zeppelin on CDH及配置spark查询hive表
2019独角兽企业重金招聘Python工程师标准>>> 
1.下载zeppelin
http://zeppelin.apache.org/download.html
我下载的是796MB的那个已经编译好的,如果需要自己按照环境编译也可以,但是要很长时间编译,这个版本包含了很多插件,我虽然是CDH环境但是这个也可以使用。
2.修改配置文件
cd /zeppelin-0.7.3-bin-all/conf
cp zeppelin-env.sh.template zeppelin-env.sh
cp zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-env.sh
添加配置如下:我的是spark2用不了spark1.6版本这个版本的zeppelin
export HIVE_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hive
export JAVA_HOME=/usr/java/jdk1.8.0_121
export MASTER=yarn-client
export ZEPPELIN_JAVA_OPTS="-Dmaster=yarn-client -Dspark.yarn.jar=/home/zeppelin-0.7.3-bin-all/interpreter/spark/zeppelin-spark_2.11-0.7.3.jar"
export DEFAULT_HADOOP_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hadoop
export SPARK_HOME=/data/parcels/cloudera/parcels/SPARK2/lib/spark2
#export SPARK_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/spark
export HADOOP_HOME=${HADOOP_HOME:-$DEFAULT_HADOOP_HOME}
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
export ZEPPELIN_LOG_DIR=/var/log/zeppelin
export ZEPPELIN_PID_DIR=/var/run/zeppelin
export ZEPPELIN_WAR_TEMPDIR=/var/tmp/zeppelin
3.配置这些其实已经足够了。
在启动
./zeppelin-daemon.sh start
4.在界面上配置就可以使用了hive的配置这个
添加依赖:
这些就可以查询hive了
5.用spark读取hive表这个比直接查询hive表快十倍
我把hive的配置文件hive-site.xml拷贝到hadoop_home/conf
添加需要的依赖
%dep
z.load("org.apache.hive:hive-jdbc:0.14.0")
z.load("org.apache.hadoop:hadoop-common:2.6.0")
z.load("/home/gl/hive-hcatalog-core-1.1.0-cdh5.9.0.jar")
%spark
import java.util.Properties
import org.apache.spark.sql.SparkSession
import org.apache.spark.SparkConf
val sparkConf = new SparkConf().setAppName("hive")
val spark = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val connectionProperties = new Properties()
connectionProperties.put("user", "")
connectionProperties.put("password", "")
connectionProperties.put("driver", "org.apache.hive.jdbc.HiveDriver")
val jdbcDF2 = spark.read
.jdbc("jdbc:hive2://*******:****/test", "bbb", connectionProperties)//.createTempView("bbb")
spark.sql("select count(*) from pc_db.pc_txt group by responseset").show()
6.
.修改登陆zeeplin验证方式
禁止匿名访问
Zeppelin启动默认是匿名(anonymous)模式登录的.如果设置访问登录权限,需要设置conf/zeppelin-site.xml文件下的zeppelin.anonymous.allowed选项为false(默认为true).如果你还没有这个文件,只需将conf/zeppelin-site.xml.template复制为conf/zeppelin-site.xml
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
a)开启Shiro
在刚安装完毕之后,默认情况下,在conf中,将找到shiro.ini.template,该文件是一个配置示例,建议你通过执行如下命令行创建shiro.ini文件:
cp conf/shiro.ini.template conf/shiro.ini
[users]
#admin = password1, admin
#user1 = password2, role1, role2
#user2 = password3, role3
#user3 = password4, role2
hadoop = hadoop, admin # 用户名、密码都是hadoop,角色为admin
bin/zeppelin-daemon.sh restart
2.How to do
首先,我们来了解一下这款工具的背景及用途。Zeppelin 目前已托管于 Apache 基金会,但并未列为顶级项目,可以在其公布的 官网访问。它提供了一个非常友好的 WebUI 界面,操作相关指令。它可以用于做数据分析和可视化。其后面可以接入不同的数据处理引擎。包括 Flink,Spark,Hive 等。支持原生的 Scala,Shell,Markdown 等。
2.1 Install
对于 Zeppelin 而言,并不依赖 Hadoop 集群环境,我们可以部署到单独的节点上进行使用。首先我们使用以下地址获取安装包:
http://zeppelin.incubator.apache.org/download.html
这里,有2种选择,其一,可以下载原文件,自行编译安装。其二,直接下载二进制文件进行安装。这里,为了方便,笔者直接使用二进制文件进行安装使用。这里有些参数需要进行配置,为了保证系统正常启动,确保的 zeppelin.server.port 属性的端口不被占用,默认是8080,其他属性大家可按需配置即可。[配置链接]
2.2 Start/Stop
在完成上述步骤后,启动对应的进程。定位到 Zeppelin 安装目录的bin文件夹下,使用以下命令启动进程:
./zeppelin-daemon.sh start
若需要停止,可以使用以下命令停止进程:
./zeppelin-daemon.sh stop
另外,通过阅读 zeppelin-daemon.sh 脚本的内容,可以发现,我们还可以使用相关重启,查看状态等命令。内容如下:

case "${1}" instart)start;;stop)stop;;reload)stopstart;;restart)stopstart;;status)find_zeppelin_process;;*)echo ${USAGE}
3.How to use
在启动相关进程后,可以使用以下地址在浏览器中访问:
http://<Your_<IP/Host>:Port>
启动之后的界面如下所示:

该界面罗列出插件绑定项。如图中的 spark,md,sh 等。那我如何使用这些来完成一些工作。在使用一些数据引擎时,如 Flink,Spark,Hive 等,是需要配置对应的连接信息的。在 Interpreter 栏处进行配置。这里给大家列举一些配置示例:
3.1 Flink
可以找到 Flink 的配置项,如下图所示:

然后指定对应的 IP 和地址即可。
3.2 Hive
这里 Hive 配置需要指向其 Thrift 服务地址,如下图所示:

另外,其他的插件,如 Spark,Kylin,phoenix等配置类似,配置完成后,记得点击 “restart” 按钮。
3.3 Use md and sh
下面,我们可以创建一个 Notebook 来使用,我们拿最简单的 Shell 和 Markdown 来演示,如下图所示:
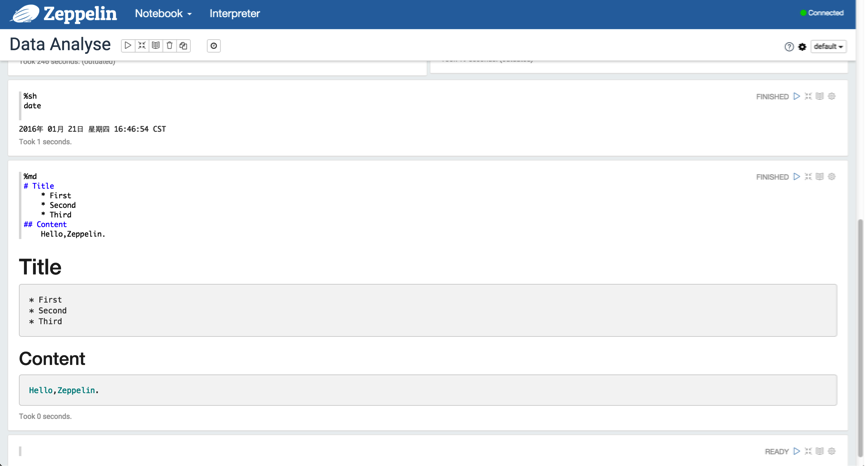
3.4 SQL
当然,我们的目的并不是仅仅使用 Shell 和 Markdown,我们需要能够使用 SQL 来获取我们想要的结果。
3.4.1 Spark SQL
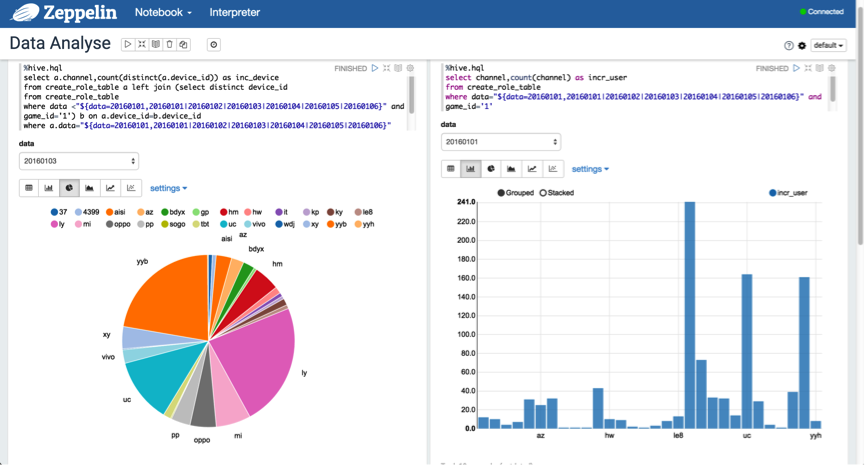
下面,我们使用 Spark SQL 去获取想要的结果。如下图所示:

这里,可以将结果以不同的形式来可视化,量化,趋势,一目了然。
3.4.2 Hive SQL
另外,可以使用动态格式来查询分区数据,以"${partition_col=20160101,20160102|20160103|20160104|20160105|20160106}"的格式进行表示。如下图所示:
3.5 Video Guide
另外,官方也给出了一个快速指导的入门视频,观看地址:[入口]
4.总结
在使用的过程当中,有些地方需要注意,必须在编写 Hive SQL 时,%hql 需要替换为 %hive.sql 的格式;另外,在运行 Scala 代码时,如果出现以下异常,如下图所示:

解决方案,在 zeppelin-env.sh 文件中添加以下内容:
export ZEPPELIN_MEM=-Xmx4g
该 BUG 在 0.5.6 版本得到修复,参考码:[ZEPPELIN-305]
五、Hue、Zeppelin比较
上一节简单介绍了Hue这种Hadoop生态圈的数据可视化组件,本节讨论另一种类似的产品——Zeppelin。首先介绍一下Zeppelin,然后说明其安装的详细步骤,之后演示如何在Zeppelin中添加MySQL翻译器,最后从功能、架构、使用场景几方面将Hue和Zeppelin做一个比较。
1. Zeppelin简介
Zeppelin是一个基于Web的软件,用于交互式地数据分析。一开始是Apache软件基金会的孵化项目,2016年5月正式成为一个顶级项目(Top-Level Project,TLP)。Zeppelin描述自己是一个可以进行数据摄取、数据发现、数据分析、数据可视化的笔记本,用以帮助开发者、数据科学家以及相关用户更有效地处理数据,而不必使用复杂的命令行,也不必关心集群的实现细节。Zeppelin的架构图如下所示。
从图中可以看到,Zeppelin具有客户端/服务器架构,客户端一般就是指浏览器。服务器接收客户端的请求,并将请求通过Thrift协议发送给翻译器组。翻译器组物理表现为JVM进程,负责实际处理客户端的请求并与服务器进行通信。
翻译器是一个插件式的体系结构,允许任何语言/后端数据处理程序以插件的形式添加到Zeppelin中。特别需要指出的是,Zeppelin内建Spark翻译器,因此不需要构建单独的模块、插件或库。Spark翻译器的架构图如下所示。
当前的Zeppelin已经支持很多翻译器,如Zeppelin 0.6.0版本自带的翻译器有alluxio、cassandra、file、hbase、ignite、kylin、md、phoenix、sh、tajo、angular、elasticsearch、flink、hive、jdbc、lens、psql、spark等18种之多。插件式架构允许用户在Zeppelin中使用自己熟悉的特定程序语言或数据处理方式。例如,通过使用%spark翻译器,可以在Zeppelin中使用Scala语言代码。
在数据可视化方面,Zeppelin已经包含一些基本的图表,如柱状图、饼图、线形图、散点图等,任何后端语言的输出都可以被图形化表示。
用户建立的每一个查询叫做一个note,note的URL在多用户间共享,Zeppelin将向所有用户实时广播note的变化。Zeppelin还提供一个只显示查询结果的URL,该页不包括任何菜单和按钮。用这种方式可以方便地将结果页作为一帧嵌入到自己的web站点中。
2. Zeppelin安装配置
下面用一个典型的使用场景——使用Zeppelin运行SparkSQL访问Hive表,在一个实验环境上说明Zeppelin的安装配置步骤。
(1)安装环境
12个节点的Spark集群,以standalone方式部署,各个节点运行的进程如下表所示。
主机名
运行进程
nbidc-agent-03
NameNode、Spark Master
nbidc-agent-04
SecondaryNameNode
nbidc-agent-11
ResourceManager、DataNode、NodeManager、Spark Worker
nbidc-agent-12
DataNode、NodeManager、Spark Worker
nbidc-agent-13
DataNode、NodeManager、Spark Worker
nbidc-agent-14
DataNode、NodeManager、Spark Worker
nbidc-agent-15
DataNode、NodeManager、Spark Worker
nbidc-agent-18
DataNode、NodeManager、Spark Worker
nbidc-agent-19
DataNode、NodeManager、Spark Worker
nbidc-agent-20
DataNode、NodeManager、Spark Worker
nbidc-agent-21
DataNode、NodeManager、Spark Worker
nbidc-agent-22
DataNode、NodeManager、Spark Worker
操作系统:CentOS release 6.4
Hadoop版本:2.7.0
Hive版本:2.0.0
Spark版本:1.6.0
(2)在nbidc-agent-04上安装部署Zeppelin及其相关组件
前提:nbidc-agent-04需要能够连接互联网。
安装Git:在nbidc-agent-04上执行下面的指令。
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
yum install gcc perl-ExtUtils-MakeMaker
yum remove git
cd /home/work/tools/
wget https://github.com/git/git/archive/v2.8.1.tar.gz
tar -zxvf git-2.8.1.tar.gz
cd git-2.8.1.tar.gz
make prefix=/home/work/tools/git all
make prefix=/home/work/tools/git install
安装Java:在nbidc-agent-03机器上执行下面的指令拷贝Java安装目录到nbidc-agent-04机器上。
scp -r jdk1.7.0_75 nbidc-agent-04:/home/work/tools/
安装Apache Maven:在agent-04上执行下面的指令。
cd /home/work/tools/
wget ftp://mirror.reverse.net/pub/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
tar -zxvf apache-maven-3.3.9-bin.tar.gz
安装Hadoop客户端:在nbidc-agent-03机器上执行下面的指令拷贝Hadoop安装目录到nbidc-agent-04机器上。
scp -r hadoop nbidc-agent-04:/home/work/tools/
安装Spark客户端:在nbidc-agent-03机器上执行下面的指令拷贝Spark安装目录到nbidc-agent-04机器上。
scp -r spark nbidc-agent-04:/home/work/tools/
安装Hive客户端:在nbidc-agent-03机器上执行下面的指令拷贝Hive安装目录到nbidc-agent-04机器上。
scp -r hive nbidc-agent-04:/home/work/tools/
安装phantomjs:在nbidc-agent-04上执行下面的指令。
cd /home/work/tools/
tar -jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
下载最新的zeppelin源码:在nbidc-agent-04上执行下面的指令。
cd /home/work/tools/
git clone https://github.com/apache/incubator-zeppelin.git
设置环境变量:在nbidc-agent-04上编辑/home/work/.bashrc文件,内容如下。
vi /home/work/.bashrc
# 添加下面的内容
export PATH=.:$PATH:/home/work/tools/jdk1.7.0_75/bin:/home/work/tools/hadoop/bin:/home/work/tools/spark/bin:/home/work/tools/hive/bin:/home/work/tools/phantomjs-2.1.1-linux-x86_64/bin:/home/work/tools/incubator-zeppelin/bin;
export JAVA_HOME=/home/work/tools/jdk1.7.0_75
export HADOOP_HOME=/home/work/tools/hadoop
export SPARK_HOME=/home/work/tools/spark
export HIVE_HOME=/home/work/tools/hive
export ZEPPELIN_HOME=/home/work/tools/incubator-zeppelin
# 保存文件,并是设置生效
source /home/work/.bashrc
编译zeppelin源码:在nbidc-agent-04上执行下面的指令。
cd /home/work/tools/incubator-zeppelin
mvn clean package -Pspark-1.6 -Dspark.version=1.6.0 -Dhadoop.version=2.7.0 -Phadoop-2.6 -Pyarn -DskipTests
(3)配置zeppelin
配置zeppelin-env.sh文件:在nbidc-agent-04上执行下面的指令。
cp /home/work/tools/incubator-zeppelin/conf/zeppelin-env.sh.template /home/work/tools/incubator-zeppelin/conf/zeppelin-env.sh
vi /home/work/tools/incubator-zeppelin/conf/zeppelin-env.sh
# 添加下面的内容
export JAVA_HOME=/home/work/tools/jdk1.7.0_75
export HADOOP_CONF_DIR=/home/work/tools/hadoop/etc/hadoop
export MASTER=spark://nbidc-agent-03:7077
配置zeppelin-site.xml文件:在nbidc-agent-04上执行下面的指令。
cp /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml.template /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml
vi /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml
# 修改下面这段的value值,设置zeppelin的端口为9090
<property>
<name>zeppelin.server.port</name>
<value>9090</value>
<description>Server port.</description>
</property>
将hive-site.xml拷贝到zeppelin的配置目录下:在nbidc-agent-04上执行下面的指令。
cd /home/work/tools/incubator-zeppelin
cp /home/work/tools/hive/conf/hive-site.xml .
(4)启动zeppelin
在nbidc-agent-04上执行下面的指令。
zeppelin-daemon.sh start
(5)测试
从浏览器输入http://nbidc-agent-04:9090/,如下图所示。
点击‘Interpreter’菜单,配置并保存spark解释器,如下图所示。
配置并保存hive解释器,如下图所示。
点击‘NoteBook’->‘Create new note’子菜单项,建立一个新的查询并执行,结果如下图所示。
说明:这是一个动态表单SQL,SparkSQL语句为:
%sql
select * from wxy.t1 where rate > ${r}
第一行指定解释器为SparkSQL,第二行用${r}指定一个运行时参数,执行时页面上会出现一个文本编辑框,输入参数后回车,查询会按照指定参数进行,如图会查询rate > 100的记录。
3. 在Zeppelin中添加MySQL翻译器
数据可视化的需求很普遍,如果常用的如MySQL这样的关系数据库也能使用Zeppelin查询,并将结果图形化显示,那么就可以用一套统一的数据可视化方案处理大多数常用查询。Zeppelin本身还不带MySQL翻译器,幸运的是已经有MySQL翻译器插件了。下面说明该插件的安装步骤及简单测试。
(1)编译MySQL Interpreter源代码
cd /home/work/tools/
git clone https://github.com/jiekechoo/zeppelin-interpreter-mysql
mvn clean package
(2)部署二进制包
mkdir /home/work/tools/incubator-zeppelin/interpreter/mysql
cp /home/work/tools/zeppelin-interpreter-mysql/target/zeppelin-mysql-0.5.0-incubating.jar /home/work/tools/incubator-zeppelin/interpreter/mysql/
# copy dependencies to mysql directory
cp commons-exec-1.1.jar mysql-connector-java-5.1.6.jar slf4j-log4j12-1.7.10.jar log4j-1.2.17.jar slf4j-api-1.7.10.jar /home/work/tools/incubator-zeppelin/interpreter/mysql/
vi /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml
在zeppelin.interpreters 的value里增加一些内容“,org.apache.zeppelin.mysql.MysqlInterpreter”,如下图所示。
(3)重启Zeppelin
zeppelin-daemon.sh restart
(4)加载MySQL Interpreter
打开主页http://nbidc-agent-04:9090/,‘Interpreter’ -> ‘Create’,完成类似下图的页面,完成点击‘Save’
(5)测试
创建名为mysql_test的note,如下图所示。
输入下面的查询语句,按创建日期统计建立表的个数。
%mysql
select date_format(create_time,'%Y-%m-%d') d, count(*) c
from information_schema.tables
group by date_format(create_time,'%Y-%m-%d')
5. Hue与Zeppelin比较
(1)功能
Zeppelin和Hue都能提供一定的数据可视化的功能,都提供了多种图形化数据表示形式。单从这点来说,个人认为功能类似,大同小异,Hue可以通过经纬度进行地图定位,这个功能我在Zeppelin 0.6.0上没有找到。
Zeppelin支持的后端数据查询程序较多,0.6.0版本缺省有18种,原生支持Spark。而Hue的3.9.0版本缺省只支持Hive、Impala、Pig和数据库查询。
Zeppelin只提供了单一的数据处理功能,包括前面提到的数据摄取、数据发现、数据分析、数据可视化等都属于数据处理的范畴。而Hue的功能相对丰富的多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。
(2)架构
Zeppelin采用插件式的翻译器,通过插件开发,可以添加任何后端语言和数据处理程序。相对来说更独立和开放。
Hue与Hadoop生态圈的其它组件密切相关,一般都与CDH一同部署。
(3)使用场景
Zeppelin适合单一数据处理、但后端处理语言繁多的场景,尤其适合Spark。
Hue适合与Hadoop集群的多个组件交互、如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。
---------------------
前提:服务器已经安装好了hadoop_client端即hadoop的环境hbase,hive等相关组件
1.环境和变量配置
①拷贝hive的配置文件hive-site.xml到zeppelin-0.7.2-bin-all/conf下
# cp /root/hadoop-2.6.0/conf/hive-site.xml /data/hadoop/zeppelin/zeppelin-0.7.2-bin-all/conf
②进入conf下进行环境变量的配置
# cd /data/hadoop/zeppelin/zeppelin-0.7.2-bin-all/conf
vim zeppelin-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
export HADOOP_CONF_DIR=/root/hadoop-2.6.0/conf
2.在web界面配置集成hive
访问zeppelin的web界面(http://ip:8080)
右上角anonymous --> interpreter --> +Create新建一个叫做hive的集成环境(也可以在jdbc的基础上修改,不用新建)
编辑hive的相关属性,hive相关的配置可以到hive-site.xml中查看
Properties value
common.max_count 1000
hive.driver org.apache.hive.jdbc.HiveDriver
hive.password hive
hive.url jdbc:hive2://uhadoop-bwgkeu-master2:10000 # 注意是hive2不是hive
hive.user hive
zeppelin.interpreter.localRepo /data/hadoop/zeppelin/zeppelin-0.7.2-bin-all/local-repo/2CNPYUV7Z
zeppelin.interpreter.output.limit 102400
zeppelin.jdbc.auth.type
zeppelin.jdbc.concurrent.max_connection 10
zeppelin.jdbc.concurrent.use true
zeppelin.jdbc.keytab.location
zeppelin.jdbc.principal
填写Dependencies相关属性
2个hive依赖包,一个mysql依赖包,不用mysql可以不用写mysql jdbc包
填好后点保存,这个时候zeppelin会出现卡顿,这是因为上面填的2个Dependencies,zeppelin去指定maven库下载相关依赖包去了,等待时间可能需几分钟。
下载完成可在local-repo目录下查看,依赖包放在local-repo/2CNPYUV7Z/(可能不同)目录下,等完全下载完成,就可查询。
Dependencies
artifact exclude
org.apache.hive:hive-jdbc:0.14.0
org.apache.hadoop:hadoop-common:2.6.0
mysql:mysql-connector-java:5.1.38
---------------------
概述
Apache Spark是一种快速和通用的集群计算系统。它提供Java,Scala,Python和R中的高级API,以及支持一般执行图的优化引擎。Zeppelin支持Apache Spark,Spark解释器组由5个解释器组成。
名称
类
描述
%spark SparkInterpreter 创建一个SparkContext并提供Scala环境
%spark.pyspark PySparkInterpreter 提供Python环境
%spark.r SparkRInterpreter 提供具有SparkR支持的R环境
%spark.sql SparkSQLInterpreter 提供SQL环境
%spark.dep DepInterpreter 依赖加载器
配置
Spark解释器可以配置为由Zeppelin提供的属性。您还可以设置表中未列出的其他Spark属性。有关其他属性的列表,请参阅Spark可用属性。
属性
默认
描述
ARGS Spark命令行参考
master local[*] Spark master uri.
例如:spark://masterhost:7077
spark.app.name Zeppelin Spark应用的名称。
spark.cores.max 要使用的核心总数。
空值使用所有可用的核心。
spark.executor.memory 1g 每个worker实例的执行程序内存。
ex)512m,32g
zeppelin.dep.additionalRemoteRepository spark-packages,
http://dl.bintray.com/spark-packages/maven,
false; id,remote-repository-URL,is-snapshot;
每个远程存储库的列表。
zeppelin.dep.localrepo local-repo 依赖加载器的本地存储库
zeppelin.pyspark.python python Python命令来运行pyspark
zeppelin.spark.concurrentSQL python 如果设置为true,则同时执行多个SQL。
zeppelin.spark.maxResult 1000 要显示的Spark SQL结果的最大数量。
zeppelin.spark.printREPLOutput true 打印REPL输出
zeppelin.spark.useHiveContext true 如果它是真的,使用HiveContext而不是SQLContext。
zeppelin.spark.importImplicit true 导入含义,UDF集合和sql如果设置为true。
没有任何配置,Spark解释器在本地模式下开箱即用。但是,如果要连接到Spark群集,则需要按照以下两个简单步骤进行操作。
1.导出SPARK_HOME
在conf/zeppelin-env.sh,导出SPARK_HOME环境变量与您的Spark安装路径。
例如,
export SPARK_HOME=/usr/lib/spark
您可以选择设置更多的环境变量
# set hadoop conf dir
export HADOOP_CONF_DIR=/usr/lib/hadoop
# set options to pass spark-submit command
export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0"
# extra classpath. e.g. set classpath for hive-site.xml
export ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf
对于Windows,确保你winutils.exe在%HADOOP_HOME%\bin。有关详细信息,请参阅在Windows上运行Hadoop的问题。
2.在“解释器”菜单中设置主机
启动Zeppelin后,转到解释器菜单并在Spark解释器设置中编辑主属性。该值可能因您的Spark群集部署类型而异。
例如,
local[*] 本地模式
spark://master:7077 standalone 集群模式
yarn-client Yarn 客户端模式
mesos://host:5050 Mesos 集群模式
而已。Zeppelin将使用任何版本的Spark和任何部署类型,而不用这种方式重建Zeppelin。有关Spark&Zeppelin版本兼容性的更多信息,请参阅Zeppelin下载页面中的“可用的口译员”部分。
请注意,不导出SPARK_HOME,它以本地模式运行,包含版本的Spark。附带的版本可能因构建配置文件而异。
SparkContext,SQLContext,SparkSession,ZeppelinContext
SparkContext,SQLContext和ZeppelinContext会自动创建并显示为变量名sc,sqlContext并z分别在Scala,Python和R环境中公开。从0.6.1起,spark当您使用Spark 2.x时,SparkSession可以作为变量使用。
请注意,Scala / Python / R环境共享相同的SparkContext,SQLContext和ZeppelinContext实例。
依赖管理
在Spark解释器中加载外部库有两种方法。首先是使用解释器设置菜单,其次是加载Spark属性。
1.通过解释器设置设置依赖关系
有关详细信息,请参阅解释器依赖管理。
2.加载Spark属性
一旦SPARK_HOME被设置conf/zeppelin-env.sh,Zeppelin使用spark-submit作为Spark解释赛跑者。spark-submit支持两种方式来加载配置。第一个是命令行选项,如--master和飞艇可以通过这些选项spark-submit通过导出SPARK_SUBMIT_OPTIONS在conf/zeppelin-env.sh。二是从中读取配置选项SPARK_HOME/conf/spark-defaults.conf。用户可以设置分发库的Spark属性有:
火花defaults.conf
SPARK_SUBMIT_OPTIONS
描述
spark.jars --jars 包含在驱动程序和执行器类路径上的本地jar的逗号分隔列表。
spark.jars.packages --packages
逗号分隔列表,用于包含在驱动程序和执行器类路径上的jar的maven坐标。
将搜索当地的maven repo,然后搜索maven中心和由–repositories提供的任何其他远程存储库。
坐标的格式应该是groupId:artifactId:version。
spark.files --files 要放置在每个执行器的工作目录中的逗号分隔的文件列表。
以下是几个例子:
SPARK_SUBMIT_OPTIONS 在 conf/zeppelin-env.sh
export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0 --jars /path/mylib1.jar,/path/mylib2.jar --files /path/mylib1.py,/path/mylib2.zip,/path/mylib3.egg"
SPARK_HOME/conf/spark-defaults.conf
spark.jars /path/mylib1.jar,/path/mylib2.jar
spark.jars.packages com.databricks:spark-csv_2.10:1.2.0
spark.files /path/mylib1.py,/path/mylib2.egg,/path/mylib3.zip
3.通过%spark.dep解释器加载动态依赖关系
注:%spark.dep解释负载库%spark和%spark.pyspark而不是 %spark.sql翻译。所以我们建议你改用第一个选项。
当你的代码需要外部库,而不是下载/复制/重新启动Zeppelin,你可以使用%spark.dep解释器轻松地完成以下工作。
从maven库递归加载库
从本地文件系统加载库
添加额外的maven仓库
自动将库添加到SparkCluster(可以关闭)
解释器利用Scala环境。所以你可以在这里编写任何Scala代码。需要注意的是%spark.dep解释前应使用%spark,%spark.pyspark,%spark.sql。
这是用法
%spark.dep
z.reset() // clean up previously added artifact and repository
// add maven repository
z.addRepo("RepoName").url("RepoURL")
// add maven snapshot repository
z.addRepo("RepoName").url("RepoURL").snapshot()
// add credentials for private maven repository
z.addRepo("RepoName").url("RepoURL").username("username").password("password")
// add artifact from filesystem
z.load("/path/to.jar")
// add artifact from maven repository, with no dependency
z.load("groupId:artifactId:version").excludeAll()
// add artifact recursively
z.load("groupId:artifactId:version")
// add artifact recursively except comma separated GroupID:ArtifactId list
z.load("groupId:artifactId:version").exclude("groupId:artifactId,groupId:artifactId, ...")
// exclude with pattern
z.load("groupId:artifactId:version").exclude(*)
z.load("groupId:artifactId:version").exclude("groupId:artifactId:*")
z.load("groupId:artifactId:version").exclude("groupId:*")
// local() skips adding artifact to spark clusters (skipping sc.addJar())
z.load("groupId:artifactId:version").local()
ZeppelinContext
Zeppelin 在Scala / Python环境中自动注入ZeppelinContext变量z。ZeppelinContext提供了一些额外的功能和实用程序。
对象交换
ZeppelinContext扩展地图,它在Scala和Python环境之间共享。所以你可以把Scala的一些对象从Python中读出来,反之亦然。
Scala
// Put object from scala
%spark
val myObject = ...
z.put("objName", myObject)
// Exchanging data frames
myScalaDataFrame = ...
z.put("myScalaDataFrame", myScalaDataFrame)
val myPythonDataFrame = z.get("myPythonDataFrame").asInstanceOf[DataFrame]
Python 展开原码
表格创作
ZeppelinContext提供了创建表单的功能。在Scala和Python环境中,您可以以编程方式创建表单。
Scala
%spark
/* Create text input form */
z.input("formName")
/* Create text input form with default value */
z.input("formName", "defaultValue")
/* Create select form */
z.select("formName", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))
/* Create select form with default value*/
z.select("formName", "option1", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))
%spark.pyspark
# Create text input form
z.input("formName")
# Create text input form with default value
z.input("formName", "defaultValue")
# Create select form
z.select("formName", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")])
# Create select form with default value
z.select("formName", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")], "option1")
在sql环境中,可以在简单的模板中创建表单。
%spark.sql
select * from ${table=defaultTableName} where text like '%${search}%'
要了解有关动态表单的更多信息,请检查Zeppelin 动态表单。
Matplotlib集成(pyspark)
这两个python和pyspark解释器都内置了对内联可视化的支持matplotlib,这是一个流行的python绘图库。更多细节可以在python解释器文档中找到,因为matplotlib的支持是相同的。通过利用齐柏林内置的角度显示系统,可以通过pyspark进行更先进的交互式绘图,如下所示:
解释器设置选项
您可以选择其中之一shared,scoped以及isolated配置Spark解释器的选项。Spark解释器为每个笔记本创建分离的Scala编译器,但在scoped模式(实验)中共享一个SparkContext。它在每个笔记本isolated模式下创建分离的SparkContext 。
用Kerberos设置Zeppelin
使用Zeppelin,Kerberos Key Distribution Center(KDC)和Spark on YARN进行逻辑设置:
配置设置
在安装Zeppelin的服务器上,安装Kerberos客户端模块和配置,krb5.conf。这是为了使服务器与KDC进行通信。
设置SPARK_HOME在[ZEPPELIN_HOME]/conf/zeppelin-env.sh使用火花提交(此外,您可能需要设置export HADOOP_CONF_DIR=/etc/hadoop/conf)
将以下两个属性添加到Spark configuration([SPARK_HOME]/conf/spark-defaults.conf)中:
spark.yarn.principal
spark.yarn.keytab
注意:如果您没有访问以上spark-defaults.conf文件的权限,可以选择地,您可以通过Zeppelin UI中的“解释器”选项卡将上述行添加到“Spark Interpreter”设置。
而已。玩Zeppelin!
---------------------
本文基于centos6.4、CDH版本5.7.6、spark版本为1.6.0
1.环境准备
git1.7.1、maven3.3.9、JDK1.8
1
2.下载最新版zeepline源码
wget http://mirror.bit.edu.cn/apache/zeppelin/zeppelin-0.7.3/zeppelin-0.7.3.tgz
tar -zxvf zeppelin-0.7.3.tgz
cd zeeplin-0.7.3
1
2
3
3.编译
mvn -X clean package -Pspark-1.6 -Dhadoop.version=2.6.0-cdh5.7.6 -Phadoop-2.6 -Pyarn -Ppyspark -Psparkr -Pvendor-repo -DskipTests -Pbuild-distr
[INFO] Zeppelin ........................................... SUCCESS [ 8.360 s]
[INFO] Zeppelin: Interpreter .............................. SUCCESS [ 5.909 s]
[INFO] Zeppelin: Zengine .................................. SUCCESS [ 22.396 s]
[INFO] Zeppelin: Display system apis ...................... SUCCESS [ 10.373 s]
[INFO] Zeppelin: Spark dependencies ....................... SUCCESS [ 32.613 s]
[INFO] Zeppelin: Spark .................................... SUCCESS [ 18.004 s]
[INFO] Zeppelin: Markdown interpreter ..................... SUCCESS [ 0.734 s]
[INFO] Zeppelin: Angular interpreter ...................... SUCCESS [ 0.259 s]
[INFO] Zeppelin: Shell interpreter ........................ SUCCESS [ 0.374 s]
[INFO] Zeppelin: Livy interpreter ......................... SUCCESS [02:06 min]
[INFO] Zeppelin: HBase interpreter ........................ SUCCESS [ 2.358 s]
[INFO] Zeppelin: Apache Pig Interpreter ................... SUCCESS [ 2.589 s]
[INFO] Zeppelin: PostgreSQL interpreter ................... SUCCESS [ 0.371 s]
[INFO] Zeppelin: JDBC interpreter ......................... SUCCESS [ 0.682 s]
[INFO] Zeppelin: File System Interpreters ................. SUCCESS [ 0.650 s]
[INFO] Zeppelin: Flink .................................... SUCCESS [ 4.925 s]
[INFO] Zeppelin: Apache Ignite interpreter ................ SUCCESS [ 21.882 s]
[INFO] Zeppelin: Kylin interpreter ........................ SUCCESS [ 0.298 s]
[INFO] Zeppelin: Python interpreter ....................... SUCCESS [01:29 min]
[INFO] Zeppelin: Lens interpreter ......................... SUCCESS [ 1.920 s]
[INFO] Zeppelin: Apache Cassandra interpreter ............. SUCCESS [ 35.499 s]
[INFO] Zeppelin: Elasticsearch interpreter ................ SUCCESS [ 5.039 s]
[INFO] Zeppelin: BigQuery interpreter ..................... SUCCESS [ 2.585 s]
[INFO] Zeppelin: Alluxio interpreter ...................... SUCCESS [ 1.680 s]
[INFO] Zeppelin: Scio ..................................... SUCCESS [ 29.029 s]
[INFO] Zeppelin: web Application .......................... SUCCESS [07:18 min]
[INFO] Zeppelin: Server ................................... SUCCESS [ 46.044 s]
[INFO] Zeppelin: Packaging distribution ................... SUCCESS [ 52.455 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 16:00 min
[INFO] Finished at: 2018-03-25T12:10:07+08:00
[INFO] Final Memory: 332M/5705M
[INFO] ------------------------------------------------------------------------
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
具体参数请参考:http://zeppelin.apache.org/docs/0.7.3/install/build.html
4.部署Zeppelin
tar -zxvf ~/zeppelin-0.7.3/zeppelin-distribution/target/zeppelin-0.7.3.tar.gz -C /opt/bigdata/
ln -s /opt/bigdata/zeppelin-0.7.3 /opt/bigdata/zeppelin
bin/zeppelin-daemon.sh start
1
2
3
访问地址:http://localhost:8080,也可修改zeppelin-site.xml默认端口
5.配置访问hive仓库
通过jdbc方式访问hive,首先确保启动hiveserver2.
1.拷贝hive相关驱动到zeppelin
cp ~/hive/lib/hive-exec-1.1.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
cp ~/hive/lib/hive-jdbc-1.1.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
cp ~/hive/lib/hive-metastore-1.1.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
cp ~/hive/lib/hive-serde-1.1.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
cp ~/hive/lib/hive-service-1.1.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
cp ~/hadoop/lib/hadoop-common-2.6.0-cdh5.7.6.jar /opt/zepplin/interpreter/jdbc/
1
2
3
4
5
6
2.重启zepplin
bin/zeppelin-daemon.sh restart
1
3.修改页面Interpreters jdbc配置
点击restart按钮
4.查询验证
6.配置集成spark on yarn
zepplin目前支持,local、yarn-client、standalone和mesos等模式,默认为local模式
1.修改zeppelin-env.sh
cp zeppelin-env.sh.template zeppelin-env.sh
export MASTER=yarn-client
export HADOOP_CONF_DIR=[your_hadoop_conf_path]
export SPARK_HOME=[your_spark_home_path]
export SPARK_SUBMIT_OPTIONS="--conf spark.dynamicAllocation.minExecutors=10 --executor-memory 2G --driver-memory 2g --executor-cores 2"
1
2
3
4
5
*重启zepplin,打开UI.设置spark参数,restart
验证spark,出错
发现是zepplin/lib下面的有hadoop的commonjar包里面没有这个方法,本身已经配置CDH环境了,所以删除所有hadoopjar(很奇怪,之前编译的是CDH版本的)
查看hdfs文件,报错
jackson版本冲突导致,zepplin中的版本为2.5.3,spark1.6使用的为2.4,更换zepplin/lib下jackson-databind的版本重启即可。
wget http://central.maven.org/maven2/com/fasterxml/jackson/core/jackson-databind/2.4.4/jackson-databind-2.4.4.jar
1
7.用户权限配置
zeppelin主要利用Apache Shiro做用户权限管理。
1.关闭匿名访问,拷贝zeppelin-site.xml,设置zeppelin.anonymous.allowed=false
conf/zeppelin-site.xml.template to conf/zeppelin-site.xml
1
2.启用shiro,拷贝shiro文件
cp conf/shiro.ini.template conf/shiro.ini
1
shiro提供了基于users/roles/urls的权限控制,也有提供基于目录服务做用户权限,本问主要介绍基于用户角色权限的方式。
[users]
admin = admin, admin
zhangsan=123456,readonly
[roles]
readonly= *
admin = *
[urls]
/api/interpreter/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/api/credential/** = authc, roles[admin]
/** = authc
3.设置zeppelin已当前登录用户访问hive,不设置的话是已启动zeppelin进程的用户访问。
参考官方文档:https://zeppelin.apache.org/docs/0.7.3/manual/userimpersonation.html
有两种方式设置:
给每个用户做免密登录
设置ZEPPELIN_IMPERSONATE_CMD,这里采用ZEPPELIN_IMPERSONATE_CMD,vim zeppelin-env.sh
“`
export ZEPPELIN_IMPERSONATE_CMD=’sudo -H -u ${ZEPPELIN_IMPERSONATE_USER} bash -c ’
export ZEPPELIN_IMPERSONATE_SPARK_PROXY_USER=false
“`
3. 重启zeppelin server.
4. 管理员账号登录UI,设置spark interceptor的Impersonate,参考sh interceptor设置
5. 创建hive表验证,查看hdfs目录用户权限
4设置node book权限,每个用户可以设置自己notebook权限
文本框带suggest功能,输入用户简称可以自动提示
最后,有一篇zeppelin的中文翻译,虽然翻译的不怎么样,推荐给需要的朋友
http://cwiki.apachecn.org/pages/viewpage.action?pageId=10030467
7.使用期间出现的bug有:
1.执行任务无法显示任务执行进度。
WARN [2018-04-24 16:04:56,238] ({qtp745160567-15917} ServletHandler.java[doHandle]:620) -
javax.servlet.ServletException: Filtered request failed.
at org.apache.shiro.web.servlet.AbstractShiroFilter.doFilterInternal(AbstractShiroFilter.java:384)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1652)
at org.apache.zeppelin.server.CorsFilter.doFilter(CorsFilter.java:72)
at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1652)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:585)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:143)
at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:577)
at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:223)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1127)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:515)
at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:185)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1061)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:215)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:97)
at org.eclipse.jetty.server.Server.handle(Server.java:499)
at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:311)
at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:257)
at org.eclipse.jetty.io.AbstractConnection$2.run(AbstractConnection.java:544)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:635)
at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:555)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.AbstractMethodError: javax.ws.rs.core.Response.getStatusInfo()Ljavax/ws/rs/core/Response$StatusType;
at javax.ws.rs.WebApplicationException.validate(WebApplicationException.java:186)
at javax.ws.rs.ClientErrorException.<init>(ClientErrorException.java:88)
at org.apache.cxf.jaxrs.utils.JAXRSUtils.findTargetMethod(JAXRSUtils.java:503)
at org.apache.cxf.jaxrs.interceptor.JAXRSInInterceptor.processRequest(JAXRSInInterceptor.java:198)
at org.apache.cxf.jaxrs.interceptor.JAXRSInInterceptor.handleMessage(JAXRSInInterceptor.java:90)
at org.apache.cxf.phase.PhaseInterceptorChain.doIntercept(PhaseInterceptorChain.java:272)
at org.apache.cxf.transport.ChainInitiationObserver.onMessage(ChainInitiationObserver.java:121)
at org.apache.cxf.transport.http.AbstractHTTPDestination.invoke(AbstractHTTPDestination.java:239)
at org.apache.cxf.transport.servlet.ServletController.invokeDestination(ServletController.java:248)
at org.apache.cxf.transport.servlet.ServletController.invoke(ServletController.java:222)
at org.apache.cxf.transport.servlet.ServletController.invoke(ServletController.java:153)
at org.apache.cxf.transport.servlet.CXFNonSpringServlet.invoke(CXFNonSpringServlet.java:167)
at org.apache.cxf.transport.servlet.AbstractHTTPServlet.handleRequest(AbstractHTTPServlet.java:286)
at org.apache.cxf.transport.servlet.AbstractHTTPServlet.doGet(AbstractHTTPServlet.java:211)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at org.apache.cxf.transport.servlet.AbstractHTTPServlet.service(AbstractHTTPServlet.java:262)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:812)
at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1669)
解决方案:
javax.ws.rs.core.Response.getStatusInfo(),是JAX-RS 2里面的功能,cxf使用是JAX-RX 1,替换cxf相关依赖。
zeppelin 0.8.0好像已经解决。https://issues.apache.org/jira/browse/ZEPPELIN-903
---------------------
一.需求
在使用spark-streaming 处理流式任务时,由于spark-shell需要登录到和生产集群相连的机器开启,使用起来也有诸多不便,且默认不支持kafka等源,所以萌生使用zeppelin 中的spark interpreter来完成streaming 任务.
二.尝试
在网上找到了一个改版的zeppelin版wordcount例子.
第一步启动nc 监听端口7777
第二步在zeppelin spark interpreter 中启动streming任务
%spark
sc.version
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Duration
import org.apache.spark.streaming.Seconds
case class Message(createdAt:Long, text:String)
val ssc = new StreamingContext(sc, Seconds(10))
val lines = ssc.socketTextStream("10.104.90.40", 7777)
val errorLines = lines.window(Seconds(10))
val message = errorLines.map(status=>
Message(System.currentTimeMillis()/1000, status)
).foreachRDD(rdd=>
if (rdd.isEmpty()==false) {
rdd.toDF().registerTempTable("message")}
)
errorLines.print
ssc.start()
第三步在nc中输入一些测试数据,在zeppelin spark interpreter读取streaming处理的结果
%spark
val data = sqlContext.sql("select * from message")
data.show()
得到类似如下的输出
data: org.apache.spark.sql.DataFrame = [createdAt: bigint, text: string]
+----------+----+
| createdAt|text|
+----------+----+
|1493709315| asd|
|1493709321| as|
|1493709321| d|
|1493709321| asd|
|1493709315| as|
|1493709315| d|
|1493709321| asd|
|1493709321| as|
|1493709321| das|
|1493709315| d|
|1493709321| as|
|1493709315| d|
|1493709315| 1q2|
|1493709321| 3|
|1493709321| 12|
|1493709321| 312|
|1493709315| |
|1493709321| 3|
|1493709315| 123|
|1493709321| qw|
+----------+----+
only showing top 20 rows
三.问题
尝试的过程中发现了如下问题:
1.停止streaming context的方式不正确
如果使用ssc.stop()停止spark streaming context 会导致zeppelin 服务端的spark context也一并停止,导致出现如下的错误,并且在web ui重启spark interpreter也不解决问题,最后只能重启整个zeppelin 服务.
java.lang.IllegalStateException: RpcEnv has been stopped
在zeppelin中停止streaming context的正确方式为
ssc.stop(stopSparkContext=false, stopGracefully=true)
2.nc server同一时间只能服务一个client
刚开始尝试nc用法时,先使用nc -lk 7777启动server端,再使用nc locahost 7777启动client,尝试互相传送信息成功,在zeppelin 中streaming任务却总是读不到任何数据
原因就在于nv server只能同时服务一个client端.
在多个client 端同时链接server 端时,按建立链接的先后会出现只有一个client端口能接收数据的情况.
如果zeppelin中的streaming任务作为client端接收到了server端的消息,即使按照1中的方法停止了streaming context,别的client端也依然接受不到消息,推测可能是server端服务对象仍然为streaming 任务.
3.ERROR [2017-05-02 11:31:12,686] ({dispatcher-event-loop-2} Logging.scala[logError]:70) - Deregistered receiver for stream 0: Restarting receiver with delay 2000ms: Error connecting to loc
alhost:7777 - java.net.ConnectException: Connection refuse
开始时使用localhost 作为socketTextStream中的host地址,却总是会出现上面的错误,但是使用telnet >open localhost 7777却可以成功建立链接
把localhost 改成10.104.90.40 则不会再出现上述错误,推测原因在于zepplin 使用的spark interpreter设置运行在了cluster mode,在除10.104.90.40 以为的机器上并没有nc 运行,7777端口也是不通的,所以会出现访问拒绝.
4.Attempted to use BlockRDD[36063] at socketTextStream at <console>:217 after its blocks have been removed!
当使用val data = sqlContext.sql("select * from message")查看streaming 处理结果时,查询后一段时间(几s)后再次运行查询任务就会出现如上错误.
在zeppelin spark interpreter日志中发现每个窗口执行完之后都与类似如下的日志
Removing RDD 37697 from persistence list
从这篇文章中的代码分析可见出错原因在于blockrdd 已经被删了导致,结合spark streaming dag任务结束后会删除数据可知
这个报错的原因在于message这张由registerTempTable 产生的表实际的存储rdd已经被删除导致.
5.hive接入问题,不解
INFO [2017-04-28 22:15:10,455] ({pool-2-thread-2} HiveMetaStoreClient.java[open]:376) - Trying to connect to metastore with URI thrift://10.104.90.40:9083
WARN [2017-04-28 22:15:10,456] ({pool-2-thread-2} UserGroupInformation.java[getGroupNames]:1492) - No groups available for user heyang.wang
WARN [2017-04-28 22:15:10,462] ({pool-2-thread-2} HiveMetaStoreClient.java[open]:444) - set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it.
5.1假期前一度出现的问题,只要对rdd进行相关action类操作如rdd.toDf,rdd.collect等就会触发,但是当时hive cli和beeline都可以正常访问hive,hive metastore 日志中也没有报错信息.
但是5.1假期或却又没问题了.
四.尝试在livy中运行spark-streaming任务
经过测试,在livy中可以以同样的方式使用spark streaming,只需要改%spark为%livy.spark
五.接入kafka数据源(未完)
参考来源:
https://www.zeppelinhub.com/viewer/notebooks/aHR0cHM6Ly9yYXcuZ2l0aHVidXNlcmNvbnRlbnQuY29tL2hhZml6dXItcmFobWFuL2NjcC1jaGFsbGVuZ2UxL21hc3Rlci96ZXBwZWxpbi9ub3RlYm9vay8yQVdLWFhKTVgvbm90ZS5qc29u
http://apache-spark-user-list.1001560.n3.nabble.com/Lifecycle-of-RDD-in-spark-streaming-td19749.html
http://www.jianshu.com/p/0e7e540de15c
http://stackoverflow.com/questions/29728151/how-to-listen-for-multiple-tcp-connection-using-nc
http://apache-zeppelin-users-incubating-mailing-list.75479.x6.nabble.com/Thrift-Exception-when-executing-a-custom-written-Interpreter-td1993.html
---------------------
lin参数配置
Kylin Interpreter已经集成到Zeppelin 0.5.5的主代码中,所以直接在Zeppelin的配置页面可以找到Kylin配置信息。启动Zeppelin后,在主页点击header上的 Interpreter到该页面找到Kylin配置栏填上配置信息。
Kylin Interpreter主要功能是把前台的配置信息和要运行的SQL转换成一个HTTP请求以获取结果,然后按照Zeppelin的规范转换格式,主要就是完成一次HTTP请求,并把自己项目的查询结果按照Zeppelin的规范格式化,这样就能配合前端展示。所以这里的配置参考Kylin Query API即可,默认修改URL,账号,密码,Project信息即可,更多关于Kylin API信息点这里(http://kylin.apache.org/docs/howto/howto_use_restapi.html)。
---------------------
---------------------
转载于:https://my.oschina.net/hblt147/blog/3010519
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 什么是MEAN堆栈? JavaScript Web应用程序
MEAN堆栈,已定义 MEAN堆栈是一个软件堆栈-即构成现代应用程序的一组技术层-完全用JavaScript构建。 MEAN将JavaScript的出现表示为一种“ 全栈开发 ”语言,从前端到后端运行应用程序中的所有内容。 MEAN中的每个缩写都代表堆栈中的一个组件:…...
2024/5/9 0:31:15 - BAAS业内发展分析(转)
在本文中我们将主要研究目前主要的BaaS平台的功能,以及Google,Facebook,Apple等互联网巨头在BaaS领域的动作。同时我们也会关注国内一些主流BaaS平台的发展以及国内互联网巨头如百度,华为等在BaaS领域的投入发展。 国外主流的Baa…...
2024/5/8 23:39:27 - mean堆栈_什么是MEAN堆栈? JavaScript Web应用程序
mean堆栈MEAN堆栈,已定义 MEAN堆栈是一个软件堆栈,即构成现代应用程序的一组技术层,它们完全用JavaScript构建。 MEAN将JavaScript的出现表示为一种“ 全栈开发 ”语言,可在前端到后端运行应用程序中的所有内容。 MEAN中的每个缩…...
2024/4/28 11:16:37 - [转] Web前端开发工程师常用技术网站整理
1、常用工具相关 有道云笔记 http://note.youdao.com/signIn/index.html 36镇-最好用的共享收藏夹 http://www.36zhen.com/ 浏览器同步测试工具 http://www.browsersync.cn/ https://www.browsersync.io/ 草料二维码生成器 http://cli.im/ GitHub https://github.…...
2024/5/9 7:45:54 - 基于Carto的小车SLAM建图定位与导航
文章目录一、录制地图包1.1 运行机器人小车节点1.2 启动小车控制节点1.3 rosbag记录数据1.4 播放录制的bag(查看是否录制成功)二、生成pbstrem文件三、pbstream转化成pgm和yaml四、功能1:键盘控制小车运动五、功能2:建图定位与导航…...
2024/4/20 19:50:00 - 使用React Native和Spring Boot构建一个移动应用
“我喜欢编写身份验证和授权代码。” 〜从来没有Java开发人员。 厌倦了一次又一次地建立相同的登录屏幕? 尝试使用Okta API进行托管身份验证,授权和多因素身份验证。 React Native是使用React构建移动应用程序的框架。 React允许您使用声明式编程风格来…...
2024/4/20 19:49:59 - AngularJS 中的Promise --- $q服务详解
AngularJS 中的Promise --- $q服务详解 先说说什么是Promise,什么是$q吧。Promise是一种异步处理模式,有很多的实现方式,比如著名的Kris Kwals Q还有JQuery的Deffered。 什么是Promise 以前了解过Ajax的都能体会到回调的痛苦,同步…...
2024/4/20 19:49:58 - angular中的$q服务
$q的一共有四个api: 1.$q.when(value, successFn, errorFn, progressFn),返回值为一个promise对象 --value可以是一个任意数据,也可以是一个promise对象: 如果是任意数据的情况,则直接调用successFn的函数,所以后两个参数没有写的…...
2024/4/20 19:49:57 - 形象的讲解angular中的$q与promise
promise不是angular首创的,作为一种编程模式,它出现在……1976年,比js还要古老得多。promise全称是 Futures and promises。具体的可以参见 http://en.wikipedia.org/wiki/Futures_and_promises 。 而在javascript世界中,一个广泛…...
2024/4/21 4:24:19 - 在指定的浏览器运行angular2 APP
和我一样大多angular2入门者,可能都遇到这样一个问题:执行 ng serve --open http://locakhost:4200/ 后打开的不是我们预料的浏览器(qq浏览器还行,IE的话根本就跑不起来),我也百度过解决方案,可…...
2024/4/21 4:24:18 - 【angular】考试卷子详情
因为数据库中数据问题,截取空白页不如上盘原型图: 主体代码: <div *ngFor"let q of qt.questionMainList; let iindex" [ngSwitch]"qt.questionTypeId"><div *ngFor"let qtl of questionTypeList; let k…...
2024/4/21 4:24:17 - 在Angular中使用promise
在ng中最好将网络请求放在service中,从而简化controller,使controller专注做自己的“桥梁”工作,即连接数据与视图。比如我们在做一个通讯录,所以我们可以这样做: 1.建一个service叫addressBook.service.js (functio…...
2024/4/21 4:24:17 - AngularJS—$q
描述 既然是用来处理异步编程的,那么在浏览器端的js里,主要是2种: setTimeout 和 Ajax 请求. promise 的使用就很像Ajax请求的成功和失败回调。 此承诺/延迟(promise/deferred)实现的灵感来自于 Kris Kowal’s Q CommonJS Promise建议文档 将承诺(promis…...
2024/4/21 4:24:15 - angular $q,defer,promise
1. $q $q是Angular的一种内置服务,它可以使你异步地执行函数,并且当函数执行完成时它允许你使用函数的返回值(或异常)。 2. defer defer的字面意思是延迟, $q.defer() 可以创建一个deferred实例(延迟对象实…...
2024/4/21 4:24:14 - angular 延迟时间
delay(ms) {return new Promise(res > setTimeout(res, ms));}import { delay } from q;await delay(time);//指定时间,ms...
2024/4/21 4:24:13 - Angular JS $q 学习备注
AngularJS $q是一个帮助处理异步执行函数的服务,当服务完成时使用它们的返回值(或异常)。 Deferred Api 一个被$q.defer()调用的deferred的新实例。 deferred对象的目的是暴露相关承诺实例,以及APIs被执行的成功或不成功情况&am…...
2024/4/21 4:24:13 - angular $q服务的用法
Promise是一种和callback有类似功能却更强大的异步处理模式,有多种实现模式方式,比如著名的Q还有JQuery的Deffered。 什么是Promise 以前了解过Ajax的都能体会到回调的痛苦,同步的代码很容易调试,但是异步回调的代码,会…...
2024/5/5 15:07:31 - angular指令实例及总结
html代码 <div ng-app"DnApp" ng-controller"SeasonDetailController"> <seamonthdetail seamon"seasonMonth" getseadatas"getSeasonDetailData(month)"></seamonthdetail> </div> controller代码 var DnApp…...
2024/4/21 4:24:11 - Angular 1.X初识
一、ng的四大特性 1.MVC: MVC是一种设计模式?它的使用让代码变得模块化,职责清晰。M(Model)即数据模型层,它用于数据结构的组织,数据的获取和存储;V(View)即…...
2024/4/21 4:24:09 - angular directive 不生效
angular环境下,写了一个directive,挂在input上,怎么都没反应。 后来拿来之前的代码看了下,被自己蠢哭了。 js里 app.directive(checkQty, function() {return {restrict: A,require: ?ngModel,link: function(scope, element,…...
2024/4/21 4:24:09
最新文章
- 常见C语言基础说明三:static修饰的函数或变量
一. 简介 前面几篇学习了 C语言中基础问题,文章如下: 常见C语言基础题说明一-CSDN博客 常见C语言基础说明二:位运算问题-CSDN博客 本文继续学习 嵌入式C开发中,可能涉及的一些C语言基础问题。 二. 常见C语言基础说明三&…...
2024/5/9 8:01:03 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/5/7 10:36:02 - A股企业数据要素利用水平数据集(2001-2022年)
参照史青春(2023)的做法,团队对上市公司-数据要素利用水平进行测算。统计人工智能技术、区块链技术、云计算技术、大数据技术、大数据技术应用五项指标在企业年报中的披露次数,求和后衡量数据要素投入水平。 一、数据介绍 数据名…...
2024/5/7 15:39:36 - xv6项目开源—05
xv6项目开源—05.md 理论: 1、设备驱动程序在两种环境中执行代码:上半部分在进程的内核线程中运行,下半部分在中断时执行。上半部分通过系统调用进行调用,如希望设备执行I/O操作的read和write。这段代码可能会要求硬件执行操作&…...
2024/5/8 1:57:10 - 第六章:使用 kubectl 创建 Deployment
使用 kubectl 创建 Deployment 目标 学习应用的部署。使用 kubectl 在 Kubernetes 上部署第一个应用。Kubernetes 部署 一旦运行了 Kubernetes 集群, 就可以在其上部署容器化应用。为此,你需要创建 Kubernetes Deployment。 Deployment 指挥 Kubernetes 如何创建和更新应用…...
2024/5/8 16:49:04 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/8 6:01:22 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/7 9:45:25 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/9 4:20:59 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/7 11:36:39 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/6 1:40:42 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/8 20:48:49 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/7 9:26:26 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/8 19:33:07 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/8 20:38:49 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/9 7:32:17 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57