Self-Supervised Representation Learning by Rotation Feature Decoupling (旋转特征解耦的自我监督表示学习)
本文是论文 Self-Supervised Representation Learning by Rotation Feature Decoupling (旋转特征解耦的自我监督表示学习)的翻译,因作者本人水平有限,难免有不妥之处,还望读者不吝赐教,谢谢!
摘要
我们介绍了一种自我监督的学习方法,该方法着眼于表示的有益特性及其在推广到实际任务中的能力。该方法将旋转不变性纳入特征学习框架,这是视觉表示的许多良好且经过充分研究的特性之一,而以前的基于深度卷积神经网络的自我监督的表示学习方法很少对此加以欣赏或利用。特别是,我们的模型学习了包含旋转相关部分和不相关部分的拆分表示。通过联合预测图像旋转和区分单个实例来训练神经网络。尤其是,我们的模型将旋转判别与实例判别解耦,这使我们能够通过减轻旋转标签噪声的影响来改进旋转预测,也可以区分实例而不考虑图像旋转。所产生的特征对更多的各种任务具有更好的通用能力。实验结果表明,在标准的自我监督特征学习基准上,我们的模型优于当前的最新方法。
1 引言
深度神经网络,尤其是卷积神经网络(ConvNets),已取得计算机视觉领域的重大突破。给定大规模手动标记的图像数据集,例如ImageNet,卷积神经网络可以通过反向传播进行良好的训练,并在许多任务上实现最先进的性能,例如图像分类[25,45]和目标检测[31]。这些网络提取的丰富表示在通常情况下,不仅可以作为训练网络的任务的良好通用功能,而且还可以用于许多其他视觉任务,例如语义分割[33]和视觉问题解答[2]。但是,以完全监督的方式训练深度神经网络需要大量的手动标记工作,这在某些实际场景中是不可行的。作为有监督的特征学习的替代方法,不依赖于昂贵且费时的人类标签的无监督方法正受到越来越多的关注。最近出现的自监督学习范式[10、43、52、27、37]是用于学习有用的通用视觉表示的可扩展且有希望的解决方案。这些方法用于使用数据本身的结构信息并定义与学习到的特征的最终应用有关的辅助(pretext)任务,以训练神经网络。在辅助(pretext)任务中,无需大量人力即可轻松开发监督信号,因此可以将大量易于获得的图像应用于训练。
在过去的几年中,已经提出了许多不同的辅助(pretext)任务来进行自我监督学习。例如,这些方法中的一类试图从另一部分本身中恢复一部分数据[43、28、53]。然而这些方法的缺点是重建和预测图像像素值通常需要大量的计算资源。深度神经网络也可以被训练来区分原始图像和恢复的不完整图像[21]。但是,生成合成图像并不总是一件容易的事。在自我监督学习中已经研究了 Siamese 网络体系结构[2,36,53],但是内存消耗通常很大。另一种不同但普遍采用的策略是在视频中发现监督信号,例如跟踪图像补丁[47]和对帧序列进行排序[30]。
现有的大多数工作都集中在设计各种辅助(pretext)任务,而很少关心学习的表示所拥有的属性以及它们是否确实有利于现实世界中任务的泛化。例如,高级表示应该传达清楚的解释或对变化因素的确定依赖性[5]。最近的尝试是预测图像旋转[17]。通过这种方法学习的特征可以很好地概括各种任务,并实现最新的性能。但是,这些特征与旋转变换是有区别的,因此不能使支持旋转不变性的视觉任务受益。此外,让人有所启发的是,并非所有的示例在实践中都是旋转可确定性的。图像的方向不仅对于圆形物体来说是模棱两可的,而且对于图像中方向不可知的其他对象也模棱两可,例如,从顶部观察的一些物品或者具有对称形状的某些物体,如图1所示。旋转这些对象不会严重影响我们的描述或理解。

图1:ImageNet中一些旋转不可知图像的示例,这些图像的默认方向不明确。
在本文中,我们提出了一种新的自监督学习算法,该算法通过一个旋转预测任务和一个实例区分任务将表示分离。学习的示例特征分别由旋转判别和旋转无关两个要素组成。旋转判别特征可以通过预测图像旋转来发现,这是简单而有效的,并且在某些基准上可以达到最新的结果[17]。对于数据集中的那些与方向无关的图像,自动分配的旋转标签通常包含噪声,这自然会导致正向的未标记学习问题。默认方向的原始图像为正实例,而旋转后的副本为未标记实例,可以为正或负。如果无法明确地识别出旋转副本的变换,我们将其视为在无标记集合中具有默认方向的正实例(请参见补充材料中的图1)。另一方面,我们通过惩罚相同图像在不同旋转下的特征之间的距离差来学习与旋转无关的特征。应用非参数方法根据这些旋转无关特征来区分不同实例。因此,这些特征将在实例级别具有判别能力。
为了证明我们的自监督学习方法的有效性,我们在标准特征转换学习基准上进行了实验。我们执行消融研究以检查模型和不同配置中的各个组件。我们还测试了旋转数据集上的特征。实验结果表明,有必要研究与旋转相关和不相关的特征。在许多方法上,包括在ImageNet和Places上的线性分类,以及在PASCAL VOC上的分类,检测和分割,我们方法中学习的特征都优于最新方法。
2 相关工作
这项工作涉及机器学习和计算机视觉中的多个主题:自监督学习,正性未标记(PU)学习和图像旋转不变性。
自我监督学习:自监督学习构建了一些直接根据输入数据计算出的监督信号。例如,某些方法尝试恢复部分数据本身,例如图像补全[43],图像上色[52、27、28]和通道预测[53]。其他方法则利用图像中的概念信息,然后构造约束,例如图像斑块位置[10、36],解决拼图游戏[37],计数[38],旋转[17]和实例判别[13、48]。依靠对抗训练的方法包括[12]和[21]。Norooziet等 [39] 和Caronet等 [6]使用聚类方法生成伪标签。除了单个任务,Doersch和Zisserman [11]以及Ren和Lee [44]还考虑一起使用多个任务来提高性能。对于视频,监督信号有:自我运动[1,42],时间相干[47,30]和声音[41]。我们的方法基于预测图像旋转[17],并考虑了学习表示所拥有的属性。我们将重点放在与旋转相关和无关的属性上。
正向未标记学习:在PU学习中,未标记的数据通常被视为负面示例,这意味着只有观察到的负面示例包含嘈杂的标签[14]。许多方法可以利用条件概率与其估计值之间的关系来建模标签错误率[46,40]。然后,标签错误的比率可通过各种方式用于处理嘈杂的观测负样本,例如排除置信度较低的样本[40],标记置信度较高的样本[49、23、19]或重加权样本[14、35、32]。但是,具有良好理论特性的PU学习方法可能无法正确扩展到使用数百万个样本训练的深度网络。在这项工作中,我们将预测图像旋转的任务作为PU学习问题进行了公式化,并通过应用未标记样本的权重来处理标签噪声。
旋转不变性:许多经典的手工制作的特征,例如用于计算机视觉的SIFT [34]和RIFT [29],对某些旋转变换都不敏感。对于最近的基于卷积网络的特征学习,一些经过精心设计的网络结构,例如G-CNN [7]和Warped Convolutions [20],在学习旋转不变特征方面表现出优异的成绩。通过数据扩充可以实现对任意变换集的不变性。Laptevet等[26]提取图像的多个旋转副本的最大池激活。Dielemanet等[9]通过组合各种变换后的特征来扩展特征图。这些不变表示学习方法主要在有监督的任务中训练。我们旨在学习以无监督的方式包含旋转无关部分的复合特征。我们的方法还依赖于数据的多个旋转副本,而我们将这种旋转信息有效地用于两个解耦的无监督任务。
3 旋转特征解耦
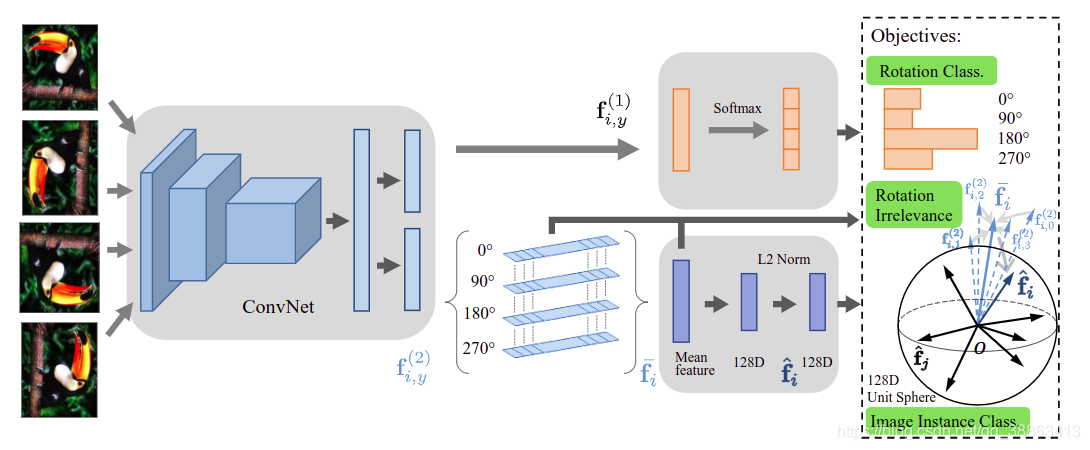
图2:提出的方法的示意图。神经网络输出一个解耦的语义特征,其中包含旋转相关和不相关的部分。通过预测图像旋转来训练第一部分。旋转标签中的噪声被建模为PU学习问题,该问题学习实例权重以减少旋转不确定图像的影响。另一部分使用非参数分类进行距离惩罚损失训练,以强制执行旋转无关性以及实例判别任务。
在本节中,我们首先回顾预测图像旋转的方法(RotNet)[17],然后将其重新表述为正向的,没有标签的学习问题,从而减轻此辅助任务设计中的先天缺陷。我们详细描述了旋转特征去耦方法,并给出了完整的模型(见图2)。
3.1 图像旋转预测
卷积网络在将原始图像映射到语义上有意义的特征向量方面特别强大,但通常使用图像及其相应的真实标签对其进行训练。为了以一种无监督的方式获得图像的通用特征,RotNet会研究图像的几何变换,特别是将图像旋转90度作为监督信号,并训练卷积网络预测其变换[17]。因此,语义有意义的表示可以在卷积网络更高层的特征图中进行编码。
给定一个训练集 ,包含N张图像,RotNet为每个图像X定义了一组旋转变换。表示第个图像进行第个变换得到的图形,。训练了一个卷积网络模型,将每个旋转的图像分类为一种转换。目标函数为:
其中代表分类问题的交叉熵损失。变换被定义为旋转几个90度,例如K=4,并且,表示将图像X逆时针旋转(y-1)* 90度。
RotNet的基本前提是旋转图像会改变图像中对象的方向,应该易于识别。为了预测图像旋转,神经网络必须识别并定位图像中的显着物体部分。因此,训练有素的神经网络可以为图像中的显着对象生成准确的特征,并且这些特征可以轻松地转移到实际任务中,例如检测和分割。
3.2 嘈杂的旋转图像
旋转预测模型中引入的先决条件可以满足大多数自然图像的需求,这些图像通常具有处于向前姿势的对象。这种图像通常具有默认方向。图像的任何旋转都会导致异常的物体方向,可以由人眼轻易地分辨。像ImageNet这样的数据集中的许多实例都有这样的图像,并且适合于旋转预测任务。
尽管具有简单性和有效性,但是这个前提会因为图像中的一些物体的方向不可知而无法满足,例如从顶部观测的物体或者对称的物体(详见图1)。在实践中,识别出这些图像的精确旋转变换是毫无意义的,并且在任何情况下都不加思考地应用卷积网络,只会将混杂因素引入到模型训练中。而且,在RotNet中学习到的特征对旋转角度是有区别的。它们在诸如浮游生物[8]和ISBI2012电子显微镜分割挑战[3]之类的与旋转无关的图像数据集中并不受欢迎。这里我们首先在下一个小节中介绍减少噪声旋转标签影响的方法,并介绍学习旋转无关特征的方法。
我们将数据集中的原始图像视为默认方向,并将其标记为正样本。未标记的样本包括所有旋转后的副本,其中某些副本在旋转后仍处于默认方向。因此,这些图像自动分配的旋转标签对于RotNet而言比较嘈杂。因此,如果所有未标记的数据都被视为负样本,则预测输入图像是否旋转是一个二分类问题[4]。在PU学习中,估计的条件概率与噪声率和样本是否干净的可信度有关[40,19]。我们提出使用估计的概率来加权每个旋转图像,并减少旋转含糊图像的相对损失。
首先,训练一个卷积网络模型进行二分类。我们用表示从该预训练模型估计图像为正的概率。我们将每个实例的权重添加到具有可调参数的交叉熵损失中,即:
可以使用计算的实例权重来重新制定目标函数(1):
可以预测图像旋转,同时减轻嘈杂样本的影响。
3.3 特征解耦
仅涉及图像旋转的图像特征对于涉及旋转不可知图像的下游任务并不实用。另一种解决方案是用与图像旋转无关的其他特征来补充与旋转相关的特征。我们通过开发特征解耦算法来实现此目标,该算法学习了一种语义特征,该语义特征在图像旋转方面具有区别性,在某种程度上与图像旋转无关。该特征的第一部分将享受从估计图像旋转的任务中继承的好处。另一部分与图像旋转无关,适用于某些方向无关的任务。
旋转分类 我们假设将图像 X高级特征表示为,其中 图像旋转显式有关,而负责与旋转变换无关的信息。使用具有参数的基于卷积网络的特征提取器,将一个输入的旋转过的图片映射到一个固定大小的向量。分类器采用特征作为输入以估计图像的旋转类型。旋转分类损失函数可以表示为:
与等式3不同,因为此处仅使用特征f的一部分来识别旋转。
旋转无关紧要 :为了实现旋转无关特征的目标,我们在具有不同旋转角度的同一图像的各个特征之间实施相似性。即:给定图像的旋转副本:,它们的特征应该尽可能彼此相似。我们通过最小化每个特征和它们的平均特征向量的距离来解决此问题,并将目标函数写为:
为了计算效率,我们采用欧几里得距离,即:。
然而,只有这个目标函数只能产生微不足道的解决方案。尽管相同图像在不同旋转角度下的特征是相似的,但是网络可以简单地输出相同矢量(例如零矢量),而与输入图像无关。因此,除了等式5,我们希望与旋转无关的特征相对于图片实例具有区分性,而不是旋转类别的区分性。可以应用非参数分类[48]来避免这种退化的解决方案。
图像实例分类:对于同一图像,在不同旋转下,特征f(2)彼此之间的相似性要比对不同图像的特征f(2)更相似。由于图像的旋转副本的特征已被约束为接近等式5中的平均特征向量,因此我们继续进行区分和散布这些平均特征。在非参数分类中,将图像X预测为数据集中第i个实例的概率为:
其中是的归一化版本,是温度参数。给定训练数据集S,我们关注于最小化负对数似然:
为了减轻在大型数据集上计算等式7的时间和空间,我们在归一化之前将均值特征线性映射到128维矢量,并采用噪声常数估计(NCE)和近端正则化[48]。目的是最小化以下损失函数:
其中。代表实际数据的分布,代表NCE中噪声的均匀分布。是另一个图像的归一化特征。
生成的模型包含三个核心模块:旋转分类(Eq.4),旋转不相关(Eq.5)和图像实例分类(Eq.8),可以写成:
我们将和串联起来表示一个输入图像。图像特征由与旋转相关和不相关的组件组成,这两个组件均包含丰富的高级语义图像表示。将包含必要的信息,例如显着物体的位置及其默认方向,以预测图像旋转。另一方面,没有与旋转有关的信息,而是更多地关注每个图像的差异。
4 实验
在本节中,我们进行实验以证明我们方法的有效性。如果以无监督的方式学习到的视觉表示是有效且通用的,它们将很好地推广到各种任务。首先,我们定性地分析了通过该算法学习到的网络。然后,我们在几个标准的迁移学习基准上报告结果。
4.1 实现细节
为了与以前的工作进行比较,我们使用由pytorch [24]实现的标准AlexNet体系结构,减少它的通道数作为特征提取器。它由五个卷积层和两个全连接层组成。我们省略了局部响应归一化(LRN)层,并在每个线性层之后添加了批归一化(BN),这是最近的自监督学习方法中的常见的过程[10,52,12,53, 17,48,44 ,6]。将解耦的特征和简单设置为具有相同的尺寸,即将表示分为两半。我们使用一层线性网络实现旋转分类器。在我们的模型中,,和分别设置为2,0.07和4096。我们简单的将用于损失平衡的参数,和都设置为1。我们在ILSVRC 2012训练集上将模型训练了总共200个epoch。最初将学习率设置为0.01,然后在前90个周期后每40个周期衰减10倍。训练网络使用0.9的动量,192的批量大小,权重的惩罚为。
4.2 定性分析
最近邻居检索:自监督训练有望为语义相似的图像分配相似的特征。我们首先对ImageNet ILSVRC 2012验证集执行最近邻检索,以测试学习到的特征捕获语义信息的能力。我们将其与RotNet基线进行比较,以了解特征去耦的效果。 我们的模型从特征提取器网络输出的4,096维向量中获取特征。相应的,RogNet从 FC7层获取特征。我们使用余弦相似度计算特征之间的距离。
图3中从左到右按距离递增的顺序排列了一些样本的检索内容。RotNet和所提出的模型都能够捕获某些类别的图像中的语义。RotNet和我们的模型在包含显着对象并且旋转明确的随机选择图像上的结果都令人满意。我们的模型有时可以捕获更细粒度的相似性。例如,在第二行中,RotNet检索一些相似的背景植物,而不是前景对象鸟。在子弹头列车上,我们的模型成功找到了相同类别的图像,而不是普通的车辆。此外,对于某些旋转不可知的图像查询,RotNet无法提取图像中对象的潜在信息。 RotNet检索到的许多图像与查询完全无关(标有红色边框)。这可能是因为RotNet更加关注对象的形状,而对不同实例的判别却较少。相反,我们的模型可以针对这些查询返回语义上更相似的图像,这确认了我们模型在实例级别的区分能力。
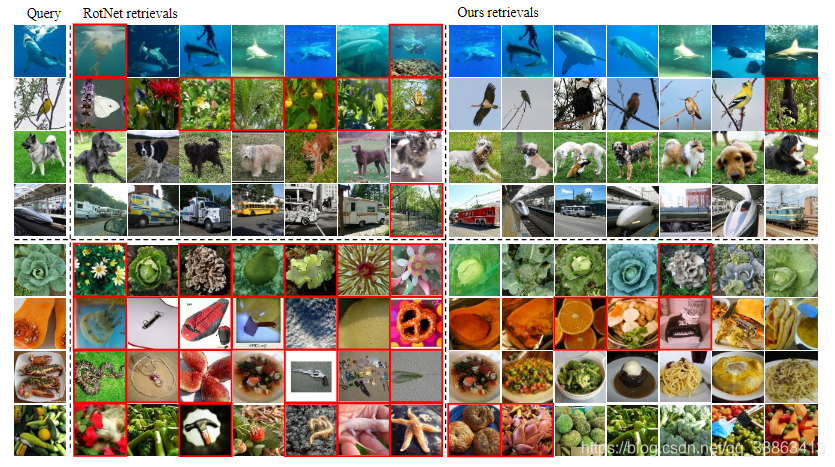
图3:最近邻居检索结果。我们在ImageNet验证集中显示RotNet的七个最近邻居和功能去耦网络。查询包含随机选择的图像(上四行)和不可旋转的图像(下四行)。语义上不相关的检索标有红色边框。
滤波器可视化:为了更好地了解通过我们的方法学习到的滤波器和特征,我们使用了不同的网络可视化技术。图4示出了来自第一层[25]的滤波器,使每个卷积层的某个通道的某些激活最大化的合成图像[15、50]和最大激活的图像[51]。我们发现模型中的较深层似乎捕获了更复杂和抽象的纹理结构。

图4:过滤器可视化。我们绘制了来自conv1层的过滤器,并显示了可以最大程度地激活不同卷积层中某个通道的特定功能图的合成图像。对应于该通道的ImageNet训练集中的前9张激活的图像在右侧。
4.3激活的线性分类
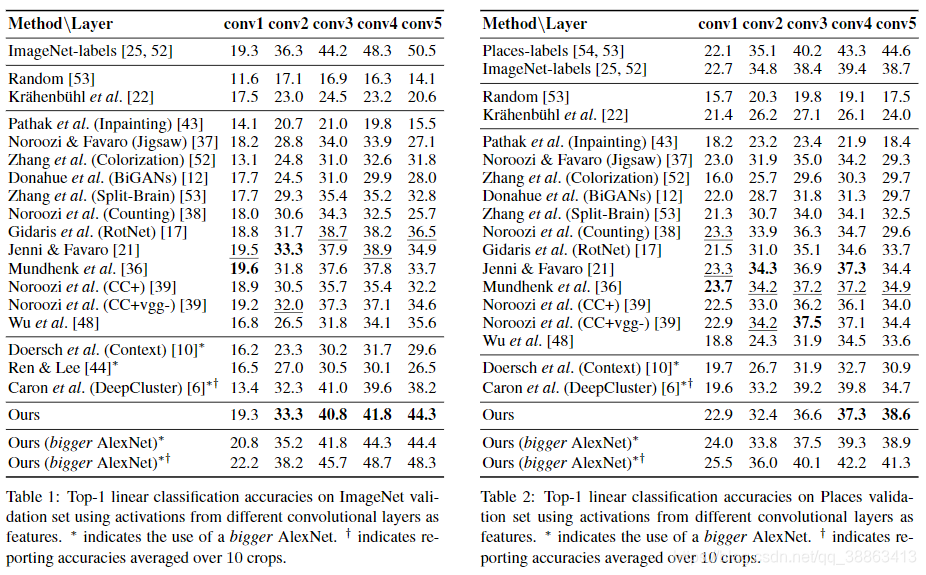
仿照Zhanget等 [52],我们在不同卷积层提取的特征的顶部训练线性分类器。该分类结果表示所学习表示的特定于任务的能力,特别是对对象类别的判别能力。通常,我们会在ILSVRC 2012 [45]和Places数据集[54]上进行这项研究。冻结特征提取器网络的所有权重,并在空间上调整特征图的大小(使用自适应最大池),以具有约9,000个元素。结果分别记录在表1和2中。表中的所有方法均使用基于AlexNet的网络,并且在ImageNet上进行了预训练,除了ImageNet标签,Places标签和Random条目外,没有标签。(带有*标记的方法使用的是更大版本的AlexNet,但没有分组或通道数量减少,而卷积层中的参数将增加50%,通常会提高性能。 在本文中,我们还报告了该网络上的结果)我们在[36,39]中报告了每种方法的最佳编号。我们还在补充材料中在ImageNet上提供了非线性分类的结果。
在ImageNet上,我们的方法从conv3t到conv5取得了最先进的结果。我们在conv1和conv2上的结果与以前的结果和ImageNet标签条目相当。请注意,网络的较低层通常捕获图像中的低级信息(如边缘或轮廓),并且具有相对较低的迁移精度,因此通常很少直接使用这些特征。重要的是要注意,大多数先前工作的性能会沿神经网络深度降低。与之形成鲜明对比的是,我们成功缩小了ImageNet标签在更高层上的差距。最大的改进(7.8%)是在conv5层上实现的,该层通常提取抽象语义信息。这表明我们的方法提取的高级功能在实际应用中更有希望。
在Places数据集上,我们方法的结果呈现出与ImageNet相似的趋势。我们在Conv4和Conv5层取得了最大的精度,同时在Conv1到Conv3上也取得了可比较的精度。在Conv5层,我们取得了最先进的3.7%。
4.4 PASCAL VOC上的多标签分类,目标检测和语义分割
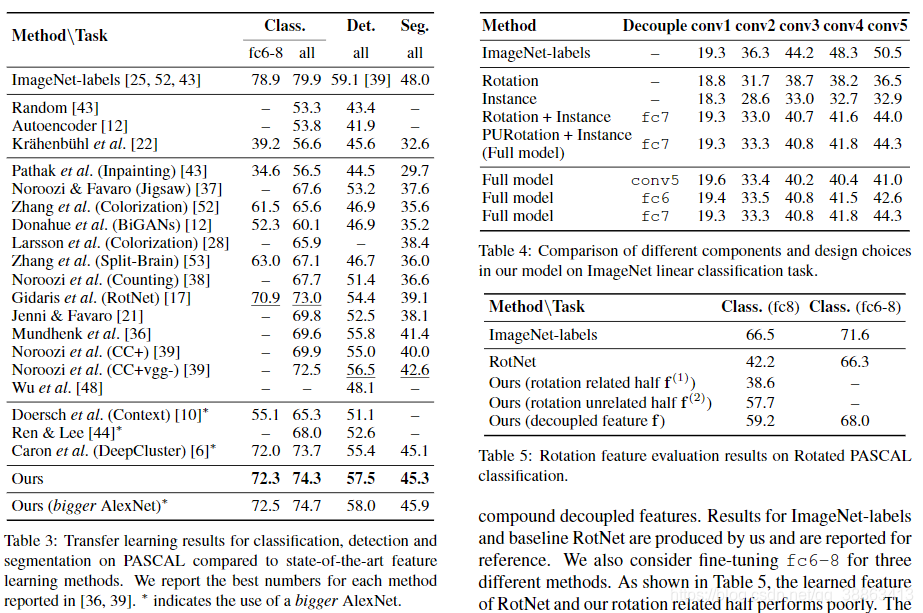
我们在PASCAL VOC数据集上测试了学习到的特征的可传递性[16]。我们使用无监督的训练网络作为PASCAL上任务的初始化模型。分类和检测的性能通过平均均值精度(mAP)进行测量,分割的性能则通过平均跨界联合(mIU)进行测量。在传输过程中,我们将批量归一化参数吸收到其先前的线性层中,并且在微调期间不使用BN层。 Kr̈ahenb̈uhlet等人提出的依赖数据的缩放方法[22]作为标准惯例,用于在所有实验中重新调整权重。表3总结了我们的方法与其他方法的比较。我们在所有这三个任务上都优于以前的方法。
PASCAL VOC 2007上的分类:我们使用Kr̈ahenb̈uhl(https://github.com/philkr/voc-classification)提供的开源协议执行多标签分类。我们在训练集上微调整个网络或仅fc6-8层,并在测试集上评估。我们的方法可以改进RotNet(目前分类的最佳方法)。可以观察到,更大的AlexNet模型将带来性能上的提升。
在PASCAL VOC 2007上的检测:对于物体检测,我们使用自监督训练的网络作为Fast-RCNN[18]的初始化。我们使用Girshick提供的公开测试框架[18],并使用多尺度训练和单尺度测试。第一层的权重在微调期间是固定的,因为它是Fast-RCNN中的默认设置。以57.5%的mAP,我们达到了最佳结果。补充材料中还提供了我们方法的每类检测性能。
在PASCAL VOC 2012上进行分割:我们使用FCN [33]在PASCAL VOC 2012训练集上微调模型并在测试集进行评估。我们的方法比最新技术高出2.7%。
4.5 讨论
消融研究:要查看模型中每个组件的影响,我们对具有固定特征的ImageNet线性分类进行消融研究。我们比较旋转预测任务(Rotation),旋转无关实例分类(Instance),这两个任务的组合(Rotation + Instance)和考虑未标记集中的嘈杂标签(PURotation +Instance)。表4的中间四行显示了不同组件的性能。当考虑旋转识别,噪声标签和实例识别时,该模型的效果最佳。
不同的配置:我们通过在ImageNet上的线性分类评估各种设计选择的效果。我们比较特征提取器网络的不同结构:AlexNet(conv5)的卷积层,conv5具有一个全连接层(fc6)的情况和conv5具有两个全连接层(fc7)的情况。结果总结在表4的下三行中。当高层的特征被解耦时,高层将学习到更好的特征。有趣的是,下层的性能趋于下降。这可能是因为将损失函数应用于较高层时,有效的梯度信息对较低层的帮助较小。
旋转特征评估:我们最终证明,当下游任务中的图像表现出旋转对称性时,解耦特征更适合。为此,我们将PASCAL VOC 2007中的图像旋转90度的倍数(即90、180和270),并在分类任务上评估。旋转后的数据集有20,044张用于训练的图像和19,808张用于测试的图像(是原始数据集的4倍)。具有不同旋转角度的每个实例共享相同的类标签。我们直接在上半部分(旋转相关)特征,下半部分(旋转无关)特征和复合解耦特征的顶部训练线性分类器。我们生产ImageNet标签和基准RotNet的结果,并报告以作参考。我们还考虑针对三种不同的方法对fc6-8进行微调。如表5所示,RotNet学习到的特征以及我们模型中与旋转相关的那一半特征性能较差。原因是它们对于图像旋转具有区分性,并且在旋转的数据集中没有很好的泛化能力。该结果表明,考虑旋转相关特征和不相关特征都是有益的。我们的方法更适合于需要旋转不变的视觉任务。
5 结论
在本文中,我们提出了一种无监督的表示学习方法,该方法学习包含旋转相关部分和不相关部分的有意义的语义特征。我们的方法从区分单个实例中分离出图像旋转预测。与标准的自监督学习基准相比,特征的迁移可实现比最新方法更高的性能。解耦特征的优点在旋转不可知任务中得到进一步证明。我们相信,为自监督型学习引入更多分析特性的表示,对推广很有帮助,并且是一个有前途的未来方向。
参考文献
[1] Pulkit Agrawal, Joao Carreira, and Jitendra Malik. Learningto see by moving. InThe IEEE International Conference onComputer Vision (ICCV), December 2015.
[2] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, MargaretMitchell, Dhruv Batra, C. Lawrence Zitnick, and DeviParikh. Vqa: Visual question answering. InThe IEEE Inter-national Conference on Computer Vision (ICCV), December2015.
[3] Ignacio Arganda-Carreras, Srinivas C. Turaga, Daniel R.Berger, Dan Cires ̧an, Alessandro Giusti, Luca M. Gam-bardella, J ̈urgen Schmidhuber, Dmitry Laptev, SarveshDwivedi, Joachim M. Buhmann, Ting Liu, Mojtaba Seyed-hosseini, Tolga Tasdizen, Lee Kamentsky, Radim Burget,Vaclav Uher, Xiao Tan, Changming Sun, Tuan D. Pham,Erhan Bas, Mustafa G. Uzunbas, Albert Cardona, JohannesSchindelin, and H. Sebastian Seung. Crowdsourcing the cre-ation of image segmentation algorithms for connectomics.Frontiers in Neuroanatomy, 9:142, 2015.
[4] Jessa Bekker and Jesse Davis. Learning from positive andunlabeled data: A survey.arXiv:1811.04820, 2018.
[5] Y. Bengio, A. Courville, and P. Vincent. Representationlearning: A review and new perspectives.IEEE Transactionson Pattern Analysis and Machine Intelligence, 35(8):1798–1828, Aug 2013.
[6] Mathilde Caron, Piotr Bojanowski, Armand Joulin, andMatthijs Douze. Deep clustering for unsupervised learningof visual features. In Vittorio Ferrari, Martial Hebert, Cris-tian Sminchisescu, and Yair Weiss, editors,Computer Vision– ECCV 2018, pages 139–156, Cham, 2018. Springer Inter-national Publishing.
[7] Taco Cohen and Max Welling. Group equivariant convo-lutional networks. In Maria Florina Balcan and Kilian Q.Weinberger, editors,Proceedings of The 33rd InternationalConference on Machine Learning, volume 48 ofProceed-ings of Machine Learning Research, pages 2990–2999, NewYork, New York, USA, 20–22 Jun 2016. PMLR.
[8] Robert K Cowen, S Sponaugle, K Robinson, and J Luo.Planktonset 1.0: Plankton imagery data collected from fgwalton smith in straits of florida from 2014–06-03 to 2014–06-06 and used in the 2015 national data science bowl (nceiaccession 0127422).NOAA National Centers for Environ-mental Information, 2015.
[9] Sander Dieleman, Jeffrey De Fauw, and Koray Kavukcuoglu.Exploiting cyclic symmetry in convolutional neural net-works. In Maria Florina Balcan and Kilian Q. Weinberger,editors,Proceedings of The 33rd International Conferenceon Machine Learning, volume 48 ofProceedings of MachineLearning Research, pages 1889–1898, New York, New York,USA, 20–22 Jun 2016. PMLR.
[10] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsu-pervised visual representation learning by context prediction.InThe IEEE International Conference on Computer Vision(ICCV), December 2015.
[11] Carl Doersch and Andrew Zisserman. Multi-task self-supervised visual learning. InThe IEEE International Con-ference on Computer Vision (ICCV), Oct 2017.
[12] Jeff Donahue, Philipp Kr ̈ahenb ̈uhl, and Trevor Darrell. Ad-versarial feature learning. InInternational Conference onLearning Representations, 2017.
[13] Alexey Dosovitskiy, Jost Tobias Springenberg, Martin Ried-miller, and Thomas Brox. Discriminative unsupervised fea-ture learning with convolutional neural networks. In Z.Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, andK. Q. Weinberger, editors,Advances in Neural InformationProcessing Systems 27, pages 766–774. Curran Associates,Inc., 2014.
[14] Charles Elkan and Keith Noto. Learning classifiers from onlypositive and unlabeled data. InProceedings of the 14th ACMSIGKDD International Conference on Knowledge Discoveryand Data Mining, KDD ’08, pages 213–220, New York, NY,USA, 2008. ACM.
[15] Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pas-cal Vincent. Visualizing higher-layer features of a deep net-work. Technical Report 1341, University of Montreal, June2009. Also presented at the ICML 2009 Workshop on Learn-ing Feature Hierarchies, Montr ́eal, Canada.
[16] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I.Williams, J. Winn, and A. Zisserman. The pascal visual ob-ject classes challenge: A retrospective.International Journalof Computer Vision, 111(1):98–136, Jan. 2015.
[17] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Un-supervised representation learning by predicting image rota-tions. InInternational Conference on Learning Representa-tions, 2018.
[18] Ross Girshick. Fast r-cnn. InThe IEEE International Con-ference on Computer Vision (ICCV), December 2015.
[19] Fengxiang He, Tongliang Liu, Geoffrey I Webb, andDacheng Tao. Instance-dependent PU learning by bayesianoptimal relabeling.arXiv:1808.02180, 2018.
[20] Jo ̃ao F. Henriques and Andrea Vedaldi. Warped convolu-tions: Efficient invariance to spatial transformations. InDoina Precup and Yee Whye Teh, editors,Proceedings ofthe 34th International Conference on Machine Learning,volume 70 ofProceedings of Machine Learning Research,pages 1461–1469, International Convention Centre, Sydney,Australia, 06–11 Aug 2017. PMLR.
[21] Simon Jenni and Paolo Favaro. Self-supervised feature learn-ing by learning to spot artifacts. InThe IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), June2018.
[22] Philipp Kr ̈ahenb ̈uhl, Carl Doersch, Jeff Donahue, and TrevorDarrell. Data-dependent initializations of convolutional neu-ral networks. InInternational Conference on Learning Rep-resentations, 2016.
[23] Jan Kremer, Fei Sha, and Christian Igel. Robust active la-bel correction. In Amos Storkey and Fernando Perez-Cruz,editors,Proceedings of the Twenty-First International Con-ference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 308–316,Playa Blanca, Lanzarote, Canary Islands, 09–11 Apr 2018.PMLR.
[24] Alex Krizhevsky. One weird trick for parallelizing convolu-tional neural networks.CoRR, abs/1404.5997, 2014.
[25] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton.Imagenet classification with deep convolutional neural net-works. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q.Weinberger, editors,Advances in Neural Information Pro-cessing Systems 25, pages 1097–1105. Curran Associates,Inc., 2012.
[26] Dmitry Laptev, Nikolay Savinov, Joachim M. Buhmann, andMarc Pollefeys. Ti-pooling: Transformation-invariant pool-ing for feature learning in convolutional neural networks.InThe IEEE Conference on Computer Vision and PatternRecognition (CVPR), June 2016.
[27] Gustav Larsson, Michael Maire, and GregoryShakhnarovich. Learning representations for automaticcolorization. In Bastian Leibe, Jiri Matas, Nicu Sebe, andMax Welling, editors,Computer Vision – ECCV 2016, pages577–593, Cham, 2016. Springer International Publishing.
[28] Gustav Larsson, Michael Maire, and GregoryShakhnarovich. Colorization as a proxy task for visualunderstanding. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), July 2017.
[29] S. Lazebnik, C. Schmid, and Jean Ponce. Semi-localaffine parts for object recognition. InProceedings ofthe British Machine Vision Conference, pages 98.1–98.10.BMVA Press, 2004. doi:10.5244/C.18.98.
[30] Hsin-Ying Lee, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Unsupervised representation learning by sort-ing sequences. InThe IEEE International Conference onComputer Vision (ICCV), Oct 2017.
[31] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Doll ́ar, and C. LawrenceZitnick. Microsoft coco: Common objects in context. InDavid Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuyte-laars, editors,Computer Vision – ECCV 2014, pages 740–755, Cham, 2014. Springer International Publishing.
[32] T. Liu and D. Tao. Classification with noisy labels by impor-tance reweighting.IEEE Transactions on Pattern Analysisand Machine Intelligence, 38(3):447–461, March 2016.
[33] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fullyconvolutional networks for semantic segmentation. InTheIEEE Conference on Computer Vision and Pattern Recogni-tion (CVPR), June 2015.
[34] David G. Lowe. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vi-sion, 60(2):91–110, Nov 2004.
[35] Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Raviku-mar, and Ambuj Tewari. Learning with noisy labels. InC. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani,and K. Q. Weinberger, editors,Advances in Neural Informa-tion Processing Systems 26, pages 1196–1204. Curran Asso-ciates, Inc., 2013.
[36] T. Nathan Mundhenk, Daniel Ho, and Barry Y. Chen. Im-provements to context based self-supervised learning. InTheIEEE Conference on Computer Vision and Pattern Recogni-tion (CVPR), June 2018.
[37] Mehdi Noroozi and Paolo Favaro. Unsupervised learningof visual representations by solving jigsaw puzzles. In Bas-tian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision – ECCV 2016, pages 69–84, Cham, 2016.Springer International Publishing.
[38] Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. Rep-resentation learning by learning to count. InThe IEEE Inter-national Conference on Computer Vision (ICCV), Oct 2017.
[39] Mehdi Noroozi, Ananth Vinjimoor, Paolo Favaro, andHamed Pirsiavash. Boosting self-supervised learning viaknowledge transfer. InThe IEEE Conference on ComputerVision and Pattern Recognition (CVPR), June 2018.
[40] Curtis G. Northcutt, Tailin Wu, and Isaac L. Chuang. Learn-ing with confident examples: Rank pruning for robust classi-fication with noisy labels. InProceedings of the Thirty-ThirdConference on Uncertainty in Artificial Intelligence, UAI’17.AUAI Press, 2017.
[41] Andrew Owens, Jiajun Wu, Josh H. McDermott, William T.Freeman, and Antonio Torralba. Ambient sound provides su-pervision for visual learning. In Bastian Leibe, Jiri Matas,Nicu Sebe, and Max Welling, editors,Computer Vision –ECCV 2016, pages 801–816, Cham, 2016. Springer Inter-national Publishing.
[42] Deepak Pathak, Ross Girshick, Piotr Dollar, Trevor Darrell,and Bharath Hariharan. Learning features by watching ob-jects move. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), July 2017.
[43] Deepak Pathak, Philipp Kr ̈ahenb ̈uhl, Jeff Donahue, TrevorDarrell, and Alexei A. Efros. Context encoders: Featurelearning by inpainting. InThe IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), June 2016.
[44] Zhongzheng Ren and Yong Jae Lee. Cross-domain self-supervised multi-task feature learning using synthetic im-agery. InThe IEEE Conference on Computer Vision andPattern Recognition (CVPR), June 2018.
[45] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San-jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,Aditya Khosla, Michael Bernstein, Alexander C. Berg, andLi Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252,Dec 2015.
[46] Clayton Scott. A Rate of Convergence for Mixture Propor-tion Estimation, with Application to Learning from NoisyLabels. In Guy Lebanon and S. V. N. Vishwanathan, ed-itors,Proceedings of the Eighteenth International Confer-ence on Artificial Intelligence and Statistics, volume 38 ofProceedings of Machine Learning Research, pages 838–846,San Diego, California, USA, 09–12 May 2015. PMLR.
[47] Xiaolong Wang and Abhinav Gupta. Unsupervised learningof visual representations using videos. InThe IEEE Inter-national Conference on Computer Vision (ICCV), December2015.
[48] Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin.Unsupervised feature learning via non-parametric instancediscrimination. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), June 2018.
[49] Pengyi Yang, Wei Liu, and Jean Yang. Positive unlabeledlearning via wrapper-based adaptive sampling. InProceed-ings of the Twenty-Sixth International Joint Conference onArtificial Intelligence, IJCAI-17, pages 3273–3279, 2017.
[50] Jason Yosinski, Jeff Clune, Thomas Fuchs, and Hod Lipson.Understanding neural networks through deep visualization.InICML Workshop on Deep Learning, 2015.
[51] Matthew D. Zeiler and Rob Fergus. Visualizing and under-standing convolutional networks. In David Fleet, Tomas Pa-jdla, Bernt Schiele, and Tinne Tuytelaars, editors,ComputerVision – ECCV 2014, pages 818–833, Cham, 2014. SpringerInternational Publishing.
[52] Richard Zhang, Phillip Isola, and Alexei A. Efros. Color-ful image colorization. In Bastian Leibe, Jiri Matas, NicuSebe, and Max Welling, editors,Computer Vision – ECCV2016, pages 649–666, Cham, 2016. Springer InternationalPublishing.
[53] Richard Zhang, Phillip Isola, and Alexei A. Efros. Split-brain autoencoders: Unsupervised learning by cross-channelprediction. InThe IEEE Conference on Computer Vision andPattern Recognition (CVPR), July 2017.
[54] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Tor-ralba, and Aude Oliva. Learning deep features for scenerecognition using places database. In Z. Ghahramani, M.Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger,editors,Advances in Neural Information Processing Systems27, pages 487–495. Curran Associates, Inc., 2014.
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 知识图谱基础(一)-什么是知识图谱
1. 知识图谱的定义知识图谱在国内属于一个比较新兴的概念,国内目前paper都比较少,应用方主要集中在BAT这类手握海量数据的企业,这个概念是google在2012年提出的,当时主要是为了将传统的keyword-base搜索模型向基于语义的搜索升级。知识图谱可以用来更好的查询复杂的关联信息…...
2024/4/19 22:23:12 - 急需大神帮助-可有偿帮助! 急
要求:写一个项目实现方案。 本人从没接触过项目方案,实在无从下手,但现在急需要一个方案,才能在入职工作!还请各位大神给予下帮助...
2024/4/16 12:34:57 - IntelFPGA_DCFIFO_IP
dcfifo常用于跨时钟域数据传输,有两种工作模式,normal mode/ showahead mode,本文主要通过仿真对比这两种模式的区别。1.showahead mode 参数设定 intended_device_family = "Cyclone 10 LP", lpm_numwords = 128, //FIFO深度在位宽为写位宽32bit时为128,响应的以…...
2024/4/23 20:00:00 - node-利用token完成身份验证
node-利用token完成身份验证...
2024/4/16 12:35:07 - 设计模式----单例模式
单例模式中最重要的思想是:构造器私有,因此能保证我们的内存中只有一个对象。单例模式分为懒汉式和饿汉式1.饿汉式:顾名思义,很饿,上来就吃。package cn.com;//饿汉式单例,在程序运行时,无论是否需要 都会创建对象,因此 可能会浪费空间 public class HungryMan {//构造…...
2024/4/19 18:03:38 - 次世代角色模型设计师与场景模型设计师有什么不同?
经常有很多同学在纠结要做角色建模还是场景建模比较好? 先从难度来说:因人而异,有的人觉得做场景容易有的人觉得很难,这个其实很大一部分和实力没有关系,更多的是你对哪个更有兴趣更适合你,所以你学起来会相对比较容易,客观来说大部分人是觉得场景会更加难一点。 从个人…...
2024/4/16 12:34:37 - 在PyTorch中使用Visdom可视化工具
在PyTorch中使用Visdom可视化工具-非常详细1.安装 pip install visdom conda install visdom2.Linux 服务器端 启动(模型训练前),默认使用端口 8097 To view training results and loss plots : python -m visdom.server3.开始模型训练 另外打开一个命令窗口,在你的环境…...
2024/4/16 12:35:07 - Registry学习资料
官网:https://registry-project.readthedocs.io/en/latest/index.html...
2024/4/25 5:58:54 - py处理并保存包含多个sheet的excel文件
py处理并保存包含多个sheet的excel文件 写在前面的话: 很久之前同学要我改个excel的数据,把所有大于30000的数据变为0,但是又不会操作excel(一个文件中包含多个sheet,我也不会~),所以只能用python做数据处理了,查了一下并简单应用,记录一下,以后查阅方便。 最近实习了…...
2024/4/16 12:34:52 - Registry新建以及版本
1.美图2.添加新的schema 现在,我们可以访问Web UI了,让我们尝试向注册表添加新的架构。您的HDF版本中可能已经包含了一些模式,但是请继续并让我们添加另一个。 单击 界面右上方的 +符号。这将打开一个名为“ Add New Schema ” 的窗口,我们可以在其中输入有关新模式的信息…...
2024/4/20 8:14:31 - Linux 五种IO模型
上一篇《聊聊同步、异步、阻塞与非阻塞》已经通俗的讲解了,要理解同步、异步、阻塞与非阻塞重要的两个概念点了,没有看过的,建议先看这篇博文理解这两个概念点。在认知上,建立统一的模型。这样,大家在继续看本篇时,才不会理解有偏差。那么,在正式开始讲Linux IO模型前,…...
2024/4/16 12:33:56 - 结构体嵌套结构体(结构体嵌套结构体变量(本身和外部),结构体嵌套结构体指针变量(本身))
结构体嵌套外部结构体变量 #include<stdio.h> #include<string.h> #include<stdlib.h>typedef struct student {int score[10];int data;} A;struct node{int i;A P;} B;int main(){return 0;}结构体嵌套本身结构体变量--------错误!! #include<stdio.h…...
2024/4/16 12:34:21 - 选择排序--第1轮
public class Choose {public static void main(String[] args){System.out.println("这是选择排序");System.out.println();int[] arr={5,23,46,1,12};System.out.println("排序前:" +Arrays.toString(arr));System.out.println();sortChoose(arr);}pub…...
2024/4/20 5:31:55 - Spark报错: Invalid Spark URL: spark://YarnScheduler@stream_test_nb:40659
1.背景参考:请点击 参考:请点击 参考:请点击 org.apache.spark.SparkException: Invalid Spark URL: spark://YarnScheduler@stream_test_nb:40659at org.apache.spark.rpc.RpcEndpointAddress$.apply(RpcEndpointAddress.scala:66)at org.apache.spark.rpc.netty.NettyRpcE…...
2024/4/20 5:15:12 - 免杀横向移动工具WMIHACKER
免杀横向移动工具WMIHACKER交互式Shell命令执行文件上传文件下载 免杀横向渗透远程命令执行,常见的WMIEXEC、PSEXEC执行命令是创建服务或调用Win32_Process.create执行命令,这些方式都已经被杀软100%拦截,通过改造出WMIHACKER免杀横向移动测试工具。 其通过135端口进行命令执…...
2024/4/16 12:35:43 - Spark报错:Bad response ERROR for block BP-78092257-8.xx-121xxx
1.背景一个spark 运行了一夜的程序突然报错 java.io.Exception : Bad response ERROR for block BP-78092257-8.xx-121xxx:blk_1158327934——84597360 from datanode DataNodeInfoWithStorage[8.99,202] at org.xxx.hadoop.xxx.$ResponseProcessor.run(DFSOutputStream.java:1…...
2024/4/4 21:06:30 - COOKIE基础与应用
什么是cookie 页面用来保存信息 比如:自动登录、记住用户名cookie的特性 同一个网站中所有页面共享一套cookie 数量、大小有限 过期时间JS中使用cookie document.cookieDate函数的使用<script> var oDate=new Date();oDate.setDate(oDate.getDate()+100);//计算当前日期…...
2024/4/16 12:35:58 - Spark structured 记录一次kudu扩容导致无法写入数据的问题
1.背景我们有个程序,是kafka写入到kudu,此时我们重启了一下任务,结果发现,任务运行后,就会卡主,提示是正在运行,但是实际上报错,打开日志,发现,一直报错找不到节点 can not access rds03 ip not found 这样一看,大约猜到是kudu master返回的地址是 域名,而我们获取到…...
2024/4/4 21:06:27 - poj 1363:火车合法的出栈次序——合法的出栈次序
#include <stdio.h>#include <stack> #include <queue>bool check_is_valid_order(std::queue<int> &order){std::stack<int> S;//临时栈int n = order.size();//获得测试队列,即出栈次序的长度for (int i = 1; i <= n; i++){S.push(i);…...
2024/4/16 12:35:33 - 编程训练————合并两个有序链表(C++)
合并两个有序链表题目描述主要思路(图解)主要代码实现测试 题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例: 输入:1->2->4, 1->3->4 输出:1->1->2->3->4->4 来源:力扣(Lee…...
2024/4/16 12:34:42
最新文章
- vue3 -- 项目使用自定义字体font-family
在Vue 3项目中使用自定义字体(font-family)的方法与在普通的HTML/CSS项目中类似。可以按照以下步骤进行操作: 引入字体文件: 首先,确保你的字体文件(通常是.woff、.woff2、.ttf等格式)位于项目中的某个目录下,比如src/assets/font/。 在全局样式中定义字体: 在你的全局…...
2024/4/26 0:04:14 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 理解 Golang 变量在内存分配中的规则
为什么有些变量在堆中分配、有些却在栈中分配? 我们先看来栈和堆的特点: 简单总结就是: 栈:函数局部变量,小数据 堆:大的局部变量,函数内部产生逃逸的变量,动态分配的数据&#x…...
2024/4/25 14:31:14 - Linux从入门到精通 --- 2.基本命令入门
文章目录 第二章:2.1 Linux的目录结构2.1.1 路径描述方式 2.2 Linux命令入门2.2.1 Linux命令基础格式2.2.2 ls命令2.2.3 ls命令的参数和选项2.2.4 ls命令选项的组合使用 2.3 目录切换相关命令2.3.1 cd切换工作目录2.3.2 pwd查看当前工作目录2.4 相对路径、绝对路径和…...
2024/4/25 22:53:12 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/25 11:51:20 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/25 18:39:24 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/25 18:38:39 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/25 18:39:23 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/25 18:39:22 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/25 18:39:22 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/25 18:39:20 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/25 16:48:44 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/25 13:39:44 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/25 18:39:16 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/25 18:39:16 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/25 0:00:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/25 4:19:21 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/25 18:39:14 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/25 18:39:12 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/25 2:10:52 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/25 18:39:00 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/25 13:19:01 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/25 18:38:58 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/25 18:38:57 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57