PyTorch多卡分布式训练DistributedDataParallel 使用方法
PyTorch多卡分布式训练DistributedDataParallel 使用方法
目录
PyTorch多卡分布式训练DistributedDataParallel 使用方法
1.DP模式和DP模式
(1)单进程多GPU训练模式:DP模式
(2)多进程多GPU训练模式:DDP模式
2.Pytorch分布式训练方法
3.Pytorch-Base-Trainer(PBT)分布式训练工具
(1) 工具介绍
(2) 安装
(3)使用方法
4.Example: 构建自己的分类Pipeline
5.可视化
1.DP模式和DP模式
Pytorch多卡训练有两种方式,一种是单进程多GPU训练模式(single process multi-gpus),另一种的多进程多卡模式(multi-processes multi-gpus)
(1)单进程多GPU训练模式:DP模式
Pytorch通过nn.DataParallel可实现多卡训练模型(简称DP模式),这是single process multi-gpus 的多卡并行机制,这种并行模式下并行的多卡都是由一个进程进行控制,其缺点有:
- 尽管 DataLoader 可以指定 num_worker,增加负责加载数据的线程数量,但是线程的资源受限于父进程,且由于python的GIL机制,不能利用好多核的并行优势
- 模型在 gpu 群组中进行初始化与广播过程依赖单一进程的串行操作
- DP模式相当于将多个GPU卡合并为一个卡进行训练
尽管DataParallel更易于使用(只需简单包装单GPU模型),但由于使用一个进程来计算模型权重,然后在每个批处理期间将分发到每个GPU,因此通信很快成为一个瓶颈,GPU利用率通常很低。而且,nn.DataParallel要求所有的GPU都在同一个节点上(不支持分布式)。
(2)多进程多GPU训练模式:DDP模式
Pytorch通过nn.parallel.DistributedDataParallel可实现多进程多卡训练模型(也称DDP模式),这种多卡并行机制的特点/优势有:
- 一个进程一个GPU(当然可以让每个进程控制多个GPU,但这显然比每个进程有一个GPU要慢)
- 充分利用多核并行的优势加载数据
- 模型在 gpu 群组中进行初始化的过程由各自的进程负责调度
- 代码可以无缝切换单机多卡与多机多卡训练,因为此时单机单卡成为了单机多卡/多机多卡并行下的一个特例
- GPU可以都在同一个节点上,也可以分布在多个节点上。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程或者说GPU之间只传递梯度,这样网络通信就不再是瓶颈。

在训练过程中,每个进程从磁盘加载batch数据,并将它们传递到其GPU。每一个GPU都有自己的前向过程,然后梯度在各个GPUs间进行All-Reduce。每一层的梯度不依赖于前一层,所以梯度的All-Reduce和后向过程同时计算,以进一步缓解网络瓶颈。在后向过程的最后,每个节点都得到了平均梯度,这样模型参数保持同步。
这就要求多个进程,甚至多个节点上的多个进程实现同步并通信。Pytorch通过distributed.init_process_group函数来实现这一点。他需要知道进程0位置以便所有进程都可以同步,以及预期的进程总数。每个进程都需要知道进程总数及其在进程中的顺序,以及使用哪个GPU。通常将进程总数称为world_size。
Pytorch提供了nn.utils.data.DistributedSampler来为各个进程切分数据,以保证训练数据不重叠。
nn.DataParallel和nn.distributedataparallel的主要差异可以总结为以下几点:
DistributedDataParallel支持模型并行,而DataParallel并不支持,这意味如果模型太大单卡显存不足时只能使用前者;DataParallel是单进程多线程的,只用于单机情况,而DistributedDataParallel是多进程的,适用于单机和多机情况,真正实现分布式训练;DistributedDataParallel的训练更高效,因为每个进程都是独立的Python解释器,避免GIL问题,而且通信成本低其训练速度更快,基本上DataParallel已经被弃用;- 必须要说明的是
DistributedDataParallel中每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的;
除了PyTorch官方实现的分布式训练方案,还有horovod分布式训练工具,不仅支持PyTorch还支持TensorFlow和MXNet框架,实现起来也是比较容易的,速度方面应该不相上下。
参考资料:PyTorch分布式训练简明教程 - 知乎
2.Pytorch分布式训练方法
分布式训练一般分为数据并行和模型并行两种,Pytorch分布式训练的实现步骤可简述如下:
- 首先在nn.DataParallel(即DP模式下)实现多卡加载数据,训练模型并调试成功;这一步是为了保证你的训练流程正常无BUG。然后就可以开始魔改了
- 数据并行(分布式):
DataLoader的样本采样器(sampler)修改为分布式采样器torch_utils.distributed.DistributedSampler - 模型并行(分布式):将torch.nn.parallel.DistributedDataParallel 代替torch.nn.DataParallel
- 为了能够使用 DistributedDataParallel 需要先进行进程间通讯环境的初始化,torch.distributed.init_process_group()
- 为了解决并行训练中加载到各个 worker/gpu 中的 sub-mini-batch 之间出现 example overlap 问题,还可以配合 torch.utils.data.distributed.DistributedSampler 进行使用
- 为了让进程与 gpu 进行一一匹配,在程序的开头通过 torch.cuda.set_device 设定目标设备
- (可选)为了让各个 worker/gpu 能有一致的初始值,在程序开头通过 torch.manual_seed 与 torch.cuda.manual_seed 来初始化随机数种子
所以代码结构如下:
# filename: distributed_example.py
# import some module
...
...parser = argparse.Argument()
parser.add_argument('--init_method', defalut='env://', type=str)
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse()import os
# Set master information and NIC
# NIC for communication
os.environ['NCCL_SOCKET_IFNAME'] = 'xxxx'
# set master node address
# recommend setting to ib NIC to gain bigger communication bandwidth
os.environ['MASTER_ADDR'] = '192.168.xx.xx'
# set master node port
# **caution**: avoid port conflict
os.environ['MASTER_PORT'] = '1234'def main():# step 1# set random seedtorch.manual_seed(seed)torch.cuda.manual_seed(seed)# step 2# set target devicetorch.cuda.set_device(args.local_rank)# step 3# initialize process group# use nccl backend to speedup gpu communicationtorch.distributed.init_process_group(backend='nccl', init_method=args.init_method)......# step 4# set distributed sampler# the same, you can set distributed sampler for validation settrain_sampler = torch.utils.data.distributed.DistributedSampler(dataset_train)train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, sampler=train_sampler, pin_memory=PIN_MEMORY,num_workers=NUM_WORKERS)......# step 5# initialize model model = resnet50()model.cuda()# step 6# wrap model with distributeddataparallel# map device with model process, and we bind process n with gpu n(n=0,1,2,3...) by default.model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)......for epoch in range(epochs):# step 7# update sampler with epochtrain_sampler.set_epoch(epoch)# then do whatever you want to do, just like a single device/gpu training program......注意:
由于程序开头采用了 torch.cuda.set_device() 指定了目标的设备,所以后续的操作中如果有涉及要将数据、模型移动到 gpu 中的操作需要改为 model.cuda()、inputs.cuda(),该指令会将对象正确地复制到对应的 cuda 设备中。
如果你执意使用 to 操作,那么注意确保 xx.to('cuda:n') 中的 cuda:n 与目标设备是匹配的。
以多进程方式启动训练脚本
你当然可以以 python distributed_example.py 这样的形式启动训练脚本,不过这样无法触发多进程。pytorch 为多进程启动脚本提供了 launch 工具,所以正确的启动方式是:
python -m torch.distributed.launch --nnodes=<nodes> --nproc_per_node=<process per node> --node_rank=<rank of current node>\distributed_example.py --arg1 --arg2 and all other arguments of your trainning script参数说明:
- nnodes:指定参与计算的节点数量,默认值为1,单机多卡的训练中可以不用指定
- nproc_per_node:指定每个节点中的所要启动的进程数量,由于进程与 gpu 一一对应,所以这里的数值不能大于系统中所能使用的 gpu 数量
- node_rank: 指定当前节点在整个系统中的序号,从 0 开始递增,需要注意的是,在多机多卡训练中 node_rank == 0 的节点表示 master,所以 node_rank == 0 的节点必须是 MASTER_ADDR 所在的节点,否则多卡间的通信无法正确建立连接。
老实说,【从DP模式升级到DDP的方法】看起来简单,步骤也不多,但真正要跑起来还是很多地方需要优化的;
这种多进程训练的方法,每个进程需要分配一个卡进行训练,这就导致你保存模型,打印Log,测试数据都变成复杂了,比如会出现多个进程都会打印相同的Log的问题;一般建议你,定义一个主进程,且在主进程中打印Log,保存模型,测试数据等操作,这样可以避免上述问题了。
那有没有一个简单方法,可以快速实现Pytorch的分布式训练
有的,我今天就介绍一个我自己整合的Pytorch的分布式训练工具:Pytorch-Base-Trainer,基于这套工具,你可以简单配置,即可实现DP或者DDP模式的训练,而无需关注各种进程间通讯,端口设置等这些复杂的过程。
3.Pytorch-Base-Trainer(PBT)分布式训练工具
(1) 工具介绍
考虑到深度学习训练过程都有一套约定成俗的流程,鄙人借鉴Keras开发了一套基础训练库: Pytorch-Base-Trainer(PBT); 这是一个基于Pytorch开发的基础训练库,支持以下特征:
- 支持多卡训练训练(DP模式)和分布式多卡训练(DDP模式),参考build_model_parallel
- 支持argparse命令行指定参数,也支持config.yaml配置文件
- 支持最优模型保存ModelCheckpoint
- 支持自定义回调函数Callback
- 支持NNI模型剪枝(L1/L2-Pruner,FPGM-Pruner Slim-Pruner)nni_pruning
- 非常轻便,安装简单
博客介绍:
Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)_pan_jinquan的博客-CSDN博客考虑到深度学习训练过程都有一套约定成俗的流程,鄙人借鉴Keras开发了一套基础训练库: Pytorch-Base-Trainer(PBT); 这是一个基于Pytorch开发的基础训练库,支持以下特征:https://panjinquan.blog.csdn.net/article/details/122662902GitHub地址:
GitHub - PanJinquan/Pytorch-Base-Trainer: Pytorch分布式训练框架![]() https://github.com/PanJinquan/Pytorch-Base-Trainer
https://github.com/PanJinquan/Pytorch-Base-Trainer
(2) 安装
- 源码安装
git clone https://github.com/PanJinquan/Pytorch-Base-Trainer
cd Pytorch-Base-Trainer
bash setup.sh #pip install dist/basetrainer-*.*.*.tar.gz- pip安装
pip install basetrainer- 使用NNI 模型剪枝工具,需要安装NNI
# Linux or macOS
python3 -m pip install --upgrade nni
# Windows
python -m pip install --upgrade nni(3)使用方法
basetrainer使用方法可以参考example.py,构建自己的训练器,可通过如下步骤实现:
- step1: 新建一个类
ClassificationTrainer,继承trainer.EngineTrainer - step2: 实现接口
def build_train_loader(self, cfg, **kwargs):"""定义训练数据"""raise NotImplementedError("build_train_loader not implemented!")def build_test_loader(self, cfg, **kwargs):"""定义测试数据"""raise NotImplementedError("build_test_loader not implemented!")def build_model(self, cfg, **kwargs):"""定于训练模型"""raise NotImplementedError("build_model not implemented!")def build_optimizer(self, cfg, **kwargs):"""定义优化器"""raise NotImplementedError("build_optimizer not implemented!")def build_criterion(self, cfg, **kwargs):"""定义损失函数"""raise NotImplementedError("build_criterion not implemented!")def build_callbacks(self, cfg, **kwargs):"""定义回调函数"""raise NotImplementedError("build_callbacks not implemented!")
step3: 在初始化中调用build
def __init__(self, cfg):super(ClassificationTrainer, self).__init__(cfg)...self.build(cfg)...
step4: 实例化ClassificationTrainer,并使用launch启动分布式训练
def main(cfg):t = ClassificationTrainer(cfg)return t.run()if __name__ == "__main__":parser = get_parser()args = parser.parse_args()cfg = setup_config.parser_config(args)launch(main,num_gpus_per_machine=len(cfg.gpu_id),dist_url="tcp://127.0.0.1:28661",num_machines=1,machine_rank=0,distributed=cfg.distributed,args=(cfg,))4.Example: 构建自己的分类Pipeline
basetrainer使用方法可以参考example.py
# 单进程多卡训练
python example.py --gpu_id 0 1 # 使用命令行参数
python example.py --config_file configs/config.yaml # 使用yaml配置文件
# 多进程多卡训练(分布式训练)
python example.py --config_file configs/config.yaml --distributed # 使用yaml配置文件
- 目标支持的backbone有:resnet[18,34,50,101], ,mobilenet_v2等,详见backbone等 ,其他backbone可以自定义添加
- 训练参数可以通过两种方法指定: (1) 通过argparse命令行指定 (2)通过config.yaml配置文件,当存在同名参数时,以配置文件为默认值
| 参数 | 类型 | 参考值 | 说明 |
|---|---|---|---|
| train_data | str, list | - | 训练数据文件,可支持多个文件 |
| test_data | str, list | - | 测试数据文件,可支持多个文件 |
| work_dir | str | work_space | 训练输出工作空间 |
| net_type | str | resnet18 | backbone类型,{resnet,resnest,mobilenet_v2,...} |
| input_size | list | [128,128] | 模型输入大小[W,H] |
| batch_size | int | 32 | batch size |
| lr | float | 0.1 | 初始学习率大小 |
| optim_type | str | SGD | 优化器,{SGD,Adam} |
| loss_type | str | CELoss | 损失函数 |
| scheduler | str | multi-step | 学习率调整策略,{multi-step,cosine} |
| milestones | list | [30,80,100] | 降低学习率的节点,仅仅scheduler=multi-step有效 |
| momentum | float | 0.9 | SGD动量因子 |
| num_epochs | int | 120 | 循环训练的次数 |
| num_warn_up | int | 3 | warn_up的次数 |
| num_workers | int | 12 | DataLoader开启线程数 |
| weight_decay | float | 5e-4 | 权重衰减系数 |
| gpu_id | list | [ 0 ] | 指定训练的GPU卡号,可指定多个 |
| log_freq | in | 20 | 显示LOG信息的频率 |
| finetune | str | model.pth | finetune的模型 |
| use_prune | bool | True | 是否进行模型剪枝 |
| progress | bool | True | 是否显示进度条 |
| distributed | bool | False | 是否使用分布式训练 |
一个简单分类例子如下:
# -*-coding: utf-8 -*-
"""@Author : panjq@E-mail : pan_jinquan@163.com@Date : 2021-07-28 22:09:32
"""
import os
import syssys.path.append(os.getcwd())
import argparse
import basetrainer
from torchvision import transforms
from torchvision.datasets import ImageFolder
from basetrainer.engine import trainer
from basetrainer.engine.launch import launch
from basetrainer.criterion.criterion import get_criterion
from basetrainer.metric import accuracy_recorder
from basetrainer.callbacks import log_history, model_checkpoint, losses_recorder, multi_losses_recorder
from basetrainer.scheduler import build_scheduler
from basetrainer.optimizer.build_optimizer import get_optimizer
from basetrainer.utils import log, file_utils, setup_config, torch_tools
from basetrainer.models import build_modelsprint(basetrainer.__version__)class ClassificationTrainer(trainer.EngineTrainer):""" Training Pipeline """def __init__(self, cfg):super(ClassificationTrainer, self).__init__(cfg)torch_tools.set_env_random_seed()cfg.model_root = os.path.join(cfg.work_dir, "model")cfg.log_root = os.path.join(cfg.work_dir, "log")if self.is_main_process:file_utils.create_dir(cfg.work_dir)file_utils.create_dir(cfg.model_root)file_utils.create_dir(cfg.log_root)file_utils.copy_file_to_dir(cfg.config_file, cfg.work_dir)setup_config.save_config(cfg, os.path.join(cfg.work_dir, "setup_config.yaml"))self.logger = log.set_logger(level="debug",logfile=os.path.join(cfg.log_root, "train.log"),is_main_process=self.is_main_process)# build projectself.build(cfg)self.logger.info("=" * 60)self.logger.info("work_dir :{}".format(cfg.work_dir))self.logger.info("config_file :{}".format(cfg.config_file))self.logger.info("gpu_id :{}".format(cfg.gpu_id))self.logger.info("main device :{}".format(self.device))self.logger.info("num_samples(train):{}".format(self.num_samples))self.logger.info("num_classes :{}".format(cfg.num_classes))self.logger.info("mean_num :{}".format(self.num_samples / cfg.num_classes))self.logger.info("=" * 60)def build_optimizer(self, cfg, **kwargs):"""build_optimizer"""self.logger.info("build_optimizer")self.logger.info("optim_type:{},init_lr:{},weight_decay:{}".format(cfg.optim_type, cfg.lr, cfg.weight_decay))optimizer = get_optimizer(self.model,optim_type=cfg.optim_type,lr=cfg.lr,momentum=cfg.momentum,weight_decay=cfg.weight_decay)return optimizerdef build_criterion(self, cfg, **kwargs):"""build_criterion"""self.logger.info("build_criterion,loss_type:{},num_classes:{}".format(cfg.loss_type, cfg.num_classes))criterion = get_criterion(cfg.loss_type, cfg.num_classes, device=self.device)return criteriondef build_train_loader(self, cfg, **kwargs):"""build_train_loader"""self.logger.info("build_train_loader,input_size:{}".format(cfg.input_size))transform = transforms.Compose([transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),transforms.RandomHorizontalFlip(),transforms.RandomCrop([cfg.input_size[1], cfg.input_size[0]]),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])dataset = ImageFolder(root=cfg.train_data, transform=transform)cfg.num_classes = len(dataset.classes)cfg.classes = dataset.classesloader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="train",shuffle=True, pin_memory=False, drop_last=True, distributed=cfg.distributed)return loaderdef build_test_loader(self, cfg, **kwargs):"""build_test_loader"""self.logger.info("build_test_loader,input_size:{}".format(cfg.input_size))transform = transforms.Compose([transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),transforms.CenterCrop([cfg.input_size[1], cfg.input_size[0]]),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])dataset = ImageFolder(root=cfg.train_data, transform=transform)loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="test",shuffle=False, pin_memory=False, drop_last=False, distributed=False)return loaderdef build_model(self, cfg, **kwargs):"""build_model"""self.logger.info("build_model,net_type:{}".format(cfg.net_type))model = build_models.get_models(net_type=cfg.net_type, input_size=cfg.input_size,num_classes=cfg.num_classes, pretrained=True)if cfg.finetune:self.logger.info("finetune:{}".format(cfg.finetune))state_dict = torch_tools.load_state_dict(cfg.finetune)model.load_state_dict(state_dict)if cfg.use_prune:from basetrainer.pruning import nni_pruningsparsity = 0.2self.logger.info("use_prune:{},sparsity:{}".format(cfg.use_prune, sparsity))model = nni_pruning.model_pruning(model,input_size=[1, 3, cfg.input_size[1], cfg.input_size[0]],sparsity=sparsity,reuse=False,output_prune=os.path.join(cfg.work_dir, "prune"))model = self.build_model_parallel(model, cfg.gpu_id, distributed=cfg.distributed)return modeldef build_callbacks(self, cfg, **kwargs):"""定义回调函数"""self.logger.info("build_callbacks")# 准确率记录回调函数acc_record = accuracy_recorder.AccuracyRecorder(target_names=cfg.classes,indicator="Accuracy")# loss记录回调函数loss_record = losses_recorder.LossesRecorder(indicator="loss")# Tensorboard Log等历史记录回调函数history = log_history.LogHistory(log_dir=cfg.log_root,log_freq=cfg.log_freq,logger=self.logger,indicators=["loss", "Accuracy"],is_main_process=self.is_main_process)# 模型保存回调函数checkpointer = model_checkpoint.ModelCheckpoint(model=self.model,optimizer=self.optimizer,moder_dir=cfg.model_root,epochs=cfg.num_epochs,start_save=-1,indicator="Accuracy",logger=self.logger)# 学习率调整策略回调函数lr_scheduler = build_scheduler.get_scheduler(cfg.scheduler,optimizer=self.optimizer,lr_init=cfg.lr,num_epochs=cfg.num_epochs,num_steps=self.num_steps,milestones=cfg.milestones,num_warn_up=cfg.num_warn_up)callbacks = [acc_record,loss_record,lr_scheduler,history,checkpointer]return callbacksdef run(self, logs: dict = {}):self.logger.info("start train")super().run(logs)def main(cfg):t = ClassificationTrainer(cfg)return t.run()def get_parser():parser = argparse.ArgumentParser(description="Training Pipeline")parser.add_argument("-c", "--config_file", help="configs file", default="configs/config.yaml", type=str)# parser.add_argument("-c", "--config_file", help="configs file", default=None, type=str)parser.add_argument("--train_data", help="train data", default="./data/dataset/train", type=str)parser.add_argument("--test_data", help="test data", default="./data/dataset/val", type=str)parser.add_argument("--work_dir", help="work_dir", default="output", type=str)parser.add_argument("--input_size", help="input size", nargs="+", default=[224, 224], type=int)parser.add_argument("--batch_size", help="batch_size", default=32, type=int)parser.add_argument("--gpu_id", help="specify your GPU ids", nargs="+", default=[0], type=int)parser.add_argument("--num_workers", help="num_workers", default=0, type=int)parser.add_argument("--num_epochs", help="total epoch number", default=50, type=int)parser.add_argument("--scheduler", help=" learning scheduler: multi-step,cosine", default="multi-step", type=str)parser.add_argument("--milestones", help="epoch stages to decay learning rate", nargs="+",default=[10, 20, 40], type=int)parser.add_argument("--num_warn_up", help="num_warn_up", default=3, type=int)parser.add_argument("--net_type", help="net_type", default="mobilenet_v2", type=str)parser.add_argument("--finetune", help="finetune model file", default=None, type=str)parser.add_argument("--loss_type", help="loss_type", default="CELoss", type=str)parser.add_argument("--optim_type", help="optim_type", default="SGD", type=str)parser.add_argument("--lr", help="learning rate", default=0.1, type=float)parser.add_argument("--weight_decay", help="weight_decay", default=0.0005, type=float)parser.add_argument("--momentum", help="momentum", default=0.9, type=float)parser.add_argument("--log_freq", help="log_freq", default=10, type=int)parser.add_argument('--use_prune', action='store_true', help='use prune', default=False)parser.add_argument('--progress', action='store_true', help='display progress bar', default=True)parser.add_argument('--distributed', action='store_true', help='use distributed training', default=False)parser.add_argument('--polyaxon', action='store_true', help='polyaxon', default=False)return parserif __name__ == "__main__":parser = get_parser()cfg = setup_config.parser_config(parser.parse_args(), cfg_updata=True)launch(main,num_gpus_per_machine=len(cfg.gpu_id),dist_url="tcp://127.0.0.1:28661",num_machines=1,machine_rank=0,distributed=cfg.distributed,args=(cfg,))
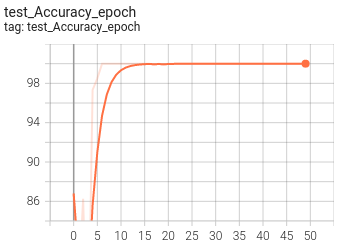
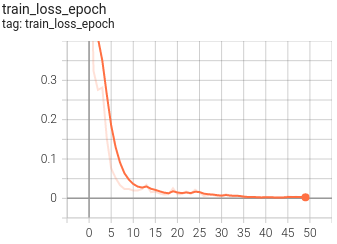
5.可视化
目前训练过程可视化工具是使用Tensorboard,使用方法:
tensorboard --logdir=path/to/log/ | 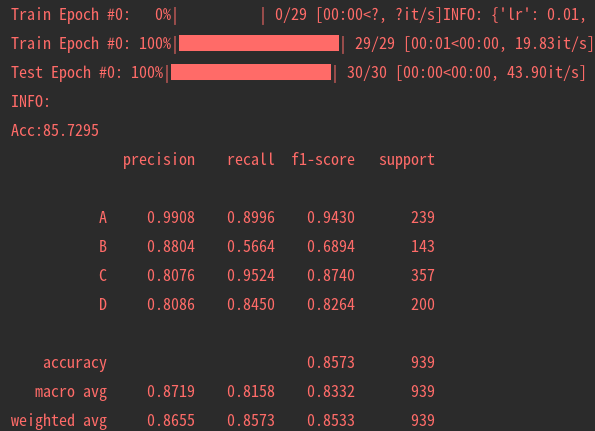 |
|---|---|
 |  |
 |  |
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 在WSL2上安装ArchLinux,及终端中文显示配置
wsl 配置wsl2 1.启用wsl 用管理员打开powershell输入 dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart2. 升级为WSL2的必要条件 对于x64的系统要求win10版本为1903 或者更高win R 输入 winver查看版本 3. 启用虚拟平…...
2024/4/18 10:58:40 - (每日一练python)搜索插入位置
搜索插入位置 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 你可以假设数组中无重复元素。 示例 1: 输入: [1,3,5,6], 5 输出: 2 示例 2: 输入: [1,3,5,6…...
2024/5/7 14:58:19 - 2022-2028全球及中国点对点微波天线行业研究及十四五规划分析报告
【报告篇幅】:113 【报告图表数】:154 【报告出版时间】:2021年12月 报告摘要 2021年全球点对点微波天线市场规模大约为208亿元(人民币),预计2028年将达到433亿元,2022-2028期间年复合增长率&…...
2024/4/13 15:03:15 - UEFI Spec chapter10 protocols-Device Path Protocol
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结前言 本节包含设备路径协议的定义,以及在UEFI环境中构建和管理设备路径所需的信…...
2024/4/13 13:17:40 - 设计模式——观察者模式
观察者模式 也被称为: 事件-订阅者模式,监听器模式 目的 观察者模式是允许你定义一个订阅机制去通知多个对象它们所观察的对象已经发生了某种事件的行为设计模式。 问题 想象一下有两个对象:顾客和商店。顾客对某个品牌的商品ÿ…...
2024/4/19 14:36:56 - 搜索引擎重视原创内容的原因是什么?
在做网站优化的时候,SEO人员都知道内容的重要性,在给网站添加内容的时候,一般都倾向于原创内容,因为搜索引擎很喜欢新颖的内容。 那么,搜索引擎重视原创内容的原因是什么?一起来了解一下吧! 1、…...
2024/4/13 13:17:25 - zsh,Powerlevel10k使用等
终端篇——Terminal三剑客之zsh - 知乎 powerlevel10k: 最好看,方便,实用的命令行主题 - zhangtianli - 博客园 利用zsh、oh-my-zsh、powerlevel10k打造一款好看好用的终端_KK下山去买菜-CSDN博客_powerlevel10k https://github.com/romkatv/powerleve…...
2024/4/18 0:20:15 - surfaceview组件的surfaceCreated()不被调用的解决方案
原文:surfaceview组件的surfaceCreated()不被调用的解决方案有时候我们有需要在native层做在surfaceview的上下文中做渲染,这个时候只是提供了一个单独什么都不做的surfaceview。 xml文件如下:<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/an…...
2024/5/7 15:55:10 - C++难点一:引用与取地址的区别
&(引用): 1.用途:给已定义的变量起别名,用来传值。 2.注意事项:在声明的时候一定要初始化。 3.判断方法: 判断方法一:出现在变量声明语句中变量的左边。 判断方法二:…...
2024/4/13 13:17:35 - opencv的solvepnp求头部姿态问题
opencv的solvepnp求头部姿态问题solvePnP与solvePnPRansac不同scale的3D Model的稳定性问题结论solvePnP与solvePnPRansac 据知乎 https://zhuanlan.zhihu.com/p/431617746 说法,RANSAC通过反复选择数据中的一组随机子集来达成目标。从而保证了稳定性,提…...
2024/4/13 13:17:35 - Vue框架相关知识day02
一、VueJS生命周期 1.1 每个 Vue 实例在被创建之前都要经过一系列的初始化过程 vue在生命周期中有这些状态,created,beforeMount,mounted,beforeUpdate,updated,beforeDestroy,destroyed。Vue 在实例化的过程中,会调用这些生命周期的钩子,给…...
2024/4/18 5:06:01 - string类型转换JSONObjec类型,并取出对应的值
方法一: var datJSON.parse(data); 方法二: String s p.get("params").toString(); JSONObject jsonObject (JSONObject) JSON.parse(s); jsonObject.get("jsh");...
2024/4/7 21:39:41 - 微信小程序-API wx.getSystemInfo(Object object) 获取系统信息
wx.getSystemInfo({success: res > {console.log(res.brand);//设备品牌console.log(res.pixelRatio);//设备像素比console.log(res.screenWidth);//屏幕宽度,单位pxconsole.log(res.screenHeight);//屏幕高度,单位pxconsole.log(res. windowWidth);/…...
2024/4/18 18:50:06 - 强制删除kubernetes的ns
5分钟6步强制删除kubernetes NameSpace小技巧 - 知乎 强制删除kubernetes的ns - 360linux - 博客园 kubectl proxy 换个窗口 kubectl get ns istio-operator -o json | jq del(.spec.finalizers) |curl -v -H "Content-Type: application/json" -X PUT --data-…...
2024/4/7 21:39:39 - 重学SpringCloud系列四之分布式配置中心---上
重学SpringCloud系列四之分布式配置中心---上服务配置中心概念及使用场景一、为什么要进行统一配置管理二、分布式配置管理中心三、主流配置中心Spring Cloud ConfigApolloNacos如何选择SpringCloudConfig配置中心Spring Cloud Config简介构建git配置文件仓库config配置中心搭建…...
2024/5/7 18:26:10 - s-function的during flag=n call must be a real vector of length n
根据刘金琨的《先进PID》中线性时变PID的传递函数写的S-fun根据下面这个贴子找到了问题所在 问题研究:flag1 call must be a real vector of length 12. – MATLAB中文论坛 一、问题描述 在用s-function编写状态方程,然后用于simulink仿真时,…...
2024/4/16 21:36:24 - 常用模块之datetime模块(date,time,datetime,timedelta)
from datetime import dateimport time# 创建对象 d1 = date(2018, 7, 31) print(d1)d2 = date.today() print(d2)d3 = date.fromtimestamp(time.time()) print(d3)# 标准格式 print(d3.isoformat())# 日历显示,格式:(年,日,星期) print(d2.isocalendar())# 获取星期,标…...
2024/4/15 9:53:14 - HTML5网页基础设计——课程介绍专栏
案例: 参考代码: <!doctype html> <html> <head> <meta charset"utf-8"> <title>动手实践</title> <style>*{margin: 0;padding: 0;font-size:14px; }dd{width: 461px;height: 145px;margin: -4p…...
2024/4/15 22:35:34 - C#实际案例分析(第六弹)
实验六 目录实验六题目要求环境设置题意分析后端数据库数据库概述SQLC#中的SQL前端ASP.NET Core前端基础知识HTML和JavaScriptASP.NET Core概述MVC(模型-视图-控制器,Model-View-Controller)RazorHTML和C#的结合体数据从何而来?完…...
2024/4/18 7:06:52 - SpringBoot中对SpringMvc的特殊定制
SpringBoot中对SpringMvc的特殊定制1、自定义拦截器2、CORS跨域请求2.1、全局配置2.2、单个配置3、Json3.1、Jackson的使用3.2、自定义json的序列化与反序列化4、国际化4.1、通过浏览器设置的语言参数,在请求头中获取实现国际化4.1.1、添加国际化资源文件4.1.2、配置…...
2024/4/18 3:43:04
最新文章
- 使用开放式用户通信连接两台西门子S71200plc
步骤1.在项目中创建两台PLC。 步骤2.分别设置两个PLC的参数。 plc1 plc2 步骤3.对两个plc进行组态 步骤4.在plc1和plc2中各自创建DB块,用于通信。 须在块的属性中取消优化块的访问选项。 plc1 plc2 步骤5.往plc1的main块中编写代码。 步骤6.往plc2的main块中编写…...
2024/5/7 18:53:42 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/7 10:36:02 - Next中的App Router
在next的13版本中,推出了一个新的App路由,由React Server Components构建,它支持共享布局、内部路由、加载状态、错误处理等。 App路由的工作目录在app目录中,app目录独立于pages目录,允许你一些路由使用pages目录&…...
2024/5/6 17:29:38 - 《前端防坑》- JS基础 - 你觉得typeof nullValue === null 么?
问题 JS原始类型有6种Undefined, Null, Number, String, Boolean, Symbol共6种。 在对原始类型使用typeof进行判断时, typeof stringValue string typeof numberValue number 如果一个变量(nullValue)的值为null,那么typeof nullValue "?" const u …...
2024/5/7 4:57:38 - 【JavaScript】如何在npm中切换源以及使用指定源安装依赖
忘不掉的是什么我也不知道 想不起当年模样 看也看不到 去也去不了的地方 也许那老街的腔调是属于我的忧伤 嘴角那点微笑越来越勉强 忘不掉的是什么我也不知道 放不下熟悉片段 回头望一眼 已经很多年的时间 透过手指间看着天 我又回到那老街 靠在你们身边渐行渐远 …...
2024/5/5 8:47:29 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/7 5:50:09 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/7 9:45:25 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/7 14:25:14 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/7 11:36:39 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/6 1:40:42 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/4 23:55:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/7 9:26:26 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/4 23:55:06 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/4 23:55:16 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/6 21:42:42 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57