自动驾驶中应用Transformer的单目 BEV 感知
Monocular BEV Perception with Transformers in Autonomous Driving
A review of academic literature and industry practice as of late 2021
作者:Patrick Langechuan Liu
原文地址: https://towardsdatascience.com/monocular-bev-perception-with-transformers-in-autonomous-driving-c41e4a893944
更新时间:
- Add DETR3D, 2021/11/07
- Add STSU, Translating images to maps, 2021/12/27
Mass production-grade autonomous driving requires scalable three-dimensional reasoning of the world. As the autonomous cars and other traffic agents move on the road, most of the time the reasoning does not need to account for height, making Birds-Eye-View (BEV) a sufficient representation.

An extremely simplified architecture of a traditional autonomous driving stack (Image by Author)
The above diagram illustrates a traditional autonomous driving stack (omitting here many aspects such as localization for simplicity). In this diagram, circles represent functional modules and are color-coded by the space they reside in. Green modules happen in 2D, and blue ones happen in BEV. Only camera perception takes place in 2D space, or more precisely, the perspective space where onboard camera images are obtained. It relies on Sensor Fusion with heavily hand-crafted rules to lift 2D detections to 3D, optionally with the help of 3D measurements from radar or lidar.
Here I say traditional for at least two reasons. First, camera perception still happens in perspective space (as opposed to a more recent trend of monocular 3D object detection, a review of which can be found here). Second, results from multimodal sensors are fused in a late-fusion fashion (as opposed to early-fusion where sensor data are fed into neural network for data-driven association and geometric reasoning).
BEV Perception is the future of camera perception
The diagram hints that it would be highly beneficial for the only outlier, camera perception, to move on to BEV. First of all, performing camera perception directly in BEV would make it straightforward to combine with perception results from other modalities such as radar or lidar as they are already represented and consumed in BEV. Perception results in BEV space would also be readily consumable by downstream components such as prediction and planning. Second, it is not scalable to purely rely on hand-crafted rules to lift 2D observations to 3D. The BEV representation lends itself to transition to an early fusion pipeline, making the fusion process completely data-driven. Finally, in a vision-only system (no radar or lidar), it then almost becomes mandatory to perform perception tasks in BEV as no other 3D hints would be available in sensor fusion to perform this view transformation.
Monocular Bird’s-Eye-View Semantic Segmentation for Autonomous Driving
A review of BEV semantic segmentation as of 2020
towardsdatascience.com
I wrote a review blog post one year ago in late 2020 summarizing the papers in academia on monocular BEV perception. This field studies how to lift monocular images into BEV space for perception tasks. Since then, I have been updating it with more papers I read to keep that blog post up to date and relevant. The scope of this field has been expanding steadily from semantic segmentation to panoptic segmentation, object detection, and even other downstream tasks such as prediction or planning.
Over the past year, largely three approaches emerged in monocular BEV perception.
- IPM: This is the simple baseline based on the assumption of a flat ground. Cam2BEV is perhaps not the first work to do this but is a fairly recent and relevant work. It uses IPM to perform the feature transformation, and uses CNN to correct the distortion of 3D objects that are not on the 2D road surface.
- Lift-splat: Lift to 3D with monodepth estimation and splat on BEV. This trend is initiated by Lift-Splat-Shoot, and many follow-up works such as BEV-Seg, CaDDN, and FIERY.
- MLP: Use MLP to model the view transformation. This line of work is initiated by VPN, and Fishing Net, and HDMapNet to follow.
- Transformers: Use attention-based transformers to model the view transformation. Or more specifically, cross-attention based transformer module. This trend starts to show initial traction as transformers take the computer vision field by storm since mid-2020 and at least till this moment, as of late-2021.
In this review blog post, I will focus on the last and latest trend — the use of Transformers for view transformation.
Almost ironically, many of the papers in literature, some before and some amid this recent wave of uprising of Transformers in CV, refer to their ad-hoc view transformation module as “view transformers”. This makes the searching in literature even more challenging to identify those who indeed used attention modules for view transformation.
To avoid confusion, in later text of this blog post, I will use capitalized Transformers to refer to the attention-based architecture. That said, the use of Transformers to perform view transformation by lifting images to BEV seems to be a good pun.
View transformation with Transformers
The general architecture of Transformers has been extensively interpreted in many other blogs (such as the famous The Illustrated Transformer), and thus we will not focus on it here. Transformers are more suitable to perform the job of view transformation due to the global attention mechanism. Each position in the target domain has the same distance to access any location in the source domain, overcoming the locally confined receptive fields of convolutional layers in CNN.
Cross-attention vs self-attention

The use of cross-attention and self-attention in Transformers (source)
There are two types of attention mechanisms in Transformers, self-attention in the Encoder and cross-attention in the Decoder. The main difference between them is the query Q. In self-attention, the Q, K, V inputs are the same, whereas in cross-attention Q is in a different domain from that for K and V.
As detailed in my previous blog, the shape of the output of the attention module is the same as the query Q. In this regard, self-attention can be seen as a feature booster in the original feature domain, whereas cross-attention can be viewed as a cross-domain generator.
The idea of cross-attention is actually the original attention mechanism, even before the creation of Transformers. The attention mechanism is first mentioned in the ICLR 2015 paper “Neural Machine Translation by Jointly Learning to Align and Translate”. The more innovative contribution of the original NeurIPS 2017 Transformer paper “Attention is All you Need” is actually replacing the bi-directional RNN encoder with self-attention modules. That is perhaps the reason why many people still prefers the term attention instead of transformers when referring to cross-attention. For a more colorful narration please see here.
Cross-attention is all you need
Many of the recent advances in Transformers in CV actually only leverages the self-attention mechanism, such as the heavily cited ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021) or Swin Transformer (Hierarchical Vision Transformer using Shifted Windows, Arxiv 2021/03). They act as an enhancement to the backbone feature extractor. However, considering the difficulty in the deployment of the general Transformer architecture in resource-limited embedded systems typical on mass production vehicles, the incremental benefit of self-attention over the well-supported CNN can be hard to justify. Until we see some groundbreaking edge of self-attention over CNN, it would be a wise choice to focus on CNN for industry applications such as mass-production autonomous driving.
Cross-attention, on the other hand, has a more solid case to make. One pioneering study of applying cross-attention to computer vision is DETR (End-to-End Object Detection with Transformers, ECCV 2020). One of the most innovative parts of DETR is the cross-attention decoder based on a fixed number of slots called object queries. Different from the original Transformer paper where each query is fed into the decoder one by one (auto-regressively), these queries are fed into the DETR decode in parallel (simultaneously). The contents of the queries are also learned and do not have to be specified before training, except the number of the queries. These queries can be viewed as a blank, preallocated template to hold object detection results, and the cross-attention decoder does the work of filling in the blanks.

The Cross-Attention Decoder part of DETR can be viewed as a cross-domain generator (source)
This prompts the idea of using the cross-attention decoder for view transformation. The input view is fed into a feature encoder (either self-attention based or CNN-based), and the encoded features serve as K and V. The query Q in target view format can be learned and only need to be rasterized as a template. The values of Q can be learned jointly with the rest of the network.

The DETR architecture can be adapted for BEV transformation (Image by Author)
In the following session, we will review some most relevant work along this line, and also we will take a deep dive into the use of Transformers in Tesla’s FSD shared by Andrej Karpathy on Tesla AI Day (08/20/2021).
PYVA (CVPR 2021)
PYVA (Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation, CVPR 2021) is among the first to explicitly mention that a cross-attention decoder can be used for view transformation to lift image features to BEV space. Similar to earlier monocular BEV perception work, PYVA performs road layout and vehicle segmentation on the transformed BEV features.

The architecture of PYVA uses an MLP and cross-attention (source)
PYVA first used an MLP to lift image features X in the perspective space to X’ in the (claimed) BEV space. A second MLP maps the X’ back to image space X’’, and uses the cycle consistency loss between X and X” to make sure this mapping process retains as much relevant information as possible.
The Transformer used by PYVA is a cross-attention module, with the query Q to be mapped BEV feature X’ in BEV space, and V and K are both the input X in perspective space (if we ignore the differences between X and X” in perspective space).
Note that there is no explicit supervision for X’ in the BEV space, and is implicitly supervised by the downstream task loss in the BEV space.
In PYVA, it seems to be the MLP that does the heavy lifting of view transformation, and the cross-attention is used to enhance the lifted features in BEV. Yet as there is no explicit supervision of the generated query in BEV space, technically it is hard to separate the contribution from the two components. An ablation study of this would have been useful to clarify this.
NEAT (ICCV 2021)
NEAT (Neural Attention Fields for End-to-End Autonomous Driving, ICCV 2021) uses Transformers to enhance the features in image feature space, before using MLP-based iterative attention to lift image features into BEV space. The goal of the paper is interpretable, high-performance, end-to-end autonomous driving, but we will only focus on the generation of the interpretable intermediate BEV representation here.

The architecture of NEAT (source)
The Transformers used in the Encoder block are based on self-attention. The authors also acknowledged that “the transformer can be removed from our encoder without changing the output dimensionality, but we include it since it provides an improvement as per our ablation study”. As we discussed above, encoders equipped with the self-attention module can be treated just as a glorified backbone, and it is not the focus of this study.
The most interesting part happens in the Neural Attention Field (NEAT) module. For a given output location (x, y), an MLP is used to take the output location and the image features as input, generate an attention map of the same spatial dimension as the input feature image. The attention map is then used to dot-product the original image feature to generate the target BEV features for the given output location. If we iterate through all possible BEV grid locations, then we can tile the output from the NEAT module into a BEV feature map.

Cross Attention module vs Neural Attention Field module (Image by Author)
This NEAT module is quite similar to the cross attention mechanism. The main difference is that the similarity measurement step between Q and K is replaced by an MLP. There are other minor details that we are ignoring here, such as the Softmax operation, and the linear projection of the value V. Mathematically, we have the following formulations for MLP, cross attention and NEAT.

The difference between MLP, Cross-attention, and NEAT (adapted from source)
The symbol convention follows my previous blog post on the difference between MLP and Transformers. In short, it is apparent that NEAT keeps the data-dependency nature of the cross-attention mechanism, but it does not have the permutation invariance of cross-attention anymore.
There is one more detail omitted in the discussion above for the clarity of comparison with cross-attention mechanism. In the implementation of NEAT, the input of the MLP is not the fully-fledged image feature c, but a globally pooled c_i which does not have any spatial extent. And iterative attention is adopted. The authors argue that it is more complex to feed the image feature c with much higher dimension than c_i into the MLP. Maybe one pass of MLP is not enough to compensate the loss of spatial content, thus multiple passes are required. The paper did not provide ablation study of this design choice.
The Decoder part also uses an MLP to generate the desired semantic meaning of the queried location (x, y). If we tile the NEAT output into a BEV feature map, the MLP taking the feature at a specific location and the location coordinates as input is equivalent to a 1x1 convolution over the BEV feature map, with (x, y) concatenated to the feature map. This operation is very similar to CoordConv (NeurIPS 2018). This is fairly standard practice to leverage the BEV feature map for downstream BEV perception tasks. We can even go beyond the 1x1 convolutions and further improve the performance with stacked 3x3 convolutions to increase the receptive field in BEV space.
In summary, NEAT uses a variant of cross-attention (MLP to replace the similarity measurement) to lift camera images to BEV space.
STSU (ICCV 2021)
STSU (Structured Bird’s-Eye-View Traffic Scene Understanding from Onboard Images, ICCV 2021) uses sparse queries for object detection, following the practice of DETR. STSU detects not only dynamic objects but also static road layouts. This is a follow-up work to BEV Feature Stitching by the same authors, a paper on BEV semantic segmentation reviewed in my other blog.

The architecture of STSU (source)
STSU uses two sets of query vectors, one set for centerlines and one for objects. What is most interesting is its prediction of the structured road layout. The lane branch includes several prediction heads.
- The detection head predicts if the lane encoded by a certain query vector exists.
- The control head predicts the location of R Bezier curve control points.
- The association head predicts an embedding vector for clustering.
- The association classifier takes in 2 embedding vectors and judges whether the centerline pairs are associated.
Bezier curves are a good fit for centerline since it allows us to model a curve of arbitrary length with a fixed number of 2D points.
The use of Transformers for lane prediction is also used in LSTR (End-to-end Lane Shape Prediction with Transformers, WACV 2011), which is still in image space. The structured road layout prediction can also be found in HDMapNet (An Online HD Map Construction and Evaluation Framework, CVPR 2021 workshop), which did not use Transformers.
DETR3D (CoRL 2021)
DETR3D (3D Object Detection from Multi-view Images via 3D-to-2D Queries, CoRL 2021) also uses sparse queries for object detection, following the practice of DETR. Similar to STSU, but DETR3D focuses on dynamic object. The queries are in BEV space and they enable DETR3D to manipulate prediction directly in BEV space instead of doing a dense transformation of the image features.

The architecture of DETR3D (source)
One advantage of BEV perception over mono3D is in the camera overlap regions where objects are more likely to be cropped by camera field-of-view. Mono3D methods have to predict the cropped objects in each camera based on the limited information from each camera viewpoint and rely on global NMS to suppress redundant boxes. DETR3D specifically evaluated on such cropped objects at image boundaries (about 9% of the entire dataset) and found significant improvement of DETR3D over mono3D methods. This is also reported in Tesla AI Day.

Multi-Cam predictions are better than Single cam results (source)
DETR3D uses several tricks to boost the performance. First is the iterative refinement of object queries. Essentially, the predicts the bbox centers in BEV is reprojected back to images with camera transformation matrices (intrinsics and extrinsics), and multi-cam image features are sampled and integrated to refine the queries. This process can be repeated multiple times (6 in this paper) to boost the performance.
The second trick is to use pretrained mono3D network backbone to boost the performance. Initialization seems to matter quite a lot for Transformers-based BEV perception network.
Translating Images into Maps (2021/10, Arxiv)
Translating Images into Maps notices that, regardless of the depth of the image pixel, there is a 1–1 correspondence between a vertical scanline in the image (image column), and a polar ray passing through the camera location in an BEV map. This is similar to the idea of OFT (BMVC 2019) and PyrOccNet (CVPR 2020), which smears the feature at a pixel location along the ray projected back into 3D space.

The use of axial cross-attention Transformers in the column direction and convolution in the row direction saves computation significantly.
Tesla’s Approach
On Tesla AI Day in 2021, Tesla revealed many intricate inner workings of the neural network powering Tesla FSD. One of the most intriguing building blocks is one dubbed “image-to-BEV transform + multi-camera fusion). At the center of this block is a Transformer module, or more concretely, a cross-attention module.

Tesla’s FSD architecture (source)
You initialize a raster of the size of the output space that you would like, and you tile it with positional encodings with sines and cosines in the output space, and then these get encoded with an MLP into a set of query vectors, and then all of the images and their features also emit their own keys and values, and then the queries keys and values feed into the multi-headed self-attention (Note by the author: this is actually cross-attention).
— Andrej Karpathy, Tesla AI Day 2021, source
Although Andrej mentioned that they used a multi-headed self-attention, but what he described is clearly a cross-attention mechanism, and the chart on the right in his slides also points to the cross-attention block in the original Transformers paper.
The most interesting part in this view transformation is the query in BEV space. It is generated from a raster in the BEV space (blank, preallocated template, as in DETR) and concatenated with Positional Encodings (PE). There is also a Context Summary that tiles with the positional encodings. The diagram does not show the details in how the context summary is generated and used with positional encodings, but I think there is a global pooling that collapses all the spatial information in the perspective space, and a tiling operation that tiles this 1x1 tensor across the predefined BEV grid.
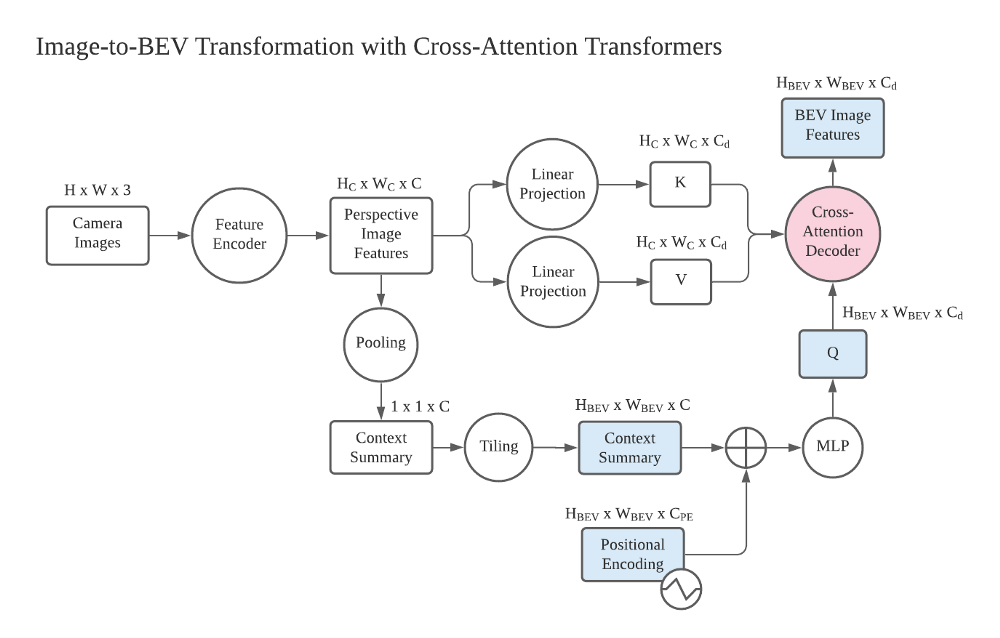
Building blocks and tensor shapes of the Image-to-BEV Transformation with cross-attention Transformers (Image by Author)
In the diagram above, I listed the more detailed blocks in the view transformation module (circles) and corresponding tensors with their shapes (squares), based on my understanding. The tensors in BEV space are color-coded blue, and the core cross-attention module is color-coded red. Hopefully, this helps interested readers in academia dig deeper in this direction.
A final word on Transformers vs MLP for BEV lifting
Illustrated Differences between MLP and Transformers for Tensor Reshaping
A deep dive into the math details, with illustrations.
towardsdatascience.com
(Lifting images to BEV space) is data dependent it’s really hard to have a fixed transformation for this component so in order to solve this issue we use a transformer to represent this space. — Andrej Karpathy, Tesla AI Day 2021
Andrej also mentioned that the view transformation problem is data-dependent and they opted for Transformers. Regarding the detailed usage of cross-attention for tensor reshaping and its difference from MLP is detailed in my previous blog, with some mathematical details and concrete illustrations. It also highlighted why the tensor reshaping by Transformers is data-dependent whereas MLP is not.
Takeaways
- Transformers are becoming more popular in academia and industry for view transformation.
- As discussed in my previous blog, though data dependency of Transformers makes it more expressive, it also makes it hard to train, and the break-even point with MLP may require tons of data, GPU and engineering efforts.
- The deployment of Transformers in the resource-limited embedded system in mass production autonomous vehicles may also be a major challenge. In particular, the current neural network accelerators or GPUs are highly optimized for convolutional neural networks (3x3 convolutions, for example).
Acknowledgment
I have had several rounds of discussion with Yi Gu, who is currently doing his Ph.D. research at the University of Macau. Our discussion prompted me to revisit the recent trend in the field of monocular BEV perception.
References
- NEAT: Neural Attention Fields for End-to-End Autonomous Driving, ICCV 2021
- PYVA: Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation, CVPR 2021
- Tesla AI day, streamed live on Youtube on Aug 20, 2021
- Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
- CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection, CVPR 2021 oral
- FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras, ICCV 2021
- BEV-Seg: Bird’s Eye View Semantic Segmentation Using Geometry and Semantic Point Cloud, CVPR 2020 workshop
- HDMapNet: An Online HD Map Construction and Evaluation Framework, CVPR 2021 workshop
- DETR: End-to-End Object Detection with Transformers, ECCV 2020
- Attention is All you Need, NeurIPS 2017
- Neural Machine Translation by Jointly Learning to Align and Translate, ICLR 2015
- ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Arxiv 2021/03
- CoordConv: An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, NeurIPS 2018
- STSU: Structured Bird’s-Eye-View Traffic Scene Understanding from Onboard Images, ICCV 2021
- DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries, CoRL 2021
- Translating Images into Maps, Arxiv 2021/10
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- centos-7.x安装Mysql
centos-7.x安装Mysql 日常踩坑 当我折腾安装好MySQL之后,来了一句,结果踩坑了,我找了好多教程,全是入坑的 systemctl start mysqld有博主这样解释到:由于MySQL在CentOS7中收费了,所以已经不支持MySQL了,…...
2024/4/14 5:15:58 - 零基础也可以--搭建一个属于自己的ETH中转服务器节点,并且带抽水功能
推荐阿里云服务器或者Ucloud 阿里云:云服务器ECS年终特惠 Ucloud:香港云服务器 如果苦力值不是特别高直接选择最便宜的就行,比较高可以选择带宽高一点的,推荐使用Linux的,Ubuntu 16 / Debian 8 / CentOS 7。 一、…...
2024/4/14 5:15:53 - Python核心编程-认识python
学习一门语言,都需要从它的发展历史开始,先去认识这门语言,了 解它的优缺点,以及它在工作中的应用。 .了解了Python之后, 首先入门的应该是变量,数据类型,运算符,输入与输出一些基础…...
2024/4/14 5:15:53 - SpringBoot嵌入Tomcat原理分析
SpringBoot嵌入Tomcat原理 内嵌Tomcat启动原理 首先,来到启动SpringBoot项目的地方,也就是朱配置类. SpringBootApplication public class InakiApplication {public static void main(String[] args) {SpringApplication.run(InakiApplication.class…...
2024/4/23 2:27:04 - 蓝桥杯训练赛(3)
目录 7-1 缩位求和 7-2 等腰三角形 7-3 结账问题 7-4 航班时间 7-5 全球变暖 7-6 完全二叉树的权值 7-7 小朋友崇拜圈 *7-8 倍数问题 7-9 递增三元组 *7-10 螺旋折线 *7-11 日志统计 *7-12 乘积最大 *7-13 耐摔指数 *7-14 三体攻击 7-1 缩位求和 -第九届蓝桥省赛…...
2024/4/16 9:08:50 - D9:Greatest Common Divisor(最大公约数,附题解)
原题:OpenJudge - 08:Greatest Common Divisor 翻译: 描述:给定A和B。找到A和B的最大公约数D。 输入:两个不大于10000的整数A、B; 输出:一个整数D。 代码:两种,①辗转相除即可&…...
2024/4/14 5:16:23 - UVM入门与进阶学习笔记13——新手上路
目录新手上路序列组件的互动继承关系新手上路 在UVM世界利用其核心特性,在创建了组件和顶层环境并完成组件之间的TLM端口连接以后,接下来就可以使得整个环境开始运转了;经过一番实践掌握了组件之间的TLM通信方式,开辟了建筑之间的…...
2024/4/14 5:16:03 - 泛微E9 OA 通过requestId获取流程当前待办人
SELECTA.creater AS 创建人Id,NODE.nodename AS 节点名称,cr.userId AS 待办人Id,cr.LASTNAME AS 待办人名称 FROMWORKFLOW_REQUESTBASE AINNER JOIN WORKFLOW_NODEBASE NODE ON NODE.ID A.CURRENTNODEIDINNER JOIN (SELECTREQUESTID,R1.LASTNAME,R1.id AS userId,RECEIVEDAT…...
2024/4/15 11:42:54 - C++ 第十二章 类和动态内存分布
12.1 动态内存和类 #ifndef D1_STRINGBAD_H #define D1_STRINGBAD_H#include <iostream>class stringbad { private:char * str;int len;static int num_strings; //静态成员变量,只创建一个静态副本 public:stringbad(const char *s );stringbad();~string…...
2024/4/7 16:55:28 - vue3快速上手
Vue3快速上手 1.Vue3简介 2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王)耗时2年多、2600次提交、30个RFC、600次PR、99位贡献者github上的tags地址:https://github.com/vuejs/vue-next/release…...
2024/4/23 14:54:49 - HTML上机
一、做一个表格,3行,4列,内容不限,表格格式要求 网页标题栏有显示;网页内容有标题;表格居中;表格有表头;表格显示内容有属性差异:表格间距;表格背景色&#…...
2024/4/7 16:55:27 - Android中的Handler类介绍,音视频开发进阶指南pdf
在Android平台中,新启动的线程是无法访问Activity里的Widget的,当然也不能将运行状态外送出来,这就需要有Handler机制进行消息的传递了,Handler类位于android.os包下,主要的功能是完成Activity的Widget与应用程序中线程…...
2024/4/14 5:16:08 - elasticsearch 搭配 canal 构建主从复制架构整合spring boot实战(二)
目录 前言 搭建环境 elasticsearch的多表结构设计 spring data elasticsearch实战 前言 上一篇完成了elasticsearch、elasticsearch-head的搭建,这一章将带入spring-boot进行开发整合。spring-boot为java的数据交互提供了许多的便利。其中spring-data模块整合了…...
2024/5/5 4:33:16 - 第十二章 类和动态内存分布
12.1 动态内存和类 #ifndef D1_STRINGBAD_H #define D1_STRINGBAD_H#include <iostream>class stringbad { private:char * str;int len;static int num_strings; //静态成员变量,只创建一个静态副本 public:stringbad(const char *s );stringbad();~string…...
2024/4/18 13:10:12 - 微服务探索之路03篇-docker私有仓库Harbor搭建+Kubernetes(k8s)部署私有仓库的镜像
目录: 微服务探索之路01篇.net6.0项目本地win10系统docker到服务器liunx系统docker的贯通 微服务探索之路02篇liunx ubuntu服务器部署k8s(kubernetes)-kubernetes/dashboard 1.简介 第一篇提到的docker官方提供了镜像仓库是公共的,私有的是需要收费的,所以我们需要在自己的服务…...
2024/4/14 5:16:14 - JAVA http请求工具类
日常工作难免遇到调用其他项目接口,一般都是restful风格,这个并非强制风格,根据项目不同能使用的工具不同,主要受限于项目类型:maven项目,一般项目等。有原生http协议进行交互,java原生自带对http的支持并不…...
2024/4/18 4:29:15 - kafka入门学习
kafka安装 下载,官网地址https://kafka.apache.org/downloads 安装 解压缩:tar -zxvf kafka_2.12-3.0.0.tgz安装步骤非常简单,直接解压即可,kafka 依赖的 Zookeeper 已经在此文件中包含配置 Zookeeper 开启: bin/zook…...
2024/4/20 11:54:16 - jenkins 配置阿里云Linux 的centos操作系统为slave节点,启动失败,提示:Launch failed - cleaning up connection
最近自己买了一台阿里云的centos服务器,准备使用持续化集成工具 jenkins 再去创建一个Linux 节点,结果去jenkins里面 启动节点的时候却报了如下的错误: 当时在网上也是寻找各种的解决办法,一直都没有找到和自己相同问题的解决办法…...
2024/4/5 4:13:53 - Echarts图表之带提示框的圆环图
<!DOCTYPE html> <html> <head> <meta charset"utf-8" /> <title>Echarts图表</title> <!-- 引入echarts.min.js --> <script src"https://cdn.staticfile.org/echarts/4.3.…...
2024/4/14 5:17:04 - 能粘贴Word 内容(含图片)的Web编辑器
1.4.2之后官方并没有做功能的改动,1.4.2在word复制这块没有bug,其他版本会出现手动无法转存的情况 本文使用的后台是Java。前端为Jsp(前端都一样,后台如果语言不通得自己做 Base64编码解码) 因为公司业务需要支持IE8…...
2024/4/15 22:05:44
最新文章
- 【vim 学习系列文章 5.1 -- vim ctags 使用】
文章目录 背景 背景 在使用cscope生成文件cscope.files之后,如何将其当做ctags 命令的输入? 可以使用一系列的Shell命令来完成这个任务。具体来说,可以使用while read循环来按行读取cscope.files文件的内容,然后使用管道|和xarg…...
2024/5/7 13:45:55 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/7 10:36:02 - 阿里云8核32G云服务器租用优惠价格表,包括腾讯云和京东云
8核32G云服务器租用优惠价格表,云服务器吧yunfuwuqiba.com整理阿里云8核32G服务器、腾讯云8核32G和京东云8C32G云主机配置报价,腾讯云和京东云是轻量应用服务器,阿里云是云服务器ECS: 阿里云8核32G服务器 阿里云8核32G服务器价格…...
2024/5/6 18:16:31 - ROS2高效学习第十章 -- ros2 高级组件之大型项目中的 launch 其二
ros2 高级组件之大型项目中的 launch 1 前言和资料2 正文2.1 启动 turtlesim,生成一个 turtle ,设置背景色2.2 使用 event handler 重写上节的样例2.3 turtle_tf_mimic_rviz_launch 样例 3 总结 1 前言和资料 早在ROS2高效学习第四章 – ros2 topic 编程…...
2024/5/7 4:57:36 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/7 5:50:09 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/7 9:45:25 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/6 9:21:00 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/7 11:36:39 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/6 1:40:42 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/4 23:55:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/7 9:26:26 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/4 23:55:06 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/4 23:55:16 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/6 21:42:42 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57