【Paper】HAR:Deep Convolutional and LSTM RNN for Multimodal Wearable Activity Recognition
论文原文:点击此处
论文下载:点击此处
论文年份:2016
论文被引:773
论文代码实现1:点击此处
论文代码实现2:点击此处
论文代码实现3:点击此处
Deep Convolutional and LSTM Recurrent Neural Networks for MultimodalWearable Activity Recognition
Abstract
Human activity recognition (HAR) tasks have traditionally been solved using engineered features obtained by heuristic processes. Current research suggests that deep convolutional neural networks are suited to automate feature extraction from raw sensor inputs. However, human activities are made of complex sequences of motor movements, and capturing this temporal dynamics is fundamental for successful HAR. Based on the recent success of recurrent neural networks for time series domains, we propose a generic deep framework for activity recognition based on convolutional and LSTM recurrent units, which: (i) is suitable for multimodal wearable sensors; (ii) can perform sensor fusion naturally; (iii) does not require expert knowledge in designing features; and (iv) explicitly models the temporal dynamics of feature activations. We evaluate our framework on two datasets, one of which has been used in a public activity recognition challenge. Our results show that our framework outperforms competing deep non-recurrent networks on the challenge dataset by 4% on average; outperforming some of the previous reported results by up to 9%. Our results show that the framework can be applied to homogeneous sensor modalities, but can also fuse multimodal sensors to improve performance. We characterise key architectural hyperparameters’ influence on performance to provide insights about their optimisation.
Keywords: human activity recognition; wearable sensors; deep learning; machine learning; sensor fusion; LSTM; neural network
传统上,人类活动识别(HAR)任务是使用启发式过程获得的工程特征来解决的。 当前的研究表明,深度卷积神经网络适合于从原始传感器输入中自动提取特征。 但是,人类活动是由复杂的运动序列组成的,捕获这种时间动态是成功进行HAR的基础。 基于时间序列域递归神经网络的最新成功,我们提出了基于卷积和LSTM递归单元的活动识别的通用深度框架,该框架:(i)适用于多模式可穿戴传感器; (ii)可以自然地进行传感器融合; (iii)在设计特征时不需要专家知识; (iv)明确建模特征激活的时间动态。 我们在两个数据集上评估我们的框架,其中一个已用于公共活动识别挑战中。 我们的结果表明,我们的框架在挑战数据集上的竞争性深层非经常性网络的平均表现为4%; 胜过某些先前报告的结果最多达9%。 我们的结果表明,该框架可以应用于同质传感器模式,但也可以融合多模式传感器以提高性能。 我们表征关键架构超参数对性能的影响,以提供有关其优化的见解。
关键词:人类活动识别; 可穿戴式传感器; 深度学习; 机器学习; 传感器融合; LSTM; 神经网络
1. Introduction
认识到人类活动(例如,从简单的手势到复杂的活动,例如“做饭”)及其在传感器数据中发生的环境是智能辅助技术(如智能家居)的核心[1], 在康复[2],健康支持[3,4],技能评估[5]或工业环境[6]中。 现在,一些简单的活动感知系统以健身追踪器或跌倒检测设备的形式投入商业化。 但是,许多具有较高社会价值的场景仍然难以捉摸,例如为痴呆症患者提供“记忆假体”,在适当的情况下在日常生活中插入微妙的线索以支持自愿的行为改变(例如,对抗肥胖)或实现自然的日常环境中的人机交互。 这些情况需要对人员在家中和外出及周围的活动有一点了解。
这项工作的动机是活动识别的两个要求:提高识别准确性和减少对工程功能的依赖,以解决日益复杂的识别问题。 由于给定动作所采用的运动动作的巨大差异,因此人类活动识别具有挑战性。 例如,2011年针对识别家庭环境中的活动而进行的“机遇”挑战表明,仅识别17个零星手势,竞争者的准确率就不会超过88%[7]。 因此,解决方案(例如活动差异化)将需要进一步提高针对更广泛活动集的识别性能。
人类活动识别(HAR)基于特定的身体运动转化为特征传感器信号模式的假设,可以使用机器学习技术对其进行感测和分类。 在本文中,我们对可穿戴式(人体)感应感兴趣,因为无论用户身在何处,它都可以进行活动和上下文识别。
可穿戴活动识别依赖于传感器的组合,例如加速度计,陀螺仪或磁场传感器[8]。 然后,使用滑动窗口上的特征提取,分类,模板匹配方法[9]或隐马尔可夫建模[10]在流传感器数据中检测与活动相对应的模式。 滑动窗口方法通常用于静态和周期性活动,而零星活动则适合模板匹配方法或隐马尔可夫建模[8,11]。
大多数识别系统从“工程化”特征池中选择特征[12]。识别相关特征既费时,又导致难以将活动识别“扩展”到复杂的高级行为(例如,一小时,一天或更长的时间),因为工程化功能与“行为单位”无关 ,而是方便的数学运算的结果。 例如,统计和频率特征与人类动作的语义上有意义的方面(例如“抓握”)无关。
深度学习广泛地指的是神经网络,它利用多层非线性信息处理进行特征提取和分类,并进行分层组织,每一层都处理前一层的输出。 在计算机视觉[13]和音频分类[14]中,深度学习技术的性能已经超过了许多传统方法。
卷积神经网络(CNN)[15]是一种DNN(深层神经网络),具有充当特征提取器的能力,可以堆叠多个卷积运算符以创建逐渐更抽象的特征的层次结构。 这样的模型能够自动学习多层要素层次结构(也称为“表示学习”)。 长期短期记忆递归(LSTM)神经网络是一种递归网络,其中包括用于对时间序列问题中的时间依赖性进行建模的内存。 CNN和LSTM在一个统一的框架中的结合已经在语音识别领域提供了最先进的结果,在该领域中需要对时间信息进行建模[16]。 这种体系结构能够捕获对卷积运算提取的特征的时间依赖性。
**深度学习技术有望满足可穿戴活动识别的要求。 首先,可以主要通过现有的识别技术来提高性能。**其次,深度学习方法可能具有发现与人类运动产生动力学相关的功能的潜力,从较低层的简单运动编码到较高层的更复杂的运动动力学。 这可能有助于将活动识别扩展到更复杂的活动。
本文的贡献如下:
- 我们提出了DeepConvLSTM:由卷积层和LSTM循环层组成的深度学习框架,它能够自动学习特征表示并对它们的激活之间的时间依赖性进行建模。
- 我们证明此框架适用于可穿戴传感器数据的活动识别,方法是将其用于人类活动识别问题的两个家族,即静态/周期性活动(运动和姿势的模式)和零星活动(手势)(sporadic activities (gestures))的活动。
- 我们证明了该框架可以无缝地分别应用于不同的传感器模式,并且还可以将它们融合以提高性能。 我们在加速度计,陀螺仪及其组合上对此进行了演示。
- 我们表明,该系统可通过最少的预处理直接处理原始传感器数据,这使其特别通用,并最大程度地减少了工程偏差。
- 我们将我们的方法的性能与参加公认活动识别挑战(OPPORTUNITY)和另一个开放数据集(Skoda)的参赛者所报告的方法进行比较。
- 我们表明,拟议的体系结构胜过了在机遇挑战中获得的公开成果,包括深层的CNN,后者在先前的研究中已经提供了最新的结果[17]。
- 我们将讨论结果,包括表征关键参数对性能的影响,并概述未来的研究场所,以利用深层建筑的特性的其他优势。
2. State of the Art
神经网络在模式分类方面功能强大,并且是深度学习技术的基础。 我们将在第2.1节中介绍浅层递归网络的基础知识,尤其是那些基于LSTM单元构建的浅层递归网络的基础知识,它们非常适合于对时间动态模型进行建模。在第2.2节中,我们回顾了深度网络(特别是卷积网络)在特征学习中的使用。 在第2.3节中,我们回顾了神经网络在深度架构中的使用及其在与人类活动识别相关的领域中的应用。
2.1. From Feedforward to Recurrent Networks
前馈神经网络或**多层感知器(MLP)**是一种通过一系列互连的计算节点处理信息的计算模型。 这些计算节点被分组为多个层,并使用加权连接相互关联。 这些层的节点称为单位(或神经元),并通过非线性操作转换数据,以将输入投影到线性可分离的空间中,从而为输入创建决策边界。
通过以有监督的方式训练MLP,MLP已成功应用于分类问题。 每个神经元都可以看作是一个表现为逻辑回归分类器的计算单位(见图1a)。 形式上,单位是根据以下功能定义的:
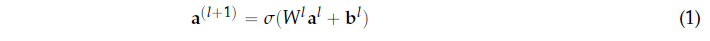
其中al表示第l层中单位的响应级别(或激活值)(al i是第l层中单位i的激活(I是上标,ij是下标)),W是权重矩阵,其中Wl ij(I是上标,ij是下标)表示关联的参数(或权重) 在第l层中的单元j和第l层1中的单元i之间建立连接时,bl是与第l层中的单元关联的偏置,而σ是激活函数(或非线性)。 对于l=1,我们使用a(1) = x 表示网络的输入数据(问题中的传感器信号)。MLP体系结构的输出由最深层中的单元激活来定义。 MLP使用完全连接的(或密集的)拓扑,其中(l+1)层中的每个单元都与l层中的每个单元连接。
MLP体系结构的局限性在于它假定所有输入和输出都相互独立。 为了使MLP对时间序列(例如传感器信号)建模,必须在输入数据中包含一些时间信息。 递归神经网络(RNN)是专门设计用于解决此问题的神经网络,它在每个单元中都使用了递归连接。 神经元的激活以权重和单位时间延迟反馈给自身,这为它提供了过去激活的记忆(隐藏值),从而使它能够学习顺序数据的时间动态。 图1b中显示了单个循环单元的表示。
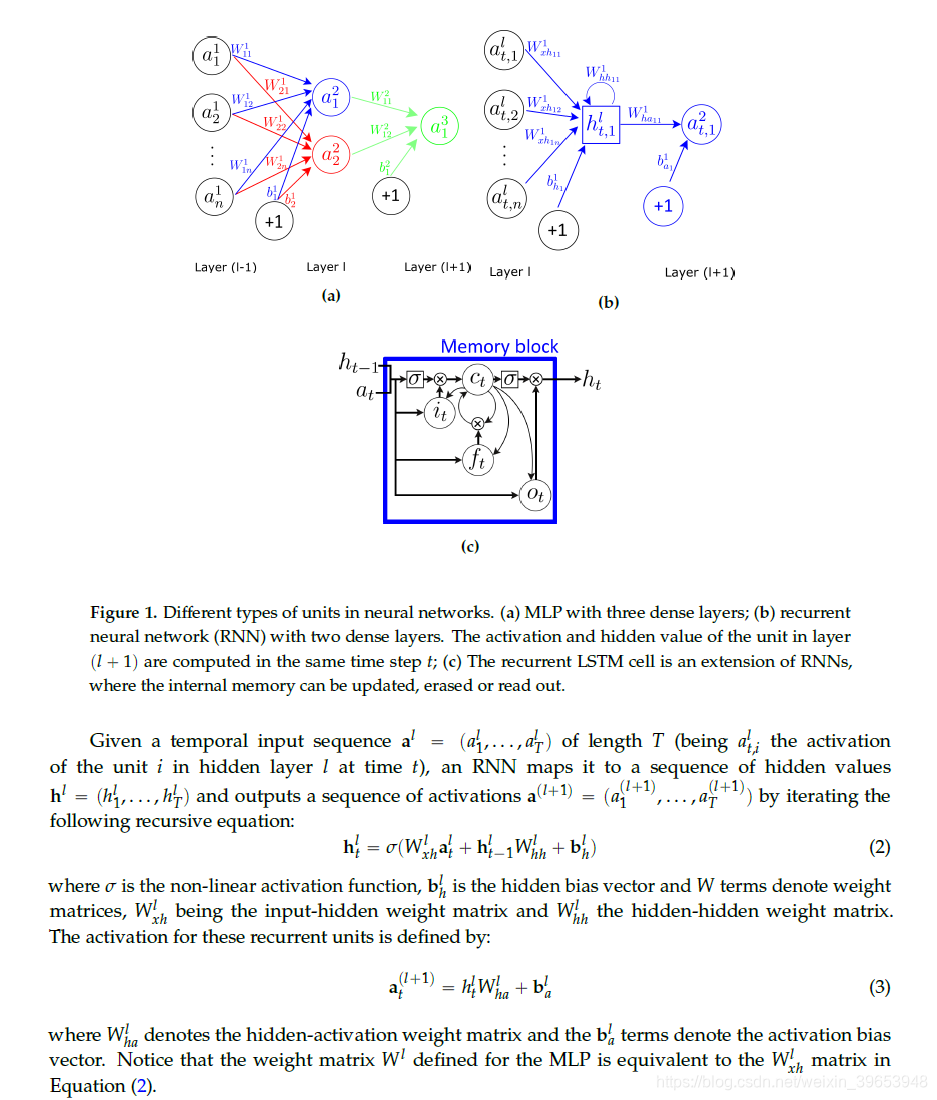
这些类型的网络具有图灵功能[18],因此原则上适合于学习序列。 但是,它们的记忆机制在处理现实世界中的序列处理时给学习带来挑战[19]。
LSTM用存储单元(而不是循环单元)扩展RNN来存储和输出信息,从而简化了长时间尺度上时间关系的学习。 LSTM利用门控的概念:一种基于输入的按组件乘法的机制,该机制定义了每个单独的存储单元的行为。 LSTM根据门的激活来更新其单元状态。 提供给LSTM的输入被馈送到不同的门,这些门控制对单元存储器执行的操作:写入(输入门),读取(输出门)或复位(忘记门)。 LSTM单位的激活按照RNN中的方法计算(请参见公式(2))。LSTM单元的隐藏值ht的计算在每个时间步t更新。 LSTM层更新的矢量表示(表示层中所有单元的矢量)如下:
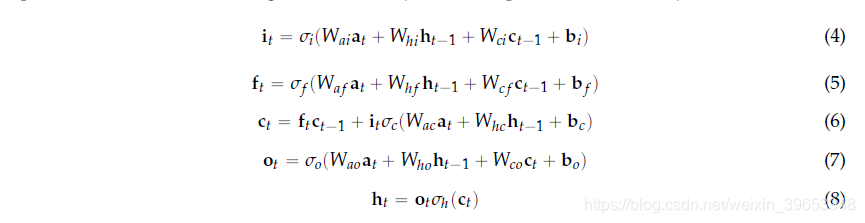
其中i,f,o和c分别是输入门,忘记门,输出门和单元激活向量,所有这些向量的大小都与定义隐藏值的向量h相同。 项σ代表非线性函数。 术语at是在时间t到存储单元层的输入。 Wai,Whi,Wci,Wa f,Wh f,Wc f,Wac,Whc,Wao,Who和Wco是权重矩阵,下标表示从前到后的关系(Wai是输入-输入门矩阵,Whi是隐藏输入 门矩阵等)。 bi,bf,bc和bo是偏差向量。 为了清楚起见,省略了图层的符号。使用LSTM单元的网络在语音识别方面提供了比标准循环单元更好的性能,它们在音素识别方面提供了最先进的结果[20]。
2.2. Feature Learning with Convolutional Networks
神经网络,无论是循环的还是前馈的,都可以接收原始传感器信号作为输入。然而,将它们应用于源自原始传感器信号的特征通常会导致更高的性能[21]。 发现适当的特征需要专家知识,这必然会限制对特征空间的系统性探索[12]。 已经提出了卷积网络(CNN)来解决这个问题[17]。 具有单层的CNN通过使用滤波器(或内核)对信号进行卷积运算,从输入信号中提取特征。 在CNN中,单位的激活表示内核与输入信号卷积的结果。 通过计算单元在同一输入的不同区域上的激活(使用卷积运算),可以检测内核捕获的模式,而不管模式发生在哪里。 在CNN中,作为有监督训练过程的一部分,对内核进行了优化,以尝试最大化类子集的内核激活级别。 特征图是单元(或图层)的数组,其单元共享相同的参数化(权重向量和偏差)。 它们的激活产生了内核对整个输入数据进行卷积的结果。
卷积运算符的应用取决于输入维数。 对于2D图像(例如视频)的时间序列,通常在2D空间卷积中使用2D内核[22]。 对于一维时间序列(例如,传感器信号),通常在时间卷积中使用一维内核[23]。 在1D域中,内核可以看作是一个过滤器,可以删除异常值,过滤数据或充当特征检测器,这些过滤器定义为最大程度地响应内核时间范围内的特定时间序列。 形式上,使用一维卷积运算提取特征图的方式为:

因此,输入级别的特征图数量为F11。在随后的层中,特征图的数量将由该层内的内核数量定义(请参见图2)。
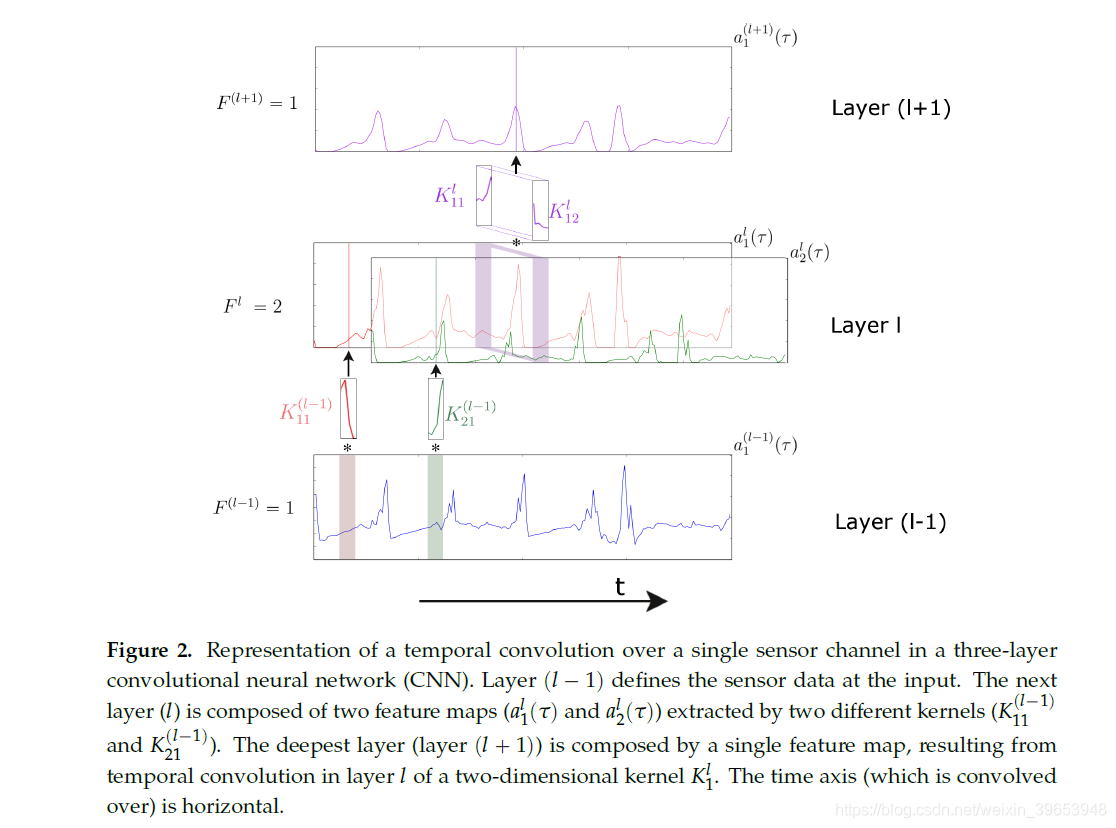
权重能够捕获手势的特定显着模式的内核将充当特征检测器。 具有多个卷积层的模型(在堆叠配置中,层1的输出是上层1的输入)可能能够学习数据的分层表示,其中更深的层在更多的层中逐步表示输入 抽象的方式。深度CNN对内容推荐[24],语音识别[25]和计算机视觉[26-28]等领域产生了重大影响,它们已成为事实上的标准方法。
2.3. Application of Deep Networks for HAR
与由少量或仅一个隐藏层(浅层网络)定义的网络相比,深层网络能够计算更复杂的输入转换,从而提供更高的表示能力。
使用卷积层和非递归层组合的网络体系结构,DNN已应用于可穿戴式HAR域。[17,23]。 从可穿戴传感器获得的原始信号经过卷积层处理,以捕获特征,这些特征由密集层进行统一,以获得不同人类活动的概率分布。 在几个基准数据集(机会,斯柯达和Actitracker数据集)上的实验证明了卷积算子能够捕获内核窗口内的时间信号结构。 结果表明,这些网络体系结构提供了具有更高判别能力的模型,性能优于最新方法。
通过在统一的深度框架中组合卷积层和循环层,可以在语音识别领域对时间序列分类进行进一步的改进,该框架包含标准循环单元[29]或LSTM单元[16]。 TIMITphone识别数据库等不同数据集上的结果证明,这些体系结构可提供一种功能部件表示,即使在不同的数据分辨率下,也可以更轻松地进行分离并捕获信息。
视频中的活动识别情况是与本文所研究的HAR场景最接近的问题之一,因为视频数据分析可以看作是时间序列建模。 在视频领域,CNN和LSTM被证明适合在随后的视频帧中组合时间信息以实现更好的视频分类。 在Sports-1M和UCF-101数据集上进行的比较分析结果表明,LSTM细胞对于充分利用视频中包含的运动信息是必不可少的,并且具有最高的报道性能[30]。
在Montalbano数据集上比较了几种深度递归的视频手势识别方法[22]。 包含递归和卷积的模型显着改善了逐帧手势识别。 结果证明了递归方法如何能够捕获时间信息,从而提供了更具区分性的数据表示。 它可以胜过非经常性网络,并可以更准确地分割手势的开始和结束帧。
其他网络拓扑(如深度信任网络(DBN))也已应用于活动识别域。 DBN是生成型深度学习网络的一种形式,其隐藏层以贪婪的分层方式进行训练。 它们可以用来提取训练数据的更深层次的表示[31]。 三个可穿戴式HAR数据集(OPPORTUNITY,Skoda和Darmstadt Daily Routines数据集)的结果表明,它们如何提供在HAR应用程序中具有普遍适用性的特征提取框架[32]。
这些相关的工作说明了使用深度CNN来学习时间序列特征的潜力,并且还表明LSTM适合于学习传感器信号中的时间动态。 尽管一些工作将CNN应用于活动识别,但是卷积层和循环层的有效结合已经在其他时间序列领域(例如语音识别)中提供了最新的结果,但尚未在HAR领域中进行研究 。
3. Architecture
我们为可穿戴活动识别引入了一个新的DNN框架,我们将其称为DeepConvLSTM。 这种架构结合了卷积层和循环层。 卷积层充当特征提取器,并在特征图中提供输入传感器数据的抽象表示。 循环图层为特征图激活的时间动态建模。 在此框架中,卷积层不包括池化操作(有关此选择的讨论,请参见第5.4节)。 为了表征DeepConvLSTM带来的好处,我们将其与“基准”非循环深层CNN进行了比较。 两种方法都是根据图3中描述的网络结构定义的。出于比较目的,它们共享相同的体系结构,具有四个卷积层和三个密集层。 输入以逐层格式进行处理,其中每一层都提供输入的表示形式,该表示将用作下一层的数据。
在这两种情况下,卷积层中的内核数和密集层中的处理单元是相同的。 DeepConvLSTM和基准CNN之间的主要区别是密集层的拓扑。 在DeepConvLSTM的情况下,这些层的单元是LSTM循环单元,在基线模型的情况下,这些单元是非循环的且完全连接的。
因此,模型之间的性能差异是体系结构差异的产物,而不是由于更好的优化,预处理或临时定制所致。网络的输入由一个数据序列组成。 该序列是使用多个传感器通道组成的滑动窗口方法(请参见第4.2节)从传感器数据中提取的短时间序列。 传感器通道的数量表示为D。在该序列中,所有通道具有相同数量的样本S1。 特征图S1的长度在不同的卷积层中变化。 仅在输入和内核完全重叠的地方计算卷积。 因此,特征图的长度定义为:
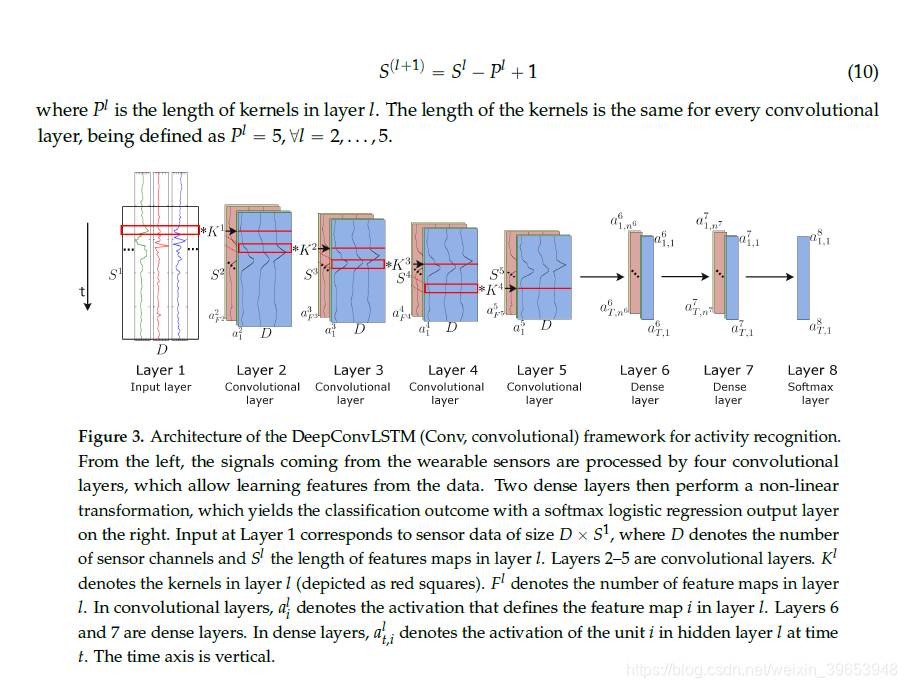
3.1. DeepConvLSTM
DeepConvLSTM是DNN,包含卷积层,递归层和softmax层。首先,通过等式(9)中定义的四个卷积运算来转换传感器数据。卷积层仅沿代表时间的轴处理输入。 在所有图层中,每个要素图的传感器通道数均相同。 在图3中,卷积运算符显示为“ * ”,该运算符应用于大小用红色矩形表示的内核。这些卷积层使用整流线性单位(ReLU)来计算特征图,其等式(9)中的非线性函数定义为s(x) = max(0,x)。 第6层和第7层是循环密集层。 循环层数的选择是根据[33]中给出的结果进行的,作者表明,在处理顺序数据时,至少两个循环层的深度是有益的。 循环密集层在每个时间步之后都会调整其内部状态。 在这里,时间t处第6层的输入是时间t处第5层的所有要素图的元素,其中t = 1…T且 T=S5。 使用双曲正切函数计算循环单元的激活。 该模型的输出是从softmax层(具有softmax激活函数的密集层)获得的,得出每个单个时间步t的类概率分布。 按照[22]中的表示法,该模型的简写为:C(64) - C(64) - C(64) - C(64) - R(128) - R(128) - Sm,其中C(Fl)表示具有Fl特征图的卷积层l,R(nl)是具有nl个单元的循环LSTM层 和Sm是softmax分类器。
3.2. Baseline Deep CNN
基线模型是一个深层的CNN,它包含卷积层,非循环层和softmax层。 这种方法共享DeepConvLSTM的卷积层。 它接收相同的输入,D×S1传感器数据序列,并且以与DeepConvLSTM体系结构相同的方式提取特征图。 在此模型中,第6层和第7层是非循环密集层,与MLP中使用的相同。 使用等式(1),使用来自最后一个卷积层的所有特征图来计算第一密集层中每个单元的激活。 密集层中的单位是ReLU,其中spxq maxp0,xq。 该模型的输出是从softmax层(具有softmax激活函数的密集层)获得的,从而得出各个类别的概率分布。对于该模型,简写为:C(64) - C(64) - C(64) - C(64) - D(128) - D(128) - Sm,其中C(Fl),其中C(Fl)表示具有Fl特征图的卷积层l,D(nl)表示具有nl单位的密集层,而Sm表示softmax分类器。
3.3. Model Implementation and Training
这里描述的神经网络是在Theano中使用Lasagne [34]实现的,这是一个轻量级的库,用于构建和训练神经网络。 模型训练和分类在具有1664内核,1050 MHz时钟速度和4 GB RAM的GPU上运行。
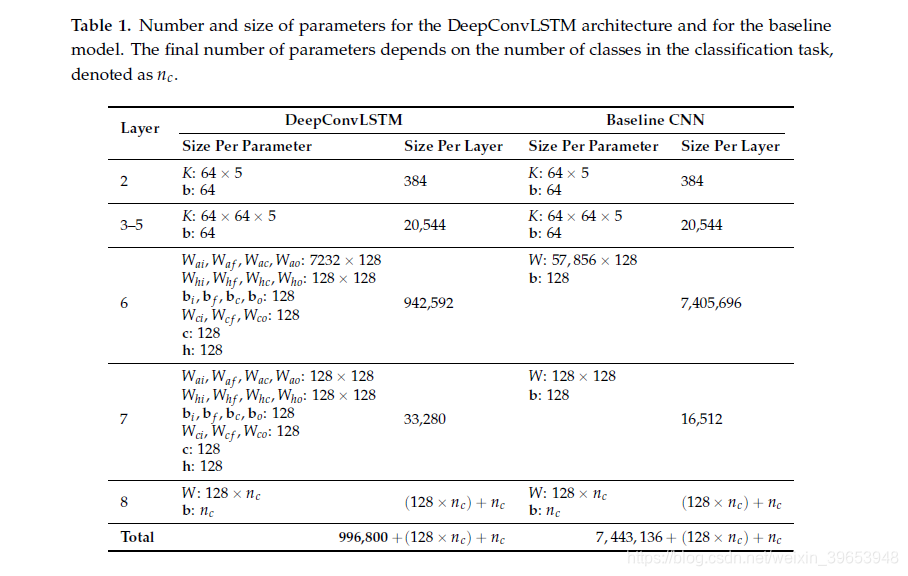
以完全监督的方式训练模型,反向传播从softmax层到卷积层的梯度。 通过使用带有RMSProp更新规则的小批量梯度下降来最小化交叉熵损失函数来优化网络参数。 在对每个参数的学习率更新进行了多次试验之后,我们发现RMSProp始终提供最佳结果,并且对学习率设置的容忍度最大。DNN中要优化的参数数量根据其所包含的层的类型而有所不同,并且在训练网络所需的时间和计算机能力方面有很大影响。 表1详细介绍了第3.1节和第3.2节中介绍的网络中参数的数量和大小。
为了提高效率,在训练和测试时,会在大小为100个数据段的微型批次上对数据进行分段。 使用此配置,在每次迷你批处理之后都将计算参数的累积梯度。 两种模型都以10e-3的学习率和p = 0.9的衰减因子进行训练。 权重被随机正交初始化。 作为正则化的形式,我们在每个密集层的输入上引入了一个删除运算符。 该运算符将训练期间随机选择的单元的激活设置为零(概率为p 0.5)。
4. Experimental Setup
我们在两个人类活动识别数据集上评估DeepConvLSTM,并将其与基准CNN进行比较,后者为深度网络提供了性能参考,并与文献中使用其他机器学习技术在这些数据集上报告的结果进行了比较。
4.1. Benchmark Datasets
可以将人类活动定义为周期性的,例如步行和骑自行车;静止的,例如坐着和站着不动;或零星的,例如面向目标的手势(例如,从杯子里喝水)[8]。必须对包含各种类型的活动的数据集进行活动识别的基准测试。 此外,人类活动(即,诸如“拿起杯子”之类的面向目标的手势)通常被嵌入到大型Null类中(Null类对应于不涵盖“有趣”活动的时间跨度,例如 ,则当用户没有参与与当前场景相关的活动之一时)。 识别嵌入在Null类中的活动往往更具挑战性,因为识别系统必须隐式地识别包含手势的数据的起点和终点,然后对其进行分类。 已经发布了用于活动识别的许多数据集,包括机会[36],PAMAP [37],斯柯达[38]和mHealth [39]数据集。在本文中,我们根据活动的多样性和可变性以及它们在HAR文献中的存在,选择了两个数据集来评估我们的方法。
4.1.1. The OpportunityDataset
机会数据集[36]包含在传感器丰富的环境中收集的一组复杂的自然活动。 总的来说,它包含了在进行早晨活动的日常生活场景中的四个对象的记录,并在环境,物体和身体上集成了不同模式的传感器。 在录制过程中,每个受试者进行了五次关于日常生活(ADL)的活动和一次训练。 在每个ADL会话中,受试者通过遵循对要执行的总体动作的宽松描述(例如,检查厨房中的食材和器皿,准备和喝咖啡,准备和吃三明治,清理)来不受限制地执行活动。 。 在练习期间,受试者进行了17次活动的预定义排序集合中的20次重复。 数据集总共包含大约6个小时的记录。
The OPPORTUNITY dataset包括静态/定期和零星活动。 它可在UCIMachine学习资料库中找到,并已被许多第三方出版物使用(例如[23,32,40])。 最重要的是,它已用于公开活动识别挑战中,参与者(在表3中列出)在识别运动模式以及偶发手势方面竞争以取得最高性能[7]。 该数据集是公开可用的,可以从[41]下载。
在本文中,我们使用机会挑战中使用的相同子集来训练和测试我们的模型。 我们针对第一个主题的所有ADL和钻取会话以及主题2和3的ADL1,ADL2和钻取会话的数据训练模型。我们针对由主题2和3组成的测试集报告分类性能,该测试集由ADL4和ADL5组成。 剩下的对象2和3的ADL3数据集用于验证。
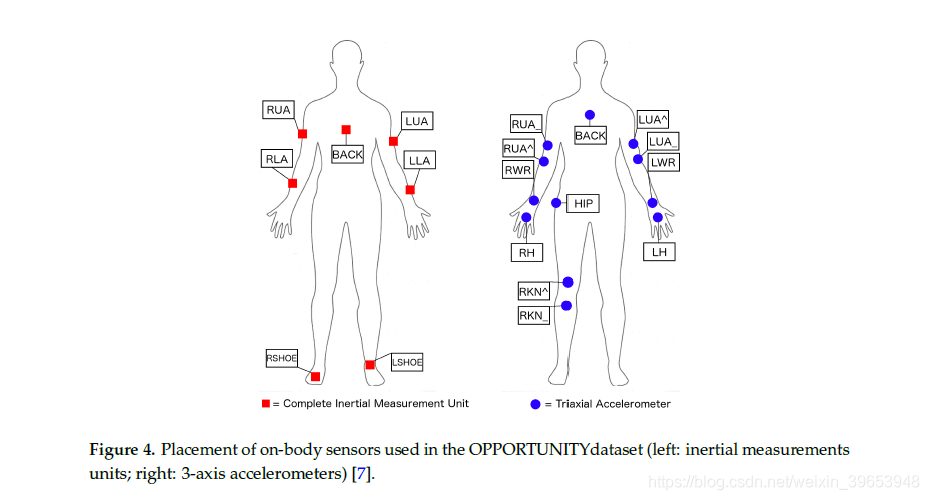
在传感器设置方面,我们遵循机会挑战准则,仅考虑了人体传感器。 这包括定制运动夹克中包含的5个商用RS485网络XSense惯性测量单元(IMU),每只脚上有2个商用InertiaCube3惯性传感器(图4,左)和四肢上的12个蓝牙加速度传感器(图4, 对)。 每个IMU由3D加速度计,3D陀螺仪和3D磁传感器组成,提供多模式传感器信息。 每个传感器轴都被视为一个单独的通道,从而产生尺寸为113个通道的输入空间。 这些传感器的采样率为30 Hz。
在这项研究中,对传感器数据进行了预处理,以使用线性插值法填充缺失值,并对通道间隔[0,1]进行归一化处理。
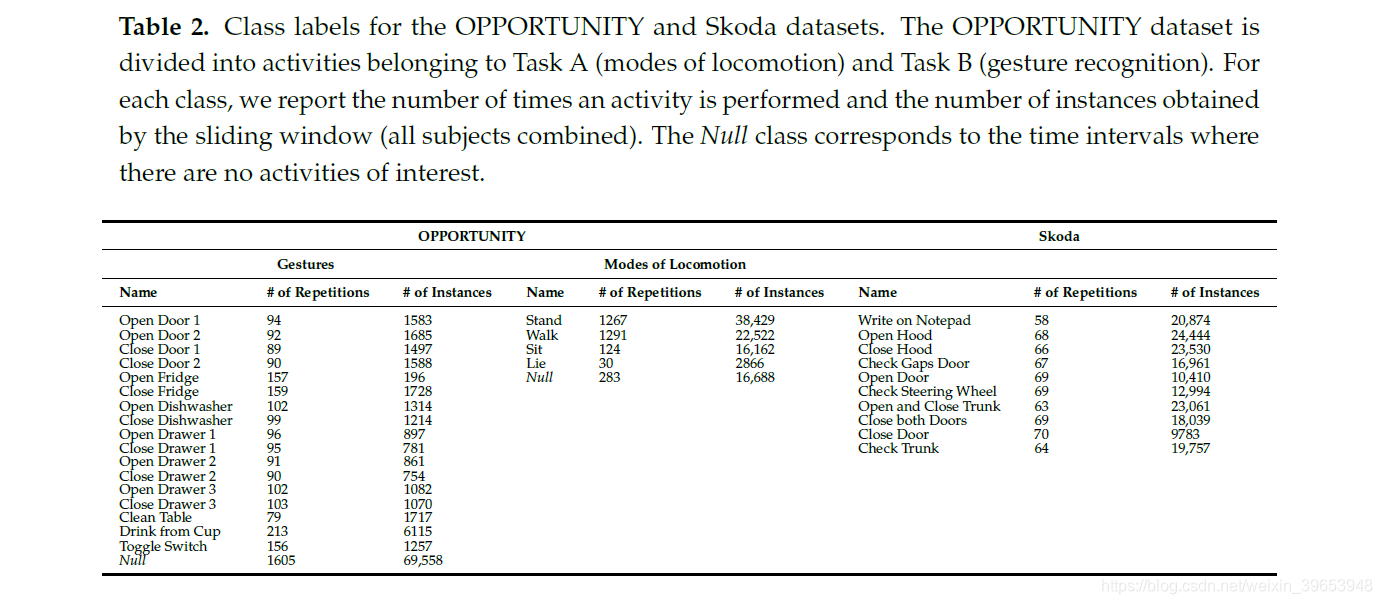
The OPPORTUNITY dataset包括手势和运动/姿势模式的多个注释。 在本文中,我们将模型集中于“机遇”挑战中定义的两个任务:
任务A:运动和姿势的识别模式。 这项任务的目的是从整套的人体穿戴传感器中对运动模式进行分类。 这是一个5类分割和分类问题。
任务B:识别零星手势。 此任务涉及识别不同的右臂手势。 这是一个18类分割和分类问题。
表2汇总了每个任务的数据集中包含的活动。
4.1.2. The Skoda Dataset
Skoda Mini Checkpoint数据集[38]描述了汽车生产环境中流水线工人的活动。 这些手势类似于在生产工厂的质量保证检查点执行的手势,并在表2中列出。
在这项研究中,一名受试者的两只手臂上都戴着20个3D加速度计。 我们将实验限于放置在右臂上的10个传感器。该数据集的原始采样率为98 Hz,但为了与OPPORTUNITY数据集进行比较,将其降低为30 Hz。数据集包含10个操作手势。记录时间约为3小时,每个手势包含约70次重复。该数据集是公开可用的,可以从[42]下载。Skoda数据集已用于评估传感器网络中的决策融合技术[38]和深度学习技术[23,43],这使其成为评估我们提出的解决方案的合适数据集。
4.2. Performance Measure
持续记录机会和斯柯达数据集。 我们使用固定长度的滑动窗口分割数据。 我们将每个窗口称为“序列”,它是网络的输入。 进行机会挑战实验设置后,窗口的长度为500 ms,步长为250 ms。 表2中每个数据集详细介绍了使用此滑动窗口配置后获得的实例(段)数。
与每个段关联的类别对应于在该间隔期间观察到的手势。 给定长度为T的滑动窗口,我们选择序列的类别作为t T处的标签,换句话说,选择窗口中最后一个样本的标签,如图5所示。
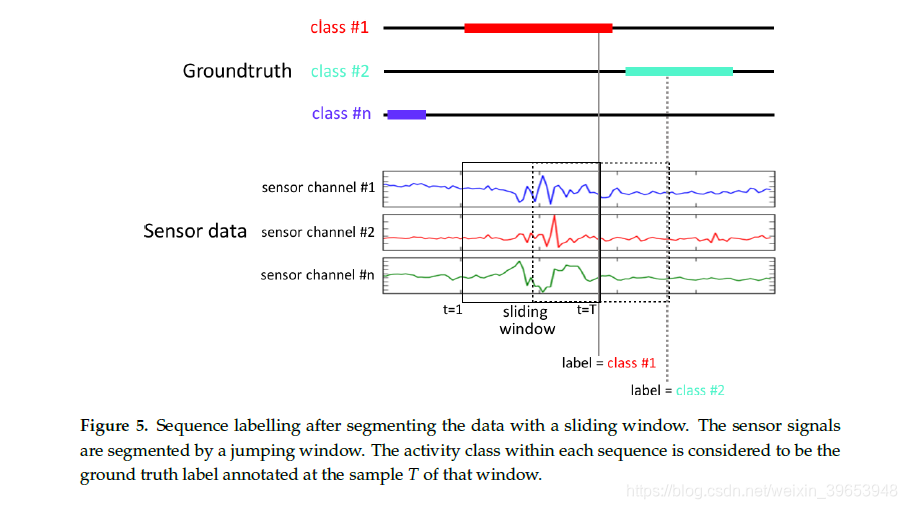
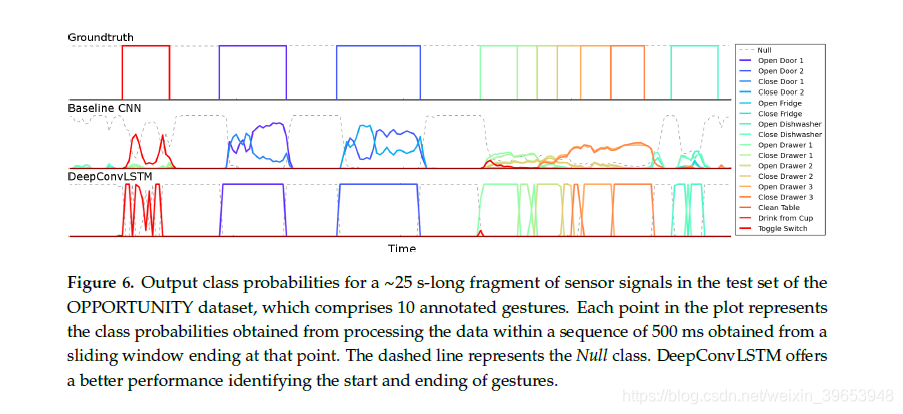
如第3节所述,DeepConvLSTM针对序列中每个时间步长t(即传感器信号的500毫秒窗口)输出类概率分布。 但是,一旦DeepConvLSTM观察到整个500毫秒序列,我们就会对类概率分布感兴趣。为此[30]存在几种方法:(1)使用最后一个时间步长T的预测;(2)在该序列中最大程度地合并预测;(3)将所有序列预测随时间累加并返回最频繁的预测。 由于LSTM单位的内存往往会随着它们所看到的样本数量的增加而变得越来越有信息性,因此DeepConvLSTM仅在观察到完整序列时才在最后一个时间步T返回类概率分布。 因此,在原始传感器信号的每个采样时,DeepConvLSTM提供了从该时间之前处理500毫秒传感器信号提取中推断出的类概率分布,如图6所示。 考虑到时间T处的样本是定义地面真相中序列标签的样本,因此也是最相关的。
自然的人类活动数据集通常高度不平衡。 当某些类由大量示例表示,而另一些仅由少数几个示例表示时,则发生类不平衡[44]。 OPPORTUNITY数据集的手势识别任务非常不平衡,因为Null类代表记录数据的75%以上(对于主题1-3,分别为76%,82%和76%)。 总体分类精度不是适当的性能度量,因为将每个实例预测为多数类的琐碎分类器可以实现非常高的精度。因此,我们使用F量度(F1)评估模型,该量度考虑了每个类别的正确分类同样重要。 F1分数结合了根据正确识别的样本总数定义的两个度量,并且在信息检索社区中被称为精确度和召回率。 精度定义为TP/TP+FP,召回率对应于TP/TP+FN,其中TP,FP分别是真假阳性的数目,而FN则是假阴性的数目。 类别不平衡可通过根据样本比例加权类别来解决:
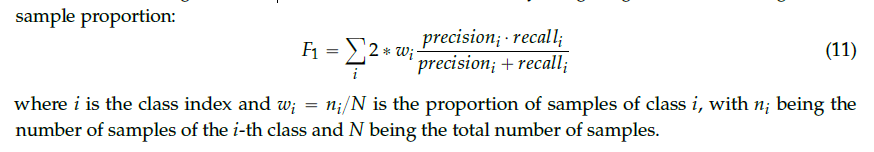
5. Results and Discussion
在本节中,我们介绍结果并讨论结果。 我们展示了这些方法的性能,还评估了它们的一些关键参数,以获取有关这些方法在领域中的适用性的一些见解。
5.1. Performance Comparison
表4和表9分别显示了在OPPORTUNITY数据集和Skoda数据集上提出的深层方法的结果。 对于OPPORTUNITY数据集,我们在此报告分类性能,包括或忽略Null类。 考虑到Null类的普遍性,可能会导致其性能被高估。 通过提供两个结果,我们可以更好地了解模型所产生的错误类型。
表3列出了数据集上使用的已发布分类技术的完整列表。 在“机遇”挑战中竞争的技术都是基于滑动窗口的,仅在分类器和提取的特征上有所不同。
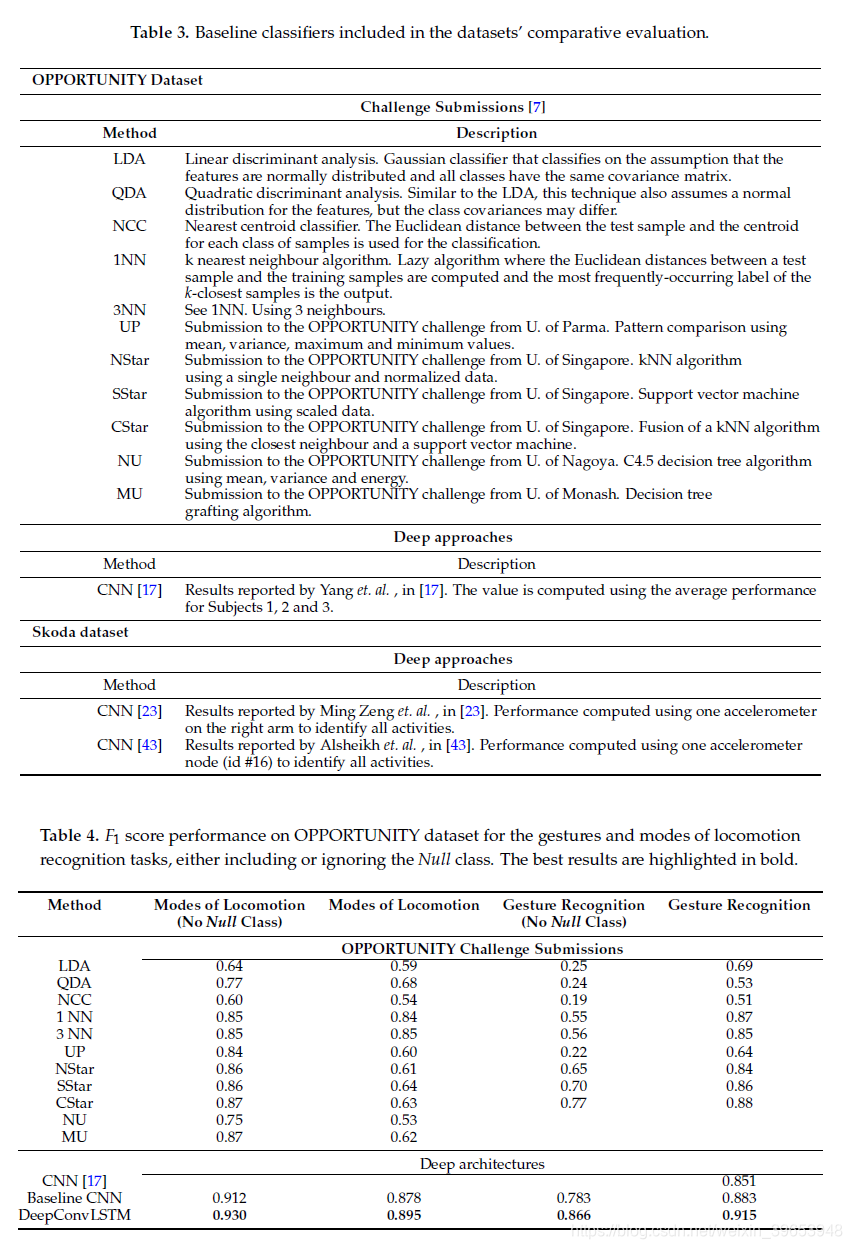
从表4的结果中,我们可以看出DeepConvLSTM在这两个任务上始终优于基线。 与“机会”挑战的最佳提交相比,它的性能平均提高了6%。 对于某些特定任务,可以注意到DeepConvLSTM如何显着提高性能:与机会挑战模型相比,没有Null类的手势识别任务提高了9%以上。 DeepConvLSTM也比Yang等人先前报道的结果提高了6%[17],使用CNN。与机会提交相比,CNN基线在识别运动模型方面也提供了更好的结果。 但是,在手势识别的情况下,它获得与名为CStar的集成方法相似的识别性能。 基线CNN的这些结果与Yang等人先前获得的结果一致。在[17]中,对原始信号数据使用CNN。在深度架构中,DeepConvLSTM系统地表现得比CNN更好,将OPPORTUNITY数据集的性能平均提高了5%。
在图6中,我们说明了OPPORTUNITY数据集上不同体系结构的输出预测中的差异。 该领域的主要挑战之一是活动的自动细分。 基线CNN方法往往会犯更多错误,并且难以做出有关手势边界的明确决定。 定义手势的开始或结束位置很麻烦。
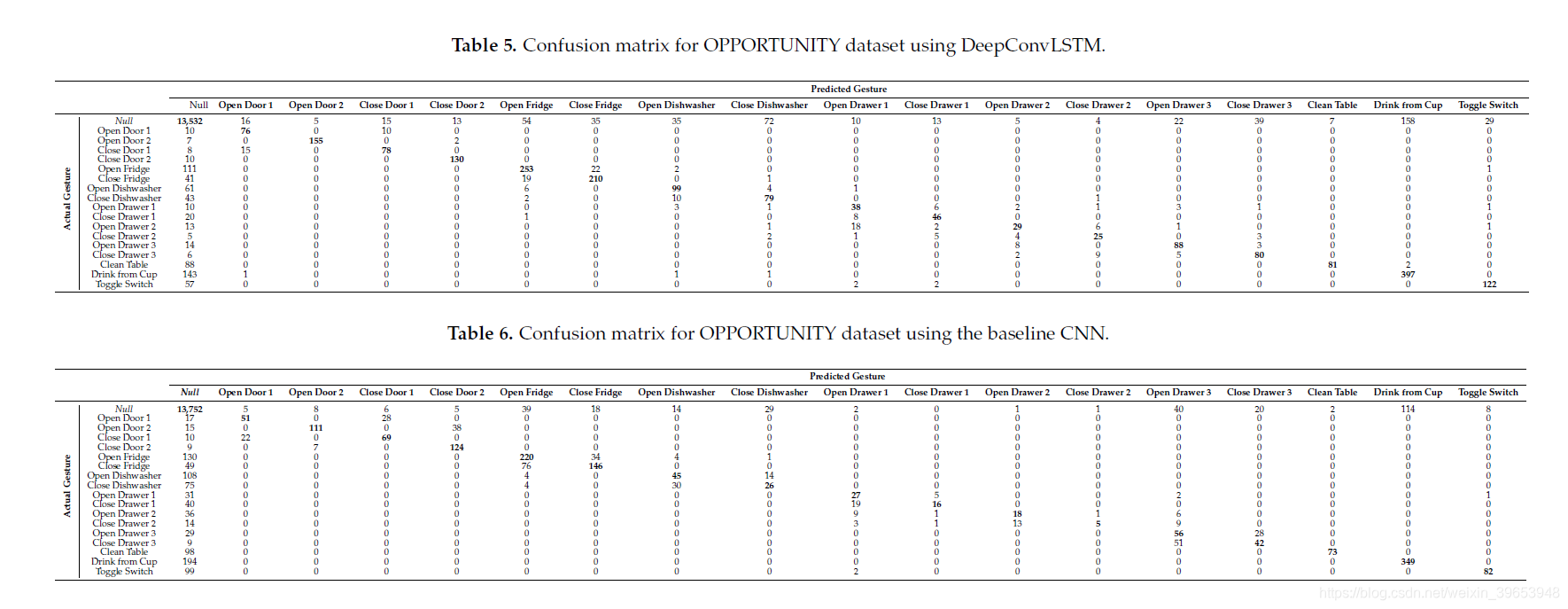
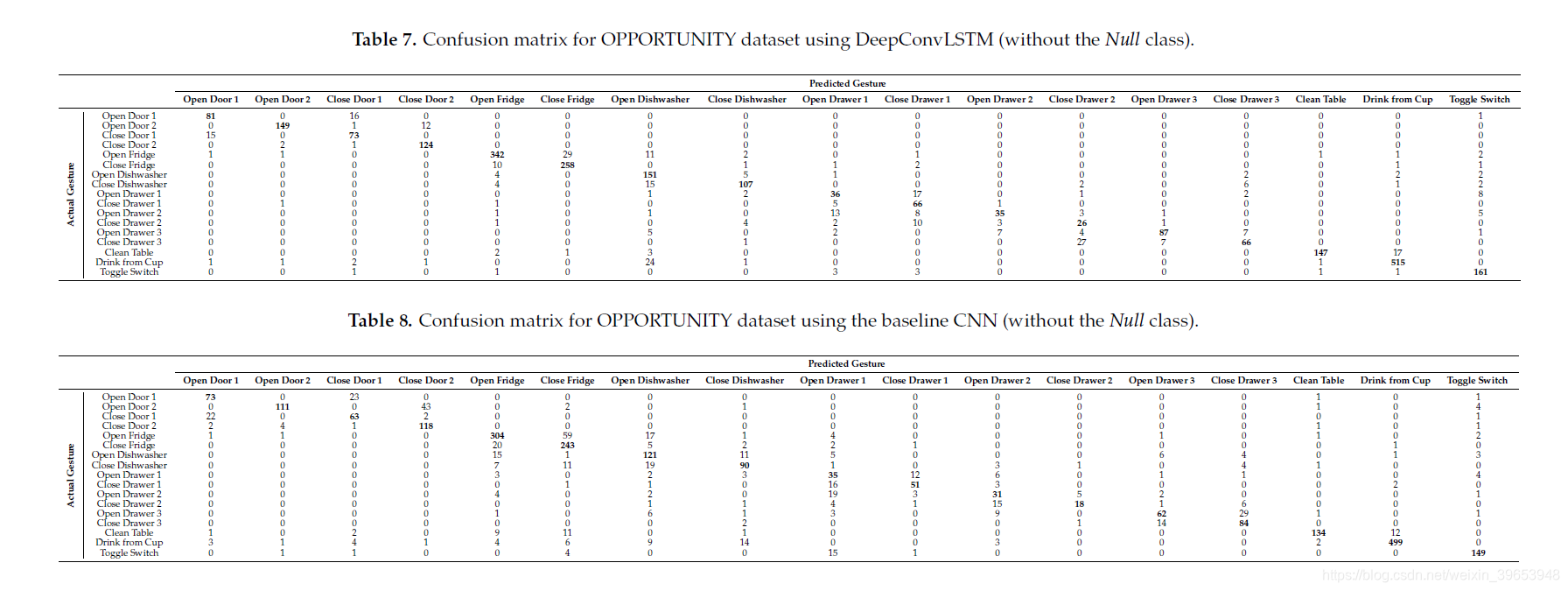
DeepConvLSTM方法的表5和表7以及基线CNN的表6和表8说明了手势识别任务的“机会”数据集上的混淆矩阵。 混淆矩阵包含有关系统完成的实际和预测手势分类的信息,以识别分类错误的性质及其数量。
混淆矩阵中的每个单元格代表将行中的手势分类为列中的手势的次数。 考虑到由于主要的Null类的存在而导致数据类的不平衡,我们报告了包括和忽略Null类在内的混淆矩阵,以便对实际系统性能有更好的了解。
当将Null类包括在识别任务中时(请参见表5和6),大多数分类错误(误报和误报)都与此类别相关。 这是最实际的设置,其中将几乎75%的处理数据(请参见表2)视为不感兴趣的活动。
当从分类任务中删除Null类时(请参见表7和8),两种方法都倾向于对相对相似的手势进行误分类,例如“开门2”-“关门2”或“开冰箱”-“关闭”。 冰箱”。 这可能是因为这些手势涉及激活相同类型的传感器,但顺序不同。 对于“开门2”-“关门2”手势,基线CNN将其中一个错误分类为其他44次,而DeepConvLSTM仅犯了14个错误。
类似地,对于“打开抽屉3”-“关闭抽屉3”手势,基准CNN产生了33个错误,而DeepConvLSTM仅错误分类了14个序列。 DeepConvLSTM对于这些类似手势的更好性能可以通过LSTM单元在处理的数据序列内捕获时间动态的能力来解释。 另一方面,基线CNN仅能建模直至内核长度的时间序列。
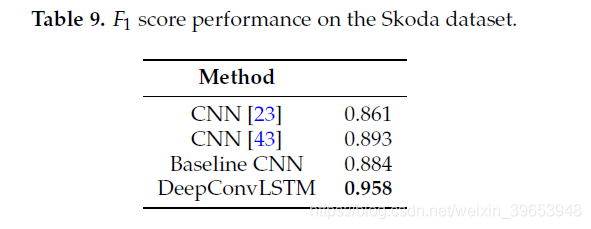
从表9的结果中,我们可以看到DeepConvLSTM优于Skoda数据集上的其他深度非循环方法,将报告的最佳结果提高了6%。 Skoda数据集具有一些特定特征:手势平均很长; 它不包含Null类; 与OPPORTUNITY数据集不同,它具有很好的平衡性。 手势的长度较长不会降低模型的性能。 这些结果证实了我们的发现,支持LSTM的使用在非常不同的场景中带来了显着优势。
5.2. Multimodal Fusion Analysis
穿戴式活动识别可以利用各种传感器。 尽管加速度计往往非常小且功耗很低,但惯性测量单元却更为复杂(结合了加速度计,陀螺仪和磁传感器),但可以提供准确的肢体方向。 因此,重要的是,活动识别框架适用于各种常用的传感器模式,以适应各种尺寸和功率的折衷。
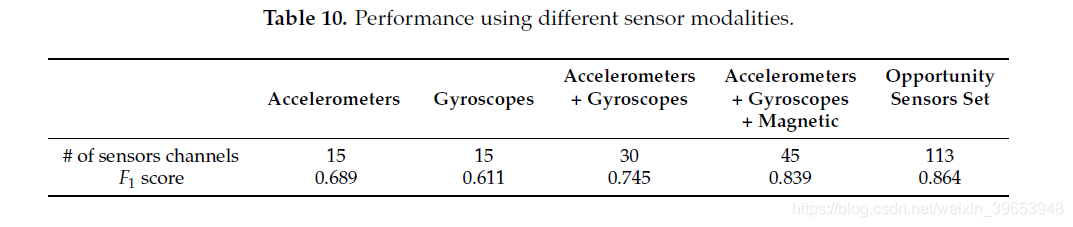
我们评估了卷积层中内核提供的自动特征提取如何适合处理不同模式的传感器信号。 在表10中,我们显示了DeepConvLSTM在识别OPPORTUNITY数据集(不包含Null类)上的手势时对于不同传感器选择的性能。 可以注意到,在没有任何特定预处理的情况下,卷积运算如何可以互换地应用于各个传感器模态。 仅使用数据集上的加速度计从69%的F1分数开始,在将加速度计和陀螺仪融合时,性能平均提高15%,而在将加速度计,陀螺仪和磁传感器融合时,性能平均提高20%。 随着传感器通道数量的增加,无论传感器的模式如何,模型的性能都会不断提高。 这些结果表明,卷积层可以从不同形式的传感器信号中提取特征,而无需临时预处理。
5.3. Hyperparameters Evaluation
我们描述了系统关键超参数的影响。 我们评估了两个关键体系结构参数的影响:网络处理的序列长度和卷积层数。
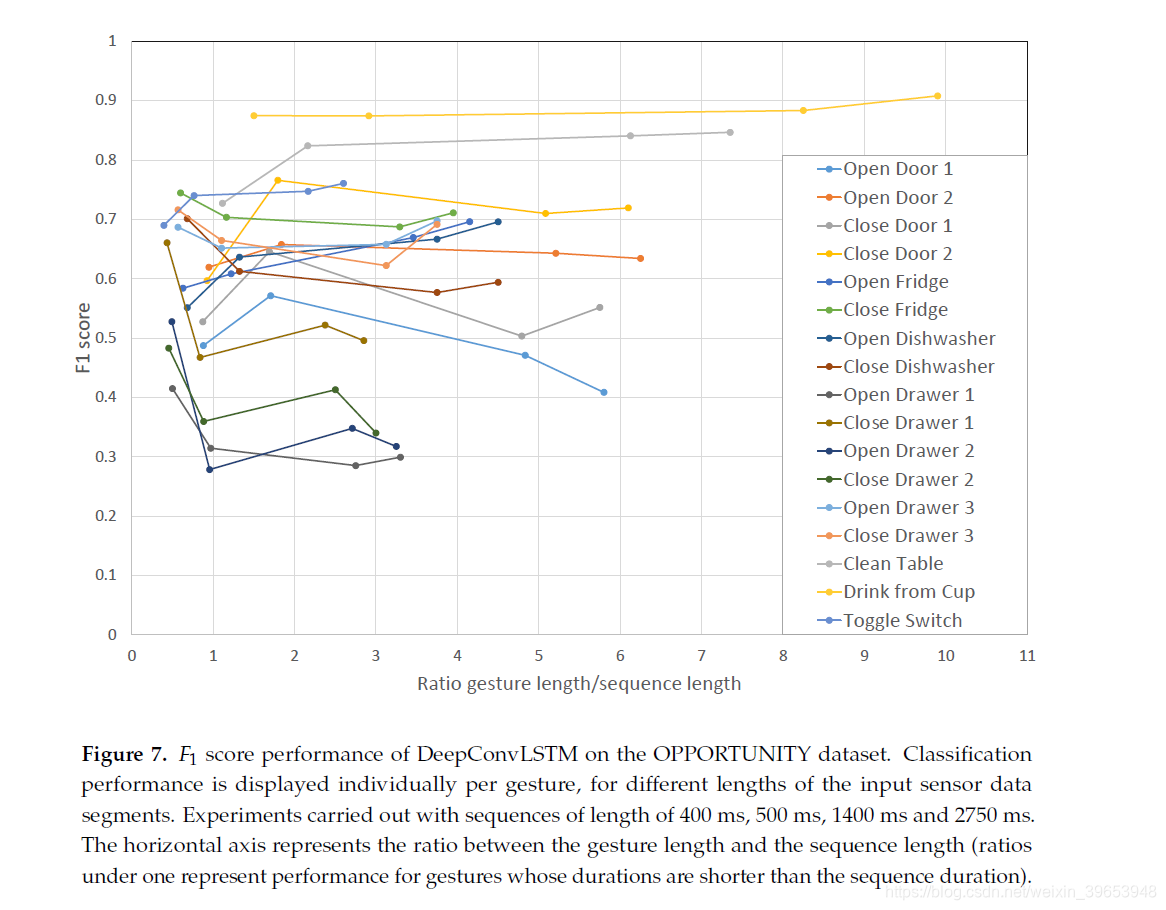
如前所述,循环模型的输入由500毫秒的数据序列组成。因此,梯度信号无法注意到时间依赖性大于此序列的长度。 首先,我们要评估此参数对具有不同持续时间的手势的识别性能的影响,尤其是在手势明显长于或短于序列持续时间的情况下。
数据集各个手势的F1得分如图7所示。该图显示了识别单个手势时的性能,该性能是手势长度和序列长度之间的比率的函数。 小于1的比率表示其持续时间比序列持续时间短的手势的性能,因此,在网络提供输出预测之前,网络可以完全观察到。 除500毫秒外,我们还进行了400毫秒,1400毫秒和2750毫秒长度的序列实验。 对于大多数手势,修改序列的长度时并没有明显的性能变化,尽管较短的手势似乎可以从模型观察到的序列中完全受益。 当多个短手势的比率小于1时,就是这种情况(“打开抽屉1”,“关闭抽屉1”,“打开抽屉2”,“关闭抽屉2”)。当手势持续时间长于序列持续时间时,DeepConvLSTM只能基于序列中特征在时间上展开的局部视图得出分类结果。 但是,结果表明DeepConvLSTM仍然可以获得良好的性能。例如,手势“从杯子喝”(比其中一个实验的序列长10倍)平均可以达到0.9 F1分数。 我们推测这是由于以下事实:较长的手势(如此数据集中的“干净桌子”或“从杯子中喝酒”)可能由几个较短的特征模式组成,即使没有完整的手势,DeepConvLSTM仍可以发现并分类手势视图。
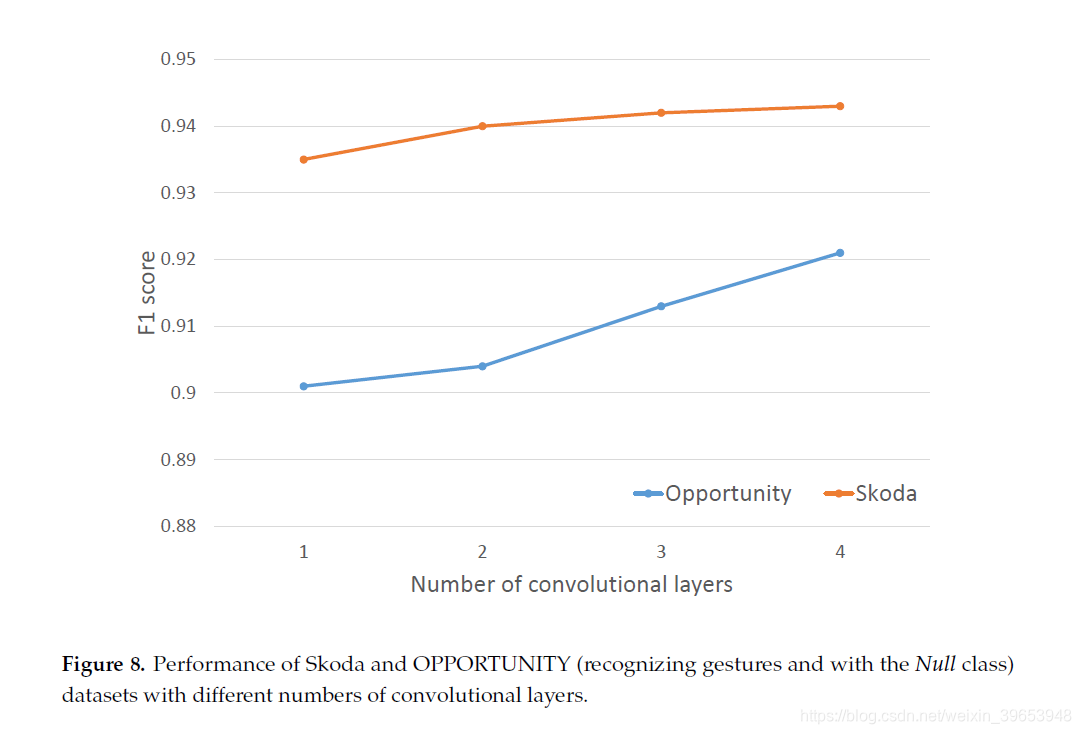
我们表征了用于自动学习特征表示的卷积层数的影响。 图8显示,增加卷积层数往往会提高OPPORTUNITY数据集的性能,在添加新层时提高1%。 在Skoda数据集的情况下,性能变化并不明显,显示出平稳的状态。OPPORTUNITY数据集的结果表明,如果增加卷积运算的数量,性能可能会进一步提高。
5.4. Discussion
使用致密层中的标准前馈单元将我们的新型DeepConvLSTM与基准模型进行直接比较的主要发现是:(i)DeepConvLSTM达到了更高的F1分数; (ii)通过更好地划分活动之间的决策界限,可以提供更好的细分特征; (iii)能够更好地消除与密切相关的活动的歧义,这些活动往往仅按时间序列的顺序而有所不同(例如,“开/关门2”或“开/关抽屉3”); (iv)即使手势比观察窗口长,也适用。 这些发现支持以下假设:基于LSTM的模型利用了学习时态特征激活动力学的优势,而基线模型无法建模。
DeepConvLSTM是和八层深度网络。 其他出版物则显示了更深层的网络,例如“ GoogLeNet”,它是用于图像分类的27层深层神经网络[45]。 确实,图8中显示的发现表明,进一步增加层数可能是有益的,尤其是对于机会数据集。 但是,培训时间会随着层数的增加而增加,并且根据可用的计算资源,未来的工作可能会考虑如何在系统性能和培训时间之间找到折衷方案。 这一点尤其重要,因为深度学习方法往往更适合在“云”基础架构上进行培训,可能使用单个可穿戴设备提供的数据(例如,[46])。 因此,层数的选择不仅取决于所需性能,而且还取决于可用的计算预算。
在文献中,CNN框架通常依次包含卷积和池化层,以此来降低数据复杂性并引入翻译不变性特征。 然而,这种方法并不是严格地属于体系结构的一部分,在时间序列域中,我们可以看到CNN的一些示例,其中并非每个卷积层都有池操作[16]。
DeepConvLSTM不包括池操作,因为网络的输入受到机会挑战所定义的滑动窗口机制的约束,并且此事实限制了对数据进行下采样的可能性,因为DeepConvLSTM需要通过递归层处理数据序列 。 但是,在没有滑动窗口要求的情况下,合并机制对于覆盖更深层的不同传感器数据时标可能很有用。 随着池化层的引入,有可能使不同的卷积层对在不同级别下采样的传感器数据序列起作用。
作为一般准则,我们建议将主要精力集中在优化与网络架构有关的超参数上,这些超参数对性能有重要影响。
实际上,与学习和正则化过程相关的参数似乎对性能的总体影响较小。 例如,我们测试了较高的辍学率(p¡0.5),但在性能方面没有差异。 这些结果与[23]中提出的结果一致。 尽管如此,还是需要权衡性能,如果有一个因素会影响计算方面,则堆叠更多的图层以增强功能的层次表示就可能不相关。
我们展示了卷积运算的鲁棒性足以直接应用于原始传感器数据,以学习在深度框架内成功胜过该问题的先前结果的特征(显着模式)。 使用CNN的主要好处是可以避免手工制作或启发式功能,从而最大程度地减少了工程偏差。 这一点尤其重要,因为活动识别技术已应用于包含更复杂活动或开放式场景的领域,其中分类器必须适应性地对不同数量的类别进行建模。
在数据方面,还值得注意的是,由于实验期间使用的最大训练数据集(对应于OPPORTUNITY数据集)由约80个组成,因此递归模型如何能够使用相对较小的数据集获得非常好的性能。 k个传感器样本,对应于6小时的记录。 这似乎表明,尽管深度学习技术通常用于大量数据(例如,计算机视觉中的数百万个帧[22]),但它们实际上可能适用于获取注释数据非常昂贵的问题领域,例如 在监督活动识别中。
尽管LSTM单元由每个单元中大量的参数组成,但是对于CNN基线模型,参数值的总数明显大于DeepConvLSTM。 对于具有Null类并遵循表1中的等式的OPPORTUNITY数据集的特定情况,DeepConvLSTM的参数由999,122个值组成,而基线CNN参数包含7,445,458个值; 这意味着增加了600%。 如表1所示,大小上的差异是由于卷积层和密集层(第5层和第6层)之间的连接类型所致。 在完全连接的体系结构中,必须将密集层(第6层)中的单元与最后一个特征图(第5层)的每个值连接,这需要非常大的权重矩阵来参数化此连接。 另一方面,递归模型逐样本处理特征图,因此需要大量减少的参数值。 尽管DeepConvLSTM是一种更复杂的方法,但是它由更小的参数组成,这对使用此方法所需的内存和计算工作具有直接的有益影响。
但是,就训练和分类时间而言,尽管DeepConvLSTM的密集层中包含了更复杂的计算单位,但两个模型之间没有如此大的差异。 在机会数据集上对DeepConvLSTM进行训练需要340.3分钟才能收敛,而基线CNN则需要282.2分钟。 基线CNN的分类时间为5.43 s,而DeepConvLSTM需要6.68 s来对整个数据集进行分类。 平均而言,DeepConvLSTM可以在一秒钟内对近15分钟的数据进行分类。 因此,此实现适用于此项工作中使用的GPU上的在线HAR。
我们尚未在可穿戴设备上实现DeepConvLSTM。 即使在高端可穿戴系统(例如,多核智能手机)中,这项工作中使用的GPU显然也超过了当今可用的计算能力。 但是,DeepConvLSTM使用1050 MHz的1664 GPU内核,可实现900实时的识别速度。 高端移动平台已经包含可用于通用处理的GPU [47]。 高通Snapdragon 820等移动处理器包括以650 MHz运行的256个GPU内核,并支持用于通用GPU计算的OpenCL配置文件。 虽然内核的功能不同,但是可用的计算能力可能足够25,足以在即将到来的移动设备中进行实时识别。 但是,最好在服务器端进行培训(例如[46]中的培训)。
如果要识别的活动集随时间变化,例如随着其他标记数据的出现(例如,通过众包[48]),则通过利用卷积层来消除对工程特征的依赖就显得尤为重要。 在这种“开放式”学习方案中,在最初部署系统后可以增加类的数量,可以将梯度的反向传播到卷积层用于在运行时根据新数据递增地适应内核。 未来的工作可能会考虑此类网络的开放式学习限制,并研究增加网络规模(例如添加新内核)以维持所需表示能力的规则。
6. Conclusions
在本文中,我们展示了基于卷积层和LSTM递归层的组合的深度架构的优势,该深度架构可从可穿戴传感器执行活动识别。 这个新框架的性能优于以往日常活动机会数据集中的平均结果,在18类手势识别任务中的平均结果为9%。 对于斯柯达汽车制造活动数据集,它的表现优于以前的深度非经常性方法,将最佳报告分数提高了6%。 这扩展了卷积和循环单元统一框架的已知适用性领域,这在可穿戴传感器数据上从未报道过。
在时间要求方面,与标准CNN相比,循环体系结构在性能和训练/识别时间之间提供了很好的折衷。 确实,循环体系结构的训练和识别时间仅增加了20%。
我们证明了循环LSTM单元对于区分一个相似类型的手势(例如“打开/关闭门2”或“打开/关闭抽屉3”)至关重要,这些手势仅因传感器样本的顺序而不同。 相比之下,CNN基准模型在诸如“开/关门2”或“开/关抽屉3”之类的活动上提供的性能要差得多,在该活动中,其错误率提高了2-3倍。 卷积内核仅能够捕获内核持续时间内的时间动态。 相比之下,循环LSTM细胞没有此限制,并且可以根据其学习的参数来学习各种(可能更长)的时间尺度上的时间动态。 此外,当直接比较时,我们已经展示了循环架构如何提供比标准CNN更好的细分特征,并且能够更精确地定义活动边界。 这些发现支持以下假设:基于LSTM的模型利用了学习时间特征激活动力学的优势,而CNN尚不能完全建模。

【毕业论文查到自己的CSDN博客,真是太冤了!!!】
作为未来的工作,我们将研究基于这些模型的转移学习方法,以对大型数据执行活动识别。 我们建议重用在基准数据集上训练的内核进行特征提取。 这种潜在的功能转移将简化活动识别器在云基础架构上的部署。
DeepConvLSTM的代码和模型参数可从[49]获得。
Acknowledgments
这项工作部分由Google Faculty Research Award赠款资助,“深度学习对可穿戴活动的识别有用吗?” 以及英国EPSRC优先拨款EP / N007816 / 1“生命学习:无限的活动和情境意识”。 该出版物受多个数据集的支持,这些数据集可在参考部分中引用的位置处公开获得。
作者贡献:Francisco JavierOrdóñez概念化并实现了深层框架,执行了实验工作,分析了结果,起草了原始手稿并修改了手稿。Daniel Roggen概念化了深层框架,分析了结果,提供了反馈,修订了手稿并批准了提交的最终手稿。
利益冲突:作者声明没有利益冲突。
References
- Rashidi, P.; Cook, D.J. The resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man.
Cybern. J. Part A 2009, 39, 949–959. - Patel, S.; Park, H.; Bonato, P.; Chan, L.; Rodgers, M. A review of wearable sensors and systems with
application in rehabilitation. J. NeuroEng. Rehabil. 2012, 9, doi:10.1186/1743-0003-9-21. - Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity Recognition Using
Inertial Sensing for Healthcare, Wellbeing and Sports Applications: A Survey. In Proceedings of the
23rd International Conference on Architecture of Computing Systems (ARCS), Hannover, Germany, 22–23
Febuary 2010; pp. 1–10. - Mazilu, S.; Blanke, U.; Hardegger, M.; Tröster, G.; Gazit, E.; Hausdorff, J.M. GaitAssist: A Daily-Life
Support and Training System for Parkinson’s Disease Patients with Freezing of Gait. In Proceedings
of the ACM Conference on Human Factors in Computing Systems (SIGCHI), Toronto, ON, Canada,
26 April–1 May 2014. - Kranz, M.; Möller, A.; Hammerla, N.; Diewald, S.; Plötz, T.; Olivier, P.; Roalter, L. The mobile fitness coach:
Towards individualized skill assessment using personalized mobile devices. Perv. Mob. Comput. 2013,
9, 203–215. - Stiefmeier, T.; Roggen, D.; Ogris, G.; Lukowicz, P.; Tröster, G. Wearable Activity Tracking in Car
Manufacturing. IEEE Perv. Comput. Mag. 2008, 7, 42–50. - Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.; Millán, J.; Roggen, D.; Tröster, G. The Opportunity
challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013,
34, 2033–2042. - Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial
Sensors. ACM Comput. Surv. 2014, 46, 1–33. - Roggen, D.; Cuspinera, L.P.; Pombo, G.; Ali, F.; Nguyen-Dinh, L. Limited-Memory Warping LCSS for
Real-Time Low-Power Pattern Recognition in Wireless Nodes. In Proceedings of the 12th European
Conference Wireless Sensor Networks (EWSN), Porto, Portugal, 9–11 February 2015; pp. 151–167. - Ordonez, F.J.; Englebienne, G.; de Toledo, P.; van Kasteren, T.; Sanchis, A.; Krose, B. In-Home Activity
Recognition: Bayesian Inference for Hidden Markov Models. Perv. Comput. IEEE 2014, 13, 67–75. - Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.J.; Howard, D.; Meijer, K.; Crompton, R. Activity identification
using body-mounted sensors: A review of classification techniques. Physiol. Meas. 2009, 30, 21–27. - Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M.P. Preprocessing techniques for context recognition from
accelerometer data. Perv. Mob. Comput. 2010, 14, 645–662. - Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional Deep Belief Networks for Scalable Unsupervised
Learning of Hierarchical Representations. In Proceedings of the 26th Annual International Conference on
Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. - Lee, H.; Pham, P.; Largman, Y.; Ng, A. Unsupervised feature learning for audio classification using
convolutional deep belief networks. In Proceedings of the 22th Annual Conference on Advances in Neural
Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–10 December 2008; pp. 1096–1104. - LeCun, Y.; Bengio, Y. Chapter Convolutional Networks for Images, Speech, and Time Series. In The Handbook
of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. - Sainath, T.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep
Neural Networks. In Proceedings of the 40th International Conference on Acoustics, Speech and Signal
Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. - Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks On
Multichannel Time Series For Human Activity Recognition. In Proceedings of the 24th International Joint
Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. - Siegelmann, H.T.; Sontag, E.D. Turing computability with neural nets. Appl. Math. Lett. 1991, 4, 77–80.
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks.
J. Mach. Learn. Res. 2003, 3, 115–143. - Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In
Proceeedings of the 38th International Conference on Acoustics, Speech and Signal Processing, Vancouver,
BC, USA, 26–31 May 2013; pp. 6645–6649. - Palaz, D.; Magimai.-Doss, M.; Collobert, R. Analysis of CNN-based Speech Recognition System using Raw
Speech as Input. In Proceedings of the 16th Annual Conference of International Speech Communication
Association (Interspeech), Dresden, Germany, 6–10 September 2015; pp. 11–15. - Pigou, L.; Oord, A.V.D.; Dieleman, S.; van Herreweghe, M.; Dambre, J. Beyond Temporal Pooling: Recurrence
and Temporal Convolutions for Gesture Recognition in Video. arXiv Preprint 2015, arXiv:1506.01911. - Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.;Wu, P.; Zhang, J. Convolutional Neural Networks for
human activity recognition using mobile sensors. In Proceedings of the 6th IEEE International Conference
on Mobile Computing, Applications and Services (MobiCASE), Austin, TX, USA, 6–7 November 2014;
pp. 197–205. - Oord, A.V.D.; Dieleman, S.; Schrauwen, B. Deep content-based music recommendation. In Proeedings of the
Neural Information Processing Systems, Lake Tahoe, NE, USA, 5–10 December 2013; pp. 2643–2651. - Sainath, T.N.; Kingsbury, B.; Saon, G.; Soltau, H.; Mohamed, A.R.; Dahl, G.; Ramabhadran, B. Deep
convolutional neural networks for large-scale speech tasks. Neural Netw. 2015, 64, 39–48. - Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks.
In Proceedings of the 25th Conference on Advances in Neural Information Processing Systems (NIPS), Lake
Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. - Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition,
localization and detection using convolutional networks. Cornell Univ. Lib. 2013, arXiv:1312.6229. - Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Zurich, Switzerland, 6–12 September
2014; pp. 1653–1660. - Deng, L.; Platt, J.C. Ensemble deep learning for speech recognition. In Proceedings of the 15th
Annual Conference of International Speech Communication Association (Interspeech), Singapore, 14–18
September 2014; pp. 1915–1919. - Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets:
Deep networks for video classification. Cornell Univ. Lab. 2015, arXiv:1503.08909. - Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006,
313, 504–507. - Plötz, T.; Hammerla, N.Y.; Olivier, P. Feature Learning for Activity Recognition in Ubiquitous Computing.
In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain,
16–22 July 2011; pp. 1729–1734. - Karpathy, A.; Johnson, J.; Li, F.F. Visualizing and understanding recurrent networks. Cornell Univ. Lab. 2015,
arXiv:1506.02078. - Dieleman, S.; Schlüter, J.; Raffel, C.; Olson, E.; Sønderby, S.K.; Nouri, D.; Maturana, D.; Thoma, M.; Battenberg,
E.; Kelly, J.; et al. Lasagne: First Release; Zenodo: Geneva, Switzerland, 2015. - Dauphin, Y.N.; de Vries, H.; Chung, J.; Bengio, Y. RMSProp and equilibrated adaptive learning rates for
non-convex optimization. arXiv 2015, arXiv:1502.04390 - Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.;
Ferscha, A.; et al. Collecting complex activity data sets in highly rich networked sensor environments.
In Proceedings of the 7th IEEE International Conference on Networked Sensing Systems (INSS), Kassel,
Germany, 15–18 June 2010; pp. 233–240. - Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings
of the 16th International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012;
pp. 108–109. - Zappi, P.; Lombriser, C.; Farella, E.; Roggen, D.; Benini, L.; Tröster, G. Activity recognition from on-body
sensors: accuracy-power trade-off by dynamic sensor selection. In Proceedings of the 5th European
Conference onWireless Sensor Networks (EWSN), Bologna, Italy, 30 January–1 February 2008; pp. 17–33. - Banos, O.; Garcia, R.; Holgado, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid:
a novel framework for agile development of mobile health applications. In Proceedings of the 6th
InternationalWork-conference on Ambient Assisted Living an Active Ageing, Belfast, UK, 2–5 December
2014; pp. 91–98. - Gordon, D.; Czerny, J.; Beigl, M. Activity recognition for creatures of habit. Pers. Ubiquitous Comput. 2014,
18, 205–221. - Opportunity Dataset. 2012. Available online: https://archive.ics.uci.edu/ml/datasets/OPPORTUNITY
+Activity+Recognition (accessed on 19 November 2015). - Skoda Dataset. 2008. Available online: http://www.ife.ee.ethz.ch/research/groups/Dataset (accessed on 19
November 2015). - Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with
Triaxial Accelerometers. arXiv preprint 2015, arXiv:1511.04664. - Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002,
6, 429–449. - Szegedy, C.; Liu,W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.
Going DeeperWith Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. - Berchtold, M.; Budde, M.; Gordon, D.; Schmidtke, H.R.; Beigl, M. Actiserv: Activity recognition service for
mobile phones. In Proceedings of the International Symposium on Wearable Computers (ISWC), Seoul,
Korea, 10–13 October 2010; pp. 1–8. - Cheng, K.T.; Wang, Y.C. Using mobile GPU for general-purpose computing: A case study of face recognition
on smartphones. In Proceedings of the International Symposium on VLSI Design, Automation and Test
(VLSI-DAT), Hsinchu, Taiwan, 25–28 April 2011; pp. 1–4. - Welbourne, E.; Tapia, E.M. CrowdSignals: A call to crowdfund the community’s largest mobile dataset.
In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing,
ACM, Seattle, WA, USA, 13–17 September 2014; pp. 873–877. - Ordonez, F.J.; Roggen, D. DeepConvLSTM. Available online: https://github.com/sussexwearlab/
DeepConvLSTM (accessed on 23 December 2015).
c 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access
article distributed under the terms and conditions of the Creative Commons by Attribution
(CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- NLP:《NLP Year in Review 2019NLP_2019_Highlights》2019年自然语言处理领域重要进展回顾及其解读
NLP:《NLP Year in Review 2019&NLP_2019_Highlights》2019年自然语言处理领域重要进展回顾及其解读 导读:2019年是自然语言处理(NLP)领域令人印象深刻的一年。在这份报告中,我想重点介绍一些我在2019年遇到的关于机器学习和NLP的最重要的…...
2024/4/14 11:11:29 - 计算机视觉领域经典论文源码
计算机视觉领域经典论文源码 转载自:http://blog.csdn.net/ddreaming/article/details/52416643 2016-CVPR论文代码资源: https://tensortalk.com/?catconference-cvpr-2016 一个GitHub账号,里面有很多计算机视觉领域最新论文的代码实现&am…...
2024/4/13 17:52:34 - 深度学习如何入门?
beanfrog ,computer vision161 人赞同先了解个大概A Deep Learning Tutorial: From Perceptrons to Algorithms神经网络肯定是要学习的,主要是BP算法,可以看看PRML3、4、5三章,可先忽略其中的贝叶斯视角的解释。一些主要的算法理解…...
2024/4/14 10:36:59 - AI - 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
本文转自: http://blog.csdn.net/zhongwen7710/article/details/45331915列出的内容比较多,我自己还在看。我计划接下来看能否按照类别和难易程度做下整理,方便网友们查看。《微软PowerBI商业智能数据可视化》-还有視頻教程。微软Power BI是目…...
2024/4/18 16:49:31 - Models in TensorFlow from GitHub
转载网址:http://note.youdao.com/share/?id71216576910b7a6cd6f2a0f2ebf8faa2&typenote#/ —— 感谢AI研习社的分享 Models in TensorFlow from GitHub 图像处理/识别 1.PixelCNN &PixelRNN in TensorFlow TensorFlowimplementation of Pixel Rec…...
2024/4/14 15:07:59 - 【人脸对齐-Landmarks】人脸关键点检测方法及评测汇总
好东西往往都在最后面,请耐心向下滑 传统方法: 1. SDM:Supervised descent method and its applications to face alignment. CVPR2013 速度: CPU(i7) - 小于12ms精度: 评测数据集1---300w (Inter-pupil Normalisati…...
2024/4/14 10:37:14 - AI视频换脸软件——仅供学习
视频换脸软件分析 学习方法自己找,贴吧百度。 一个学习地址:deepfakes 中文站 http://deepfakes.com.cn/ 1.Fakeapp 系统:Win7, Win10 优点:容易使用,集成GUI图形界面,环境安装比较简单,只要下…...
2024/4/19 19:42:57 - 换脸开源项目faceswap在centos的实现
富强 民主 文明 和谐 自由 平等 公正 法治 爱国 敬业 诚信 友善 文章目录项目介绍项目地址数据获取环境搭建conda和tensorflow项目环境安装ffmpeg工作流程文件夹规则定义操作步骤1、抽取脸部特征2、人工筛选3、训练模型4、调用模型进行换脸补充使用频繁的linux命令服务器环境&a…...
2024/4/14 11:14:01 - Object detection with deep learning and OpenCV
目录 Single Shot Detectors for Object DetectionDeep learning-based object detection with OpenCV这篇文章只是基于OpenCV使用SSD算法执行目标检测;不涉及到SSD的理论原理、不涉及训练过程;也就是说仅仅使用训练好的模型文件基于OpenCV做测试&#x…...
2024/4/19 14:21:33 - OpenFaceswap 入门教程(1):软件安装篇
众多换脸软件中,DeepFaceLab其实是安装和使用最方便,更新最快的,但是由于其没有可是化界面,对于很新手来说,可能入门还是有点难度。那么今天就来介绍一款操作极其直观和简单的换脸软件OpenFaceSwap。这款软件的安装和使…...
2024/4/14 10:37:14 - deep neural_使用Core ML,Swift,Neural Engine在iOS中进行设备上的机器学习
deep neural介绍 (Introduction) Core ML is a Machine Learning Library launched by Apple in WWDC 2017.Core ML是Apple在WWDC 2017中推出的机器学习库。 It allows iOS developers to add real-time, personalized experiences with industry-leading, on-device machine …...
2024/4/14 10:37:29 - 跑深度模型的显卡_A100跑DeepFaceLab,日迭代破百万,像素上800!
昨天用滴滴云的A100做了下TenorFlow的基准测试,可能略显抽象!今天来跑跑DeepFaceLab,整体来说A100还是挺强!已经连续看了两天命令行和数字了,头围有所增加!环境配置:主角:A100-SXM4-…...
2024/4/14 10:37:19 - 各大短视频平台换脸视频背后的技术揭秘及deepfacelab教程
1.抖音等各大短视频平台是如何进行换脸? 1.1 以前主流换脸框架 1.1.1 FakeAPP,是国内网络上广告最火的换脸软件,但是有水印,而且好像2.2版本还有极大的不安全后门,反正我早就不用了。 1.1.2 OpenFaceswap࿰…...
2024/4/19 15:26:01 - Deepfacelab(换脸软件)v2018.12.2官方安装版
Deepfacelab是一款知名的换脸软件,也可以说是目前最好玩的换脸软件,但没有GUI,目前这款软件仅支持A卡,虽然看起来比较难,但跑过一次后就会上手! 使用方法: 解压开你会发现Deepfacelab文件夹内有…...
2024/4/19 13:45:23 - 使用colab运行deepface实现换脸视频示例流程
代码参考使用的是来自github:https://github.com/dream80/DeepFaceLab_Colab 示例流程仅供参考学习,不要用于非法用途哦!!! 1.打开colab,挂载谷歌云盘。点击圆圈中的小标志就可以,然后按提示操作就可以。 …...
2024/4/19 15:34:50 - 【转载】关于文献阅读和科研选题
本文转载自程明明老师博客:https://mmcheng.net/paperreading/ 对于论文的阅读和研究脉络的梳理很清晰,特别是在于找研究方向的建议上:从开山文献开始,会到当事人的角度去思考,然后逐步阅读后面的文献再思考&#x…...
2024/4/14 10:37:55 - Res2Net: A New Multi-scale Backbone Architecture(多尺度骨干网络)
Res2Net: A New Multi-scale Backbone Architecture Shang-Hua Gao∗, Ming-Ming Cheng∗, Kai Zhao, Xin-Y u Zhang, Ming-Hsuan Y ang, and Philip T orr 多尺度特征的抽象表示对于许多视觉任务都具有重要意义。骨干卷积神经网络(CNNs)的最新进展不断…...
2024/4/14 10:37:45 - [转]2020 年最具潜力 44 个顶级开源项目,涵盖 11 类 AI 学习框架、平台(值得收藏)
导语:Github 开源项目技术图 雷锋网 AI 开发者按:工欲善其事必先利其器,这也是大部分开发者在日常工作中最重要开发原则。选择与开发内容相匹配的工具,常常会使我们事半功倍。但面对人工智能的多个领域,如ÿ…...
2024/4/14 10:38:05 - 视觉世界中的“众里寻她”--开放环境下的人物特征表示
编者按:辛弃疾在《青玉案.元夕》中曾这样写道,“众里寻她千百度,蓦然回首,那人却在,灯火阑珊处。” 其实在视觉理解领域,这半阙词,描绘的即是,在熙熙攘攘的视觉世界中,通过剥离场景,只关注所关心的那个她的过程 。 如果能够更好地对“她”进行表示,将直接影响到相关…...
2024/4/14 10:38:15 - 可怜张继科没夺冠
B - BTime Limit:1000MS Memory Limit:65535KB 64bit IO Format:%I64d & %I64u Submit Status Practice HDU 4815Description A crowd of little animals is visiting a mysterious laboratory – The Deep Lab of SYSU. “Are you surprised by the STS (speech t…...
2024/4/14 10:37:45
最新文章
- 跨境电商指南:防关联浏览器和云主机有什么区别?
跨境电商的卖家分为独立站卖家和平台卖家。前者会自己开设独立站点,比如通过 shopify;后者则是入驻亚马逊或 Tiktok 等平台,开设商铺。其中平台卖家为了扩大收益,往往不止开一个店铺,或者有店铺代运营的供应商…...
2024/4/20 6:23:11 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 机器学习——模型融合:平均法
机器学习——模型融合:平均法 在机器学习领域,模型融合是一种通过结合多个基本模型的预测结果来提高整体模型性能的技术。模型融合技术通常能够降低预测的方差,提高模型的鲁棒性,并在一定程度上提高预测的准确性。本文将重点介绍…...
2024/4/19 15:45:44 - 第N6周:使用Word2vec实现文本分类
import torch import torch.nn as nn import torchvision from torchvision import transforms,datasets import os,PIL,pathlib,warnings #忽略警告信息 warnings.filterwarnings("ignore") # win10系统 device torch.device("cuda"if torch.cuda.is_ava…...
2024/4/18 2:22:40 - Hive的安装
1.上传安装包 解压 tar zxvf apache-hive-3.1.2-bin.tar.gz# 解决Hive与Hadoop之间guava版本差异 cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/2.修改配置文件 h…...
2024/4/16 23:09:14 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/19 14:24:02 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/19 18:20:22 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/19 11:57:31 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/19 11:57:31 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/19 11:57:52 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/19 11:57:53 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/19 11:58:14 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/19 11:58:20 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/19 23:45:49 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/19 11:58:39 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/19 11:58:51 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/20 3:12:02 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/19 11:59:15 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/19 11:59:23 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/19 11:59:44 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/19 11:59:48 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/19 12:00:06 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/19 16:57:22 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/19 12:00:25 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/19 12:00:40 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57