离散数学期末复习概念_复习第1部分中的基本概念
离散数学期末复习概念
深层钢筋学习讲解— 12 (DEEP REINFORCEMENT LEARNING EXPLAINED — 12)
Part 1 of the “Deep Reinforcement Learning Explained” series introduces a practical approach to the essential concepts in Reinforcement Learning (RL) and Deep Learning (DL) to begin in the area of Deep Reinforcement Learning (DRL).
“ 深度强化学习介绍”系列的第1部分介绍了一种针对强化学习(RL)和深度学习(DL)的基本概念的实用方法,从深度强化学习(DRL)领域开始。
This post starts a new part, Part 2, where we will introduce the implementation of Reinforcement Learning classical methods, as Monte Carlo, Temporal Difference Learning, SARSA or Q-learning.
这篇文章开始一个新的部分, 第2部分,我们将在其中介绍强化学习经典方法的实现 ,例如蒙特卡洛(Monte Carlo),时间差异学习,SARSA或Q学习。
萨顿和巴托的强化学习书 (Reinforcement Learning book by Sutton and Barto)
We will formalize a little more the formulation presented in Part 1 in order to align it to the notation used in the textbook Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto. This book is “the” classic text with an excellent introduction to Reinforcement Learning fundamentals. Thus, if the reader wishes, he will be able to use this excellent book to deepen at a theoretical level in any of the subjects that we present here. I think that with the basis of RL that the reader acquired in Part 1, it is easy to do it now and it can be very helpful for the reader to have bibliographic resources like this to complement your study.
我们将对第1部分中提出的公式进行更多形式化,以使其与Richard S. Sutton和Andrew G. Barto的教科书《 强化学习:入门》中使用的符号保持一致。 本书是“经典”教材,对强化学习的基础知识进行了出色的介绍。 因此,如果读者愿意,他将能够使用这本出色的书在理论水平上加深我们在此提出的任何主题。 我认为,以读者在第1部分中获得的RL为基础,现在很容易做到这一点,对于读者来说,拥有像这样的书目资源来补充您的研究可能会非常有帮助。
Dr. Richard S. Sutton is a distinguished research scientist at DeepMind and a renowned professor of computing science at the University of Alberta. Dr. Sutton is considered one of the founding fathers of modern computational Reinforcement Learning. Dr. Andrew G. Barto is a professor emeritus at University of Massachusetts Amherst, and was the doctoral advisor of Dr. Sutton.
Richard S. Sutton博士是DeepMind的杰出研究科学家, 也是阿尔伯塔大学计算机科学的著名教授。 Sutton博士被认为是现代计算强化学习的创始人之一。 博士 安德鲁·巴托 ( Andrew G. Barto)是麻省大学阿默斯特分校(University of Massachusetts Amherst)的名誉教授,也是萨顿(Sutton)博士的博士生顾问。
符号和定义已更新 (Notation and definitions updated)
In this section we will review and update the mathematical notation introduced in Part 1 of this series modified a little in order to fit the one presented in Sutton’s book.
在本节中,我们将回顾和更新本系列第1部分中引入的数学符号,并对其进行了一些修改,以适应萨顿书中介绍的数学符号。
Because the Medium editor has certain limitations for writing formulas, I am going to write these formulas in Latex and include here as images. In order to make it clearer, I will create a set of cheatsheets with the main formulas and definitions to guide your study of RL along with this series. The latex code of these cheatsheets can be found on the GitHub of this series.
由于中型编辑器在编写公式方面有一定的局限性,因此我将在Latex中编写这些公式,并将其作为图像包含在其中。 为了使内容更清楚,我将创建一组备有主要配方和定义的备忘单 ,以指导您学习RL及其系列。 这些备忘单的乳胶代码可以在本系列的GitHub上找到。
In post 2 we have seen that we can use a Markov Decision Process (MDP) as a formal definition of the problem that we’d like to solve with Reinforcement Learning. A MDP is defined by 5 parameters <S,A,R,γ,p>, where each one indicates:
在第二篇文章中,我们看到我们可以使用马尔可夫决策过程(MDP)作为我们要通过强化学习解决的问题的正式定义。 一个MDP由5个参数<S,A,R,γ,p>定义,其中每个参数指示:

Other related definitions that we will use along this series are:
我们将在本系列中使用的其他相关定义是:
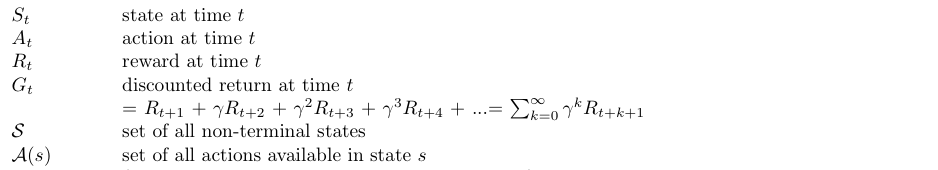
At an arbitrary time step t, the Agent and the MDP Environment interaction has evolved as a sequence of states, actions, and rewards (trajectory) like this:
在任意时间步长t ,Agent与MDP Environment的交互已演变为一系列状态,动作和奖励( 轨迹 ),如下所示:
Remember that the Environment responds to the Agent at time step t, it considers only the state and action at the previous time step t-1 . It does not care what states were presented to the Agent more than one step prior. It does not look at the actions that the Agent took prior to the last one. And finally, neither how much reward it is collecting, has no effect on how the Environment chooses to respond to the Agent.
请记住,环境在时间步t响应代理,它仅考虑前时间步t-1的状态和动作。 它不关心在多于一个步骤之前向代理呈现了哪些状态。 它不查看代理在上一个代理之前执行的操作。 最后,无论收集到多少报酬,都不会影响环境如何选择响应代理。
Because of this, we can completely define how the Environment decides the state and reward by specifying the transition function p as we did here (the dot over the equals sign in the equation reminds us that it is a definition). The function p defines the dynamics of the MDP. These conditional probabilities are said to specify the one-step dynamics of the Environment.
因此,我们可以像在此一样通过指定转换函数p来完全定义环境如何决定状态和奖励(等式中等号上的点提醒我们这是一个定义)。 函数p定义了MDP的动态特性。 据说这些条件概率指定了环境的一步动态 。
As a summary, emphasize that when we have a real problem in mind, we will need to specify the MDP as a way to formally define the problem that we want our Agent to solve. The Agent will know the states and actions along with the discount factor. We have the function p, those specify how the Environment works and will be unknown to the Agent. Despite not having this information, the Agent will still have to learn from interaction with the Environment on how to accomplish its goal.
作为总结,强调当我们想到一个实际问题时,我们将需要指定MDP作为正式定义我们希望我们的代理解决的问题的方法。 代理将了解状态和操作以及折扣系数。 我们具有函数p ,这些函数指定环境如何工作,并且对代理是未知的 。 尽管没有此信息,代理仍然必须从与环境的交互中学习如何实现其目标。
连续任务的折现率 (Discount rate for continuing task)
Before continuing, I recommend the reader to review post 2 to refresh the basics. But let us briefly add how the discount rate behaves in a continuing task not covered in Part 1.
在继续之前,我建议读者阅读第二篇文章以刷新基础知识。 但是,让我们简要地添加折扣率在第1部分中未涉及的连续任务中的行为。
连续任务示例 (Continuing Task Example)
In Part 1 of this series, we used an episodic task, the Frozen-Lake Environment, a simple grid-world Environment from OpenAI Gym, a toolkit for developing and comparing RL algorithms. In this section we will introduce a continuing task using another Environment, the Cart-Pole balancing problem:
在本系列的第1部分中,我们使用了一个偶发性任务,即冰冻湖水环境,这是来自OpenAI Gym的简单网格世界环境,该环境是开发和比较RL算法的工具包。 在本节中,我们将介绍使用另一个环境的持续任务,即购物车-车子平衡问题 :
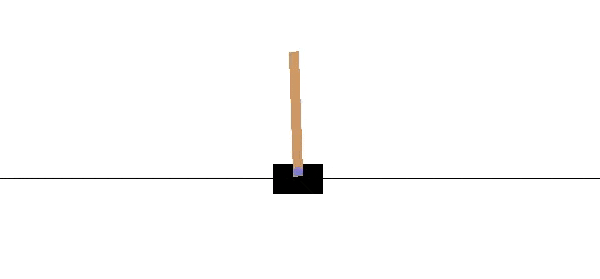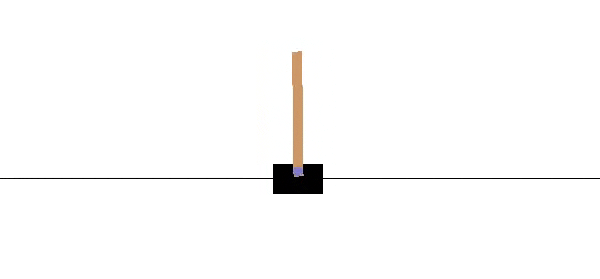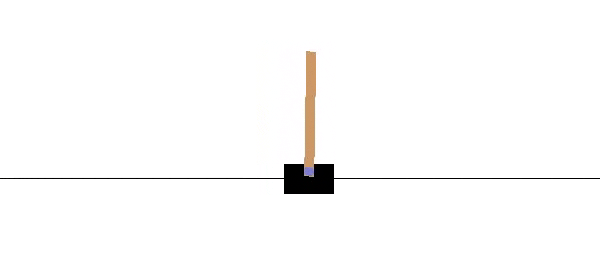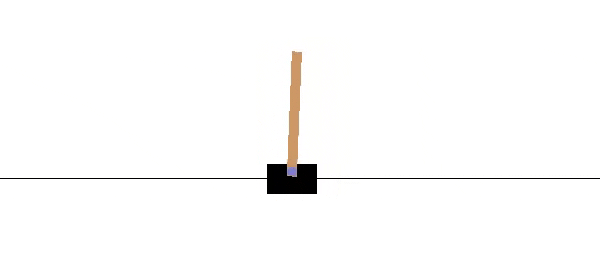
As it is shown in the previous figure, a cart is positioned on a frictionless track along the horizontal axis, and a pole is anchored to the top of the cart. The objective is to keep the pole from falling over by moving the cart either left or right, and without falling off the track.
如上图所示,手推车沿水平轴放置在无摩擦的轨道上,并且一根杆子固定在手推车的顶部。 目的是通过向左或向右移动手推车来防止杆子跌落,并且不会掉落轨道。
The system is controlled by applying a force of +1 (left) or -1 (right) to the cart. The pendulum starts upright, and the goal is to prevent it from falling over. A reward of +1 is provided for every time-step that the pole remains upright, including the final step of the episode. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the center.
通过对推车施加+1(左)或-1(右)的力来控制系统。 钟摆开始直立,目的是防止其跌落。 对于杆保持直立的每个时间步(包括情节的最后一步),都会提供+1的奖励。 当杆子与垂直线的夹角超过15度时,或者推车从中心移出2.4个单位以上时,情节结束。
The observation space for this Environment at each time point is an array of 4 numbers. At every time step, you can observe its position, velocity, angle, and angular velocity. These are the observable states of this world. You can look up what each of these numbers represents in this document. Notice the minimum (-Inf) and maximum (Inf) values for both Cart Velocity and the Pole Velocity at Tip. Since the entry in the array corresponding to each of these indices can be any real number, that means, the state space is infinite!
此环境在每个时间点的观察空间是4个数字的数组。 在每个时间步上,您都可以观察其位置,速度,角度和角速度。 这些是这个世界可观察的状态。 您可以查询本文档中每个数字所代表的含义。 请注意小车速度和顶杆速度的最小值(-Inf)和最大值(Inf)。 由于数组中与这些索引中的每个索引对应的条目可以是任何实数,因此,状态空间是无限的!
At any state, the cart only has two possible actions: move to the left or move to the right. In other words, the state-space of the Cart-Pole has four dimensions of continuous values and the action-space has one dimension of two discrete values.
在任何状态下,购物车只有两种可能的动作: 向左 移动或向右移动 。 换句话说,购物车杆的状态空间具有四个连续值的维,而动作空间具有两个离散值的一维。
折扣率 (Discount rate)
Which discount rates would encourage the Agent to keep the pole balanced in our example of continuing task for as long as possible?
哪种折扣率会鼓励代理商在我们继续执行任务的示例中尽可能长时间保持平衡?
With any discount rate γ>0, the Agent receives a positive reward for each time-step where the pole has not yet fallen. Thus, the agent will try to keep the pole balanced for as long as possible.
在任何贴现率γ> 0的情况下,对于极点尚未下降的每个时间段,代理都会收到正回报。 因此,代理将尝试尽可能长时间地保持极点平衡。
However, imagine that the reward signal is amended to only give a reward to the Agent at the end of an episode. In other words that is, the reward is 0 for every time step, with the exception of the final time step, when the episode terminates, and then the Agent receives a reward of +1.
但是,想象一下将奖励信号修改为仅在情节结束时对特工给予奖励。 换句话说,当情节终止时,除了最后一个时间步长以外,每个时间步长的奖励都是0,然后特工会收到+1的奖励。
In this case, if the discount rate is γ=1, the agent will always receive a reward of +1 (no matter what actions it chooses during the episode), and so the reward signal will not provide any useful feedback to the agent.
在这种情况下,如果折现率是γ= 1,则代理将始终获得+1的奖励(无论在情节期间选择何种操作),因此奖励信号将不会向代理提供任何有用的反馈。
If the discount rate is γ<1 the Agent will try to terminate the episode as soon as possible (by either dropping the pole quickly or moving off the edge of the track). Thus, in this case, we must redesign the reward signal!
如果折现率为γ <1,代理将尝试尽快终止该情节(通过快速掉下杆或从轨道边缘移开)。 因此,在这种情况下,我们必须重新设计奖励信号!
The solution to this problem, that means a series of actions that need to be learned by the Agent towards the pursuit of a goal, is determined by the Policy. In the next section, we will continue a little further in the formal definition of the solution to this problem.
该问题的解决方案(即代理人为实现目标而需要学习的一系列操作)由政策决定。 在下一节中,我们将继续对这个问题的解决方案进行正式定义。
政策 (Policy)
The policy is the strategy (e.g. some set of rules) that the Agent employs to determine the next action based on the current state. Typically denoted by 𝜋(𝑎|𝑠), the Greek letter pi, a policy is a function that determines the next action a to take given a state s.
该策略是代理用来根据当前状态确定下一个操作的策略(例如,某些规则集)。 通常用𝜋(𝑎|𝑠)(希腊字母pi)表示 是确定给定状态s采取下一个动作a的函数。
The simplest kind of policy is a mapping from the set of environment states S to the set of possible actions A. We call this kind of policy a deterministic policy. But in post 2 we also introduced that the policy 𝜋(𝑎|𝑠) can be defined as probability and not as concrete action. In other words that are, a stochastic policy that has a probability distribution over actions that an Agent can take at a given state.
最简单的策略是从环境状态S到可能动作A的映射。 我们称这种政策为确定性政策 。 但是在第二篇文章中,我们还介绍了可以将策略𝜋(𝑎|𝑠)定义为概率而不是具体行动。 换句话说,是一种随机策略 ,该策略对代理在给定状态下可以采取的操作具有概率分布。
The stochastic policy will allow the Agent to choose actions randomly. More formally, We define a stochastic policy as a mapping that accepts an Environment state S and action A and returns the probability that the agent takes action A while in state S:
随机策略将允许代理随机选择操作。 更正式地说,我们将随机策略定义为接受环境状态S和动作A并返回代理在状态S时采取动作A的概率的映射:
During the learning process, the policy 𝜋 may change as the Agent gains more experience. For example, the Agent may start from a random policy, where the probability of all actions is uniform; meanwhile, the Agent will hopefully learn to optimize its policy toward reaching the optimal policy.
在学习过程中,策略𝜋可能会随着代理获得更多经验而发生变化。 例如,代理可以从随机策略开始,在该策略中所有操作的概率是一致的; 同时,Agent有望学习优化其策略以达到最佳策略。
Now that we know how to specify a policy, what steps can we take to make sure that the Agent’s policy is the best one? We will use the state-value function and action-value function already introduced in Post 2.
现在我们知道如何指定策略,我们可以采取哪些步骤来确保代理策略是最佳策略? 我们将使用Post 2中已经介绍的state-value函数和action-value函数。
价值功能 (Value functions)
The state-value function, also referred to as the value function, or even the V-function, measures the goodness of each state, it tells us the total return we can expect in the future if we start from that state.
状态值函数 (也称为值函数 ,甚至称为V函数 )衡量每个状态的优劣,它告诉我们如果从该状态开始,可以期望将来获得总收益。
For each state s, the state-value function tells us the expected discounted return G, if the agent started in that state s, and then use the policy to choose its actions for all time steps. It is important to note that the state value function will always correspond to a particular policy, so if we change the policy, we change the state-value function. For this reason, we typically denote the function with the lowercase v with the corresponding policy 𝜋 in the subscript and defined formally by:
对于每个状态s ,状态值函数会告诉我们预期的折现收益G ,如果代理在该状态s中启动,然后使用该策略为所有时间步选择其动作。 重要的是要注意,状态值函数将始终对应于特定策略,因此,如果我们更改策略,则将更改状态值函数。 因此,我们通常在下标中用对应的策略note表示小写v的函数,并通过以下方式正式定义:
where 𝔼[·] denotes the expected value of a random variable given that the agent follows policy 𝜋, and t is any time step. As we introduced in Post 8, it is used expectation 𝔼[.] in this definition because the environment transition function might act in a stochastic way.
其中𝔼[·]表示给定代理遵循策略𝜋的随机变量的期望值, t是任何时间步长。 正如我们在Post 8中介绍的那样,在此定义中使用了期望𝔼[。],因为环境转换函数可能以随机方式起作用。
Also in post 2 we extended the definition of state-value function to state-action pairs, defining a value for each state-action pair, which is called the action-value function, also known as Q-function or simply Q. It defines the value of taking action a in state s under a policy π, as the expected Return G starting from s, taking the action a, and thereafter following policy π:
同样在第二篇文章中,我们将状态值函数的定义扩展到状态动作对,为每个状态动作对定义了一个值,这称为动作值函数,也称为Q函数或简称Q。它定义了在策略π下在状态s下采取措施a的值,作为预期收益G从s开始,采取措施a,然后遵循策略π:
贝尔曼期望方程 (Bellman Expectation Equation)
For a general MDP, we have to work in terms of an expectation, since it’s not often the case that the immediate reward and next state can be predicted with certainty. Indeed, we saw in the previous post that the reward r and next state s’ are chosen according to the one-step dynamics of the MDP. In this case, where the r and s′ are drawn from a (conditional) probability distribution p(s′,r∣s,a), the Bellman Expectation Equation expresses the value of any state s in terms of the expected immediate reward and the expected value of the next state (satisfying a recursive relationships).
对于一般的MDP,我们必须根据期望进行工作,因为通常无法确定地预测即时回报和下一状态。 确实,我们在上一篇文章中看到,根据MDP的单步动态选择了奖励r和下一个状态s' 。 在这种情况下,如果r和s '是从(条件)概率分布p(s',r∣s,a)中得出的 ,则Bellman期望方程式根据期望的立即回报来表示任何状态s的值,并且下一个状态的期望值 (满足递归关系 )。
For the general case, where the Agent’s policy π is stochastic, the Agent selects action a with probability π(a∣s) when in state s, and the Bellman Expectation Equation can be expressed as:
对于一般情况,在代理策略π 随机的情况下,当处于状态s时,代理以概率π ( a ∣ s )选择动作a ,而Bellman期望方程可表示为:
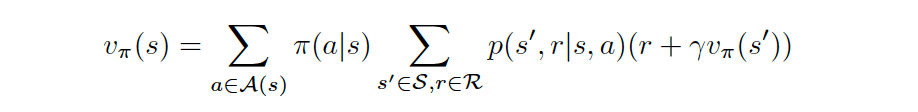
In this case, we multiply the sum of the reward and discounted value of the next state (r+γvπ(s′)) by its corresponding probability π(a∣s)p(s′,r∣s,a) and sum over all possibilities to yield the expected value.
在这种情况下,我们将下一个状态( r + γvπ ( s ))的奖励和折扣值之和乘以其相应的概率π ( a ∣ s ) p ( s ′, r ∣ s , a )和对所有可能性求和以得出期望值。
We also have the Bellman equation for the action-value function:
对于动作值函数,我们还有Bellman方程:
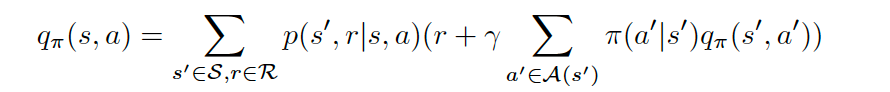
最优政策 (Optimal Policy)
The goal of the Agent is to maximize the total cumulative reward in the long run. The policy, which maximizes the total cumulative reward is called the optimal policy. In Post 8 we introduced the “optimal” value functions.
代理商的目标是从长远来看最大化总累积奖励。 使总累积奖励最大化的策略称为最优策略 。 在Post 8中,我们介绍了“最优”值函数。
A policy π′ is defined to be better than or equal to a policy π if and only if vπ′(s)≥vπ(s) for all s∈S. An optimal policy π∗ satisfies π∗≥π for all policies π. An optimal policy is guaranteed to exist but may not be unique.
策略π'被定义为优于或等于π政策当且仅当Vπ'(一个或多个 )≥Vπ(S)对于所有s∈S。 最优政策 π*满足π*≥π所有策略π。 最优策略可以保证存在,但可能不是唯一的。
All optimal policies have the same state-value function v∗, called the optimal state-value function. A more formal definition for the optimal state-value functions could be:
所有最优策略都具有相同的状态值函数v ∗ ,称为最优状态值函数 。 最佳状态值函数的更正式定义可以是:
and for the action-value function:
对于动作值函数:
All optimal policies have the same action-value function q∗, called the optimal action-value function.
所有最优策略都具有相同的作用值函数q ∗ ,称为最优作用值函数 。
This optima action-value are very useful in order to obtain the optimal policy. The Agent estimates it by interacting with the Environment. Once the agent determines the optimal action-value function q∗, it can quickly obtain an optimal policy π∗ by setting:
该最佳动作值对于获得最佳策略非常有用。 代理通过与环境交互来估计它。 一旦代理确定了最佳行动值函数q ∗,它就可以通过设置以下内容快速获得最佳策略π ∗:
As we saw in Post 8 the Bellman equation is used to find the optimal values of the value functions in the algorithms to calculate them. A more formal expression could be:
正如我们在文章8中看到的那样,使用Bellman方程在算法中找到值函数的最佳值以进行计算。 更为正式的表达可能是:
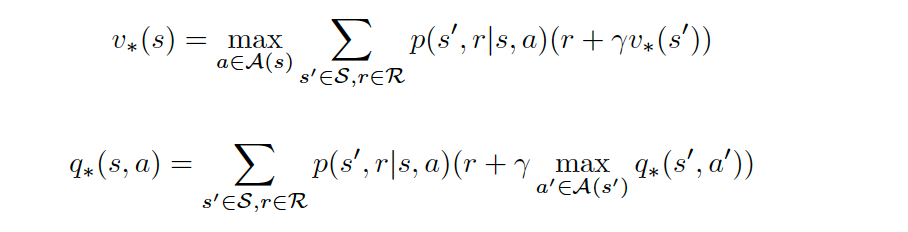
接下来是什么? (What is next?)
We have reached the end of this post!. In the following post, we are going to introduce the Monte Carlo Method, a learning method for estimating value functions and discovering optimal policies. Unlike the Value Iteration algorithm introduced in Posts 9, 10 and 11, here we do not assume complete knowledge of the Environment. Monte Carlo methods require only experience — sample sequences of states, actions, and rewards from actual or simulated interaction with the Environment, similar with what we did with the Cross-Entropy Method introduced in Post 6.
我们已经到了这篇文章的结尾! 在下面的文章中 ,我们将介绍蒙特卡洛方法,这是一种用于估计价值函数和发现最优政策的学习方法。 不同于数值迭代算法,帖子介绍了9 , 10和11 ,在这里我们不承担环境的完整的知识。 蒙特卡洛方法只需要经验,即与环境的实际或模拟交互中的状态,动作和奖励的示例序列,与我们在Post 6中引入的交叉熵方法相似。
See you in the next post!
下篇再见!
翻译自: https://towardsdatascience.com/reviewing-essential-concepts-from-part-1-e28234ee7f4f
离散数学期末复习概念
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 武汉整双眼皮诠美正规
...
2024/4/21 14:54:39 - 武汉同济双眼皮价格表
...
2024/4/20 15:11:33 - 武汉双眼皮修复名医
...
2024/5/2 12:49:12 - 武汉双眼皮诠美挺好
...
2024/4/20 15:11:30 - 武汉哪双眼皮诠美正规
...
2024/4/20 15:11:29 - Angular4_NgForOf 指令作用
NgForOf 指令作用 该指令用于基于可迭代对象中的每一项创建相应的模板。每个实例化模板的上下文对象继承于外部的上下文对象,其值与可迭代对象对应项的值相关联。 NgForOf 指令语法 * 语法糖 <li *ngFor"let item of items; index as i; trackBy: trackByFn…...
2024/4/21 14:54:38 - 武汉开双眼皮诠美正规
...
2024/5/2 20:49:28 - 武汉割双眼皮诠美真好
...
2024/4/22 14:33:11 - Vue 与 Angular(2以上)的比较 ——参考 Vue 官方文档的个人总结
对 TypeScript 的支持 Angular 必须用 TypeScript 来开发。 Vue 也支持 TypeScript ,但并没有像 Angular那么深入。 在中小型规模的项目中,引入 TS 可能并不会带来太多明显的优势,所以使用 Vue比较多。 运行性能 这两个框架运行速度都很快…...
2024/4/21 14:54:36 - 武汉割双眼皮诠美典范
...
2024/4/21 14:54:35 - 无痕五点五点双眼皮恢复过程图
...
2024/4/21 14:54:33 - 无痕双眼皮会不会取消
...
2024/4/24 18:50:39 - angular项目中实现类似table栏中顶部tr标头固定,列表滚动 类似于position:fixed效果,但是不相对于body固定定位 无效的position:fixed...
题主在工作遇到需要类似于table表格的效果,其中table在body里面,并不是顶部table栏,如下图效果: 刚开始楼主想到利用bootstrap中的table和 顶部tr进行position:fixed实现此功能,但是在实际操作中发现bootst…...
2024/5/2 10:54:26 - 钉钉微应用手机端导航栏配置
一、设置导航栏颜色 在url后面拼接dd_nav_bgcolor参数即可,如下: 支持的格式:“AARRGGBB” http://abc.xyz?dd_nav_bgcolorFF5E97F6 二、微应用页面支持横屏 在url后面拼接dd_orientation参数即可,如下: http://abc.xyz?dd_o…...
2024/4/28 4:53:39 - ionic之将android导航栏安放到底部
我是代码 .config(function ($stateProvider, $urlRouterProvider,$ionicConfigProvider) {$ionicConfigProvider.platform.ios.tabs.style(standard);$ionicConfigProvider.platform.ios.tabs.position(bottom);$ionicConfigProvider.platform.android.tabs.style(standard);$…...
2024/4/28 15:07:31 - ionic tabs完美自定义背景及点击和正常的颜色
上一篇提到自定义tabs,但是因为时间关系及阐述一点导航栏的东西,没有完成,这篇接上一篇,接着来自定义tabs,ionic中已经内置了默认的几种样式,基本也能满足了自己的应用,不过公司项目就不行了&am…...
2024/4/27 17:14:52 - 无痕翘睫双眼皮管几年
...
2024/4/27 15:14:19 - 无痕翘睫法双眼皮能拆
...
2024/4/27 19:02:45 - angualar 6 + ts 动态 加载 组件 随手记
需求是把网站首页修改成组件动态加载的,由于刚接触ng6 很多概念还不懂,只能是读ng6 的手册,其实代码很简单,但是概念理解不太到问,走了一些弯路,具体解决如下: 场景 根据api返回的json数据&…...
2024/4/27 17:47:18 - Angular HTML template的解析位置
文件: compiler.umd.js path: turbo_modules/angular/compiler9.1.12/bundles: 函数名:TemplateParser.prototype.parse TemplateParser.prototype.parse function(component, template, directives, pipes, schemas, templateUrl, pres…...
2024/5/1 2:58:37
最新文章
- 贪心算法 Greedy Algorithm
1) 贪心例子 称之为贪心算法或贪婪算法,核心思想是 将寻找最优解的问题分为若干个步骤 每一步骤都采用贪心原则,选取当前最优解 因为没有考虑所有可能,局部最优的堆叠不一定让最终解最优 v2已经不会更新v3因为v3更新过了 贪心算法是一种在…...
2024/5/2 21:42:45 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - JRT高效率开发
得益于前期的基础投入,借助代码生成的加持,本来计划用一周实现质控物维护界面,实际用来四小时左右完成质控物维护主体,效率大大超过预期。 JRT从设计之初就是为了证明Spring打包模式不适合软件服务模式,觉得Spring打包…...
2024/5/2 10:47:23 - 贪心算法|376.摆动序列
力扣题目链接 class Solution { public:int wiggleMaxLength(vector<int>& nums) {if (nums.size() < 1) return nums.size();int curDiff 0;int preDiff 0;int result 1;for (int i 0; i < nums.size() - 1; i) {curDiff nums[i 1] - nums[i];if ((pre…...
2024/5/1 13:23:37 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/1 17:30:59 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/2 16:16:39 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/29 2:29:43 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/2 9:28:15 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/27 17:58:04 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/27 14:22:49 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/28 1:28:33 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/30 9:43:09 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/27 17:59:30 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/2 15:04:34 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/28 1:34:08 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/29 20:46:55 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/30 22:21:04 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/1 4:32:01 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/27 23:24:42 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/28 5:48:52 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/30 9:42:22 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/2 9:07:46 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/30 9:42:49 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57