCA)
- PCA就是将高维的数据通过线性变换投影到低维空间上去。
- 投影思想:找出最能够代表原始数据的投影方法。被PCA降掉的那些维度只能是那些噪声或是冗余的数据。
- 去冗余:去除可以被其他向量代表的线性相关向量,这部分信息量是多余的。
- 去噪声,去除较小特征值对应的特征向量,特征值的大小反映了变换后在特征向量方向上变换的幅度,幅度越大,说明这个方向上的元素差异也越大,要保留。
- 对角化矩阵,寻找极大线性无关组,保留较大的特征值,去除较小特征值,组成一个投影矩阵,对原始样本矩阵进行投影,得到降维后的新样本矩阵。
- 完成PCA的关键是——协方差矩阵。协方差矩阵,能同时表现不同维度间的相关性以及各个维度上的方差。协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。
- 之所以对角化,因为对角化之后非对角上的元素都是0,达到去噪声的目的。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉,即去冗余。
图解PCA
-
PCA可解决训练数据中存在数据特征过多或特征累赘的问题。核心思想是将m维特征映射到n维(n < m),这n维形成主元,是重构出来最能代表原始数据的正交特征。
-
假设数据集是m个n维,。如果,需要降维到,现在想找到某一维度方向代表这两个维度的数据。下图有两个向量方向,但是哪个向量才是我们所想要的,可以更好代表原始数据集的呢?
有以下两个主要评价指标:
-
样本点到这个直线的距离足够近。
-
样本点在这个直线上的投影能尽可能的分开。
如果我们需要降维的目标维数是其他任意维,则: -
样本点到这个超平面的距离足够近。
-
样本点在这个超平面上的投影能尽可能的分开。
优点
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素。
- 计算方法简单,主要运算是特征值分解,易于实现。
缺点
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
2.5.3 比较这两种方法
降维的必要性:
- 多重共线性和预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
- 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有2%。
- 过多的变量,对查找规律造成冗余麻烦。
- 仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
降维的目的:
- 减少预测变量的个数。
- 确保这些变量是相互独立的。
- 提供一个框架来解释结果。相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示。
- 数据在低维下更容易处理、更容易使用。
- 去除数据噪声。
- 降低算法运算开销。
LDA和PCA区别
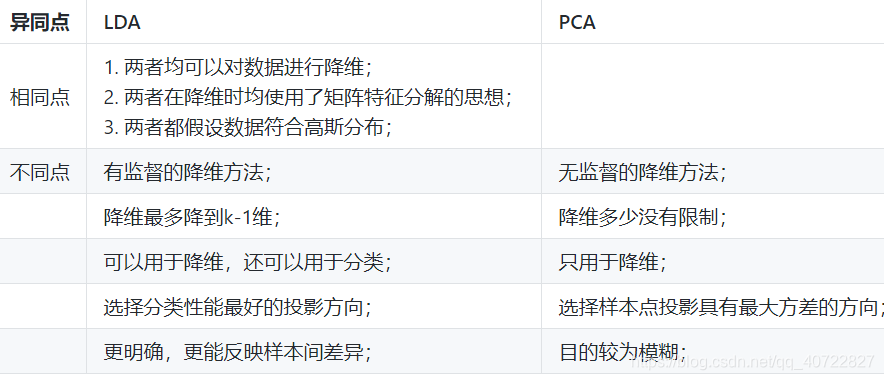
3. 机器学习评估方法
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
3.1 准确率(Accuracy)
准确率(Accuracy)。顾名思义,就是所有的预测正确(正类负类)的占总的比重。
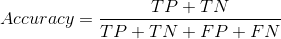
- 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准 确率的最主要因素。
3.2 精确率(Precision)
- 精确率(Precision),查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。
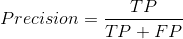
3.3 召回率(Recall)
- 召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。
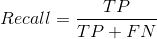
-
为了综合评估一个排序模型的好坏,不仅要看模型在不同 Top N下的Precision@N和Recall@N,而且最好绘制出模型的P-R(Precision- Recall)曲线。这里简单介绍一下P-R曲线的绘制方法。
-
P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲 线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本, 小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R 曲线是通过将阈值从高到低移动而生成的。下图是P-R曲线样例图,其中实线代表 模型A的P-R曲线,虚线代表模型B的P-R曲线。原点附近代表当阈值最大时模型的 精确率和召回率。
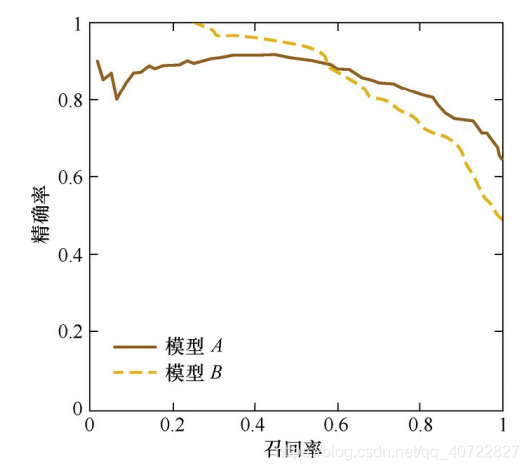
- 由图可见,当召回率接近于0时,模型A的精确率为0.9,模型B的精确率是1, 这说明模型B得分前几位的样本全部是真正的正样本,而模型A即使得分最高的几 个样本也存在预测错误的情况。并且,随着召回率的增加,精确率整体呈下降趋 势。但是,当召回率为1时,模型A的精确率反而超过了模型B。这充分说明,只用某个点对应的精确率和召回率是不能全面地衡量模型的性能,只有通过P-R曲线的 整体表现,才能够对模型进行更为全面的评估。
3.4 F1值(H-mean值)
- F1值(H-mean值)。F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
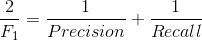
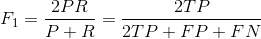
3.5 ROC曲线
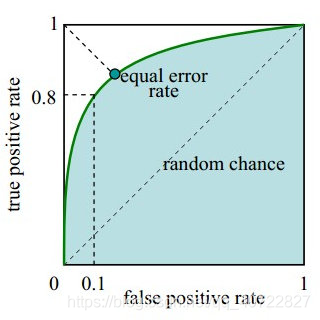
- ROC曲线。接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,ROC曲线上每个点反映着对同一信号刺激的感受性。
- 下图是ROC曲线例子。
-
横坐标:1-Specificity,伪正类率(False positive rate,FPR,FPR=FP/(FP+TN)),预测为正但实际为负的样本占所有负例样本的比例;
-
纵坐标:Sensitivity,真正类率(True positive rate,TPR,TPR=TP/(TP+FN)),预测为正且实际为正的样本占所有正例样本的比例。
-
真正的理想情况,TPR应接近1,FPR接近0,即图中的(0,1)点。ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
AUC值
- AUC (Area Under Curve) 被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
从AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
一句话来说,AUC值越大的分类器,正确率越高。
3.6 余弦距离和欧式距离
余弦距离: 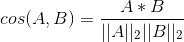
欧式距离:在数学中,欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。
- 对于两个向量A和B,余弦距离关注的是向量之间的角度关系,并不关心它们的绝对大小,其取值 范围是[−1,1]。当一对文本相似度的长度差距很大、但内容相近时,如果使用词频 或词向量作为特征,它们在特征空间中的的欧氏距离通常很大;而如果使用余弦 相似度的话,它们之间的夹角可能很小,因而相似度高。
- 此外,在文本、图像、 视频等领域,研究的对象的特征维度往往很高,余弦相似度在高维情况下依然保 持“相同时为1,正交时为0,相反时为−1”的性质,而欧氏距离的数值则受维度的 影响,范围不固定,并且含义也比较模糊。
3.7 A/B测试
- AB测试是为Web或App界面或流程制作两个(A/B)或多个(A/B/n)版本,在同一时间维度,分别让组成成分相同(相似)的访客群组(目标人群)随机的访问这些版本,收集各群组的用户体验数据和业务数据,最后分析、评估出最好版本,正式采用。
3.8 模型评估方法
Holdout检验
-
Holdout 检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分 成训练集和验证集两部分。比方说,对于一个点击率预测模型,我们把样本按照 70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型 验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
-
Holdout 检验的缺点很明显,即在验证集上计算出来的最后评估指标与原始分 组有很大关系。为了消除随机性,研究者们引入了“交叉检验”的思想。
交叉检验
- 交叉验证是用来观察模型的稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份
作为训练集,多次计算模型的精确性来评估模型的平均准确程度。训练集和测试集的划分会干扰模型的结果,因此
用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。在实际实验中,n经常取10。

自助法
-
不管是Holdout检验还是交叉检验,都是基于划分训练集和测试集的方法进行 模型评估的。然而,当样本规模比较小时,将样本集进行划分会让训练集进一步 减小,这可能会影响模型训练效果。有没有能维持训练集样本规模的验证方法 呢?自助法可以比较好地解决这个问题。
-
自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有 放回的随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采 样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验 证,这就是自助法的验证过程。
3.9 超参数调优
为了进行超参数调优,我们一般会采用网格搜索、随机搜索、贝叶斯优化等 算法。在具体介绍算法之前,需要明确超参数搜索算法一般包括哪几个要素。一 是目标函数,即算法需要最大化/最小化的目标;二是搜索范围,一般通过上限和 下限来确定;三是算法的其他参数,如搜索步长。
- 网格搜索,可能是最简单、应用最广泛的超参数搜索算法,它通过查找搜索范 围内的所有的点来确定最优值。如果采用较大的搜索范围以及较小的步长,网格 搜索有很大概率找到全局最优值。然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候。因此,在实际应用中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置;然 后会逐渐缩小搜索范围和步长,来寻找更精确的最优值。这种操作方案可以降低 所需的时间和计算量,但由于目标函数一般是非凸的,所以很可能会错过全局最 优值。
- 随机搜索,随机搜索的思想与网格搜索比较相似,只是不再测试上界和下界之间的所有 值,而是在搜索范围中随机选取样本点。它的理论依据是,如果样本点集足够 大,那么通过随机采样也能大概率地找到全局最优值,或其近似值。随机搜索一 般会比网格搜索要快一些,但是和网格搜索的快速版一样,它的结果也是没法保证的。
- 贝叶斯优化算法,贝叶斯优化算法在寻找最优最值参数时,采用了与网格搜索、随机搜索完全 不同的方法。网格搜索和随机搜索在测试一个新点时,会忽略前一个点的信息; 而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形 状进行学习,找到使目标函数向全局最优值提升的参数。
3.10 过拟合和欠拟合
- 过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是 模型在训练集上的表现很好,但在测试集和新数据上的表现较差。欠拟合指的是 模型在训练和预测时表现都不好的情况。下图形象地描述了过拟合和欠拟合的区别。
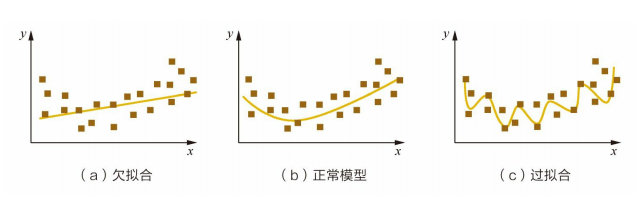
防止过拟合:
- 从数据入手,获得更多的训练数据。
- 降低模型复杂度。
- 正则化方法,给模型的参数加上一定的正则约束。
- 集成学习方法,集成学习是把多个模型集成在一起。
防止欠拟合:
- 添加新特征。
- 增加模型复杂度。
- 减小正则化系数。
4. 检验方法
4.1 KS检验
Kolmogorov-Smirnov检验是基于累计分布函数的,用于检验一个分布是否符合某种理论分布或比较两个经验分布是否有显著差异。
- 单样本K-S检验是用来检验一个数据的观测经验分布是否符合已知的理论分布。
- 两样本K-S检验由于对两样本的经验分布函数的位置和形状参数的差异都敏感,所以成为比较两样本的最有用且最常用的非参数方法之一。
检验统计量为: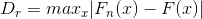
其中 Fn(x)为观察序列值,F(x)为理论序列值或另一观察序列值。
4.2 T检验
-
T检验,也称student t检验,主要用户样本含量较小,总体标准差未知的正态分布。
-
t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
-
t检验分为单总体检验和双总体检验。
4.3 F检验
- T检验和F检验的由来:为了确定从样本中的统计结果推论到总体时所犯错的概率。F检验又叫做联合假设检验,也称方差比率检验、方差齐性检验。是由英国统计学家Fisher提出。通过比较两组数据的方差,以确定他们的精密度是否有显著性差异。
4.4 Grubbs检验
- 一组测量数据中,如果个别数据偏离平均值很远,那么称这个数据为“可疑值”。用格拉布斯法判断,能将“可疑值”从测量数据中剔除。
4.5 卡方检验
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
-
提出原假设H0:总体X的分布函数F(x);
-
将总体x的取值范围分成k个互不相交的小区间A1-Ak;
-
把落入第i个区间Ai的样本的个数记做fi,成为组频数,f1+f2+f3+…+fk = n;
-
当H0为真时,根据假设的总体理论分布,可算出总体X的值落入第i个小区间Ai的概率pi,于是n*pi就是落入第i个小区间Ai的样本值的理论频数;
-
当H0为真时,n次试验中样本落入第i个小区间Ai的频率fi/n与概率pi应该很接近。基于这种思想,皮尔逊引入检测统计量:
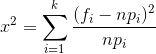
在H0假设成立的情况下服从自由度为k-1的卡方分布。
KS检验与卡方检验
相同点:都采用实际频数和期望频数只差进行检验
不同点:
- 卡方检验主要用于类别数据,而KS检验主要用于有计量单位的连续和定量数据。
- 卡方检验也可以用于定量数据,但必须先将数据分组才能获得实际的观测频数,而KS检验能直接对原始数据进行检验,所以它对数据的利用比较完整。
你知道的越多,你不知道的越多。
有道无术,术尚可求,有术无道,止于术。
如有其它问题,欢迎大家留言,我们一起讨论,一起学习,一起进步
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 2020十大国内伦敦金交易app排名榜单
在香港,黄金市场权威代表为成立逾百年的香港金银业贸易场,是香港唯一一间进行实货及现货黄金买卖的黄金及贵金属交易平台。任何交易商要成为贸易场的行员,必先通过严格审批。投资者在选择交易商时,应以金银业贸易场行员为标准,再配合计算投资成本及可获盈利,选择有利自己…...
2024/4/27 23:24:53 - 2020电赛芯片介绍和题目估计(二):LMT70
写的第一篇介绍反响还不错,这里就继续更新第二篇介绍 这次介绍的是LMT70 LMT70是精密模拟温度传感器,其供电要求低、引脚简单、具有很宽的温度测量范围,是一款医用级的传感器。 根据其测量结果精确、体积小、电源要求低的特点,我推测这次的省赛应该会让用LMT70设计一个可穿…...
2024/4/23 20:13:55 - centos6.5安装rabbitMQ的详解步骤
今天在centos6.5上安装rabbitMQ时,安装 erlang,下载安装文件执行命令:wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm报错:OpenSSL: error:140770FC:SSL routines:SSL23_GET_SERVER_HELLO:unknown protocol经过网上搜索资料发现是centos6.…...
2024/4/26 11:00:25 - 设计模式之单例模式singleton
1. 问题引入: java通过读取properties配置文件信息来创建Config配置类.在系统运行中,可能很多地方都要用到Config对象实例,就会有多个内容相同的对象.这样会造成内存资源浪费.上面的问题描述抽象一下,即:一个系统运行期间,某个类只需要一个类的实例就可以了,那么应该如何实现?…...
2024/4/19 13:45:12 - [C++]多线程队列实现
1、多线程队列实现 void initSrand() //微秒级随机种子 {LARGE_INTEGER start;QueryPerformanceCounter(&start);srand(unsigned(start.LowPart)); }void initSrand1() //毫秒级随机种子 {struct timeb tb;ftime(&tb);srand(unsigned(tb.millitm)); }int cap=10; de…...
2024/4/26 19:58:55 - InnoDB 事务(读MySQL技术内幕-InnoDB存储引擎)
ACID:原子性(Atomicity):整个数据库事务是不可分割的工作单位,事务中所有操作都成功,整个事务才算成功一致性(Consistency):从一种一致状态到下一种一致状态隔离性(Isolation):事务提交前对其他事务都不可见持久性(Durability):事务只要提交,就是永久性的事务的…...
2024/4/27 16:56:31 - JSP - MyEclipse 开发工具 +Tomcat 的安装和使用
可以从 https://www.myeclipsecn.com/download/ 地址或者其他途径下载myeclipse软件 下载好web服务器 tomcat软件 博主本人也是初学,下载myeclipse8.5版本的软件,安装完成之后如下图:之后打开myeclipse软件 workspace地址就是:以后创建的项目存放的地址,可以放在一个自己…...
2024/5/5 4:22:08 - 开源测试框架期末复习
第一章:基础概念 软件测试分类 根据项目流程阶段划分软件测试:单元测试、集成测试、系统测试、验收测试软件测试工作中对软件代码的可见程度:白盒测试与黑盒测试软件的不同测试面:功能测试与性能测试软件测试工作的自动化程度:手工测试与自动化测试自动化测试优缺点:重点…...
2024/4/24 17:56:27 - CSS可扩展性
今日在写pc官网的时候,一直对于HTML+css的结构编写完全按照自己的思维方式,今天把代码交给老大的时候,被他指出很多编写代码的错误性,比如代码结构,标签的使用,语义化,css的可扩展性,由于网站主要还是需要做seo优化,所以在标签使用上也有些不合理之处,给了我一些建议…...
2024/4/28 1:10:25 - Java基础知识日积月累(Tip of the Day05)
1.当参数或局部变量与成员变量同名时选择就近原则2.this就是对象的地址,谁调就是谁3.动态初始化对象与静态初始化对象4.构造生成全选可以Ctrl+A5.通过构造方法来创建对象6.API和API文档是两回事7.变量与常量字符串的拼接本质8.全是常量在运算时有常量优化机制...
2024/4/1 2:47:51 - MYSQL-mysql版本升级到5.7并迁移数据
文章目录MYSQL-mysql版本升级到5.7并迁移数据1. 安装mariadb数据库,并测试登录2.查看test数据库并备份数据3. 卸载mariadb数据库4. 安装高版本mysql数据库5. 恢复数据 MYSQL-mysql版本升级到5.7并迁移数据 1. 安装mariadb数据库,并测试登录 [root@server ~]# yum install -y …...
2024/4/25 16:13:16 - 吸管工具组(颜色取样)
吸管工具组(颜色取样)使用吸管工具组可以对图片中的任一位置进行颜色取样,方便操作图像。 可以对当前图层,当前和下方图层,全部图层,所有图层等颜色进行取样。学习目标掌握颜色取样 掌握标尺工具 掌握注释和计数小知识可以通过点击PS右上角的颜色属性,点击前景色,吸取到的…...
2024/4/20 7:32:24 - Python与Golang各自的特点及应用领域
特点 python ①解释型语言 程序不需要在运行前编译,在运行程序的时候才翻译,专门的解释器负责在每个语句执行的时候解释程序代码。这样解释型语言每执行一次就要翻译一次,效率比较低。 ②动态数据类型 支持重载运算符,也支持泛型设计。(运算符重载,就是对已有的运算符重新…...
2024/4/26 12:46:37 - 图框工具(剪切蒙版)
图框工具(剪切蒙版)假如我们需要更换电视内中的内容,或者要给特殊的图形添加背景图片,再或者为文字添加背景照片颜色,剪切蒙版是经常使用的…图框工具的基本功能 可以以一种矩形的方式或者圆形的方式选择出图片的一片区域,进行剪切蒙版。 对图层创建剪切蒙版 对图层创建剪切…...
2024/4/28 5:41:02 - Python模块-导入的路径范围
模块导入的路径范围 由sys模块的sys.path方法来规定,sys.path返回的数据类型是列表。 案例 import sys print(sys.path)输出: [E:\\workspace\\importTest, E:\\workspace\\importTest, E:\\xuegod\\python35.zip, E:\\xuegod\\DLLs, E:\\xuegod\\lib, E:\\xuegod, E:\\xuego…...
2024/4/20 0:28:30 - HBase的数据类型
HBase的数据类型 1 简介 在HBASE中,数据存储在具有行和列的表中。这是看起来关系数据库(RDBMS)一样,但将HBASE表看成是多个维度的Map结构更容易理解。ROWKEY C1列蔟 C2列蔟rowkey 列1 列2 列3 列4 列4 列6rowkey 0001C1(Map) 列1 => 值1 列2 => 值2 列3 => 值3C…...
2024/4/29 5:40:02 - JSP --- MyEclipse 开发工具 Tomcat 的安装和使用
可以从 https://www.myeclipsecn.com/download/ 地址或者其他途径下载myeclipse软件 下载好web服务器 tomcat软件 博主本人也是初学,下载myeclipse8.5版本的软件,安装完成之后如下图:之后打开myeclipse软件 workspace地址就是:以后创建的项目存放的地址,可以放在一个自己…...
2024/4/30 14:31:07 - LeetCode.1 两数之和
题目 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍示例 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 …...
2024/3/21 23:43:34 - 2020毕业心得
时隔好几个月,终于上线开始瞄一下我的博客了。 2020年的3月份一直到现在9月份一直没有时间打开自己的博客看一看。 这几个月经历了从学生到员工的,从学校到社会的转换。 不禁感慨学校的美好,也并不是说外面不好, 这几个月里会慢慢发现自己的不足 ,同时会经历很多意想不到的…...
2024/4/29 0:06:38 - 数据结构|链表常见面试题
以下是链表中常见面试题单链表实现约瑟夫环 反转单链表 K个节点为一组反转链表 返回链表中间(1/2)节点(扩展返回链表1/K节点) 单链表排序(冒泡排序&快速排序) 查找单链表的中间节点,要求只能遍历一次链表 查找单链表的倒数第K个节点,要求只能遍历一次链表 删除单链…...
2024/4/29 2:48:26
最新文章
- Typora编辑markdown的技巧
参考视频的B站链接: 手把手教你撰写Typora笔记 在其中选择了常用的部分做标记。 一、标题 使用ctrl数字键,可以快捷的把一行文字变成n级标题 二、源代码模式 可以在下图所示进入 三、设置typora能够自动显示粘贴的图片 打开“偏好设置”࿰…...
2024/5/5 4:32:17 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - SpringBoot和Vue2项目配置https协议
1、SpringBoot项目 ① 去你自己的云申请并下载好相关文件,SpringBoot下载的是Tomcat(默认),Vue2下载的是Nginx ② 将下载的压缩包里面的.pfx后缀文件拷贝到项目的resources目录下 ③ 编辑配置文件 (主要是框里面的内…...
2024/5/3 23:22:42 - 分享一个Python爬虫入门实例(有源码,学习使用)
一、爬虫基础知识 Python爬虫是一种使用Python编程语言实现的自动化获取网页数据的技术。它广泛应用于数据采集、数据分析、网络监测等领域。以下是对Python爬虫的详细介绍: 架构和组成:下载器:负责根据指定的URL下载网页内容,常用的库有Requests和urllib。解析器:用于解…...
2024/5/4 3:49:57 - MySQL数据库(一)
文章目录 1.MySQL8.0安装配置1.安装教程2.启动方法3.启动注意事项4.Navicat使用5.Navicat演示 2.MySQL数据库基本介绍1.三层结构2.SQL语句分类 3.MySQL数据库基本操作1.创建数据库2.不区分大小写的校对规则3.查看、删除数据库4.备份和恢复数据库1.备份数据库db01和db02…...
2024/5/4 3:52:42 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/4 12:05:22 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/4 11:23:32 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/4 14:46:16 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/4 23:54:44 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/4 12:10:13 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/4 23:54:49 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/4 23:54:44 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/4 14:46:12 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/4 14:46:11 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/4 14:46:11 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/5 2:25:33 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/4 21:24:42 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/4 12:39:12 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/4 13:16:06 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/4 16:48:41 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/4 14:46:05 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/5 3:37:58 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/4 23:54:30 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/4 9:07:39 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/4 14:46:02 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57