Flink源码分析之深度解读流式数据写入hive
文章目录
- 前言
- 数据流处理
- hive基本信息获取
- 流、批判断
- 写入格式判断
- 构造分区提交算子
- 详解StreamingFileWriter
- 简述StreamingFileSink
- 分区信息提交
- 提交分区算子
- 分区提交触发器
- 分区提交策略
- 总结
前言
前段时间我们讲解了flink1.11中如何将流式数据写入文件系统和hive [flink 1.11 使用sql将流式数据写入hive],今天我们来从源码的角度深入分析一下。以便朋友们对flink流式数据写入hive有一个深入的了解,以及在出现问题的时候知道该怎么调试。
其实我们可以想一下这个工作大概是什么流程,首先要写入hive,我们首先要从hive的元数据里拿到相关的hive表的信息,比如存储的路径是哪里,以便往那个目录写数据,还有存储的格式是什么,orc还是parquet,这样我们需要调用对应的实现类来进行写入,其次这个表是否是分区表,写入数据是动态分区还是静态分区,这些都会根据场景的不同而选择不同的写入策略。
写入数据的时候肯定不会把所有数据写入一个文件,那么文件的滚动策略是什么呢?写完了数据我们如何更新hive的元数据信息,以便我们可以及时读取到相应的数据呢?
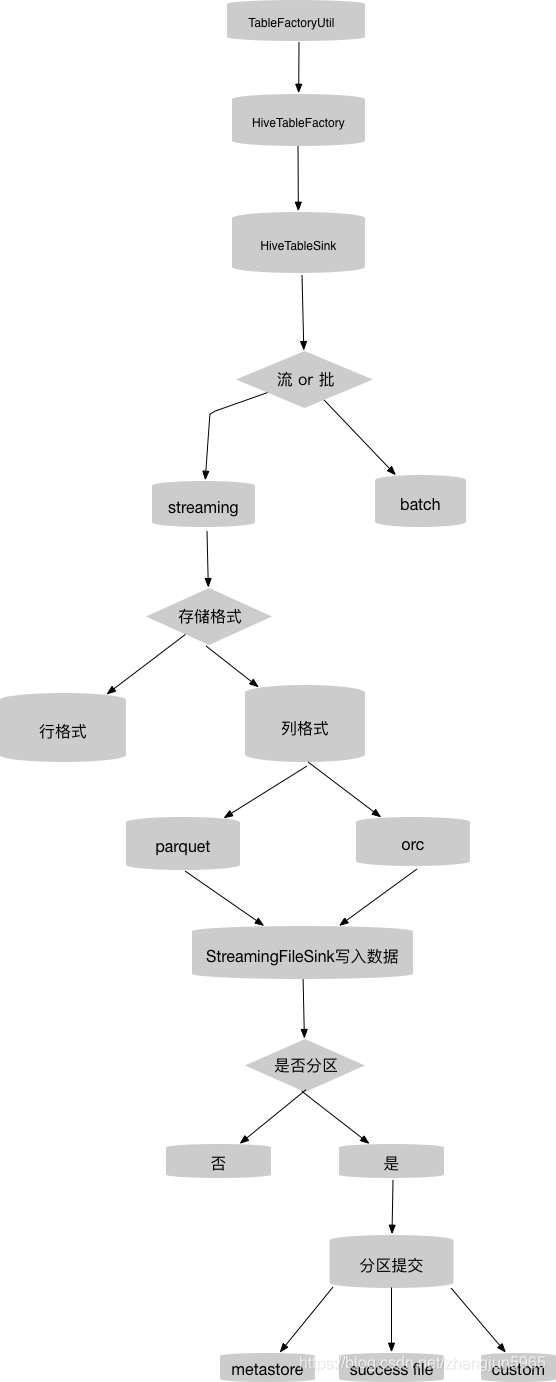
我画了一个简单的流程图,大家可以先看下,接下来我们带着这些疑问,一步步的从源码里探索这些功能是如何实现的。
数据流处理
我们这次主要是分析flink如何将类似kafka的流式数据写入到hive表,我们先来一段简单的代码:
//构造hive catalogString name = "myhive";String defaultDatabase = "default";String hiveConfDir = "/Users/user/work/hive/conf"; // a local pathString version = "3.1.2";HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);tEnv.registerCatalog("myhive", hive);tEnv.useCatalog("myhive");tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);tEnv.useDatabase("db1");tEnv.createTemporaryView("kafka_source_table", dataStream);String insertSql = "insert into hive.db1.fs_table SELECT userId, amount, " +" DATE_FORMAT(ts, 'yyyy-MM-dd'), DATE_FORMAT(ts, 'HH'), DATE_FORMAT(ts, 'mm') FROM kafka_source_table";tEnv.executeSql(insertSql);
系统在启动的时候会首先解析sql,获取相应的属性,然后会通过java的SPI机制加载TableFactory的所有子类,包含TableSourceFactory和TableSinkFactory,之后,会根据从sql中解析的属性循环判断使用哪个工厂类,具体的操作是在TableFactoryUtil类的方法里面实现的。
比如对于上面的sql,解析之后,发现是要写入一个表名为hive.db1.fs_table的hive sink。所以系统在调用TableFactoryUtil#findAndCreateTableSink(TableSinkFactory.Context context)方法以后,得到了TableSinkFactory的子类HiveTableFactory,然后调用相应的createTableSink方法来创建相应的sink,也就是HiveTableSink。
我们来简单看下HiveTableSink的变量和结构。
/*** Table sink to write to Hive tables.*/
public class HiveTableSink implements AppendStreamTableSink, PartitionableTableSink, OverwritableTableSink {private static final Logger LOG = LoggerFactory.getLogger(HiveTableSink.class);private final boolean userMrWriter;//是否有界,用来区分是批处理还是流处理private final boolean isBounded;private final JobConf jobConf;private final CatalogTable catalogTable;private final ObjectIdentifier identifier;private final TableSchema tableSchema;private final String hiveVersion;private final HiveShim hiveShim;private LinkedHashMap<String, String> staticPartitionSpec = new LinkedHashMap<>();private boolean overwrite = false;private boolean dynamicGrouping = false;
我们看到它实现了AppendStreamTableSink, PartitionableTableSink, OverwritableTableSink三个接口,这三个接口决定了hive sink实现的功能,数据只能是append模式的,数据是可分区的、并且数据是可以被覆盖写的。
类里面的这些变量,看名字就大概知道是什么意思了,就不做解释了,讲一下HiveShim,我们在构造方法里看到hiveShim是和hive 的版本有关的,所以其实这个类我们可以理解为对不同hive版本操作的一层封装。
hiveShim = HiveShimLoader.loadHiveShim(hiveVersion);
tablesink处理数据流的方法是consumeDataStream,我们来重点分析下。
hive基本信息获取
首先会通过hive的配置连接到hive的元数据库,得到hive表的基本信息。
String[] partitionColumns = getPartitionKeys().toArray(new String[0]);String dbName = identifier.getDatabaseName();String tableName = identifier.getObjectName();try (HiveMetastoreClientWrapper client = HiveMetastoreClientFactory.create(new HiveConf(jobConf, HiveConf.class), hiveVersion)) {Table table = client.getTable(dbName, tableName);StorageDescriptor sd = table.getSd();
- 获取到hive的表的信息,也就是Table对象。
- 获取表的一些存储信息,StorageDescriptor对象,这里面包含了hive表的存储路径、存储格式等等。
流、批判断
接下来判断写入hive是批处理还是流处理
if (isBounded){...... //batch } else {......//streaming}
由于这次我们主要分析flink的流处理,所以对于batch就暂且跳过,进入else,也就是流处理。
在这里,定义了一些基本的配置:
- 桶分配器TableBucketAssigner,简单来说就是如何确定数据的分区,比如按时间,还是按照字段的值等等。
- 滚动策略,如何生成下一个文件,按照时间,还是文件的大小等等。
- 构造bulkFactory,目前只有parquet和orc的列存储格式使用bulkFactory
//桶分配器TableBucketAssigner assigner = new TableBucketAssigner(partComputer);//滚动策略TableRollingPolicy rollingPolicy = new TableRollingPolicy(true,conf.get(SINK_ROLLING_POLICY_FILE_SIZE).getBytes(),conf.get(SINK_ROLLING_POLICY_ROLLOVER_INTERVAL).toMillis());//构造bulkFactoryOptional<BulkWriter.Factory<RowData>> bulkFactory = createBulkWriterFactory(partitionColumns, sd);
createBulkWriterFactory方法主要是用于构造写入列存储格式的工厂类,目前只支持parquet和orc格式,首先定义用于构造工厂类的一些参数,比如字段的类型,名称等等,之后根据不同类型构造不同的工厂类。如果是parquet格式,最终构造的是ParquetWriterFactory工厂类,如果是orc格式,根据hive的版本不同,分别构造出OrcBulkWriterFactory或者是OrcNoHiveBulkWriterFactory。
写入格式判断
如果是使用MR的writer或者是行格式,进入if逻辑,使用HadoopPathBasedBulkFormatBuilder,如果是列存储格式,进入else逻辑,使用StreamingFileSink来写入数据.
if (userMrWriter || !bulkFactory.isPresent()) {HiveBulkWriterFactory hadoopBulkFactory = new HiveBulkWriterFactory(recordWriterFactory);builder = new HadoopPathBasedBulkFormatBuilder<>(new Path(sd.getLocation()), hadoopBulkFactory, jobConf, assigner).withRollingPolicy(rollingPolicy).withOutputFileConfig(outputFileConfig);LOG.info("Hive streaming sink: Use MapReduce RecordWriter writer.");} else {builder = StreamingFileSink.forBulkFormat(new org.apache.flink.core.fs.Path(sd.getLocation()),new FileSystemTableSink.ProjectionBulkFactory(bulkFactory.get(), partComputer)).withBucketAssigner(assigner).withRollingPolicy(rollingPolicy).withOutputFileConfig(outputFileConfig);LOG.info("Hive streaming sink: Use native parquet&orc writer.");}
在大数据处理中,列式存储比行存储有着更好的查询效率,所以我们这次以列式存储为主,聊聊StreamingFileSink是如何写入列式数据的。通过代码我们看到在构造buckets builder的时候,使用了前面刚生成的bucket assigner、输出的配置、以及文件滚动的策略。
构造分区提交算子
在HiveTableSink#consumeDataStream方法的最后,进入了FileSystemTableSink#createStreamingSink方法,这个方法主要做了两件事情,一个是创建了用于流写入的算子StreamingFileWriter,另一个是当存在分区列并且在配置文件配置了分区文件提交策略的时候,构造了一个用于提交分区文件的算子StreamingFileCommitter,这个算子固定的只有一个并发度。
StreamingFileWriter fileWriter = new StreamingFileWriter(rollingCheckInterval,bucketsBuilder);DataStream<CommitMessage> writerStream = inputStream.transform(StreamingFileWriter.class.getSimpleName(),TypeExtractor.createTypeInfo(CommitMessage.class),fileWriter).setParallelism(inputStream.getParallelism());DataStream<?> returnStream = writerStream;// save committer when we don't need it.if (partitionKeys.size() > 0 && conf.contains(SINK_PARTITION_COMMIT_POLICY_KIND)) {StreamingFileCommitter committer = new StreamingFileCommitter(path, tableIdentifier, partitionKeys, msFactory, fsFactory, conf);returnStream = writerStream.transform(StreamingFileCommitter.class.getSimpleName(), Types.VOID, committer).setParallelism(1).setMaxParallelism(1);}
我们看到在代码中,inputStream经过transform方法,最终将要提交的数据转换成CommitMessage格式,然后发送给它的下游StreamingFileCommitter算子,也就是说StreamingFileCommitter将会接收StreamingFileWriter中收集的数据。
详解StreamingFileWriter
这个StreamingFileWriter我们可以理解为一个算子级别的写入文件的sink,它对StreamingFileSink进行了一些包装,然后添加了一些其他操作,比如提交分区信息等等。我们简单看下这个类的结构,并简单聊聊各个方法的作用。
public class StreamingFileWriter extends AbstractStreamOperator<CommitMessage>implements OneInputStreamOperator<RowData, CommitMessage>, BoundedOneInput{@Overridepublic void initializeState(StateInitializationContext context) throws Exception {......................... } @Overridepublic void snapshotState(StateSnapshotContext context) throws Exception {......................... }@Overridepublic void processWatermark(Watermark mark) throws Exception {......................... }@Overridepublic void processElement(StreamRecord<RowData> element) throws Exception {......................... }/*** Commit up to this checkpoint id, also send inactive partitions to downstream for committing.*/@Overridepublic void notifyCheckpointComplete(long checkpointId) throws Exception {......................... }@Overridepublic void endInput() throws Exception {......................... }@Overridepublic void dispose() throws Exception {......................... } }- initializeState :初始化状态的方法,在这里构造了要写入文件的buckets,以及具体写入文件的StreamingFileSinkHelper等等。
- snapshotState:这个方法主要是进行每次checkpoint的时候调用。
- processWatermark这个方法通过名字就能看出来,是处理水印的,比如往下游发送水印等等。
- processElement:处理元素最核心的方法,每来一条数据,都会进入这个方法进行处理。
- notifyCheckpointComplete,每次checkpoint完成的时候调用该方法。在这里,收集了一些要提交的分区的信息,用于分区提交。
- endInput:不再有更多的数据进来,也就是输入结束的时候调用。
- dispose:算子的生命周期结束的时候调用。
简述StreamingFileSink
StreamingFileSink我们来简单的描述下,通过名字我们就能看出来,这是一个用于将流式数据写入文件系统的sink,它集成了checkpoint提供exactly once语义。
在StreamingFileSink里有一个bucket的概念,我们可以理解为数据写入的目录,每个bucket下可以写入多个文件。它提供了一个BucketAssigner的概念用于生成bucket,进来的每一个数据在写入的时候都会判断下要写入哪个bucket,默认的实现是DateTimeBucketAssigner,每小时生成一个bucket。
它根据不同的写入格式分别使用StreamingFileSink#forRowFormat或者StreamingFileSink#forBulkFormat来进行相应的处理。
此外,该sink还提供了一个RollingPolicy用于决定数据的滚动策略,比如文件到达多大或者经过多久就关闭当前文件,开启下一个新文件。
具体的写入ORC格式的数据,可以参考下这个文章:
flink 1.11 流式数据ORC格式写入file ,由于我们这次主要是讲整体写入hive的流程,这个sink就不做太具体的讲解了。
分区信息提交
StreamingFileWriter#notifyCheckpointComplete 调用commitUpToCheckpoint在checkpoint完成的时候触发了分区的提交操作。
private void commitUpToCheckpoint(long checkpointId) throws Exception {helper.commitUpToCheckpoint(checkpointId);CommitMessage message = new CommitMessage(checkpointId,getRuntimeContext().getIndexOfThisSubtask(),getRuntimeContext().getNumberOfParallelSubtasks(),new ArrayList<>(inactivePartitions));output.collect(new StreamRecord<>(message));inactivePartitions.clear();}
在这里,我们看到,使用inactivePartitions构造了CommitMessage对象,然后使用output.collect将这个提交数据收集起来,也就是上文我们提到的这里收集到的这个数据将会发给StreamingFileCommitter算子来处理。
而inactivePartitions里面的数据是什么时候添加进来的呢,也就是什么时候才会生成要提交的分区呢?我们跟踪一下代码,发现是给写入文件的buckets添加了一个监听器,在bucket成为非活跃状态之后,触发监听器,然后将对应的bucket id 添加到inactivePartitions集合。
@Overridepublic void initializeState(StateInitializationContext context) throws Exception {..........................buckets.setBucketLifeCycleListener(new BucketLifeCycleListener<RowData, String>() {@Overridepublic void bucketCreated(Bucket<RowData, String> bucket) {}@Overridepublic void bucketInactive(Bucket<RowData, String> bucket) {inactivePartitions.add(bucket.getBucketId());}});}
而通知bucket变为非活动状态又是什么情况会触发呢?从代码注释我们看到,到目前为止该bucket已接收的所有记录都已提交后,则该bucket将变为非活动状态。
提交分区算子
这是一个单并行度的算子,用于提交写入文件系统的分区信息。具体的处理步骤如下:
- 从上游收集要提交的分区信息
- 判断某一个checkpoint下,所有的子任务是否都已经接收了分区的数据
- 获取分区提交触发器。(目前支持partition-time和process-time)
- 使用分区提交策略去依次提交分区信息(可以配置多个分区策略)
这里我们主要讲一下 StreamingFileCommitter#processElement方法是如何对进来的每个提交数据进行处理的。
@Overridepublic void processElement(StreamRecord<CommitMessage> element) throws Exception {CommitMessage message = element.getValue();for (String partition : message.partitions) {trigger.addPartition(partition);}if (taskTracker == null) {taskTracker = new TaskTracker(message.numberOfTasks);}boolean needCommit = taskTracker.add(message.checkpointId, message.taskId);if (needCommit) {commitPartitions(message.checkpointId);}}我们看到,从上游接收到CommitMessage元素,然后从里面得到要提交的分区,添加到PartitionCommitTrigger里(变量trigger),然后通过taskTracker来判断一下,该checkpoint每个子任务是否已经接收到了分区数据,最后通过commitPartitions方法来提交分区信息。
进入commitPartitions方法,看看是如何提交分区的。
private void commitPartitions(long checkpointId) throws Exception {List<String> partitions = checkpointId == Long.MAX_VALUE ?trigger.endInput() :trigger.committablePartitions(checkpointId);if (partitions.isEmpty()) {return;}try (TableMetaStoreFactory.TableMetaStore metaStore = metaStoreFactory.createTableMetaStore()) {for (String partition : partitions) {LinkedHashMap<String, String> partSpec = extractPartitionSpecFromPath(new Path(partition));LOG.info("Partition {} of table {} is ready to be committed", partSpec, tableIdentifier);Path path = new Path(locationPath, generatePartitionPath(partSpec));PartitionCommitPolicy.Context context = new PolicyContext(new ArrayList<>(partSpec.values()), path);for (PartitionCommitPolicy policy : policies) {if (policy instanceof MetastoreCommitPolicy) {((MetastoreCommitPolicy) policy).setMetastore(metaStore);}policy.commit(context);}}}}
从trigger中获取该checkpoint下的所有要提交的分区,放到一个List集合partitions中,在提交的分区不为空的情况下,循环遍历要配置的分区提交策略PartitionCommitPolicy,然后提交分区。
分区提交触发器
目前系统提供了两种分区提交的触发器,PartitionTimeCommitTigger和ProcTimeCommitTigger,分别用于处理什么时候提交分区。
- ProcTimeCommitTigger 主要依赖于分区的创建时间和delay,当处理时间大于’partition creation time’ + 'delay’的时候,将提交这个分区
- PartitionTimeCommitTigger 依赖于水印,当水印的值大于 partition-time + delay的时候提交这个分区。
分区提交策略
目前系统提供了一个接口PartitionCommitPolicy,用于提交分区的信息,目前系统提供了以下几种方案,
- 一种是METASTORE,主要是用于提交hive的分区,比如创建hive分区等等
- 还有一种是SUCCESS_FILE,也就是往对应的分区目录下写一个success文件。
- 此外,系统还提供了一个对外的自定义实现,用于用户自定义分区提交,比如提交分区之后合并小文件等等。自定义提交策略的时候,需要实现PartitionCommitPolicy接口,并将提交策略置为custom。
我在网上也看到过一些实现该接口用于合并小文件的示例,但是我个人觉得其实有点不太完美,因为这个合并小文件可能会涉及很多的问题:
- 合并的时候如何保证事务,保证合并的同时如何有读操作不会发生脏读
- 事务的一致性,如果合并出错了怎么回滚
- 合并小文件的性能是否跟得上,目前flink只提供了一个单并行度的提交算子。
- 如何多并发合并写入
所以暂时我也没有想到一个完美的方案用于flink来合并小文件。
总结
通过上述的描述,我们简单聊了一下flink是如何将流式数据写入hive的,但是可能每个人在做的过程中还是会遇到各种各种的环境问题导致的写入失败,比如window和linux系统的差异,hdfs版本的差异,系统时区的配置等等,在遇到一些个性化的问题之后,就可能需要大家去针对自己的问题去个性化的debug了。
更多干货信息,欢迎关注我的公众号【大数据技术与应用实战】

如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 刘汝佳(一)——紫书1~2章
目录第一章1.三位数反转(反转后首位是0也要输出)2.变量交换3.鸡兔同笼(注意无解的条件)(已知鸡和兔的总数量为n,总腿数为m。)4.输入3个整数,从小到大排序后输出5.3n+1问题第二章1.阶乘之和2.例题2-5 数据统计3.例题2-6:数据统计II4.习题2-2:韩信点兵(hanxin)5.习题…...
2024/5/7 14:40:55 - 从PXE启动安装ESXi系统
环境介绍: 192.168.3.152 物理服务器一台 一个ESXi的安装ISO镜像 关闭firewalld和selinux 安装必要软件: 在W上安装 yum -y install dhcp xinet tftp-server httpd syslinux yum -y install system-config-kickstart (用于全自动安装) 配置http配置 安装好httpd服务后,到…...
2024/5/7 14:40:23 - Quickprop介绍:一个加速梯度下降的学习方法
由于80年代/ 90年代的普通反向传播算法收敛缓慢,Scott Fahlman发明了一种名为Quickprop[1]的学习算法,它大致基于牛顿法。他的简单想法在诸如“N-M-N编码器”任务这样的问题域中优于反向传播(有各种调整),即训练一个具有N个输入、M个隐藏单位和N个输出的de-/ Encoder网络。 …...
2024/5/7 14:41:20 - i.MX6ULL终结者搭建交叉编译环境
我们在第三章讲解了如何在Linux下进行C程序开发,我们使用的gcc编译器进行代码的编译,编译完,直接在X86架构下的PC下运行的。我们学习的i.MX6 ULL是arm架构的,所以我们需要使用支持arm的编译器并且该编译器在X86架构下运行,这个编译器我们通常称为交叉编译器。 arm交叉编译…...
2024/5/7 18:07:59 - 开发环境和生产环境
111...
2024/5/7 14:18:35 - master -> master (non-fast-forward)
master -> master (non-fast-forward)报错 一般git出现这个错误时,一般是出现在新创建的仓库,并且是第一次进行提交时 我的理解是因为你在gitee或者github创建仓库时使用了初始化文件,导致git认为你的仓库是就仓库,而你的仓库是新的仓库。 或者你在创建新仓库时忘记执行…...
2024/5/6 17:02:40 - shell 脚本定时切割Nginx 日志
需求nginx的日志文件路径每天0点对nginx 的access与error日志进行切割以前一天的日期为命名 准备touch /usr/local/soft/nginxLog/nginx_script.sh #创建文件chmod +x 文件名 #给文件可执行权限编辑脚本vi /usr/local/soft/nginxLog/nginx_script.sh脚本内容: #!/bin/…...
2024/4/29 17:33:28 - spring-boot-devtools导致服务器不断重启
昨天上线的时候遇到的一个问题,开始焦头烂额,因为时间紧迫,后来终于发现原来是个比较低级的错误,项目引用的spring-boot-devtools的包后,如果打包项目内的文件有变化,devtools会扫描包内文件,发现变化后进行热部署,而我们项目中恰好有个上传文件的模块,上传的时候会写…...
2024/5/8 1:14:34 - MSP430低功耗模式摘抄(未完)
抄自http://www.elecfans.com/emb/581249.html单片机中,功耗最低的单片机要MSP430单片机,这是做手持设备最优选择,MSP430中,用到5种低功耗,LPM0,LPM1,LPM2,LPM3,LPM4,这五种低功耗各种解释如下 :CPU的活动状态称为AM(ACTVE MODE)模式。其中AM耗电最大,LPM4耗电最…...
2024/5/8 1:46:51 - Linux 免密码在服务器之间随意切换登录
执行命令创建密钥:ssh-keygen -t rsa执行该命令之后一直按entry 即可生成秘钥文件[root@vincent1 ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): …...
2024/5/1 19:05:10 - (转)理解JS执行上下文
执行上下文(Execution Context): 函数执行前进行的准备工作(也称执行上下文环境)运行JavaScript代码时,当代码执行进入一个环境时,就会为该环境创建一个执行上下文,它会在你运行代码前做一些准备工作,如确定作用域,创建局部变量对象等。具体做了什么先按下不表,先来看下…...
2024/5/7 13:20:26 - SpringMVC处理异常的三种方式
SpringMVC处理异常的三种方式 使用 @ ExceptionHandler 注解 实现 HandlerExceptionResolver 接口 使用 @controlleradvice 注解使用 @ ExceptionHandler 注解 使用该注解有一个不好的地方就是:进行异常处理的方法必须与出错的方法在同一个Controller里面,可以看到,这种方式…...
2024/5/1 17:02:41 - shell脚本编写 crontab 定时器介绍
crond服务介绍以守护进程方式在无需人工干预的情况下来处理着一系列作业和指令的服务crond服务的启动、停止命令启动 systemctl start crond.service查看状态: systemctl status crond.service停止 systemctl stop crond.service重新启动 systemctl restart crond.servicecron…...
2024/5/7 18:35:50 - 寄存器reg &= ~1 位与操作的问题
在网上偶尔看到一个关于寄存器某位清零的操作,有人指出如题写法并不健壮,此博客记录。 问题的关键在于 ~1 的值,假设值 1 占8位(由编译器决定), 二进制表示为 0000 0001 那么~1的值为 1111 1110 此时与一个寄存器 & ,确实可以将第 0 位清零,且确保[7:1]位不变。 但…...
2024/5/7 15:22:06 - centos 7 搭建 nfs 文件共享服务器
NFS介绍NFS(Network File System)即网络文件系统,它允许网络中服务器之间通过TCP/IP网络共享资源,NFS的一个 最大优点就是可以节省本地存储空间NFS体系至少有两个主要部分一台NFS服务器和若干台客户机环境准备服务器A:192.168.10.100 #作服务端服务器B:192.168.10.101 …...
2024/5/7 18:53:15 - Java的方法中参数为可变形参
标题:Java的方法中参数为可变形参 一、注意 1.可变形参要放在参数列表的最后一个位置【否则javac分不清对应形参中的实参】```java //eg:这样写会编译错误,【去掉注释】 //public void test(String...params,String str){}public static void main(String[] args){//this.tes…...
2024/4/29 22:27:06 - 思泰CANopen IO模块基本通信测试(二)
2. CANopen通信链路搭建2.1 物理连接部分PEAK system CAN总线监视软件,PCAN-view;PEAK system USB--CAN转换器DB9母口总线;SYSTEC(思泰)CANopen IO-X1 16DI / 8DO模块;24V直流电源。 2.2 PCAN-view软件部分PCAN-view是由PEAK提供的CAN总线驱动程序,可以模拟CANopen主站进…...
2024/5/2 0:36:50 - 上亿流量架构-2
...
2024/5/2 3:51:14 - leetcode【每日一题】机器人能否返回原点 Java
想法 在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。 移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返…...
2024/5/2 16:31:49 - Anaconda3 windows下 使用 anaconda search -t conda <包名> 不显示 或 找不到anaconda的问题
解决方法:使用anaconda powershell prompt,进入路径 <anaconda根目录>\Scripts,就可以使用anaconda search了出现问题的情况使用base环境是可以使用ananconda search的,但是切换了环境就出问题了。之前试过在系统环境变量里加入 <anaconda根目录>\Scripts,虽然…...
2024/5/6 19:25:37
最新文章
- 【数据结构】链表经典OJ题目练习(2)
面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode) 思路1:先计算出链表的长度,在将链表中的值存在数组中,在返回第k个节点。 思路2:利用快慢指针,先让快指针走k步,在让快慢指针分…...
2024/5/8 2:44:20 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/7 10:36:02 - 【C++】类和对象①(什么是面向对象 | 类的定义 | 类的访问限定符及封装 | 类的作用域和实例化 | 类对象的存储方式 | this指针)
目录 前言 什么是面向对象? 类的定义 类的访问限定符及封装 访问限定符 封装 类的作用域 类的实例化 类对象的存储方式 this指针 结语 前言 最早的C版本(C with classes)中,最先加上的就是类的机制,它构成…...
2024/5/8 0:14:18 - Golang Gin框架
1、这篇文章我们简要讨论一些Gin框架 主要是给大家一个基本概念 1、Gin主要是分为路由和中间件部分。 Gin底层使用的是net/http的逻辑,net/http主要是说,当来一个网络请求时,go func开启另一个协程去处理后续(类似epoll)。 然后主协程持续…...
2024/5/5 8:48:03 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/7 19:05:20 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/7 22:31:36 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/8 1:37:40 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/7 14:19:30 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/8 1:37:39 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/7 16:57:02 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/7 14:58:59 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/7 1:54:46 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/7 21:15:55 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/8 1:37:35 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/7 16:05:05 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/7 16:04:58 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/8 1:37:32 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/7 16:05:05 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/8 1:37:31 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/8 1:37:31 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/7 11:08:22 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/7 7:26:29 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/8 1:37:29 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/7 17:09:45 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57