推荐系统技术
目录
推荐系统技术
整体流程
用户画像
match部分
CF(协同过滤)
Swing
Content I2I
Session-based I2I
向量召回
RankI2I
Rank部分
LR
LR+GBDT
FM/FFM
MLR
FNN
AFM
NFM
PNN
Wide&Deep
DeepFM
DeepFFM
DCN
xDeepFM
FAT-DeepFFM
DIN
DIEN
推荐系统技术
整体流程
推荐系统整个过程分为几个阶段,在这里把他分为四个阶段:用户画像、match(召回)、rank(实时打分)、adapter(后处理)。其中match和rank是两个关键任务,也是推荐方面优化的主要方向。
- 【用户画像】 这部分主要是为了对用户建模,根据用户的历史行为挖掘用户的偏好数据(偏好目的地、Item、Poi、类目、类型等等),挖掘用户的属性信息,为后面几个阶段服务(通过用户的偏好信息去召回推荐的商品列表,在adapter阶段作一些后处理等);
- 【match】 这部分主要是为了召回用户可能感兴趣的推荐列表,因为在实际应用场景中,商品的数量往往很多(例如新闻、音乐、电影、商品等,亿级别的数量),直接用一个模型对所有商品打分往往不太现实。可以认为match部分是一个粗排序的阶段,我们希望在这个阶段从广大的商品池子中召回出用户可能感兴趣的所有商品,因此需要从多个不同的角度去召回(根据用户偏好的目的地召回对应目的地下的热门Item、根据偏好的类目召回对应类目下的热门Item、根据用户偏好的Item召回相似的Item等等)。
- 【rank】 这部分是在match过后对召回的商品进行一个精确的排序,通过机器学习模型对商品打分,返回分数靠前的n个商品作为最终的推荐列表。
- 【adapter】 这部分就是对推荐列表进行预处理了,例如曝光过滤(控制商品的曝光次数,避免商品持续曝光导致用户的疲劳度)、打散(为了增加推荐的丰富性,对推荐结果进行类目、目的地的多样性化)、黑名单过滤等等。
用户画像
根据用户的历史行为计算偏好,score分为两个部分计算,从商品的角度计算商品的流行度(根据宝贝的成交、收藏、加购、点击设置不同的权重,以时间衰减的方式累加分数),从用户的角度计算用户对商品的偏好score
match部分
match部分的方法很多,主要有CF(协同过滤)、基于graph embedding的方法(DeepWalk、LINE、NOde2Vec、SDNE)、session_based等。可以分为3大类:I2I(包括CFI2I,EmbedI2I,SwingI2I,SessionI2I,ContentI2I等)、X2I(例如Dest2I,Cat2I,Tag2I,Poi2I等)、hot(用来打底,当其他方式都无召回时,采用hot)。
CF(协同过滤)
分为基于用户的CF和基于Item 的CF,该方法被广为应用
基于User的CF:
U1看过I1,I2,I3,U2看过I1,I2,则认为U1,U2相似,则可以把I3推荐给U2。
基于Item的CF:
I1被U1,U2,U3看过,I2被U1,U2看过,则认为I1,I2相似,则可以把I2推荐给U3。
【CF-I2I实际应用举例】:对每个用户,计算用户权重u_score=1 /pow(log(2, 3 +count(item_id)), 2),根据用户历史行为商品数量计算一个user权重,用户行为Item数越多,权重越低;对每个Item,计算Item的I_score=sum(u_score)。考虑每一个item对(trig_item,rec_item),其中rec_item为与trig_item相似的item,未避免取所有这样的对,可对每一个对的类目进行限制,类目一致与不一致的考量。如何衡量他们的相似度?取出所有同时有过trig_item和rec_item的用户,记这样的用户数为n,将这部分用户的u_score相加记为sum_u_score,则sim_score=sum_u_score / (1.0 + pow(trig_item_I_score * rec_item_I_score, 0.5)),如下图,最后可根据trig_item与rec_item类目是否一致等信息进行加权。 根据以上式子可以看出,当rec_item与trig_item分布单独出现的次数增加时,两者的sim_score会越小,极端情况下,若所有用户的历史行为中,rec_item与trig_item要么同时出现要么不出现,此时的sim_score达到最大,即两者是非常相似的:有rec_item行为的用户也会有trig_item行为。


特点:CF实效成本低,全量发现能力弱,基于历史相似扩展;存在冷启动问题,抗噪音能力差,算出来结果中会有一些看起来不太准的case,实际用的时候会借助一些其他的信息,比如商品类目;另外一个问题就是“哈里波特”问题;
Swing
阿里原创算法-swing,基于图结构做match,计算商品间的相似度(swing利用user-item二部图计算i2i,比改进过的CF算法仍有明显提升,目前已在各场景中已经广泛应用),定义如下(Ui表示点击过i的user集合,Iu表示user u点击过的item集合):
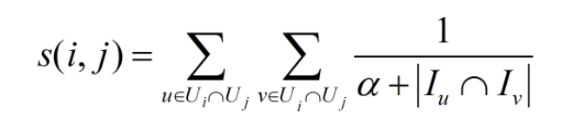
含义:如果多个user在点击了s的同时,都只共同点了某一个其他的item,那么这个item和s一定是强关联的;
CF以用户的共同点击次数来衡量商品i和j的相似度,SWING在此基础上考虑2个user pari对之间的结构,两个用户共同点击的item数越多,说明i和j的关联越弱。如下图,其中intersection表示u1和u2点击过的item交集数


# 关键代码
for i in xrange(0, len(u2items)):wi = math.pow(len(u2items[i]) + 5, -0.35)for j in xrange(i + 1, len(u2items)):intersection = u2items[i] & u2items[j]wj = wi * math.pow(len(u2items[j]) + 5, -0.35)for id in intersection:u2swing[id] = u2swing.get(id, 0.0) + wj / (1 + len(intersection))【特点】:凭借着最强相关的Swing结构,可以最大程度的抵抗噪声的影响;和CF相比,swing要更严格,它更好的利用了人的协同能力,去噪能力强,每一个swing结构都是“有益”的信息,而CF中很多节点都可能是不相关的“噪声”,而且没有办法区分;另一个优点是它对网络结构的变化相对更灵敏,如果出现一个新的很相关的item,如果有部分用户都发现了这个item并且都点了它,那么它就很可能排上去。
Content I2I
对商品title的词向量作加权平均。1.根据word2Vec得到title的词向量;2.根据词的类型(如时间季节、人群、地区等),设置对应权重,将词向量加权平均得到新的item向量;3.计算item向量间的相似度作为宝贝的相似度。
Session-based I2I
可读读这方面的文章《A Survey on Session-based Recommender Systems》地址
向量召回
向量召回需要对user或item进行embedding,计算embedding向量之间的相似度,通过embedding的形式进行向量召回,能够大大增加召回率。
embedding
由于id类特征的稀疏性,大部分模型都或多或少会使用特征的embedding表示:将高维稀疏的one-hot编码表示转换为一个低维稠密实数向量(low-dimensional dense embedding),简单的可以将其理解为一种映射。类似于hash方法,embedding方法把位数较多的稀疏数据压缩到位数较少的空间,不可避免会有冲突;然而,embedding学到的是类似主题的语义表示,对于item的“冲突”是希望发生的,这有点像软聚类,这样才能解决稀疏性的问题。embedding原理参考地址。
embedding常用的方法包括矩阵分解(MF)、因子分解机(FM)和神经网络。常用矩阵分解的方法把User-Item评分矩阵分解为两个低秩矩阵的乘积,这两个低秩矩阵分别为User和Item的隐向量集合,隐向量遍可以作为embedding,通过User和Item隐向量的点积来预测用户对未见过的物品的兴趣,处理部分冷启动的问题;MF方法可以看作是FM模型的一种特例,即MF可以看作特征只有userId和itemId的FM模型,FM的优势是能够将更多的特征融入到这个框架中,详细请参考下文FM部分;如今用的比较广泛的是基于神经网络的嵌入方法,网络的输入、输出都是实体ID的one-hot编码向量,两层之间就是Embedding层,层与层之间通过全连接的方式相连,Embedding层的神经元个数即Embeeding向量的维数,输入层与Embedding层的链接对应的权重矩阵M(n*m),即对应n个输入实体的m维embedding向量。由于one-hot向量同一时刻只会有一个元素值为1,其他值都是0,因此对于当前样本,只有与值为1的输入节点相连的边上的权重会被更新,即不同ID的实体所在的样本训练过程中只会影响与该实体对应的embedding表示。
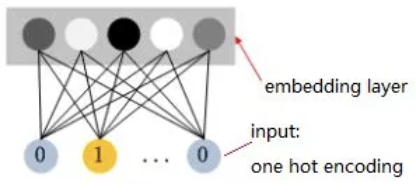
graph embedding
图嵌入,即用一个低维,稠密的向量去表示图中的点,使节点间的向量相似度接近原始节点间在网络结构、近邻关系、Meta信息等多维度上的相似性,能够整体反映图中的结构。常用的graph embedding方法的介绍可参考地址
其中常用的Deep walk embedding方法是将网络中的节点映射为高维空间中的点(embedding向量),这些数据同时还保留着节点之间的结构信息。Deep walk包括两个部分,第一个是随机游走,其原理是对每一个节点,随机的选择其邻居节点,这样游走t-1以后,就获取了一个长度为t的序列,对每个节点进行f次如此的采样,这样会获取大量的随机序列,将原始的图结构转变为了大量序列结构;第二个部分是skip-gram算法,这本来是NLP任务word2vector中使用的算法,其原理就在于根据中心词预测两边的词,例如一个序列(或者说一个语句)是a b c d e f,假如我的窗口大小是2,中心词是c,那么我会得到(c,a)、(c,b)、(c,d)、(c,e)这样的训练数据,也就是找他的n跳邻居,开始随机初始化embedding向量,随着训练的迭代,embedding向量会越来越能反应网络的原始结构信息。
总体两步:1、随机游走产生行为序列 2、在行为序列上训练doc2vect模型
RankI2I
I2I的种类有很多,各种I2I得到的sim_score的scale不统一,人工计算得到的sim_score可能不足以反应到真实分数情况,造成在match的截断部分,根据sim_score取topN的召回数据时,会丢失有效的Item。例如,CFI2I召回项及score:a:0.8,b:0.7,c:0.6;SwingI2I召回项:d:0.5,e:0.4,f:0.3;matc截断数为4时,根据score的排序最终得到a:0.8,b:0.7,c:0.6,d:0.5,这样导致丢失可能效果更好的e:0.4,f:0.3。且ranki2i在item-CF得到的两个商品之间的相似度的基础上再乘以该商品对的联合ctr,对i2i的simScore进行修正,使得i2i表不仅考虑了两个商品的点击共现性,还考虑了召回商品的点击率。
方法:针对不同I2I得到的推荐Item,采用模型对每一对(trig_item,rec_item)进行打分,用模型的score代替match计算的sim_score作为I2I最终的score。
主要特点:1.多种MatchType召回的列表,存在权重不统一以及截断数量的问题;2.Match过程存在多次截断,避免丢失用户感兴趣的商品;3.基于相关性的召回,ranki2i:相关性召回的基础上引入ctr效果的影响。
Rank部分
rank部分主要是训练一个ctr打分模型,对候选集进行实时排序,下面对常用模型进行介绍。
LR
LR是业界最常用也最通用的基本模型,函数形式来看,LR模型可以看做是一个没有隐层的神经网络模型(感知机模型)。其一直是CTR预估问题的benchmark模型,由于其简单、易于并行化实现、可解释性强等优点而被广泛使用。然而由于线性模型本身的局限,不能处理特征和目标之间的非线性关系,因此模型效果严重依赖于算法工程师的特征工程经验。为了让线性模型能够学习到原始特征与拟合目标之间的非线性关系,通常需要对原始特征做一些非线性转换。常用的转换方法包括:特征聚类、连续特征离散化(包括等频离散、等间距离散,或者采用树模型通过gain来找到最优分裂点进行划分)、特征交叉(数值累加、累乘,类目组合等)等。特征离散化相当于把线性函数变成了分段线性函数,从而引入了非线性结构;同时可以起到一个平滑的作用,对异常值和噪音有一定的鲁棒性。特征交叉主要是将领域知识融入模型,往往单个特征对目标判定的贡献是较弱的,而不同类型的特征组合在一起就能够对目标的判定产生较强的贡献。例如用户性别和商品类目交叉就能够刻画例如“女性用户偏爱美妆类目”,“男性用户喜欢球类类目”的知识。
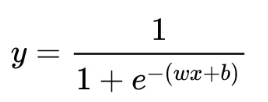
缺点:LR模型完全依靠于人工特征工程,需要对领域知识有一定了解,而且即使有经验的工程师也很难穷尽所有的特征交叉组合。LR模型可以理解为一个简单的一层神经网络,事实上这种方法最大的优势是具有强大的的记忆能力,但是这种模型在泛化能力上会有一些欠缺。
LR+GBDT
针对LR的缺点,Facebook 在14年的论文中提出了采用GBDT(Gradient Boost Decision Tree)的叶子节点作为组合特征的方法。设计思路:对于连续型特征或者值空间较小的类别特征输入到GBDT(一般采用浅层的树),将其得到的每棵树的叶子节点编号作为LR的组合特征(叶子节点个数即表示特征维度),再将其他离散特征和组合特征共同输入到LR去做预测。如下图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到LR中进行分类。 GBDT模型能够学习高阶非线性特征组合,对应树的一条路径(用叶子节点来表示);而其他稀疏特征则通过LR进行处理,这样既能做高阶特征组合又能利用线性模型易于处理大规模稀疏数据的优势。

【为什么建树采用GBDT而非RF】:很多实践证明GBDT的效果要优于RF,且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
LR VS GBDT
高维稀疏特征的时候,使用 gbdt 很容易过拟合,lr 的效果会比 gbdt 好;GBDT只是对历史的一个记忆,泛化能力较弱。
(参考知乎)假设有1w个样本,y类别0和1,100维特征,其中10个样本都是类别1,而特征f1的值为0,1,且刚好这10个样本的f1特征值都为1,其余9990样本都为0(在高维稀疏的情况下这种情况很常见),我们都知道这种情况在树模型的时候,很容易优化出含一个使用f1为分裂节点的树直接将数据划分的很好,但是当测试的时候,却会发现效果很差,因为这个特征只是刚好偶然间跟y拟合到了这个规律,这也是我们常说的过拟合。但是当时我还是不太懂为什么线性模型就能对这种case处理的好?照理说线性模型在优化之后不也会产生这样一个式子:y=W1*f1+Wi*fi....,其中W1特别大以拟合这十个样本吗,因为反正f1的值只有0和1,W1过大对其他9990样本不会有任何影响。
是因为现在的模型普遍都会带着正则项,而lr等线性模型的正则项是对权重的惩罚(l1,l2),也就是W1一旦过大,惩罚就会很大,进一步压缩W1的值,使他不至于过大;而树模型则不一样,树模型的惩罚项通常为叶子节点数和深度等,而我们都知道,对于上面这种case,树只需要一个节点就可以完美分割9990和10个样本,惩罚项极其之小,这也就是为什么在高维稀疏特征的时候,线性模型会比非线性模型好的原因了:带正则化的线性模型比较不容易对稀疏特征过拟合。
【工业界的经验】,先根据业务场景做提取统计类特征使用gbdt模型快速拿到收益,然后考虑加入海量离散类特征,使用LR/FM模型进一步提升效果。至于原有的统计类特征可以通过gbdt叶子节点转换成离散特征一并加入到LR/FM中。
FM/FFM
FM(Factorization Machines)模型通过隐变量的方式,发现两两特征之间的组合关系,但这种特征组合仅限于两两特征之间,即二阶组合,模型如下式,式中前两部分即普通的LR,较LR多了最后的组合部分,将任意两个特征进行组合,其中<Vi,Vj>表示组合特征的权重。
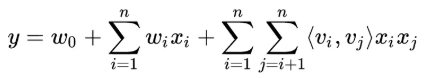
FM和树模型都能够自动学习特征交叉组合,但基于树的模型只适合连续型或值空间较小的稀疏数据,容易学到高阶组合,却不适合学习高度稀疏数据的特征组合,一方面高度稀疏数据的特征维度一般很高,这时基于树的模型学习效率很低,甚至不可行,这个在GBDT+LR一节中已讨论过;另一方面树模型也不能学习到训练数据中很少或没有出现的特征组合,因为树模型只是对历史的一个记忆,泛化能力较弱。相反,FM模型因为通过隐向量的内积来提取特征组合,对于训练数据中很少或没有出现的特征组合也能够学习到(当然,FM只能学习到二阶的特征组合,对于高阶特征组合则需采用其他方法),避免了由于数据稀疏性导致特征权重不可学的问题(在数据很稀疏的情况下,满足xi,xj都不为0的情况非常少,这样将导致ωij无法通过训练得出;为了求出ωij,我们对每一个特征分量xi引入辅助向量Vi=(vi1,vi2,⋯,vik)。然后,利用vivj^T对ωij进行求解,如下图)。例如,特征i和特征j在训练数据中从来没有成对出现过,但特征i经常和特征k成对出现,特征j也经常和特征k成对出现,因而在FM模型中特征i和特征j会有一定的相关性。毕竟所有包含特征i的训练样本都会导致模型更新特征的隐向量Vi,同理,所有包含特征j的样本也会导致模型更新隐向量Vj,这样<Vi,Vj>就不太可能为0。


FFM(Field-aware Factorization Machine)模型是对FM模型的扩展,通过引入field的概念,FFM把相同性质的特征归于同一个field。例如:“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码生成了550个特征,这550个特征都是说明商品所属的品类,因此它们也可以放到同一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。在FFM中,每一维特征 xi,针对其它特征的每一种field fj,都会学习一个隐向量 Vi,fj。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type”特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
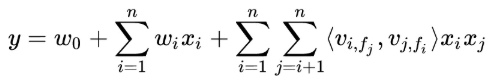
FM是FFM的特例,在FM模型中,每一维特征的隐向量只有一个,即FM是把所有特征都归属到一个field时的FFM模型。FM与FFM的详细对比见博客。
MLR
MLR(混合逻辑回归)是阿里在2012年提出并使用的广告点击率预估模型。MLR模型是对线性LR模型的推广,它利用分片线性方式对数据进行拟合。基本思路是采用分而治之的策略:如果分类空间本身是非线性的,则按照合适的方式把空间分为多个区域,每个区域里面可以用线性的方式进行拟合,最后MLR的输出就变为了多个子区域预测值的加权平均。如下图(C)所示,就是使用4个分片的MLR模型学到的结果。分片数为时,退化为普通LR,分片数越多,模型的拟合能力越强。

MLR模型在大规模稀疏数据上探索和实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;同时模型复杂度可控,有较好泛化能力;同时保留了LR模型的自动特征选择能力。
存在的问题
虽然理论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。由于上述几种方法无法建模两个特征之间深层次的关系或者说高阶交叉特征,为了解决该问题,学者们通过Deep Network来建模更高阶的特征之间的关系,但是对于离散特征的处理,我们使用的是将特征转换成为one-hot的形式,将One-hot类型的特征输入到DNN中,会导致网络参数过多,因此一般都会把稀疏类特征embedding后输入到网络中。由此学者们提出了一系列方法,例如:FM系列(FNN,AFM,NFM,DeepFM,xDeepFM,PNN),DCN,Wide&Deep等。其中FM系列又分为两种主流的方法:并行结构和串行结构。
| 结构 | 描述 | 模型 |
| 并行 | FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果 | DeepFM,DCN,Wide&Deep |
| 串行 | 将FM的一次项和二次项结果(或其中之一)作为DNN部分的输入,经DNN得到最终结果 | PNN,NFM,AFM,FNN |
目前也有很多基于CNN与RNN的用于CTR预估的模型。但是基于CNN的模型比较偏向于相邻的特征组合关系提取,基于RNN的模型更适合有序列依赖的点击数据,例如阿里提出的DIN,DIEN等。
FNN
FNN(Factorization-machine supported Neural Network),FNN模型就是用FM模型学习到的embedding向量初始化MLP,再由MLP完成最终学习。分为两个阶段:第一个阶段先用一个模型做特征工程;第二个阶段用第一个阶段学习到新特征训练最终的模型,类似于LR+GBDT。其模型结构如下:

缺点:不能对低阶特征拟合,需要预训练模型。针对FNN的缺点,下文的NFM有了更完善的改进。
AFM
根据上面介绍的FM,我们知道FM在进行预测时,会让一个特征固定一个特定的向量,当这个特征与其他特征做交叉时,都是用同样的向量去做计算。这个是很不合理的,因为不同的特征之间的交叉,重要程度是不一样的。如何体现这种重要程度,之前介绍的FFM模型是一个方案。另外,结合attention机制也是一种处理方案,而AFM便是采用的这种方式。attention可参考地址。网络结构如下图,图中的前三部分:sparse iput,embedding layer,pair-wise interaction layer,都和FM是一样的。而后面的两部分,则是AFM的创新所在。从比较宏观的角度理解,AFM就是通过一个attention net生成一个关于特征交叉项的权重,然后将FM原来的二次项直接累加,变成加权累加。

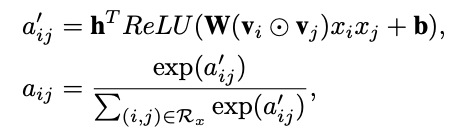
缺点:AFM只是在FM的基础上添加了attention的机制,但是实际上,由于最后的加权累加,二次项并没有进行更深的网络去学习非线性交叉特征,所以AFM并没有发挥出DNN的优势。
NFM
NFM(Neural Factorization Machines),其函数形式![]() ,其中,f(x)是用来建模特征之间交互关系的多层前馈神经网络模块。NFM网络结构如下图,embedding layer 得到的vector即FM中要学习的隐向量v,B-Interaction Layer其实就是计算FM中的二次项的过程,因此得到的向量维度就是我们的Embedding的维度,其结果为:
,其中,f(x)是用来建模特征之间交互关系的多层前馈神经网络模块。NFM网络结构如下图,embedding layer 得到的vector即FM中要学习的隐向量v,B-Interaction Layer其实就是计算FM中的二次项的过程,因此得到的向量维度就是我们的Embedding的维度,其结果为:![]() ,Hidden Layers就是我们的DNN部分,将Bi-Interaction Layer得到的结果接入多层的神经网络进行训练,从而捕捉到特征之间复杂的非线性关系。在进行多层训练之后,将最后一层的输出求和,同时加上一次项和偏置项,就得到了我们的预测输出。
,Hidden Layers就是我们的DNN部分,将Bi-Interaction Layer得到的结果接入多层的神经网络进行训练,从而捕捉到特征之间复杂的非线性关系。在进行多层训练之后,将最后一层的输出求和,同时加上一次项和偏置项,就得到了我们的预测输出。

PNN
思想来源:MLP中的节点add操作可能不能有效探索到不同类别数据之间的交互关系,虽然MLP理论上可以以任意精度逼近任意函数,但越泛化的表达,拟合到具体数据的特定模式越不容易。DNN的高阶特征交互建模是元素级的(bit-wise),也就是说同一个域对应的embedding向量中的元素也会相互影响,而FM类方法是以向量级(vector-wise)的方式来构建高阶交叉关系,vector-wise的方式构建的特征交叉关系比bit-wise的方式更容易学习。虽然两种建模交叉特征的方式有一些区别,但两者并不是相互排斥的,如果能把两者集合起来,便会相得益彰。PNN便是采用了这种方式。
PNN(Product-based Neural Networks)主要是在深度学习网络中增加了一个inner/outer product layer,用来建模特征之间的关系。网络结构如下图,Embedding Layer和Product Layer之间的权重为常量1,在学习过程中不更新。Product Layer的节点分为两部分,一部分是线性部分Z向量,一部分是非线性部分P向量,Z向量的维数与输入层的Field个数(N)相同,,P向量的每个元素的值由embedding层的feature向量两两成对并经过Product操作之后生成,
![]() ,维度为N*(N-1),fi即每个field的embedding向量。
,维度为N*(N-1),fi即每个field的embedding向量。

PNN核心部分在于其Product思想,来源于在ctr预估中,认为特征之间的关系更多是一种and“且”的关系,而非add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。Product操作有两种:内积和外积;对应的网络结构分别为IPNN和OPNN,两者的区别如下图,IPNN中P的计算即使用内积来代表pij,所以,pij其实是一个数;而OPNN的计算使用外积,此时pij为M*M的矩阵。

由于IPNN和OPNN中的计算复杂度过高,文章对其计算进行了优化。
在IPNN中,由于Product Layer的P向量由field两两配对产生,因此维度膨胀很大,给l1 Layer的节点计算带来了很大的压力。受FM启发,可以把这个大矩阵转换分解为小矩阵和它的转置相乘(对称矩阵的分解),表征到低维度连续向量空间,来减少模型复杂度:
![]()
在OPNN中,外积操作带来更多的网络参数,为减少计算量,使得模型更易于学习,采用了多个外积矩阵按元素叠加(element-wise superposition)的技巧来减少复杂度,其重新定义了p矩阵,具体如下:
![]()
Wide&Deep
上述几种串行结构,将embedding后的向量输入到神经网络中,使低阶和高阶特征组合隐含地体现在隐藏层中,学习到一个隐式交叉特征,这样无法确定学习到了多少阶的交叉特征。而如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合,这就产生了并行的网络结构。
像LR这样的wide模型学习特征与目标之间的直接相关关系,偏重记忆(memorization),如在推荐系统中,wide模型产生的推荐是与用户历史行为的物品直接相关的物品。这样的模型缺乏刻画特征之间的关系的能力,比如模型无法感知到“土豆”和“马铃薯”是相同的实体,在训练样本中没有出现的特征组合自然就无法使用,因此可能模型学习到某种类型的用户喜欢“土豆”,但却会判定该类型的用户不喜欢“马铃薯”。
WDL(Wide & Deep Learning)是Google在2016年提出的模型,其巧妙地将传统的特征工程与深度模型进行了强强联合。模型结构如下:

WDL分为wide和deep两部分联合训练,单看wide部分与LR模型并没有什么区别;deep部分则是先对不同的ID类型特征做embedding,在embedding层接一个全连接的MLP(多层感知机),用于学习特征之间的高阶交叉组合关系。由于Embedding机制的引入,WDL相对于单纯的wide模型有更强的泛化能力。
特点:PNN与FM相比,舍弃了低阶特征,也就是线性的部分,这在一定程度上使得模型不太容易记住一些数据中的规律。而WDL模型混合了宽度模型与深度模型,其宽度部分保留了低价特征,偏重记忆;深度部分引入了bit-wise的特征交叉能力。WDL模型的一大缺点是宽度部分的输入依旧依赖于大量的人工特征工程。
DeepFM
FNN模型首先预训练FM,再将训练好的FM应用到DNN中。PNN网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。PNN和FNN与其他已有的深度学习模型类似,都很难有效地提取出低阶特征组合。WDL模型混合了宽度模型与深度模型,但是宽度模型的输入依旧依赖于特征工程。
上述模型要不然偏向于低阶特征或者高阶特征的提取,要不然依赖于特征工程。而DeepFM模型可以以端对端的方式来学习不同阶的组合特征关系,并且不需要其他特征工程。DeepFM的结构中包含了因子分解机部分以及深度神经网络部分,分别负责低阶特征的提取和高阶特征的提取。其等价于FM + WDL,网络结构如下图:

上图中红色箭头所表示的链接权重恒定为1(weight-1 connection),在训练过程中不更新,可以认为是把节点的值直接拷贝到后一层,再参与后一层节点的运算操作。DeepFM包含两部分:神经网络部分与因子分解机部分,这两部分共享相同的输入与embedding向量。对于给定特征i,向量Wi用于表征一阶特征的重要性,隐变量Vi是用于表示该特征与其他特征的相互影响。在FM部分,Vi用于表征二阶特征,同时在DNN部分用于构建高阶特征。所有的参数端到端的进行训练。DeepFM最终的预测结果:![]() ,其中
,其中![]() 即与前面介绍的FM模型一致,
即与前面介绍的FM模型一致,![]() H为隐层的层数。
H为隐层的层数。
特点:DeepFM在融合bit-wise和vector-wise交叉特征的基础上,同时还能保留低阶特征。DeepFM模型融合了FM和WDL模型,其FM部分实现了低阶特征和vector-wise的二阶交叉特征建模,其Deep部分使模型具有了bit-wise的高阶交叉特征建模的能力。
DeepFFM
有了DeepFM自然就有DeepFFM,相比DeepFM,DeepFFM将FM换成了FFM,且在FFM侧去除了二阶特征,在DNN侧输入可采用2中不同的方式。公式![]()
两种方式得到DNN部分的输入,分别是计算内积和哈达玛积,如下式,最终输入DNN的维度分别是n(n-1)/2,n(n-1)/2*k


存在的问题
FM、DeepFM和Inner-PNN都是通过原始特征隐向量的内积来构建vector-wise的二阶交叉特征,这种方式有两个主要的缺点:1.必须要穷举出所有的特征对,即任意两个field之间都会形成特征组合关系,而过多的组合关系可能会引入无效的交叉特征,给模型引入过多的噪音,从而导致性能下降;2.二阶交叉特征有时候是不够的,好的特征可能需要更高阶的组合。虽然DNN部分可以部分弥补这个不足,但bit-wise的交叉关系是晦涩难懂、不确定并且不容易学习的。
DCN
思想来源:二阶交叉特征通过穷举所有的原始特征对得到,那么通过穷举的方法得到更高阶的交叉特征,必然会产生组合爆炸的维数灾难,导致网络参数过于庞大而无法学习,同时也会产生很多的无效交叉特征。DCN(Deep & Cross Network)便是针对该问题进行了有效处理。
DCN模型从嵌入和堆积层(embedding and stacking layer)开始,接着是一个交叉网络(cross network)和一个与之平行的深度网络(deep network),之后是最后的组合层(combination output layer),它结合了两个网络的输出,如下图所示。

embedding and stacking layer:将稀疏特征的embedding向量与连续特征向量叠加起来形成一个向量,作为模型的输入,![]() ;cross network:核心思想是以有效的方式应用显式特征交叉(显式地捕获高阶特征组合),每个层的输出
;cross network:核心思想是以有效的方式应用显式特征交叉(显式地捕获高阶特征组合),每个层的输出![]() 其中l表示对应层数,
其中l表示对应层数,为对应层的weight和bias参数,如下图Figure2所示,在完成一个特征交叉f后,每个cross layer会将它的输入加回去。cross network的独特结构使得交叉特征的阶(the degress of cross features)随着layer的深度而增长,在第l层layer,它的最高多项式阶为l+1。如果用Lc表示交叉层数,d表示输入维度,则总参数数量为:d * Lc * 2 (w和b)。一个cross network的时间和空间复杂度对于输入维度是线性关系。因而,比起它的deep部分,一个cross network引入的复杂度微不足道,DCN的整体复杂度与传统的DNN在同一水平线上。Deep network:获取高阶隐式特征交叉。 combination output layer:链接层将两个并行网络的输出连接起来,经过一层全链接层得到输出。

特点:DCN能够有效地捕获有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征工程或遍历搜索,实验结果表明,交叉网络(DCN)在LogLoss上与DNN相比少了近一个量级的参数量,具有较低的计算成本。同时,上图Figure2我们注意到![]() 的计算为一个数值标量,因此Cross Network的输出就相当于输入x0不断乘以一个数,只不过这个数与x0高度相关,DCN模型的两个主要的不足:1.CrossNet的输出被限定在一种特殊的形式上;2.特征交叉还是以bit-wise的方式构建的。
的计算为一个数值标量,因此Cross Network的输出就相当于输入x0不断乘以一个数,只不过这个数与x0高度相关,DCN模型的两个主要的不足:1.CrossNet的输出被限定在一种特殊的形式上;2.特征交叉还是以bit-wise的方式构建的。
xDeepFM
为了引入更高阶的vector-wise的交叉特征,同时又能控制模型的复杂度,避免产生过多的无效交叉特征,xDeepFM应运而生(DCN的进阶)。
xDeepFM模型是自动构建交叉特征且能够端到端学习的集大成者,为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,xDeepFM首先提出了一种新的名为压缩交互网络(Compressed Interaction Network,简称CIN)的模型。xDeepFM的框架结构如下图,模型的输入是所有field的embedding向量,这个与上面几个模型类似,从图中可以看出,最终输出包含三部分:原始特征部分、CIN模块和mlp。

模型的主要贡献就是CIN模块,详细结构如下图所示。该模块的主要功能就是捕捉特征高阶交叉,而且可以具体指定最高多少阶。CIN的输入是所有field的embedding向量构成的矩阵![]() m表示field的个数,D为embedding的维度,该矩阵的第i行对应第i个field的embedding向量。CIN网络也是一个多层的网络,它的第k层的输出也是一个矩阵,记为
m表示field的个数,D为embedding的维度,该矩阵的第i行对应第i个field的embedding向量。CIN网络也是一个多层的网络,它的第k层的输出也是一个矩阵,记为![]()
表示k层的embedding向量个数,
。CIN每层的输入包括两部分:上层的输出和整体输入
,
的第h行计算:
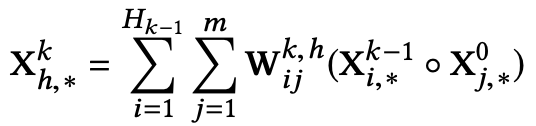 其中括号部分表示两者的哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量。根据下图(a)对该公式进行理解,在计算
其中括号部分表示两者的哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量。根据下图(a)对该公式进行理解,在计算时,定义一个中间变量,
![]() ,
,是个3维tensor,由D个数据矩阵堆叠而成,其中每个数据矩阵是由
的一个列向量与
的一个列向量的外积运算(Outer product)而得,
的生成过程实际上是由
与
沿着各自embedding向量的方向计算外积的过程。
可以被看作是一个宽度为m、高度为
、通道数为 D 的图像,在这个虚拟的图像上进行卷积操作即得到
,如下图(b),
是其中一个卷积核,总共有
个不同的卷积核,因而借用CNN网络中的概念,
可以看作是由
个feature map堆叠而成。
CIN的宏观框架如下图(c)所示,它的特点是,最终学习出的特征交互的阶数是由网络的层数决定的,每一层隐层都通过一个池化操作连接到输出层,从而保证了输出单元可以见到不同阶数的特征交互模式。同时不难看出,CIN的结构与循环神经网络RNN是很类似的,即每一层的状态是由前一层隐层的值与一个额外的输入数据计算所得。不同的是,CIN中不同层的参数是不一样的,而在RNN中是相同的;RNN中每次额外的输入数据是不一样的,而CIN中额外的输入数据是固定的,始终是。

集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。值得一提的是,为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据。而在具体的应用场景下,不同的模块也可以接入各自不同的输入数据,例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入一部分稀疏的特征子集。
FAT-DeepFFM
AFM模型,是在特征进行交叉之后,再对交叉特征进行权重计算,但本文认为,在特征进行交叉之前,对特征的重要性进行一个计算也十分重要。当特征为n个时,交叉后计算重要性的权重个数为n的平方,但是交叉前计算特征重要性的话,只需要计算n个权重。这么做的话在特征比较多的时候,对计算资源的节省是十分明显的。
该模型由张俊林老师提出,主要贡献:1.在特征进行交叉之前,对特征的重要性进行计算也十分重要,其效果比在特征交叉后加attention好;2.借鉴图像领域的SENet网络做attention

上图除了中间attention模块,其他同Deep FFM,文章主要贡献就在图中的attention部分,作者称为CENet Field Attention。分为两个阶段:
1.Compose阶段
每一个向量压缩成一维的值,每一个特征对应的Embedding Matrix是k * n,压缩之后变为一个n维的向量,较SENet的max pooling方式,本文改为采用一维卷积(1*1*k大小的filter)
2.Excitation阶段
将每个特征i对应的n维压缩向量计作DVi,n个特征向量拼接输入到2层的神经网络,输出n*n维度的向量作为每个field的attention权重。

DIN
DIEN
未完待续。。。
【参考】
https://www.zhihu.com/question/35821566
https://mp.weixin.qq.com/s/s79Dpq5v6ouvCE_vneTYBA
https://www.jianshu.com/p/152ae633fb00
Factorization Machines;
Wide & Deep Learning for Recommender Systems;
Deep Learning over Multi-Field Categorical Data: A Case Study on User Response Prediction;
Product-based Neural Networks for User Response Prediction;
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction;
Neural Factorization Machines for Sparse Predictive Analytics;
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks;
Deep & Cross Network for Ad Click Predictions;
Deep Interest Network for Click-Through Rate Prediction
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 基于Java Web的新闻发布系统设计与实现
获取项目源文件,技术交流与指导联系Q:1225467431 摘要:现如今快速发展的互联网,已成为新兴的媒体发布形式,逐步影响到传统媒体行业的发展。与传统的信息传播媒体如电视、广播、报纸等相比,电脑、智能手机等终端因其传递信息方便、快捷,并满足人们对外界瞬息万变的信息的…...
2024/4/16 23:10:06 - MySQL Workbench下数据库备份与恢复详解
一、登录数据库,找到Data Export 二、1、在左边选择自己要导出的数据库 2、选择数据库下要导出的表 3、选择导出位置 4、开始导出 三、导出后的数据 四、数据库恢复...
2024/5/6 7:09:30 - Android 谷歌官方Kotlin语言入门教程(一)基础语法
Kotlin简介Kotlin是一门与Swift类似的静态类型JVM语言,由JetBrains设计开发并开源。与Java相比,Kotlin的语法更简洁、更具表达性,而且提供了更多的特性,比如,高阶函数、操作符重载、字符串模板。它与Java高度可互操作,可以同时用在一个项目中Kotlin官方学习文档:1、教程 …...
2024/4/16 23:10:06 - ThingJSAPI之控制楼层效果
如何控制楼层的层级效果?比如进入楼层展开楼层?三维可视化园区中该怎么去访问对象?又是如何让场景显示和隐藏的呢?在ThingJS物联网可视化PaaS平台中,ThingJS提供了控制场景的方法,让我们来看看它是如何控制的吧! ThingJS官方示例中按分类访问对象,使用全局APP对象,通过…...
2024/5/6 6:44:30 - vuejs 和 element 搭建的一个后台管理界面
介绍: 这是一个用vuejs2.0和element搭建的后台管理界面。 相关技术: vuejs2.0:渐进式JavaScript框架,易用、灵活、高效,似乎任何规模的应用都适用。 element:基于vuejs2.0的ui组件库。 vue-router:一般单页面应用spa都要用到的前端路由。 vuex:Vuex 是一…...
2024/4/20 12:49:29 - Kotlin 第一章: Kotlin简介以及插件安装
Kotlin 第一章: Kotlin简介以及插件安装写在最前面:这篇文章是我把之前的文章更改编辑器,重新编译格式之后,上传的,所以文章顺序看起来会很奇怪,不过 CSDN 不支持两种编辑器互通也是蛮尴尬的。重点来了:首先,先来说一下 Kotlin 的发布时间吧。Kotlin 是于3月11号发布的…...
2024/4/16 23:09:48 - logrus hook输出日志到本地磁盘
logrus是go的一个日志框架,它最让人激动的应该是hook机制,可以在初始化时为logrus添加hook,logrus可以实现各种扩展功能,可以将日志输出到elasticsearch和activemq等中间件去,甚至可以输出到你的email和叮叮中去,不要问为为什么可以发现可以输入到叮叮中去,都是泪,手动…...
2024/4/16 23:09:00 - SQL SERVER 数据库备份的三种策略及语句
1.全量数据备份 备份整个数据库,恢复时恢复所有。优点是简单,缺点是数据量太大,非常耗时全数据库备份因为容易实施,被许多系统优先采用。在一天或一周中预定的时间进行全数据库备份使你不用动什么脑筋。使用这种类型的备份带来的问题是非常缺乏灵活性,而且当数据库被冲掉后…...
2024/4/16 23:10:12 - 熊市学技术—《挖矿=POW=工作量证明》
在《比特币:四十八万页的账本》中提到,货币的本质是记账方式,比特币是一种分布式的记账方式,那问题来了,这账是谁来记,怎么记?答案:矿工通过挖矿,来记账。说起挖矿这两字给人的第一印象是一帮黑不溜秋的矿工拿着锄头和探照灯,在漆黑的地下挖掘,在无数声叮叮当当的敲…...
2024/4/16 23:10:00 - C# 数据库课程设计
数据库课程设计报告 题目:安徽工业大学通讯录管理系统 学号: 1590.......姓名:程学长指导教师:陈业斌完成日期:2018年6月7日 目录一 引言1.1 通讯录系统设计开发的目的和意义1.2设计通讯录系统的任务及目标1.3通讯录系统开发及运行的软硬件环境二 通讯录…...
2024/4/16 23:10:12 - laravel 数据库备份和数据恢复
/*** 数据备份*/ public function save(){$DB_HOST = getenv(DB_HOST);$DB_DATABASE = getenv(DB_DATABASE); //从配置文件中获取数据库信息$DB_USERNAME = getenv(DB_USERNAME);$DB_PASSWORD = getenv(DB_PASSWORD);$dumpfname = $DB_DATABASE . "_" . date("Y…...
2024/4/17 2:04:21 - 看例子代码,学kotlin语法(1.3)(解构声明与数据类)
kotlin学习相关链接 在线学习 Kotlin 官方文档 中文站(更新到 1.1):https://www.kotlincn.net/ 网址(更新到 1.0.3):http://tanfujun.com/kotlin-web-site-cn/ Kotlin 中文论坛:https://www.kotliner.cn/ 《Kotlin for android developers》中文版翻译 语言学习网址:RU…...
2024/4/4 21:58:33 - 菜鸡刷CTF(四)
高手进阶(4) 题目12:wtc_rsa_bbq 难度系数: 题目来源: tinyctf-2014 题目描述:暂无 解题: 可以看到cry200的前几个字符为504B0304,这是zip文件的文件头,于是我们将其保存为zip文件。zip文件中包括key.pem文件和cipher.bin文件。 我们使用openssl可以获得公钥的信息,其…...
2024/4/16 23:10:54 - Angular_文档_03_生命周期_组件交互
Lifecycle HooksA component has a lifecycle managed by Angular.Angular creates it, renders it, creates and renders its children, checks it when its data-bound properties change, and destroys it before ......
2024/4/18 6:35:44 - 【Java】实现数据库备份-MySQL版
java实现mysql备份数据,直接code工具类 import java.io.BufferedReader; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.io.PrintWrit…...
2024/4/16 23:11:06 - 开发工程师人生之路
开发工程师人生之路原文地址:http://topic.csdn.net/u/20110323/16/16EBE2AC-BCA5-49DA-A050-45CF522A0828.html相对同时刚出校门同学从事其它行业而言优厚的薪水,以及不断学习更新的专业知识不仅仅让你感到生活的充实,更满足了你那不让外人知的虚荣心。在刚出校门的几年中,…...
2024/3/31 22:20:44 - Kotlin与java的互操作-Kotlin在Android中的使用(三)
文章目录一、Java调用Kotlin1.对象2.实例字段3.静态字段4.静态方法5.可见性6.生成重载7.受检异常8.空安全性二、Kotlin调用Java1.Getter 和 Setter2.返回 void 的方法3.将 Kotlin 中是关键字的 Java 标识符进行转义4.空安全与平台类型5.注解类型参数6.已映射类型7.Kotlin 中的 …...
2024/4/18 13:38:53 - 对比代码不同及反编译软件
众所周知java文件编译后会生成class文件,那我们在已知class的时候如何获取java呢?这个时候就需要反编译软件了,有很多种,博主用的是jd-gui小巧方便,直接将你的class文件拖入便自动反编译。对于有改变的代码还没有放在svn上对比的我们可以使用beyondCompare显示出不同,结构…...
2024/4/16 23:11:00 - 关于kotlin的简单使用
前言我就不介绍了,想要了解的可以去看下官方文档下面是kotlin中文的文档: https://www.gitbook.com/book/wangjiegulu/kotlin-for-android-developers-zh 我使用的Android studio2.3.2,需要下载kotlin插件,添加步骤: 在Android Studio中打开Settings,选择Plugins选项,输…...
2024/4/20 15:48:22 - (转一个帖子)10年造就一个程序员
最近园子到处充斥着类似《告别程序员生涯,一点感慨,与诸君共勉》http://topic.csdn.net/u/20110331/00/37ad95f8-f559-497f-b527-191eb701ef77.html?99610《开发工程师人生之路(强烈推荐,分析的透彻!)》http://topic.csdn.net/u/20110323/16/16ebe2ac-bca5-49da-a050-45cf5…...
2024/4/19 2:44:50
最新文章
- 介绍一下std::thread
std::thread 是 C11 标准库中的一个类,它用于表示和控制线程的执行。通过 std::thread,你可以创建和管理多个并发执行的线程,这些线程可以共享应用程序的资源,并执行不同的任务。 创建线程 std::thread 的构造函数用于创建线程。…...
2024/5/6 18:37:13 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/6 9:38:23 - 比nestjs更优雅的ts控制反转策略-依赖查找
一、Cabloy5.0内测预告 Cabloy5.0采用TS对整个全栈框架进行了脱胎换骨般的大重构,并且提供了更加优雅的ts控制反转策略,让我们的业务开发更加快捷顺畅 1. 新旧技术栈对比: 后端前端旧版js、egg2.0、mysqljs、vue2、framework7新版ts、egg3…...
2024/5/6 2:59:50 - 【初阶数据结构】——牛客:OR36 链表的回文结构
文章目录 1. 题目介绍2. 思路分析3. 代码实现 1. 题目介绍 链接: link 这道题呢是让我们判断一个链表是否是回文结构。但是题目要求设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法。 所以如果我们想把链表的值存到一个数组中再去判断就不可行了。 2. 思路…...
2024/5/3 2:47:37 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/4 23:54:56 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/4 23:54:56 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/6 9:21:00 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/4 23:55:16 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/6 1:40:42 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/4 23:55:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/4 23:55:06 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/4 23:55:06 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/4 23:55:16 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/4 23:55:01 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57