Kafka知识体系总结
目录
- 0- 知识图谱
- 1- 消息队列
- 1.1- 消息队列的介绍
- 1.2- 消息队列的应用场景
- 1.3- 消息队列的两种模式
- 1.3.1- 点对点模式
- 1.3.2- 发布/订阅模式
- 1.4- 常用的消息队列介绍
- 1.4.1- RabbitMQ
- 1.4.2- ActiveMQ
- 1.4.3- RocketMQ
- 1.4.4- Kafka
- 1.5- Pulsar
- 1.5.1- Pulsar 的特性
- 1.5.2- Pulsar 存储架构
- 1.5.3- Pulsar 消息消费
- 1.6- Kafka与Pulsar对比
- 1.6.1- Pulsar 的主要优势
- 1.6.2- Pulsar 的劣势
- 1.6.3- 什么时候应该考虑 Pulsar
- 1.7- 其他消息队列与Kafka对比
- 2- Kafka基础
- 2.1- kafka的基本介绍
- 2.2- kafka的好处
- 2.3- 分布式的发布与订阅系统
- 2.4- kafka的主要应用场景
- 2.4.1- 指标分析
- 2.4.2- 日志聚合解决方法
- 2.4.3- 流式处理
- 3- Kafka架构及组件
- 3.1- kafka架构
- 3.1.1- 生产者API
- 3.1.2- 消费者API
- 3.1.3- StreamsAPI
- 3.1.4- ConnectAPI
- 3.2- kafka主要组件
- 3.2.1- producer(生产者)
- 3.2.2- topic(主题)
- 3.2.3- partition(分区)
- 3.2.4- consumer(消费者)
- 3.2.5- consumer group(消费者组)
- 3.2.6- partition replicas(分区副本)
- 3.2.7- segment文件
- 3.2.8- message的物理结构
- 4- Kafka集群操作
- 4.1- 创建topic
- 4.2- 查看主题命令
- 4.3- 生产者生产数据
- 4.4- 消费者消费数据
- 4.5- 运行describe topics命令
- 4.6- 增加topic分区数
- 4.7- 增加配置
- 4.8- 删除配置
- 4.9- 删除topic
- 5- Kafka的JavaAPI操作
- 5.1- 生产者代码
- 5.2- 消费者代码
- 5.2.1- 自动提交offset
- 5.2.2- 手动提交offset
- 5.2.3- 消费完每个分区之后手动提交offset
- 5.2.4- 指定分区数据进行消费
- 5.2.5- 重复消费与数据丢失
- 5.2.6- consumer消费者消费数据流程
- 5.3- kafka Streams API开发
- 6- Kafka中的数据不丢失机制
- 6.1- 生产者生产数据不丢失
- 6.1.1- 发送消息方式
- 6.1.2- 发送消息方式ack机制(确认机制)
- 6.2- broker中数据不丢失
- 6.3- 消费者消费数据不丢失
- 7- Kafka配置文件说明
- 8- CAP理论
- 8.1- 分布式系统当中的CAP理论
- 8.2- Partition tolerance
- 8.3- Consistency
- 8.4- Availability
- 9- Kafka中的CAP机制
- 10- Kafka监控及运维
- 10.1- kafka-eagle概述
- 10.2- 环境和安装
- 10.2.1- 环境要求
- 10.2.2- 安装步骤
- 11- Kafka大厂面试题
- 11.1- 为什么要使用 kafka?
- 11.2- Kafka消费过的消息如何再消费?
- 11.3- kafka的数据是放在磁盘上还是内存上,为什么速度会快?
- 11.4- Kafka数据怎么保障不丢失?
- 11.5- 采集数据为什么选择kafka?
- 11.6- kafka 重启是否会导致数据丢失?
- 11.7- kafka 宕机了如何解决?
- 11.8- 为什么Kafka不支持读写分离?
- 11.9- kafka数据分区和消费者的关系?
- 11.10- kafka的数据offset读取流程
- 11.11- kafka内部如何保证顺序,结合外部组件如何保证消费者的顺序?
- 11.12- Kafka消息数据积压,Kafka消费能力不足怎么处理?
- 11.13- Kafka单条日志传输大小
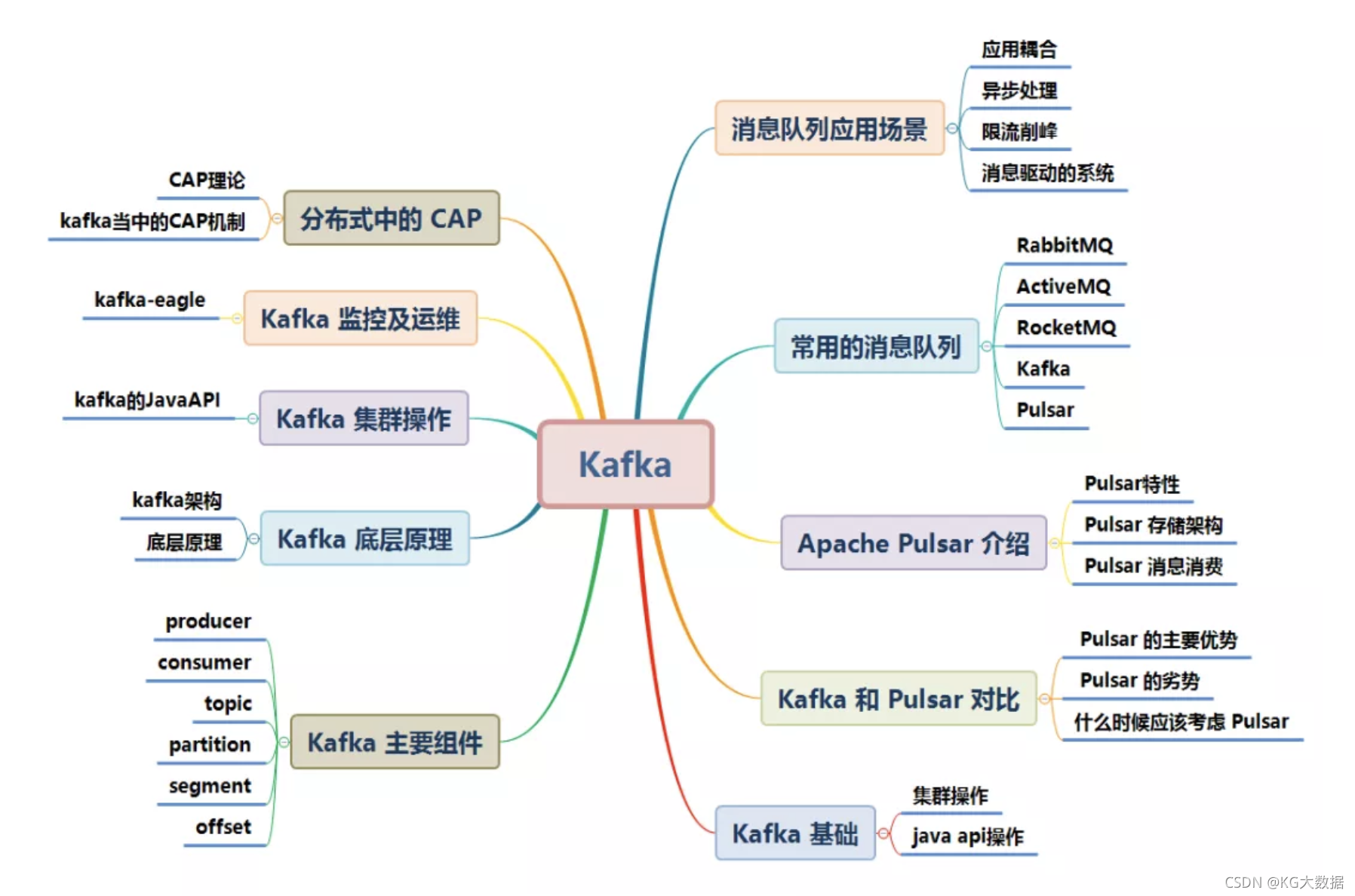
0- 知识图谱
本文档参考了关于 Kafka 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图。
1- 消息队列
1.1- 消息队列的介绍
消息(Message)是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
1.2- 消息队列的应用场景
消息队列在实际应用中包括如下四个场景:
- 应用耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
- 异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
- 限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
- 消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
下面详细介绍上述四个场景以及消息队列如何在上述四个场景中使用:
1. 异步处理
具体场景:用户为了使用某个应用,进行注册,系统需要发送注册邮件并验证短信。对这两个操作的处理方式有两种:串行及并行。
-
串行方式:新注册信息生成后,先发送注册邮件,再发送验证短信;

在这种方式下,需要最终发送验证短信后再返回给客户端。 -
并行处理:新注册信息写入后,由发短信和发邮件并行处理;
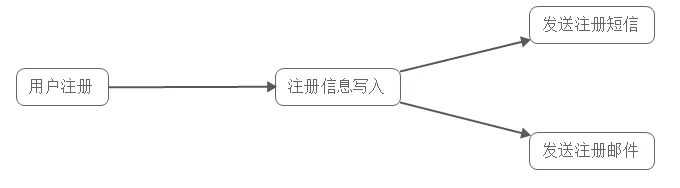
在这种方式下,发短信和发邮件 需处理完成后再返回给客户端。假设以上三个子系统处理的时间均为50ms,且不考虑网络延迟,则总的处理时间:
串行:50+50+50=150ms
并行:50+50 = 100ms
- 若使用消息队列:
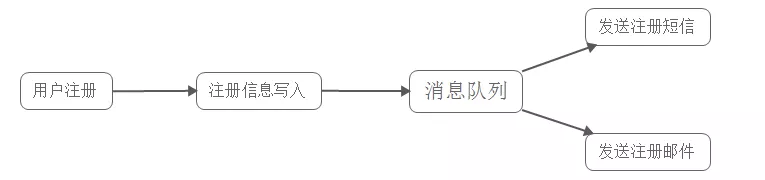
在写入消息队列后立即返回成功给客户端,则总的响应时间依赖于写入消息队列的时间,而写入消息队列的时间本身是可以很快的,基本可以忽略不计,因此总的处理时间相比串行提高了2倍,相比并行提高了一倍;
2. 应用耦合
具体场景:用户使用QQ相册上传一张图片,人脸识别系统会对该图片进行人脸识别,一般的做法是,服务器接收到图片后,图片上传系统立即调用人脸识别系统,调用完成后再返回成功,如下图所示:
该方法有如下缺点:

- 人脸识别系统被调失败,导致图片上传失败;
- 延迟高,需要人脸识别系统处理完成后,再返回给客户端,即使用户并不需要立即知道结果;
- 图片上传系统与人脸识别系统之间互相调用,需要做耦合;
若使用消息队列:

客户端上传图片后,图片上传系统将图片信息如uin、批次写入消息队列,直接返回成功;而人脸识别系统则定时从消息队列中取数据,完成对新增图片的识别。
此时图片上传系统并不需要关心人脸识别系统是否对这些图片信息的处理、以及何时对这些图片信息进行处理。事实上,由于用户并不需要立即知道人脸识别结果,人脸识别系统可以选择不同的调度策略,按照闲时、忙时、正常时间,对队列中的图片信息进行处理。
3. 限流削峰
具体场景:购物网站开展秒杀活动,一般由于瞬时访问量过大,服务器接收过大,会导致流量暴增,相关系统无法处理请求甚至崩溃。而加入消息队列后,系统可以从消息队列中取数据,相当于消息队列做了一次缓冲。

该方法有如下优点:
- 请求先入消息队列,而不是由业务处理系统直接处理,做了一次缓冲,极大地减少了业务处理系统的压力;
- 队列长度可以做限制,事实上,秒杀时,后入队列的用户无法秒杀到商品,这些请求可以直接被抛弃,返回活动已结束或商品已售完信息;
4. 消息驱动的系统
具体场景:用户新上传了一批照片,人脸识别系统需要对这个用户的所有照片进行聚类,聚类完成后由对账系统重新生成用户的人脸索引(加快查询)。这三个子系统间由消息队列连接起来,前一个阶段的处理结果放入队列中,后一个阶段从队列中获取消息继续处理。

该方法有如下优点:
- 避免了直接调用下一个系统导致当前系统失败;
- 每个子系统对于消息的处理方式可以更为灵活,可以选择收到消息时就处理,可以选择定时处理,也可以划分时间段按不同处理速度处理;
1.3- 消息队列的两种模式
消息队列包括两种模式,点对点模式(point to point, queue)和发布/订阅模式(publish/subscribe,topic)
1.3.1- 点对点模式
点对点模式下包括三个角色:
- 消息队列
- 发送者 (生产者)
- 接收者(消费者)

消息发送者生产消息发送到queue中,然后消息接收者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);
- 发送者和接发收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
1.3.2- 发布/订阅模式
发布/订阅模式下包括三个角色:
- 角色主题(Topic)
- 发布者(Publisher)
- 订阅者(Subscriber)
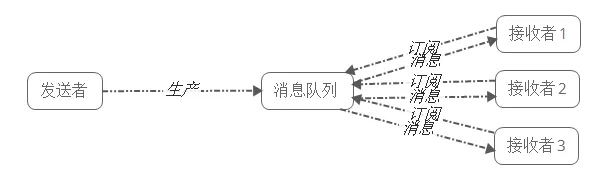
发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
1.4- 常用的消息队列介绍
1.4.1- RabbitMQ
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
1.4.2- ActiveMQ
ActiveMQ是由Apache出品,ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能。
1.4.3- RocketMQ
RocketMQ出自 阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理等。
1.4.4- Kafka
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
1.5- Pulsar
Apahce Pulasr是一个企业级的发布-订阅消息系统,最初是由雅虎开发,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
Pulsar 非常灵活:它既可以应用于像 Kafka 这样的分布式日志应用场景,也可以应用于像 RabbitMQ 这样的纯消息传递系统场景。它支持多种类型的订阅、多种交付保证、保留策略以及处理模式演变的方法,以及其他诸多特性。
1.5.1- Pulsar 的特性
- 内置多租户:不同的团队可以使用相同的集群并将其隔离,解决了许多管理难题。它支持隔离、身份验证、授权和配额;
- 多层体系结构:Pulsar 将所有 topic 数据存储在由 Apache BookKeeper 支持的专业数据层中。存储和消息传递的分离解决了扩展、重新平衡和维护集群的许多问题。它还提高了可靠性,几乎不可能丢失数据。另外,在读取数据时可以直连 BookKeeper,且不影响实时摄取。例如,可以使用 Presto 对 topic 执行 SQL 查询,类似于 KSQL,但不会影响实时数据处理;
- 虚拟 topic:由于采用 n 层体系结构,因此对 topic 的数量没有限制,topic 及其存储是分离的。用户还可以创建非持久性 topic;
- N 层存储:Kafka 的一个问题是,存储费用可能变高。因此,它很少用于存储"冷"数据,并且消息经常被删除,Apache Pulsar 可以借助分层存储自动将旧数据卸载到 Amazon S3 或其他数据存储系统,并且仍然向客户端展示透明视图;Pulsar 客户端可以从时间开始节点读取,就像所有消息都存在于日志中一样;
1.5.2- Pulsar 存储架构
Pulsar 的多层架构影响了存储数据的方式。Pulsar 将 topic 分区划分为分片(segment),然后将这些分片存储在 Apache BookKeeper 的存储节点上,以提高性能、可伸缩性和可用性。

Pulsar 的无限分布式日志以分片为中心,借助扩展日志存储(通过 Apache BookKeeper)实现,内置分层存储支持,因此分片可以均匀地分布在存储节点上。由于与任一给定 topic 相关的数据都不会与特定存储节点进行捆绑,因此很容易替换存储节点或缩扩容。另外,集群中最小或最慢的节点也不会成为存储或带宽的短板。
Pulsar 架构能实现分区管理,负载均衡,因此使用 Pulsar 能够快速扩展并达到高可用。这两点至关重要,所以 Pulsar 非常适合用来构建关键任务服务,如金融应用场景的计费平台,电子商务和零售商的交易处理系统,金融机构的实时风险控制系统等。
通过性能强大的 Netty 架构,数据从 producers 到 broker,再到 bookie 的转移都是零拷贝,不会生成副本。这一特性对所有流应用场景都非常友好,因为数据直接通过网络或磁盘进行传输,没有任何性能损失。
1.5.3- Pulsar 消息消费
Pulsar 的消费模型采用了流拉取的方式。流拉取是长轮询的改进版,不仅实现了单个调用和请求之间的零等待,还可以提供双向消息流。通过流拉取模型,Pulsar 实现了端到端的低延迟,这种低延迟比所有现有的长轮询消息系统(如 Kafka)都低。
1.6- Kafka与Pulsar对比
1.6.1- Pulsar 的主要优势
- 更多功能:Pulsar Function、多租户、Schema registry、n 层存储、多种消费模式和持久性模式等;
- 更大的灵活性:3 种订阅类型(独占,共享和故障转移),用户可以在一个订阅上管理多个 topic;
- 易于操作运维:架构解耦和 n 层存储;
- 与 Presto 的 SQL 集成,可直接查询存储而不会影响 broker;
- 借助 n 层自动存储选项,可以更低成本地存储;
1.6.2- Pulsar 的劣势
Pulsar 并不完美,Pulsar 也存在一些问题:
- 相对缺乏支持、文档和案例;
- n 层体系结构导致需要更多组件:BookKeeper;
- 插件和客户端相对 Kafka 较少;
- 云中的支持较少,Confluent 具有托管云产品。
1.6.3- 什么时候应该考虑 Pulsar
- 同时需要像 RabbitMQ 这样的队列和 Kafka 这样的流处理程序;
- 需要易用的地理复制;
- 实现多租户,并确保每个团队的访问权限;
- 需要长时间保留消息,并且不想将其卸载到另一个存储中;
- 需要高性能,基准测试表明 Pulsar 提供了更低的延迟和更高的吞吐量。
总之,Pulsar还比较新,社区不完善,用的企业比较少,网上有价值的讨论和问题的解决比较少,远没有Kafka生态系统庞大,且用户量非常庞大,目前Kafka依旧是大数据领域消息队列的王者!所以我们还是以Kafka为主!
1.7- 其他消息队列与Kafka对比
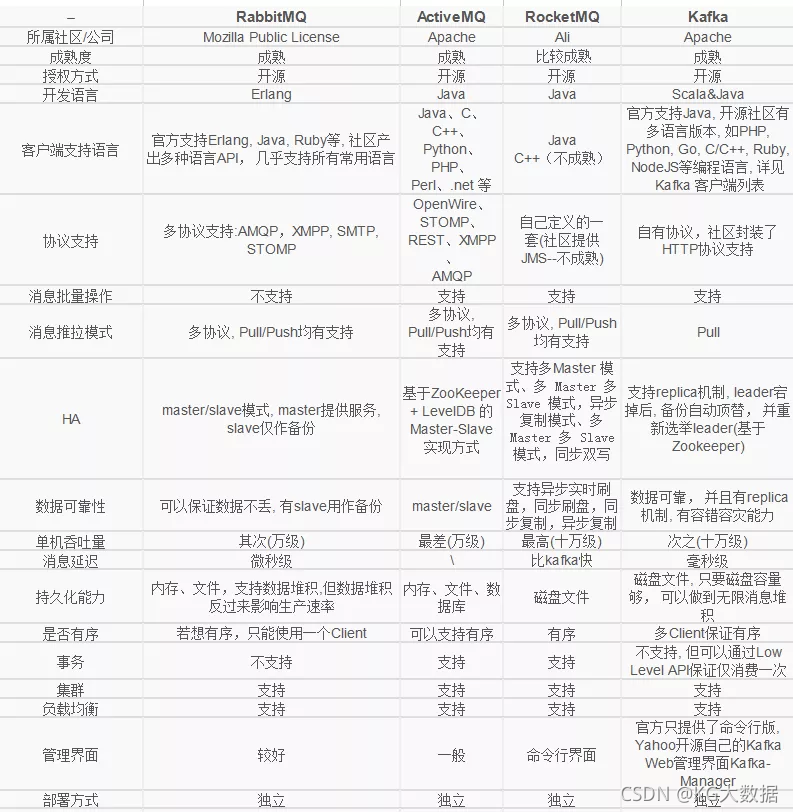
2- Kafka基础
2.1- kafka的基本介绍
官网:http://kafka.apache.org/
kafka是最初由linkedin公司开发的,使用scala语言编写,kafka是一个分布式,分区的,多副本的,多订阅者的日志系统(分布式MQ系统),可以用于搜索日志,监控日志,访问日志等。
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
2.2- kafka的好处
- 可靠性:分布式的,分区,复本和容错的。
- 可扩展性:kafka消息传递系统轻松缩放,无需停机。
- 耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快速的保存在磁盘上,因此它是持久的。
- 性能:kafka对于发布和定于消息都具有高吞吐量。即使存储了许多TB的消息,他也爆出稳定的性能。
- kafka非常快:保证零停机和零数据丢失。
2.3- 分布式的发布与订阅系统
apache kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使能够将消息从一个端点传递到另一个端点,kafka适合离线和在线消息消费。kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。kafka构建在zookeeper同步服务之上。它与apache和spark非常好的集成,应用于实时流式数据分析。
2.4- kafka的主要应用场景
2.4.1- 指标分析
kafka 通常用于操作监控数据。这设计聚合来自分布式应用程序的统计信息, 以产生操作的数据集中反馈。
2.4.2- 日志聚合解决方法
kafka可用于跨组织从多个服务器收集日志,并使他们以标准的格式提供给多个服务器。
2.4.3- 流式处理
流式处理框架(spark,storm,flink)重主题中读取数据,对齐进行处理,并将处理后的数据写入新的主题,供 用户和应用程序使用,kafka的强耐久性在流处理的上下文中也非常的有用。
3- Kafka架构及组件
3.1- kafka架构
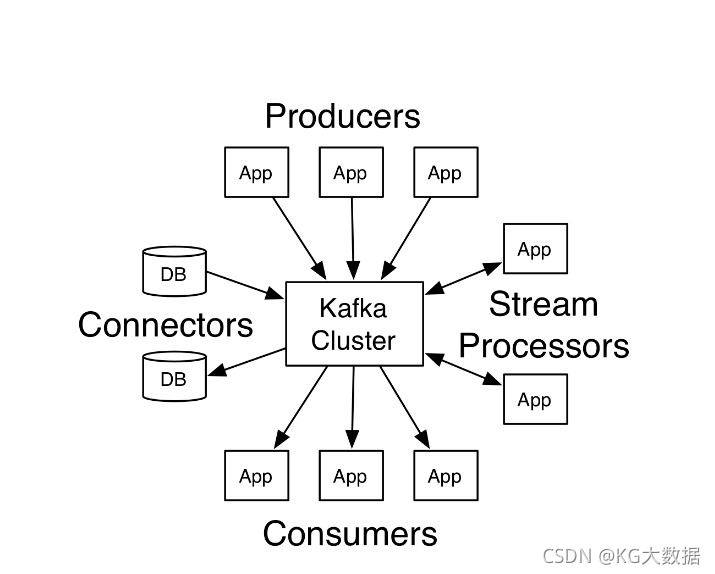
3.1.1- 生产者API
允许应用程序发布记录流至一个或者多个kafka的主题(topics)。
3.1.2- 消费者API
允许应用程序订阅一个或者多个主题,并处理这些主题接收到的记录流。
3.1.3- StreamsAPI
允许应用程序充当流处理器(stream processor),从一个或者多个主题获取输入流,并生产一个输出流到一个或 者多个主题,能够有效的变化输入流为输出流。
3.1.4- ConnectAPI
允许构建和运行可重用的生产者或者消费者,能够把kafka主题连接到现有的应用程序或数据系统。例如:一个连接到关系数据库的连接器可能会获取每个表的变化。
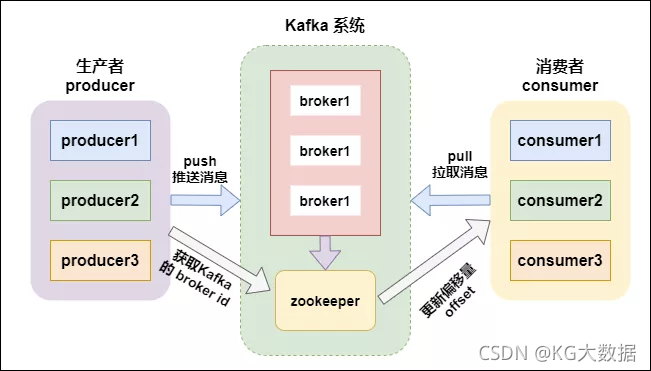
注:在Kafka 2.8.0 版本,移除了对Zookeeper的依赖,通过KRaft进行自己的集群管理,使用Kafka内部的Quorum控制器来取代ZooKeeper,因此用户第一次可在完全不需要ZooKeeper的情况下执行Kafka,这不只节省运算资源,并且也使得Kafka效能更好,还可支持规模更大的集群。
过去Apache ZooKeeper是Kafka这类分布式系统的关键,ZooKeeper扮演协调代理的角色,所有代理服务器启动时,都会连接到Zookeeper进行注册,当代理状态发生变化时,Zookeeper也会储存这些数据,在过去,ZooKeeper是一个强大的工具,但是毕竟ZooKeeper是一个独立的软件,使得Kafka整个系统变得复杂,因此官方决定使用内部Quorum控制器来取代ZooKeeper。
这项工作从去年4月开始,而现在这项工作取得部分成果,用户将可以在2.8版本,在没有ZooKeeper的情况下执行Kafka,官方称这项功能为Kafka Raft元数据模式(KRaft)。在KRaft模式,过去由Kafka控制器和ZooKeeper所操作的元数据,将合并到这个新的Quorum控制器,并且在Kafka集群内部执行,当然,如果使用者有特殊使用情境,Quorum控制器也可以在专用的硬件上执行。
kafka支持消息持久化,消费端是主动拉取数据,消费状态和订阅关系由客户端负责维护,消息消费完后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以。
- broker:kafka集群中包含一个或者多个服务实例(节点),这种服务实例被称为broker(一个broker就是一个节点/一个服务器);
- topic:每条发布到kafka集群的消息都属于某个类别,这个类别就叫做topic;
- partition:partition是一个物理上的概念,每个topic包含一个或者多个partition;
- segment:一个partition当中存在多个segment文件段,每个segment分为两部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用于快速查询, .log 文件当中数据的偏移量位置;
- producer:消息的生产者,负责发布消息到 kafka 的 broker 中;
- consumer:消息的消费者,向 kafka 的 broker 中读取消息的客户端;
- consumer group:消费者组,每一个 consumer 属于一个特定的 consumer group(可以为每个consumer指定 groupName);
- .log:存放数据文件;
- .index:存放.log文件的索引数据。
3.2- kafka主要组件
3.2.1- producer(生产者)
producer主要是用于生产消息,是kafka当中的消息生产者,生产的消息通过topic进行归类,保存到kafka的broker里面去。
3.2.2- topic(主题)
- kafka将消息以topic为单位进行归类;
- topic特指kafka处理的消息源(feeds of messages)的不同分类;
- topic是一种分类或者发布的一些列记录的名义上的名字。kafka主题始终是支持多用户订阅的;也就是说,一 个主题可以有零个,一个或者多个消费者订阅写入的数据;
- 在kafka集群中,可以有无数的主题;
- 生产者和消费者消费数据一般以主题为单位。更细粒度可以到分区级别。
3.2.3- partition(分区)
kafka当中,topic是消息的归类,一个topic可以有多个分区(partition),每个分区保存部分topic的数据,所有的partition当中的数据全部合并起来,就是一个topic当中的所有的数据。
一个broker服务下,可以创建多个分区,broker数与分区数没有关系;
在kafka中,每一个分区会有一个编号:编号从0开始。
每一个分区内的数据是有序的,但全局的数据不能保证是有序的。(有序是指生产什么样顺序,消费时也是什么样的顺序)
3.2.4- consumer(消费者)
consumer是kafka当中的消费者,主要用于消费kafka当中的数据,消费者一定是归属于某个消费组中的。
3.2.5- consumer group(消费者组)
消费者组由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。
每个消费者都属于某个消费者组,如果不指定,那么所有的消费者都属于默认的组。
每个消费者组都有一个ID,即group ID。组内的所有消费者协调在一起来消费一个订阅主题( topic)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个消费者(consumer)来消费,可以由不同的消费组来消费。
partition数量决定了每个consumer group中并发消费者的最大数量。如下图:
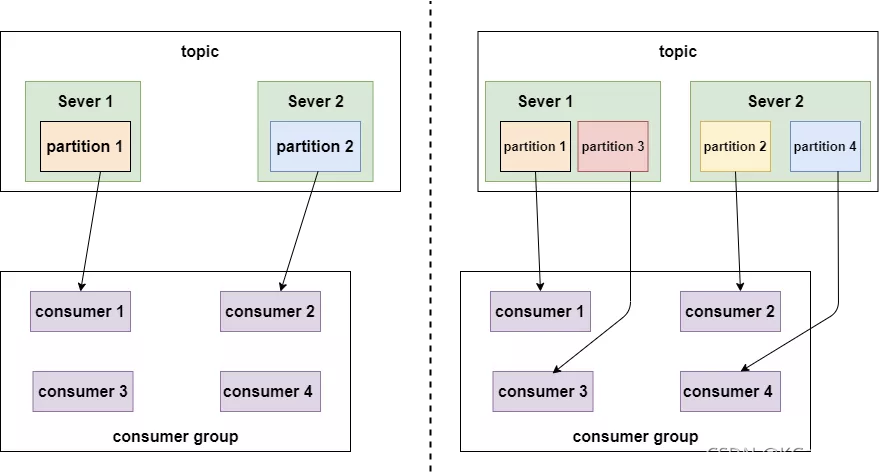
如上面左图所示,如果只有两个分区,即使一个组内的消费者有4个,也会有两个空闲的。
如上面右图所示,有4个分区,每个消费者消费一个分区,并发量达到最大4。
来看另一副图:
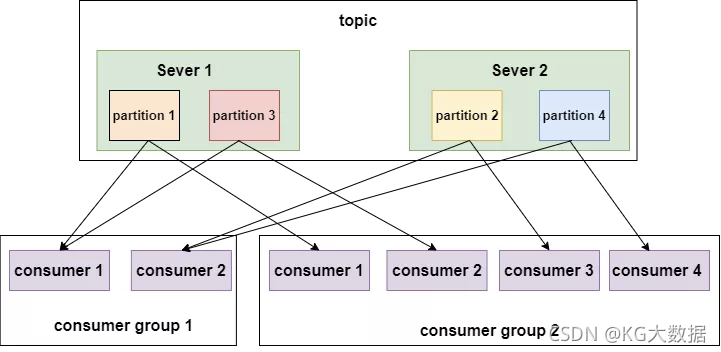
如上图所示,不同的消费者组消费同一个topic,这个topic有4个分区,分布在两个节点上。左边的 消费组1有两个消费者,每个消费者就要消费两个分区才能把消息完整的消费完,右边的 消费组2有四个消费者,每个消费者消费一个分区即可。
总结下kafka中分区与消费组的关系:
消费组:由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。某一个主题下的分区数,对于消费该主题的同一个消费组下的消费者数量,应该小于等于该主题下的分区数。
如:某一个主题有4个分区,那么消费组中的消费者应该小于等于4,而且最好与分区数成整数倍 1 2 4 这样。同一个分区下的数据,在同一时刻,不能同一个消费组的不同消费者消费。
总结:分区数越多,同一时间可以有越多的消费者来进行消费,消费数据的速度就会越快,提高消费的性能。
3.2.6- partition replicas(分区副本)
kafka 中的分区副本如下图所示:
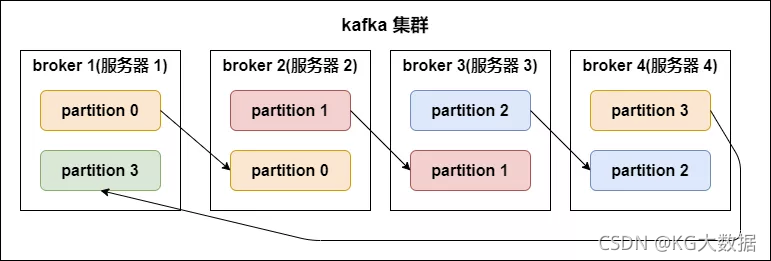
副本数(replication-factor):控制消息保存在几个broker(服务器)上,一般情况下副本数等于broker的个数。
一个broker服务下,不可以创建多个副本因子。创建主题时,副本因子应该小于等于可用的broker数。
副本因子操作以分区为单位的。每个分区都有各自的主副本和从副本;
主副本叫做leader,从副本叫做 follower(在有多个副本的情况下,kafka会为同一个分区下的所有分区,设定角色关系:一个leader和N个 follower),处于同步状态的副本叫做in-sync-replicas(ISR);
follower通过拉的方式从leader同步数据。消费者和生产者都是从leader读写数据,不与follower交互。
副本因子的作用:让kafka读取数据和写入数据时的可靠性。
副本因子是包含本身,同一个副本因子不能放在同一个broker中。
如果某一个分区有三个副本因子,就算其中一个挂掉,那么只会剩下的两个中,选择一个leader,但不会在其他的broker中,另启动一个副本(因为在另一台启动的话,存在数据传递,只要在机器之间有数据传递,就会长时间占用网络IO,kafka是一个高吞吐量的消息系统,这个情况不允许发生)所以不会在另一个broker中启动。
如果所有的副本都挂了,生产者如果生产数据到指定分区的话,将写入不成功。
lsr表示:当前可用的副本。
3.2.7- segment文件
一个partition当中由多个segment文件组成,每个segment文件,包含两部分,一个是 .log 文件,另外一个是 .index 文件,其中 .log 文件包含了我们发送的数据存储,.index 文件,记录的是我们.log文件的数据索引值,以便于我们加快数据的查询速度。
索引文件与数据文件的关系
既然它们是一一对应成对出现,必然有关系。索引文件中元数据指向对应数据文件中message的物理偏移地址。
比如索引文件中 3,497 代表:数据文件中的第三个message,它的偏移地址为497。
再来看数据文件中,Message 368772表示:在全局partiton中是第368772个message。
注:segment index file 采取稀疏索引存储方式,减少索引文件大小,通过mmap(内存映射)可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
.index 与 .log 对应关系如下:

上图左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”, 分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……
那么为什么在index文件中这些编号不是连续的呢?这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
value 代表的是在全局partiton中的第几个消息。
以索引文件中元数据 3,497 为例,其中3代表在右边log数据文件中从上到下第3个消息, 497表示该消息的物理偏移地址(位置)为497(也表示在全局partiton表示第497个消息-顺序写入特性)。
log日志目录及组成kafka在我们指定的log.dir目录下,会创建一些文件夹;名字是 (主题名字-分区名) 所组成的文件夹。在(主题名字-分区名)的目录下,会有两个文件存在,如下所示:

在目录下的文件,会根据log日志的大小进行切分,.log文件的大小为1G的时候,就会进行切分文件;如下:

在kafka的设计中,将offset值作为了文件名的一部分。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局 partion的最大offset(偏移message数)。数值最大为64位long大小,20位数字字符长度,没有数字就用 0 填充。
通过索引信息可以快速定位到message。通过index元数据全部映射到内存,可以避免segment File的IO磁盘操作;
通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
稀疏索引:为了数据创建索引,但范围并不是为每一条创建,而是为某一个区间创建;好处:就是可以减少索引值的数量。不好的地方:找到索引区间之后,要得进行第二次处理。
3.2.8- message的物理结构
生产者发送到kafka的每条消息,都被kafka包装成了一个message
message 的物理结构如下图所示:

所以生产者发送给kafka的消息并不是直接存储起来,而是经过kafka的包装,每条消息都是上图这个结构,只有最后一个字段才是真正生产者发送的消息数据。
4- Kafka集群操作
4.1- 创建topic
创建一个名字为test的主题, 有三个分区,有两个副本:
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 3 --topic test
4.2- 查看主题命令
查看kafka当中存在的主题:
bin/kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181
4.3- 生产者生产数据
模拟生产者来生产数据:
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
4.4- 消费者消费数据
执行以下命令来模拟消费者进行消费数据:
bin/kafka-console-consumer.sh --from-beginning --topic test --zookeeper node01:2181,node02:2181,node03:2181
4.5- 运行describe topics命令
执行以下命令运行describe查看topic的相关信息:
bin/kafka-topics.sh --describe --zookeeper node01:2181 --topic test
结果说明:
这是输出的解释。第一行给出了所有分区的摘要,每个附加行提供有关一个分区的信息。由于我们只有一个分 区用于此主题,因此只有一行。
“leader”是负责给定分区的所有读取和写入的节点。每个节点将成为随机选择的分区部分的领导者。(因为在kafka中 如果有多个副本的话,就会存在leader和follower的关系,表示当前这个副本为leader所在的broker是哪一个)
“replicas”是复制此分区日志的节点列表,无论它们是否为领导者,或者即使它们当前处于活动状态。(所有副本列表0,1,2)
“isr”是“同步”复制品的集合。这是副本列表的子集,该列表当前处于活跃状态并且已经被领导者捕获。(可用的列表数)
4.6- 增加topic分区数
执行以下命令可以增加topic分区数:
bin/kafka-topics.sh --zookeeper zkhost:port --alter --topic topicName --partitions 8
4.7- 增加配置
动态修改kakfa的配置:
bin/kafka-topics.sh --zookeeper node01:2181 --alter --topic test --config flush.messages=1
4.8- 删除配置
动态删除kafka集群配置:
bin/kafka-topics.sh --zookeeper node01:2181 --alter --topic test --delete-config flush.messages
4.9- 删除topic
目前删除topic在默认情况下知识打上一个删除的标记,在重新启动kafka后才删除。
如果需要立即删除,则需要在 server.properties中配置:
delete.topic.enable=true
然后执行以下命令进行删除topic:
kafka-topics.sh --zookeeper zkhost:port --delete --topic topicName
5- Kafka的JavaAPI操作
5.1- 生产者代码
使用生产者,生产数据:
/**
* 订单的生产者代码,
*/
public class OrderProducer {
public static void main(String[] args) throws InterruptedException {
/* 1、连接集群,通过配置文件的方式
* 2、发送数据-topic:order,value
*/
Properties props = new Properties(); props.put("bootstrap.servers", "node01:9092"); props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>
(props);
for (int i = 0; i < 1000; i++) {
// 发送数据 ,需要一个producerRecord对象,最少参数 String topic, V value kafkaProducer.send(new ProducerRecord<String, String>("order", "订单信
息!"+i));
Thread.sleep(100);
}
}
}
kafka当中的数据分区:
kafka生产者发送的消息,都是保存在broker当中,我们可以自定义分区规则,决定消息发送到哪个partition里面去进行保存 查看ProducerRecord这个类的源码,就可以看到kafka的各种不同分区策略。
kafka当中支持以下四种数据的分区方式:
//第一种分区策略,如果既没有指定分区号,也没有指定数据key,那么就会使用轮询的方式将数据均匀的发送到不同的分区里面去//ProducerRecord<String, String> producerRecord1 = new ProducerRecord<>("mypartition", "mymessage" + i);//kafkaProducer.send(producerRecord1);//第二种分区策略 如果没有指定分区号,指定了数据key,通过key.hashCode % numPartitions来计算数据究竟会保存在哪一个分区里面//注意:如果数据key,没有变化 key.hashCode % numPartitions = 固定值 所有的数据都会写入到某一个分区里面去//ProducerRecord<String, String> producerRecord2 = new ProducerRecord<>("mypartition", "mykey", "mymessage" + i);//kafkaProducer.send(producerRecord2);//第三种分区策略:如果指定了分区号,那么就会将数据直接写入到对应的分区里面去
// ProducerRecord<String, String> producerRecord3 = new ProducerRecord<>("mypartition", 0, "mykey", "mymessage" + i);// kafkaProducer.send(producerRecord3);//第四种分区策略:自定义分区策略。如果不自定义分区规则,那么会将数据使用轮询的方式均匀的发送到各个分区里面去kafkaProducer.send(new ProducerRecord<String, String>("mypartition","mymessage"+i));
自定义分区策略:
public class KafkaCustomPartitioner implements Partitioner {@Overridepublic void configure(Map<String, ?> configs) {}@Overridepublic int partition(String topic, Object arg1, byte[] keyBytes, Object arg3, byte[] arg4, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int partitionNum = partitions.size();Random random = new Random();int partition = random.nextInt(partitionNum);return partition;}@Overridepublic void close() {}}
主代码中添加配置:
@Testpublic void kafkaProducer() throws Exception {//1、准备配置文件Properties props = new Properties();props.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("partitioner.class", "cn.itcast.kafka.partitioner.KafkaCustomPartitioner");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//2、创建KafkaProducerKafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);for (int i=0;i<100;i++){//3、发送数据kafkaProducer.send(new ProducerRecord<String, String>("testpart","0","value"+i));}kafkaProducer.close();}
5.2- 消费者代码
消费必要条件:
消费者要从kafka Cluster进行消费数据,必要条件有以下四个:
- 地址:bootstrap.servers=node01:9092
- 序列化:key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer
- 主题(topic):需要制定具体的某个topic(order)即可。
- 消费者组:group.id=test
5.2.1- 自动提交offset
消费完成之后,自动提交offset:
/**
* 消费订单数据--- javaben.tojson
*/
public class OrderConsumer {
public static void main(String[] args) {
// 1\连接集群
Properties props = new Properties(); props.put("bootstrap.servers", "hadoop-01:9092"); props.put("group.id", "test");//以下两行代码 ---消费者自动提交offset值
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>
(props);
// 2、发送数据 发送数据需要,订阅下要消费的topic。order kafkaConsumer.subscribe(Arrays.asList("order"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);// jdk queue offer插入、poll获取元素。blockingqueue put插入原生, take获取元素
for (ConsumerRecord<String, String> record : consumerRecords) { System.out.println("消费的数据为:" + record.value());
}
}
}
}
5.2.2- 手动提交offset
如果Consumer在获取数据后,需要加入处理,数据完毕后才确认offset,需要程序来控制offset的确认。
关闭自动提交确认选项:props.put(“enable.auto.commit”, “false”);
手动提交offset值:kafkaConsumer.commitSync();
完整代码如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
//关闭自动提交确认选项
props.put("enable.auto.commit", "false");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("test"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
// 手动提交offset值
consumer.commitSync();
buffer.clear();
}
}
5.2.3- 消费完每个分区之后手动提交offset
上面的示例使用commitSync将所有已接收的记录标记为已提交。在某些情况下,可能希望通过明确指定偏移量来更好地控制已提交的记录。在下面的示例中,我们在完成处理每个分区中的记录后提交偏移量:
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) { System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() -1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally { consumer.close();}
注意事项:
提交的偏移量应始终是应用程序将读取的下一条消息的偏移量。因此,在调用commitSync(偏移量)时,应该在最后处理的消息的偏移量中添加一个。
5.2.4- 指定分区数据进行消费
-
如果进程正在维护与该分区关联的某种本地状态(如本地磁盘上的键值存储),那么它应该只获取它在磁盘上维护的分区的记录。
-
如果进程本身具有高可用性,并且如果失败则将重新启动(可能使用YARN,Mesos或AWS工具等集群管理框 架,或作为流处理框架的一部分)。在这种情况下,Kafka不需要检测故障并重新分配分区,因为消耗过程将在另一台机器上重新启动。
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test");
props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//consumer.subscribe(Arrays.asList("foo", "bar"));//手动指定消费指定分区的数据---start
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1); consumer.assign(Arrays.asList(partition0, partition1));
//手动指定消费指定分区的数据---end
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
注意事项:
- 要使用此模式,只需使用要使用的分区的完整列表调用assign(Collection),而不是使用subscribe订阅主题。
- 主题与分区订阅只能二选一。
5.2.5- 重复消费与数据丢失
说明:
- 已经消费的数据对于kafka来说,会将消费组里面的offset值进行修改,那什么时候进行修改了?是在数据消费 完成之后,比如在控制台打印完后自动提交;
- 提交过程:是通过kafka将offset进行移动到下个message所处的offset的位置。
- 拿到数据后,存储到hbase中或者mysql中,如果hbase或者mysql在这个时候连接不上,就会抛出异常,如果在处理数据的时候已经进行了提交,那么kafka伤的offset值已经进行了修改了,但是hbase或者mysql中没有数据,这个时候就会出现数据丢失。
- 什么时候提交offset值?在Consumer将数据处理完成之后,再来进行offset的修改提交。默认情况下offset是 自动提交,需要修改为手动提交offset值。
- 如果在处理代码中正常处理了,但是在提交offset请求的时候,没有连接到kafka或者出现了故障,那么该次修 改offset的请求是失败的,那么下次在进行读取同一个分区中的数据时,会从已经处理掉的offset值再进行处理一 次,那么在hbase中或者mysql中就会产生两条一样的数据,也就是数据重复。
5.2.6- consumer消费者消费数据流程
流程描述:
Consumer连接指定的Topic partition所在leader broker,采用pull方式从kafkalogs中获取消息。对于不同的消费模式,会将offset保存在不同的地方 官网关于high level API 以及low level API的简介:http://kafka.apache.org/0100/documentation.html#impl_consumer
高阶API(High Level API):
kafka消费者高阶API简单;隐藏Consumer与Broker细节;相关信息保存在zookeeper中:
/* create a connection to the cluster */
ConsumerConnector connector = Consumer.create(consumerConfig);interface ConsumerConnector {/**
This method is used to get a list of KafkaStreams, which are iterators over
MessageAndMetadata objects from which you can obtain messages and their
associated metadata (currently only topic).
Input: a map of <topic, #streams>
Output: a map of <topic, list of message streams>
*/
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
/**
You can also obtain a list of KafkaStreams, that iterate over messages
from topics that match a TopicFilter. (A TopicFilter encapsulates a
whitelist or a blacklist which is a standard Java regex.)
*/
public List<KafkaStream> createMessageStreamsByFilter( TopicFilter topicFilter, int numStreams);
/* Commit the offsets of all messages consumed so far. */ public commitOffsets()
/* Shut down the connector */ public shutdown()
}
说明:
大部分的操作都已经封装好了,比如:当前消费到哪个位置下了,但是不够灵活(工作过程推荐使用)
低级API(Low Level API):
kafka消费者低级API非常灵活;需要自己负责维护连接Controller Broker。保存offset,Consumer Partition对应关系:
class SimpleConsumer {/* Send fetch request to a broker and get back a set of messages. */
public ByteBufferMessageSet fetch(FetchRequest request);/* Send a list of fetch requests to a broker and get back a response set. */ public MultiFetchResponse multifetch(List<FetchRequest> fetches);/**Get a list of valid offsets (up to maxSize) before the given time.
The result is a list of offsets, in descending order.
@param time: time in millisecs,
if set to OffsetRequest$.MODULE$.LATEST_TIME(), get from the latest
offset available. if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliestavailable. public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);* offset
*/
说明:
没有进行包装,所有的操作有用户决定,如自己的保存某一个分区下的记录,你当前消费到哪个位置。
5.3- kafka Streams API开发
需求:
使用StreamAPI获取test这个topic当中的数据,然后将数据全部转为大写,写入到test2这个topic当中去。
第一步:创建一个topic
node01服务器使用以下命令来常见一个 topic 名称为test2:
bin/kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic test2 --zookeeper node01:2181,node02:2181,node03:2181
第二步:开发StreamAPI
public class StreamAPI {public static void main(String[] args) {Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092");props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());KStreamBuilder builder = new KStreamBuilder();builder.stream("test").mapValues(line -> line.toString().toUpperCase()).to("test2");KafkaStreams streams = new KafkaStreams(builder, props);streams.start();}
}
执行上述代码,监听获取 test 中的数据,然后转成大写,将结果写入 test2。
第三步:生产数据
node01执行以下命令,向test这个topic当中生产数据:
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
第四步:消费数据
node02执行一下命令消费test2这个topic当中的数据:
bin/kafka-console-consumer.sh --from-beginning --topic test2 --zookeeper node01:2181,node02:2181,node03:21816- Kafka中的数据不丢失机制
6.1- 生产者生产数据不丢失
6.1.1- 发送消息方式
生产者发送给kafka数据,可以采用同步方式或异步方式
同步方式:
发送一批数据给kafka后,等待kafka返回结果:
- 生产者等待10s,如果broker没有给出ack响应,就认为失败。
- 生产者重试3次,如果还没有响应,就报错.
异步方式:
发送一批数据给kafka,只是提供一个回调函数:
- 先将数据保存在生产者端的buffer中。buffer大小是2万条 。
- 满足数据阈值或者数量阈值其中的一个条件就可以发送数据。
- 发送一批数据的大小是500条。
注:如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。
6.1.2- 发送消息方式ack机制(确认机制)
生产者数据发送出去,需要服务端返回一个确认码,即ack响应码;ack的响应有三个状态值0,1,-1
- 0:生产者只负责发送数据,不关心数据是否丢失,丢失的数据,需要再次发送
- 1:partition的leader收到数据,不管follow是否同步完数据,响应的状态码为1
- -1:所有的从节点都收到数据,响应的状态码为-1
如果broker端一直不返回ack状态,producer永远不知道是否成功;producer可以设置一个超时时间10s,超过时间认为失败。
6.2- broker中数据不丢失
在broker中,保证数据不丢失主要是通过副本因子(冗余),防止数据丢失。
6.3- 消费者消费数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。也就是需要我们自己维护偏移量(offset),可保存在 Redis 中。
7- Kafka配置文件说明
Server.properties配置文件说明:
#broker的全局唯一编号,不能重复
broker.id=0#用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092#处理网络请求的线程数量
num.network.threads=3#用来处理磁盘IO的线程数量
num.io.threads=8#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400#请求套接字的缓冲区大小
socket.request.max.bytes=104857600#kafka运行日志存放的路径
log.dirs=/export/data/kafka/#topic在当前broker上的分片个数
num.partitions=2#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1#segment文件保留的最长时间,超时将被删除
log.retention.hours=168#滚动生成新的segment文件的最大时间
log.roll.hours=1#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824#周期性检查文件大小的时间
log.retention.check.interval.ms=300000#日志清理是否打开
log.cleaner.enable=true#broker需要使用zookeeper保存meta数据
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181#zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000#partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000#消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessful 错误!
host.name=kafka01advertised.host.name=192.168.140.128producer生产者配置文件说明
#指定kafka节点列表,用于获取metadata,不必全部指定
metadata.broker.list=node01:9092,node02:9092,node03:9092
# 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区
#partitioner.class=kafka.producer.DefaultPartitioner
# 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。
compression.codec=none
# 指定序列化处理类
serializer.class=kafka.serializer.DefaultEncoder
# 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。
#compressed.topics=# 设置发送数据是否需要服务端的反馈,有三个值0,1,-1
# 0: producer不会等待broker发送ack
# 1: 当leader接收到消息之后发送ack
# -1: 当所有的follower都同步消息成功后发送ack.
request.required.acks=0 # 在向producer发送ack之前,broker允许等待的最大时间 ,如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因未能成功(比如follower未能同步成功)
request.timeout.ms=10000# 同步还是异步发送消息,默认“sync”表同步,"async"表异步。异步可以提高发送吞吐量,
也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息
producer.type=sync# 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms
# 此值和batch.num.messages协同工作.
queue.buffering.max.ms = 5000# 在async模式下,producer端允许buffer的最大消息量
# 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积
# 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000
queue.buffering.max.messages=20000# 如果是异步,指定每次批量发送数据量,默认为200
batch.num.messages=500# 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后
# 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)
# 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间
# -1: 无阻塞超时限制,消息不会被抛弃
# 0:立即清空队列,消息被抛弃
queue.enqueue.timeout.ms=-1# 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数
# 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失)
# 有可能导致broker接收到重复的消息,默认值为3.
message.send.max.retries=3# producer刷新topic metada的时间间隔,producer需要知道partition leader的位置,以及当前topic的情况
# 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新
# (比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000
topic.metadata.refresh.interval.ms=60000
consumer消费者配置详细说明:
# zookeeper连接服务器地址
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
# zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉
zookeeper.session.timeout.ms=5000
#当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡
zookeeper.connection.timeout.ms=10000
# 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息
zookeeper.sync.time.ms=2000
#指定消费
group.id=itcast
# 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息
# 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为true
auto.commit.enable=true
# 自动更新时间。默认60 * 1000
auto.commit.interval.ms=1000
# 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察
conusmer.id=xxx
# 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生
client.id=xxxx
# 最大取多少块缓存到消费者(默认10)
queued.max.message.chunks=50
# 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册 "Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点, 此值用于控制,注册节点的重试次数.
rebalance.max.retries=5# 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存
fetch.min.bytes=6553600# 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumer
fetch.wait.max.ms=5000
socket.receive.buffer.bytes=655360
# 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest
auto.offset.reset=smallest
# 指定序列化处理类
derializer.class=kafka.serializer.DefaultDecoder
8- CAP理论
8.1- 分布式系统当中的CAP理论
分布式系统(distributed system)正变得越来越重要,大型网站几乎都是分布式的。
分布式系统的最大难点,就是各个节点的状态如何同步。
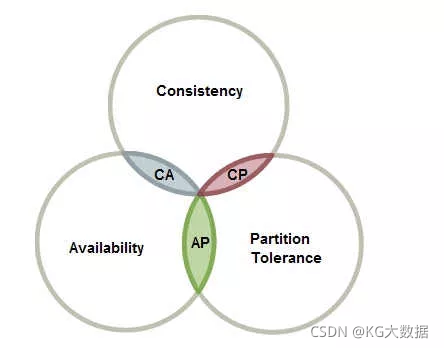
为了解决各个节点之间的状态同步问题,在1998年,由加州大学的计算机科学家 Eric Brewer 提出分布式系统的三个指标,分别是:
- Consistency:一致性
- Availability:可用性
- Partition tolerance:分区容错性
Eric Brewer 说,这三个指标不可能同时做到。最多只能同时满足其中两个条件,这个结论就叫做 CAP 定理。
CAP理论是指:分布式系统中,一致性、可用性和分区容忍性最多只能同时满足两个。
一致性:Consistency
- 通过某个节点的写操作结果对后面通过其它节点的读操作可见
- 如果更新数据后,并发访问情况下后续读操作可立即感知该更新,称为强一致性
- 如果允许之后部分或者全部感知不到该更新,称为弱一致性
- 若在之后的一段时间(通常该时间不固定)后,一定可以感知到该更新,称为最终一致性
可用性:Availability
- 任何一个没有发生故障的节点必须在有限的时间内返回合理的结果
分区容错性:Partition tolerance
- 部分节点宕机或者无法与其它节点通信时,各分区间还可保持分布式系统的功能
一般而言,都要求保证分区容忍性。所以在CAP理论下,更多的是需要在可用性和一致性之间做权衡。
8.2- Partition tolerance
先看 Partition tolerance,中文叫做"分区容错"。
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
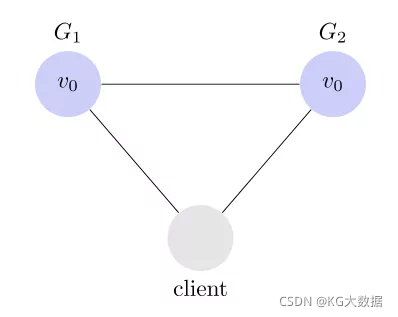
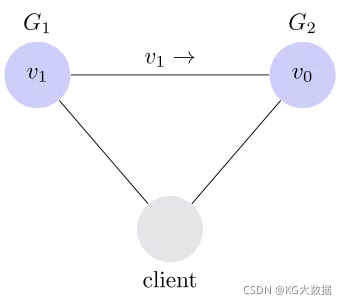
上图中,G1 和 G2 是两台跨区的服务器。G1 向 G2 发送一条消息,G2 可能无法收到。系统设计的时候,必须考虑到这种情况。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是存在的。即永远可能存在分区容错这个问题
8.3- Consistency
Consistency 中文叫做"一致性"。意思是,写操作之后的读操作,必须返回该值。举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。
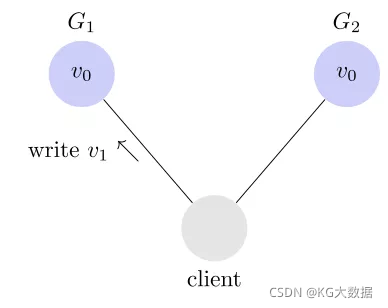
接下来,用户的读操作就会得到 v1。这就叫一致性。
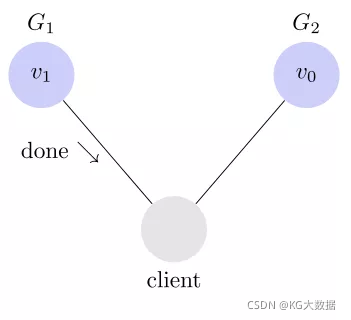
问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。
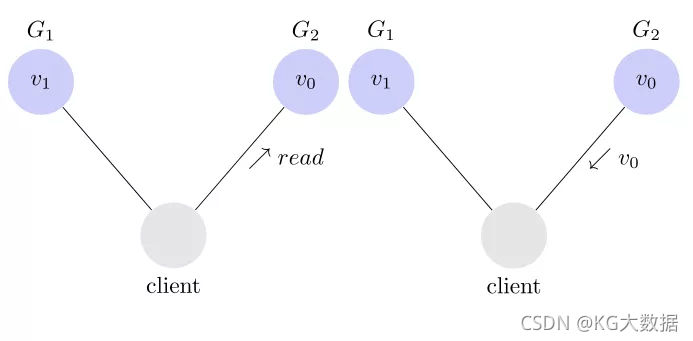
为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。
这样的话,用户向 G2 发起读操作,也能得到 v1。
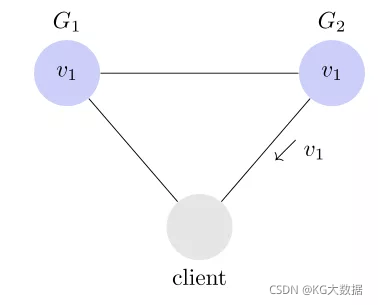
8.4- Availability
Availability 中文叫做"可用性",意思是只要收到用户的请求,服务器就必须给出回应。用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。
9- Kafka中的CAP机制
kafka是一个分布式的消息队列系统,既然是一个分布式的系统,那么就一定满足CAP定律,那么在kafka当中是如何遵循CAP定律的呢?kafka满足CAP定律当中的哪两个呢?
kafka满足的是CAP定律当中的CA,其中Partition tolerance通过的是一定的机制尽量的保证分区容错性。
其中C表示的是数据一致性。A表示数据可用性。
kafka首先将数据写入到不同的分区里面去,每个分区又可能有好多个副本,数据首先写入到leader分区里面去,读写的操作都是与leader分区进行通信,保证了数据的一致性原则,也就是满足了Consistency原则。然后kafka通过分区副本机制,来保证了kafka当中数据的可用性。但是也存在另外一个问题,就是副本分区当中的数据与leader当中的数据存在差别的问题如何解决,这个就是Partition tolerance的问题。
kafka为了解决Partition tolerance的问题,使用了ISR的同步策略,来尽最大可能减少Partition tolerance的问题。
每个leader会维护一个ISR(a set of in-sync replicas,基本同步)列表。
ISR列表主要的作用就是决定哪些副本分区是可用的,也就是说可以将leader分区里面的数据同步到副本分区里面去,决定一个副本分区是否可用的条件有两个:
- replica.lag.time.max.ms=10000 副本分区与主分区心跳时间延迟
- replica.lag.max.messages=4000 副本分区与主分区消息同步最大差
produce 请求被认为完成时的确认值:request.required.acks=0。
- ack=0:producer不等待broker同步完成的确认,继续发送下一条(批)信息。
- ack=1(默认):producer要等待leader成功收到数据并得到确认,才发送下一条message。
- ack=-1:producer得到follwer确认,才发送下一条数据。
10- Kafka监控及运维
在开发工作中,消费在Kafka集群中消息,数据变化是我们关注的问题,当业务前提不复杂时,我们可以使用Kafka 命令提供带有Zookeeper客户端工具的工具,可以轻松完成我们的工作。随着业务的复杂性,增加Group和 Topic,那么我们使用Kafka提供命令工具,已经感到无能为力,那么Kafka监控系统目前尤为重要,我们需要观察 消费者应用的细节。
10.1- kafka-eagle概述
为了简化开发者和服务工程师维护Kafka集群的工作有一个监控管理工具,叫做 Kafka-eagle。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具。
10.2- 环境和安装
10.2.1- 环境要求
需要安装jdk,启动zk以及kafka的服务
10.2.2- 安装步骤
1.下载源码包
kafka-eagle官网:http://download.kafka-eagle.org/
我们可以从官网上面直接下载最细的安装包即可kafka-eagle-bin-1.3.2.tar.gz这个版本即可
代码托管地址:
https://github.com/smartloli/kafka-eagle/releases
2.解压
这里我们选择将kafak-eagle安装在第三台。
直接将kafka-eagle安装包上传到node03服务器的/export/softwares路径下,然后进行解压 node03服务器执行一下命令进行解压。
3.准备数据库
kafka-eagle需要使用一个数据库来保存一些元数据信息,我们这里直接使用msyql数据库来保存即可,在node03服务器执行以下命令创建一个mysql数据库即可。
进入mysql客户端:
create database eagle;
4.修改kafak-eagle配置文件
执行以下命令修改kafak-eagle配置文件:
vim system-config.properties
修改为如下:
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=node01:2181,node02:2181,node03:2181
cluster2.zk.list=node01:2181,node02:2181,node03:2181kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://node03:3306/eagle
kafka.eagle.username=root
kafka.eagle.password=123456
5.配置环境变量
kafka-eagle必须配置环境变量,node03服务器执行以下命令来进行配置环境变量: vim /etc/profile:
export KE_HOME=/opt//kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2
export PATH=:$KE_HOME/bin:$PATH
修改立即生效,执行: source /etc/profile
6.启动kafka-eagle
执行以下界面启动kafka-eagle:
cd kafka-eagle-web-1.3.2/bin
chmod u+x ke.sh
./ke.sh start
7.主界面
访问kafka-eagle
http://node03:8048/ke/account/signin?/ke/
用户名:admin
密码:123456
11- Kafka大厂面试题
11.1- 为什么要使用 kafka?
- 缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
- 解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
- 冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
- 健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
- 异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
11.2- Kafka消费过的消息如何再消费?
kafka消费消息的offset是定义在zookeeper中的, 如果想重复消费kafka的消息,可以在redis中自己记录offset的checkpoint点(n个),当想重复消费消息时,通过读取redis中的checkpoint点进行zookeeper的offset重设,这样就可以达到重复消费消息的目的了。
11.3- kafka的数据是放在磁盘上还是内存上,为什么速度会快?
kafka使用的是磁盘存储。
速度快是因为:
- 顺序写入:因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是耗时的。所以硬盘 “讨厌”随机I/O, 喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
- Memory Mapped Files(内存映射文件):64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上。
- Kafka高效文件存储设计:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。通过索引信息可以快速定位 message和确定response的 大 小。通过index元数据全部映射到memory(内存映射文件), 可以避免segment file的IO磁盘操作。通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
注意:
- Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中 小的offset命名。这样在查找指定offset的 Message的时候,用二分查找就可以定位到该Message在哪个段中。
- 为数据文件建 索引数据文件分段 使得可以在一个较小的数据文件中查找对应offset的Message 了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
11.4- Kafka数据怎么保障不丢失?
分三个点说,一个是生产者端,一个消费者端,一个broker端。
1.生产者数据的不丢失
kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1。
如果是同步模式:
ack设置为0,风险很大,一般不建议设置为0。即使设置为1,也会随着leader宕机丢失数据。所以如果要严格保证生产端数据不丢失,可设置为-1。
如果是异步模式:
也会考虑ack的状态,除此之外,异步模式下的有个buffer,通过buffer来进行控制数据的发送,有两个值来进行控制,时间阈值与消息的数量阈值,如果buffer满了数据还没有发送出去,有个选项是配置是否立即清空buffer。可以设置为-1,永久阻塞,也就数据不再生产。异步模式下,即使设置为-1。也可能因为程序员的不科学操作,操作数据丢失,比如kill -9,但这是特别的例外情况。
注:
ack=0:producer不等待broker同步完成的确认,继续发送下一条(批)信息。
ack=1(默认):producer要等待leader成功收到数据并得到确认,才发送下一条message。
ack=-1:producer得到follwer确认,才发送下一条数据。
2.消费者数据的不丢失
通过offset commit 来保证数据的不丢失,kafka自己记录了每次消费的offset数值,下次继续消费的时候,会接着上次的offset进行消费。
而offset的信息在kafka0.8版本之前保存在zookeeper中,在0.8版本之后保存到topic中,即使消费者在运行过程中挂掉了,再次启动的时候会找到offset的值,找到之前消费消息的位置,接着消费,由于 offset 的信息写入的时候并不是每条消息消费完成后都写入的,所以这种情况有可能会造成重复消费,但是不会丢失消息。
唯一例外的情况是,我们在程序中给原本做不同功能的两个consumer组设置 KafkaSpoutConfig.bulider.setGroupid的时候设置成了一样的groupid,这种情况会导致这两个组共享同一份数据,就会产生组A消费partition1,partition2中的消息,组B消费partition3的消息,这样每个组消费的消息都会丢失,都是不完整的。为了保证每个组都独享一份消息数据,groupid一定不要重复才行。
3.kafka集群中的broker的数据不丢失
每个broker中的partition我们一般都会设置有replication(副本)的个数,生产者写入的时候首先根据分发策略(有partition按partition,有key按key,都没有轮询)写入到leader中,follower(副本)再跟leader同步数据,这样有了备份,也可以保证消息数据的不丢失。
11.5- 采集数据为什么选择kafka?
采集层 主要可以使用Flume, Kafka等技术。
Flume:Flume 是管道流方式,提供了很多的默认实现,让用户通过参数部署,及扩展API.
Kafka:Kafka是一个可持久化的分布式的消息队列。Kafka 是一个非常通用的系统。你可以有许多生产者和很多的消费者共享多个主题Topics。
相比之下,Flume是一个专用工具被设计为旨在往HDFS,HBase发送数据。它对HDFS有特殊的优化,并且集成了Hadoop的安全特性。
所以,Cloudera 建议如果数据被多个系统消费的话,使用kafka;如果数据被设计给Hadoop使用,使用Flume。
11.6- kafka 重启是否会导致数据丢失?
- kafka是将数据写到磁盘的,一般数据不会丢失。
- 但是在重启kafka过程中,如果有消费者消费消息,那么kafka如果来不及提交offset,可能会造成数据的不准确(丢失或者重复消费)。
11.7- kafka 宕机了如何解决?
1.先考虑业务是否受到影响
kafka 宕机了,首先我们考虑的问题应该是所提供的服务是否因为宕机的机器而受到影响,如果服务提供没问题,如果实现做好了集群的容灾机制,那么这块就不用担心了。
2.节点排错与恢复
想要恢复集群的节点,主要的步骤就是通过日志分析来查看节点宕机的原因,从而解决,重新恢复节点。
11.8- 为什么Kafka不支持读写分离?
在 Kafka 中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型。Kafka 并不支持主写从读,因为主写从读有 2 个很明显的缺点:
- 数据一致性问题:数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
- 延时问题:类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经历 网络→主节点内存→网络→从节点内存 这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历 网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘 这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
而kafka的主写主读的优点就很多了:
- 可以简化代码的实现逻辑,减少出错的可能;
- 将负载粒度细化均摊,与主写从读相比,不仅负载效能更好,而且对用户可控;
- 没有延时的影响;
- 在副本稳定的情况下,不会出现数据不一致的情况。
11.9- kafka数据分区和消费者的关系?
每个分区只能由同一个消费组内的一个消费者(consumer)来消费,可以由不同的消费组的消费者来消费,同组的消费者则起到并发的效果。
11.10- kafka的数据offset读取流程
- 连接ZK集群,从ZK中拿到对应topic的partition信息和partition的Leader的相关信息
- 连接到对应Leader对应的broker
- consumer将⾃自⼰己保存的offset发送给Leader
- Leader根据offset等信息定位到segment(索引⽂文件和⽇日志⽂文件)
- 根据索引⽂文件中的内容,定位到⽇日志⽂文件中该偏移量量对应的开始位置读取相应⻓长度的数据并返回给consumer
11.11- kafka内部如何保证顺序,结合外部组件如何保证消费者的顺序?
kafka只能保证partition内是有序的,但是partition间的有序是没办法的。爱奇艺的搜索架构,是从业务上把需要有序的打到同⼀个partition。
11.12- Kafka消息数据积压,Kafka消费能力不足怎么处理?
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
11.13- Kafka单条日志传输大小
kafka对于消息体的大小默认为单条最大值是1M但是在我们应用场景中, 常常会出现一条消息大于1M,如果不对kafka进行配置。则会出现生产者无法将消息推送到kafka或消费者无法去消费kafka里面的数据, 这时我们就要对kafka进行以下配置:server.properties
replica.fetch.max.bytes: 1048576 broker可复制的消息的最大字节数, 默认为1M
message.max.bytes: 1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右
注意:message.max.bytes必须小于等于replica.fetch.max.bytes,否则就会导致replica之间数据同步失败。
都看到这里了,就点个赞吧? 我代表(加内特,科比,詹姆斯,库里)谢谢你呀!
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- WIFI模块中AP模式和STA模式的区别
WIFI模块中,AP和STA模式中分别意思是: 1.AP:也就是无线接入点,是一个无线网络的创建者,是网络的中心节点。一般家庭或办公室使用的无线路由器就是一个AP。 2.STA站点就是每一个连接到无线网络中的终端(如笔记本电脑、PDA及其它可以联网的用户设备)都可称为一个站点。 AP模式:…...
2024/4/19 7:28:56 - js数组转换
var data {id:"11",name:"张三"};var keyMap {id: "序列", name: "姓名"};var objs Object.keys(data).reduce((newData, key) > { let newKey keyMap[key] || key newData[newKey] data[key] return newData; }, {}) console.…...
2024/4/25 4:47:13 - Vue监视属性
1.监视属性watch: 1.当被监视的属性变化时,回调函数自动调用,进行相关操作 2.监视的属性必须存在,才能进行监视!! 3.监视的两种写法: (1).new Vue时传入watch配置 (2).通过vm.$watch监视 html里直接{{isHot}}<script type"text/javascript">const vm new V…...
2024/4/15 7:47:12 - 汇编语言3
1.转移指令 定义:修改IP或同时修改CS和IP的指令称为转移指令 jmp short :-127~127 jmp near ptr:-32768~32767 jmp 偏移量:并没有给出目的地址的地址,而是给出了目的地址相对此时IP的偏移量 jmp far ptr:段间转移 包含目的地的地址 高位地址为段地址,低位地址为偏移地址 j…...
2024/4/15 7:47:12 - Dbeaver 导入csv文件
环境:pg数据库 连接工具Dbeaver 需求:一个excel表格导入到数据库中的一个表 开始: excel 表内容如下 如果是excel表,要先把后缀名称改成csv,然后打开csv文件,选择另存为,填写文件名称࿰…...
2024/4/26 13:04:43 - c++网络技术支撑
服务器端代码: #define _WINSOCK_DEPRECATED_NO_WARNINGS #include<WinSock2.h> #include<Windows.h> #include<iostream> using namespace std; #pragma comment(lib,"ws2_32")int main() {WSADATA wsaDate {};WSAStartup(MAKEWORD(2…...
2024/4/20 16:32:25 - Java——类和对象超详细总结
文章目录类和对象1.类与对象的初步认识2.类和类的实例化3.类的成员3.1字段/属性/成员变量3.2方法3.3 static关键字4.封装4.1 private实现封装4.2 getter和setter方法5.构造方法5.1基本语法5.2 this关键字6.认识代码块6.1什么是代码块6.2普通代码块6.3构造代码块6.4静态代码块类…...
2024/4/15 7:46:57 - GAN与WGAN
文章目录GAN和WGANGAN判别网络生成网络训练GAN存在的问题训练稳定性模型坍塌改进方法:WGANWasserstein\text{Wasserstein}Wasserstein距离评价网络生成网络开源代码GAN和WGAN GAN 生成对抗网络(GAN, Generative Adversarial Networks)是2014年由Goodfellow提出的模…...
2024/4/18 11:07:49 - 【Java面试题】数据库与JVM综合篇(附有答案,2021年您应该知道的技术之一)
1、列不可再分; 2、每一行数据只做一件事,只与一列相关,主键; 3、每个属性都与主键有直接关系,而不是间接关系; 三大范式只是设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果…...
2024/4/15 7:47:02 - 我是如何开发一个项目的
文章目录碎碎念明确为什么要开发这个项目是很重要的需求分析项目设计之螺旋式上升“备忘录模式” 开启测试做在前碎碎念 鉴于这个毕设已经重写第三遍了,我觉得有必要写这么两篇来指导一下我自己了。 第一篇是《我是如何开发一个项目的》,从我浅薄的项目…...
2024/4/23 5:46:18 - 读书笔记:《JavaScript高级程序设计》(第4版)--第一章:什么是JavaScript
1.1简短的历史回顾 JavaScript是一门脚本语言。ECMAScript是JavaScript的实现标准。当然,在语言表达的时候不必特别区分,基本上是同义词。 1.2JavaScript实现 完整的JavaScript实现包括:核心(ECMAScript)、文档对象模…...
2024/4/20 13:16:24 - Gartner发布2021企业低代码魔力象限,这个平台连续三年第一
今年年初,阿里云智能总裁张建锋在接受《钛媒体》专访时说:“2021 年的潮流就是低代码开发。”而回望2021年过去的10个月,低代码开发确实以一种不可阻挡的趋势,席卷了各个行业。 作为国际知名咨询机构,Gartner每年都会…...
2024/4/19 4:25:50 - 什么是Java类和对象(初阶)
目录 1.面向对象 2.类和对象 3.类和对象的关系 4.定义类 5.成员变量和局部变量 6.调用方法 1.面向对象 众所周知,Java语言是一门面向对象的语言,什么是面向对象?面向对象是以对象为基础,完成各种操作,主要强调对…...
2024/4/20 22:54:12 - 一招教你快速打造企业级数据可视化大屏
低代码是这两年最热的技术话题之一,围绕着低代码产生了许多理念。有人说这是类似语法糖的玩具,也有人说低代码将颠覆整个行业并取代大批开发者。众说纷纭,那么低代码的真实面貌究竟是什么? 11月4日 19点,云智慧技术经…...
2024/4/26 0:48:01 - 第二章求100以内偶数之和
文字描述 1.定义两个变量sum和i,i的初始值为2; 2.i<100,转到第三步,否则转到第六步; 3.sum等于sum加i; 4.i增加2; 5.返回第三步; 6.输出sum此时sum的值为他们的和; 流程图 求100以内偶…...
2024/4/17 14:01:26 - 阿里云GanosBase升级,发布首个云孪生时空数据库
简介: GanosBase是李飞飞带领的达摩院数据库与存储实验室联合阿里云共同研发的新一代位置智能引擎;本次重磅升级为V4.0版本,推出首个云孪生时空数据库。 作者 | 谢炯 来源 | 阿里技术公众号 导读: GanosBase是李飞飞带领的达摩院…...
2024/4/19 9:09:07 - Windows远程访问Ubuntu 16.04
远程连接到Linux服务器(本文是Ubuntu),方法分为两种。 第一种:通过SSH服务(使用xshell等工具)来远程访问,编写终端命令,不过这个是无界面的,很多人也喜欢这种方式,因为快捷方便。 …...
2024/4/15 7:47:48 - 数据库---data
创建数据库 create database demo1; 切换到某个数据库 use demo1; 创建表 create table test(id varchar(20),name varchar(20),age varchar(20),addr varchar(20)); 展示表 show tables; 向test表插入数据 insert into test values(‘1001’,’zhangsan’,’20’,’chizh…...
2024/4/25 2:38:56 - 交叉验证和网格搜索 GridSearchCV / cross_val_score
交叉验证 1.定义:将拿到的训练集,分为训练集和验证集 几折交叉验证(训练集被分为几部分) 2.分割方式: 训练集:训练集验证集 测试集:测试集 3.为什么需要交叉验证 …...
2024/4/20 20:34:33 - LeetCode 刷题 (算法入门)
一、有序数组的进阶 方法三:双指针法 利用双指针,left和right从数组两端向中间遍历,每次将对应元素平方后比较大的值逆序存放在数组中 class Solution { public:vector<int> sortedSquares(vector<int>& nums) {int n nu…...
2024/4/24 11:12:11
最新文章
- 免费的一键伪原创工具,用来高效写文章真妙!
写文章是一件耗时间、费精力的事,遇到没有写作灵感的时候,写文章就像嚼蜡一样难受,但好在有免费的一键伪原创工具,它能帮助我们高效率实现自动写作文章,并且整个写作的过程我们无需思考内容怎么去写,是可以…...
2024/4/26 22:57:33 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 开启 Keep-Alive 可能会导致http 请求偶发失败
大家好,我是蓝胖子,说起提高http的传输效率,很多人会开启http的Keep-Alive选项,这会http请求能够复用tcp连接,节省了握手的开销。但开启Keep-Alive真的没有问题吗?我们来细细分析下。 最大空闲时间造成请求…...
2024/4/23 4:15:19 - vscode安装通义灵码
作为vscode的插件,直接使用 通义灵码-灵动指间,快码加编,你的智能编码助手 通义灵码,是一款基于通义大模型的智能编码辅助工具,提供行级/函数级实时续写、自然语言生成代码、单元测试生成、代码注释生成、代码解释、研…...
2024/4/24 15:00:15 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/26 18:09:39 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/26 20:12:18 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/25 18:38:39 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/25 18:39:23 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/25 18:39:22 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/25 18:39:22 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/26 21:56:58 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/25 16:48:44 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/26 16:00:35 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/25 18:39:16 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/25 18:39:16 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/26 22:01:59 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/25 18:39:14 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/25 18:39:12 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/25 2:10:52 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/25 18:39:00 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/26 19:46:12 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/25 18:38:58 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/25 18:38:57 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57