深度学习简明教程系列 —— 基础知识(合集)
本教程是深度学习简明教程系列的第一部分,旨在提取最精炼且必备的深度学习知识点,供读者快速学习及本人查阅复习所用,大多内容是本人结合个人理解补充细节整合而成,参考链接放在文章最后。
目录
第一章 模型评估
1.1 基础概念
1.2 P-R曲线
1.3 ROC曲线和AUC
1.4 目标检测评价
1.5 语义分割评价
1.6 相关面试题
第二章 卷积
2.1 理解卷积
2.2 理解感受野
2.3 特殊卷积结构
2.4 卷积的可视化
2.5 总结
2.6 相关面试题
第三章 激活函数
3.1 常用激活函数
3.2 相关面试题
第四章 损失函数
4.1 概览
4.2 分类任务损失函数
4.3 回归任务损失函数
4.4 相关面试题
第五章 优化算法
5.1 概述
5.2 存在的挑战
5.3 梯度下降优化方法
5.4 梯度优化额外的策略
5.5 相关面试题
第六章 反向传播算法(BP算法)
6.1 神经网络
6.2 正向传播
6.3 反向传播
6.4 总结
6.5 相关面试题
第七章 梯度消失和梯度爆炸
7.1 产生原因
7.2 解决方案
7.3 相关面试题
第八章 范数正则化
8.1 正则化概述
8.2 L0范数与L1范数
8.3 L2范数
8.4 正则化参数的选择
8.5 相关面试题
第九章 Batch Normalization
9.1 使用BN的原因
9.2 什么是BN
9.3 BN具体是怎么做的
9.4 其他Normalization方法
9.5 相关面试题
第十章 Dropout
10.1 Dropout简介
10.2 模型变化
10.3 相关面试题
第十一章 注意力机制
11.1 注意力机制分类
11.2 注意力模块
11.3 相关面试题
第一章 模型评估
1.1 基础概念
假设有个样本,其中有
个样本分类正确,则有:
准确率(Accuracy):
错误率(Error):
这两个指标虽然常用,但无法满足所有任务需求,我们还会用查准率(Precision)、召回率(Recall)、误检率(Noise Factor)、漏检率(Prob of Miss)来衡量分类效果。在二分类问题中,可以根据样本真实类别和预测类别的组合划分为:
真阳(TP):预测为真,实际为真;
假阳(FP):预测为真,实际为假;
真阴(TN):预测为假,实际为假;
假阴(FN):预测为假,实际为真。
因此有:
查准率(Precision):
,意即预测的正例有几个是对的;
召回率(Recall):
,意即真正的正例预测了几个;
误检率(Noise Factor):
,意即预测的正例有几个是错的;
漏检率(Prob of Miss):
,意即漏掉几个正例没检测出来。
1.2 P-R曲线
查准率和召回率是一对矛盾的度量指标,一般呈现负相关,在很多情况下,我们可以通过绘制出学习器的P-R曲线(Precision - Recall Curve)来比较学习器的好坏。P-R图以查准率为纵轴,召回率为横轴,大致如下图所示:
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言外层的学习器性能优于内层,例如上面的A和B优于学习器C。但是A和B的性能无法直接判断,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1值:
- 平衡点(BEP)是 P = R 时的取值,如果这个值较大,则说明学习器的性能较好。
- F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。
注意:一条P-R曲线要对应一个阈值。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例,从而计算相应的精准率和召回率。
1.3 ROC曲线和AUC
1.3.1 ROC曲线
接受者操作特性曲线(Receiver Operating Characteristic Curve),简称ROC曲线,纵轴是击中率(TPR),横轴是虚警率(FPR)。
击中率,也即真正类率(True Postive Rate):TPR = TP/(TP+FN),代表分类器预测的正类中实际正例占所有正例的比例。
虚警率,也即负正类率(False Postive Rate):FPR = FP/(FP+TN),代表分类器预测的正类中实际负例占所有负例的比例。
下图为ROC曲线示意图,因现实任务中通常利用有限个测试样例来绘制ROC图,因此应为无法产生光滑曲线,如右图所示。
绘图过程:给定m个正例子,n个反例子,根据学习器预测结果进行排序,先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,再将分类阈值依次设为每个样例的预测值,即依次将每个例子划分为正例。设前一个坐标为(x,y),若当前为真正例,对应标记点为(x,y+1/m),若当前为假正例,则标记点为(x+1/n,y),然后依次连接各点。
注意:
- ROC曲线也需要相应的阈值才可以进行绘制,原理同上的P-R曲线。
- ROC曲线越左上凸越好,P-R曲线越右上凸越好。
1.3.2 AUC
AUC (Area under Curve):ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器;
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值;
- AUC = 0.5,跟随机猜测一样(例:丢硬币),模型没有预测价值。
1.4 目标检测评价
1.4.1 mAP
mAP(mean Average Precision)即各类别AP的平均值。由此我们可以知道,要计算mAP必须先绘出各类别P-R曲线,计算出AP。
1)VOC2010之前
只需要选取当Recall >= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。具体来说,计算precision时采用一种插值方法,即对于某个recall值r,precision值取所有recall>=r中的最大值(这样保证了p-r曲线是单调递减的,避免曲线出现抖动)。
2)VOC2010及其之后
需要针对每一个不同的Recall值r(包括0和1),Precision值取所有recall >= r+1中的最大值,然后计算PR曲线下面积作为AP值。
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。
1.5 语义分割评价
评价指标一般包含如下三个方面:
- 执行时间(execution time)
- 内存占用(memory footprint)
- 准确度(accuracy)
1.5.1 准确度


1.6 相关面试题
Q:
A:
第二章 卷积
2.1 理解卷积
通俗来讲,图像处理中的卷积就是通过一个模板矩阵,在图像上进行滑窗,把对应位置上的元素相乘后加起来,得到最终的结果,可以形象理解为把原图像一块区域“卷”起来融合成新图像的一个像素点,这个模板矩阵即为卷积核。
假设原图像的大小为 ,卷积核大小为
,往图像两边填充
个像素,滑窗步长为
,则经过卷积后特征图的大小为:
假设原图像通道数为C1,卷积后通道数为C2,需要训练的参数量为:
浮点数相乘计算的次数为:
2.2 理解感受野
感受野用来表示神经网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的全部信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。

由于图像是二维的,具有空间信息,因此感受野的实质其实也是一个二维区域。但业界通常将感受野定义为一个正方形区域,因此也就使用边长来描述其大小了。感受野的抽象公式如下:

其中, 为第n个卷积层的感受野,
和
分别表示第n个卷积层的kernel_size和stride。
2.3 特殊卷积结构
2.3.1 分组卷积(Group convolution)
分组卷积最早出现在AlexNet中,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最过程中把多个GPU的结果进行通道concat。通过使用分组卷积可以大大减少参数量。

2.3.2 Inception结构
传统的层叠式网络,基本上都是一个个卷积层的堆叠,每层只用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3卷积层。事实上,同一层feature map可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来(concat),得到的特征往往比使用单一卷积核的要好,谷歌的GoogleNet,或者说Inception系列的网络,就使用了多个卷积核的结构。

2.3.3 Bottleneck结构
发明GoogleNet的团队发现,如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如下图所示:

1×1卷积核也被认为是影响深远的操作,它主要用来改变通道数,降低参数量,往后大型的网络为了降低参数量都会应用上1×1卷积核。我们来做个对比计算,假设输入feature map的维度为256维,要求输出维度也是256维。有以下两种操作:

- 256维的输入直接经过一个3×3×256的卷积层,输出一个256维的feature map,那么参数量为:256×3×3×256 = 589824
- 256维的输入先经过一个1×1×64的卷积层,再经过一个3×3×64的卷积层,最后经过一个1×1×256的卷积层,输出256维,参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69632,足足把第一种操作的参数量降低到九分之一。
2.3.4 深度可分离卷积(DepthWise Convolution)
标准的卷积过程如下图所示,一个2×2的卷积核在卷积时,对应图像区域中的所有通道均被同时考虑,问题在于,为什么一定要同时考虑图像区域和通道?我们为什么不能把通道和空间区域分开考虑?

Xception网络就是基于以上的问题发明而来。我们首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道feature maps之后,这时再对这批新的通道feature maps进行标准的1×1跨通道卷积操作。这种操作被称为 “DepthWise Convolution” ,缩写“DW”,它的直接作用就在于可以大幅降低参数量。

- 直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6912
- DW操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一。
2.3.5 通道洗牌
在AlexNet的Group Convolution当中,特征的通道被平均分到不同组里面,最后再通过两个全连接层来融合特征,这样一来,就只能在最后时刻才融合不同组之间的特征,对模型的泛化性是相当不利的。为了解决这个问题,ShuffleNet在每一次层叠这种Group conv层前,都进行一次channel shuffle,shuffle过的通道被分配到不同组当中。进行完一次group conv之后,再一次channel shuffle,然后分到下一层组卷积当中,以此循环。

经过channel shuffle之后,Group conv输出的特征能考虑到更多通道,输出的特征自然代表性就更高。另外,AlexNet的分组卷积,实际上是标准卷积操作,而在ShuffleNet里面的分组卷积操作是depthwise卷积,因此结合了通道洗牌和分组depthwise卷积的ShuffleNet,能得到超少量的参数以及超越mobilenet、媲美AlexNet的准确率。
2.3.6 通道加权
无论是在Inception、DenseNet或者ShuffleNet里面,我们对所有通道产生的特征都是不分权重直接结合的,那为什么要认为所有通道的特征对模型的作用就是相等的呢? 这是一个好问题,于是,ImageNet 2017冠军SENet就出来了。

从上图可以看到,一组特征在上一层被输出,这时候分两条路线,第一条直接通过,第二条进行如下操作:
- 首先进行Squeeze操作(Global Average Pooling),把每个通道二维的特征图压缩成一个一维向量,从而得到一个特征通道向量(每个数字代表对应通道的特征);
- 然后进行Excitation操作,把这一列特征通道向量输入两个全连接层和sigmoid,建模出特征通道间的相关性,得到的输出其实就是每个通道对应的权重;
- 最后,把这些权重通过Scale乘法通道加权到原来的特征上(第一条路),这样就完成了特征通道的权重分配。
2.3.7 空洞卷积(Dilated Convolution)
标准的3×3卷积核只能看到对应区域3×3的大小,但是为了能让卷积核看到更大的范围,dilated conv使其成为了可能。dilated conv原论文中的结构如图所示:

上图b可以理解为卷积核大小依然是3×3,但是每个卷积点之间有1个空洞(dilated rate = 1),也就是在绿色7×7区域里面,只有9个红色点位置作了卷积处理,其余点权重为0。这样即使卷积核大小不变,但它看到的区域变得更大了。
2.3.8 可变形卷积(Deformable Convolution)
传统的卷积核一般都是长方形或正方形,但MSRA提出了一个相当反直觉的见解,认为卷积核的形状可以是变化的,变形的卷积核能让它只看感兴趣的图像区域 ,这样识别出来的特征更佳。

要做到这个操作,可以直接在原来的卷积核的基础上再加一层卷积核,这层卷积核学习的是下一层卷积核的位置偏移量(offset),实际增加的计算量是相当少的,但能实现可变形卷积核,识别特征的效果更好。

在实际操作时,并不是真正地把卷积核进行扩展,而是对卷积前图片的像素重新整合,变相地实现卷积核的扩张,具体来说可变性卷积的流程为:
- 原始图片大小为b*h*w*c,记为U,经过一个普通卷积,卷积填充为same,对应的输出结果为(b*h*w*2*k*k),记为V,输出的结果是指原图片batch中卷积核在每个像素上的偏移量(k*k的卷积核具有x偏移与y偏移,因此通道数为2*k*k);
- 将U中图片的像素索引值与V相加,得到偏移后的position(即在原始图片U中的坐标值),需要将position值限定为图片大小以内。但position只是一个坐标值,而且还是float类型的,我们需要这些float类型的坐标值获取像素。
- 例如取一个坐标值(a,b),将其转换为四个整数,floor(a), ceil(a), floor(b), ceil(b),将这四个整数进行整合,得到四对坐标(floor(a),floor(b)), ((floor(a),ceil(b)), ((ceil(a),floor(b)), ((ceil(a),ceil(b))。这四对坐标每个坐标都对应U中的一个像素值,而我们需要得到(a,b)的像素值,这里采用双线性差值的方式计算(一方面得到的像素准确,另一方面可以进行反向传播)。
- 在得到position的所有像素后,即得到了一个新图片M,将这个新图片M作为输入数据输入到别的层中,如普通卷积。
2.3.9 上采样、上池化和转置卷积
1)上采样(UnSampling)
UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容以插值方式来扩充Feature Map,属于人工特征工程,没有要学习的参数。常用上采样方法有:最近邻插值(Nearest neighbor interpolation)、双线性插值(Bi-Linear interpolation)、双立方插值(Bi-Cubic interpolation)

2)上池化(UnPooling)
在Maxpooling的时候保留最大值的位置信息,之后在UnPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。

3)转置卷积(Deconvolution)
反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核(参数与之前正向卷积过程中使用到的卷积核参数一致),再进行卷积。具体步骤如下:
- 设卷积核大小为k*k,输入为方形矩阵;
- 对输入进行四边补零,单边补零的数量为k-1;
- 将卷积核旋转180°,在新的输入上进行直接卷积。


下图展示一个反卷积的工作过程,乍看一下好像反卷积和卷积的工作过程差不多,主要的区别在于反卷积输出图片的尺寸会大于输入图片的尺寸,通过增加padding来实现这一操作。

下图中的反卷积的stride为2,通过间隔插入padding来实现的。同样,可以根据反卷积的o、s、k、p参数来计算反卷积的输出i,也就是卷积的输入。公式如下:i=(o−1)∗s+k−2∗p,其实就是根据上式推导出来的。

2.4 卷积的可视化
2.4.1 可视化方案
总体思路就是将某一层的feature maps 经过相反的结构。如经过max pooling层那么就在对称位置记住所取位置后,unpooling到相应位置,如经过relu那么在对称位置在经过一次relu,如经过conv那么在对称位置使用相同的Filter的转置进行deconv。
- 反池化:我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。
- 反激活:反激活过程和激活过程没有什么差别,都是直接采用relu函数。
- 反卷积:对于反卷积过程,采用卷积过程转置后的卷积核(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),反卷积实际上应该叫卷积转置。
最后可视化网络如下图所示:

网络的整个过程,从右边开始:输入图片-->卷积-->Relu-->最大池化-->得到结果特征图-->反池化-->Relu-->反卷积。
举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
2.4.2 理解可视化


从上图可看出:
- layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;
- layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;
- layer 4学习到的则是比较有区别性的特征,比如狗头等物体的局部;
- layer 5学习到的则是物体整体的信息,具有辨别性关键特征。
总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。
2.4.3 特征学习过程

在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图,可以看出前几层(lower)收敛较快,后几层收敛较慢。

上图是对应着图像平移、缩放、旋转给featuremap带来的变化,可以看出第一层中对于图像变化非常敏感,第7层就接近于线性变化,最后的输变化就相对较小了。
2.5 总结
总的来说,卷积核的发展有如下几个方面和特点:
卷积核方面:
- 大卷积核用多个小卷积核代替;
- 单一尺寸卷积核用多尺寸卷积核代替;
- 固定形状卷积核趋于使用可变形卷积核;
- 使用1×1卷积核(bottleneck结构)。
卷积层通道方面:
- 标准卷积用depthwise卷积代替;
- 使用分组卷积;
- 分组卷积前使用通道洗牌;
- 通道加权计算。
卷积层连接方面:
- 使用skip connection,让模型更深;
- Densely connection,使每一层都融合上其它层的特征输出(DenseNet)
2.6 相关面试题
Q:
A:
第三章 激活函数
定义:在神经网络中,神经元节点的激活函数定义了对神经元输出的映射,即神经元的输出经过激活函数处理后再作为输出。
作用:神经网络中激活函数的主要作用是提供网络的非线性建模能力,如不特别说明,激活函数一般而言是非线性函数。
3.1 常用激活函数
3.1.1 Sigmoid函数
Sigmoid 是使用范围最广的一类激活函数,具有指数函数形状 。定义为:

可见,sigmoid在定义域内处处可导,两侧导数逐渐趋近于0,也称为软饱和激活函数;与软饱和相对的是硬饱和激活函数,即:f'(x)=0,当 |x| > c,其中 c 为常数。
缺点:1)梯度消失;2)输出均值始终大于0,收敛慢。
3.1.2 Tanh函数

可见,tanh(x)=2sigmoid(2x)-1,也具有软饱和性。tanh 网络的收敛速度要比sigmoid快。因为 tanh 的输出均值比 sigmoid 更接近 0,SGD会更接近 natural gradient(一种二次优化技术),从而降低所需的迭代次数。
缺点:1)梯度消失。
3.1.3 ReLU函数
与传统的sigmoid激活函数相比,ReLU能够有效缓解梯度消失问题,从而直接以监督的方式训练深度神经网络,无需依赖无监督的逐层预训练,这也是2012年深度卷积神经网络在ILSVRC竞赛中取得里程碑式突破的重要原因之一。

可见,ReLU 在x<0 时硬饱和;由于 x>0时导数为 1,所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。但其仍存在几个问题:
- 随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新,这种现象被称为“神经元死亡”。
- ReLU还经常被“诟病”的一个问题是输出存在偏移现象,即输出均值恒大于零,偏移现象和神经元死亡会共同影响网络的收敛性。
3.1.4 PReLU函数
PReLU是ReLU 和 LReLU的改进版本,具有非饱和性:

与Leaky ReLU相比,PReLU中的负半轴斜率a可学习而非固定,虽然PReLU 引入了额外的参数,但基本不需要担心过拟合。与ReLU相比,PReLU收敛速度更快,因为PReLU的输出更接近0均值。
3.1.5 RReLU函数
数学形式与PReLU类似,但RReLU是一种非确定性激活函数,其参数是随机的。这种随机性类似于一种噪声,能够在一定程度上起到正则效果。
3.1.6 Maxout函数
Maxout是ReLU的推广,其可以看做是在深度学习网络中加入一层激活函数层,包含一个参数n。这一层相比ReLU,sigmoid等,其特殊之处在于增加了n个神经元,然后输出激活值最大的值。
![]()
Maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
3.1.7 ELU函数
ELU融合了sigmoid和ReLU,具有左侧软饱性。其正式定义为:

右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。
3.2 相关面试题
Q:
A:
第四章 损失函数
4.1 概览

4.2 分类任务损失函数
4.2.1 二分类交叉熵损失(sigmoid_cross_entropy)
其中, 是样本标签(0/1),
是模型预测样本为正例的概率。
4.2.2 二分类平衡交叉熵损失(balanced_sigmoid_cross_entropy)
其中, 是样本标签(0/1),
是模型预测样本为正例的概率,
是一个超参数。
4.2.3 多分类交叉熵损失(softmax_cross_entropy)
其中, 是类别数,
是样本标签的onehot表示,
中每个元素
表示样本属于第
类的概率。
4.2.4 Focal Loss
Focal Loss主要用于解决多分类任务中样本不平衡的现象,可以获得更好的分类效果:
其中, 用于平衡不同类别样本的重要性,
表示给第
类样本分配的权重,数量少的类别分配更大的权重,数量多的减小权重;
用于控制预测结果的loss大小,概率大说明是容易分类的样本,loss就会减小,概率小说明是困难、错分的样本,loss就会增大,通过这一参数可以使模型更关注于困难样本。论文中α=0.25,γ=2效果最好。
4.2.5 Dice Loss
dice系数源于二分类,本质上是衡量两个样本的重叠部分,二分类时使用该loss,本质就是不断学习,使得交比并越来越大。
![]()
最终Dice Loss = 1 - DSC
4.2.6 合页损失(hinge loss)
svm中使用的损失函数,由于合页损失优化到满足小于一定gap距离就会停止优化,而交叉熵损失却是一直在优化,所以,通常情况下,交叉熵损失效果优于合页损失。
- 当
大于等于+1或者小于等于-1时,都是分类器确定的分类结果,此时的损失函数loss为0;
- 当预测值
时,分类器对分类结果不确定,loss不为0。显然,当
时,loss达到最大值。
4.2.7 KL散度
KL散度( Kullback–Leibler divergence),也叫相对熵,是描述两个概率分布P和Q差异的一种方法。

从上述公式中我们可以看出,KL散度 = 交叉熵 - 熵。
4.3 回归任务损失函数
4.3.1 均方误差(Mean Square Error, MSE)
MSE表示了预测值与目标值之间差值的平方和然后求平均。

L2损失表示了预测值与目标值之间差值的平方和然后开更方,L2表示的是欧几里得距离。

MSE和L2的曲线走势都一样。区别在于一个是求的平均,一个是求的开方。
4.3.2 平均绝对误差(Mean Absolute Error, MAE)
MAE表示了预测值与目标值之间差值的绝对值然后求平均。

L1表示了预测值与目标值之间差值的绝对值,L1也叫做曼哈顿距离。

MAE和L1的区别在于一个求了均值,一个没有求,两者的曲线走势也是完全一致的。
总结:MAE/L1 Loss 对于局外点更鲁棒,但它的导数不连续使得寻找最优解的过程低效;MSE/L2 Loss 对于局外点敏感,但在优化过程中更为稳定和准确。

4.3.3 Huber Loss和Smooth L1 Loss
Huber loss具备了MAE和MSE各自的优点,当δ趋向于0时它就退化成了MAE,而当δ趋向于无穷时则退化为了MSE。

Smooth L1 loss具备了L1 loss和L2 loss各自的优点,本质就是L1和L2的组合。

Huber loss和Smooth L1 loss具有相同的曲线走势,当Huber loss中的δ等于1时,Huber loss等价于Smooth L1 loss。

对于Huber损失来说,δ的选择十分重要,它决定了模型处理局外点的行为。当残差大于δ时使用L1损失,很小时则使用更为合适的L2损失来进行优化。Huber损失函数克服了MAE和MSE的缺点,不仅可以保持损失函数具有连续的导数,同时可以利用MSE梯度随误差减小的特性来得到更精确的最小值,也对局外点具有更好的鲁棒性。但Huber损失函数的良好表现得益于精心训练的超参数δ。
4.3.4 对数双曲余弦(Log Cosh Loss)


其优点在于对于很小的误差来说log(cosh(x))与(x2)/2很相近,而对于很大的误差则与abs(x)-log2很相近。这意味着log-cosh损失函数可以在拥有MSE优点的同时也不会受到局外点的太多影响。它拥有Huber的所有优点,并且在每一个点都是二次可导的。
4.4 相关面试题
Q:
A:
第五章 优化算法
5.1 概述
机器学习的本质是建立优化模型,通过优化方法,不断迭代参数向量,找到使目标函数最优的参数向量,最终建立模型。通常用到的优化方法:梯度下降方法、牛顿法、拟牛顿法等。这些优化方法的本质就是在更新参数。
5.1.1 梯度下降法
梯度下降是一种最小化目标函数 J(θ) 的方法,其中 是模型参数,而最小化目标函数是通过在其关于 θ 的 梯度
的相反方向更新 θ 来实现的;而学习率(learning rate)则决定了在到达(局部)最小值的过程中每一步走多长。
梯度下降目前主要有三种方式:
- 批量梯度下降(BGD,每次进行一次参数更新需要在整个训练集上计算梯度);
- 随机梯度下降(SGD,每次只使用一个随机的样本进行参数更新);
- 小批量梯度下降(MBGD,每次从训练集中取出 n 个样本作为一个 mini-batch,以此来进行一次参数更新)。根据数据量的大小,我们在参数更新的准确性和执行更新所需时间之间做了一个权衡。
Q:MBGD中batch size的选择
A:
1)为什么 batch size 会影响训练结果
2)在合理范围内,增大 Batch_Size 有何好处
内存利用率提高了,大矩阵乘法的并行化效率提高;
跑完一个epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快;
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
3)盲目增大 Batch_Size 有何坏处
内存利用率提高了,但是内存容量可能撑不住了;
跑完一次 epoch(全数据集)所需的迭代次数减少,但所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢;
Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
运行结果如上图所示,其中绝对时间做了标准化处理。运行结果与上文分析相印证:




5.1.2 牛顿法
首先得明确,牛顿法是为了求解函数值为零的时候变量的取值问题的,具体地,当要求解 f(θ)=0 时,如果 f 可导,那么可以通过迭代公式

来迭代求得最小值,可以通过一个动图来说明这个过程。
在机器学习中,我们应用牛顿法求解目标函数的一阶导数为0时的参数,进而求出目标函数最小值时的参数。那么迭代公式变为:
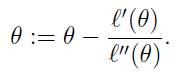
当θ是向量时,牛顿法可以使用下面式子表示:
其中H叫做海森矩阵,其实就是目标函数对参数向量 θ 的二阶导数。下面给出牛顿法的完整算法描述:
- 给定参数初值
和精度阈值
,并令t = 0;
- 计算目标函数对于参数向量的一阶导数
和二阶导数 H;
- 若
,则停止迭代,否则确定搜索方向
;
- 计算新的参数
;
- 令
,转至第二步。
通过比较牛顿法和梯度下降法的迭代公式,可以发现两者及其相似,海森矩阵的逆就好比梯度下降法的学习率参数alpha。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;同时,海森矩阵的的逆在迭代中不断减小,起到逐渐缩小步长的效果。
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
5.1.3 拟牛顿法
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。


这样的迭代与牛顿法类似,区别就在于用近似矩阵 代替真实的Hesse矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵
的更新。具体来说,求近似矩阵的方法有:
1)DFP算法

2)BFGS算法

3)L-BFGS算法

5.2 存在的挑战
在深度学习中,我们很少去用牛顿法,而是采用梯度下降法,但是标准的 MBGD 并不保证好的收敛,也提出了以下需要被解决的问题:
- 选择一个好的学习率是非常困难的。太小的学习率导致收敛非常缓慢,而太大的学习率则会阻碍收敛,导致损失函数在最优点附近震荡甚至发散。
- 学习率不能做到自适应数据的特点。学习率的减小规则和阈值也是需要在训练前定义好的,另外,相同的学习率被应用到所有参数更新中。如果我们的数据比较稀疏,特征有非常多不同的频率,那么此时我们可能并不想要以相同的程度更新他们,反而是对更少出现的特征给予更大的更新。
- 对于神经网络来说,另一个最小化高度非凸误差函数的关键挑战是避免陷入他们大量的次局部最优点(suboptimal)。传统的梯度下降方法难以逃脱鞍点,因为其各个维度上梯度都趋近于0。
5.3 梯度下降优化方法
5.3.1 动量法(Momentum)
SGD 在遇到沟壑时会比较困难(即在一个维度上比另一个维度更陡峭的曲面),这些曲面通常包围着局部最优点。在这些场景中,SGD 震荡且缓慢的沿着沟壑的下坡方向朝着局部最优点前进,如下图所示:

动量(Momentum)是一种在相关方向加速 SGD 的方法,并且能够减少震荡。

原理:它通过在当前更新向量(梯度方向)中加入了先前一步的状态,对于那些当前的梯度方向与上一次梯度方向相同的向量维度进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的向量维度进行削减,即这些方向上减慢了。因此可以获得更快的收敛速度与减少振荡。
其具体计算公式如下

其中,动量项 γ 通常设置为 0.9 或者相似的值。
5.3.2 Nesterov Accelerated Gradient(NAG)
Momentum中,θ 每次都会多走 的量;在NAG中,我们直接让 θ 先走到
之后的地方,然后再根据那里的梯度前进一步,这种预期更新防止我们下降得太快,也带来了更高的响应速度,这在一些任务中非常有效的提升了性能。

- 动量法首先计算当前梯度(图 4 中的小蓝色向量),然后在更新累积梯度方向上大幅度的跳跃(图 4 中的大蓝色向量);
- NAG 首先在先前的累积梯度方向上进行大幅度的跳跃(图 4 中的棕色向量),评估这个梯度并做一下修正(图 4 中的红色向量),这就构成一次完整的 NAG 更新(图 4 中的绿色向量)。

NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。
通过上面的两种方法,可以做到每次学习过程中能够根据损失函数的斜率做到自适应更新来加速SGD的收敛。下一步便需要对每个参数根据参数的重要性进行各自自适应更新。
5.3.3 Adagrad
Adagrad也是一种基于梯度的优化算法,它能够对不同时刻的参数 θ 自适应不同的学习速率,对稀疏特征,得到大的学习更新,对非稀疏特征,得到较小的学习更新,因此该优化算法适合处理稀疏特征数据。其计算公式如下:

其中 是一个对角矩阵,对角元素
是参数
从开始到时间点 t 为止的梯度平方和;ϵ 是一个平滑项,用于防止分母为 0 ,通常为 10−8 左右;
为目标函数关于参数 θ 在 t 时刻的梯度。
Adagrad的优缺点
优势:在于它能够为每个参数自适应不同的学习速率,而一般的人工都是设定为0.01。
缺点:在于需要计算参数梯度序列平方和,并且学习速率趋势是不断衰减最终达到一个非常小的值。
5.3.4 RMSProp
RMSProp是 Adagrad 的扩展,旨在帮助缓解后者学习率单调下降的问题。与 Adagrad 累积过去所有梯度的平方和不同,RMSProp主要有两个方面的改进:
- Adadelta 限制在过去某个大小为w的窗口内的梯度(相当于滑动平均值);
- 存储先前 w 个梯度的平方效率不高,Adadelta 的梯度平方和被递归的定义为过去所有梯度平方的滑动平均值。
在 t 时刻的滑动平均值 仅仅取决于先前的平均值和当前的梯度:
![]()
先前我们推导过的 Adagrad 的参数更新向量,我们现在用过去梯度平方和的滑动平均 来代替对角矩阵
:
![]()
由于分母只是一个梯度的均方根误差(Root Mean Squared,RMS),我们可以用缩写来代替:
![]()
这种方法即RMSProp,解决了对历史梯度一直累加而导致学习率一直下降的问题,但仍需要自己选择初始的学习率。

Hinton 建议将 γ 设为 0.9 ,默认学习率 η 设为 0.001 。
5.3.5 Adadelta
为了解决参数更新中单位不匹配的问题,并自适应的选择一个学习率,Adadelta定义了另一个关于参数 的滑动平均:
![]()
那么参数的均方根误差即为:
![]()
由于 未知,采用上一步
来代替学习率
,最终得到Adadelta的更新规则:

5.3.6 Adam
Adaptive Moment Estimation是另一种为每个参数计算自适应学习率的方法。除了像 Adadelta 和 RMSprop 一样存储历史梯度平方的滑动平均值 外,Adam 也存储历史梯度的滑动平均值
,类似于动量:

与
分别是梯度的带权平均和带权有偏方差,初始为0向量,Adam的作者发现他们倾向于0向量,特别是在衰减因子β1,β2接近于1时。为了改进这个问题,对
与
进行偏差修正:

最终Adam的更新公式为:
![]()
作者建议 β1 的默认值为 0.9 , β2 的默认值为 0.999 ,ϵ 的默认值为 10−8 。实践证明 Adam 在训练中非常有效,而且对比其他自适应学习率算法也有优势。
5.4 梯度优化额外的策略
介绍一些可以和前面讨论的算法一起使用的策略,用以进一步提升 SGD 的性能。
1)Shuffling and Curriculum Learning
- 为了使得学习过程更加无偏,应该在每次迭代中随机打乱训练集中的样本。
- 另一方面,在很多情况下,我们是逐步解决问题的,而将训练集按照某个有意义的顺序排列会提高模型的性能和SGD的收敛性,如何将训练集建立一个有意义的排列被称为Curriculum Learning。
2)Batch normalization
- Batch normalization在每次mini-batch反向传播之后重新对参数进行0均值、1方差的标准化过程。这样可以使用更大的学习速率,以及花费更少的精力在参数初始化点上。Batch normalization充当着正则化、减少甚至消除掉Dropout的必要性。
3)Early stopping
- 在验证集上如果连续的多次迭代过程中损失函数不再显著地降低,那么应该提前结束训练。
4)Gradient noise

5.5 相关面试题
Q:
A:
第六章 反向传播算法(BP算法)
基本思想: BP算法就是目前使用较为广泛的一种参数学习算法。其主要由由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。
6.1 神经网络
假设我们有一个神经网络,第 层的输入定义为
,经过激活函数后的输出定义为
,激活函数定义为
,本层的权重定义为
,大致如下图所示:
通常来说,这些参数的形式如下:
其中, 表示第
层神经元的个数,例如上图中的例子,
就是一个三行两列的矩阵。
6.2 正向传播
正向传播就是将样本输入到神经网络,从而获得输出值的过程,其中涉及到了两个重要的公式:
利用这两个式子,我们只需要通过权重矩阵和偏置值,就可以一路计算得到神经网络每一层的输入 和输出
,并记录下来。
6.3 反向传播
BP算法是一种更新权重的方法,我们知道每一层都有一个权重 ,在BP算法中,我们通过梯度下降法来更新每层的权重:
其中,L为模型的损失函数,它是关于最后一层输出 的一个函数,
是学习率。
该方法的关键在于如何求出损失函数关于神经网络某一隐层权重权值矩阵的偏导。
在正向传播中我们可以很容易看出,神经网络最后一层的输出 ,其实是关于某个隐层输入
的函数,综上我们可以得到损失函数L是关于某个隐层权重矩阵的函数:
为此,通过链式法则我们可以得到:
此时,我们定义左边这一项为误差项 ,则有:
其中,我们可以看到
是我们在正向传播中记录下来的输出值,所以问题就转化为我们如何求得每一层的误差项
了。
在正向传播 中,我们有两个重要公式,通过他们结合链式法则,我们可以将 进一步拆解:
这个公式告诉我们,只要知道了 层的误差项和权重矩阵,我们就可以求得
层的误差项。实际应用到BP算法中,步骤如下:
- 先求最后一层的误差项;
- 根据该层误差项求得获得损失函数对于该层权重矩阵的偏导;
- 利用梯度下降法计算权重矩阵的更新值;
- 往前递推前一层的误差项,转至第2步,直至更新完所有层的权重。
假设损失函数为MSE,最后一层的误差项是可以直接根据损失函数 L 计算得到的:
6.4 总结
我们只解决了给一组数据如何更新权重,它叫做标准误差传播算法。它对于每个训练样本都会改变一次所有的权值。但是它的更新非常非常频繁,而且容易受到干扰。我们希望误差累积到一定程度以后再一次性更新,因此需要用累积误差逆传播算法。因此,我们每次更新应该是要对n个训练集累积下来的误差求平均,再用来更新权重矩阵。
综上所述,BP算法的整体流程如下:
- 初始化权重矩阵和偏置;
- 将训练集输入神经网络正向传播,记录下每层的输入输出等中间变量;
- 利用损失函数,先求最后一层的误差项;
- 根据该层误差项求得获得损失函数对于该层权重矩阵的偏导;
- 利用梯度下降法计算权重矩阵的更新值;
- 往前递推前一层的误差项,跳至第4步,直至更新完所有层的权重。
具体实际的例子,可以参考:https://www.jianshu.com/p/708e11654913
6.5 相关面试题
Q:
A:
第七章 梯度消失和梯度爆炸
7.1 产生原因
7.1.1 梯度消失
以下图的反向传播为例,

假设每一层只有一个神经元且对于每一层输出:
![]()
其中σ为sigmoid函数,xi为输入值,zi为净激活值。我们可以推导出:

而sigmoid的导数σ'(x)如下图

从上图我们可以看到,σ'(x)的最大值为0.25,而且我们初始化的权重绝对值通常都小于1。于是,当神经网络的层数越多,在链式法则中连乘激活函数的导数越多次,求导的结果就越小,因而会出现梯度消失的现象。
7.1.2 梯度爆炸
若我们初始化的权重w很大,大到乘以激活函数的导数都大于1,即|σ'(z)w|>1,那么连乘后,可能会导致求导的结果很大,形成梯度爆炸。
7.2 解决方案
梯度消失和梯度爆炸本质上是一样的,都是因为网络层数太深而引发的梯度反向传播中的连乘效应。
7.2.1 梯度消失解决方案
换用Relu等其他激活函数;
采用BN,将输入值的分布落入激活函数中对输入比较敏感的区域(即梯度大的区域),从而避免梯度消失;
采用ResNet残差结构;
采用LSTM结构;
7.2.2 梯度爆炸解决方案
采用好的参数初始化方式,如He初始化;
预训练(pre-training)和微调(fine tuning):预训练就是把一个已经训练好的模型参数,应用到另一个任务上作为初始参数的过程;微调就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程;
梯度截断:设值一个剪切阈值,如果更新梯度时,梯度超过了这个阈值,那么就将其强制限制在这个范围之内,以此防止梯度爆炸;
采用权重正则化:正则化主要是通过对网络权重做正则来限制过拟合,但是根据正则项在损失函数中的形式可以看出,如果发生梯度爆炸,那么权值的范数(正则项)就会变的非常大,反过来,通过限制正则化项的大小,也可以在一定程度上限制梯度爆炸的发生。
7.3 相关面试题
Q:
A:
第八章 范数正则化
监督机器学习中训练模型时,需要保证模型“简单”的基础上最小化训练误差,这样得到的参数才具有好的泛化性能(也就是测试误差也小),最小化误差是为了让我们的模型拟合训练数据,而模型“简单”就是通过正则化来实现的,可以防止我们的模型过分拟合训练数据。
8.1 正则化概述
正则化的使用可以约束我们的模型的特性,能将人对这个模型的先验知识融入到模型的学习当中,强行地让学习到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。 一般来说,监督学习可以看做最小化下面的目标函数:
![]()
正则化函数 Ω(w) 有很多种选择,一般是模型复杂度的单调递增函数,模型越复杂,正则项值就越大。不同的选择对参数 w 的约束不同,取得的效果也不同,我们在论文中常见的都聚集在:零范数、一范数、二范数、迹范数、Frobenius范数和核范数等等。
8.2 L0范数与L1范数
L0范数和L1范数可以实现参数的稀疏化,L1因具有比L0更好的优化求解特性而被广泛应用。
- L0范数是指向量中非0的元素的个数。如果我们用L0范数来正则化一个参数矩阵W的话,就是希望W的大部分元素都是0,即是让参数矩阵W是稀疏的。
- L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)。
Q:为什么L1范数会使权值稀疏?
A:假设有如下带L1正则项的损失函数:
我们在使用梯度下降法求解参数最优解时,就是不断在参数空间中寻找最优点,如果我们在原始损失函数
后添加L1正则化项,相当于对
下面我们举一个例子来直观说明:我们考虑二维的情况,即只有两个权值w1和w2 ,此时L1=∣w1∣+∣w2∣。我们将求解
图中彩色线是

Q:为什么要稀疏?让参数稀疏有什么好处呢?
A:
1)特征选择(Feature Selection)
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,
的大部分特征和最终的输出
相关性很低,在最小化目标函数的时候考虑
2)可解释性(Interpretability)
另一个青睐于稀疏的理由是,由于我们只选择出少量特征,模型就会变得“简单”,因此我们就能更容易的去分析、解释一个模型。例如说患某种病的概率是y,我们收集到了1000中可能影响患病概率的因素,通过学习我们得到的权重矩阵W里只有很少的非零元素,假设只有5个非零的

,我们就有理由相信这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个
8.3 L2范数
L2范数是向量各元素的平方和然后求平方根。
在损失函数中加入L2正则项,训练时会有选择的让某些与模型输出相关性低的特征权值变得很小,趋近于0。
Q:为什么w越小,模型越简单?
A:可以假设一个线性回归方程,如果某个特征的参数很大,这个特征稍微变动一点点,就会对输出造成很大影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,也就是说模型的『抗扰动能力强』。
因此,拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型,一般认为这样参数值小的模型比较简单,能适应不同的数据集,在一定程度上避免了过拟合现象。
8.4 正则化参数的选择
1)L1正则化参数
通常越大的λ可以让代价函数在参数为0时取到最小值。

2)L2正则化参数
λ越大, 衰减得越快。另一个理解可以参考下图,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。

8.5 相关面试题
Q:
A:
第九章 Batch Normalization
9.1 使用BN的原因
首先我们来回顾一下MBGD的过程:假设训练数据集合T包含 N 个样本,而每个Mini-Batch的Batch Size为 b ,于是整个训练数据可被分成 N/b 个Mini-Batch。在模型通过SGD进行训练时,一般跑完一个Mini-Batch的实例,叫做完成训练的一步(step),跑完N/b步则整个训练数据完成一轮训练,则称为完成一个Epoch。完成一个Epoch训练过程后,对训练数据做随机Shuffle打乱训练数据顺序,重复上述步骤,然后开始下一个Epoch的训练,对模型完整充分的训练由多轮Epoch构成。

由上述过程可以看出,对于Mini-Batch SGD训练方法来说,Mini-Batch内的每个实例需要走一遍当前的网络,产生当前参数下神经网络的预测值,并根据预测值计算损失,然后反向传播更新权重参数。这种时候,通常会出现一个叫Covariance Shift的问题:
- 在输入层上,如果一批样本的分布与另一批样本的分布显著不同:[0,1] vs [10,100],对于一个浅层模型而言,训练第一批样本时,模型可能在描绘函数A,训练第二批样本时,模型发现自己在描绘函数B,完全不同于A。这样就是推翻自己重复劳动,训练低效。
- 输入层的这种情况,对于其他层而言,也是一样无法逃避。对于中间某个隐层的某些神经元,它们的输出值可能会远大于同层其他神经元,导致这些神经元的分布与其他神经元大幅偏离,就会出现本层的Covariance Shift的问题,这样子训练就会很低效。
总结:对于神经网络某一层的某些神经元,如果它们的激活值分布与同层其他神经元大幅偏离,就会出现Covariance Shift的问题,导致训练效率低下,而解决方案就是统一每一层激活值的分布。
9.2 什么是BN
规范化(Normalization)是一种对数值的特殊函数变换方法,也就是会在原始数值x外套一层起规范化作用的函数,转换后的数值满足一定的分布特性,即:
![]()
因为神经网络里主要有两类实体:神经元或者连接神经元的带权边,所以深度学习中的Normalization可以分为两大类:
- 对神经元激活值/净激活值进行Normalization操作,如BatchNorm/LayerNorm/InstanceNorm/GroupNorm等;
- 对神经元带权边进行Normalization操作,如Weight Norm等;

不论哪种Normalization方法,其规范化目标都是一样的,就是将其激活值规整为均值为0,方差为1的正态分布。具体到Batch Normalization,它的整个规范化过程可以分为两步:
1)将激活值规范到均值为0,方差为1的正态分布范围内。
![]()
其中, 为某个神经元原始激活值,
为规范后的值,μ是神经元集合S中包含的m个神经元激活值的均值,即:
![]()
为根据均值和集合S中神经元各自激活值求出的激活值标准差:
![]()
其中, ε是为了增加训练稳定性而加入的小的常量数据。
2)经过第一步的Normalization操作后,会导致新的分布丧失从前层传递过来的信息,且无法有效利用激活函数的非线性功能;因此,第二步中加入了缩放因子 γ 和平移因子 β,每个神经元在训练过程中会自动学习这两个调节因子,以自行决定是否需要对新分布做一定程度的缩放和平移(如果让γ=σ、β=μ,则其可以取消Normalization)。
![]()
这一步的核心思想就是让神经网络自己学习找到一个比较好平衡点,既能享受非线性较强的表达能力,又避免激活值的分布出现Covariance Shift,导致网络收敛速度太慢。
BN的效果:
- 可以加快模型收敛速度,不用再依赖精细的参数初始化过程,还可以调大学习率等各种方便;
- 用多个样本间计算统计量(均值、方差),引入了随机噪声,能够对模型参数起到正则化的作用,有利于增强模型泛化能力。
BN的缺点:
- 如果Batch Size太小,就得不到有效得统计量,也就是说噪音太大,那么BN效果会明显下降;
- 对于像素级图片生成任务来说,BN效果不佳;
- RNN等动态网络使用BN效果不佳且使用起来不方便;
- 训练时和推理时统计量不一致:对于BN来说,采用Mini-Batch内实例来计算统计量,在训练时没有问题,但在推理时由于是单实例的,所以就无法获得BN计算所需的均值和方差。一般解决方法是采用训练时刻记录的各个Mini-Batch的统计量的数学期望,以此来推算全局的均值和方差,在线推理时采用这样推导出的统计量。虽说实际使用并没大问题,但是确实存在训练和推理时刻统计量计算方法不一致的问题。
9.3 BN具体是怎么做的
目前各类Normalizaiton方法大同小异,最主要的区别在于神经元集合S的范围怎么定,不同的方法采用了不同的神经元集合定义方法(用于计算均值和方差)。
9.3.1 MLP中的BN
假设在训练时某个batch包含n个样本,对于前向神经网络来说,这n个样本分别通过同一个神经元k的时候会产生n个激活值,使用BN时就是对这n个同一个神经元被不同样本激发的激活值进行规范化。

9.3.2 CNN中的BN
对于CNN中某个卷积层对应输出特征图的第k个通道来说,假设某个Batch包含n个样本,那么每个样本在这个通道k都会产生一个二维激活平面,也就是说Batch中n个样本分别通过同一个卷积核的输出通道k的时候产生了n个激活平面。假设激活平面为 ,那么n个样本总共包含
个激活值,使用BN就是对这
个激活值进行规范化。

9.4 其他Normalization方法
BN要求计算统计量的时候必须在同一个Mini-Batch内的实例之间进行统计,因此形成了Batch内实例之间的相互依赖和影响的关系。如何从根本上解决这些问题?一个自然的想法是:把对Batch的依赖去掉,转换统计集合范围。在统计均值方差的时候,不依赖Batch内数据,只用当前处理的单个训练数据来获得均值方差的统计量,这样因为不再依赖Batch内其它训练数据,那么就不存在因为Batch约束导致的问题。在BN后的几乎所有改进模型都是在这个指导思想下进行的。
9.4.1 Layer Normalization
为了能够在只有当前一个训练实例的情形下,也能找到一个合理的统计范围,一个最直接的想法是:MLP的同一隐层自己包含了若干神经元;同理,CNN中同一个卷积层包含k个输出通道,每个通道包含m*n个神经元,整个通道包含了k*m*n个神经元;类似的,RNN的每个时间步的隐层也包含了若干神经元。那么我们完全可以直接用同层隐层神经元的响应值作为集合S的范围来求均值和方差,这就是Layer Normalization的基本思想。下图分示了MLP、CNN和RNN的Layer Normalization的集合S计算范围,因为很直观,所以这里不展开详述。



但Layer Normalization目前看好像也只适合应用在RNN场景下,在CNN等环境下效果是不如BatchNorm或者GroupNorm等模型的。
9.4.2 Instance Normalization
一个样本在经过某个卷积层后得到了 的输出特征图,Instance Normalization就是对其中的每个通道k上
个激活值都单独进行规范化。也正是因此,这种方法只能在CNN中使用。

Instance Normalization对于一些图片生成类的任务比如图片风格转换来说效果是明显优于BN的,但在很多其它图像类任务比如分类等场景效果不如BN。
9.4.3 Group Normalization
从上面的Layer Normalization和Instance Normalization可以看出,这是两种极端情况,Layer Normalization是将同层所有神经元作为统计范围,而Instance Normalization则是CNN中将同一卷积层中每个卷积核对应的输出通道单独作为自己的统计范围。那么,有没有介于两者之间的统计范围呢?
通道分组是CNN常用的模型优化技巧,所以自然而然会想到对CNN中某一层卷积层的输出或者输入通道进行分组,在分组范围内进行统计,这就是Group Normalization的核心思想。

Group Normalization在要求Batch Size比较小的场景下或者物体检测/视频分类等应用场景下效果是优于BN的。
9.5 相关面试题
Q:
A:
第十章 Dropout
10.1 Dropout简介
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。因此每一次都是在训练一个不同的网络,消除减弱了神经元节点间的联合适应性,增强了泛化能力,所以对过拟合有抑制作用。
10.2 模型变化
为了达到ensemble的特性,有了dropout后,神经网络的训练和预测就会发生一些变化。
10.2.1 训练层面
无可避免的,训练网络的每个单元要添加一道概率流程。

对应的公式变化如下如下:
- 没有dropout的神经网络

- 有dropout的神经网络

10.2.2 预测层面
预测的时候,不需要舍弃神经元。

其他Drop技术:
Dropout:完全随机扔
SpatialDropout:按channel随机扔
Stochastic Depth:按res block随机扔
DropBlock:每个feature map上按spatial块(n*n的方块)随机扔
Cutout:在训练时把输入图像按spatial块随机扔
DropConnect:将与神经元相连的输入权值以一定概率置0
10.3 相关面试题
Q:
A:
第十一章 注意力机制
概念:注意力机制是用来模拟人类对环境的生理感知机制而提出的,它是一种方法论,没有严格的数学定义。比如,传统的局部图像特征提取、显著性检测、滑动窗口方法等都可以看作一种注意力机制。在神经网络中,注意力机制通常就是一个额外的神经网络模块,能够硬性选择输入的某些部分,或者柔性地给输入的不同部分分配不通的权值。
作用:
- 结构化的选取输入的子集,从而降低数据的维度,减少计算负担。
- 注意力机制能够帮助模型选择更好的中间特征,从而提高输出的质量。
11.1 注意力机制分类
注意力机制可以分为四类:
- 基于输入项的柔性注意力(Item-wise Soft Attention)
- 基于输入项的硬性注意力(Item-wise Hard Attention)
- 基于位置的柔性注意力(Location-wise Soft Attention)
- 基于位置的硬性注意力(Location-wise Hard Attention)

11.1.1 基于项的注意力机制
1)输入
对于基于项的注意力和基于位置的注意力,它们的输入形式是不同的。
- 基于项的注意力的输入需要是包含明确项的序列,或者需要额外的预处理步骤来生成包含明确项的序列(项可以是一个向量、矩阵,甚至一个特征图);
- 基于位置的注意力则是针对输入为一个单独的特征图设计的,所有的目标可以通过位置指定。
2)输出
基于项的注意力在项的层面操作。原始输入经过神经网络处理后(如RNN或CNN),形成了一个每一项具有一个单独编码的序列。
- 基于项的柔性注意力为每一项计算一个权重,然后对所有项进行线性加权合并。合并后的编码就是注意力机制操作后的特征,用于做预测;
- 基于项的硬性注意力的不同在于它会做出硬性的选择,而不是线性加权。具体就是根据注意力的权重随机地选取若干(通常是一个)编码作为最终的特征。
11.1.2 基于位置的注意力机制
基于位置的注意力直接在一个单独的特征图上进行操作。
- 基于位置的硬性注意力从输入的特征图中离散地选取一个子区域,作为最终的特征,选取的位置是由注意力模块计算出来的;
- 基于位置的柔性注意力则对整个特征图做一个变换,使得感兴趣的部分能够突出出来(加权)。
11.2 注意力模块
注意力机制通常由一个连接在原神经网络之后的额外的神经网络实现,整个模型仍然是端对端的,因此注意力模块能够和原模型一起同步训练。对于柔性注意力,注意力模块对其输入是可微的,所以整个模型仍可用梯度方法来优化。而硬性注意力机制要做出硬性的决定,离散地选择其输入的一部分,这样整个系统对于输入不再是可微的。所以强化学习中的一些技术被用来优化包含硬性注意力的模型(强化学习的机制是通过收益函数来激励)。

下面我们通过几个例子直观了解注意力模块在神经网络中的应用:
1)Squeeze-and-Excitation Networks
SENet中提出显示的建模特征通道之间的相互依赖关系,这其实就是通道维度的一种注意力机制,体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。


通过上图我们可以看到,SENet就是将某一层特征图作一次Squeeze操作,通过对各个通道进行全局平均池化,将一个channel上整个空间的特征编码为一个全局特征;随后为了抓取各个通道之间的关系,采用两个全连接层进行非线性关系学习,其中,第一个全连接层用来降维,第二个全连接层恢复维度,并采用Sigmoid将输出的Channel Attention Featuremap的值限定在0-1之间,作为各个通道的注意力权重;最后,通过将权重和原始特征图的各个通道进行相乘,获得包含了通道重要性信息的新特征图。
2)CBAM: Convolutional Block Attention Module
CBAM是一种结合了空间(spatial)和通道(channel)的注意力机制模块,相比于senet只关注通道的注意力机制可以取得更好的效果。其具体模块示意图如下:

其中主要包括两个模块:Channel Attention Module 和 Spatial Attention Module,下面分别来介绍一下。
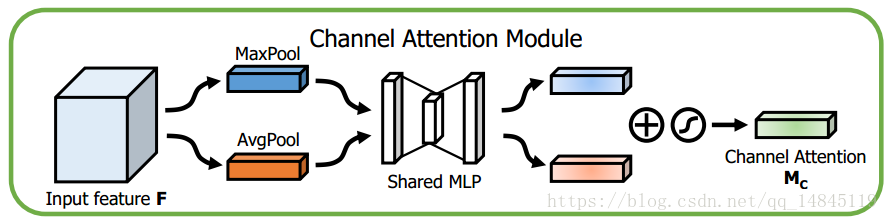
Channel Attention Module
CAM其实和SENet中的通道注意力模块类似,CBAM将输入的featuremap,分别经过基于特征平面的global max pooling 和global average pooling;然后分别连接MLP,将MLP输出的两个对应特征进行elementwise加和操作,再经过sigmoid激活操作,生成最终的channel attention featuremap;最后,将该channel attention featuremap和input featuremap做elementwise乘法操作,生成Spatial attention模块需要的输入特征图。
Spatial Attention Module
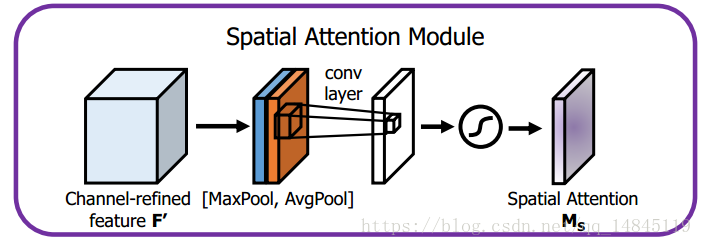
将Channel Attention Module 输出的特征图作为本模块的输入特征图。首先做一个基于通道的global max pooling 和global average pooling,然后将这2个结果基于 channel 做concat操作;随后经过一个卷积操作,降维为单个channel,再经过sigmoid生成激活值在0-1之间的Spatial Attention Feature;最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
11.3 相关面试题
Q:
A:
参考:
https://www.zhihu.com/question/53405779
https://zhuanlan.zhihu.com/p/61880018
https://www.jianshu.com/p/ac46cb7e6f87
https://zhuanlan.zhihu.com/p/28749411
https://zhuanlan.zhihu.com/p/28492837
https://zhuanlan.zhihu.com/p/22142013
https://blog.csdn.net/u014380165/article/details/76946358
https://blog.csdn.net/qq_14845119/article/details/80787753?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2
https://blog.csdn.net/u010099080/article/details/78177781
https://www.cnblogs.com/tianqizhi/p/9713951.html
https://zhuanlan.zhihu.com/p/45190898
https://blog.csdn.net/zouxy09/article/details/24971995
https://blog.csdn.net/jinping_shi/article/details/52433975
https://zhuanlan.zhihu.com/p/43200897
https://blog.csdn.net/stdcoutzyx/article/details/49022443
https://www.zhihu.com/question/32673260/answer/71137399
https://www.zhihu.com/question/61607442/answer/440401209
https://zhuanlan.zhihu.com/p/56501461
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- Jmeter(二) - 从入门到上天 - 基本测试(详解教程)
小刘,又回来啦, 继续写 Jmeter 、Jmeter 俺了解的也不是很深入,但是为了写这篇文章,我把官网啃了好久,也看了好多大佬的优秀文章,所以开始了第二篇 ,哈哈!先从界面的 语言开始吧,首先,如果大家刚下载 Jmeter ,那么你看到的肯定是 英文的 于是我们要把他设置成中文的…...
2024/5/5 6:11:52 - 守望先锋【OWL战队资料】电竞API数据接口 使用代码示例演示
守望先锋 电竞API专用电竞数据接口 分享使用代码 示例演示:【OWL战队资料】战队资料 分享使用 野子数据 http://yes-esports.com/ 电竞API数据接口调用的示例代码 具体如下: import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.annotation.JSONField; import ja…...
2024/5/4 3:29:28 - 18.分布式缓存Redis
艾编程架构课程第三十一---三十四节笔记分布式缓存Redis0. 分布式架构的分析1. 分布式缓存分析及选型1.1. 什么是NoSQL1.2.什么是Redis1.3. Redis VS Memcache VS Ehcache2. Redis安装及常用数据类型命令2.1. 单机安装2.2. Redis String命令2.3. Redis操作hash类型2.4. Redis操…...
2024/4/30 20:41:17 - 成长为架构师途中的一些思考
活到老,学到老。如何在繁忙的工作中做好技术积累,构建个人核心竞争力,相信是很多工程师同行都在思考的问题。本文试图从三个方面来解答: 第一部分阐述了一些学习的原则。任何时候,遵循一些经过检验的原则,都是影响效率的重要因素,正确的方法是成功的秘诀;提升工作和学习…...
2024/4/28 7:31:05 - JVM底层原理学习(六)之调优方法
上一篇:JVM底层原理学习(五)之调优工具 JVM调优方法 预防规范化的代码,性能更高的代码. 从点滴做起变量作用域for (int i = 0; i <10000000 ; i++) {int mid = 10000; }字符串的操作建议使用Stringbuffer 或者 StringBuilderfront =front + “hello” + “wolrd” + “a”…...
2024/4/17 16:03:20 - 自动化之追踪热点
自动化之追踪热点一、成果二、主要思路:调api 一、成果 每天定时,主要是早上8点和晚上10点自动检测桌面的待办任务然后使用图片展示,如: 1、桌面待做事项2、微博实时热点3、学术热点追踪二、主要思路:调api 方法: 这里的微博热点爬虫、以及cnki爬虫都是已经写好的程序,在…...
2024/5/5 10:34:52 - 大学一年级(行走的皮卡丘)
大学一年级(yuan) 自律 学习 坚强 ,拒绝迷茫。 --------电子信息工程学院(简称:电信学院) 文章目录大学一年级(yuan)自律 学习 坚强 ,拒绝迷茫。 --------电子信息工程学院(简称:电信学院)在广东石油化工学院的第一年2018.8月学习C语言(学习到…...
2024/4/28 13:29:26 - 11.前端:vue
艾编程架构课程第十九---二十三节笔记未完待续艾编程前端第一课:实现电商购物车01 - Vuejs介绍02 - Vuejs-快速下载和安装03 - Vuejs实操系列04 - Vuejs实操系列 - 插值表达式05- Vue基础篇 - 生命周期钩子06 - Vue内置指令 - 事件指令-v-on指令-点击事件07 - Vue内置指令 - …...
2024/4/13 10:11:29 - WAF(web应用防火墙)
一、是什么?WAF主要用于保护web服务器不受攻击,防止因受到攻击导致软件服务中断或被远程控制。(可理解为HTTP层面的IDS)二、主要功能1.web防护(事前)网络层防护:syn flood,cc攻击等 DOS攻击应用层攻击:sql注入,xss攻击,CSRF攻击,暴力破解等网页防篡改:文件监控+二…...
2024/4/11 14:22:06 - Android岗常见40道面试题,面试前必须了解的知识点!!!
Android常见原理性面试专题1. Handler机制和底层实现2.Handler、Thread和HandlerThread的差别1) Handler线程的消息通讯的桥梁,主要用来发送消息及处理消息。2) Thread普通线程,如果需要有自己的消息队列,需要调用Looper.prepare()创建Looper实例,调用loop()去循环消息。…...
2024/4/11 21:32:03 - 机器学习原理详解
我们先来说个老生常谈的情景:某天你去买芒果,小贩摊了满满一车芒果,你一个个选好,拿给小贩称重,然后论斤付钱。自然,你的目标是那些最甜最成熟的芒果,那怎么选呢?你想起来,啊外婆说过,明黄色的比淡黄色的甜。你就设了条标准:只选明黄色的芒果。于是按颜色挑好、付钱…...
2024/4/11 21:32:02 - 给你的图片带个口罩吧
文章前言 最近在学习百度的百度架构师手把手带你零基础实践深度学习课程,为期21天,该课程从基础的知识加案例代码的铺垫,以及作业打卡加实践作业的方式,还有老师的讲解,由浅到深的带你理解深度学习,总体来说还是不错的。另外paddle框架的paddlehub有一些对常用场景已经训…...
2024/4/23 2:19:05 - 店宝宝:明星直播带货,创新是第一生产力
七月中旬,在直播热仿佛褪去的下半场,明星胡海泉才第一次在抖音上试水电商直播,然而他的第一场直播,就创下了佳绩。胡海泉的第一场直播持续了5个多小时,在他的直播间里,他与母婴KOL辰辰妈、NPC主理人李晨Nic、云集创始人肖尚略、小米生态链总经理屈恒多位行业大拿侃侃而谈…...
2024/4/11 21:32:01 - VMware安装centos7以及在上面安装图形化界面
这里先就放三篇文章赶紧记录一下,免得忘记了,至于VMware安装centos7比较简单,后续再说: 第一篇:linux的命令行界面下安装图形化界面 在第一篇中我用vi指令编辑base.repo时,出现无法保存的情况,报错信息是: 有人说是:原因是权限不够,普通用户用vi 进行不了保存,需要使…...
2024/4/27 12:57:39 - SpringBoot注册Servlet、Filter、Listener
SpringBoot注册Servlet、Filter、Listener 由于SpringBoot默认是以jar包的方式启动嵌入式的Servlet容器来启动SpringBoot的web应用,没有web.xml文件. Spring Boot 提供了 ServletRegistrationBean, FilterRegistrationBean, ServletListenerRegistrationBean三个类分别用来注册…...
2024/4/19 8:41:27 - 简单工厂模式&策略模式
案例:营业员根据客户所购买商品的单价和数量,根据不同活动向客户收费正常原价收费 八折收费 满300返100简单工厂模式(Sample Factory Pattern) 简单工厂模式定义 定义一个简单工厂类,它可以根据参数的不同返回不同类的实例,被创建的实例通常都具有共同的父类 简单工厂模式结…...
2024/4/28 20:06:13 - Linux Graphics 周刊(第 2 期)
(2020.8.17 ~ 2020.8.23)DRM 1. 修复 dma-heap 导出 name 不准确的问题 dma-heap 为我们提供了一个辅助函数 heap_helper_export_dmabuf(),用于将自定义的 heap 导出为 dma-buf。但实际运行时你会发现,通过该接口导出的 dma-buf name 并不是我们期望的 heap name,而是统一的…...
2024/4/16 13:25:04 - Hadoop 系列3—— 分布式计算框架 MapReduce
一、MapReduce概述Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输…...
2024/4/11 21:31:55 - Python 第四课 运算符
1 运算符的概念 运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算。例 如:2+3,其操作数是2和3,而运算符则是“+” 2 运算符的分类 算术运算符 赋值运算符 比较运算符(关系运算符) 逻辑运算符 条件运算符(三元运算符) 2.1 算术运算符 加法运算符 表现形式…...
2024/4/11 21:31:54 - 背包系统
背包系统 需要写两个脚本 搭完UI过后Equip和Box 要分别加上脚本,脚本如下: using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI;public class HeroEquip : MonoBehaviour,IBeginDragHandler,IDragHandler,IEndDragHandler {[Header("装备类型&qu…...
2024/4/11 21:31:53
最新文章
- 【ARM Cortex-M3指南】3:Cortex-M3基础
文章目录 三、Cortex-M3基础3.1 寄存器3.1.1 通用目的寄存器 R0~R73.1.2 通用目的寄存器 R8~R123.1.3 栈指针 R133.1.4 链接寄存器 R143.1.5 程序计数器 R15 3.2 特殊寄存器3.2.1 程序状态寄存器3.2.2 PRIMASK、FAULTMASK和BASEPRI寄存器3.2.3 控制寄存器 3.3 操作模式3.4 异常…...
2024/5/5 15:50:13 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - ChatGPT 初学者指南
原文:ChatGPT for Beginners 译者:飞龙 协议:CC BY-NC-SA 4.0 介绍 如果您一直关注新闻和趋势,您可能已经在某个地方读到或听到过,Sam Altman 的生成式人工智能平台 ChatGPT 已经将人工智能推向了一个新的高度 - 许多…...
2024/5/4 11:20:55 - 深入理解springboot
第五章 访问数据库 1.配置数据源 在applicaiton.properties中 spring.datasource.urljdbc:mysql://localhost:3306/chapter5 第九章 springmvc 1.总体流程 http请求发送给控制器,控制器与业务层交互,业务层使用noSQL缓存,业务层与数据访问层…...
2024/5/5 15:07:17 - 416. 分割等和子集问题(动态规划)
题目 题解 class Solution:def canPartition(self, nums: List[int]) -> bool:# badcaseif not nums:return True# 不能被2整除if sum(nums) % 2 ! 0:return False# 状态定义:dp[i][j]表示当背包容量为j,用前i个物品是否正好可以将背包填满ÿ…...
2024/5/4 12:05:22 - 【Java】ExcelWriter自适应宽度工具类(支持中文)
工具类 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.CellType; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet;/*** Excel工具类** author xiaoming* date 2023/11/17 10:40*/ public class ExcelUti…...
2024/5/5 12:22:20 - Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
2024/5/4 14:46:16 - TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
2024/5/4 23:54:44 - VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
2024/5/5 15:25:47 - 【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...
2024/5/4 23:54:49 - 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
2024/5/4 23:54:44 - 【ES6.0】- 扩展运算符(...)
【ES6.0】- 扩展运算符... 文章目录 【ES6.0】- 扩展运算符...一、概述二、拷贝数组对象三、合并操作四、参数传递五、数组去重六、字符串转字符数组七、NodeList转数组八、解构变量九、打印日志十、总结 一、概述 **扩展运算符(...)**允许一个表达式在期望多个参数࿰…...
2024/5/4 14:46:12 - 摩根看好的前智能硬件头部品牌双11交易数据极度异常!——是模式创新还是饮鸩止渴?
文 | 螳螂观察 作者 | 李燃 双11狂欢已落下帷幕,各大品牌纷纷晒出优异的成绩单,摩根士丹利投资的智能硬件头部品牌凯迪仕也不例外。然而有爆料称,在自媒体平台发布霸榜各大榜单喜讯的凯迪仕智能锁,多个平台数据都表现出极度异常…...
2024/5/4 14:46:11 - Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...
2024/5/4 14:46:11 - 用欧拉路径判断图同构推出reverse合法性:1116T4
http://cplusoj.com/d/senior/p/SS231116D 假设我们要把 a a a 变成 b b b,我们在 a i a_i ai 和 a i 1 a_{i1} ai1 之间连边, b b b 同理,则 a a a 能变成 b b b 的充要条件是两图 A , B A,B A,B 同构。 必要性显然࿰…...
2024/5/5 2:25:33 - 【NGINX--1】基础知识
1、在 Debian/Ubuntu 上安装 NGINX 在 Debian 或 Ubuntu 机器上安装 NGINX 开源版。 更新已配置源的软件包信息,并安装一些有助于配置官方 NGINX 软件包仓库的软件包: apt-get update apt install -y curl gnupg2 ca-certificates lsb-release debian-…...
2024/5/4 21:24:42 - Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为: ... ROW FORMAT DELIMITED FIELDS TERMINATED BY \u0001 COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMI…...
2024/5/5 13:14:22 - 【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要 异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…...
2024/5/4 13:16:06 - --max-old-space-size=8192报错
vue项目运行时,如果经常运行慢,崩溃停止服务,报如下错误 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 因为在 Node 中,通过JavaScript使用内存时只能使用部分内存(64位系统&…...
2024/5/4 16:48:41 - 基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
2024/5/4 14:46:05 - JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
2024/5/5 3:37:58 - C++中只能有一个实例的单例类
C中只能有一个实例的单例类 前面讨论的 President 类很不错,但存在一个缺陷:无法禁止通过实例化多个对象来创建多名总统: President One, Two, Three; 由于复制构造函数是私有的,其中每个对象都是不可复制的,但您的目…...
2024/5/4 23:54:30 - python django 小程序图书借阅源码
开发工具: PyCharm,mysql5.7,微信开发者工具 技术说明: python django html 小程序 功能介绍: 用户端: 登录注册(含授权登录) 首页显示搜索图书,轮播图࿰…...
2024/5/4 9:07:39 - 电子学会C/C++编程等级考试2022年03月(一级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536输入 只有一行,一个双精度浮点数。输出 一行,保留8位小数的浮点数。样例输入 3.1415926535798932样例输出 3.1…...
2024/5/5 15:25:31 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57