200817 python + BI
一、零碎知识点
快捷操作
shift+回车 执行并跳转到下一行
ctrl+回车 仅执行停留在当行
type()
% 余数
// 整除
None缺失
''空值
多变量同时赋值
a,b,c = 1,2,3
二、三大数据结构
1. 列表
# 取出第一个元素
list_name[0]
# 取出最后一个元素
list_name[-1]
# 左闭右开,起始位置~结束位置-1
list_name[起始:结束]# 插入新的元素到列表指定位置【同时更新原有列表】
list_name.insert然后按住shift+tab可以调出帮助文件
Signature: num.insert(index, object, /)
Docstring: Insert object before index.
Type: builtin_function_or_method# 插入新的元素到列表尾端【同时更新原有列表,且一次只能插入一个】
list_name.append()# 插入多个值到末尾,但需要手动更新
old_list = old_list + [元素1,...]# 删除
list_name.pop()
# 无参数默认删除最后一个
Signature: num.pop(index=-1, /)
Docstring:
Remove and return item at index (default last).
# set+list = 列表去重
a = [1,2,3,3]
b = [2,3,4]
# a + b = [1, 2, 3, 3, 2, 3, 4]
# 但想得到的是 [1,2,3,4] 去重的交集# 集合去重
set(a)
# {1, 2, 3}# 交集
set(a) & set(b)# 并集
set(a) | set(b)# 差集
set(a) - set(b)
2. 字典
没有顺序之分
# 创建字典
a = {'id':1, 'name':'gouzi', 'sex':'male'}# 查看元素
a['id'] # 1
a['ID'] # error
# 提高容错
list_name.get()
Signature: a.get(key, default=None, /)
Docstring: Return the value for key if key is in the dictionary, else default.a.get('ID')
# 查找,有则返回值,如若没有则更新
a.setdefault('id',2) #1
a.setdefault('age',0)
# {'id': 1, 'name': 'gouzi', 'sex': 'male', 'age': 0}# 删除元素
a.pop('id')
# 添加元素
a['id'] = 2# 提取标签
list(a.keys())
# 提取值
list(a.values())
# 同时提取
list(a.items())
3. 元组
用圆括号表示,里面的元素不能够修改
三、控制流
1. if
if 判断条件: #注意这个英文冒号xxxxx
2. while + break vs continue
一直执行直到判断条件为False
注意避免死循环

3. for + range/list…
range(stop) -> range object 输出 0 ~ (stop - 1)
range(start, stop[, step]) -> range object
# 除了 range和list 可以用for,字典也可以
for i in a.keys(): # values同理print(i)# 或者同时输出
for k,v in a.items():print(k,v)
循环进阶:简化写法
list_1 = []
for i in range(1,11):if i%2 == 0:list_1.append(i)# 简化写法
list_2 = [i for i in range(1,11) if i%2 == 0]# 除了i,还可以是
list_3 = [i**2 for i in range(1,11) if i%2 == 0]
list_4 = ['str'+ str(i) for i in range(1,11) if i%2 == 0]# 也可以用在字典上
dic = {'a':1,'b':2,'c':3}
list_5 = [i**2 for i in dic.values()]
四、函数
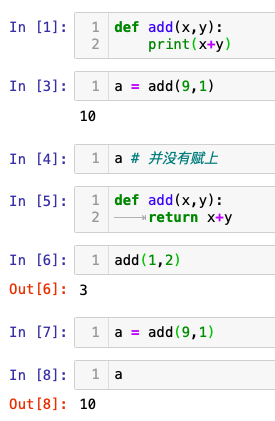
1. 自定义函数
def add(x,y):return x+y #这样可以将函数返回的值赋给变量;如果是print(x+y)则不行
2. map函数
#求列表1~10中每个元素的平方
#方法一
[i**2 for i in range(1,11)]#方法二
def squ(x):return(x*x)[squ(i) for i in range(1,11)]#方法三 【用map函数:】
list(map(squ,range(1,11)))
3. 匿名函数
list(map(lambda x:x*x,[1,2,3]))
#输入x【冒号】输出x^2
#这样不用定义函数
4. 第三方包 numpy & pandas
# 想要计算列表中各个元素出现的次数
a = [2,1,5,6,0,2,4,6,7,7]
d = {} #空字典for i in a:if i in d.keys():d[i] += 1else: d[i] = 1# 第三方包
import collections
collections.Counter(a)# 其他常用的包
import csv
import datetime
import math
import numpy as np #起别名
import pandas as pdb = np.array([[1,2,3,4],[5,6,7,8]])
# 同样可以用【】进行切片
b.dtype
# dtype('int64')⚠️list中数据类型不一定要一致,但是array中类型必须全部一致pd.Series([1,2,3]) #注意大写S
# 索引 & 数值
# 可自定义索引
s1 = pd.Series([1,2,3],index = ['a','b','c'])
s1['a']
#可同时多个索引
s1[['a','c']]
/*
a 1
b 2
c 3
dtype: int64
*/# 数据类型的转换,并没有更改原本的数据类型,只是预览
s1.astype('str')# 也可以导入字典的形式
s2 = {'name':'QQ','age':18}
s3 = pd.Series(s2)
/*
name QQ
age 18
dtype: object
*/# 数据框支持多种数据类型的输入
# 由字典导入,也可以列表然后自己定义index/columns

#查看具体信息
df = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=list('abc'))
df.info()#提取列
df['a'] #由dataframe变成series
#或者
df.a#提取行
df.ix[0:1]# 单一条件查找
df[df.a == 1]
# 多条件查找
# 错误
df[df.a == 1 & df.b == 2]
# The truth value of a Series is ambiguous.
# 正确:要使用小括号
df[(df.a == 1) & (df.b == 2)]
# 或者
df.query('(a == 1) & (b == 2)') #需要用引号括起来# 增
df.append #运算效率低df.iloc[1] # 注意是【】,得到的是第二行数据
df.iloc[1:2] #也是一样的结果,因为右边2是开区间
df.iloc[1:2,1:2]
# 如果index是字符串,也可以使用
df.index = ['one','two','three']
df.loc['two']
df.loc['two','b']
df.loc['two',['b','c']]/* dfa b c
one 1 2 3
two 4 5 6
three 7 8 9*/
五、实际案例
1. 导入数据
import pandas as pd
pd.read_csv('xx_utf.csv') #默认utf
# 如果是gbk(这里sample文件不是用逗号分割而是用\t,所以需要改sep)
df = pd.read_csv('xx_gbk.csv',encoding = 'gbk', sep = '\t')
# 还可以更改列名,添加参数names = list(...)# 概览
df.info()
# 描述统计
df.describe()df.head() #默认五行
2. 计算
df.tail() #默认五行# 数据类型的修改
df.top = df.top.astype('str')# 数据转置
df.T# 单一字段排序
df.avg.sort_values() # 返回结果是数组
df.sort_values(by = 'avg',ascending = False) #返回结果是数据框
# by排序的依据# 多个字段升降序
df.sort_values(['avg','city'],ascending = False)df.sort_index()# 排名
df.avg.rank(ascending = False, method = 'average')
# 如果出现多个值相同,排名则(min+max)/2
# e.g.四个值都并列第一,则(1+4)/2 = 2.5
# method还有max/min/first(不考虑并列,值相同时先遇到谁谁就是第一名[按照index])/last# 唯一值
df.workYear.unique()# 唯一值以及他们出现的次数
df.workYear.value_counts()# 累计求和
df.avg.cumsum()# 分段统计
# 错误写法
df.cut()
# 报错:Dataframe object has no attribute cut
# 正确写法
pd.cut(df.avg,bins = 20)
# 将数据分成20等分
# 参数labels = [...]可以写对应区间的标签 比如 低中高
# 一般为了方便查看会写成df['bins'] = pd.cut(df.avg,bins = 20)
# 也可以人工分割
pd.cut(df.avg,bins = [0,5,10,20,30,设置一个特别的的极大值],labels = ['0~5',...] )# 分位法进行分割
pd.qcut(x数据,q几等分位,labels = None, retbins = False开区间闭区间,precision = 3, duplicates = 'raise' 去重操作)
3. 聚合函数
df.groupby(by = 'city').count()
df.groupby(by = 'city').max()
... ...# 多字段
df.groupby(by = ['city','workYear']).mean()# 算分组之后工资最大值和最小值的差
for k,v in df.groupby(by = ['city']):print(max(v.avg) - min(v['avg']))print('我是分割线')
4. 多表关联操作 concat/join/merge
因为没有数据,假设有两张表position和company
# merge 针对的是列
position.merge(right关联的表,how = 'inner'关联的方式,on关联条件【字段名字相同】,left_on = None, right_on = None【名字不一致时使用】, right_index = F)pd.merge(left,right,how,...)# join 针对的是索引
company.join(position)# concat 堆叠 所有字段直接堆在一起,字段全部合并
pd.concat([company,pisition],axis = 0上下拼接/1左右拼接)
# 应用:每个月的销售表数据堆叠成大表df1 = pd.DataFrame({'A':list('abc'),'B':list('efg'),'C':list('hij')}
)df2 = pd.DataFrame({'C':list('abc'),'D':list('edf')}
)

# 多重索引
# 想从分组结果中提取某分类数据
position.groupby(by = ['city','eduction']).mean().avg['上海']['博士']
# 按照第一/二重索引的顺序
position.groupby(by = ['city','eduction']).mean().loc['上海','博士']# 如果不用groupby怎么设置多重索引
position.set_index(['city','education'])
# 但并没有排好序,没有合并,数据结果零散
position.sort_values(by = ['city','education']).set_index(['city','education']) #把列变成索引# 把索引变成列
position.groupby(by = ['city','eduction']).mean().reset_index()
5. 文本函数
position.positionLabels.str.count('分析师')
# 表.字段.str.函数 ; str对值里面的字符串进行操作
# 统计每行有几个‘分析师’position.positionLabels.str.find('分析师')
# 该字段出现的位置,显示为-1则表示未检索到position.positionLabels.str[1:-1] #删除每个字符串的首尾字符
position.positionLabels.str[1:-1].str.replace("'","") #删除引号
6. 数据清洗
import numpy as np
# 人为使数据变脏
position.loc[position.city == '深圳',city] = np.NaN #比起None,推荐使用这个# 填充
position.fillna(1) #将数据框中所有的空值填充为1# 删除空值所在的行(默认),所在列(axis = 1)
position.dropna() # 删除重复元素
position.duplicated() #返回bool
position = position[~position.duplicated()] #波浪号反向操作
# 更简单的方法
position.drop_duplicates()
7. apply
# 目标:在avg平均薪资数值后面加上‘k’
position.avg.astype('str')+'k' #不能直接相加,因为avg是浮点数position.avg.apply(lambda x:str(x)+'k')
# axis = 0 对列使用 = 1 行# 聚合apply
# 不同城市下薪资排名前几的职位
# sample
def func(x,n):# x 数据集 l 排名的依据 n 排名 r = x.sort_values('avg', ascending = False)return r[:n]position.groupby('city').apply(func,n = 3)# agg
position.groupby('city').agg('mean')
# 等价于 position.groupby('city').mean()
# 同时运用多个函数
position.groupby('city').agg(['mean','sum'])
# 自定义函数
position.groupby('city').agg(lambda x:max(x) - min(x))
8. 数据透视
position.pivot_table(index = ['city','education'], columns = 'workYear', values = ['avg','top'], aggfunc = [np.mean,np.sum])
# margins汇总项要不要
# 对avg和top都进行mean和sum的操作# 但如果想分别对avg进行mean操作,对top进行sum操作
# 字典!
position.pivot_table(index = ['city','education'], columns = 'workYear', values = ['avg','top'], aggfunc = {'avg':np.mean,'top':np.sum})
# 导入数据透视表最好是先reset_index
position.pivot_table(index = ['city','education'], columns = 'workYear', values = ['avg','top'], aggfunc = {'avg':np.mean,'top':np.sum}).reset_index().to_csv()
六、Python+数据库
1. 连接&读取数据库
# 终端
pip install pymysql #可能会安装在老版本下pip3 install pymysql #安装在python3的文件下
方法一 : pymysql
import pymysql# 创建连接
conn = pymysql.connect(host = 'localhost', #主机,数据库所在的位置,一般直接输入localhost本地或者ip地址user = 'root', #账户名password = '123',db = 'temp' , #连接的数据库schemaport = 3306, #端口默认3306charset = 'utf8'# 文本编码
)# 创建游标
cur = conn.cursor()
cur.execute('select * from Chars')
# 返回6,说明数据有6行data = cur.fetchall() #调取结果
dataconn.commit() #如果对数据进行修改,记得commit
# 打开游标操作结束,记得关闭
cur.close()
conn.close()
方法二 : Pandas
import sqlalchemy #那么之后调用就是sqlalchemy.create_engine
# 如果写的是
from sqlalchemy import create_engine
# 则直接调用create_engine
import pandas as pdsql = 'select * from Chars'
engine = create_engine('mysql+pymysql://root:password@localhost:3306/temp?charset=utf8')
# 用户名:密码@主机:端口/数据库?文本编码
data = pd.read_sql(sql,engine)# 也可以写成函数的形式
def reader(query,db):engine = create_engine('mysql+pymysql://root:password@localhost:3306/{0}?charset=utf8.format(db)')df = pd.read_sql(query,engine)return df# 可以用来加载数据
reader(
"""
select date(paidTime) as order_dt,userId as user_id,sum(price) as order_amount,count(orderId) as order_products
from data.orderinfo
where isPaid = "已支付"
group by date(paidTime),userId
"""
)
2. 写入数据库
结果.to_sql(name = 想写入到哪个数据库,con = 'mysql+pymysql://root:password@localhost:3306/temp?charset=utf8')
# 1. if_exists参数:= fail如果原来就存在这个数据表,则写入失败
# = append 表存在插入数据;不存在则自动新建一张表
# 2. index = True 索引也作为字段写入(一般选择False)
# 建议在数据库里先建表再插入
七、实例✨
1. 数据清洗
import pandas as pd
import numpy as npcolumns = ['user_id','order_dt','order_products','order_amount']/*
user_id 用户ID
order_dt 购买日期
order_products 购买产品数
order_amount 购买金额
*/df = pd.read_table('CDNOW_master.txt',names = columns, sep = '\s+')
# 通过多个字符串进行分割
# s+可以将tab和多个空格都当成一样的分隔符
# sep='\s+': 指代\f\n\t\r\v这些,分别为换页符,换行符,制表符,回车符,垂直制表符df.info()
# 发现order_dt的类型应该为日期,但是显示为int
# 可以之后改,也可以在pd.read_table导入数据的时候,添加参数parse_dates(把哪个字段转化成日期格式),date_parser具体的时间类型(同to_datetime中的format)
df.head()
df.describe()df['order_dt'] = pd.to_datetime(df.order_dt, format = '%Y%m%d')
# 后续需要使用月度进行数据分析,因此添加月份字段

# 上面dtype = datetime64[ns] ns是纳秒
df['month'] = df.order_dt.values.astype('datetime64[M]')
# 不要忘记values
/* 改为月份格式
array(['1997-01', '1997-01', '1997-01', ..., '1997-03', '1997-03','1997-03'], dtype='datetime64[M]')
*/
2. 进行用户消费趋势的分析(按月)
# (1)每月的消费总金额
# 我写的
df.groupby('month').agg('sum')['order_amount']
# 老师写的,后面使用更加方便
grouped_month = df.groupby('month')
order_month_amount = grouped_month.order_amount.sum()
order_month_amount.head()# 加载数据可视化包
import matplotlib.pyplot as plt
# 可视化显示在页面上
%matplotlib inline
# 更改设计风格
plt.style.use('ggplot')
order_month_amount.plot() #折线图# (2)每月的消费次数
grouped_month.user_id.count().plot()# (3)每月的产品购买量
grouped_month.order_products.sum().plot()# (4)每月的消费人数
# 我写的
result = grouped_month.user_id.unique().reset_index()
result.user_id.apply(lambda x:len(x)).plot()
# 老师写的
grouped_month.user_id.apply(lambda x:len(x.drop_duplicates())).plot()# 或者用数据透视表 —— 清晰明了
df.pivot_table(index = 'month',values = ['order_products','order_amount','user_id'],aggfunc = {'order_products' : 'sum','order_amount' : 'sum','user_id' : 'count'}).head()# 每月用户平均消费金额的趋势
grouped_month.order_amount.mean().plot()
# 每月用户平均消费次数的趋势
grouped_month.order_products.mean().plot()
3. 用户个体消费分析
# (1) 用户消费金额、消费次数的描述统计
grouped_user = df.groupby('user_id')
grouped_user.sum().describe()
# 结果显示:
# 用户平均购买了7张CD,但是中位数只有3,说明小部分用户购买了大量的CD
# 用户平均消费同理,有极值干扰# (2)用户消费金额和消费次数的散点图(线性还是非线性)
# 知识点:散点图是plot.scatter; 过滤数据可以用querygrouped_user.sum().plot.scatter(x = 'order_amount', y ='order_products')
# 线性,但大部分数据集中在左下角,删除极值点再画一次图grouped_user.sum().query('order_products < 400').plot.scatter(x = 'order_amount', y ='order_products')#(3)用户消费金额的分布图(是否分布呈现梯度)
grouped_user.order_amount.sum().hist()
# bins参数:柱子的多少
# 从直方图可以看出,用户消费金额绝大部分呈现集中趋势,小部分异常值干扰了判断。可以使用过滤操作排除异常 # (4) 用户消费次数的分布图
grouped_user.sum().query('order_products < 100').order_products.hist()
# 这里的100可以大概通过切比雪夫定理来定
/*
适用于任何数据集,而不论数据的分布情况如何。
至少75%的数据值与平均数的距离在z=2个标准差之内;
至少89%的数据值与平均数的距离在z=3个标准差之内;
至少94%的数据值与平均数的距离在z=4个标准差之内;易混淆
经验法则(Empirical Rule):需要数据符合正态分布。大约68%的数据值与平均数的距离在1个标准差之内;
大约95%的数据值与平均数的距离在2个标准差之内;
几乎所有的数据值与平均数的距离在3个标准差之内;
*/
# 描述统计order_products的均值是7,std = 17,所以按94%计算4*17+7# (5) 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
# ⚠️升序排列
user_cumsum = grouped_user.sum().sort_values('order_amount').apply(lambda x:x.cumsum()/x.sum())
user_cumsum.reset_index().order_amount.plot()
# 记住这里需要reset_index(),因为user_cumsum的索引是user_id,作图会出现问题
# 按用户消费金额进行升序排列,由图可知50%的用户仅贡献了15%的消费额度。而排名前5000的用户贡献了60%的消费额
4. 用户消费行为
- 用户第一次消费(首购)
- 用户最后一次消费
- 新老客户消费比
- 多少用户仅消费一次?
- 每月新客占比?
- 用户分层
- RFM
- 新、老、活跃、回流、流失
- 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
- 用户生命周期(按第一次&最后一次消费)
- 用户生命周期描述
- 用户生命周期分布
# 每天新客的数量变化
grouped_user.order_dt.min().value_counts().plot()
# 注意value_counts有s有括号
# 由图可知:用户第一次购买分布集中在前三个月;其中,在2月11日-25日有一次剧烈的波动# 最后一次消费(流失)
grouped_user.order_dt.max().value_counts().plot()
# 用户最后一次购买的分布比第一次分布更广;
# 大部分最后一次购买集中在前三个月,说明有很多用户购买了一次就不再进行购买
# 随着时间的递增,最后一次购买数也在递增,消费呈现流失上升的状况# 新老客户消费比
# 有多少用户仅消费一次?(老师是按照首次消费时间=最后一次消费时间,但万一一天内多次消费
user_life = grouped_user.order_dt.agg(['min','max'])
(user_life['min'] == user_life['max']).value_counts()
# 结论:有一半的用户就消费了一次
# 所以我写的是
temp = grouped_user.order_dt.count().reset_index()
temp[temp.order_dt == 1].count()# 每月新客占比# RFM
rfm = df.pivot_table(index = 'user_id',values = ['order_dt','order_products','order_amount'],aggfunc = {'order_dt' : 'max','order_products' : 'sum','order_amount' : 'sum'})# (Recency):表示客户最近一次购买的时间有多远
# P.S. 数据是199X年的数据,距今太久,这里用max进行相减
rfm['R'] = (rfm.order_dt.max() - rfm.order_dt)/np.timedelta64(1,'D')
# 分子部分是有单位的,后面除以是去掉单位且除以1(该数值可以修改

图源自: RFM 秦路老师

# (Frequency):客户在最近一段时间内购买的次数
# (Monetary)
rfm.rename(columns = {'order_products':'F','order_amount':'M'},inplace = True)# 🌟巧妙 不用多个ifelse
def rfm_func(x):level = x.apply(lambda x:'1' if x>0 else '0')label = level.R + level.F + level.Md = {'111':'重要价值客户','011':'重要保持客户','101':'重要挽留客户','001':'重要发展客户','110':'一般价值客户','010':'一般保持客户','100':'一般挽留客户','000':'一般发展客户'}result = d[label]return resultrfm['label'] = rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)# 使用plot.scatter自带的作图,点的颜色需要新加一列
rfm.loc[rfm.label == '重要价值客户','color'] = '#00CED1'
rfm.loc[~(rfm.label == '重要价值客户'),'color'] = '#DC143C'
# 也可以给每个类别上色,这里省略;后续的学习会使用Matplotlib
rfm.plot.scatter(x = 'F', y = 'R', c = rfm.color,alpha = 0.4)

rfm.groupby('label').count()
rfm.groupby('label').sum()/*
注意使用平均值时,极值会有影响,所以RFM的划分标准应该以业务为准(可以改为中位数或者自己划分)
- 尽量用小部分的用户覆盖大部分的额度
- 不要为了数据好看划分等级
*/# 用户分层:新客、老客、活跃、回流、流失
pivoted_counts = df.pivot_table(index = 'user_id',columns = 'month',values = 'order_dt',aggfunc = 'count').fillna(0)
pivoted_counts.head()
# 每个月消费的次数# 简化,只想知道这个月是否消费
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
# 但有个问题需要注意:要区分是0是没消费还是这时候是非用户,首次消费在这之后,只是数据透视,自动用0补上了def active_status(data):status = []for i in range(18):#若本月没有消费,一直未注册?不活跃?if data[i] == 0:if len(status) > 0:if status[i-1] == 'unreg':status.append('unreg')else:status.append('inactive')else:status.append('unreg')# 本月有消费:首次?回流?活跃else:if len(status) == 0:status.append('new')else:if status[i-1] == 'inactive':status.append('return')elif status[i-1] == 'unreg':status.append('new')else:status.append('active')return status# result_type ='expand'!!!
purchase_status = df_purchase.apply(active_status,axis = 1,result_type ='expand')
purchase_status.columns = pivoted_counts.columns
总之,
- 若本月没有消费
- 若之前有消费,则为流失或者不活跃
- 其他则为未注册
- 若本月有消费
- 若是第一次消费或者上个月为未注册,则为新用户
- 若之前有过消费且上个月为不活跃,则为回流
- 其他则为活跃
实际业务中,通常用SQL来‘上个月的状态表left join这个月的消费情况’,而不是数据透视
# 未注册不希望被count,设置为np.NaN
purchase_status_ct = purchase_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
purchase_status_ctpurchase_status_ct.fillna(0).T.head()
# 面积图
# 会有遮挡,换一下列的顺序
cols = ['active','new','return','inactive']
new_status = purchase_status_ct.fillna(0).T[cols]
new_status.plot.area()

# 各个状态的占比 / 消费用户的构成
purchase_per = new_status.apply(lambda x:x/x.sum(),axis=1)/*
活跃用户(持续消费的用户)对应的是消费运营的质量
回流用户(之前不消费本月才消费)对应的是唤回运营
不活跃用户 对应的是流失
*/# 上个月的没有消费的用户有多少这个月回来了
# shift()错位,往下平移一个
purchase_per['return']/purchase_per['inactive'].shift()# 用户购买周期(按订单来算,距离上一个订单的时间)
order_diff = grouped_user.apply(lambda x:x.order_dt - x.order_dt.shift())
order_diff.describe()# 只保留数值,去除单位,画图
(order_diff / np.timedelta64(1,'D')).hist(bins=20)
# 用户生命周期
(user_life['max'] - user_life['min']).describe()
# 大多数集中在0天,也就是只够买过一次,排除该部分数据再画图u_l = ((user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1,'D'))
u_l[u_l > 0].hist(bins=40)
# 仍存在较短生命周期的用户,但也有不少的用户稳定
5. 复购率和回购率分析
- 复购率:自然月内,购买多次的用户占比
- 回购率:曾经购买过的用户在某一时期内的再次购买的占比
# 用透视表计算客户每个月的消费次数
pivoted_counts=df.pivot_table(index='user_id',columns='month',values='order_dt',aggfunc='count').fillna(0)
pivoted_counts.head()purchase_r = pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
# 计算复购率:如果x>1,则赋值1 -> 表明消费次数在1次以上
# x==0赋值np.NaN,不会参与计算;其余情况赋值0#计算复购率
(purchase_r.sum()/purchase_r.count()).plot(figsize = (10,4))
# 复购的人数/消费的人数NaN不计算在内
# 宽10高4
# 结论:复购率稳定在20%左右,前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低

def purchase_back(data):status = []for i in range(17):if data[i] == 1: # 当月消费if data[i+1] == 1: # 次月消费status.append(1) #当月消费过,次月也消费了,回购用户1if data[i+1] == 0:status.append(0) # 次月未消费则为0,没有回购else:status.append(np.NaN) # 当月没消费
则不计NaNstatus.append(np.NaN) # 因为最后一个月缺少下一个月的数据,填补为空return pd.Series(status,df_purchase.columns)#对透视表应用函数purchase_back:
purchase_b = df_purchase.apply(purchase_back, axis =1)
purchase_b.head()
# 对照原始表进行理解
df_purchase.head()# 计算回购率:
(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4))
# 次月消费过的/本月消费用户数

八、可视化
1. Pandas
- 折线图 plot
- 柱形图 bar
- 直方图 hist
- 箱线图 box
- 密度图 kde
- 面积图 area
- 散点图 scatter
- 散点图矩阵 scatter_matrix
- 饼图 pie
import pandas as pd# 没找到课件的数据集,自己对照着视频中的数据改造了下DataAnalyst数据集
df = pd.read_csv('position_gbk.csv',encoding = 'gbk')%matplotlib inline
# 将matplotlib的图表直接显示在单元格里面# 折线图
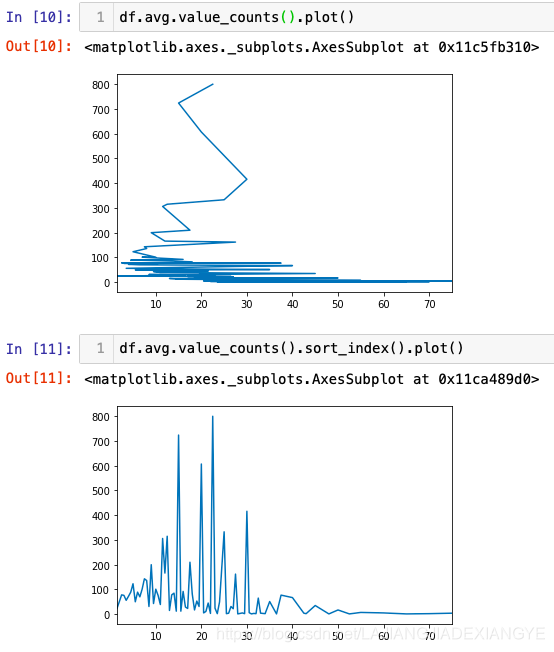
# 工资出现次数的折线显示乱七八糟是因为index无序
df.avg.value_counts().sort_index().plot()
# 柱形图
df.avg.value_counts().sort_index().plot(kind = 'bar')
df.avg.value_counts().sort_index().plot.bar() #更好,可以调用参数df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.bar()# 小方格是因为中文不兼容# 堆积柱形图
df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.bar(stacked = True)
# 水平轴方向绘制 +h
df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.barh(stacked = True)

# 直方图
df.avg.hist() #有网格
df.avg.plot.hist()# 无网格
# 多重直方图(类似于面积图那种,同时画出好几个直方图叠加在一起)
# 数据要转换成多列,这个例子里以学历为列
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5)
# unstack :series变成表格形式&行列转换
# 堆积
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5,stacked = True, bins = 30)
# 横向转换用参数orientation = 'horizontal'


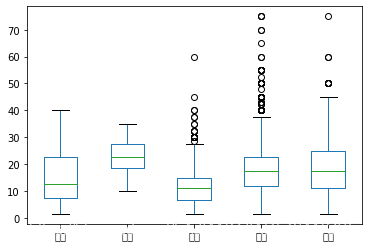
# 箱线图
# 首先得到一个多维度的数据框
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.box()
# 建议直接调用boxplot,更精简
df.boxplot(column = 'avg', by = 'education')

# 密度图
df.avg.plot.kde() #薪资的密度函数
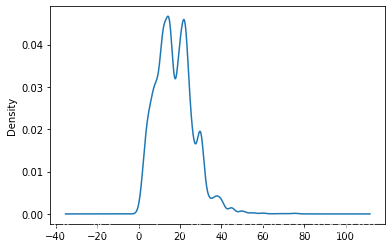
# 面积图
df.pivot_table(index = 'avg', columns = 'education', aggfunc = 'count', values = 'positionId').plot.area()
# 也可以对数据进行操作,变成百分比面积图df.pivot_table(index = 'avg', columns = 'education', aggfunc = 'count', values = 'positionId').apply(lambda x:x/x.sum()).plot.area()
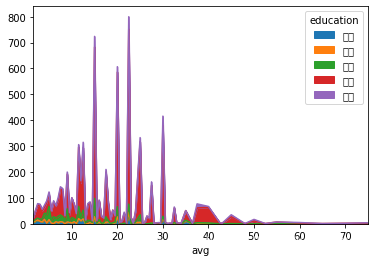
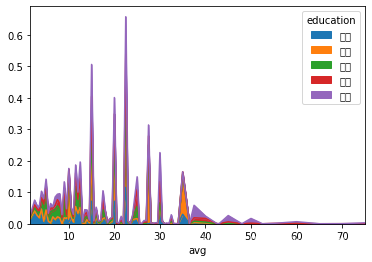
# 散点图
# 生成数据
df.groupby('companyId').aggregate(['mean','count']).avg.plot.scatter(x='mean',y='count')
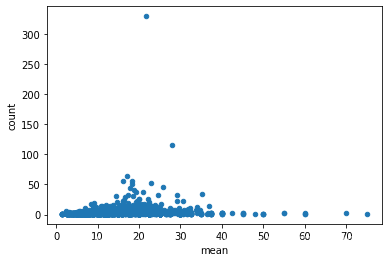
# 散点矩阵图
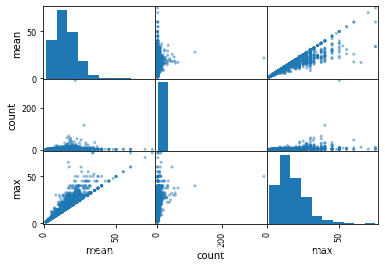
# 多个变量的关系;自身变量和自身变量则默认显示柱状图
matrix = df.groupby('companyId').aggregate(['mean','count','max']).avg
pd.plotting.scatter_matrix(frame = matrix)
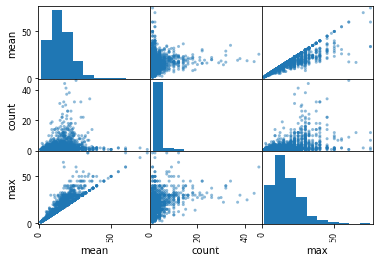
# 可以和数据清洗进行结合
pd.plotting.scatter_matrix(matrix.query('count < 50'))
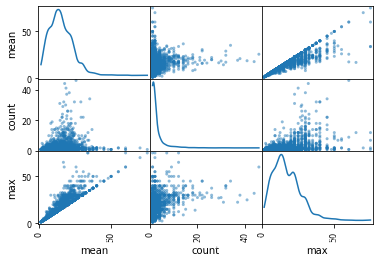
# 可以把柱状图变成密度图
pd.plotting.scatter_matrix(matrix.query('count < 50'),diagonal = 'kde')
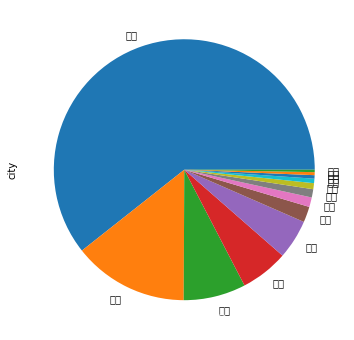
# 饼图
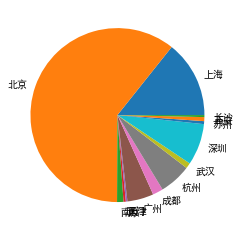
df.city.value_counts().plot.pie(figsize = (6,6))
2. matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotplib inline# 解决问题:中文字符无法显示
plt.rcParams['font.sans-serif'] = ['SimHei']
grouped_city = df.groupby('city').avg.count()
plt.pie(grouped_city,labels = grouped_city.index)
# 默认字体改为黑体
这里存在的问题是运行了但是仍然不显示中文,
问题在字体库压根没这字体emm
step 1: 先找到自己的字体库路径
可输入代码 matplotlib.matplotlib_fname() 自己找找
e.g. /Users/user_name/opt/anaconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf
step 2: 去下载字体并放到当前路径,再运行结果还不行emm
n小时瞎搞瞎删的连pandas都用不了,然后卸载重新装了anaconda又成功了(迷
参考:
https://www.jianshu.com/p/15b5189f85a3
https://www.jianshu.com/p/d1eeaa58ff4e
# 解决问题:在坐标轴上能显示负数
plt.rcParams['axes.unicode_minus'] = False
plt.plot(np.random.random_integers(-20,20,20))
针对这种图像输出上显示内存地址,可以通过plt.show()不显示
# 几张图 & 画布的长和宽
plt.figure(1,figsize=(10,4))
plt.plot(np.random.random_integers(-20,20,20))
plt.title('折线图')
plt.xticks([0,15,20]) #调整x轴的刻度
plt.xlabel('x轴')
plt.show()

plt.plot(np.random.random_integers(-20,20,20))
plt.plot(np.random.random_integers(-20,20,20))
# 一层层叠加上去
# 增加图例
plt.legend(('No_1','No_2'))
# 两层括号,以元组的形式
plt.show()
# 或者
plt.plot(np.random.random_integers(-20,20,20),label = 'no1', color = 'r')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2', color = 'b')
plt.legend()
plt.show()
# 分类显示不同学历薪资分布
# 多重聚合记得用方括号
data = df.groupby(['education','companyId']).aggregate(['mean','count']).avg.reset_index()

for edu,grouped in data.groupby('education'):
#grouped:不同学历下面的数据框x = grouped['mean']y = grouped['count']plt.scatter(x,y,label = edu)
plt.legend()
# plt.legend(loc = 'upper right')
plt.xlabel('平均薪资')
plt.ylabel('招聘人数')
plt.show()
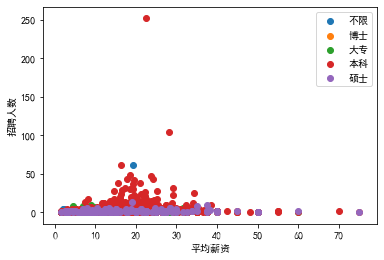
# 绘制子图
plt.figure(figsize = (12,4))
plt.subplot(1,2,1) # 1行2列,此时绘制的是第一个图;可缩写成121
plt.plot(np.random.random_integers(-20,20,20),label = 'no1', color = 'r')
plt.subplot(1,2,2) # 1行2列,此时绘制的是第二个图
plt.plot(np.random.random_integers(-20,20,20),label = 'no2', color = 'b')
plt.legend()
plt.show()
plt.figure(figsize = (12,4))
# 第一张图
plt.subplot(221)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2')
plt.legend() # 第二张图
plt.subplot(222)
plt.plot(np.random.random_integers(-20,20,20),label = 'no3')
plt.plot(np.random.random_integers(-20,20,20),label = 'no4')
plt.legend() # 第三张图
# 上面两张图不管,下面重置
plt.subplot(212)
plt.plot(np.random.random_integers(-20,20,20),label = 'no5')plt.show()
plt.figure(figsize = (12,4))
# 第一张图
plt.subplot(221)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2')
plt.legend() # 第二张图
plt.subplot(223)
plt.plot(np.random.random_integers(-20,20,20),label = 'no3')
plt.plot(np.random.random_integers(-20,20,20),label = 'no4')
plt.legend() # 第三张图
# 上面两张图不管,下面重置
plt.subplot(122)
plt.plot(np.random.random_integers(-20,20,20),label = 'no5')plt.show()
data = df.groupby(['city','companyId']).aggregate(['mean','count']).avg.reset_index()plt.figure(figsize = (16,8))
plt.subplot(121)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')for city,grouped in data.groupby('city'):
#grouped:不同学历下面的数据框x = grouped['mean']y = grouped['count']#⚠️放在这里plt.subplot(122)plt.scatter(x,y,label = city)
plt.legend()
# plt.legend(loc = 'upper right')
plt.xlabel('平均薪资')
plt.ylabel('招聘人数')
plt.show()

3. seaborn


- 分布
- distplot 概率分布图
- kdeplot 概率密度图
- joinplot 联合密度图
- pairplot 多变量图
- 分类
- boxplots 箱线图
- violinplots 提琴图
- barplot 柱形图
- factorplot 因子图
- 线性
- lmplot 回归图
- heatmap 热图
import seaborn as sns
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table('CDNOW_master.txt',names = columns, sep = '\s+')# 直方图+概率密度图
sns.distplot(df.order_amount)
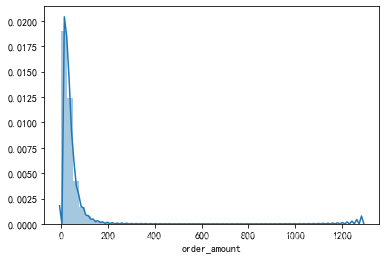
# 只有直方图
sns.distplot(df.order_amount,kde = False)
# 概率密度图
sns.kdeplot(df.order_amount)
# 联合密度图
grouped_user = df.groupby('user_id').sum()
sns.jointplot(grouped_user.order_products,grouped_user.order_amount, kind = 'reg')
# 默认散点图;order_products 销量 order_amount 金额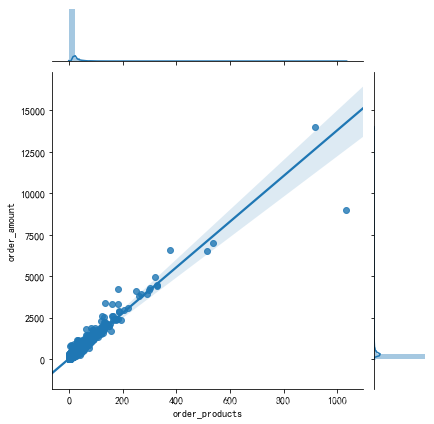
# 联合密度图
df['order_dt'] = pd.to_datetime(df.order_dt, format = '%Y%m%d')
rfm = df.pivot_table(index = 'user_id',values = ['order_products','order_amount','order_dt'],aggfunc = {'order_dt' : 'max','order_amount' : 'sum','order_products' : 'sum'})
rfm['R'] = (rfm.order_dt.max() - rfm.order_dt)/np.timedelta64(1,'D')
rfm.rename(columns = {'order_products':'F', 'order_amount':'M'}, inplace = True)
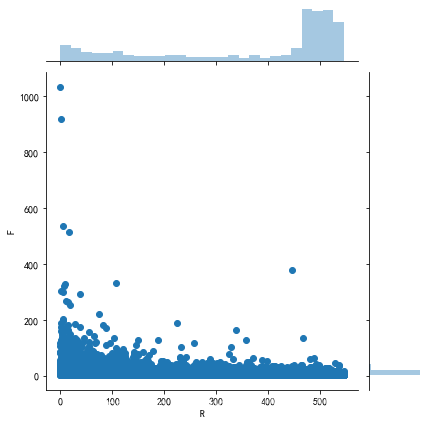
rfm.head()sns.jointplot(rfm.R,rfm.F)
# 三张表都加了元素
sns.jointplot(rfm.R,rfm.F,kind = 'reg')
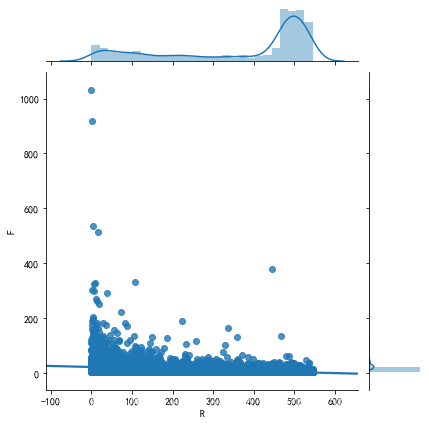
# 多变量图,类似于pandas的散点图矩阵
sns.pairplot(rfm)
# 其中参数hue是个分类变量,比如说男女,可以用不同的颜色来表示出来
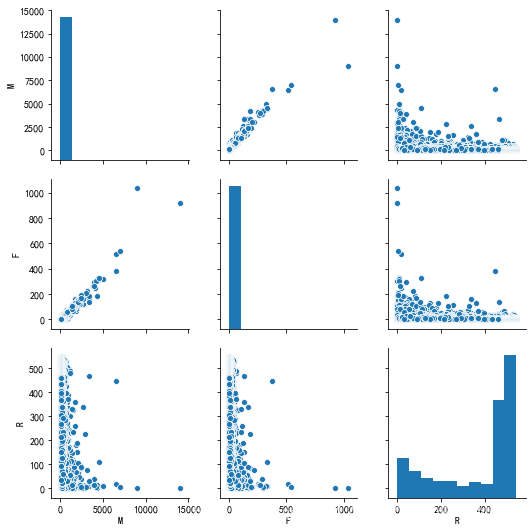
# 箱线图
df = pd.read_csv('cy.csv',encoding = 'gbk') # 餐饮数据
plt.figure(figsize = (20,5))
sns.boxplot(x = '类型', y = '口味', data = df)

df2 = df.query("(城市 == '上海') |(城市 == '北京')")
plt.figure(figsize = (20,5))
sns.boxplot(x = '类型', y = '口味', hue = '城市', data = df2)
# 增加一个对比的维度‘城市’

# 提琴图
plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', data = df2)
# 数据集中 -> ‘胖瘦’程度

plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', hue = '城市', data = df2)

# 拼接起来,比左右对比更加直观
plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', hue = '城市', data = df2, split = True)

# 因子图
# 类似简化版的箱线图
# plt.figure(figsize = (20,5)) 画布拉大失效,因为因子图自带size参数(现在更名为height,aspect调整图片的高度
# 因子图 kind = 'box' 就会变成箱线图
sns.factorplot(x = '类型', y = '口味',data = df2, hue = '城市', height = 10, aspect = 2)

# 类似散点图矩阵的功能
sns.factorplot(x = '类型', y = '口味',data = df2, col = '城市', kind = 'violin',height = 5, aspect = 2)
# 当城市类别过多时,该函数仍然会机械的想把所有的图显示在一行,因此需要用到col_wrap参数
# hue是图表里面进行对比,col是整个图表进行对比
# 把col改成row则变成上下排列

# 回归图
# 画出直线,不代表是线性关系,有可能是强行,一定要整体看
sns.lmplot(x = '口味', y = '环境', data = df2)
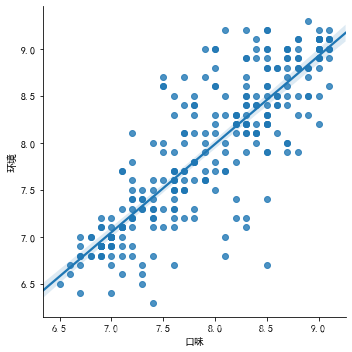
sns.lmplot(x = '口味', y = '环境', data = df2, hue = '城市')
# order = 1 默认为线性,可以进行修改
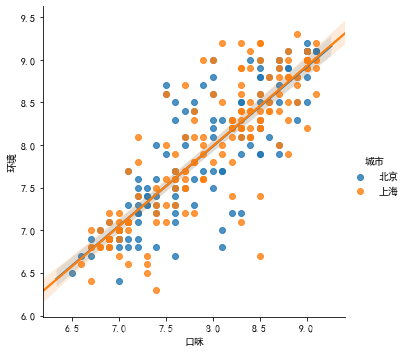
# 热力图
# 城市和餐厅类型是否与关联
pt = df.pivot_table(index = '城市', columns = '类型', values = '口味', aggfunc = 'mean')
plt.figure(figsize = (10,10))
sns.heatmap(pt)

sns.heatmap(pt,annot = True) #图上显示数值

4. python搭建BI —— superset
【世上无难事只要肯放弃 再见:> tableau我来了】
# 终端:创建虚拟环境
conda create -n superset python=3.7# 激活虚拟环境
source activate superset
# 我用的是conda activate superset也可以# 安装/* 不是pip install superset
否则后面会报错
AttributeError: 'NoneType' object has no attribute 'auth_type'
但是按照网络教程的pip install superset==0.28.1
也会出现很多红字错误ERROR: Command errored out with exit status 1
*/# 启动
# 到安装虚拟环境的路径
cd /opt/anaconda3/envs/superset
cd bin
python superset
# 最后一步会有些报错 no module named XXX 安装一下就好# 初始化配置
fabmanager create-admin --app superset
# 创建账号,记住所输入的信息
/*
username[admin]:admin
user first name[admin]:shu
user last name[admin]:fen
email: sf@offer.com
password:offer
*/⚠️注意,安装的时候 有个包怎么都装不上
No module named 'geohash’
解决办法:
- 改geohash所在的文件夹名字为Geohash「即首字母大写」
- 打开这个文件夹中的__init__.py,将第一行from geohash改为from .geohash
- 保存,再去终端pip install geohash
后来又出现了👇的问题
sqlalchemy_utils.exceptions.ImproperlyConfigured: 'cryptography' is required to use EncryptedType
就是缺少这个包 pip install cryptography就行
有问题戳这个链接:ubuntu16下部署apache superset趟坑指南(内有福利)
基本上都解决了
python superset db upgradepython superset load_examples
python superset init# 启动
python superset runserver #可能会说某个模块找不到,但是是linux的
python superset runserver -d #以开发者的形式进行激活
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 9.5一个任务
本期内容详解: 任务:将文件(record.txt)中的数据进行分割并按照以下规律保存起来: -小甲鱼的对话单独保存为boy_.txt的文件(去掉“小甲鱼:”) -小客服的对话单独保存为girl_.txt的文件(去掉“小客服:”) -文件中总共有三段对话,分别保存为boy_1.txt,girl_1.txt,b…...
2024/4/28 19:34:26 - 利用shell脚本快速实现中代理开启和关闭
目录1. shell脚本函数2. 修改终端初始配置文件3. 测试终端代理 1. shell脚本函数 新建一个文件命名为 teminal_proxy.sh,然后编写一下连个函数 # 开启代理 function proxy_on(){export ALL_PROXY=socks5://127.0.0.1:1087 # 注意你的端口号可能不是1087,注意修改export http…...
2024/4/27 16:36:44 - [论文总结] 集约经营人工林营林研究进展
Advances in Silviculture of Intensively Managed Plantations 作者:Rafael A. Rubilar et al., Current Forestry Reports, 2018. 论文链接: link 造林策略:种植面积,树种,种植密度 旬的森林土地征用的决策包括潜在的生产力、地面信息、预期产量。在获得土地后,管理者第…...
2024/4/27 22:21:55 - ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》的完整翻译,如有翻译不当之处敬请评论指出,蟹蟹!(2019-10-17) 作者:Qilong Wang1, Banggu Wu1, Pengfei Zhu1, Peihua Li2, Wangmeng Zuo3, Qinghua Hu1 发表:暂未知 代码:https://…...
2024/4/11 15:28:32 - #php 安装memcache的扩展#
1:window系统安装php-memcache扩展下载memcache.dll扩展下载地址是http://windows.php.net/downloads/pecl/releases/memcache/3.0.8/注意 下载对应的php版本 V9 V6 V11 安全模式和非安全模式三点可以通过再运行的phpinfo查看到,如图所示根据以上信息选择对应的memcache扩…...
2024/4/11 15:28:32 - 代码写方法
1,先根据需求设计好整体的步骤流程--最好形成流程图,对照现有条件没有问题后写代码2,根据流程图步骤,用注释,伪代码的形式先代码标注好待做的步骤,甚至每个步骤要做的事项3,做的过程中边做边抽象方法,在此基础上可以将抽象的方法变为公用方法,每个方法一件事情5,为了…...
2024/4/11 15:28:30 - 彩色圆点气泡跟随 鼠标光标动画特效
彩色圆点气泡跟随 鼠标光标动画特效效果图如下: 泡泡会根据鼠标的移动在鼠标下方会生成泡泡 然后缓缓上升。 可以父子以下代码看一下实际效果。1、下面是HTML结构 HTML结构很简单,主要是靠css和一点js去实现 <body><div>光标移动查看</div><!-- <spa…...
2024/4/11 15:28:29 - 为什么总是感觉压力很大?应该怎么办?
不管在职场上,还是在生活中,总是有时候会感觉压力很大。有些学员甚至压力大到无法入睡,十分焦虑。有些咨询的学员,说自己几个月都无法正常入睡,一直在喝中药调理。又没有什么身体上太多的问题,就是压力大。 TVB有句名言:“做人,最重要的就是开心”。基本每一个人,都希…...
2024/4/11 15:28:28 - java.net.BindException: Address already in use: 解决方法
java.net.BindException: Address already in use: 解决方法参考文章: (1)java.net.BindException: Address already in use: 解决方法 (2)https://www.cnblogs.com/dayspring/p/11636263.html 备忘一下。...
2024/5/2 5:21:25 - 标注版FileOutputStream写数据加入异常处理(加入异常处理的字节输出流操作)
package cnitcast_02;import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException;/** 加入异常处理的字节输出流操作*/ public class 标注版FileOutputStream写数据加入异常处理 {public static void main(String[] args) {//分开做…...
2024/4/23 9:24:48 - 优化Tmocat服务的安全配置
文章目录隐藏版本信息删除默认的测试页面 隐藏版本信息 未修改版本信息前,使用命令查看服务器的版本信息 proxy有192.168.2.5的IP地址,这里使用proxy作为客户端访问192.168.2.100服务器(web1)。 [root@proxy ~]# curl -I http://192.168.2.100:8080/xx #访问不存在…...
2024/4/11 15:28:25 - 阿里云telnet 3306端口失败
在阿里云的服务器上安装了MySQL, 然后远程访问总是不通。 查询了很久,排查思路如下:检查mysql是否启动 检查防火墙开启 检查本机3306端口是否处于监听状态 检查阿里云控制台是否开启了安全限制 检查mysql用户能否在远程进行登录 mysql 的 bind-address 设置为 127.0.0.1我们…...
2024/4/25 22:10:18 - Mybatis的查询、关联查询
使用Mybatis进行查询 查询结果的映射 Mybatis通过<select>进行查询。通过<resultMap>将查询结果封装成实体类: <resultMap id="deptMap" type="Dept"><!--<![CDATA[<id>是主键标签]]> --><!--<![CDATA[<pro…...
2024/4/11 15:28:23 - Tomcat基础
文章目录概述Java简介JDK简介Java Servlet安装部署Tomcat服务器部署Tomcat服务器软件(192.168.2.100/24)修改Tomcat配置文件使用Tomcat部署虚拟主机配置服务器虚拟主机修改www.b.com网站的首页目录跳转配置Tomcat日志配置Tomcat支持SSL加密网站额外扩展 概述 Java简介 Java是一…...
2024/4/17 11:31:13 - Python之torch.range() torch.arange()
...
2024/4/28 20:55:33 - Mysql查询某字段值重复的数据
Mysql查询某字段值重复的数据select user_name,count(*) as count from user group by user_name having count>1;...
2024/4/17 1:25:34 - Zabbix报警机制
文章目录一、基本概念二、触发器2.1、创建触发器2.2、创建表达式2.3、添加几个用户测试三、创建动作四、设置邮件报警4.1、创建Media4.2、创建Action4.3、效果测试 一、基本概念 自定义的监控项默认不会自动报警 首页也不会提示错误 需要配置触发器与报警动作才可以自动报警触发…...
2024/4/25 14:45:47 - Zabbix监控案例
文章目录使用192.168.1.102实验目的:调用自己编写的shell脚本,监控数据案例一、监控nginx服务的运行状态1.1、环境准备1.2、编写监控脚本1.3、定义监控服务使用命令1.4、web页面配置案例二、监控服务器的TCP连接状态2.1、概述2.2、编写监控脚本3.3、定义监控服务使用命令3.4、…...
2024/4/26 10:52:07 - Excel VBA 小程序 - 文本型数字转为数值型数字
实现功能:选中当前工作表中的所有数据内容,将文本型数字转换为数值型数字。 缺点:日期格式的字符串会变成数值 Sub 转数值型数字() With ActiveSheet.UsedRange.NumberFormatLocal = "G/通用格式".Value = .Value End With End Sub...
2024/4/11 19:08:09 - Hadoop基础认知
HDFS:分布式文件存储系统,解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。 MAPREDUCE:分布式计算框架, 实现在很多机器上分布式并行运算 YARN:分布式资源调度平台,帮用户调度大量的mapreduce程序,并合理分配运算资源...
2024/4/11 19:08:08
最新文章
- 蜜罐部署解析
蜜罐就是给黑客设置的一个陷阱,引导黑客攻击,但凡打蜜罐的都是真实攻击行为 蜜罐可以部署再外网 将节点部署在互联网区,用来感知互联网来自自动化蠕虫、竞争对手和境外的 真实威胁,甚至发现针对客户的 0day攻击,通过和…...
2024/5/3 16:44:36 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 华为海思2024春招数字芯片岗机试题(共9套)
huawei海思2024春招数字芯片岗机试题(共9套,有答案和解析,答案非官方,未仔细校正,仅供参考)(WX:didadidadidida313,加我备注:CSDN huawei数字题目,谢绝白嫖哈)…...
2024/5/3 3:08:35 - 【python】Flask Web框架
文章目录 WSGI(Web服务器网关接口)示例Web应用程序Web框架Flask框架创建项目安装Flask创建一个基本的 Flask 应用程序调试模式路由添加变量构造URLHTTP方法静态文件模板—— Jinja2模板文件(Template File)<...
2024/5/2 2:33:45 - 2024 年高效开发的 React 生态系统
要使用 React 制作应用程序,需要熟悉正确的库来添加您需要的功能。例如,要添加某个功能(例如身份验证或样式),您需要找到一个好的第三方库来处理它。 在这份综合指南中,我将向您展示我建议您在 2024 年使用…...
2024/5/1 13:50:40 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/3 11:50:27 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/2 16:04:58 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/2 23:55:17 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/3 16:00:51 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/3 11:10:49 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/2 6:03:07 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/2 9:47:30 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/2 23:47:43 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/3 13:26:06 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/3 1:55:15 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/2 9:47:28 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/3 16:23:03 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/3 1:55:09 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/2 8:37:00 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/3 14:57:24 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/2 9:47:25 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/2 23:47:16 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/2 18:46:52 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/3 7:43:42 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/3 1:54:59 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57