【AI视野·今日CV 计算机视觉论文速览 第171期】Tue, 3 Dec 2019
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 3 Dec 2019
Totally 82 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚****三维点云补全模型, 提出了一种可以实现均匀、细致、完整的点云补全方法。通过由参数曲面片进行的粗粒度补全,到与输入点云进行融合的细粒度补全实现了较好的重建。(from UC San Diego Beihang University 清华)
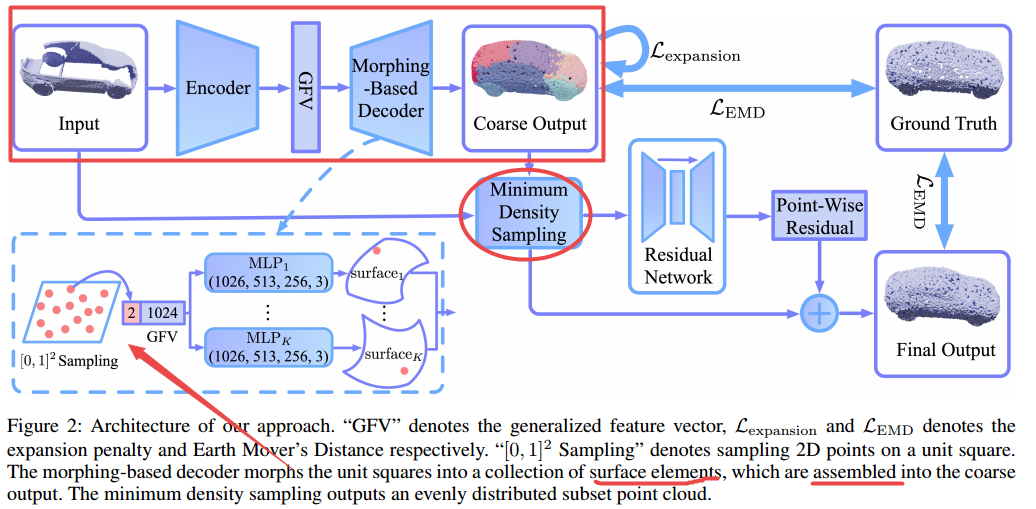
补全后的结果:

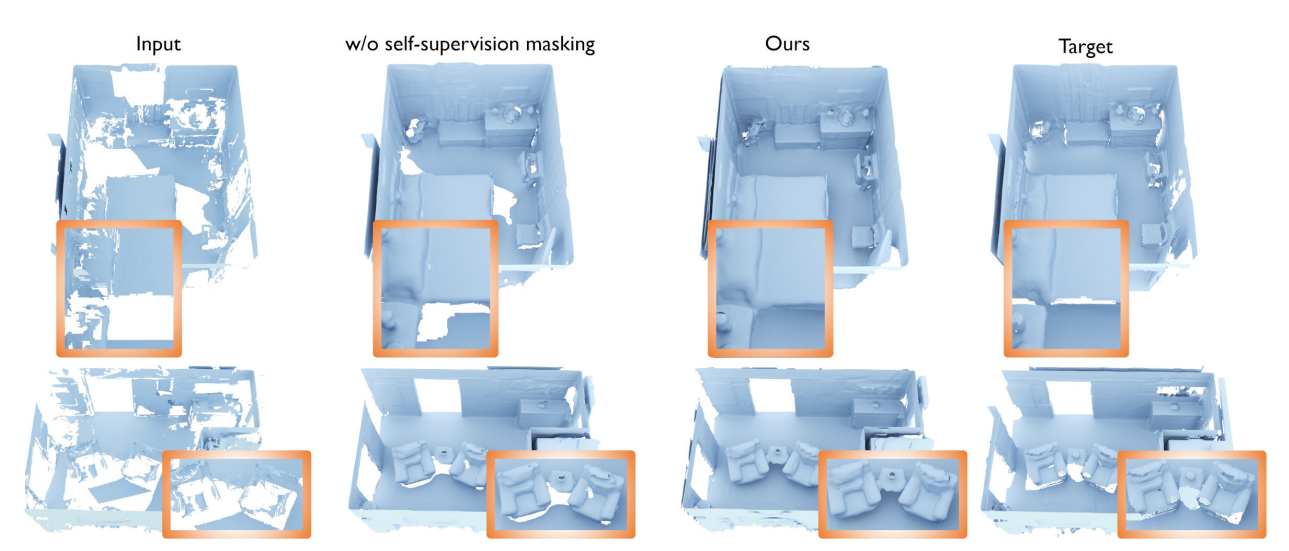
📚****自监督场景深度补全, 基于自监督的方法,实现非完整扫描的生成式补全。通过将输入的不完整的扫描进行部分移除得到更为稀疏的扫描结果,并基于此来进行补全。利用稀疏生成网络从已有的结构上学习出补全方法,随后去补全输入中缺失的部分。(from TUM)
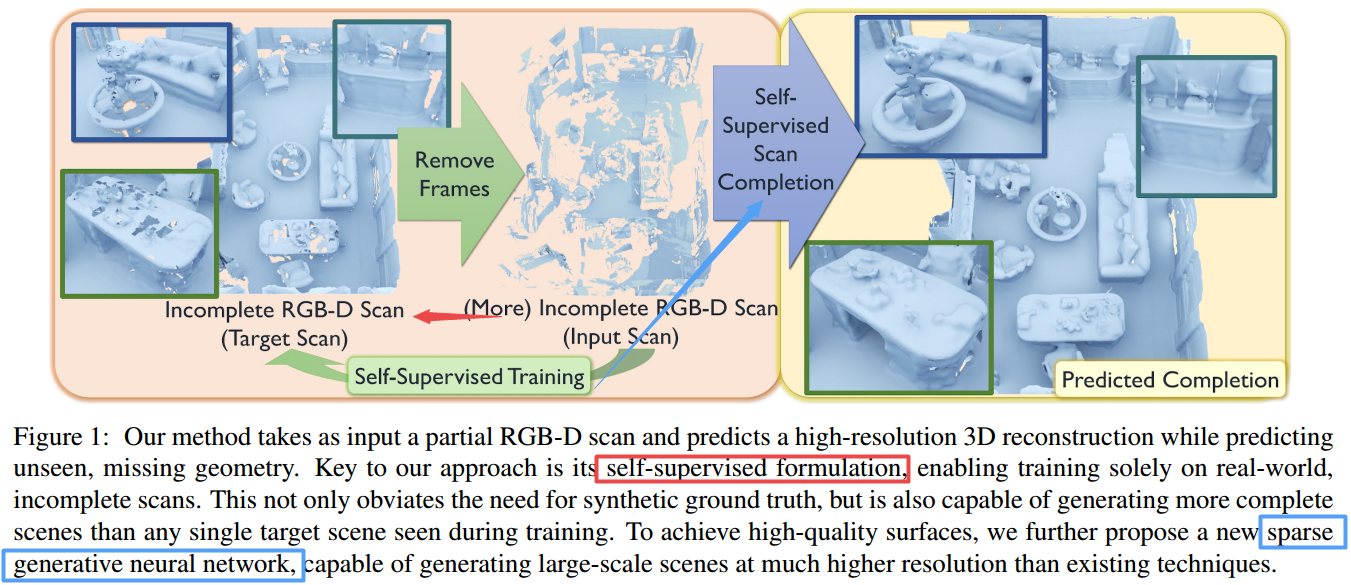
自监督的训练流程,通过更稀疏的来重建输入的场景,并用mask剔除输入中没有的部分:

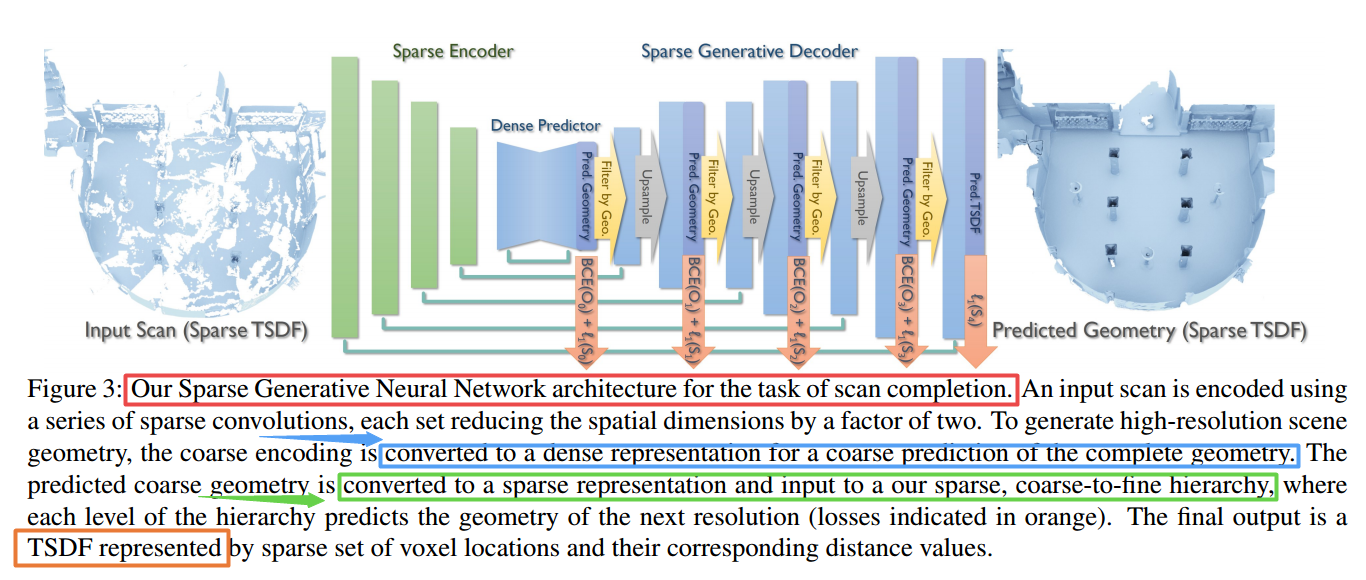
模型中使用的稀疏生成网络架构:
一些补全的结果:
ref:dataset:Matterport3D [3] Scan2CAD
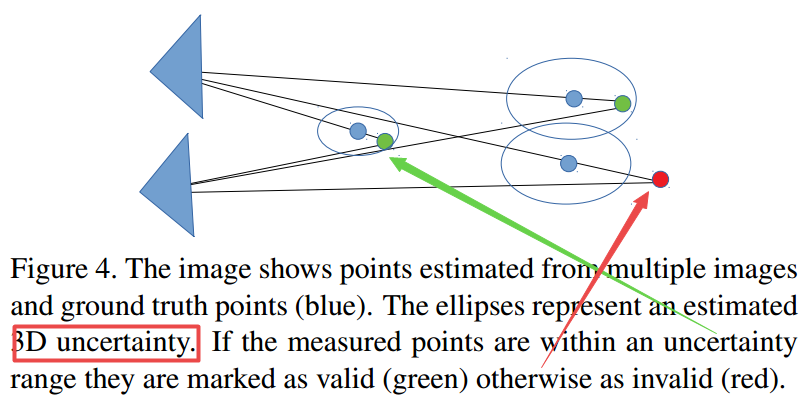
📚***FusionMapping, 利用二维图像和三维Lidar点云进行融合深度预测。(from CMU)
优化流程图:

实现的结果,第三个图显示了最后预测出的点云,在图像预测深度的提升下对细节有很好的重建:
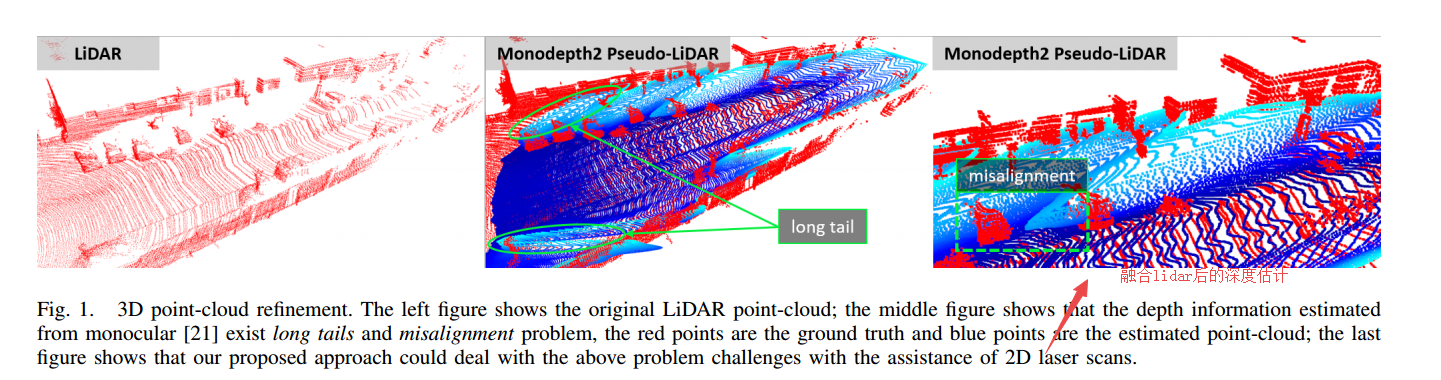
📚**DeepC-MVS基于置信度预测的多视角重建, 基于多视角高分辨率图像的三维重建方法,通过置信度预测网络和几何误差传递得到的基准进行训练,在训练中加入了基准的置信度图(来自于几何误差估计)。为了得到半稠密的基准来训练网络,这一工作还提出了一个合成数据集。(from 索尼 EPFL TU Graz)
使用置信度预测包含两个主要的步骤,首先利用用于局外点聚类和局外点滤波,随后用于深度优化。主要优点在于利用置信度网络来提升模型的有效性。通过置信度来优化网络的输出。

dataset:ETH3D[31]
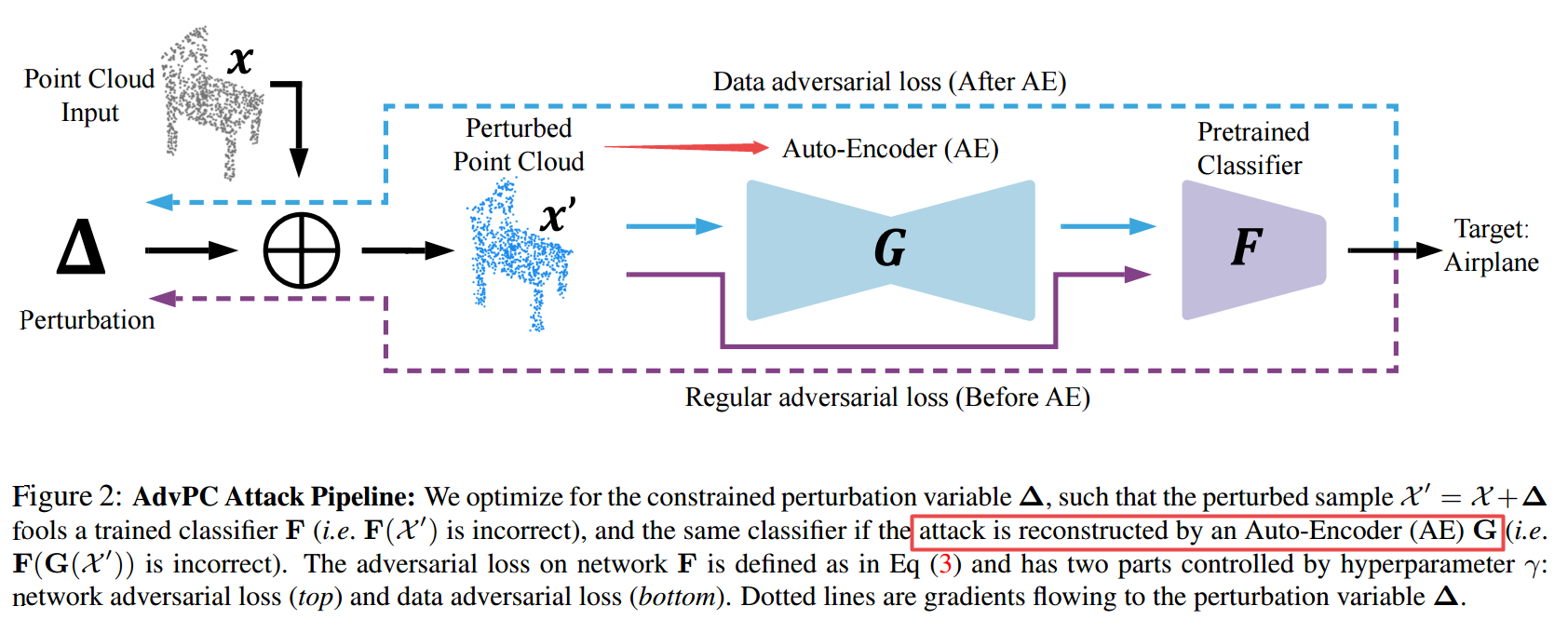
📚AdvPC点云可迁移的对抗扰动, 提出了一种新颖的三维点云网络攻击方法,具有可迁移性和对抗弹性(from KAUST)
现有的点云攻击方法不具有可迁移性、并且比较容易通过统计的方法进行防御。这一方法充分利用了输入数据的分布,使得这些扰动可以抵抗现有防御的弹性,具有很好的可移植性。
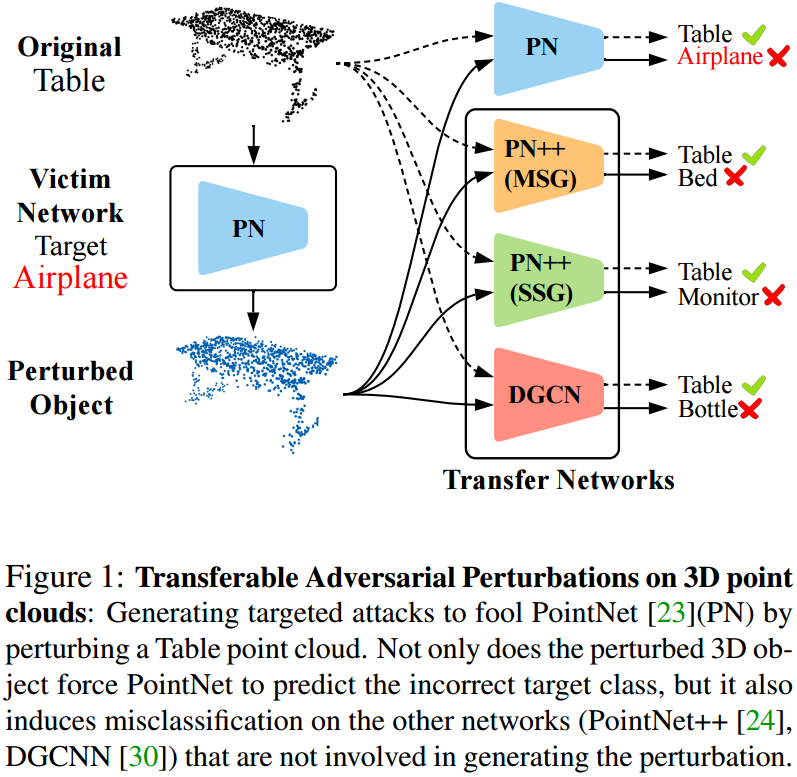
基于概率嵌入的点云实例分割方法, (from KAUST)
用于点云三维目标检测的关系图网络, (from 湖南大学)
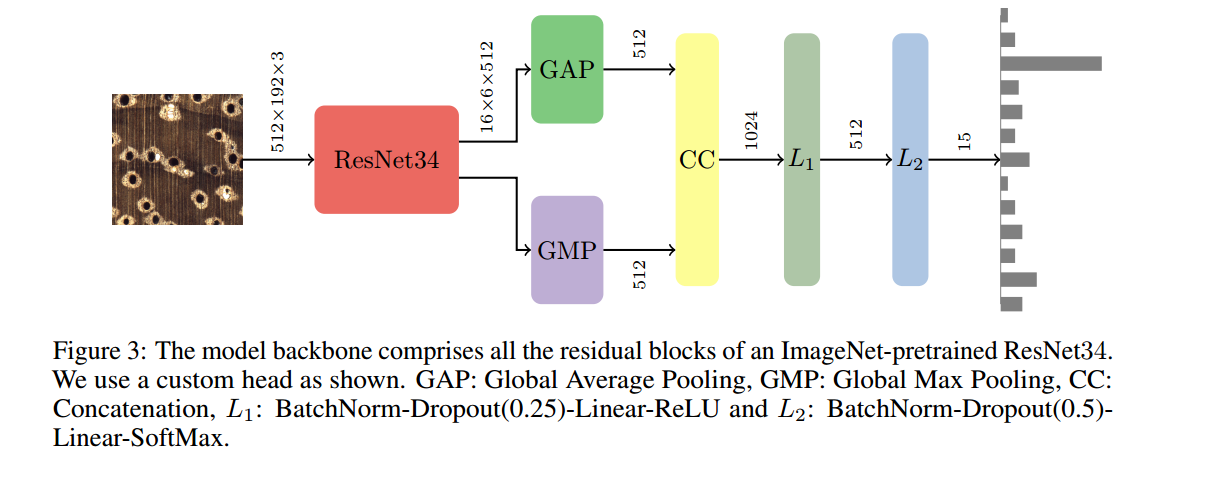
基于图像的木材识别,(from Center for Wood Anatomy Research, USDA Forest Products Laboratory)
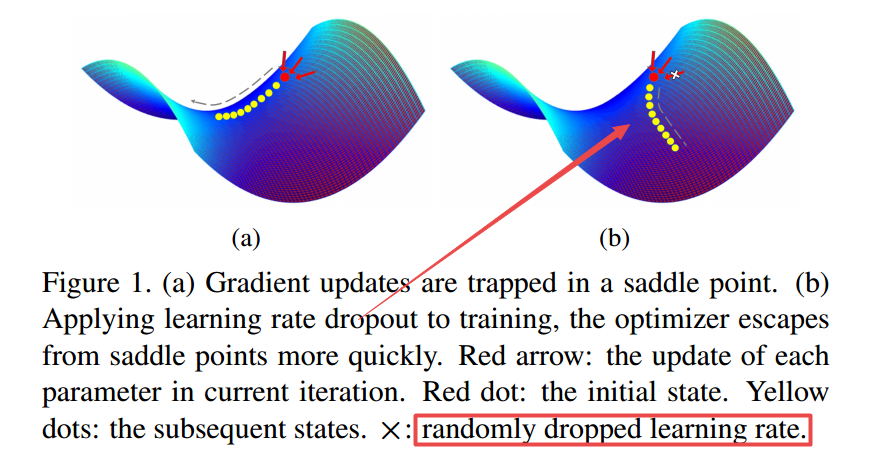
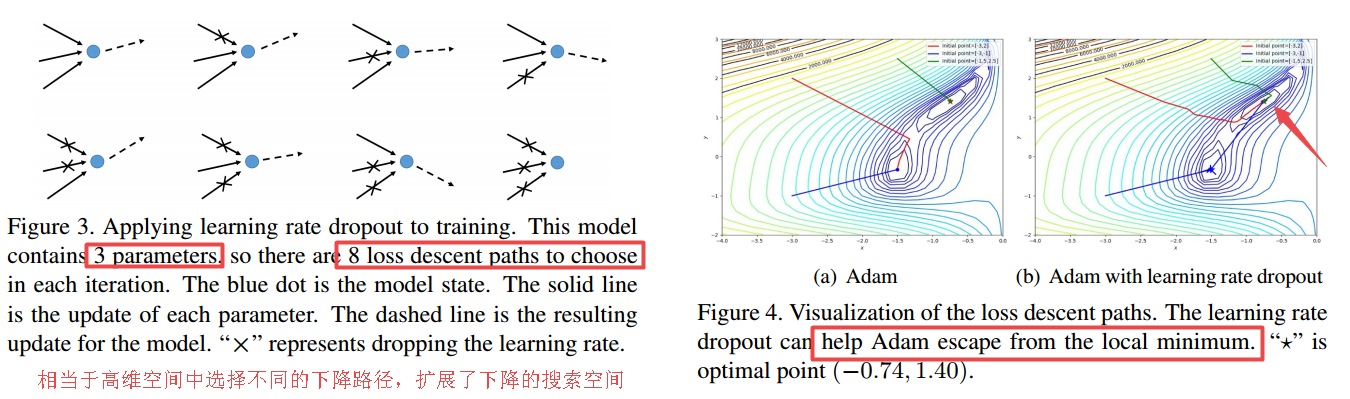
LRD:Learning Rate Dropout,LRD方法可以通过随机地设置参数空间中的某些参数学习率为0来帮助优化器进行主动搜索,只有学习率不为零的参数才会更新参数。(from 厦门大学 哥伦比亚大学)
由于不同参数的学习率随机的被丢弃,使得优化器可以选择新的损失下降路径。下降路径的不确定性使得模型可以避开鞍点和局域最小值。
与标准的dropout比较,学习率dropout只对红线部分学习率置为零,不更新参数。
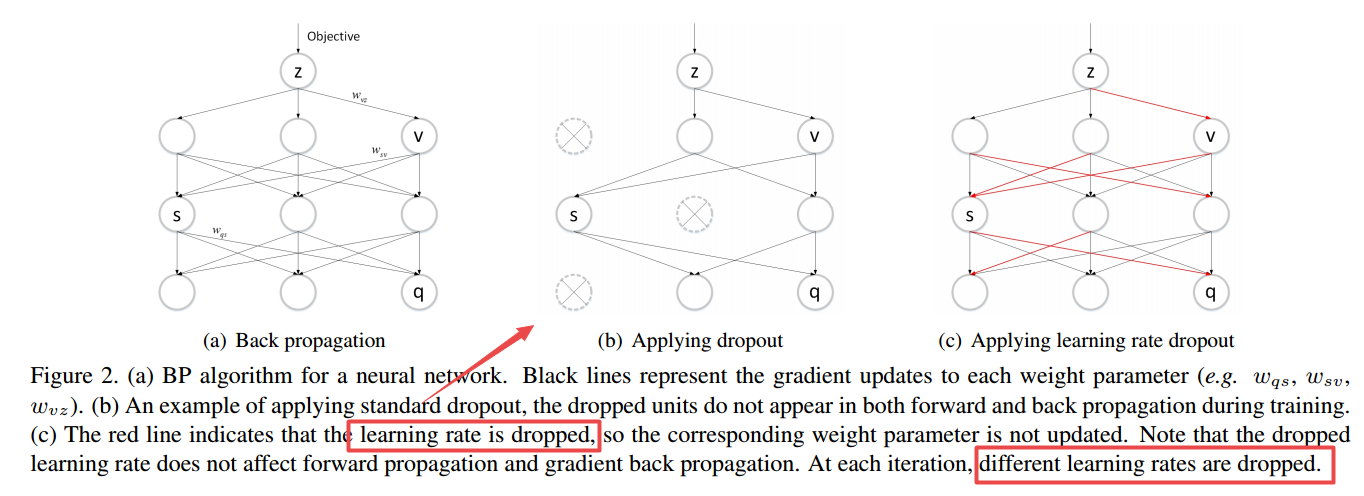
code:https://github.com/HuangxingLin123/LearningRate-Dropout
++基于深度学习的生物识别综述,包含了各种常见的生物识别数据集、识别方法的历史发展等等。主要针对人脸、指纹、掌纹、虹膜、瞳孔、耳朵和体态进行识别。(from New York University)
++基于深度学习的视觉追踪综述,非常丰富完整的总结(from Yazd University, Yazd, Iran)


SGAS: Sequential Greedy Architecture Search,一种新的神经架构搜索方法,解决搜索出的架构测评指标较差的问题。(from KAUST Intelligent Systems Lab, Intel Labs,)
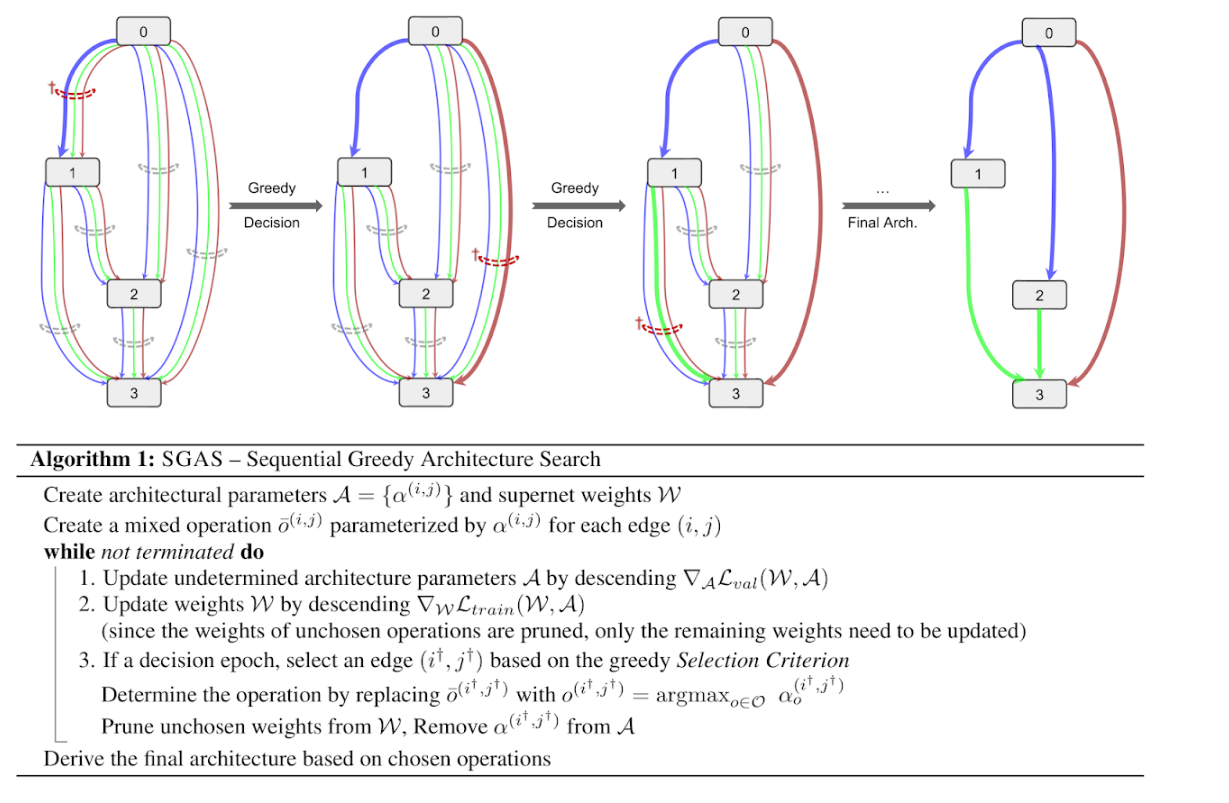
code:https://sites.google.com/kaust.edu.sa/sgas
基于校正滤波器的图像超分辨方法,提高模型在未知退化数据上的泛化表现(from Tel Aviv University, Israel)
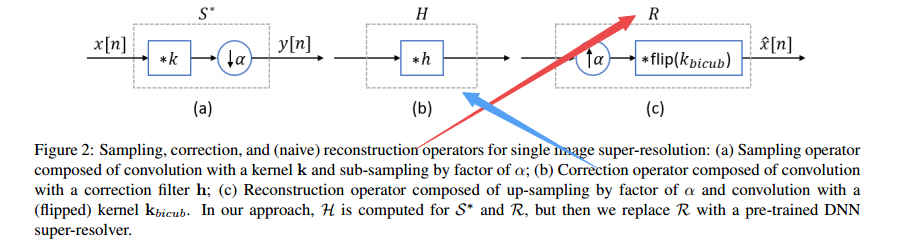
校正滤波器处理后的结果:

LatentFusion,利用端到端的差分重建和渲染对于未知目标的位置估计(from University of Washington Nvidia)

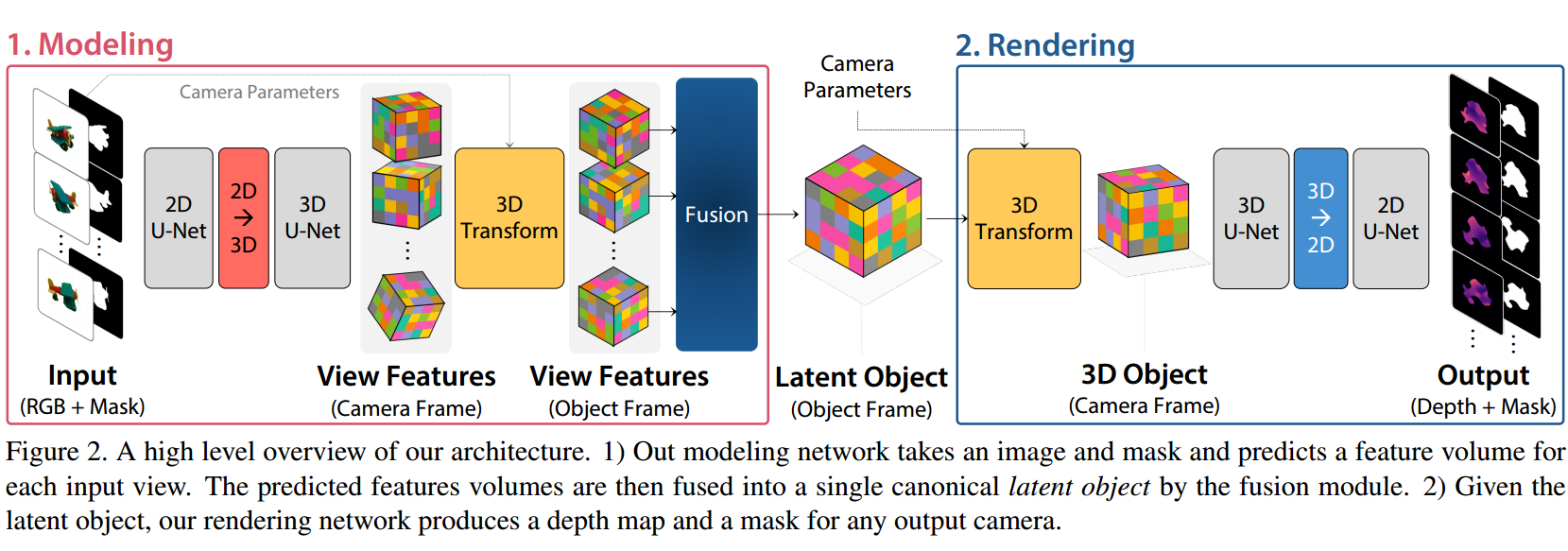
dataset:MOPED

人体姿态的深度图数据集DIH: Depth Images with Humans:https://www.idiap.ch/dataset/dih
Daily Computer Vision Papers
| View-Invariant Probabilistic Embedding for Human Pose Authors Jennifer J. Sun, Jiaping Zhao, Liang Chieh Chen, Florian Schroff, Hartwig Adam, Ting Liu 对相似人体配置的描述可能会随着观点的变化而变化。我们只想使用2D信息,使视觉算法能够识别多个视图中人体姿势的相似性。此功能对于分析图像和视频中的人体运动和人类行为非常有用。在本文中,我们提出了一种仅从2D关节关键点学习紧凑视图不变嵌入空间的方法,而无需明确预测3D姿势。由于2D姿势是从3D空间投影的,因此它们具有固有的模糊性,很难通过确定性映射来表示。因此,我们使用概率嵌入对该输入不确定性进行建模。实验结果表明,与2D到3D姿势提升模型相比,我们的嵌入模型在不同摄像机视图中检索相似姿势时可实现更高的准确性。结果还表明,我们的模型能够跨数据集进行泛化,并且我们的嵌入方差与输入姿势歧义相关。 |
| A Multigrid Method for Efficiently Training Video Models Authors Chao Yuan Wu, Ross Girshick, Kaiming He, Christoph Feichtenhofer, Philipp Kr henb hl 训练竞争性深视频模型比训练其对应的图像模型要慢一个数量级。缓慢的培训会导致较长的研究周期,从而阻碍了视频理解研究的进展。按照训练图像模型的标准做法,视频模型训练假定固定的小批形状,特定数量的剪辑,帧和空间大小。但是,最佳形状是什么?高分辨率模型的性能很好,但训练速度很慢。低分辨率模型训练速度更快,但它们不准确。受数值优化中的多重网格方法启发,我们建议使用具有不同空间时间分辨率的可变小型批处理形状,这些形状会根据计划而变化。不同的形状来自在多个采样网格上对训练数据进行重新采样。在缩小其他尺寸时,通过扩大最小批量大小和学习率来加快培训速度。我们凭经验证明了一个通用而稳健的网格计划,可以针对不同的模型(I3D,非本地,SlowFast,数据集动力学,某物,Charades和带有或不带有预训练的训练设置)提供开箱即用的训练速度,而不会损失准确性。 128个GPU或1个GPU。作为说明性示例,与基线训练方法相比,所提出的多网格方法训练的ResNet 50 SlowFast网络的壁钟时间缩短了4.5倍,使用相同的硬件,同时还提高了Kinetics 400的绝对精度0.8。 |
| IENet: Interacting Embranchment One Stage Anchor Free Detector for Orientation Aerial Object Detection Authors Youtian Lin, Pengming Feng, Jian Guan 空中图像中的物体检测由于缺乏可见的特征和物体的不同方向而成为一项具有挑战性的任务。当前,基于R CNN框架的检测器的数量在水平包围盒HBB和定向包围盒OBB的目标预测中取得了重大进展。但是,仍然存在用于一级无锚解决方案的空间。本文提出了一种针对航拍图像中目标物体的无级锚定检测器,该检测器建立在每像素预测方式检测器的基础上。我们通过开发具有自我关注机制的分支交互模块来融合分类和框回归分支中的特征,从而使之成为可能。此外,在角度预测中采用几何变换以使其对于预测网络更易于管理。我们还引入了用于OBB检测的IOU丢失,它比常规多边形IOU效率更高。在DOTA和HRSC2016数据集上对提出的方法进行了评估,结果表明,与先进的检测器相比,我们的IENet具有更高的OBB检测性能。 |
| More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation Authors Quanfu Fan, Chun Fu Chen, Hilde Kuehne, Marco Pistoia, David Cox 视频动作识别的当前最先进模型主要基于昂贵的3D ConvNet。这导致需要大型GPU集群来训练和评估此类架构。为了解决这个问题,我们提出了一种轻量级且内存友好的动作识别架构,该架构仅使用一小部分资源即可与当前架构相媲美或比目前架构更好。所提出的体系结构基于在低分辨率帧上运行的深层子网与在高分辨率帧上运行的紧凑型子网的组合,从而可同时实现高效率和准确性。我们证明了与基线相比,我们的方法可将FLOPs减少3 sim4倍,将内存使用减少sim2倍。这样可以在相同的计算预算下用更多的输入帧训练更深的模型。为了进一步消除对大规模3D卷积的需求,提出了一种时间聚合模块,以非常小的额外计算成本对视频中的时间依赖性进行建模。我们的模型在多个动作识别基准(包括动力学,时事和时机)上均取得了出色的性能。可以在以下位置找到代码和模型 |
| Mis-classified Vector Guided Softmax Loss for Face Recognition Authors Xiaobo Wang, Shifeng Zhang, Shuo Wang, Tianyu Fu, Hailin Shi, Tao Mei 由于深度卷积神经网络CNN的发展,人脸识别取得了长足的进步,其主要任务是如何改善特征识别。为此,基于几个边距的文本例如为了提高不同类别之间的特征余量,提出了角度,相加角和相加角余量softmax损失函数。然而,尽管已经取得了巨大的成就,但它们主要受到三个问题的困扰1显然,他们忽略了信息特征挖掘对判别性学习的重要性2他们仅鼓励基础真理类的特征余量,而没有意识到与其他非基础事物的区别性真理类别3不同类别之间的特征余量设置为相同且固定的,可能无法很好地适应情况。为了解决这些问题,本文开发了一种新颖的损失函数,该函数自适应地强调了分类错误的特征向量,以指导判别性特征学习。因此,我们可以解决上述所有问题,并获得更具区分性的面部特征。据我们所知,这是将特征余量和特征挖掘的优点继承为统一损失函数的首次尝试。在几个基准上的实验结果证明了我们的方法优于最新技术的有效性。 |
| Information bottleneck through variational glasses Authors Slava Voloshynovskiy, Mouad Kondah, Shideh Rezaeifar, Olga Taran, Taras Holotyak, Danilo Jimenez Rezende 信息瓶颈IB原则1已成为深度模型的信息理论分析的重要元素。可变自动编码器VAE 2 3和生成对抗网络GAN的许多最先进的生成模型GAN 4族在互信息项上使用各种界限来引入某些正则化约束5 6 7 8 9 10。因此,这些模型之间的主要区别在于添加了正则化约束和目标明确的目标。 |
| Improving Model Drift for Robust Object Tracking Authors Qiujie Dong, Xuedong He, Haiyan Ge, Qin Liu, Aifu Han, Shengzong Zhou 区分性相关过滤器在对象跟踪中表现出出色的性能。但是,在复杂的场景中,被跟踪目标的外观特征是可变的,这很容易污染模型并导致模型漂移。在本文中,考虑到次要峰对模型更新的影响更大,我们提出了一种检测响应图的主要和次要峰的方法。其次,提出了一种新的使用自适应更新判别机制的置信函数,该函数具有良好的鲁棒性。第三,我们提出了一种具有相关性滤波器的鲁棒跟踪器,该跟踪器使用了手工制作的功能,可以改善复杂场景中的模型漂移。最后,为了应对当前的跟踪器多特征响应合并,我们提出了一种简单的指数自适应合并方法。在OTB2013,OTB100和TC128数据集上进行了广泛的实验。我们的方法在实时高速运行的同时,还可以针对几种最先进的跟踪器发挥出色的性能。 |
| Mixture Dense Regression for Object Detection and Human Pose Estimation Authors Ali Varamesh, Tinne Tuytelaars 混合模型是公认的机器学习方法,在计算机视觉中,大多数已将其应用于逆向或不确定问题。但是,它们是通用的分而治之技术,以数据驱动的方式将输入空间分为相对同质的子集。因此,不仅定义不明确,而且定义明确的复杂问题也应从中受益。为此,我们设计了一种使用混合密度网络进行空间回归的多模式解决方案,用于稠密物体检测和人体姿态估计。对于这两个任务,我们表明混合模型收敛更快,产生的精度更高,并且将输入空间划分为可解释的模式。对于物体检测,混合成分学会着重于对象尺度,其成分的分布紧随地面真实物体尺度的分布。对于人体姿势估计,混合模型基于观点和不确定性(即正视图和后视图)对数据进行划分,而后视图则具有更高的不确定性。我们在MS COCO数据集上进行实验,没有遇到任何模式崩溃。但是,为了避免数值不稳定,我们必须对混合方差项的激活函数进行一些修改。 |
| Tabulated MLP for Fast Point Feature Embedding Authors Yusuke Sekikawa, Teppei Suzuki 为了在测试时大幅加快点数据嵌入的速度,我们提出了一个新框架,该框架使用一对多层感知器MLP并查找表LUT将点坐标输入转换为高维特征。与需要数百万个点积的MLP实现的PointNet的功能嵌入部分相比,我们的测试时间不需要矩阵矢量积的这种层,而仅需要从离散输入定义的列表化MLP中查找最接近的实体,然后进行插值在3D晶格上。我们将此框架称为LUTI MLP LUT插值MLP,它提供了一种方法来训练以特定方式耦合到LUT的端到端列表化MLP,而无需在测试时进行任何近似。 LUTI MLP还为测试时在李代数mathfrak se 3上的全局姿势坐标的嵌入函数的Jacobian计算提供了极大的加速,可用于点集配准问题。在使用ModelNet40数据集进行了广泛的架构分析之后,我们确认即使是小尺寸桌子,LUTI MLP的性能也可以与MLP相媲美,达到8倍,8倍,8倍的嵌入速度,约12倍的Jacobian速度和860倍的速度规范的雅可比行列式。 |
| A Robust Iris Authentication System on GPU-Based Edge Devices using Multi-Modalities Learning Model Authors Siming Zheng, Rahmita Wirza O.K. Rahmat, Fatimah Khalid, Nurul Amelina Nasharuddin 近年来,移动互联网加速了智能移动技术的发展。移动支付,移动安全和隐私保护已成为广泛关注的焦点。虹膜识别已成为这些领域中的一种高度安全的身份验证技术,它已广泛应用于生物识别身份验证领域的不同科学领域。卷积神经网络CNN是图像识别的主流深度学习方法之一,但其抗噪能力较弱,需要一定的内存才能进行图像分类任务的训练。在这种情况下,我们提出了基于Mask R CNN和Inception V4神经网络模型的微调神经网络模型,该模型将每个组件集成到整个系统中,该系统将虹膜检测,提取和识别功能结合在一起作为虹膜识别系统。该框架具有可扩展性和高可用性的特点,不仅可以学习虹膜图像的部分整体关系,而且可以增强整个框架的鲁棒性。重要的是,可以使用不同光谱的样本(例如可见波长VW和近红外NIR虹膜生物特征数据库)训练提出的模型。在Jetson Nano的移动边缘计算设备中执行时,可实现99.10的识别平均精度。 |
| Efficient Convolutional Neural Networks for Depth-Based Multi-Person Pose Estimation Authors Angel Mart nez Gonz lez, Michael Villamizar, Olivier Can vet, Jean Marc Odobez 实现健壮的多人2D身体地标定位和姿势估计对于HRI设置中遇到的人类行为和互动理解至关重要。最近已经提出了精确的方法,但是它们通常依赖于相当深的卷积神经网络CNN体系结构,因此需要大量的计算和训练资源。在本文中,我们研究了不同的体系结构和方法来解决这些问题,并实现快速,准确的多人2D姿势估计。为了提高速度,我们建议使用深度图像,深度图像的结构包含有关人体标志的足够信息,同时比带纹理的彩色图像更简单,因此潜在地需要较少复杂的CNN进行处理。在这方面,我们做出以下贡献。我研究了几种结合姿势机的CNN架构设计,这些姿势机依赖于检测器概念的级联和轻巧高效的CNN结构ii,以解决具有高可变性的大型训练数据集的需求,我们依赖于将多人合成深度数据与真实数据结合起来的半合成数据传感器背景iii我们探索领域适应技术以解决通过在真实深度图像上进行测试而引入的性能差距iv以提高我们的快速轻量级CNN模型的准确性,我们研究了可有效提高性能的多个架构级别的知识提炼。对合成数据和真实数据进行的实验和结果突显了我们设计选择的影响,提供了解决实际应用中通常面临的标准问题的方法的见解,并导致架构在性能和速度上均有效地达到了我们的目标。 |
| Training the Convolutional Neural Network with Statistical Dependence of the Response on the Input Data Distortion Authors Igor Janiszewski, Dmitry Slugin, Vladimir V. Arlazarov 本文提出了一种使用有关输入数据失真程度的信息来训练卷积神经网络的方法。学习过程通过附加层进行了修改,随后又被删除了,因此原始网络的体系结构不会改变。例如,考虑LeNet5体系结构网络,该网络具有基于MNIST符号的训练数据和失真模型,该模型具有失真程度可变的高斯模糊。这种方法不会造成网络质量损失,并且在对测试数据的响应中具有明显的无错误区域,这是传统的培训方法所没有的。响应在统计上取决于输入图像的失真程度,并且它们之间存在很强的关系。 |
| DAL -- A Deep Depth-aware Long-term Tracker Authors Yanlin Qian, Alan Luke i , Matej Kristan, Joni Kristian K m r inen, Jiri Matas 最好的RGBD跟踪器可提供高精度,但运行缓慢。另一方面,最好的RGB跟踪器速度很快,但在RGBD数据集上明显逊色。在这项工作中,我们提出了一种深度深度感知的长期跟踪器,该跟踪器可实现最新的RGBD跟踪性能,并且运行速度很快。我们重新构造了深度判别相关滤波器DCF,以将深度信息嵌入到深度特征中。此外,相同的深度感知相关滤波器用于目标重新检测。综合评估表明,所建议的跟踪器在Princeton RGBD,STC和新发布的CDTB基准上均达到了最先进的性能,并以20 fps的速度运行。 |
| IPG-Net: Image Pyramid Guidance Network for Object Detection Authors Ziming Liu, Guangyu Gao, Lin Sun 对于基于卷积神经网络的目标检测,存在一个典型的难题,空间信息被很好地保留在浅层中,不幸的是,这些浅层没有足够的语义信息,而深层却具有较高的语义概念,但却丢失了很多空间信息,从而导致严重的信息失衡。为了获取浅层的足够语义信息,要素金字塔网络FPN用于构建自顶向下的传播路径。在本文中,除了浅层信息的自上而下的组合以外,我们提出了一种新颖的网络,称为图像金字塔制导网络IPG网络,以确保每层的空间信息和语义信息都足够。我们的IPG网络包含三个主要部分:图像金字塔导航子网,基于ResNet的骨干网络和融合模块。据我们所知,我们是第一个引入图像金字塔制导子网的人,该子网为每个尺度的特征提供空间信息,以解决信息不平衡的问题。即使在ResNet的最深层阶段,该子网也可以保证有足够的空间信息用于边界框回归和分类。此外,我们设计了一个有效的融合模块来融合来自图像金字塔的特征和来自特征金字塔的特征。我们已尝试将这种新颖的网络应用于一阶段模型和两阶段模型,可以从最流行的基准数据集(即MS COCO和Pascal VOC)获得最新的结果。 |
| Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task Authors Aritra Bhowmik, Stefan Gumhold, Carsten Rother, Eric Brachmann 我们解决了计算机视觉的核心问题,即图像匹配的2D特征点检测和描述。长期以来,像精巧的SIFT算法这样的手工设计在准确性和效率上都是无与伦比的。最近,出现了学习型特征检测器,该检测器使用神经网络来实现检测和描述。训练这些网络通常会优化低级匹配分数,通常会预先定义应该或不应该匹配,或应该或不应该包含关键点的图像补丁集。不幸的是,这些低水平匹配分数的准确性提高并不一定会转化为高水平视觉任务的更好性能。我们提出了一种新的训练方法,该方法将特征检测器嵌入完整的视觉管道中,并且以端到端的方式训练可学习的参数。我们使用强化学习中的原理克服了关键点选择和描述符匹配的离散性。作为示例,我们解决了一对图像之间的相对姿势估计的任务。我们证明,在针对测试中应解决的任务进行训练时,可以提高基于学习的状态检测器的准确性。我们的培训方法几乎没有限制学习任务,并且适用于预测关键点热图和关键点位置描述符的任何体系结构。 |
| Patchy Image Structure Classification Using Multi-Orientation Region Transform Authors Xiaohan Yu, Yang Zhao, Yongsheng Gao, Shengwu Xiong, Xiaohui Yuan 外部轮廓和内部结构都是分类对象的重要特征。然而,大多数现有方法分别考虑外部轮廓特征和内部结构特征,因此在对具有相似轮廓和柔性结构的斑驳图像结构进行分类时无法起作用。为了解决上述局限性,本文提出了一种新颖的多方向区域变换MORT,可以同时有效地刻画轮廓和结构特征,以进行斑驳的图像结构分类。 MORT在多个方向上的多个方向区域上执行,以有效整合斑点特征,因此能够以粗糙到精细的方式更好地描述形状。此外,可以将提出的MORT扩展为与深度卷积神经网络技术相结合,以进一步提高分类准确性。获得了极具挑战性的极具挑战性的超细粒品种识别任务,昆虫翅膀识别任务和大变异蝴蝶识别任务的实验结果,证明了提出的MORT在分类斑驳图像结构方面优于现有方法的有效性和优越性。 。我们的代码和三个补丁图像结构数据集可在以下位置获得: |
| DEGAS: Differentiable Efficient Generator Search Authors Sivan Doveh, Raja Giryes 网络体系结构搜索NAS可在各种任务(例如分类和语义分段)中获得最先进的结果。近来,已经针对生成对抗网络GAN提出了一种基于增强学习的方法。在这项工作中,我们通过使用称为DEGAS可微分有效GenerAtor搜索的方法,提出了GAN搜索的替代策略,该方法侧重于在GAN中高效查找生成器。我们的搜索算法受到差分体系结构搜索策略和全局潜在优化GLO程序的启发。这导致有效和稳定的GAN搜索。找到生成器体系结构后,可以将其插入到任何现有的GAN训练框架中。对于我们在这项工作中使用的CTGAN,新模型的初始评分结果比CIFAR 10高0.25,而STL优于0.77。在较短的搜索时间内,它也比基于RL的GAN搜索方法获得更好的结果。 |
| SPSTracker: Sub-Peak Suppression of Response Map for Robust Object Tracking Authors Qintao Hu, Lijun Zhou, Xiaoxiao Wang, Yao Mao, Jianlin Zhang, Qixiang Ye 现代视觉跟踪器通常在特征响应具有目标中心峰值响应的高斯分布的假设下构建在线学习模型。但是,当其他目标和/或背景噪声不断干扰,从而在跟踪响应图上产生子峰值并导致模型漂移时,这种假设就难以置信。在本文中,我们提出了一种用于子峰响应抑制和峰响应执行的校正在线学习方法,旨在以系统的方式处理渐进式干扰。我们的方法称为SPSTracker,它应用简单而有效的峰响应池PRP来聚合和对齐判别特征,以及利用边界响应截断BRT来减少特征响应的差异。通过与多尺度特征融合,SPSTracker将多个子峰的响应分布聚集到单个最大峰,这增强了特征的判别能力,从而可以进行可靠的对象跟踪。在OTB,NFS和VOT2018基准上进行的实验表明,SPSTrack的性能要优于最新的实时跟踪器。 |
| Face Detection with Feature Pyramids and Landmarks Authors Samuel W. F. Earp, Pavit Noinongyao, Justin A. Cairns, Ankush Ganguly 准确的面部检测和面部标志定位对于任何面部识别系统都是至关重要的。我们介绍了三个具有不同大小的主干MobileNetV2 25,MobileNetV2100和ResNet101的单级RCNN,以及在WIDER FACE数据集上专门训练的六层特征金字塔。我们使用八种上下文模块架构比较了人脸检测和地标精度,其中四种是先前研究提出的,而四种是修改版本。我们没有发现任何提议的体系结构显着胜过任何证据的事实,并假设附加层的随机初始化至少具有同等的重要性。为了说明这一点,我们提出了一个模型,该模型可在WIDER FACE上达到近乎最新的性能,并通过简单的上下文模块提供高精度地标。我们还介绍了使用MobileNetV2主干的结果,这些主干可以在WIDER FACE硬验证集上实现90多个平均精度,同时可以实时运行。通过与其他作者进行比较,我们显示出我们的模型超越了类似大小的RCNN的现有技术,并且可以匹配更重的网络的性能。 |
| Exposing and Correcting the Gender Bias in Image Captioning Datasets and Models Authors Shruti Bhargava, David Forsyth 图像字幕的任务暗含了性别识别。然而,由于数据中的性别偏见,图像字幕模型的性别识别受到影响。此外,由于逐词预测,性别活动偏差会影响字幕预测中的其他词,从而导致众所周知的标签偏差问题。在这项工作中,我们调查了COCO字幕数据集中的性别偏见,并表明,这种偏见不仅来自具有上下文的性别统计分布,还来自人类注释者有缺陷的注释。我们在训练的模型中研究这种偏见造成的问题。我们提出了一种通过将任务分为两个子任务来消除偏见的技术:性别中立图像字幕和性别分类。通过这种脱钩,可以消除性别背景的影响。我们训练了性别中性的图像字幕模型,即使在针对与训练数据具有类似偏差的数据集进行评估时,该模型也可以提供与性别模型可比的结果。有趣的是,此模型对没有人的图像的预测也明显不同于接受性别字幕训练的预测。我们使用可用的包围盒和基于遮罩的图像中人的注释来训练性别分类器。这使我们摆脱了背景,专注于预测性别的人。通过将性别替换为性别中立字幕,我们得到了最终的性别预测。我们的预测与采用性别训练的模型取得了相似的效果,同时没有性别偏见。最后,我们的主要结果是,在反刻板印象的数据集上,我们的模型优于通过性别训练的流行图像字幕模型。 |
| Skeleton based Activity Recognition by Fusing Part-wise Spatio-temporal and Attention Driven Residues Authors Chhavi Dhiman, Dinesh Kumar Vishwakarma, Paras Aggarwal 同时,同一动作的类内差异很大,并且这些动作之间的类间相似性也很大,这使得视频中的动作识别非常具有挑战性。在本文中,我们提出了一种新颖的基于骨架的部分时空CNN RIAC网络的3D人类动作识别框架,以部分方式可视化动作动态,并通过应用加权后期融合机制将各个部分用于动作识别。基于零件的基于骨骼的运动动力学有助于突出骨骼的局部特征,这是通过将完整的骨骼分为五个部分(例如头到脊椎,左腿,右腿,左手,右手)来执行的。 RIAFNet架构受到InceptionV4架构的极大启发,该架构统一了ResNet和基于Inception的时空时态表示概念,并实现了迄今为止最高的top 1精度。为了提取和学习动作识别的显着特征,使用了注意力驱动的残差,这些残差增强了残差组件的性能,从而可以有效地基于3D骨架进行时空动作表示。通过对三个具有挑战性的数据集(例如UT Kinect Action 3D,Florence 3D action数据集和MSR Daily Action3D数据集)进行广泛的实验,评估了所提出框架的鲁棒性,这始终证明了我们方法的优越性 |
| Deep Learning for Visual Tracking: A Comprehensive Survey Authors Seyed Mojtaba Marvasti Zadeh, Li Cheng, Hossein Ghanei Yakhdan, Shohreh Kasaei 视觉目标跟踪是计算机视觉中最受欢迎的但具有挑战性的研究主题之一。考虑到问题的不适性及其在现实世界中的广泛应用情况,已经建立了许多大规模的基准数据集,并在此基础上开发了相当多的方法,并证明了这些方法近年来取得了重大进展,主要是近来的研究工作取得了重大进展。学习基于DL的方法。这项调查旨在系统地调查当前基于DL的视觉跟踪方法,基准数据集和评估指标。它还广泛评估和分析了领先的视觉跟踪方法。首先,从网络体系结构,网络开发,视觉跟踪的网络训练,网络目标,网络输出和相关过滤器优势的利用等六个关键方面总结了基于DL的方法的基本特征,主要动机和贡献。其次,比较了流行的视觉跟踪基准及其各自的属性,并总结了它们的评估指标。第三,在一套完善的OTB2013,OTB2015,VOT2018和LaSOT基准测试中,对基于DL的方法进行了全面的检查。最后,通过对这些最新方法进行定量和定性的批判性分析,研究了它们在各种常见情况下的利弊。它可以作为从业人员温和的使用指南,以权衡何时,在何种条件下选择哪种方法。它还有助于就当前问题进行讨论,并阐明有前途的研究方向。 |
| Interpreting Context of Images using Scene Graphs Authors Himangi Mittal, Ajith Abraham, Anuja Arora 了解视觉场景包含对象,关系和上下文。处理图像的传统方法主要关注对象检测,而无法捕获对象之间的关系。关系可以提供有关场景中对象的丰富语义信息。上下文可以帮助理解图像,因为它可以帮助我们感知对象之间的关系,从而使我们对图像有更深入的了解。通过这种想法,我们的项目提供了一个模型,该模型着重于通过将图像表示为图形来查找图像中存在的上下文,其中节点将是对象,而边缘将是它们之间的关系。使用视觉和语义线索找到上下文,这些视觉线索和语义线索被进一步连接并提供给支持向量机SVM,以检测两个对象之间的关系。这为我们提供了图像的上下文,该上下文可进一步用于类似的图像检索,图像字幕或故事生成等应用程序中。 |
| Just Go with the Flow: Self-Supervised Scene Flow Estimation Authors Himangi Mittal, Brian Okorn, David Held 当与高度动态的环境交互时,场景流使自治系统可以推理多个独立对象的非刚性运动。这在自动驾驶领域特别感兴趣,在自动驾驶领域中,许多汽车,人,自行车和其他物体都需要精确跟踪。当前技术水平要求来自自动驾驶场景的带注释的场景流数据以在监督学习下训练场景流网络。作为替代方案,我们提出了一种基于最近邻和周期一致性来训练场景流的方法,该方法使用两个自我监督的损失。这些自我监督的损失使我们能够在大型未标记的自动驾驶数据集上训练我们的方法,结果方法在没有现实世界注解的情况下与当前最新的监督性能匹配,并且在将我们的自我监督方法与基于监督的学习相结合时超过了最新的性能。较小的标记数据集。 |
| AdvPC: Transferable Adversarial Perturbations on 3D Point Clouds Authors Abdullah Hamdi, Sara Rojas, Ali Thabet, Bernard Ghanem 深度神经网络很容易受到对抗性攻击,在这种攻击中,对它们输入的无意识干扰会导致错误的网络预测。这种现象已经在图像领域进行了广泛的研究,直到最近才扩展到3D点云。在这项工作中,我们提出了针对3D点云网络的新型数据驱动的对抗攻击。我们旨在解决当前3D点云对抗攻击中的以下问题,它们在不同网络之间无法很好地传递,并且易于抵御简单的统计方法。在此程度上,我们开发了新的点云攻击,我们将其复制为AdvPC来利用输入数据分布。这些攻击导致对当前防御有弹性的摄动,而与现有技术的攻击相比则保持高度可传递性。我们使用四个流行的点云网络PointNet,PointNet MSG和SSG以及DGCNN来测试我们的攻击。我们提出的攻击方法可使某些网络的传输能力提高多达20个点。它还提高了在ModelNet40数据上突破23点防御的能力。 |
| DeepC-MVS: Deep Confidence Prediction for Multi-View Stereo Reconstruction Authors Andreas Kuhn 1 , Christian Sormann 2 , Mattia Rossi 3 , Oliver Erdler 1 , Friedrich Fraundorfer 2 1 Sony Europe B.V., 2 Graz University of Technology, 3 cole Polytechnique F d rale de Lausanne 深度神经网络DNN具有提高基于图像的3D重建质量的潜力。仍然存在的挑战是利用DNN的潜力来改善ETH3D基准测试提供的高分辨率图像数据集的3D重建。在本文中,我们提出了一种在图像域中使用DNN的方法,以实现基于几何图像的3D重构的显着质量改进。这是通过使用置信度预测网络来实现的,该置信度预测网络已适应多视图立体声MVS情况,并接受了由几何误差传播建立的自动生成的地面真实情况的训练。除了用于训练DNN的半密集现实世界地面真相数据集,我们还提供了一个合成数据集来扩大训练数据集。我们展示了置信度预测在3D重建管道中的两个基本步骤中的效用,首先,将其用于离群值聚类和过滤,其次,将其用于深度细化步骤。提出的3D重建管道DeepC MVS利用高分辨率的高分辨率图像对MVS中的重要部分进行了深度学习,并且对流行基准进行的实验评估证明了3D重建达到了最先进的质量。 |
| RST-MODNet: Real-time Spatio-temporal Moving Object Detection for Autonomous Driving Authors Mohamed Ramzy, Hazem Rashed, Ahmad El Sallab, Senthil Yogamani 运动物体检测MOD是自动驾驶汽车的一项关键任务,因为运动物体比静态物体具有更高的碰撞风险。基于检测到的移动物体的未来状态来计划自我车辆的轨迹。这是非常具有挑战性的,因为必须对自我运动进行建模和补偿,以便能够理解周围物体的运动。在这项工作中,我们提出了一种实时的端到端CNN架构,用于MOD利用时空上下文来提高鲁棒性。我们使用光流图像,除了显式运动图之外,还利用嵌入在顺序图像中的时间运动信息构建了一种新型的时间感知架构。我们证明了该算法对KITTI数据集的影响,相对于基准而言,它获得了8的改进。我们将我们的算法与最先进的方法进行了比较,并在KITTI Motion数据集上以三倍于运行时间的准确性获得了竞争性结果。拟议的算法在目标为嵌入式平台上部署的标准台式机GPU上以23 fps的速度运行。 |
| Diversifying Inference Path Selection: Moving-Mobile-Network for Landmark Recognition Authors Biao Qian, Yang Wang, Zhao Zhang, Richang Hong, Meng Wang, Ling Shao 深度卷积神经网络极大地受益于计算机视觉任务。但是,高计算复杂度限制了它们在现实世界中的应用。为此,已经提出了许多用于有效网络学习的方法以及在便携式移动设备中的应用。在本文中,我们提出了一种新颖的下划线M oving下划线M obile下划线网络,称为M 2 Net,用于地标识别,为每个地标图像配备了定位的地理信息。我们直观地发现,M 2 Net实质上可以促进推理路径选择块子集选择的多样性,从而提高识别精度。上述直觉是通过我们建议的奖励功能以及地理位置和地标的输入来实现的。我们还发现,通过我们的体系结构可以提高其他便携式网络的性能。我们构建了两个地标图像数据集,每个地标都与地理信息相关联,在此数据集上我们进行了广泛的实验,以证明M 2 Net以可比较的复杂度实现了更高的识别精度。 |
| LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation Authors Keunhong Park, Arsalan Mousavian, Yu Xiang, Dieter Fox 当前的6D对象姿态估计方法通常需要为每个对象提供3D模型。这些方法还需要进行额外的培训才能合并新对象。结果,它们难以缩放到大量对象,并且不能直接应用于看不见的对象。在这项工作中,我们提出了一种用于看不见物体的6D姿态估计的新颖框架。我们设计了端到端神经网络,该网络使用少量对象的参考视图来重建对象的潜在3D表示。使用学习到的3D表示,网络可以从任意视图渲染对象。使用该神经渲染器,我们可以针对给定输入图像的姿势直接进行优化。通过使用大量3D形状训练我们的网络以进行重构和渲染,我们的网络可以很好地推广到看不见的对象。我们为看不见的物体姿态估计MOPED提供了一个新的数据集。我们在MOPED以及ModelNet数据集上评估了用于看不见的物体姿态估计的方法的性能。 |
| MetAdapt: Meta-Learned Task-Adaptive Architecture for Few-Shot Classification Authors Sivan Doveh, Eli Schwartz, Chao Xue, Rogerio Feris, Alex Bronstein, Raja Giryes, Leonid Karlinsky 很少有射击学习FSL是一个快速增长的话题。通常,在FSL中,模型是在由许多小任务元任务组成的数据集上训练的,并学会适应测试期间将遇到的新颖任务。这也称为元学习。到目前为止,元学习FSL方法集中于优化预定义网络体系结构的参数,以使其易于适应新任务。此外,可以观察到,通常,较大的体系结构在较小的体系结构下达到某个饱和点的性能要好一些,甚至会由于过度拟合而降低性能。但是,很少有人关注显式优化FSL的体系结构,也没有关注在测试时对特定新颖任务进行体系结构调整。在这项工作中,我们建议采用从可微分神经体系结构搜索D NAS文献中借用的工具,以在不过度拟合的情况下优化FSL的体系结构。此外,为了使体系结构任务具有适应性,我们提出了MetAdapt控制器模块的概念。这些模块被添加到模型中,并经过元训练以预测给定新颖任务的最佳网络连接。使用提议的方法,我们在两种流行的少数镜头基准miniImageNet和FC100上观察了最新技术结果。 |
| Affect-based Intrinsic Rewards for Learning General Representations Authors Dean Zadok, Daniel McDuff, Ashish Kapoor 积极影响与人们对学习的兴趣,好奇心和满意度增加有关。在强化学习中,外部奖励通常很少且难以定义,内在动机的学习可以帮助应对这些挑战。我们认为积极影响是一种重要的内在奖励,可以有效地帮助推动探索,这对于收集对学习一般表征至关重要的经验很有用。我们提出了一种新颖的方法,该方法利用了独立于任务的内在奖励功能,该功能在捕获积极影响的自发微笑行为上训练。为了评估我们的方法,我们对通过我们的政策和几种基准方法收集的数据进行了一些下游计算机视觉任务的培训。我们表明,基于内在情感奖励的策略成功地增加了事件的持续时间,探索的区域并减少了冲突。影响是提高了一些下游计算机视觉任务的学习速度。 |
| The Group Loss for Deep Metric Learning Authors Ismail Elezi, Sebastiano Vascon, Alessandro Torcinovich, Marcello Pelillo, Laura Leal Taixe 深度度量学习通过利用神经网络获得高度区分性的特征嵌入,可在诸如聚类和图像检索等任务中取得令人印象深刻的结果,这些特征嵌入可用于将样本分为不同的类别。已经进行了许多研究来设计用于训练这种网络的智能损失函数或数据挖掘策略。大多数方法只考虑小批量中的成对或三重样本来计算损失函数,这通常基于嵌入之间的距离。我们提出了“组损失”,这是一种基于可微分标签传播方法的损失函数,该函数在组的所有样本之间实施嵌入相似性,同时在属于不同组的数据点之间提升低密度区域。在平滑性假设(相似对象应该属于同一组)的指导下,所提出的损失训练了神经网络进行分类任务,从而在类中的样本之间实施了一致的标记。我们在几个数据集上展示了聚类和图像检索方面的最新技术成果,并展示了与其他技术(例如合奏)结合使用该方法的潜力 |
| Training Object Detectors from Few Weakly-Labeled and Many Unlabeled Images Authors Zhaohui Yang, Miaojing Shi, Yannis Avrithis, Chao Xu, Vittorio Ferrari 弱监督对象检测试图通过分配对边界框的需求来限制监督的数量,但仍假定整个训练集上的图像级别标签都可用。在这项工作中,我们研究了从一个或几个带有图像级别标签的干净图像和一大堆完全未标记图像中训练对象检测器的问题。这是半监督学习的极端情况,其中标记的数据不足以引导分类器或检测器的学习。我们的解决方案是使用标准的弱监督管道,根据教师模型在未标记集上生成的图像级伪标签训练学生模型,并通过区域级相似性进行引导以清理标记的图像。通过使用最新的PCL管道和更多未标记的图像,我们可以获得与许多现有的弱监督检测解决方案相媲美或更高的性能。 |
| Alignment Free and Distortion Robust Iris Recognition Authors Min Ren, Caiyong Wang, Yunlong Wang, Zhenan Sun, Tieniu Tan 虹膜识别是一种可靠的个人识别方法,但仍有很大的空间可以提高其准确性,尤其是在约束较少的情况下。例如,头部姿势的自由移动可能会导致虹膜图像之间的较大旋转差异。并且光照变化可能会导致虹膜纹理的不规则变形。为了使类内虹膜图像与头部旋转稳定地匹配,现有的解决方案通常需要通过在虹膜图像预校准的确定范围内进行详尽搜索或通过蛮力搜索虹膜特征匹配中的最小汉明距离来进行精确的对齐操作。在野外,虹膜旋转的不确定性要比约束条件下的不确定性大得多,在确定的范围内进行详尽的搜索是不可行的。本文提出了一种统一的特征级别解决方案,可以在野外实现无对准和变形鲁棒虹膜识别。提出了一种新的基于深度学习的方法,称为无对准虹膜网络AFINet,该方法使用一种称为NetVLAD的可训练的VLAD向量的局部聚集描述符编码器来解耦局部表示及其空间位置之间的相关性。变形卷积用于通过密集自适应采样克服虹膜纹理失真。在三个公共虹膜图像数据库和模拟降级数据库上进行的广泛实验的结果表明,AFINet明显优于现有的虹膜识别方法。 |
| Gate-Shift Networks for Video Action Recognition Authors Swathikiran Sudhakaran, Sergio Escalera, Oswald Lanz 用于视频动作识别的Deep 3D CNN旨在学习联合时空时空特征空间中的强大表示。然而,实际上,由于涉及大量参数和计算,因此可能缺乏足够大的数据集以进行大规模训练,因此它们可能无法正常运行。在本文中,我们将空间门控引入3D核的空间时间分解中。我们通过门移位模块GSM来实现这一概念。 GSM轻巧,可将2D CNN转换为高效的时空时域特征提取器。通过插入GSM,二维CNN学会了在时间上自适应地路由要素并将其组合,而几乎没有其他参数和计算开销。我们对提议的模块进行了广泛的评估,以研究其在视频动作识别中的有效性,在Something Something V1和Diving48数据集上获得了最先进的结果,并在EPIC Kitchens上获得了模型复杂度要低得多的竞争性结果。通过将GSM插入TSN中,在Something Something V1上,我们使用不到1个额外的参数和计算就将识别准确度从17.52绝对提高到49.56,提高了32。通过集合在不同时间尺度上训练的模型,我们达到了55岁以上。 |
| Dynamic Graph Representation for Partially Occluded Biometrics Authors Min Ren, Yunlong Wang, Zhenan Sun, Tieniu Tan 由于各种遮挡的不利影响,卷积神经网络CNN的生物特征识别能力大大下降。为此,我们提出了一个新颖的统一框架,该框架结合了CNN和图形模型的优点,以学习用于生物特征识别遮挡问题的动态图形表示,称为动态图形表示DGR。通过图生成器将卷积特征重新构建到某些区域上,以建立生物识别特征的空间部分之间的连接,并基于这些节点表示来构建特征图。特征图的每个节点对应于输入图像的特定部分,边缘表示部分之间的空间关系。通过分析节点之间的相似性,该框架能够自适应地删除代表被遮挡部分的节点。在动态图匹配期间,我们提出了一种新颖的策略来测量节点和相邻矩阵之间的距离。以这种方式,所提出的方法比基于CNN的方法更具说服力,因为动态图方法暗示了对生物识别决策的更多说明和合理推断。在虹膜和面部上进行的实验证明了所提出框架的优越性,与基线方法相比,该框架大大提高了遮挡生物特征识别的准确性。 |
| End to End Trainable Active Contours via Differentiable Rendering Authors Shir Gur, Tal Shaharabany, Lior Wolf 我们提出一种迭代分割多边形的图像分割方法。在每次迭代中,基于2D位移图的局部值(通过编码器解码器体系结构从输入图像中推断出)来移动多边形的顶点。使用的主要训练损失是多边形形状与地面真值分割蒙版之间的差异。该网络使用神经渲染器从其顶点创建多边形,从而使过程完全可区分。我们证明了我们的方法在包括医疗成像和航拍图像在内的各种基准测试中均优于最新的分割网络和深度主动轮廓解决方案。我们的代码位于 |
| Learning to Relate from Captions and Bounding Boxes Authors Sarthak Garg, Joel Ruben Antony Moniz, Anshu Aviral, Priyatham Bollimpalli 在这项工作中,我们提出了一种新颖的方法,该方法通过依靠图像标题和对象边界框注释作为监督的唯一来源,以弱监督的方式预测图像中各个实体之间的关系。我们提出的方法使用自上而下的注意力机制将标题中的实体与图像中的对象对齐,然后利用标题的句法结构来对齐关系。我们使用这些对齐方式来训练一个关系分类网络,从而获得接地字幕和密集关系。通过在图像中存在的关系上实现回忆15的回忆50和回忆25的回忆100,我们在视觉基因组数据集上证明了我们模型的有效性。我们还显示该模型成功地预测了在相应字幕中不存在的关系。 |
| Exploiting Motion Information from Unlabeled Videos for Static Image Action Recognition Authors Yiyi Zhang, Li Niu, Ziqi Pan, Meichao Luo, Jianfu Zhang, Dawei Cheng, Liqing Zhang 旨在识别基于单个图像的动作的静态图像动作识别通常依赖于昂贵的人类标记工作,例如足够的标记动作图像和大规模标记图像数据集。相反,可以经济地获得大量未标记的视频。因此,探索了一些使用无标签视频来促进图像动作识别的作品,可以将其分为以下两类:a。在无标签视频上使用设计的代理任务来增强动作图像的视觉表示,这属于自我监督学习的范围b使用从未标记视频中获悉的生成器生成动作图像的辅助表示。在本文中,我们将上述两种策略整合在一个统一的框架中,该框架由视觉表示增强VRE模块和运动表示增强MRA模块组成。具体地,VRE模块包括代理任务,该代理任务对未标记的视频施加伪运动标签约束和时间相干约束,而MRA模块可以通过利用未标记的视频来预测静态动作图像的运动信息。我们基于带有有限标签数据的四个基准人类行为数据集展示了我们框架的优越性。 |
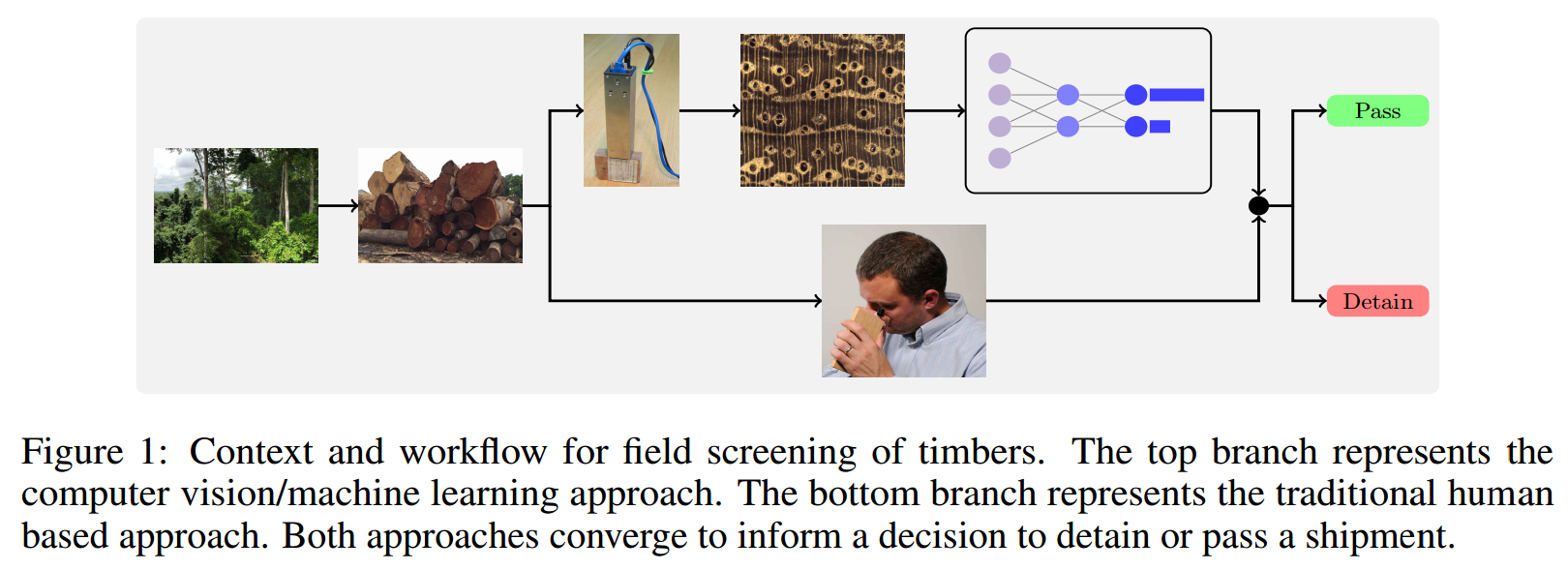
| Image Based Identification of Ghanaian Timbers Using the XyloTron: Opportunities, Risks and Challenges Authors Prabu Ravindran, Emmanuel Ebanyenle, Alberta Asi Ebeheakey, Kofi Bonsu Abban, Ophilious Lambog, Richard Soares, Adriana Costa, Alex C. Wiedenhoeft 如果木材视觉系统可以在野外有效部署,则有潜力使生产国和消费国都有权打击非法伐木。在工发组织的支持下,作为一项积极的国际合作伙伴关系而开展的这项工作,我们构建并整理了与田间相关的图像数据集,以训练使用XyloTron系统对加纳15种商业木材进行木材识别的分类器。我们在实验室中测试了模型性能,然后使用多个XyloTron设备在多个站点上收集了实际的现场性能数据。我们介绍了经过训练的模型在实验室和现场的效率,讨论了部署机器学习木材识别模型的实际含义和挑战,并得出结论认为,现场测试是必不可少的步骤,应被视为验证计算机视觉木材识别的金标准系统。 |
| A Programmatic and Semantic Approach to Explaining and DebuggingNeural Network Based Object Detectors Authors Edward Kim, Divya Gopinath, Corina Pasareanu, Sanjit Seshia 即使深度神经网络已经非常有效地执行视觉和感知任务,但仍然难以解释和调试其行为。在本文中,我们提出了一种程序和语义方法来解释,理解和调试基于神经网络的感知系统的正确和不正确的行为。我们的方法具有语义,因为它采用了检测器要处理的环境场景分布的高级表示形式。这是程序性的,该表示形式是特定领域概率性编程语言中的程序,使用该语言可以生成合成数据来训练和测试神经网络。我们提出了一个框架,该框架评估神经网络的性能以识别正确和错误的检测,从语义上表征正确和错误场景的结果中提取规则,然后使用这些规则专门研究概率程序,以便更精确地描述场景其中神经网络是否正确运行,而无需人工干预即可识别重要特征。我们使用SCENIC概率编程语言和基于神经网络的对象检测器演示了我们的结果。我们的实验表明,可以自动生成紧凑的规则,从而显着提高网络的正确检测率或相反的错误检测率,从而有助于调试和了解其行为。 |
| Morphing and Sampling Network for Dense Point Cloud Completion Authors Minghua Liu, Lu Sheng, Sheng Yang, Jing Shao, Shi Min Hu 3D点云完成是从局部点云推断出完整几何形状的任务,已引起了社区的关注。为了获得高保真密度的点云并避免不均匀分布,细节模糊或现有方法结果的结构损失,我们提出了一种新颖的方法来分两个阶段完成部分点云。具体来说,在第一阶段,该方法使用参数化表面元素的集合来预测完整但粗粒度的点云。然后,在第二阶段,它通过一种新颖的采样算法将粗粒度预测与输入点云合并。我们的方法利用联合损失函数来指导点的分布。大量的实验验证了我们方法的有效性,并证明它在推土机距离EMD和倒角距离CD中都优于现有方法。 |
| Biometric Recognition Using Deep Learning: A Survey Authors Shervin Minaee, Amirali Abdolrashidi, Hang Su, Mohammed Bennamoun, David Zhang 在过去的几年中,基于深度学习的模型已经在许多计算机视觉,语音识别和自然语言处理任务中取得了最先进的成果,并且非常成功。这些模型似乎很自然地适合处理从手机身份验证到机场安全系统的日益扩大的生物识别问题。近年来,基于深度学习的模型已越来越多地用于提高不同生物识别系统的准确性。在这项工作中,我们对120多种有前途的生物识别识别工作进行了全面调查,包括面部,指纹,虹膜,掌纹,耳朵,语音,签名和步态识别,这些研究部署了深度学习模型,并展示了它们的优势和潜力。不同的应用程序。对于每种生物特征识别,我们首先介绍文献中广泛使用的可用数据集及其特征。然后,我们将讨论为该生物识别技术开发的一些有前途的深度学习作品,并在流行的公共基准上展示它们的性能。我们还将讨论在使用这些模型进行生物识别时的一些主要挑战,以及该领域研究的未来可能方向。 |
| Averaging Essential and Fundamental Matrices in Collinear Camera Settings Authors Amnon Geifman, Yoni Kasten, Meirav Galun, Ronen Basri 近年来,从Motion构造结构的全球方法越来越流行。全局方法的一个重大缺点是它们对共线相机设置的敏感性。在本文中,我们介绍了一种分析和算法,用于当子集或所有摄影机中心共线时平均双焦点张量基本矩阵或基本矩阵。 |
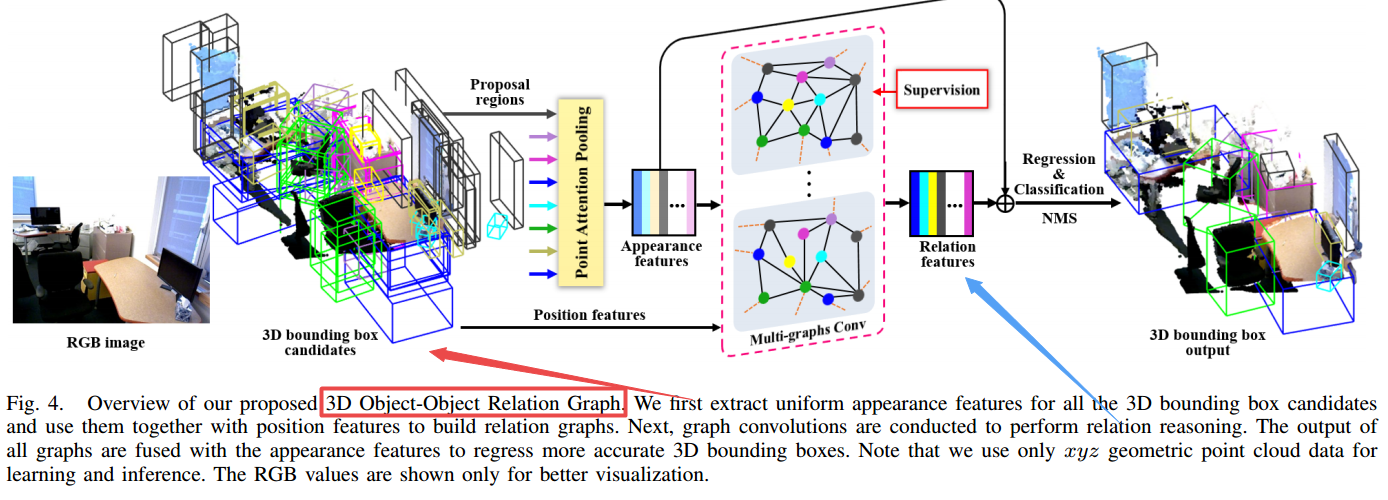
| Relation Graph Network for 3D Object Detection in Point Clouds Authors Mingtao Feng, Syed Zulqarnain Gilani, Yaonan Wang, Liang Zhang, Ajmal Mian 卷积神经网络CNN已成为2D图像上大多数对象检测任务的强大策略。但是,没有直接实现在点云中检测3D对象而不将其转换为规则网格的功能。现有技术水平的3D对象检测方法旨在单独识别3D对象而不在学习或推理期间利用它们的关系。在本文中,我们首先提出一种将方向矢量和伪几何中心的预测相关联的策略,从而为3D边界框候选者回归提供双赢解决方案。其次,我们提出了点注意力集中机制,以从学习到的方向特征,语义特征和目标点的空间坐标中受益,为每个3D目标提议提取统一的外观特征。最后,外观特征与位置特征一起用于为所有提案建模其共存的3D对象对象关系图。我们探讨了关系图对有监督和无监督设置下提案外观特征增强的影响。所提出的关系图网络由3D对象提议生成模块和3D关系模块组成,使其成为端到端可训练网络,用于在点云中检测3D对象。在具有挑战性的基准的3D点云SunRGB Dand ScanNet数据集上进行的实验表明,我们的算法可以比现有的现有方法更好地执行。 |
| EM-NET: Centerline-Aware Mitochondria Segmentation in EM Images via Hierarchical View-Ensemble Convolutional Network Authors Zhimin Yuan, Jialin Peng 尽管深层编码器解码器网络已实现了从电子显微镜EM图像中进行线粒体分割的惊人性能,但它们仍会产生具有许多不连续性和误报的粗略分割。此外,对大型3D数据集的劳动密集型注释和3D模型的巨大内存开销的需求也是主要的限制。为了解决这些问题,我们引入了一个名为EM Net的多任务网络,其中包括一个辅助中心线检测任务,以解决由中心线表示的线粒体的形状信息。因此,中心线检测子网能够提高分割任务的准确性和鲁棒性,尤其是在只有少量注释数据可用时。为了实现轻量级的3D网络,我们引入了一种新颖的分层视图集成卷积模块,以减少参数数量,并促进多视图信息的聚合。公开基准测试的验证显示了EM Net的最新性能。即使训练数据大大减少,我们的方法仍然显示出令人鼓舞的结果。 |
| Pruning at a Glance: Global Neural Pruning for Model Compression Authors Abdullah Salama, Oleksiy Ostapenko, Tassilo Klein, Moin Nabi 深度学习模型由于其高性能而已成为多个领域的主导方法。不幸的是,操作此类模型的大小和因此的计算要求可能相当高。因此,这构成了在诸如移动电话或嵌入式系统之类的受存储器和电池限制的设备上部署的限制。为了解决这些限制,我们提出了一种新颖而简单的修剪方法,该方法通过根据整个网络中的全局阈值删除整个过滤器和神经元来压缩神经网络,而无需进行任何层敏感度的预先计算。生成的模型是紧凑的,非稀疏的,具有与非压缩模型相同的准确性,最重要的是,不需要特殊的部署基础结构。我们通过在CIFAR10上生成高度压缩的模型(分别为VGG 16,ResNet 56和ResNet 110)而没有与基线相比损失任何性能,以及在ImageNet上生成ResNet 34和ResNet 50而又没有明显损失的情况下,证明了该方法的可行性。准确性。我们还提供了经过良好训练的30压缩ResNet 50,略高于基本模型的精度。此外,分别压缩AlexNet和LeNet 5的56和97以上。有趣的是,所得模型修剪模式与使用层敏感度预先计算步骤的其他方法高度相似。我们的方法不仅表现出良好的性能,而且更易于实现。 |
| Urban Driving with Conditional Imitation Learning Authors Jeffrey Hawke, Richard Shen, Corina Gurau, Siddharth Sharma, Daniele Reda, Nikolay Nikolov, Przemyslaw Mazur, Sean Micklethwaite, Nicolas Griffiths, Amar Shah, Alex Kendall 手工为现实世界中的城市自动驾驶制定通用的决策规则非常困难。另外,从易于收集的人类驾驶示范中学习行为也很有吸引力。先前的工作研究了用于自动驾驶的模仿学习IL,但有很多限制。示例包括仅执行车道跟随而不是遵循用户定义的路线,仅使用单个摄像机视图或缺少状态可观察性的大量裁剪的帧,仅使用横向转向控制,而不使用纵向速度控制以及与交通的交互作用。重要的是,大多数这样的系统已经在仿真中被评估为一个简单的领域,它缺乏现实世界的复杂性。受这些挑战的驱使,我们专注于通过人类驾驶演示利用计算机视觉为IL学习语义,几何和运动的表示形式。作为我们的主要贡献,我们提出了一种端到端的条件模仿学习方法,该方法将真实车辆上的横向和纵向控制相结合,以遵循具有简单交通的城市路线。我们通过数据平衡解决固有的数据集偏差,在六个月内收集的大约30个小时的演示中训练了我们的最终政策。我们通过在欧洲城市街道上驾驶35公里的新颖路线来评估我们在自动驾驶汽车上的方法。 |
| Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers Authors Shady Abu Hussein, Tom Tirer, Raja Giryes 单图像超分辨率任务是过去十年中研究最多的逆问题之一。近年来,当采集过程使用固定的已知下采样内核(通常是双三次内核)时,深度神经网络DNN表现出优于其他方法的性能。但是,最近的一些工作表明,在实际情况下,测试数据与训练数据不匹配,例如当下采样内核不是双三次内核或无法在训练中使用时,领先的DNN方法会遭受巨大的性能下降。受到有关广义采样的文献的启发,在这项工作中,我们提出了一种方法,用于提高已使用固定核根据其他核所获得的观测值进行训练的DNN的性能。对于已知的内核,我们设计了一种封闭形式的校正过滤器,该过滤器修改了低分辨率图像以匹配由另一个内核(例如双三次的,从而改善了现有的预训练DNN的结果。对于未知内核,我们扩展了这一思想并提出了一种算法,用于盲目估计所需的校正滤波器。我们证明了我们的方法优于其他为一般下采样内核设计的超分辨率方法。 |
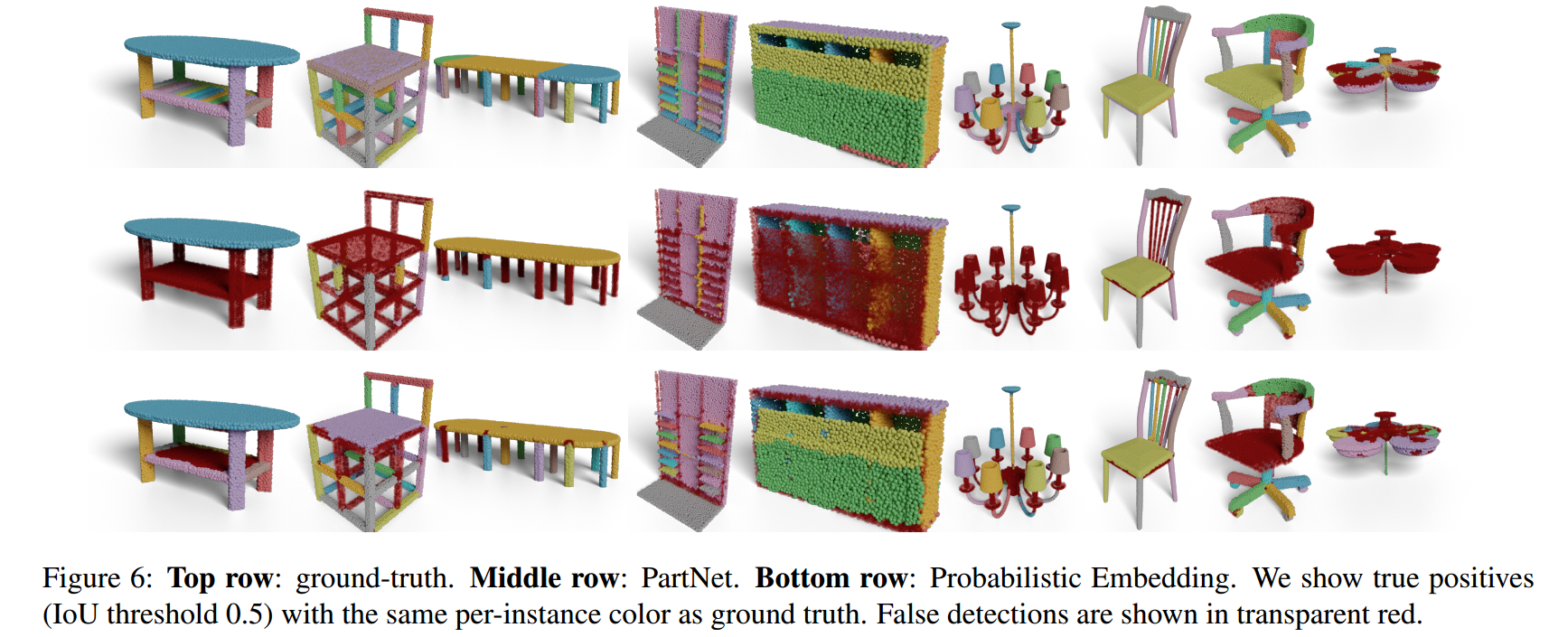
| Point Cloud Instance Segmentation using Probabilistic Embeddings Authors Biao Zhang, Peter Wonka 在本文中,我们提出了一个新的点云实例分割框架。我们的框架有两个步骤:嵌入步骤和聚类步骤。在嵌入步骤中,我们的主要贡献是为点云嵌入提出了一个概率嵌入空间。具体来说,每个点都表示为三变量正态分布。在聚类步骤中,我们提出了一种新颖的损失函数,该函数既有利于语义分割又有利于聚类。我们的实验结果表明对SOTA进行了重要改进,即在PartNet数据集上每个类别的mAP平均增加了3.1。 |
| Learning Rate Dropout Authors Huangxing Lin, Weihong Zeng, Xinghao Ding, Yue Huang, Chenxi Huang, John Paisley 深度神经网络的性能高度依赖于其训练,而寻找更好的局部最优解是许多优化算法的目标。但是,现有的优化算法显示出对下降路径的偏好,该下降路径收敛缓慢并且不试图避免不良的局部最优。在这项工作中,我们提出了学习率下降LRD,这是一种用于训练与坐标系下降有关的简单梯度下降技术。 LRD通过在每次迭代中将一些学习率随机设置为零来从经验上帮助优化器积极探索参数空间,仅更新学习率不为0的参数。随着不同参数的学习率下降,优化器将为当前更新采样一条新的损耗下降路径。下降路径的不确定性有助于模型避免出现鞍点和不良的局部极小值。实验表明,LRD在加速训练同时防止过度拟合方面出奇地有效。 |
| Sub-pixel matching method for low-resolution thermal stereo images Authors Yannick Wend Kuni Zoetgnande, Geoffroy Cormier, Alain J r me Foug res, Jean Louis Dillenseger 在本地化和跟踪应用程序的上下文中,我们开发了基于廉价的低分辨率80x60像素热像仪的立体视觉系统。我们提出了一种用于子像素热的三重子像素立体匹配框架,称为ST。1基于相位一致性的鲁棒特征提取方法; 2基于像素精度的这些特征的粗略匹配;以及3基于局部相位相干性的子像素精度的精细匹配。我们对非常低分辨率的热图像进行了实验,这些热图像是使用立体声系统获得的,该立体声系统的生产与从基准数据集中的高分辨率图像相同。即使相位一致性计算时间很高,它也可以提取比ORB或SURF等最新技术高出两倍的特征。我们提出了相位相关性的改进版本,应用于相位一致性特征空间中,用于子像素匹配。使用模拟立体声,我们研究了相位一致性阈值和子像素匹配的子图像大小如何影响精度。然后,我们证明了在给定立体声设置和图像分辨率的情况下,错误1个像素会导致该点的Z位置出现500 mm的误差。最后,我们证明了在低分辨率图像上,我们的方法可以比基线方法ORB OpenCV KNN匹配提取出四倍的匹配。而且,我们的比赛更加强劲。更准确地说,当站立的人的投影点时,当ORB OpenCV KNN给出1000毫米以上时,ST的标准偏差为300毫米。 |
| A Free Lunch in Generating Datasets: Building a VQG and VQA System with Attention and Humans in the Loop Authors Jihyeon Janel Lee, Sho Arora 尽管它们在训练人工智能系统中很重要,但是获取大型数据集仍然具有挑战性。例如,ImageNet数据集需要1400万个基本人类知识标签,例如图像是否包含椅子。不幸的是,这种知识是如此简单,以至于对于人类注释者而言是乏味的,但是也足够隐蔽,以至于它们是必需的。但是,人为完成诸如标记大量数据的任务而进行的协作工作成本高昂,不一致且容易出错,并且这种方法无法解决所得数据集本质上是静态的问题。如果我们问人们要回答的问题并将其作为数据收集起来,那将意味着我们可以以低得多的成本收集数据,而扩展数据集将仅仅是问更多问题的问题。我们将重点放在视觉问题解答VQA的任务上,并提出一个使用视觉问题生成VQG产生问题,向社交媒体用户询问问题并收集其回答的系统。我们提出了两个模型,这些模型可以比以前的基线更好地解析嘈杂的人为回答中的干净答案,目标是最终将答案合并到可视问题解答VQA数据集中。通过演示我们的系统如何以极少或几乎没有成本的方式收集大量数据,我们设想了将来将使用类似的系统来提高其他任务的性能。 |
| FusionMapping: Learning Depth Prediction with Monocular Images and 2D Laser Scans Authors Peng Yin, Jianing Qian, Yibo Cao, David Held, Howie Choset 通常,获取准确的三维深度信息需要昂贵的多光束LiDAR设备。最近,研究人员通过从二维彩色图像中预测深度信息,开发出了一种较便宜的选择。但是,从二维图像估计的深度信息与真实的LiDAR点云之间在精度上仍然存在很大差距。在本文中,我们介绍了一种基于融合的深度预测方法,称为FusionMapping。这是将彩色图像和二维激光扫描融合以估计地层深度的第一种方法。更具体地说,我们提出了一种基于自动编码器的深度预测网络和一种用于深度估计的新型点云优化网络。我们在KITTI LiDAR里程表数据集和室内移动机器人系统上分析了FusionMapping方法的性能。结果表明,与现有方法相比,我们引入的方法可以更好地估算深度。 |
| Learning Perceptual Inference by Contrasting Authors Chi Zhang, Baoxiong Jia, Feng Gao, Yixin Zhu, Hongjing Lu, Song Chun Zhu 在图片中思考,即对人类而言毫不费力且瞬时的空间时间推理,即一种进行逻辑归纳的重要能力,以及在技术发展的智力史中的关键因素。在海量数据集,更深层的模型和强大的计算的推动下,现代人工智能AI进入了一个阶段,在某些特定任务中可以观察到超人水平的性能。但是,目前的AI在图片中思考的能力仍然远远落后。在这项工作中,我们研究如何在这种Raven的渐进式矩阵RPM一项具有挑战性的任务上提高机器推理能力。具体来说,我们从心理学,认知和教育领域借用了对比效果的构想,以设计和训练置换不变模型。受认知研究的启发,我们为模型配备了一个简单的推理模块,该模块与感知主干共同训练。结合所有元素,我们提出了对比感知推理网络CoPINet,并通过经验证明了CoPINet为两个主要数据集上的排列不变模型设置了最新的技术水平。我们得出的结论是,空间时间推理取决于设想与对象之间的关系一致的可能性,并且可以从像素级输入中解决。 |
| OptiBox: Breaking the Limits of Proposals for Visual Grounding Authors Zicong Fan, Si Yi Meng, Leonid Sigal, James J. Little 由于语言基础在更通用的图像语言高级推理任务(例如图像字幕,VQA)中起着关键作用,近年来语言基础问题引起了人们的广泛关注。尽管在视觉接地方面取得了巨大进步,但是大多数方法的性能都受到了最近所有管道的早期阶段中获得的边界框建议书质量的阻碍。为了解决此限制,我们提出了一种通用的渐进式查询引导边界框优化架构OptiBox,该架构利用全局图像编码来添加上下文。我们在2016年首次引入的GroundeR模型的上下文中应用了此体系结构,该模型具有许多独特而吸引人的属性,例如能够通过利用循环语言重构在半监督的环境中学习。使用我们建议的GroundeR OptiBox和简单的语义语言重建损失,我们可以在Flickr30k Entities数据集的监督设置下达到最先进的接地性能。更重要的是,我们仅用50个训练数据就可以超越许多最新的完全受监督的模型,并且竞争性低至3。 |
| Prior-based Domain Adaptive Object Detection for Adverse Weather Conditions Authors Vishwanath A. Sindagi, Poojan Oza, Rajeev Yasarla, Vishal M. Patel 不利的天气条件(例如雨水和阴霾)破坏了捕获图像的质量,这导致在纯净图像上训练的检测网络在这些图像上的性能较差。为了解决这个问题,我们提出了一种无监督的基于先验的领域对抗对象检测框架,用于使检测器适应不同的天气条件。我们观察到,由于不同的天气条件而导致的损坏,我遵循了物理原理,因此可以进行数学建模,并且通常会导致特征空间退化,从而导致检测性能下降。出于这些动机,我们建议使用通过图像形成原理获得的特定于天气的先验知识来定义新颖的先验对抗损失。用于训练适应过程的先前对抗损失旨在通过减少特征中的天气特定信息来产生天气不变特征,从而减轻天气对检测性能的影响。此外,我们在对象检测管道中引入了一组残差特征恢复块,以使特征空间失真,从而实现进一步的改进。在不同的数据集(如有雾的城市景观,多雨的城市景观,RTTS和UFDD)上进行评估时,所提出的框架在很大程度上优于所有现有方法。 |
| SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans Authors Angela Dai, Christian Diller, Matthias Nie ner 我们提出一种新颖的方法,通过推断未观察到的场景几何,将部分和嘈杂的RGB D扫描转换为高质量的3D场景重建。我们的方法是完全自我监督的,因此可以仅在现实世界中进行不完整的扫描培训。为了实现自我监控,我们从给定的不完整3D扫描中删除帧,以使其更加不完整,然后通过关联同一扫描的两个局部性级别,同时掩盖从未观察到的区域来制定更不完整的自我监控。通过在大型训练集上进行归纳,我们可以预测3D场景的完成情况,而无需看任何完整的几何图形的3D扫描。结合新的3D稀疏生成神经网络体系结构,我们的方法能够以粗略到精细的分层方式预测高度详细的表面,以2cm的分辨率生成3D场景,是现有技术水平的两倍以及在重建质量上要远远超过它们。 |
| Adversarial normalization for multi domain image segmentation Authors Pierre Luc Delisle, Benoit Anctil Robitaille, Christian Desrosiers, Herve Lombaert 图像归一化是医学成像中的关键步骤。此步骤通常在每个数据集的基础上完成,从而阻止了当前的分割算法充分利用跨多个数据集联合归一化信息的全部潜力。为了解决这个问题,我们提出了一种针对图像分割的对抗标准化方法,该方法学习了跨多个数据集的通用标准化函数,同时又保留了图像真实性。对抗训练提供了一种最佳的归一化方法,该方法可以提高分割精度和对不现实的归一化功能的区分。因此,我们的贡献利用了来自多个领域的通用影像信息。我们的常规归一化方法的最佳性是通过结合婴儿和成人的大脑图像来评估的。具有挑战性的iSEG和MRBrainS数据集的结果揭示了对抗性归一化方法进行细分的潜力,Dice较基准提高了59.6。 |
| KernelNet: A Data-Dependent Kernel Parameterization for Deep Generative Modeling Authors Yufan Zhou, Changyou Chen, Jinhui Xu 使用内核学习是现代机器学习中经常使用的工具。用于此类学习的标准方法使用预定义的内核,该内核需要仔细选择超参数。为了减轻这种负担,我们在本文中提出了一个框架,该框架基于深度神经网络参数化的内核的随机特征和隐式频谱分布傅里叶变换,构造和学习依赖数据的内核。我们称其为构建的网络em KernelNet,并将其应用于各种情况下的深度生成建模,包括MMD GAN的变体和隐式的Variational Autoencoder VAE(深度生成模型中的两种流行的学习范例)。大量的实验证明了所提出的KernelNet的优势,与相关方法相比,始终可以实现更好的性能。 |
| Applying Knowledge Transfer for Water Body Segmentation in Peru Authors Jessenia Gonzalez, Debjani Bhowmick, Cesar Beltran, Kris Sankaran, Yoshua Bengio 在这项工作中,我们提出了卷积神经网络在卫星图像中分割水体的应用。我们首先使用U Net模型的变体从秘鲁的高分辨率图像中分割河流和湖泊。为了避免稀缺标签数据的问题,我们研究了基于知识转移的模型的适用性,该模型从高分辨率标签图像中学习映射,并将其与非常高分辨率的映射相结合,从而可以实现更好的分割。我们通过一个端到端的单一过程来训练该模型。我们的初步结果表明,从可用的高分辨率图像中添加信息无助于开箱即用,实际上会使结果更糟。这使我们推断出高分辨率数据可能来自不同的分布,并且其相加会导致结果差异增加。 |
| Augmented Reality for Human-Swarm Interaction in a Swarm-Robotic Chemistry Simulation Authors Sumeet Batra, John Klingner, Nikolaus Correll 我们提出了一种在增强现实显示中注册机器人群体的各个成员的方法,同时向用户显示有关群体动态的相关信息,否则这些信息将被隐藏。群体中的单个群体成员和集群通过它们的颜色以及在与邻居眨眼的时间间隔不同的特定时间间隔闪烁来标识。我们表明,该问题是图着色问题的一个实例,可以在O log n时间内以分布式方式解决。我们使用群体化学模拟演示了我们的方法,其中机器人按照化学规则模拟形成分子的单个原子。然后,使用增强现实来显示有关单个群体成员的内部状态及其拓扑关系(对应于分子键)的信息。 |
| Detecting mechanical loosening of total hip replacement implant from plain radiograph using deep convolutional neural network Authors Alireza Borjali, Antonia F. Chen, Orhun K. Muratoglu, Mohammad A. Morid, Kartik M. Varadarajan 普通射线照相术广泛用于检测全髋关节置换THR植入物的机械松动。当前,放射线照片是由医学专业人员手动评估的,这可能导致观察者之间和内部观察者的可靠性较差且准确性较低。此外,手动检测THR植入物的机械松动需要经验丰富的临床医生,他们可能并不总是很容易获得,可能会导致诊断延迟。在这项研究中,我们提出了一种新颖的,全自动且可解释的方法,可使用深度卷积神经网络CNN从平片上检测出THR植入物的机械松动。我们使用五次交叉验证对40例前后髋部X射线进行了CNN训练,并将其与大剂量董事会认证的骨科外科医生AFC进行了比较。为了增加对机器结果的信心,我们还实施了显着图以可视化CNN进行诊断的位置。在诊断THR植入物的机械性松动方面,CNN的表现优于整形外科医师,在敏感性0.94方面明显高于整形外科医师0.53,而特异性为0.96。显着性图显示,CNN会查看临床相关特征进行诊断。此类CNN可用于对THR植入物的机械松动进行自动放射学评估,以补充从业者的决策过程,提高其诊断准确性,并使他们能够从事更多以患者为中心的护理。 |
| Efficient Relaxed Gradient Support Pursuit for Sparsity Constrained Non-convex Optimization Authors Fanhua Shang, Bingkun Wei, Hongying Liu, Yuanyuan Liu, Jiacheng Zhuo 大规模的非凸稀疏约束问题最近得到了广泛的关注。大多数现有的确定性优化方法(例如GraSP)不适用于大规模和高维问题,因此具有硬阈值的随机优化方法(例如SVRGHT)变得更具吸引力。受GraSP的启发,本文提出了一种新的通用松弛梯度支持追踪RGraSP框架,该子算法只需要满足松弛下降条件即可。我们还设计了两种特定的半随机梯度硬阈值算法。特别是,我们的算法比SVRGHT具有更少的硬阈值操作,并且它们的平均每次迭代成本要低得多,即SVRGHT的O d vs.O d log d,这导致了更快的收敛速度。我们在合成和真实数据集上的实验结果表明,我们的算法优于现有的梯度硬阈值方法。 |
| An Attention-Based Speaker Naming Method for Online Adaptation in Non-Fixed Scenarios Authors Jungwoo Pyo, Joohyun Lee, Youngjune Park, Tien Cuong Bui, Sang Kyun Cha 说话人命名任务可以找到并识别某个电影或戏剧场景中的活动说话人,这对于处理高级视频分析应用程序(例如自动字幕标注和视频摘要)至关重要。现代方法通常利用基于梯度的方法而非基于规则的算法来开发生物特征。但是,在某些情况下,基于朴素渐变的方法无法有效工作。例如,当将新角色添加到目标标识列表时,需要频繁地训练神经网络以标识新人,这会导致模型准备工作的延迟。在本文中,我们提出了一种基于注意力的方法,该方法通过在线适应更新新添加的数据而无需梯度更新过程,从而减少了模型建立时间。我们比较了三种评估指标的准确性,内存使用率,基于注意力的方法的建立时间以及在扬声器命名的各种受控设置下现有的基于梯度的方法。此外,我们将现有的说话人命名模型和基于注意力的模型应用于真实视频,以证明我们的方法显示出与现有技术水平模型相当的准确性,在某些情况下甚至具有更高的准确性。 |
| Flow Contrastive Estimation of Energy-Based Models Authors Ruiqi Gao, Erik Nijkamp, Diederik P. Kingma, Zhen Xu, Andrew M. Dai, Ying Nian Wu 本文研究了一种联合估计基于能量的模型和基于流量的模型的训练方法,其中基于共享的对抗值函数对两个模型进行迭代更新。这种联合训练方法具有以下特点。 1基于能量的模型的更新基于噪声对比估计,而流动模型充当了强大的噪声分布。 2流程模型的更新大约使流程模型和数据分布之间的Jensen Shannon差异最小。 3与生成对抗网络GAN估计由生成器模型定义的隐式概率分布不同,我们的方法估计数据上的两个显式概率分布。使用所提出的方法,我们证明了流动模型综合质量的显着改善,并显示了基于学习能量的模型进行无监督特征学习的有效性。此外,所提出的训练方法可以容易地适应于半监督学习。我们以最先进的半监督学习方法获得了竞争性结果。 |
| Anomaly Detection in Particulate Matter Sensor using Hypothesis Pruning Generative Adversarial Network Authors YeongHyeon Park, Won Seok Park, Yeong Beom Kim, Seok Woong Chang 世界卫生组织(WHO)提供了管理颗粒物PM含量的指南,因为当PM含量较高时,它将威胁人类健康。为了管理PM水平,首先需要测量PM值的程序。基于Beta衰减监控器BAM的PM传感器可用于精确测量PM值。但是,基于BAM的传感器不仅维护成本高昂,而且还会导致用于监测PM水平的较低空间分辨率。我们使用基于锥形元素振荡微平衡TEOM的传感器,该传感器比基于BAM的传感器需要的成本更低,以此作为提高空间分辨率以监测PM水平的一种方法。与基于BAM的传感器相比,基于TEOM的传感器的故障概率更高。在本文中,我们旨在检测故障以维护这些经济高效的传感器。在本文中,我们将来自传感器的多种故障称为异常,我们的目的是检测PM传感器中的异常。我们提出了一种以假想修剪生成对抗网络HP GAN命名的新颖架构,用于异常检测。我们通过实验提出了与其他异常检测模型的性能比较。结果表明,提出的体系结构HP GAN在异常检测时达到了最先进的性能。 |
| Fastened CROWN: Tightened Neural Network Robustness Certificates Authors Zhaoyang Lyu, Ching Yun Ko, Zhifeng Kong, Ngai Wong, Dahua Lin, Luca Daniel 现实生活中深度学习应用的快速增长伴随着严重的安全隐患。为了减轻这种不舒服的现象,已经进行了许多研究,以提供对不同深度神经网络中的脆性水平的可靠评估。除了设计对抗攻击外,过去五年还设计了证明受保护地区的量词。 Salman等人的综述工作。在凸松弛框架下统一一系列现有的验证程序。我们从此类工作中获得启发,并进一步证明了确定性CROWN Zhang等人的最优性。给定线性规划问题在轻度约束下的2018年解决方案。给定这个理论结果,就显示出不必要的基于计算的线性规划方法。然后,我们提出了一种基于优化的方法,将神经网络的鲁棒性证书收紧。在经过单独培训的各种网络上的大量实验证明了FROWN在保护较大的鲁棒区域方面的有效性。 |
| Pyramid Convolutional RNN for MRI Reconstruction Authors Puyang Wang, Eric Z. Chen, Terrence Chen, Vishal M. Patel, Shanhui Sun 从欠采样数据中快速,准确地重建MRI图像在临床实践中至关重要。基于压缩感测的方法广泛用于图像重建,但是由于迭代算法,速度较慢。近年来,基于深度学习的方法显示出令人鼓舞的进展。但是,从高度欠采样的数据中恢复精细细节仍然具有挑战性。在本文中,我们介绍了一种新颖的基于深度学习的方法,即金字塔卷积RNN PC RNN,可以从多个尺度重建图像。我们在fastMRI数据集上评估了我们的模型,结果表明,与其他方法相比,该模型取得了显着改进,并且可以恢复更多的细节。 |
| Detecting GAN generated errors Authors Xiru Zhu, Fengdi Che Equal Contribution , Tianzi Yang, Tzuyang Yu, David Meger, Gregory Dudek 尽管最新的GAN在生成超逼真的图像方面具有令人印象深刻的性能,但GAN鉴别器仍难以评估单个生成样本的质量。这是因为评估所生成图像的质量的任务不同于确定图像是真实的还是伪造的。生成的图像可能很完美,除了在单个区域之外,但仍被检测为伪造的。相反,我们提出了一种新颖的方法来检测生成的图像中错误的位置。通过将实际图像与生成的图像进行比较,我们为每个像素计算其属于真实分布还是生成的分布。此外,我们将注意力集中在对模型的远程依赖性上,这允许检测在本地合理但不是整体性的错误。为了进行评估,我们表明,与FID和IS不同,我们的错误检测可以作为单个图像的质量指标。我们利用改进的Wasserstein,BigGAN和StyleGAN来显示基于我们的指标的排名与FID分数有着显着的相关性。我们的工作为更好地了解GAN以及从GAN模型中选择最佳样本的能力打开了大门。 |
| Texture Hallucination for Large-Scale Painting Super-Resolution Authors Yulun Zhang, Zhifei Zhang, Stephen DiVerdi, Zhaowen Wang, Jose Echevarria, Yun Fu 我们的目标是超级解析数字绘画,通过高分辨率参考绘画材料合成逼真的细节,以实现非常大的缩放比例(例如8x,16x)。然而,先前的单图像超分辨率SISR方法将丢失纹理细节或引入令人不快的伪像。另一方面,基于参考的SR Ref SR方法可以在某种程度上传递纹理,但是要处理非常大的比例并保持原始输入的保真度仍然不切实际。为了解决这些问题,我们提出了一种有效的高分辨率幻觉网络,用于具有很大比例因子的有效网络结构和特征转移。为了传递更详细的纹理,我们设计了一个小波纹理损失,这有助于增强更多的高频分量。同时,为降低图像重建损失带来的平滑效果,我们进一步放松了重建约束,并降低了退化损失,以确保缩减后的超分辨率结果与低分辨率输入之间的一致性。我们还通过考虑物理尺寸和图像分辨率来收集高分辨率(例如4K分辨率绘画数据集PaintHD)。通过与SISR和Ref SR最新技术方法进行比较,我们在PaintHD上进行了广泛的实验,证明了我们方法的有效性。 |
| A Method for Computing Class-wise Universal Adversarial Perturbations Authors Tejus Gupta, Abhishek Sinha, Nupur Kumari, Mayank Singh, Balaji Krishnamurthy 我们提出了一种用于计算深度神经网络的类特定通用对抗性摄动的算法。这种扰动会在特定类别的大部分图像中引起错误分类。与以前使用迭代优化来计算通用扰动的方法不同,所提出的方法采用的扰动是神经网络权重的线性函数,因此可以更快地进行计算。该方法不需要任何训练数据并且没有超参数。攻击可在ImageNet上最先进的深度神经网络上获得34到51的虚假率,并跨模型传输。我们还研究了标准和对抗训练模型学习的决策边界的特征,以了解普遍的对抗扰动。 |
| Stochastic tissue window normalization of deep learning on computed tomography Authors Yuankai Huo, Yucheng Tang, Yunqiang Chen, Dashan Gao, Shizhong Han, Shunxing Bao, Smita De, James G. Terry, Jeffrey J. Carr, Richard G. Abramson, Bennett A. Landman 组织窗口过滤已被广泛用于计算机断层扫描CT图像分析的深度学习中,以改善训练性能,例如用于腹部CT的软组织窗口。但是,组织窗标准化的有效性值得怀疑,因为训练后的模型的可推广性可能会进一步受到损害,尤其是当这种模型应用于具有不同CT重建内核,对比机制,采集动态变化和生理变化的新队列时。我们评估在多站点CT队列中使用和不使用软组织窗口标准化的有效性。此外,我们提出了一种随机组织窗口标准化SWN方法,以提高组织窗口标准化的可推广性。与随机采样不同,SWN方法将随机化以软组织窗口为中心,以保持对腹部器官的特异性。为了评估不同策略的性能,采用了来自6个数据集的80个训练以及453个验证和测试扫描,以使用标准2D U Net进行多器官分割。六个数据集涵盖了场景,其中训练和测试扫描来自1个相同的扫描仪和相同的人口,2个相同的CT对比但病理不同,以及3个不同的CT对比和病理。传统的软组织窗口和非窗口方法在1上获得了更好的性能。拟议的SWN通过统计分析在2和3上获得了一般的优越性能,这为训练后的模型提供了更好的通用性。 |
| Hepatocellular Carcinoma Intra-arterial Treatment Response Prediction for Improved Therapeutic Decision-Making Authors Junlin Yang, Nicha C. Dvornek, Fan Zhang, Julius Chapiro, MingDe Lin, Aaron Abajian, James S. Duncan 这项工作提出了一条管道,以预测肝细胞癌HCC患者对动脉内治疗的治疗反应,从而改善治疗决策。我们的图形神经网络模型无缝结合了基线MR扫描,治疗前的临床信息和计划的治疗特征的异类输入,并已在经动脉化疗栓塞TACE治疗的HCC患者中得到验证。它达到0.713 pm 0.075的精度,0.7 pm 0.082 pm的F1和0.710 pm 0.108的AUC。此外,管道还结合了不确定性估计,以选择困难的案例,并与错误分类的案例保持一致。拟议中的管道可通过提高模型准确性和纳入不确定性评估,为肝癌患者提供更明智的动脉内治疗决策。 |
| Integrate Image Representation to Text Model on Sentence Level: a Semi-supervised Framework Authors Lisai Zhang, Qingcai Chen, Dongfang Li, Buzhou Tang 整合视觉功能已被证明对语言表示学习很有用。然而,在大多数现有的多模式模型中,视觉和文本数据的对齐是前提。在本文中,我们提出了一种用于句子级语言表示的新型半监督视觉集成框架。唯一性包括:1通过半监督方法进行集成,该方法可以通过预先训练可视化网络将图像带入文本NLU任务,2在训练和预测阶段都动态集成视觉表示。为了验证所提出框架的有效性,我们对SemEval 2018 Task 11进行了实验,并在阅读理解任务上达到了最新水平。考虑到视觉集成框架仅需要图像数据库,并且不需要额外的对齐来进行训练和预测,它为多模态语言学习提供了一种有效且可行的方法。 |
| Transferability versus Discriminability: Joint Probability Distribution Adaptation (JPDA) Authors Wen Zhang, Dongrui Wu 转移学习在一项任务中利用数据或知识来帮助解决另一项却又相关的任务。许多现有的TL方法都是基于联合概率分布度量,该度量是边际分布和条件分布的加权和,但是,它们独立地优化了两个分布,而忽略了它们的内在依赖性。本文提出了一种新颖且令人沮丧的联合概率分布自适应JPDA方法,以取代迁移学习中常用的联合最大均值差异度量。在分配适应期间,JPDA通过最小化相应类别的联合概率差异来提高源域和目标域之间的可传递性,并通过最大化它们的联合概率差异来提高不同类别之间的可辨性。在六个图像分类数据集上的实验表明,JPDA优于基于转移度量学习方法的几种最新技术。 |
| Image segmentation of liver stage malaria infection with spatial uncertainty sampling Authors Ava P. Soleimany, Harini Suresh, Jose Javier Gonzalez Ortiz, Divya Shanmugam, Nil Gural, John Guttag, Sangeeta N. Bhatia 在全球范围内根除疟疾取决于有效的药物来对抗这种疾病的安静而专心的肝脏阶段。药物开发的金标准仍然是体外细胞培养模型中肝期寄生虫的显微成像。由于这些模型中的寄生虫在大小,形状和密度方面都有很大的差异,因此图像分析在该管道中存在主要瓶颈。与其他高度可变的数据集一样,传统的分割模型依赖于手工制作的特征,因此普遍性较差,因此,手动注释肝阶段疟疾图像仍然是标准方法。为了满足这一需求,我们开发了一种卷积神经网络体系结构,该体系结构利用空间辍学采样进行肝脏阶段疟疾图像中的寄生虫分割和认知不确定性估计。我们的管道可以产生几乎与专家注释相同的高精度分割,可以很好地归纳到肝阶段疟疾寄生虫的各种数据集,并促进学习的特征图之间的独立性,从而对生成的预测的不确定性进行建模。 |
| Convolutional neural networks model improvements using demographics and image processing filters on chest x-rays Authors Mir Muhammad Abdullah, Mir Muhammad Abdur Rahman, Mir Mohammed Assadullah 目的本研究的目的是通过基于年龄,性别和14种病理图像的预处理滤波器创建不同的二值分类模型,以观察卷积神经网络CNN建模正确分类与胸部放射影像总预测的比率的准确性变化。 |
| Probing the State of the Art: A Critical Look at Visual Representation Evaluation Authors Cinjon Resnick, Zeping Zhan, Joan Bruna 在过去的五年中,自我监督研究取得了很大的进步,其中大部分增长是由难以量化比较的目标驱动的。这些技术包括着色,循环一致性和图像块的噪声对比估计。因此,该领域已经确定了一些测量方法,这些测量方法依赖于线性探针来判断哪种方法是最好的。我们的第一个贡献是证明该检验是不够的,并且在线性分类上表现不佳的模型可以在涉及时间更多的任务(如时间活动本地化)上表现很弱。我们的第二个贡献是分析五个不同表示形式的功能。我们的第三项贡献是用于时空活动本地化的急需的新数据集。 |
| SGAS: Sequential Greedy Architecture Search Authors Guohao Li, Guocheng Qian, Itzel C. Delgadillo, Matthias M ller, Ali Thabet, Bernard Ghanem 架构设计已成为成功的深度学习的关键组成部分。自动神经体系结构搜索NAS的最新进展显示出了广阔的前景。但是,发现的架构通常无法在最终评估中进行概括。在搜索阶段具有较高验证精度的体系结构在评估中可能会表现较差。为了缓解这个常见问题,我们引入了顺序贪婪架构搜索SGAS,这是一种用于神经架构搜索的有效方法。通过将搜索过程划分为子问题,SGAS以贪婪的方式选择并修剪候选操作。我们将SGAS应用于卷积神经网络CNN和图卷积网络GCN的搜索体系结构。大量的实验表明,SGAS能够以最小的计算成本为蛋白质相互作用图中的图像分类,点云分类和节点分类等任务找到最先进的体系结构。请拜访 |
| Square Attack: a query-efficient black-box adversarial attack via random search Authors Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, Matthias Hein 我们提出了方格攻击,这是一种新的基于分数的黑匣子l 2和l强悍的对抗攻击,它不依赖于局部梯度信息,因此不受梯度掩盖的影响。平方攻击是基于随机搜索方案的,其中我们在随机位置选择局部正方形更新,以使扰动的l infty或l 2范数大约等于每一步的最大预算。与更复杂的现有技术方法相比,我们的方法在算法上透明,对超参数的选择具有鲁棒性,并且查询效率明显更高。特别是,在ImageNet上,与最近的Meunier等人的Infty攻击相比,我们将各种深度网络的平均查询效率提高了至少2到7倍。同时具有较高的成功率。在成功率方面,Square Attack甚至可以胜过基于梯度的白盒攻击。此外,我们通过打破基于随机化的最近提出的防御来显示其效用。我们的攻击代码位于 |
| Learning Likelihoods with Conditional Normalizing Flows Authors Christina Winkler, Daniel Worrall, Emiel Hoogeboom, Max Welling 归一化流NFs通过在变量公式更改的情况下通过可逆神经网络转换简单的基本密度p z,可以建模具有强大的维数相关性和高多模态的复杂分布py。这种行为在多元结构化的预测任务中是理想的,在这些任务中,基于每像素损失的手工方法不足以捕获输出尺寸之间的强相关性。我们对条件归一化流CNF(一类NFs)进行研究,其中基础密度到输出空间的映射以输入x为条件,以对条件密度p y x建模。 CNF在采样和推断方面非常有效,可以基于似然性目标进行训练,并且CNF作为生成流,不会遭受模式崩溃或训练不稳定性的困扰。我们提供了一种有效的方法来训练针对二进制问题的连续CNF,尤其是,我们将这些CNF应用于超分辨率和船只分割任务,以证明在可能性和常规指标方面在标准基准数据集上的竞争表现。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com

如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- Algorand近期合作更新整理
Algorand基金会最近发布了Algorand 2.0,这是一项重要的协议升级,极大地扩展了可在Algorand平台上构建的去中心化应用程序的范围。借助所有直接内置在第1层中的新功能套件,可以创建企业级分布式应用程序的同时并不会牺牲其性能或安全性。 Algorand 与意大利作者和出版商协会S…...
2024/4/20 5:53:54 - 如何快速刷网课——直接修改学习状态为“已学完”
问题背景 在某教师培训平台上刷网课,之前破解了其进度条无法拖动的限制:破解网课视频进度条无法拖动问题 但就算进度条能拖动了,还得等视频缓存后才能拖过去。有时缓存很慢,仍然比较麻烦。于是开始探索如何不再看视频,直接将状态修改为“已学完”。 思路是:找到视频播放结…...
2024/4/24 1:42:10 - 我的Java Web之路 - Spring MVC和Spring IoC初步使用
本系列文章旨在记录和总结自己在Java Web开发之路上的知识点、经验、问题和思考,希望能帮助更多码农和想成为码农的人。 本文转发自头条号【普通的码农】的文章,大家可以关注一下,直接在今日头条的移动端APP中阅读。因为平台不同,会出现有些格式、图片、链接无效方面的问题…...
2024/4/19 20:50:59 - 部落冲突
题目背景 在一个叫做Travian的世界里,生活着各个大大小小的部落。其中最为强大的是罗马、高卢和日耳曼。他们之间为了争夺资源和土地,进行了无数次的战斗。期间诞生了众多家喻户晓的英雄人物,也留下了许多可歌可泣的动人故事。 其中,在大大小小的部落之间,会有一些道路相连…...
2024/4/12 18:16:18 - Redis
Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行360的刁难。 作为一个在互联网公司面一次拿一次Offer的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(请允许我使用一下夸张的修辞…...
2024/4/23 22:33:38 - 走进大数据丨 Hadoop生态体系
Hadoop是一个由Apache基金会所开发的分布式系统的基础架构。用户可以在不了解分布式的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop优点1.高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。2.高扩展性:Hadoop是在可用的计算机集簇间分配数据…...
2024/4/23 8:11:39 - 蠎周刊-398-MicroPython 物联网编程没问题
原文: PyCoders Weekly - Issue #398191211 Zoom.Quiet(大妈) 用时 42 分钟 完成快译 191211 Zoom.Quiet(大妈) 用时 17 分钟 完成格式转抄.------MicroPython: Python编程硬件简介REAL PYTHONAre you interested in the Internet of Things, home automation, and connected d…...
2024/4/22 19:55:02 - 假设你是个妹子
假设你是个妹子,你有一位男朋友,于此同时你和另外一位男生暧昧不清,比朋友好,又不是恋人。你随时可以甩了现任男友,另外一位马上就能补上。这是冷备份。 假设你是个妹子,同时和两位男性在交往,两位都是你男朋友。并且他们还互不干涉,独立运行。这就是双机热备份。 假设…...
2024/4/24 3:52:16 - 傅里叶分析之掐死教程
傅里叶分析之掐死教程(完整版)更新于2014.06.06Heinrich生娃学工打折腿知乎日报收录作 者:韩 昊知 乎:Heinrich微 博:@花生油工人知乎专栏:与时间无关的故事谨以此文献给大连海事大学的吴楠老师,柳晓鸣老师,王新年老师以及张晶泊老师。转载的同学请保留上面这句话,谢谢…...
2024/4/24 8:36:21 - pyspark相关配置
hadoop(配置文件都在$HADOOP_HOME/etc/hadoop)hadoop.env.sh#export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/opt/modules/jdk1.8.0_11#配置java_homecore-site.xml<configuration><property><name>fs.default.name</name><value>hdfs://pysp…...
2024/4/18 19:30:13 - final,finally,finalize的区别
一.简单区别:final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。 finally是异常处理语句结构的一部分,表示总是执行。 finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文…...
2024/4/19 18:04:40 - python中的递归
python中的递归 在函数内部调用自己本身就是递归 例如阶乘和累加 累加 def sum(n):if n == 1:return 1return n + sum(n-1) print(sum(3)) 运行结果 6 ===> sum(3) ===> 3 + sum(2) ===> 3 + (2 + sum(1)) ===> 3 + (2 + 1) ===> 6 阶乘 def fact(n):if n == 1:…...
2024/4/24 17:28:52 - sql基础教程--4
1.数据插入insert insert into 表名(列名1,列名2,列名3) values(值1,值2,值3); 字符型要是’’ 列名可以省,这样的话,从左到右进行插入数据。 可以插入null ,但是插入null值的时候,列的约束可以为空。 在创建表的时候,可以指定默认值 default 值 在插入的时候可以用关…...
2024/4/19 12:28:16 - fiddler手机抓包 手机应用显示证书无效,证书过期的决解办法
试了好多办法 手机应用都无法正常上网,最后发现是由于电脑上安装的fiddler版本太低导致,最后对fiddler进行了update,把手机上 电脑上 所有的fiddler证书都移除,重新安装,最后解决了。以下是手机和电脑删除重新安装证书的图示步骤,大家参考下:电脑删除:电脑增加:手机删…...
2024/4/8 1:29:56 - Spring的后置处理器到底是怎么回事?
这里要介绍的是Spring的扩展类点之一的:BeanPostProcessor. 废话不多说,开搞! 1.准备代码TestProcessor类@Component public class TestProcessor implements BeanPostProcessor ,PriorityOrdered{@Overridepublic Object postProcessBeforeInitialization(Object bean, String…...
2024/4/24 3:57:18 - 自学CS & Data Science 近期资源总结
学习的道路上,能够找到优质的资源,比看n多教程要强。 最近挖掘了斯坦福大学的CS主页,找到了很多有意思的资源教案,可以花点时间浏览一下对CS和自己感兴趣的主题深入了解。 0-CS启蒙: CS 101 :Introduction to Computing Principles --有视频,但是个人觉得视频效率有点低。…...
2024/3/29 4:39:46 - 实现多线程安全的3种方式
1、先来了解一下:为什么多线程并发是不安全的?在操作系统中,线程是不拥有资源的,进程是拥有资源的。而线程是由进程创建的,一个进程可以创建多个线程,这些线程共享着进程中的资源。所以,当线程一起并发运行时,同时对一个数据进行修改,就可能会造成数据的不一致性,看下…...
2024/4/20 16:28:03 - Stack
Stack 问题 一、简介 优点:Stack是线程安全的,底层是数组 缺点: 二、继承关系图是浅拷贝 Stack实现了继承Vector,具有线程安全,除了push方法,其他都加了synchornized 实现了RandomAccess接口,for 循环速度比迭代速度快 三、存储结构 四、源码分析 内部类 无 属性 无 构造…...
2024/4/18 16:08:08 - Mysql : InnoDB: Table flags are 0 in the data dictionary but the flags in file ./ibdata1 are 0x4800!
Mysql报错,是因为自己之前装的高版本然后再装低版本导致的 [FATAL] InnoDB: Table flags are 0 in the data dictionary but the flags in file ./ibdata1 are 0x4800! 2019-12-10 22:37:46 0x7f416f5ff780 InnoDB: Assertion failure in thread 139919018162048 in file ut0…...
2024/4/19 20:39:24 - vscode格式化代码
vscode格式化代码vscode格式化代码快捷键注意事项 vscode格式化代码快捷键 Shift + Alt + F 注意事项 编写lua,安装了Lua Coder Assistant,发现格式化代码时,会默认将双引号变成单引号,可以去用户设置界面,Extensions->Lua Coder Assistant Configuration->Quotemar…...
2024/4/18 20:50:39
最新文章
- DRF: 序列化器、View、APIView、GenericAPIView、Mixin、ViewSet、ModelViewSet的源码解析
前言:还没有整理,后续有时间再整理,目前只是个人思路,文章较乱。 注意路径匹配的“/” 我们的url里面加了“/”,但是用apifox等非浏览器的工具发起请求时没有加“/”,而且还不是get请求,那么这…...
2024/4/25 0:19:47 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 游戏引擎架构01__引擎架构图
根据游戏引擎架构预设的引擎架构来构建运行时引擎架构 ...
2024/4/23 6:16:08 - ASP.NET Core 标识(Identity)框架系列(一):如何使用 ASP.NET Core 标识(Identity)框架创建用户和角色?
前言 ASP.NET Core 内置的标识(identity)框架,采用的是 RBAC(role-based access control,基于角色的访问控制)策略,是一个用于管理用户身份验证、授权和安全性的框架。 它提供了一套工具和库&…...
2024/4/22 12:01:14 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/23 20:58:27 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/23 13:30:22 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/23 13:28:06 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/24 18:16:28 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/23 13:27:44 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/19 11:57:53 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/23 13:29:53 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/23 13:27:22 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/23 13:28:42 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/23 22:01:21 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/23 13:29:23 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/25 0:00:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/23 13:47:22 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/19 11:59:23 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/19 11:59:44 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/23 13:28:08 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/24 16:38:05 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/23 13:28:14 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/23 13:27:51 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/23 13:27:19 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57