深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读
早期成果
卷积神经网络是各种深度神经网络中应用最广泛的一种,在机器视觉的很多问题上都取得了当前最好的效果,另外它在自然语言处理,计算机图形学等领域也有成功的应用。
第一个真正意义上的卷积神经网络由LeCun在1989年提出[1],后来进行了改进,它被用于手写字符的识别,是当前各种深度卷积神经网络的鼻祖。接下来我们介绍LeCun在早期提出的3种卷积网络结构。
文献[1]的网络由卷积层和全连接层构成,网络的输入是16x16的归一化图像,输出为0-9这10个类,中间是3个隐含层。这个网络的结构如下图所示:
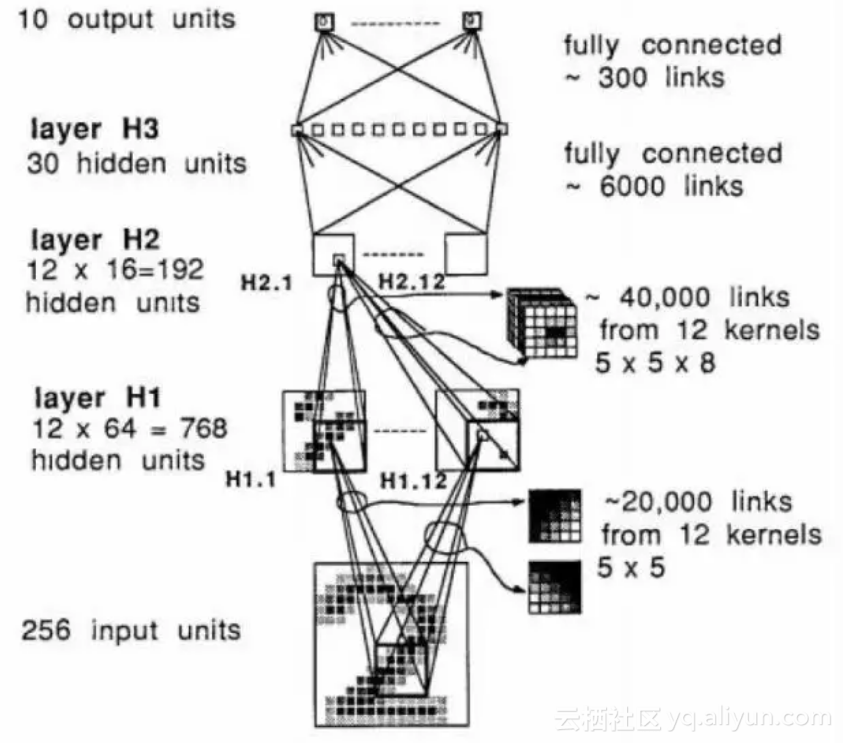
这篇文章提出了权重共享(weight sharing)和特征图像(feature map)的概念,这些概念被沿用至今,就是卷积层的原型。网络有1个输入层,1个输出层,3个隐含层构成,其中隐含层H1和H2是卷积层,H3是全连接层。网络的激活函数选用了tanh(双曲正切)函数,损失函数选用了均方误差(mean squared error)函数,即欧氏距离的均值。网络的权重用均匀分布的随机数进行初始化,训练时参数梯度值的计算采用了反向传播算法,梯度值的更新采用了在线(online)的随机梯度下降法。
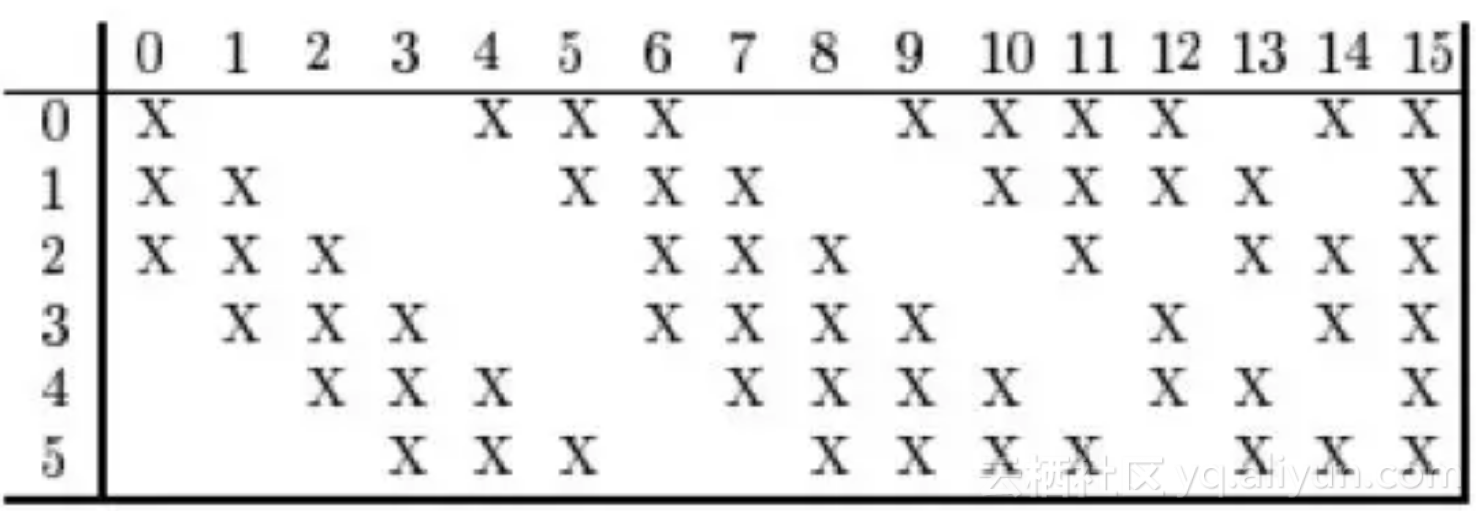
文献[2]的网络结构和文献[1]类似,用于邮政编码的识别,在9%拒识率的条件下错误率为1%。网络的输入为28x28的图像,输出为0-9这10个类。整个网络有4个隐含层,其中H1为4个5x5的卷积核,输出为4张24x24的特征图像。H2为下采样层,对H1的输出结果进行2x2的下采样,得到4张12x12的图像。H3有12个5x5的卷积核,输出为12张8x8的图像,这里输出图像每个通道的多通道卷积只作用于前一层输出图像的部分通道上,为什么采用这样方式?有两个原因:1.减少参数,2.这种不对称的组合连接的方式有利于提取多种组合特征。H2和H3的连接关系如下图所示:
H4为下采样层,对H3的输出图像进行2x2的下采样,得到12张4x4的特征图像。最后为输出层,接收H4特特征图像,输出10个类别的概率。
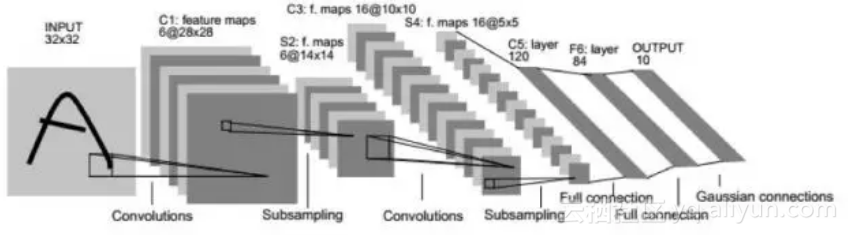
文献[3]的网络即为LeNet-5网络,这是第一个被广为流传的卷积网络,整个网的结构如下图所示:
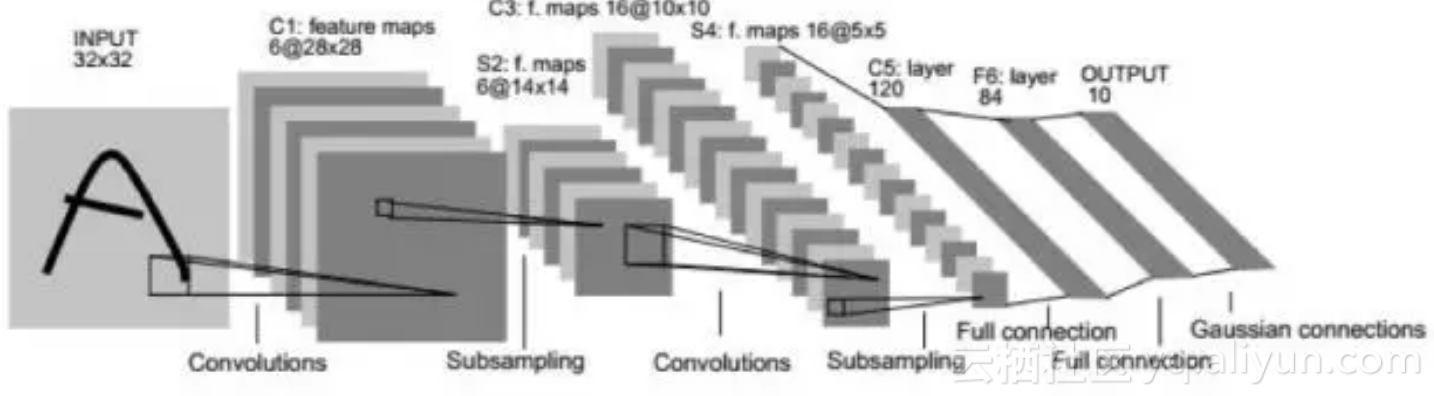
下面是基于LeNet-5的手写体数字识别案例:

这个网络的输入为32x32的图像,整个网络有2个卷层,2个池化层,2个全连接层,一个输出层,输出层有10个神经元,代表10个数字类。卷积层C1有6个5x5的卷积核,作用于灰度图像,产生6张28x28的输出图像。池化层S2作用于C1的输出图像,执行2x2的池化,产生6张14x14的输出图像。卷积层C3有16个5x5的卷积核,每个卷积核作用于前一层输出图像的部分通道上,产生16张10x10的输出图像。C3和S2的连接关系如下图所示:
池化层S4对C3的输出图像进行2x2的池化,得到16张5x5的输出图像。全连接层C5有120个节点,全连接层F6有64个节点。
网络的激活函数选用tanh函数,损失函数采用均方误差函数,训练时采用随机梯度下降法和反向传播算法。
早期的卷积网络被用于人脸检测[4][5],人脸识别[6],字符识别[7]等各种问题。但并没有成为主流的方法,其原因主要是梯度消失问题、训练样本数的限制、计算能力的限制3方面因素。梯度消失的问题在之前就已经被发现,对于深层神经网络难以训练的问题,文献[8]进行了分析,但给出的解决方法没有成为主流。
深度卷积神经网络
在深入分析比较当前主流深度卷积神经网络的特点之前,我们从各网络在ImageNet 2012测试数据集的准确率以及网络的参数量和计算复杂度三个维度进行分析,希望读者对当前的主流网络结构有一个整体的认知。如下图所示:
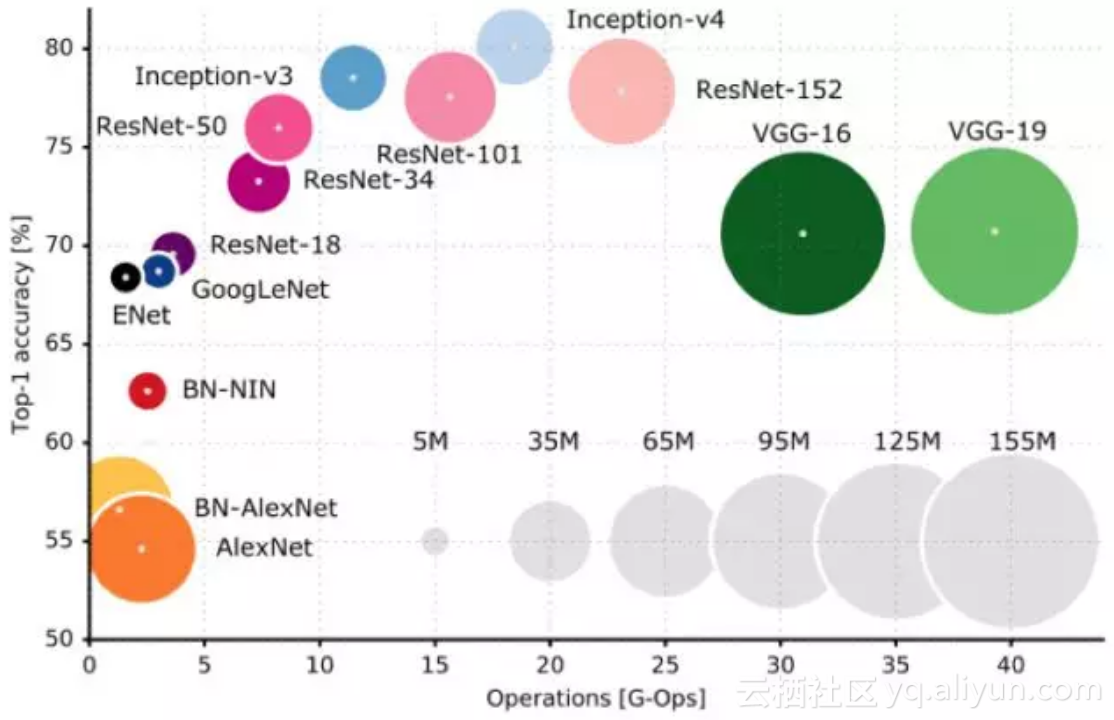
深度卷积网络的大发展起步于2012年的AlexNet网络,在这之后各种改进的网络被不断的提出,接下来我们会介绍各种典型的网络结构。
AlexNet网络
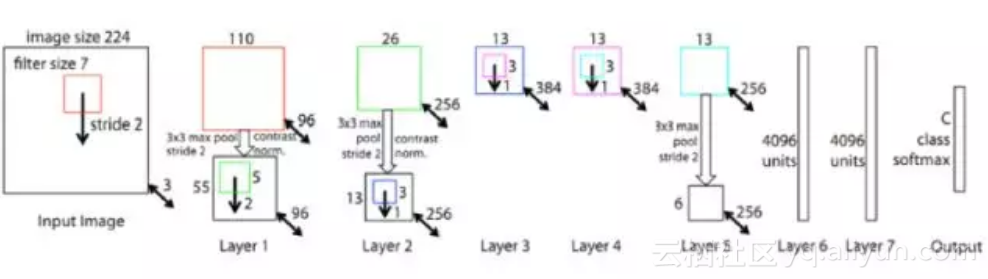
现代意义上的深度卷积神经网络起源于AlexNet网络[9],它是深度卷积神经网络的鼻祖。这个网络相比之前的卷积网络最显著的特点是层次加深,参数规模变大。网络结构如下图所示:
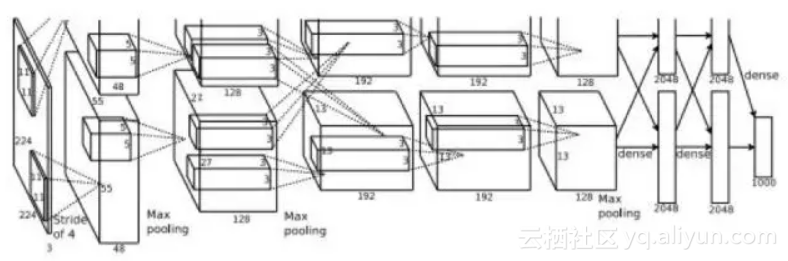
这个网络有5个卷积层,它们中的一部分后面接着max-pooling层进行下采样;最后跟3个全连接层。最后一层是softmax输出层,共有1000个节点,对应ImageNet图集中 1000个图像分类。网络中部分卷基层分成2个group进行独立计算,有利于GPU并行化以及降低计算量。
这个网络有两个主要的创新点:1. 新的激活函数ReLU,2. dropout机制[10]。dropout的做法是在训练时随机的选择一部分神经元进行休眠,另外一些神经元参与网络的优化,起到了正则化的作用以减轻过拟合。
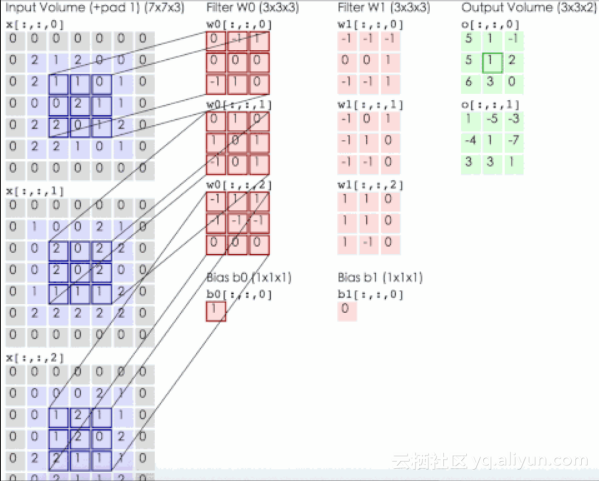
网络的输入图像为的彩色三通道图像。第1个卷积层有96组11x11大小的卷积核,卷积操作的步长为4。这里的卷积核不是2维而是3维的,每个通道对应有3个卷积核(所以是一组卷积核),具体实现时是用3个2维的卷积核分别作用在RGB通道上,然后将三张结果图像相加。下图为输入为3通道,卷积层参数为2组每组3个卷积核,输出结果为2通道的动态卷积过程
第2个卷积层有256组5x5大小的卷积核,分为两个group,即每个group通道数为128组,每组有48个卷积核。第3个卷积层有384组3x3大小的卷积核,每组有256个卷积核。第4个卷积层有384组3x3大小的卷积核,分为两个group,即每个group通道数为192组,每组有192个卷积核。第5个卷积层有256组,3x3大小的卷积核,分为两个group,即每个group为128组,每组有192个卷积核。
这个网络没有使用传统的sigmoid或tanh函数作为激活函数,而是使用了新型的ReLU函数[11]:
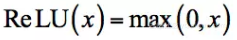
其导数为符号函数sgn。ReLU函数和它的导数计算简单,在正向传播和反向传播时都减少了计算量。由于在时函数的导数值为1,可以在一定程度上解决梯度消失问题,训练时有更快的收敛速度。当时函数值为0,这使一些神经元的输出值为0,从而让网络变得更稀疏,起到了类似L1正则化的作用,也可以在一定程度上缓解过拟合。
ZFNet网络
文献[12]提出通过反卷积(转置卷积)进行卷积网络层可视化的方法,以此分析卷积网络的效果,并指导网络的改进,在AlexNet网络的基础上得到了效果更好的ZFNet网络。
该论文是在AlexNet基础上进行了一些细节的改动,网络结构上并没有太大的突破。该论文最大的贡献在于通过使用可视化技术揭示了神经网络各层到底在干什么,起到了什么作用。如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。下图为典型反卷积网络示意图:
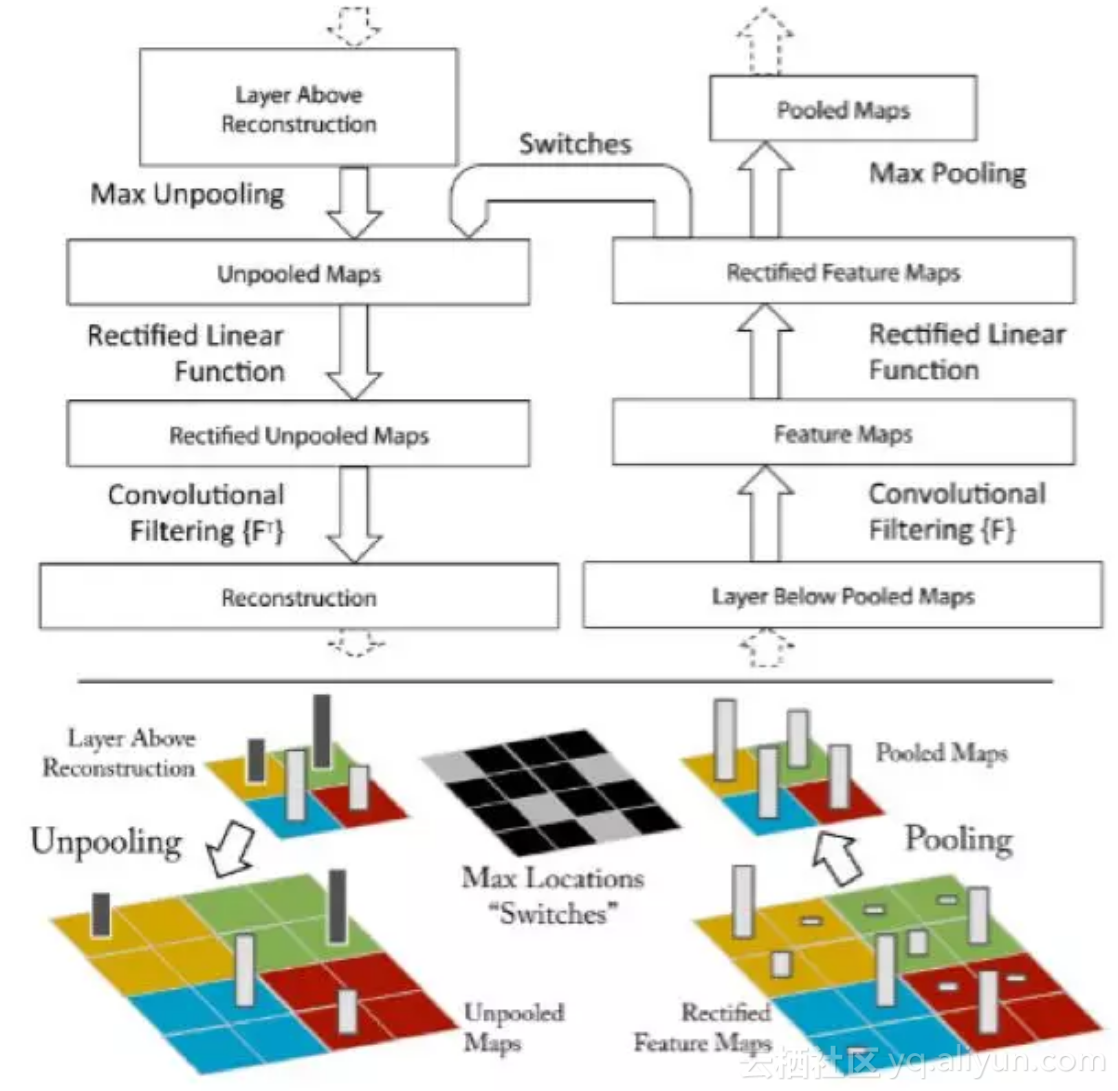
ZFNet网络结构如下图所示:
ZFNet在保留AlexNet的基本结构的同时利用反卷积网络可视化的技术对特定卷积层的卷积核尺寸进行了调整,第一层的卷积核从11*11减小到7*7,将stride从4减小到2,Top5的错误率比AlexNet比降低了1.7%。
GoogLeNet网络
文献[13]提出了一种称为GoogLeNet网络的结构(Inception-V1)。在AlexNet出现之后,针对图像类任务出现了大量改进的网络结构,总体来说改进的思路主要是增大网络的规模,包括深度和宽度。但是直接增加网络的规模将面临两个问题,首先,网络参数增加之后更容易出现过拟合,在训练样本有限的情况下这一问题更为突出。另一个问题是计算量的增加。GoogLeNet致力于解决上面两个问题。
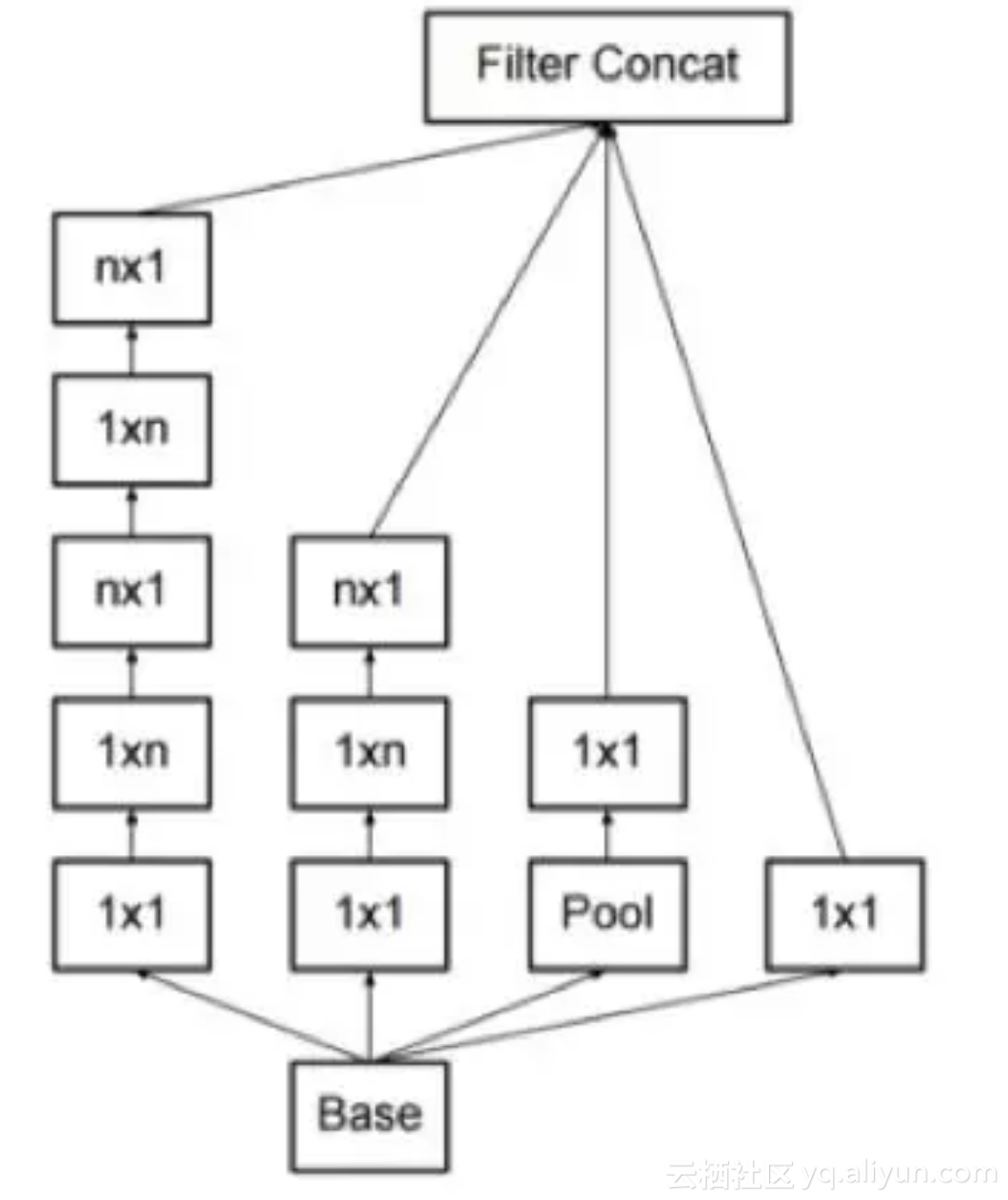
GoogLeNet由Google在2014年提出,其主要创新是Inception机制,即对图像进行多尺度处理。这种机制带来的一个好处是大幅度减少了模型的参数数量,其做法是将多个不同尺度的卷积核,池化层进行整合,形成一个Inception模块。典型的Inception模块结构如下图所示:
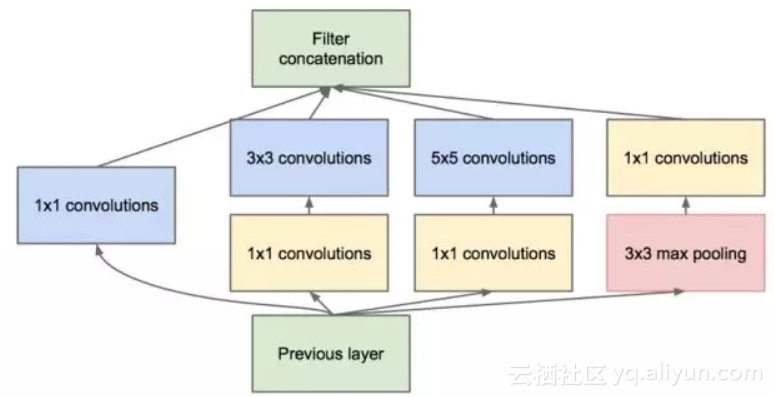
上图的模块由3组卷积核以及一个池化单元组成,它们共同接受来自前一层的输入图像,有三种尺寸的卷积核,以及一个max pooling操作,它们并行的对输入图像进行处理,然后将输出结果按照通道拼接起来。因为卷积操作接受的输入图像大小相等,而且卷积进行了padding操作,因此输出图像的大小也相同,可以直接按照通道进行拼接。
从理论上看,Inception模块的目标是用尺寸更小的矩阵来替代大尺寸的稀疏矩阵。即用一系列小的卷积核来替代大的卷积核,而保证二者有近似的性能。
上图的卷积操作中,如果输入图像的通道数太多,则运算量太大,而且卷积核的参数太多,因此有必要进行数据降维。所有的卷积和池化操作都使用了1x1卷积进行降维,即降低图像的通道数。因为1x1卷积不会改变图像的高度和宽度,只会改变通道数。
GoogleNet网络结构如下图所示:
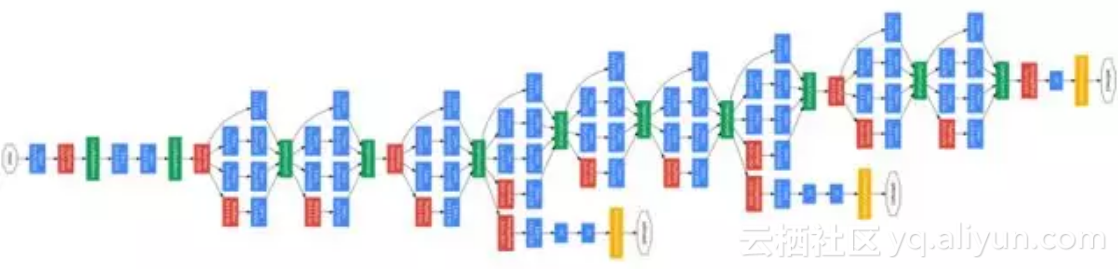
GoogleNet在ILSVRC 2014的比赛中取得分类任务的第一名,top-5错误率6.67%。相较于之前的AlexNet-like网络,GoogleNet的网络深度达到了22层,参数量减少到AlexNet的1/12,可以说是非常优秀且非常实用的模型。
为了降低网络参数作者做了2点尝试,一是去除了最后的全连接层,用全局平均池化替代。全连接层几乎占据了AlexNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。用全局平均池化层取代全连接层的做法借鉴了Network In Network(以下简称NIN)论文[16]。二是GoogleNet中精心设计的Inception模块提高了参数的利用效率,这一部分也借鉴了NIN的思想,形象的解释就是Inception模块本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。不过GoogleNet比NIN更进一步的是增加了分支网络。
VGG网络
VGG网络由著名的牛津大学视觉组(Visual Geometry Group)2014年提出[14],并取得了ILSVRC 2014比赛分类任务的第2名(GoogleNet第一名)和定位任务的第1名。同时VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和池化尺寸(2x2)。到目前为止,VGGNet依然经常被用来提取图像特征,被广泛应用于视觉领域的各类任务。
VGG网络的主要创新是采用了小尺寸的卷积核。所有卷积层都使用3x3卷积核,并且卷积的步长为1。为了保证卷积后的图像大小不变,对图像进行了填充,四周各填充1个像素。所有池化层都采用2x2的核,步长为2。全连接层有3层,分别包括4096,4096,1000个节点。除了最后一个全连接层之外,所有层都采用了ReLU激活函数。下图为VGG16结构图:
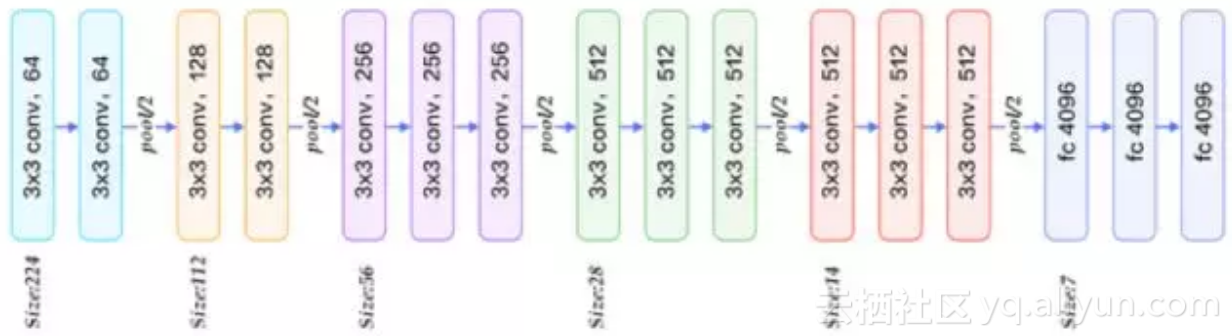
VGG与Alexnet相比,做了以下改进:
1.去掉了LRN层,作者实验中发现深度卷积网络中LRN的作用并不明显
2.采用更小的连续3x3卷积核来模拟更大尺寸的卷积核,例如2层连续的3x3卷积层可以达到一层5x5卷积层的感受野,但是所需的参数量会更少,两个3x3卷积核有18个参数(不考虑偏置项),而一个5x5卷积核有25个参数。后续的残差网络等都延续了这一特点。
残差网络
残差网络(Residual Network)[15]用跨层连接(Shortcut Connections)拟合残差项(Residual Representations)的手段来解决深层网络难以训练的问题,将网络的层数推广到了前所未有的规模,作者在ImageNet数据集上使用了一个152层的残差网络,深度是VGG网络的8倍但复杂度却更低,在ImageNet测试集上达到3.57%的top-5错误率,这个结果赢得了ILSVRC2015分类任务的第一名,另外作者还在CIFAR-10数据集上对100层和1000层的残差网络进行了分析。VGG19网络和ResNet34-plain及ResNet34-redisual网络对比如下:
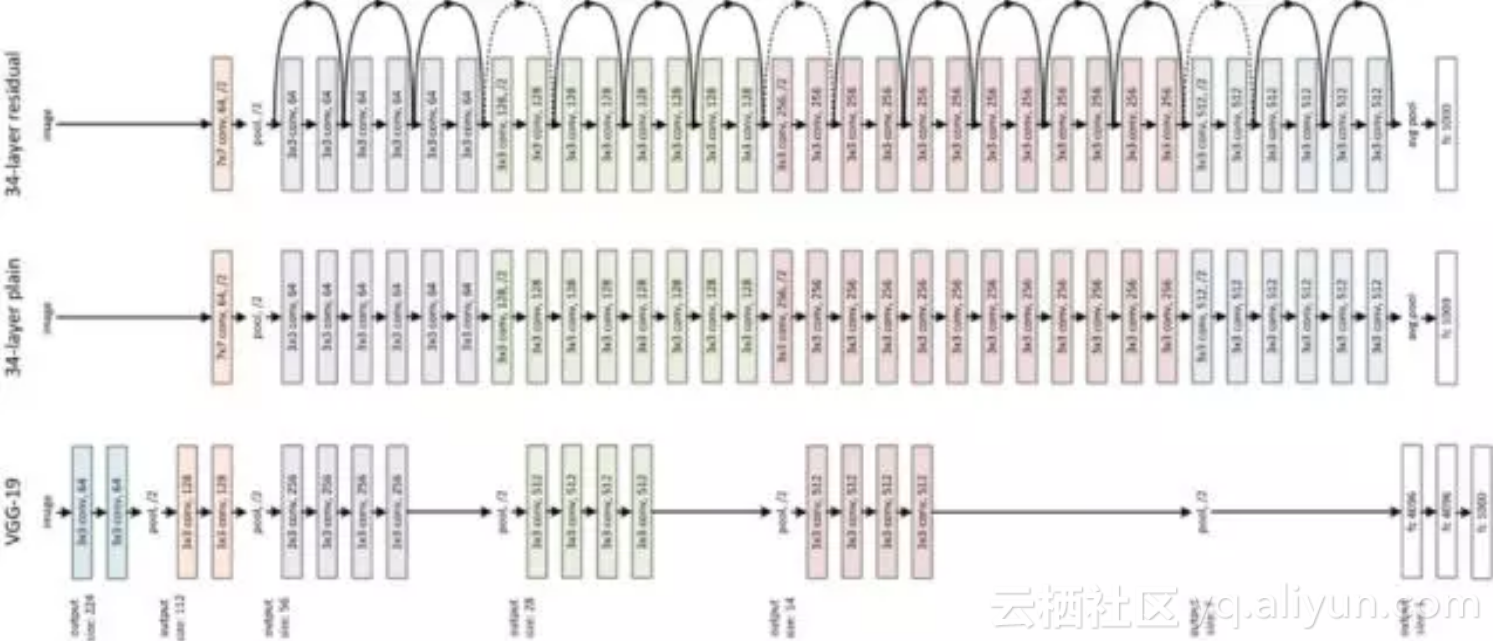
之前的经验已经证明,增加网络的层数会提高网络的性能,但增加到一定程度之后,随着层次的增加,神经网络的训练误差和测试误差会增大,这和过拟合还不一样,过拟合只是在测试集上的误差大,这个问题称为退化。
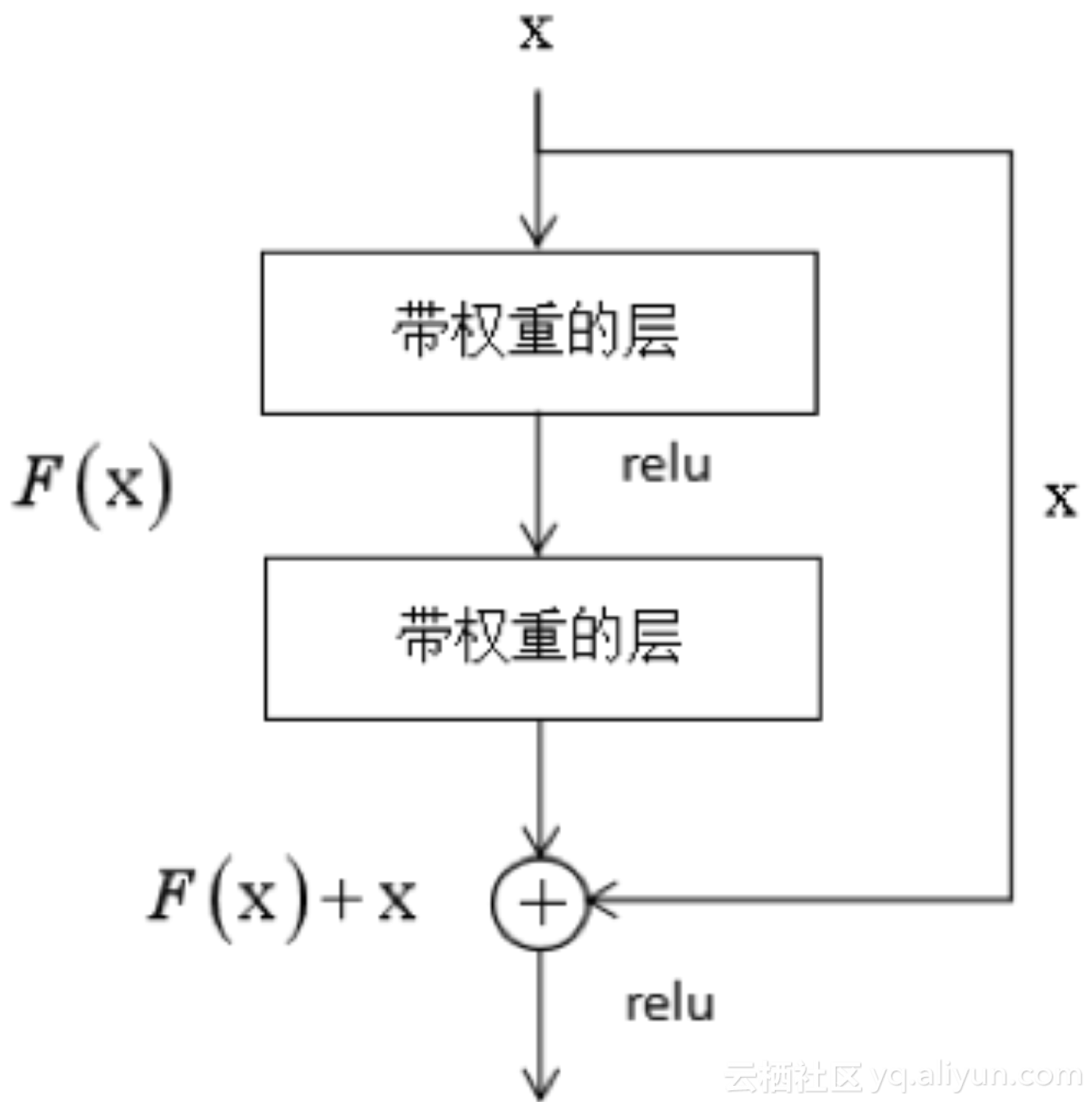
为了解决这个问题,作者设计了一种称为深度残差网络的结构,这种网络通过跳层连接和拟合残差来解决层次过多带来的问题,这种做法借鉴了高速公路网络(Highway Networks)的设计思想,与LSTM有异曲同工之妙。这一结构的原理如下图所示:
后面有文献对残差网络的机制进行了分析。得出了以下结论:残差网络并不是一个单一的超深网络,而是多个网络指数级的隐式集成,由此引入了多样性的概念,它用来描述隐式集成的网络的数量;在预测时,残差网络的行为类似于集成学习;对训练时的梯度流向进行了分析,发现隐式集成大多由一些相对浅层的网络组成,因此,残差网络并不能解决梯度消失问题。
为了进一步证明残差网络的这种集成特性,并确定删除掉一部分跨层结构对网络精度的影响,作者进行了删除层的实验,在这里有两组实验,第一组是删除单个层,第二组是同时删除多个层。为了进行比较,作者使用了残差网络和VGG网络。实验结果证明,除了个别的层之外,删掉单个层对残差网络的精度影响非常小。相比之下,删掉VGG网络的单个层会导致精度的急剧下降。这个结果验证了残差网络是多个网络的集成这一结论。
第三组实验是对网络的结构进行变动,集调整层的顺序。在实验中,作者打乱某些层的顺序,这样会影响一部分路径。具体做法是,随机的交换多对层的位置,这些层接受的输入和产生的输出数据尺寸相同。同样的,随着调整的层的数量增加,错误率也平滑的上升,这和第二组实验的结果一致。
但是笔者认为作者的这种解释有些牵强。普通意义上的集成学习算法,其各个弱学习器之间是相互独立的,而这里的各个网络之间共享了一些层,极端情况下,除了一层不同之外,另外的层都相同。另外,这些网络是同时训练出来的,而且使用了相同的样本。
GoogleNet-Inception-Like网络改进系列
Inception-V2(GoogleNet-BN)
作者基于GoogleNet的基本结构进行了改进,Top1错误率相较减少了2个百分点,主要做了以下的改进:
1.加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯。
2.学习VGG用2个3x3的conv替代Inception模块中的5x5,既降低了参数数量,也加快了计算速度。
Inception-V3
Inception-V3一个最重要的改进是卷积核分解(Factorization),将7x7的卷积核分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),我们称为非对称分解,如下图所示。这样做既可以加速计算减少参数规模,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性。
除此以外作者对这个训练优化的算法也做了改进:
1.通过改进AdaGrad提出了RMSProp一种新的参数优化的方式。RMSprop是Geoff Hinton提出的一种自适应学习率方法。AdaGrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解AdaGrad算法学习率下降较快的问题。 实验证明RMSProp在非凸条件下优化结果更好。
AdaGrad的迭代公式为:
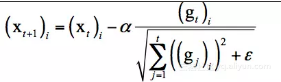
RMSProp的迭代公式为:
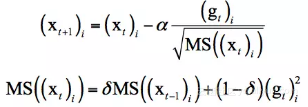
2.采用了Label Smoothing的策略,该方法是一种通过在输出标签中添加噪声,实现对模型进行约束,降低模型过拟合程度的一种正则化方法。
Inception-V4
Inception-v4相较于v3版本增加了Inception模块的数量,整个网络变得更深了。
Xception
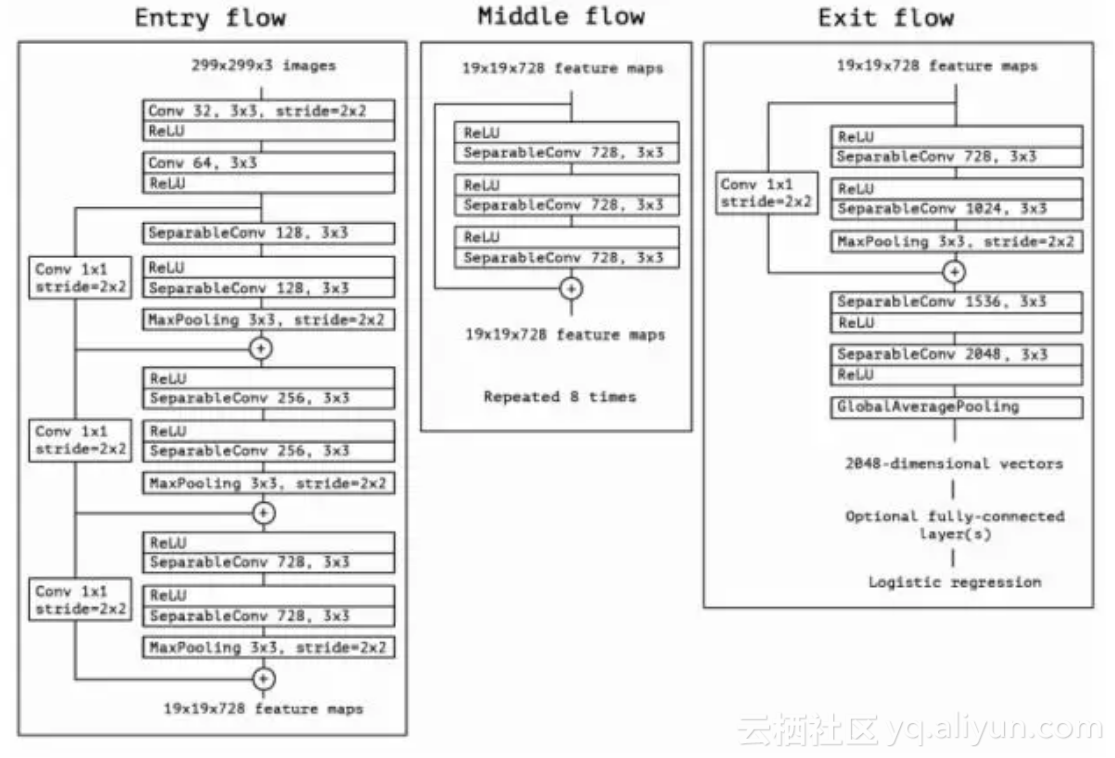
Xception是Google针对Inception v3的另一种改进,主要是采用Depthwise Separable Convolution来替换原来Inception v3中的卷积操作, 在基本不增加网络复杂度的前提下提高了模型的效果。什么是Depthwise Separable Convolution? 通常,在一组特征图上进行卷积需要三维的卷积核,也即卷积核需要同时学习空间上的相关性和通道间的相关性。Xception通过在卷基层加入group的策略将学习空间相关性和学习通道间相关性的任务分离,大幅降低了模型的理论计算量且损失较少的准确度。
Xception网络结构如下图所示:
Inception-ResNet v1/v2
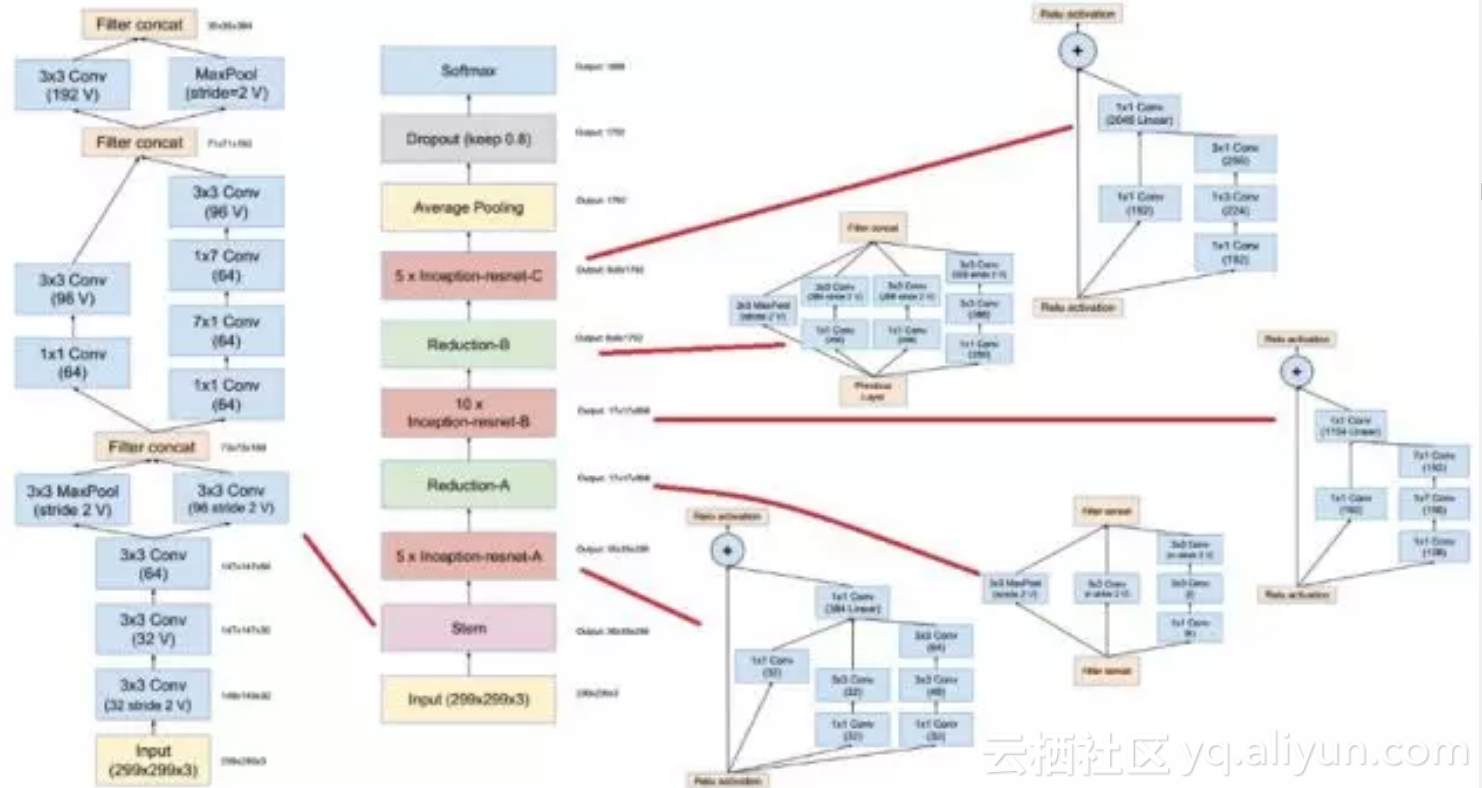
作者基于Inception-v3和Inception-v4将残差网络的思想进行融合,分别得到了Inception-ResNet-v1和Inception-ResNet-v2两个模型。不仅提高了分类精度而且训练的稳定性也得到增强。
Inception-ResNet-v2 网络结构如下图所示:
NASNet
此论文由Google brain出品,是在之前的一篇论文NAS-Neural Architecture Search With Reinforcement Learning的基础做了突破性的改进,使得能让机器在小数据集(CIFAR-10数据集)上自动设计出CNN网络,并利用迁移学习技术使得设计的网络能够被很好的迁移到ImageNet数据集,验证集上达到了82.7%的预测精度,同时也可以迁移到其他的计算机视觉任务上(如目标检测)。该网络的特点为:
1.延续NAS论文的核心机制,通过强化学习自动产生网络结构。
2.采用ResNet和Inception等成熟的网络拓扑结构减少了网络结构优化的搜索空间,大型网络直接由大量的同构模块堆叠而成,提高学习效率。
3.在CIFAR-10上进行了架构搜索,并将最好的架构迁移到ImageNet图像分类和COCO物体检测上。
下图为采用AutoML设计的Block结构:
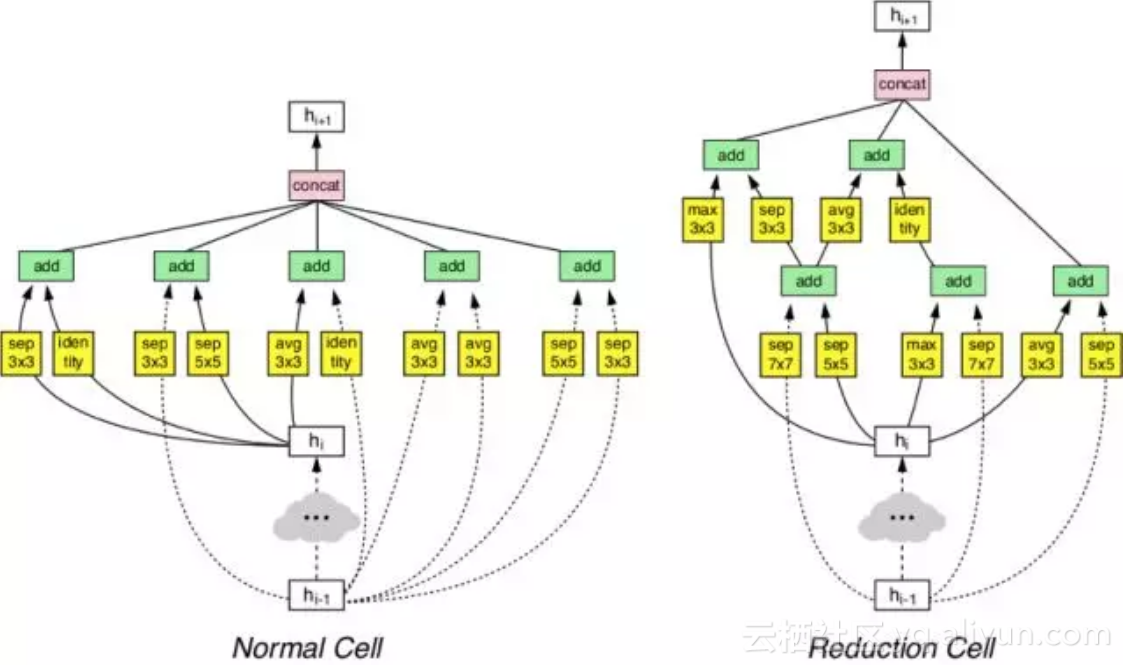
VGG-Residual-Like网络改进系列
WRN(wide residual network)
作者认为,随着模型深度的加深,梯度反向传播时,并不能保证能够流经每一个残差模块(residual block)的权重,以至于它很难学到东西,因此在整个训练过程中,只有很少的几个残差模块能够学到有用的表达,而绝大多数的残差模块起到的作用并不大。因此作者希望使用一种较浅的,但是宽度更宽的模型,来更加有效的提升模型的性能。
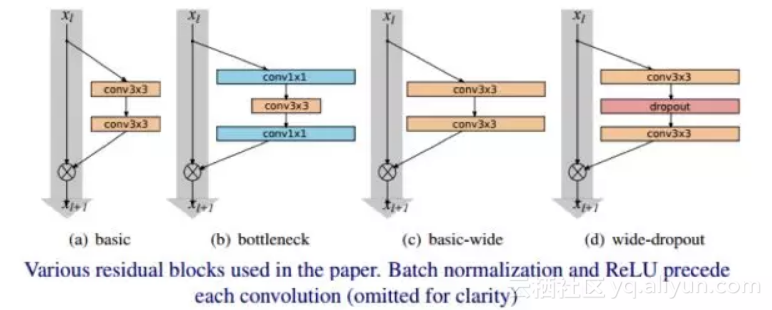
ResNet原作者针对CIFAR-10所使用的的网络,包含三种Residual Block,卷积通道数量分别是16、32、64,网络的深度为6*N+2。而在这里,WRN作者给16、32、64之后都加了一个系数k,也就是说,作者是通过增加Residual Block卷积通道的数量来使模型变得更宽,从而N可以保持很小的值,就可以是网络达到很好的效果。
CIFAR-10和CIFAR -100性能对比:
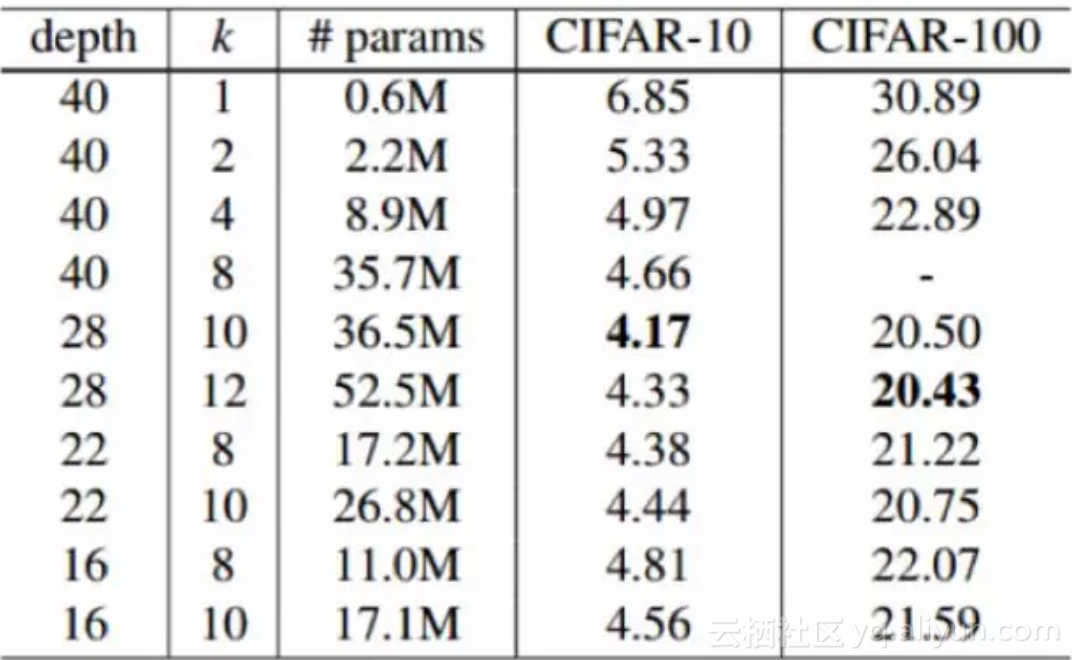
上述实验表明单独增加模型的宽度是对模型的性能是有提升的。不过也不能完全的就认为宽度比深度更好,两者只有相互搭配,才能取得更好的效果。
ResNeXt
作者提出 ResNeXt 的主要原因在于:传统的提高模型准确率的做法,都是加深或加宽网络,但是随着超参数数量的增加(比如通道数,卷积核大小等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率。
这篇论文提出了ResNeXt网络,同时采用了VGG堆叠的思想和Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,原文的解释是the size of the set of transformations,如下图(a)(b) cardinality=32所示:
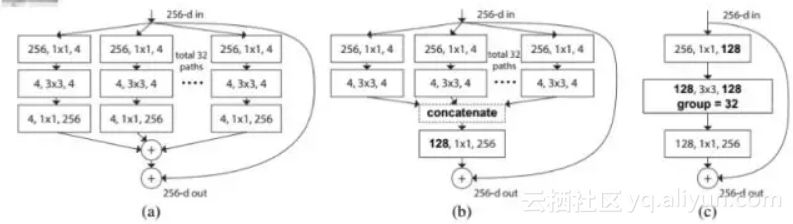
通过实验给出了下面的结论:
1.证明ResNeXt比ResNet更好,而且Cardinality越大效果越好
2.增大Cardinality比增大模型的width或者depth效果更好
当时取得了state-of-art的结果,虽然后来被其它的网络结构超越,但就在最近Facebook 在图像识别技术上又有了新突破,基于ResNeXt 101-32x48d在ImageNet测试中准确度达到创纪录的 85.4%!(使用了35亿张图像,1.7万主题标签进行模型训练,规模史无前例!!!笔者这里不下什么结论,各位看官自行体会...)
DenseNet
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。DenseNet的一个优点是网络更窄,参数更少,很大一部分原因得益于dense block的设计,后面有提到在dense block中每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。下面是DenseNet 的一个示意图:
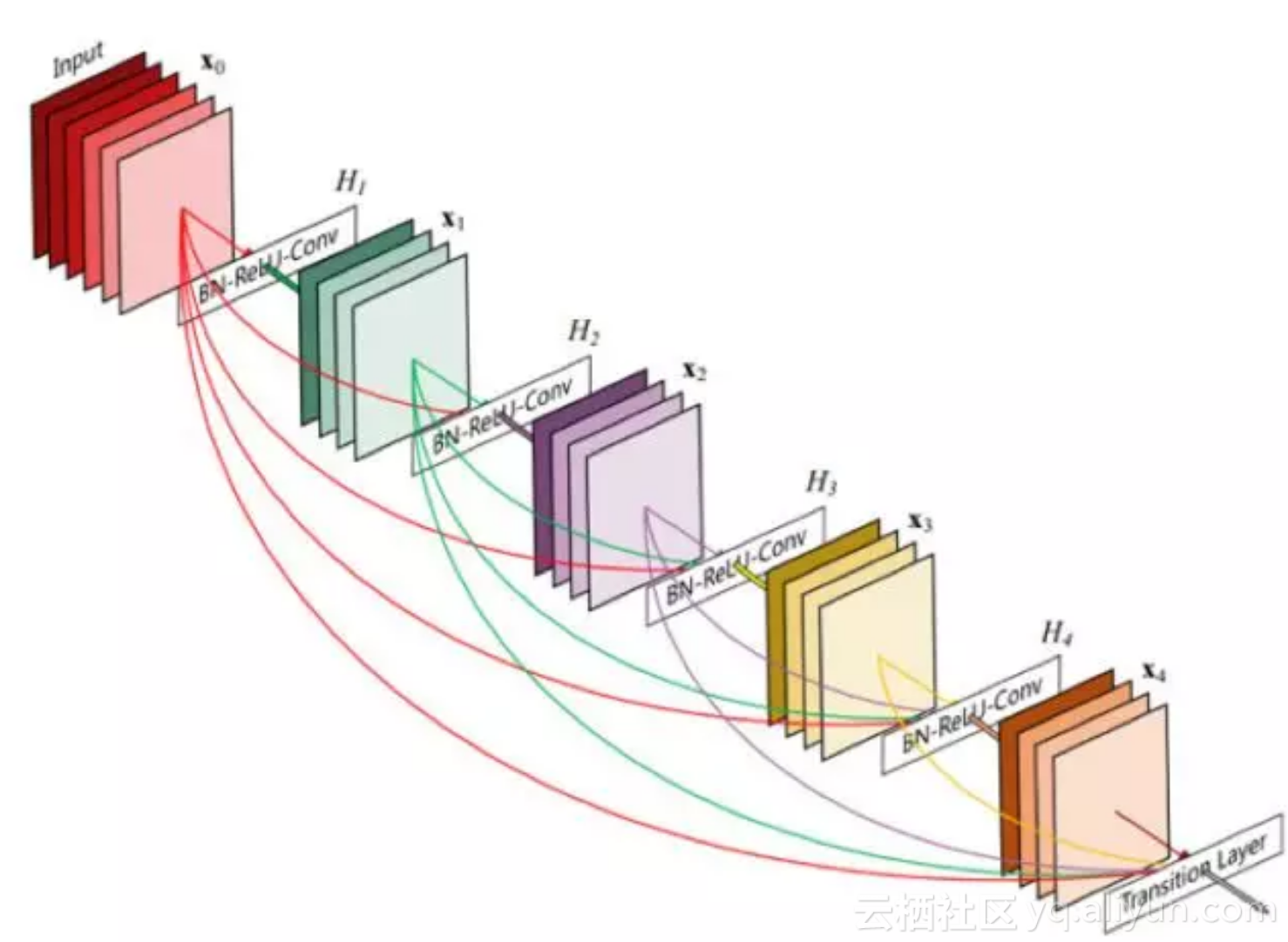
DenseNet可以有效地减少网络参数规模,达到减轻过拟合的效果,对小数据集合的学习很有效果。但是由于中间输出的feature map数量是多层Concat的结果,导致网络在训练和测试的时候显存占用并没有明显的优势,计算量也没有明显的减少!
MobileNet
MobileNets是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,网络设计的核心Separable Convolution可以在牺牲较小性能的前提下有效的减少参数量和计算量。Separable Convolution将传统的卷积运算用两步卷积运算代替:Depthwise convolution与Pointwise convolution,如下图所示:
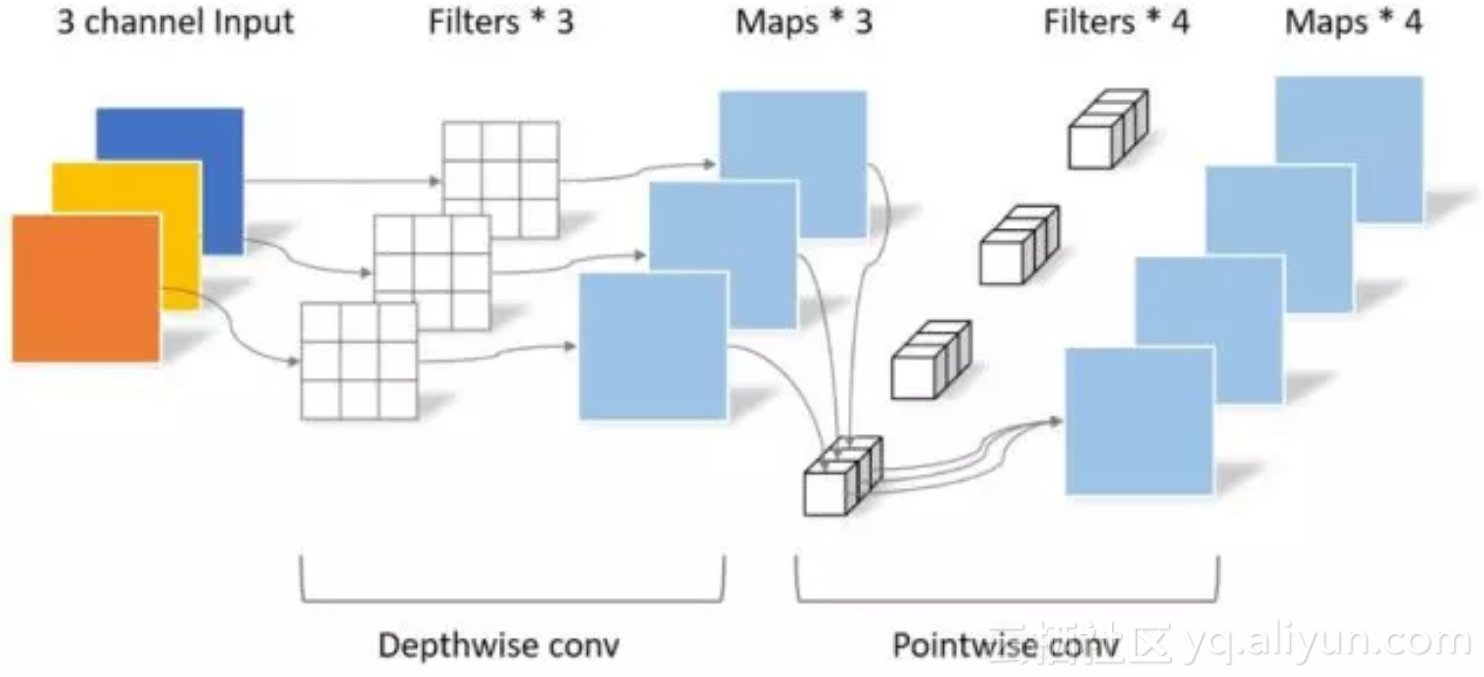
从图中可以明确的看出,由于输入图片为三通道,Depthwise conv的filter数量只能为3,而传统的卷积方法会有3x3总共9个filter。
后续的MobileNet-v2主要增加了残差结构,同时在Depthwise convolution之前添加一层Pointwise convolution,优化了带宽的使用,进一步提高了在嵌入式设备上的性能。可分离卷积如下图所示:
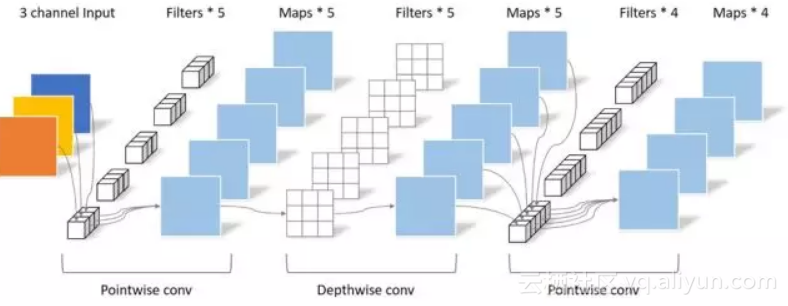
深度神经网络优化策略汇总
接下来介绍卷积神经网络的各种改进措施,其中经典网络的改进措施已经在前面各个网络中介绍。针对卷积神经网络的改进措施主要在以下几个方面:卷积层,池化层,激活函数,损失函数,网络结构,正则化技术等方面。优化算法对网络的训练至关重要,在这里我们单独列出来了。
卷积层
卷积层的改进有以下几种:卷积核小型化,1x1卷积,Network In Network,Inception机制,卷积分解(Factorization),反卷积运算等,下面分别介绍。
Network In Network[16]的主要思想是用一个小规模的神经网络来替代卷积层的线性滤波器,在这篇文献中,小型网络是一个多层感知器卷积网络。显这种小型网络比线性的卷积运算有更强的的描述能力。
卷积核小型化是现在普遍接受的观点,在VGG网络中已经介绍了。1x1卷积可以用于通道降维,也可以用于全卷积网络,保证卷积网络能接受任意尺寸的输入图像,并能做逐像素的预测。Inception机制在GoogLeNet网络中已经介绍,这里也不在重复。
卷积操作可以转化为图像与一个矩阵的乘积来实现,反卷积[17]也称为转置卷积,它的操作刚好和这个过程相反,正向传播时左乘矩阵的转置,反向传播时左乘矩阵。注意这里的反卷积和信号处理里的反卷积不是一回事,它只能得到和原始输出图像尺寸相同的图像,并不是卷积运算的逆运算。反卷积运算有一些实际的用途,包括接下来要介绍的卷积网络的可视化;全卷积网络中的上采样,图像生成等。反卷积运算通过对卷积运算得到的输出图像左乘卷积矩阵的转置,可以得到和原始图像尺寸相同的一张图像。
池化层
池化层的改进主要有以下几种:L-P池化,混合池化,随机池化,Spatial pyramid pooling,ROI pooling。
激活函数
除了传统的sigmoid,tanh函数,深度卷积神经网络中出现了各种新的激活函数,主要的有:ReLU,ELU,PReLU等,它们取得了不错的效果,其中ReLU以及它的改进型在卷积网络中被普遍采用。
损失函数
损失函数也是一个重要的改进点。除了欧氏距离损失之外,交叉熵,对比损失,合页损失等相继被使用。
在一些复杂的任务上,出现了多任务损失损失函数。典型的有目标检测算法,人脸识别算法,图像分割算法等,这些损失函数在人脸识别、目标检测系列综述文章中已经进行介绍,在这里不再重复。
网络结构
这里的网络结构指拓扑结构以及层的使用上。连接关系的改进如残差网络和DenseNet等结构在前面已经做了介绍。
全卷积网络Fully Convolutional Networks[31],简称FCN,是在标准卷积网络基础上所做的改变,它将标准卷积网络的全连接层替换成卷积层,以适应图像分割、深度估计等需要对原始图像每个像素点进行预测的情况。一般情况下,全卷积网络最后几个卷积层采用1x1的卷积核。由于卷积和下采样层导致了图像尺寸的减小,为了得到与原始输入图像尺寸相同的图像,使用了反卷积层实现上采样以得到和输入图像尺寸相等的预测图像。
不同层的卷积核有不同的感受野,描述了图像在不同尺度的信息。多尺度处理也是卷积网络的一种常用手段,将不同卷积层输出图像汇总到一个层中进行处理可以提取图像多尺度的信息,典型的做法包括GoogLeNet,SSD,Cascade CNN,DenseBox。
归一化技术
神经网络在训练过程中每一层的参数会随着迭代的进行而不断变化,这会导致它后面一层的输入数据的分布不断发生变化,这种问题称为internal covariate shift。在训练时,每一层要适应输入数据的分布,这需要我们在迭代过程中调整学习率,以及精细的初始化权重参数。为了解决这个问题,我们需要对神经网络每一层的输入数据进行归一化。其中一种解决方案为批量归一化Batch Normalization[66],它是网络中一种特殊的层,用于对前一层的输入数据进行批量归一化,然后送入下一层进行处理,这种做法可以加速神经网络的训练过程。
优化算法
除了标准的mini-batch随机梯度下降法之外,还有一些改进版本的梯度下降法,它们在很多实验和实际应用中取得了更好的效果,下面分别进行介绍。
AdaGrad[67]为自适应梯度,即adaptive gradient算法,是梯度下降法最直接的改进。唯一不同的是,AdaGrad根据前几轮迭代时的历史梯度值来调整学习率。AdaDelta算法[70]也是梯度下降法的变种,在每次迭代时也利用梯度值构造参数的更新值。Adam算法[68]全称为adaptive moment estimation,它由梯度项构造了两个向量m和v,它们的初始值为0。NAG算法是一种凸优化方法,由Nesterov提出。和标准梯度下降法的权重更新公式类似,NAG算法构造一个向量v,初始值为0。RMSProp算法[69]也是标准梯度下降法的变种,它由梯度值构造一个向量,初始化为0,
参数初始化和动量项对算法的收敛都至关重要,文献[32]对这两方面的因素进行了分析。它的观点认为,对于深度神经网络和循环神经网络的训练优化问题求解,权重初始值和动量项都很重要,二者缺一不可。如果初始值设置不当,即使使用动量项也很难收敛到好的效果;另一方面,如果初始值设置的很好,但不使用动量项,收敛效果也打折扣。
理论解释
卷积网络一般有很深的层次,要对它进行严格而细致的分析比较困难。与网络的应用和设计相比,对它的理论和运行机理分析与解释相对较少。如果我们能分析清楚卷积网络的运行机理,把卷积操作可视化的显示出来,无论是对于理解卷积网络,还是对于网络的设计都具有重要的意义。
对多层卷积神经网络的理论解释和分析来自两个方面。第一个方面是从数学角度的分析,对网络的表示能力、映射特性的数学分析;第二个方面是多层卷积网络和人脑视觉系统关系的研究,分析二者的关系有助于理解、设计更好的方法,同时也促进了神经科学的进步。
典型应用
卷积神经网络在诸多领域得到了成功的应用。接下来我们将介绍它在机器视觉,计算机图形学,自然语言处理这些典型领域的应用。对于这些应用问题和为它们设计的网络结构和算法,理解的关键点是:
1.网络的结构。即网络由那些层组成,各个层的作用是什么,它们的输入数据是什么,输出数据是什么。
2.训练目标即损失函数,这直接取决于要解决的问题。
机器视觉
卷积神经网络在图像分类问题上取得成功之后很快被用于人脸检测问题,在精度上大幅度超越之前的AdaBoost框架,当前已经有一些高精度、高效的算法。直接用滑动窗口加卷积网络对窗口图像进行分类的方案计算量太大很难达到实时,使用卷积网络进行人脸检测的方法采用各种手段解决或者避免这个问题。在这些方法中,Cascade CNN,DenseBox,Femaleness-Net,MT-CNN是其中的代表。
和人脸、行人等特定目标检测不同,通用目标检测的任务是同时检测图像中多种类型的目标。各类目标的形状不同,因此目标矩形的宽高比不同,难度更大。典型的算法是R-CNN,SPP网络,Fast R-CNN,Faster R-CNN,YOLO,SSD,R-FCN,FPN等。
人脸关键点定位的目标是确定关键位置的坐标,如眼睛的中点,鼻尖和嘴尖等。它在人脸识别、美颜等功能中都有应用。这个问题是一个回归问题,要实现的是如下映射:
文献[26]提出了一种用级联的卷积网络进行人脸关键点检测的方法,通过逐级细化的思路实现。本文检测5个关键点,分别是左右眼的中心LE和RE,鼻尖N,嘴的左右端LM和RM。采用了3个层次的卷积网络进行级联,逐步求精。第一个层次上包含3个卷积网络,分别称为F1,EN1,NM1,输入分别为整个人脸图像,眼睛和鼻子,鼻子和嘴巴。每个网络都同时预测多个关键点。对每个关键点,将这些网络的预测值进行平均以减小方差。系统的结构如下图所示:
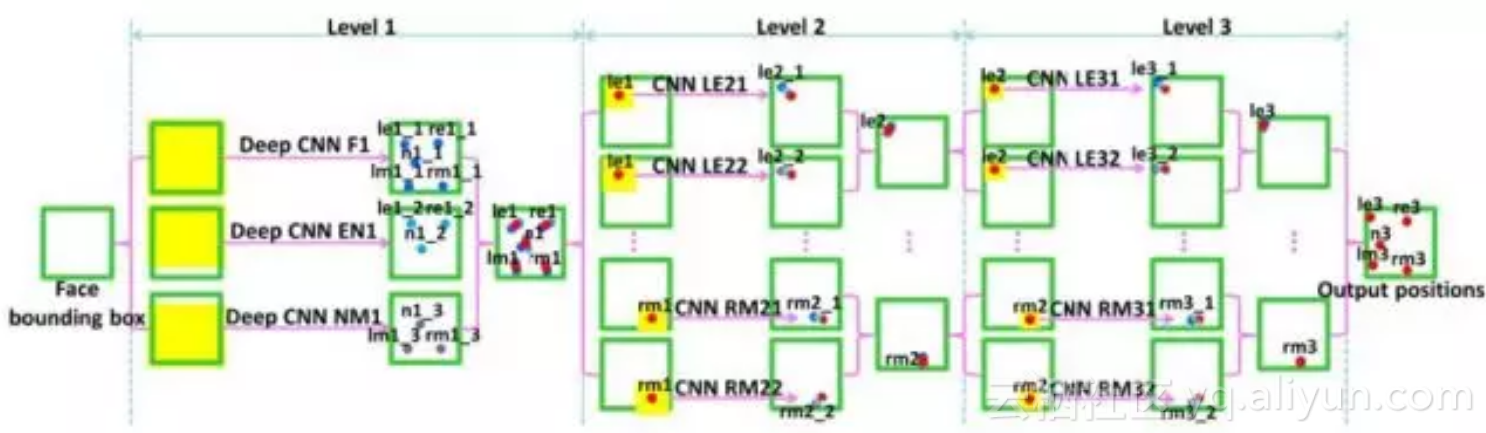
人脸识别也是深度卷积神经网络成功应用的典型领域。
文字定位和识别也是卷积网络成功应用的方向[27][28][29][30],后者属于图像分类问题。在这里我们不详细介绍。除了图像分类,目标检测等大类任务之后,接下来我们重点介绍卷积网络在机器视觉其他问题上的应用。
图像语义分割和图像识别是密切相关的问题。分割可看做对每个像素的分类问题。卷积网络在进行多次卷积和池化后会缩小图像的尺寸,最后的输出结果无法对应到原始图像中的单一像素,卷积层后面接的全连接层将图像映射成固定长度的向量,这也与分割任务不符。针对这两个问题有几种解决方案,最简单的做法是对一个像素为中心的一块区域进行卷积,对每个像素都这样的操作。这种方法有两个缺点:计算量大,利用的信息只是本像素周围的一小片区域。更好的方法是全卷积网络,这是我们接下来要介绍的重点。
文献[31]提出了一种称为全卷积网络FCN的结构来实现图像的语义分割,这种模型从卷积特征图像恢复出原始图像每个像素的类别。网络能够接受任意尺寸的输入图像,并产生相同尺寸的输出图像,输入图像和输出图像的像素一一对应。这种网络支持端到端、像素到像素的训练。
最简单的FCN的前半部分改装自AlexNet网络,将最后两个全连接层和一个输出层改成3个卷积层,卷积核均为1x1大小。解决卷积和池化带来的图像分辨率缩小的问题的思路是上采样。
网络的最后是上采样层,在这里用反卷积操作实现上采样,反卷积的卷积核通过训练得到。在实现时,在最后一个卷积层后面接上一个反卷积层,将卷积结果映射回和输入图像相等的尺寸。为了得到更精细的结果,可以将不同卷积层的反卷积结果组合起来。系统结构如下图所示:
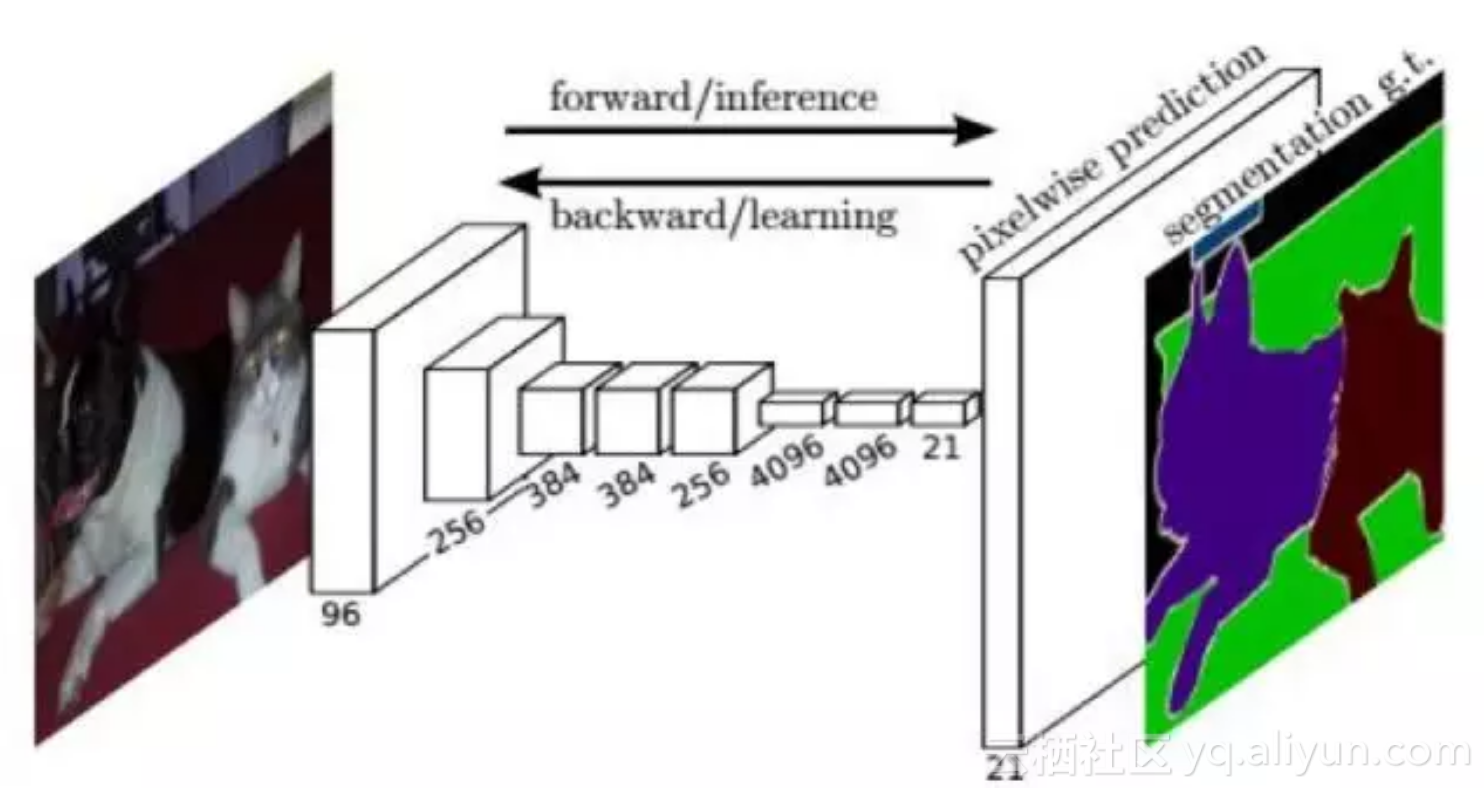
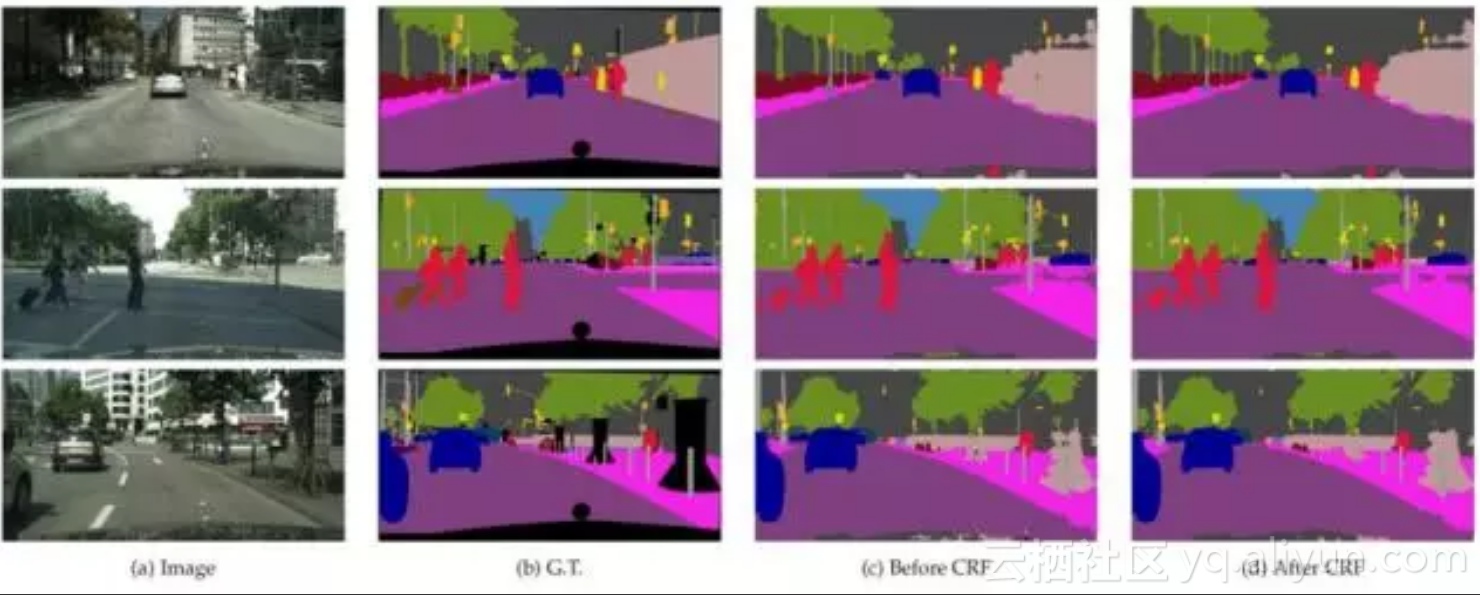
文献[34]提出了一种称为DeepLab的图像分割方法。这个方法的创新有3点:用上采样的滤波器进行卷积,称为atrous卷积,以实现密集的、对像素级的预测;采用了atrous空间金字塔下采样技术,以实现对物体的多尺度分割;第三点是使用了概率图模型,实现更精确的目标边界定位,通过将卷积网络最后一层的输出值与一个全连接的条件随机场相结合得到。算法运行结果如下图所示:
文献[35]提出了一种称为SegNet的图像语义分割网络,这也是一个全卷积网络,其主要特点是整个网络由编码器和解码器构成。网络的前半部分是编码器,由多个卷积层和池化层组成。网络的后半部分为解码器,由多个上采样层和卷积层构成。解码器的最后一层是softmax层,用于对像素进行分类。
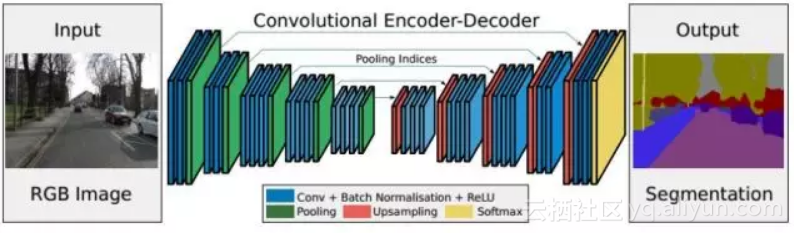
编码器网络的作用是产生有语义信息的特征图像;解码器网络的作用是将编码器网络输出的低分辨率特征图像映射回输入图像的尺寸,以进行逐像素的分类。解码器用编码器max池化时记住的最大元素下标值执行非线性上采样,这样上采样的参数不用通过学习得到。上采样得到的特征图像通过卷积之后产生密集的特征图像。整个框架实现了完全端到端的训练。
边缘检测的目标是找出图像中所有的边缘像素点。Sobel算子和拉普拉斯算子都可以通过卷积和阈值化的方式提取出图像的边缘。更复杂的方法有Canny算子,它首先用Sobel算子得到梯度图像,在进行阈值化之后进行非最大抑制,最后得到更为干净的边缘图。和图像分割一样,纯图像处理的方法只在像素一级进行操作,没有利用图像语义和结构信息。边缘和轮廓检测可以看做是二分类问题,正样本为边缘点的像素,负样本为非边缘像素。
文献[39]提出了一种称为DeepEdge的边缘提取方法,这是一种基于图像块的方法,卷积网络作用于原始图像中以每个像素为中心的小图像块,判断该像素是否为边缘像素。轮廓检测流程分为如下几步:
1.用Canny算子提取候选轮廓点,它输出的边缘图像中所有的边界点作为候选轮廓点。
2.为所有候选轮廓点提取4个尺度的子图像,将它们同时送入卷积网络中进行处理。
3.将卷积的结果送入2个子网络中进行处理,第一个网络用于分类,第二个网络用于回归。
4.将这两个网络的输出值进行加权平均,得到最后的分数值,这个分数值表示该候选轮廓点是否真的是轮廓点。
5.对上一步的输出分数进行阈值化,得到最终的轮廓图像。
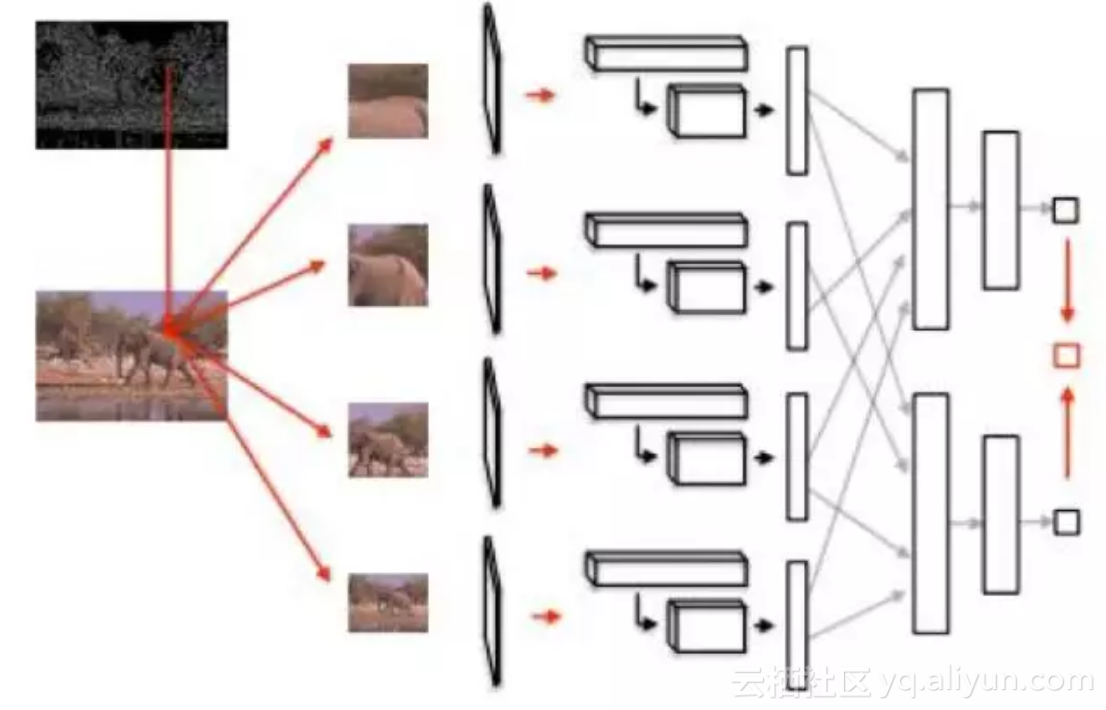
边缘检测的结果如下图所示:
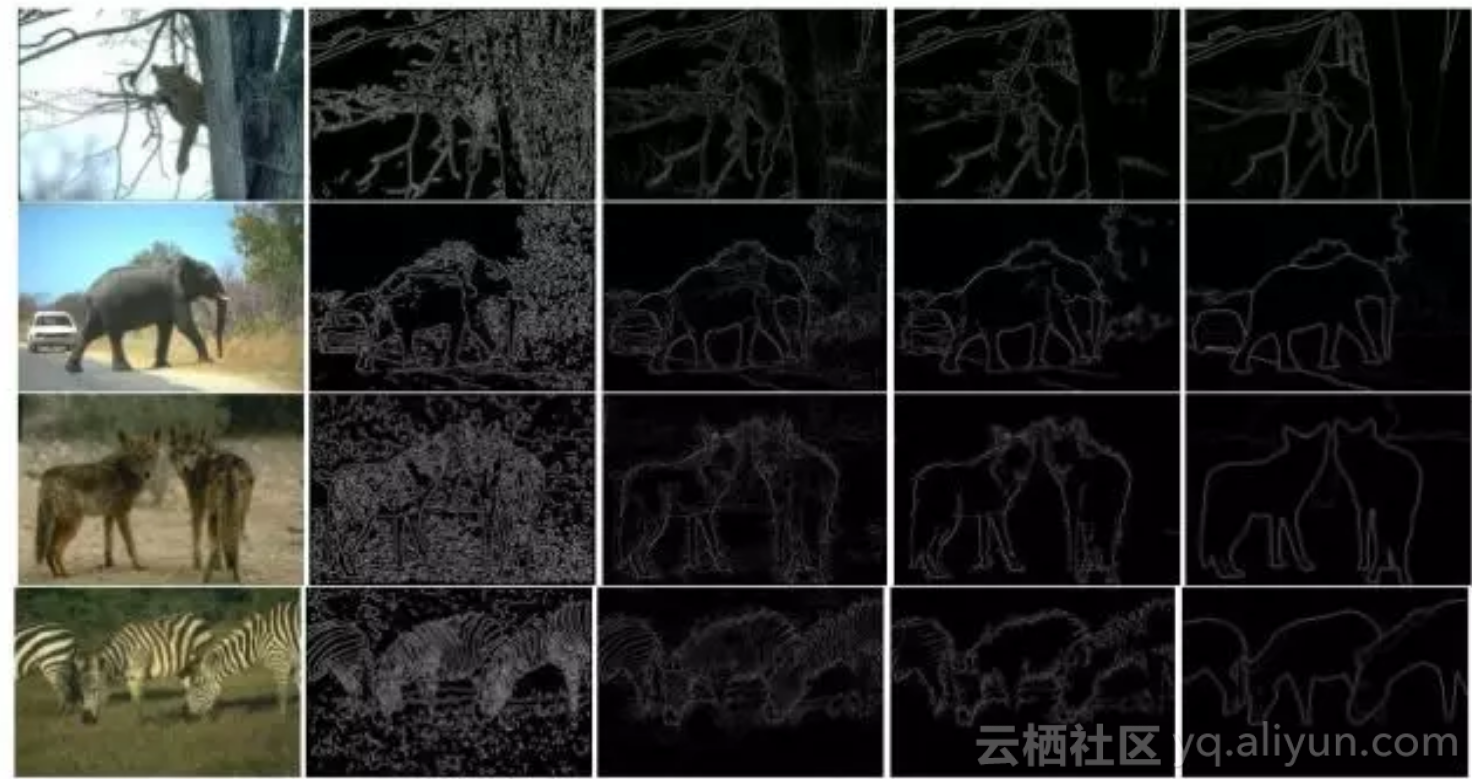
文献[37]提出了一种称为DeepContour的物体轮廓提取算法,这也是一种基于图像块的方法。在这里将正样本即轮廓划分为多个子类,并且用不同的模型拟合这些子类。作者设计了一种新的损失函数,称为positive-sharing loss,各个子类共享正样本类的损失。在这里用卷积网络对小的图像块进行分类,这些图像块从整个图像中切分出来,可能包括轮廓,也可能不包括轮廓。

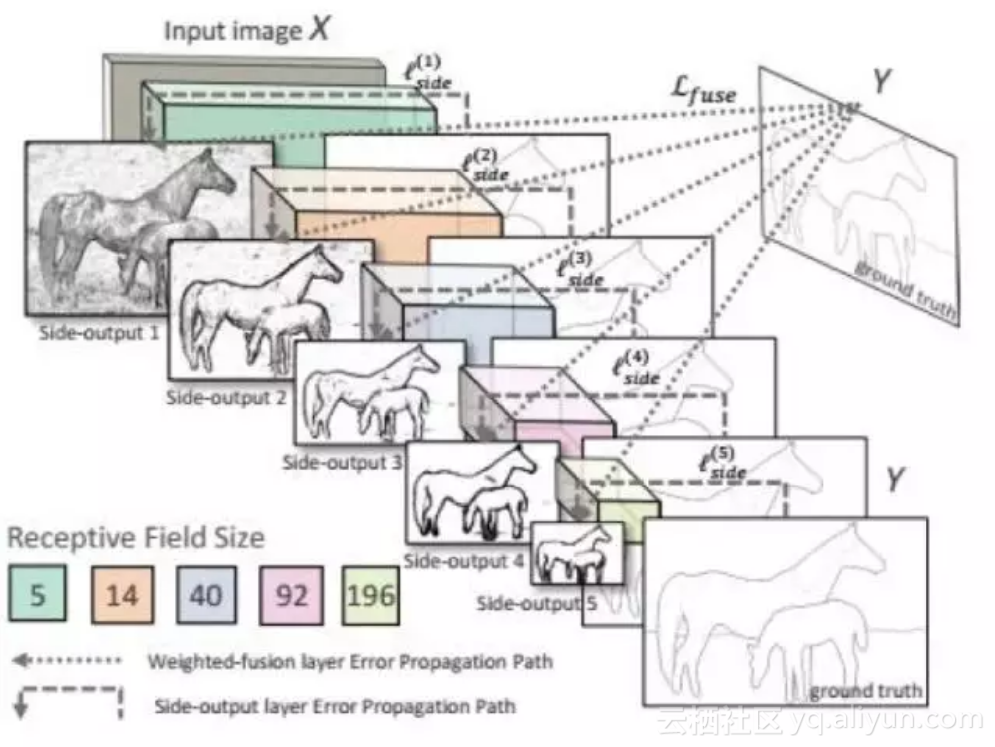
文献[38]提出了一种称为整体式嵌套(Holistically-Nested)的边缘检测算法。整体式是指整个算法是端到端的,嵌套式指在整个边缘检测的过程中通过不断的细化求解,得到精确的边界图像。网络对输入图像进行了多尺度的处理,这通过卷积网络运行过程中得到的多个尺度的特征图像进行处理融合而实现。
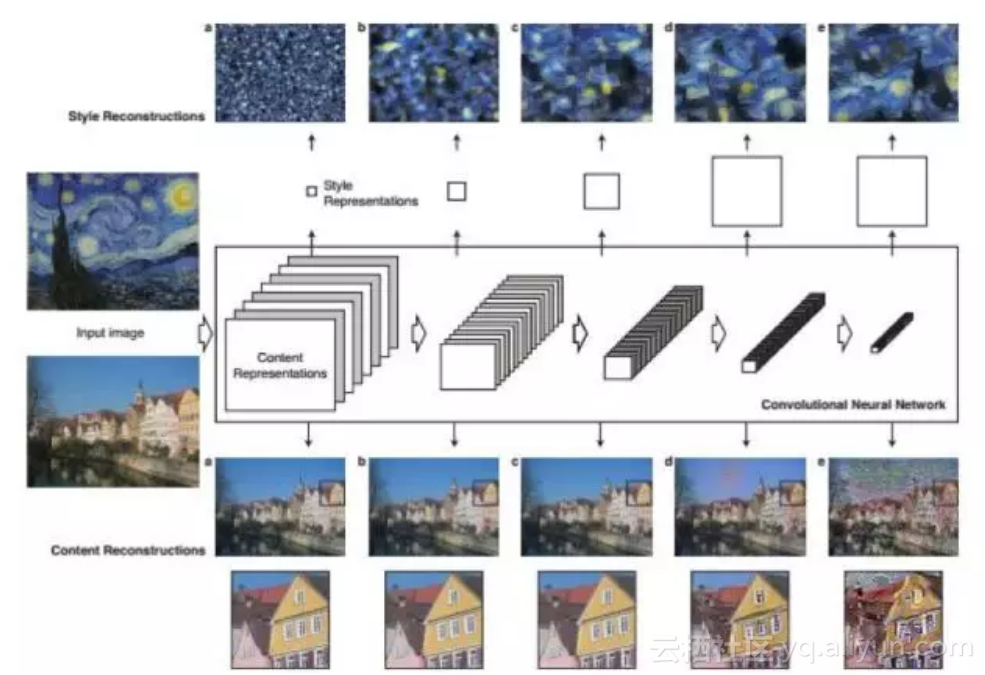
风格迁移的任务是把输入图像变成另一种风格,如油画风格,但要保持和输入图像的内容相同,这是一个根据两张图像生成一张图像的问题。
文献[40]提出了一种用卷积网络进行风格迁移的方法。在这里将风格看成是纹理特征,风格迁移看成是提取待迁移图像的语义及内容信息,然后将纹理风格作用于该图像,得到想要的风格的输出图像。
算法的输入包括一张风格图像和一张要进行风格迁移的内容图像,输出的新图像内容和内容图像保持一致,风格和风格图像保持一致。处理流程为:
1.用卷积网络提取风格图像的风格特征,内容图像的内容特征。
2.从一张白噪声图像开始迭代生成目标图像,优化的目标是使得目标图像的风格特征与风格图像相似,内容特征与内容图像相似。
图像增强的任务是提升图像的对比度。文献[90]提出了一种用卷积神经网络进行图像增强的方法。其基本思想是学习人工对图像进行增强调整的模型。这种方法达到了非常好的效果,而且可以在移动设备上做到实时处理。
在进行图像增强时,卷积网络输出的是原始图像的低分辨版本,进行双边空间中的一系列仿射变换,然后对这些仿射变换进行保边缘的上采样。然后将上采样后的变换作用于原始输出图像,得到增强后的图像。
卷积神经网络被成功的用于根据单张图像估计深度信息。文献[41]提出了一种用多尺度的卷积网络从单张图像估计深度的方法,在这里,深度信息只是相对数据,即图像中每个像素离摄像机的远近关系,而不是真实的物理距离。由于每个像素点都会预测出一个深度值,因此这是一个逐像素的回归问题。
系统的输入是单张RGB图像,输出是深度图,和输入图像尺寸相同。系统由两个卷积网络层叠组成,第一个网络对整个图像进行粗的全局深度预测,第二个卷积网络用局部信息对全局预测结果进行求精。
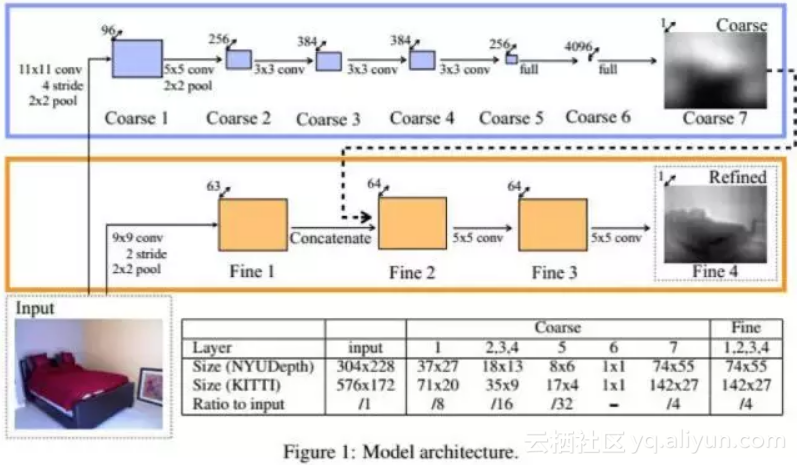
算法运行的结果如下图所示:

更进一步,文献[42]提出了一种用多尺度卷积神经网络从单张图像估计深度信息、法向量的方法。这个卷积网络的输入为单张RGB图像,输出为三张图像,分别为深度图,法向量图,以及物体分割标记图。
这个卷积网络包括三个尺度,形成级联结构。每个尺度的第一个层都接受原始RGB图像作为输入,另外还接受上一个级卷积网络的输出作为输入,这个输出是经过上采样的。
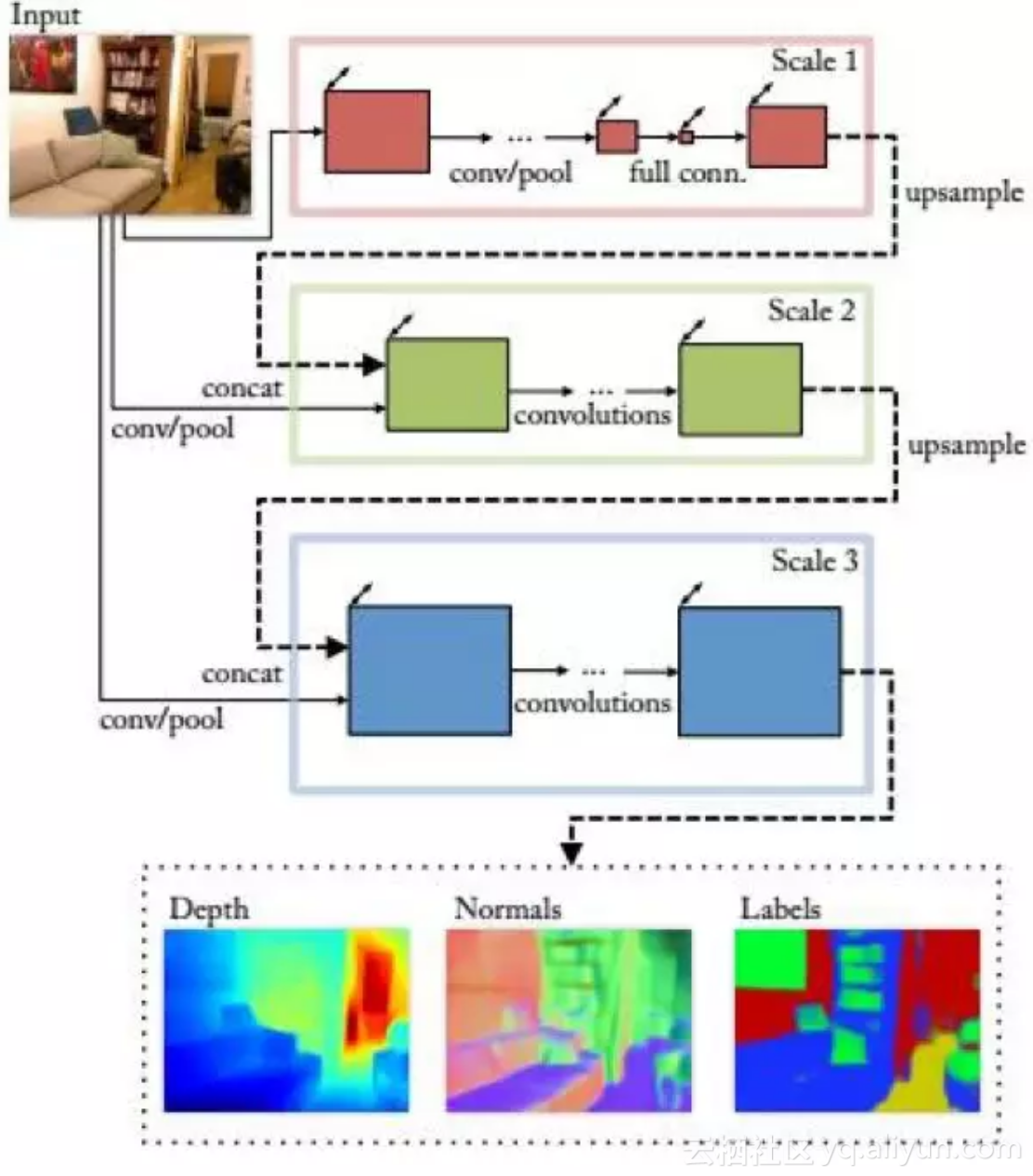
目标跟踪是机器视觉领域中的一个重要问题,它分为单目标跟踪与多目标跟踪两种问题。前者只跟踪单个目标,后者要对多个目标同时进行跟踪。单目标跟踪是一个状态预测问题,它根据目标在之前帧中的位置、大小、外观和运动信息估计在当前帧中的位置、大小等状态。
文献[44]用卷积神经网络来实现目标的检测以用于目标跟踪。网络的输入为固定尺寸的图像,包含3个卷积层,输出为概率图像,表示该位置为目标的概率。在卷积层和全连接层之间加入了SPP网络中的SPP池化层,以提高目标定位的精度。整个网络先用ImageNet的目标检测数据集进行离线训练,这样就具有区分目标和背景的能力。
文献[46]提出了一种用全卷积网络进行目标跟踪的方法,卷积网络的作用是目标检测。这种方法用一个在ImageNet数据集上预先训练好的卷积网络提取图像的特征,用于区分目标和背景,卷积网络采用VGG结构。另外也用卷积网络的特征生成热度图,表示每个位置处是目标的概率。
文献[45]提出了一种称为Multi-Domain的卷积网络结构实现目标跟踪。这个网络的前半部分是卷积层和全连接层,后面是多个domain-specific层, 它们用于实现目标的精确定位。
其他的目标跟踪文章见参考文献,在此不一一列举。
图形学
计算机图形学是计算机科学的一个重要分支,它的任务是用计算机程序生成图像,尤其是真实感图像。图形学中有3个主要的问题:几何模型的建立,物理模型的建立包括光照模型,渲染即由几何和物理模型生成最终的图像。
机器学习技术在图形学中的应用代表了数据驱动这类方法,它通过大量的训练样本得到要建立的模型的参数,或者直接由训练的模型生成图像。卷积网络适合处理图像、2D或者3D空间中的网格数据这里具有空间结构的数据,在图形学的很多问题上也取得了很好的效果。
文献[51]提出了一种用基于八叉树的卷积网络进行3D形状分析的方法,称为O-CNN。在这里用八叉树表示3D物体,将八叉树最精细叶子节点的法向量均值作为卷积网络的输入,执行3D卷积运算。这种卷积网络能对3D形状进行分类,检索和分割。
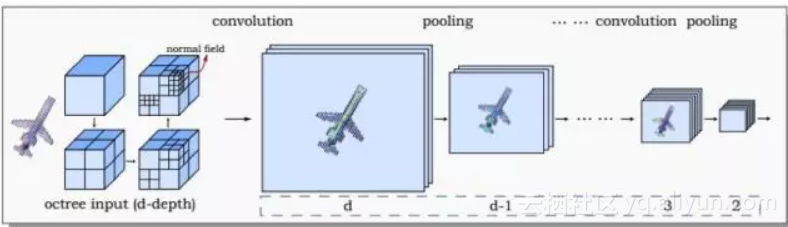
在图形学中,物理模型包括对要绘制的物体进行力学和光学建模。前者主要针对运动的物体,包括刚体和流体。对所有要渲染的物体,都需要建立光学模型,包括物体表面材质的光学特征,以及光照模型。
文献[53]提出了一种使用单张图片估计物体表面反射函数的方法,该算法用卷积网络表示表面反射函数。表面反射函数定义了物体表面的光学反射特性,它决定了给定光照条件下物体表面的颜色和纹理,这对绘制物体至关重要。
流体模拟是图形学中一个重要的问题,它对液体、气体如烟雾等物体的运动进行建模和绘制。在仿真、游戏与动画、电影特技里都有这种技术的应用。经典的方法是基于物理的流体模拟。它主要由两步构成:对流体的运动进行建模,及对流体的表面进行绘制,前者的基础是流体力学。在流体力学领域,描述流体运动使用的是Navier-Stokes方程,这是一个复杂的偏微分方程组。用离散化的数值方法计算需要求解大规模的方程组,非常耗时,使得高精度的流体模拟很难实时进行。
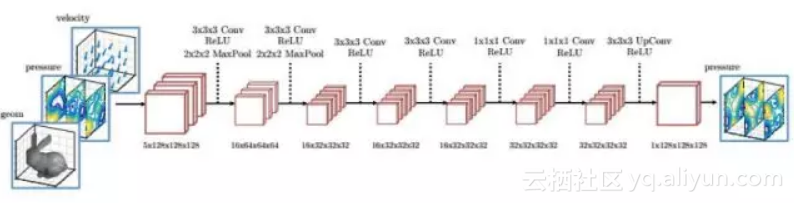
文献[58]提出了一种用卷积网络加速流体模拟的方法,这种方法不再求解大规模的线性方程组,而是直接用卷积网络进行预测。这个网络用大量的仿真数据作为训练集,采用半监督的方法进行训练,目标是最小化长期速度散度。
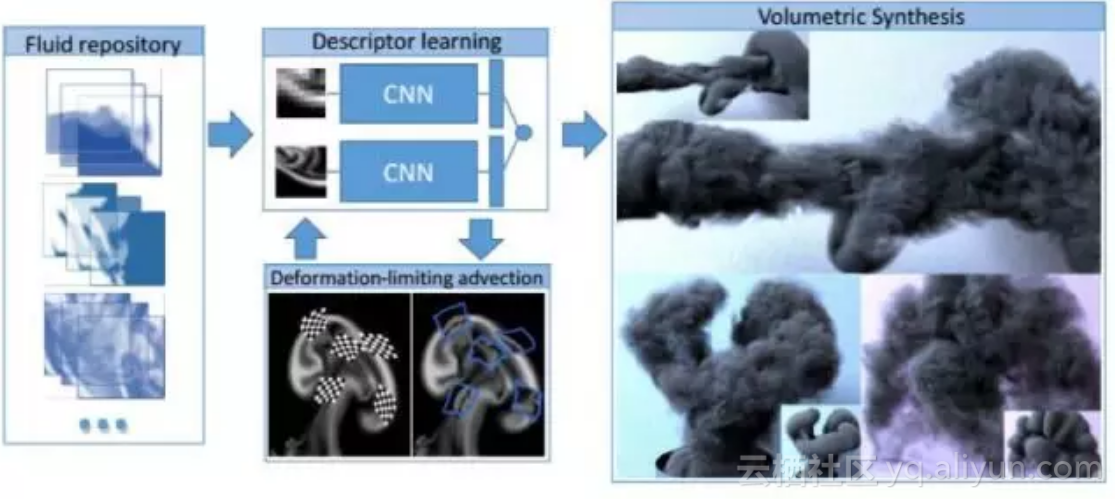
文献[52]提出了一种用卷积网络进行烟雾合成的方法,其关键是用卷积网络建立烟雾运动的力学模型。在这里采用了一个有4个卷积层和2个全连接层的卷积网络。卷积网络的作用是学习描述粗糙尺度烟雾模拟局部和精细尺度烟雾模拟局部对应关系的映射。在新场景中生成精细的烟雾特效时,只需进行快速的粗糙模拟,并根据卷积网络建立的映射得到与各局部相对应的精细模拟局部,然后将其细节形体信息转移过来即可。
纹理合成是渲染时重要的一步,它从小的纹理样图生成大的纹理图像,然后映射到物体表面的曲面上,要保证生成的图像没有缝隙。和风格迁移一样,这也是一个从图像生成图像的问题。卷积神经网络的卷积3输出值蕴含了图像的信息,因此可以根据它来计算纹理特征,用来衡量样例图像和生成的图像的相似度。
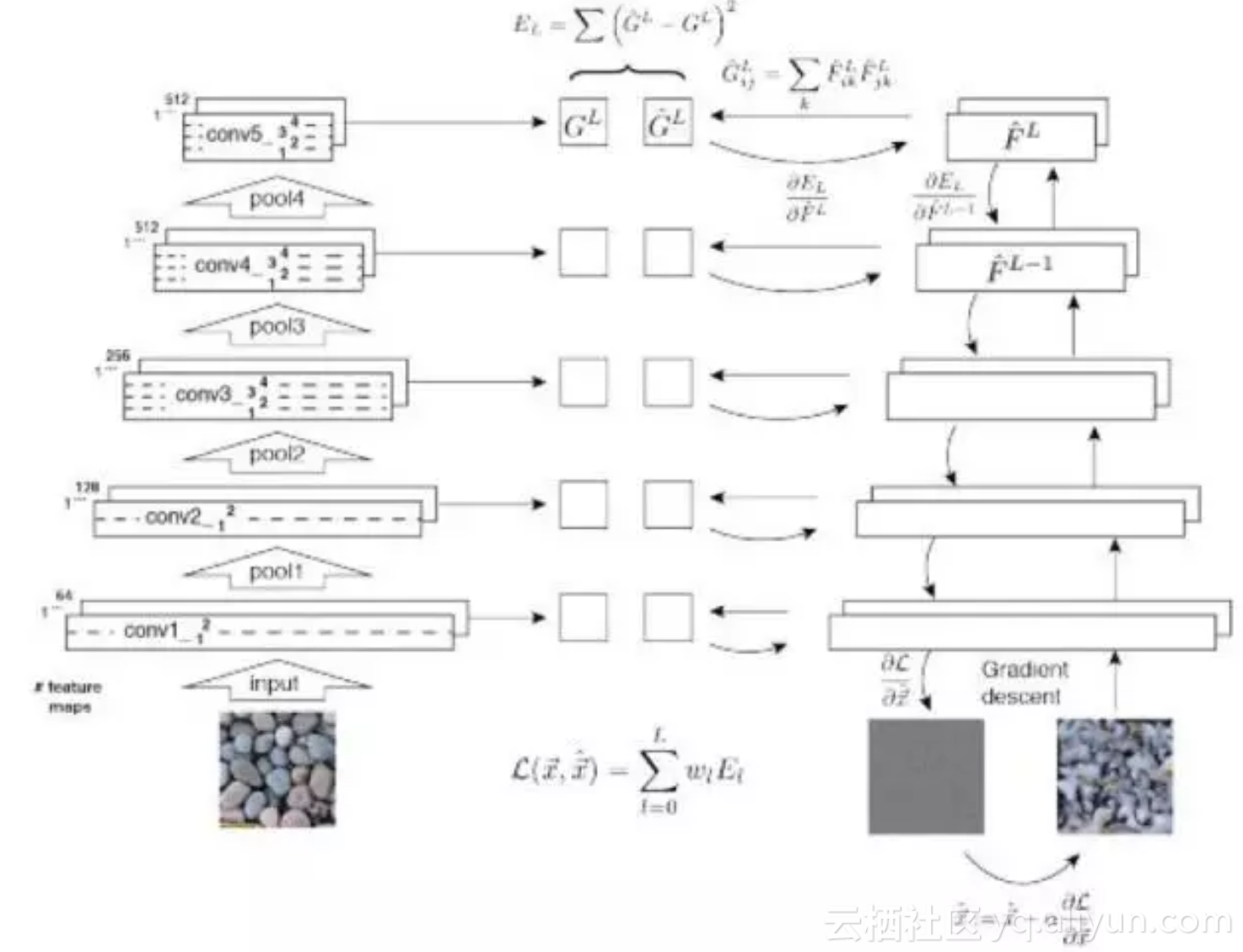
文献[55]提出了一种用卷积网络合成纹理的方案,其思想和前面介绍的风格迁移类似。这个方法分为两步。首先是纹理分析,它的输入是纹理样图,送入卷积网络处理之后,在各个卷积层的输出特征图像上计算Gram矩阵。第二步是纹理合成,它的输入是一张白噪声图像,送入卷积网络进行处理,用纹理模型在卷积网络的各个层上计算损失函数。然后用梯度下降法迭代更新这张白噪声图像,使得损失函数最小化。对白噪声图像的优化结果就是合成得到的纹理图像,它与纹理样例图像具有相同的Gram矩阵。
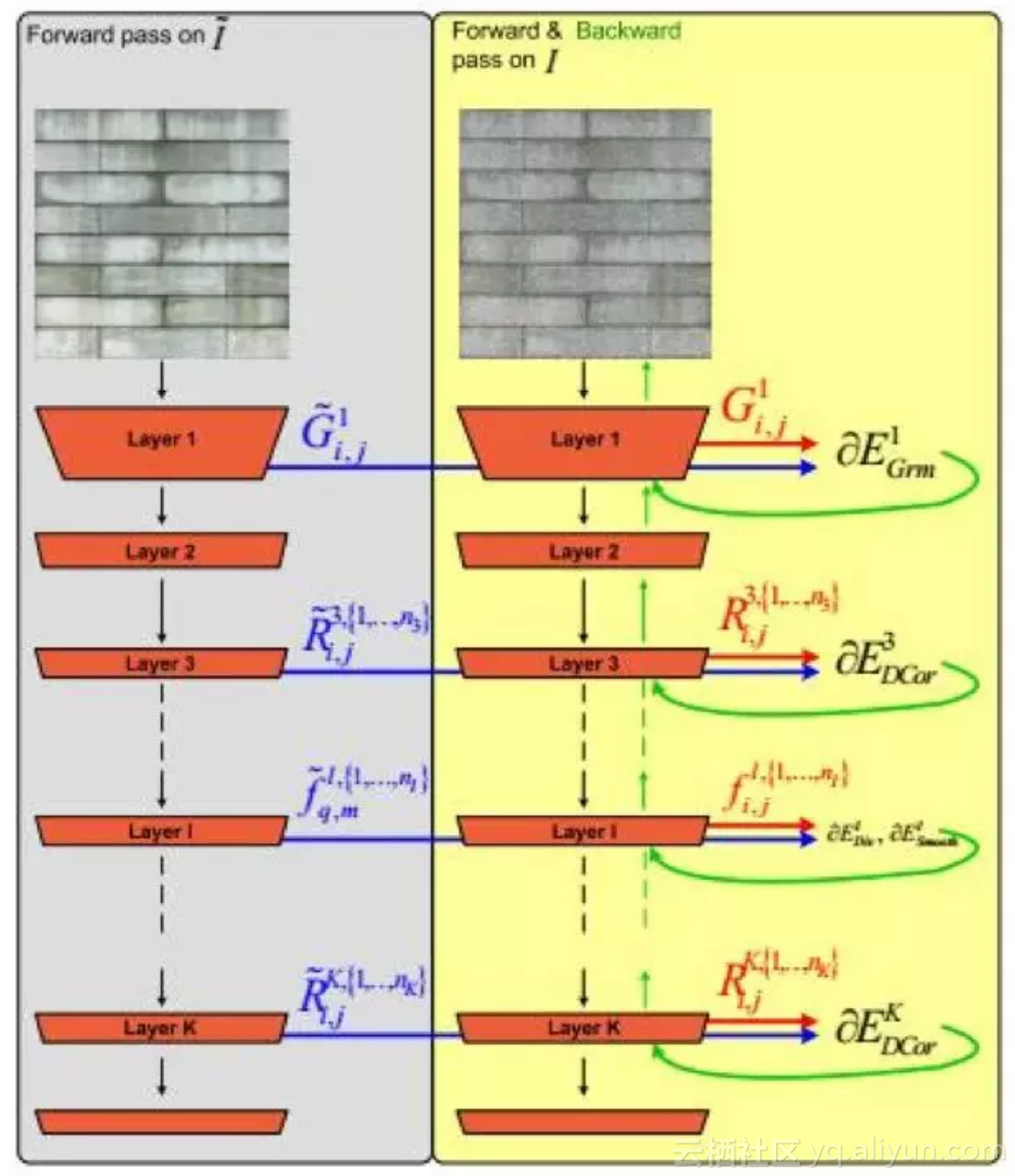
文献[56]提出了一种用卷积网络学习纹理的特征,然后合成纹理的方法。它们的方法思路和Leon 的类似,也是用一个卷积网络提取出图像在各个层的纹理特征,另外,用同样的网络对一张白噪声图像进行处理,提取出相同的纹理特征。然后用梯度下降法更新噪声图像,目标是使得二者的纹理特征相同。在这里,他们没有使用Gram矩阵描述纹理特征,而是使用了结构化能量,它基于输出图像的相关系数,捕捉纹理的自相似性和规则性。
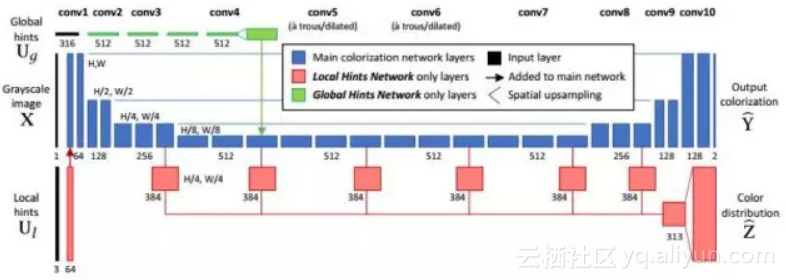
图像彩色化的目标是给定一张黑白图像,在少量的用户交互作用下生成对应的彩色图像。在这里的用户交互一般是让用户在黑白图像的某些位置设置颜色。
文献[60]提出了一种使用卷积网络将黑白图像彩色化的方法。卷积网络的输入是灰度图像以及少量的用户提示信息,输出数据是彩色图像。其目标是根据灰度图像的结构信息以及用户在几个典型位置的输入颜色,预测出每个像素的颜色值。系统由两个神经网络构成。第一个为局部提示网络,它接受稀疏的用户输入;第二个网络是全局提示网络,它使用图像的全局统计信息。
下图是彩色化的结果:

High Dynamic Range即高度动态范围,简称HDR,它确保在某些极端光照条件下,图像的高光和弱光区域都很清晰。普通照相机因为传感器量化范围的限制,产生的图像图像会有欠曝光或者过曝光区域,HDR是解决这个问题的一种方法。
产生HDR图像的做法一般是用相机拍摄多张有不同曝光度的LDR(Low Dynamic Range,低动态范围)的图像,然后合并成一张高动态范围的图像。生成HDR图像需要解决两个问题:1.需要将多张LDR图像对齐,2.将这些图像进行合并,生成HDR图像。第1个问题可以用光流法等手段解决,但会留下人工痕迹。
文献[54]提出了一种用机器学习的手段进行HDR图像合成的方法。这种方法能够根据3张不同曝光的LDR图像生成HDR图像。首先用光流法将高曝光与低曝光图像与中度曝光图像对齐,中度曝光图像为参考图像。最后生成的HDR图像与参考图像对齐,但包含另外两张图像即高曝光与低曝光图像的信息。然后将3张对齐的图像送入卷积网络中预测,生成HDR图像。

自然语言处理
自然语言处理领域大多数的问题都是时间序列问题,这是循环神经网络擅长处理的问题,在下一章中我们将详细介绍。但对于有些问题,使用卷积网络也能进行建模并且得到了很好的结果,在这里我们重点介绍文本分类和机器翻译。
文献[64]设计了一种用卷积网络进行句子分类的方案。这个方法的结构很简单,使用不同尺寸的卷积核对文本矩阵进行卷积,卷积核的宽度等于词向量的长度,然后使用max池化。对每一个卷积核提取的向量进行操作,最后每一个卷积核对应一个数字,把这些数据拼接起来,得到一个表征该句子的向量。最后的预测都是基于该句子的。
文献[65]提出了一种用卷积网络进行机器翻译的方法。这篇文章用卷积网络实现了序列到序列的学习,而之前的经典做法是用循环神经网络构建序列到序列的学习框架。在WMT 14的英语-德语,英语-法语数据集上,这种方法的精度超越了Google的LSTM循环神经网络翻译系统。
工程优化
深度神经网络的模型需要占用大量的存储空间,网络传输时也会耗费大量的带宽和时间,这限制了在移动设备、智能终端上的应用。在Caffe中,AlexNet网络的模型文件超过200MB,VGG则超过500MB,这样的模型文件是不适合集成到app安装包中的。因此需要对模型进行压缩,在下一节中我们将介绍解决这一问题的典型方法。
复杂的模型不仅带来存储空间的问题,还有计算量的增加。运行在服务端的模型可以通过GPU、分布式等并行计算技术进行加速,运行在移动端和嵌入式系统中的模型由于成本等因素的限制,除了采用并行计算等进行加速之外,还需要对算法和模型本身进行裁剪或者优化以加快速度。在下一节中,我们将详细介绍加快网络运行速度的方法。
减少存储空间和计算量的一种方法是对神经网络的模型进行压缩。有多种实现手段,包括减小网络的规模,对模型的权重矩阵进行压缩,对模型的参数进行编码,神经网络二值化等,接下来分别介绍。
权重剪枝
文献[71]提出了一种卷积神经网络模型压缩方法。在不影响精度的前提下,能够将AlexNet网络模型的参数减少到1/9,VGG-16网络模型的参数减少到1/13。其做法是先按照正常的流程训练神经网络,然后去掉小于指定阈值的权重,最后对剪枝后的模型进行重新训练,反复执行上面的过程直到完成模型的压缩。
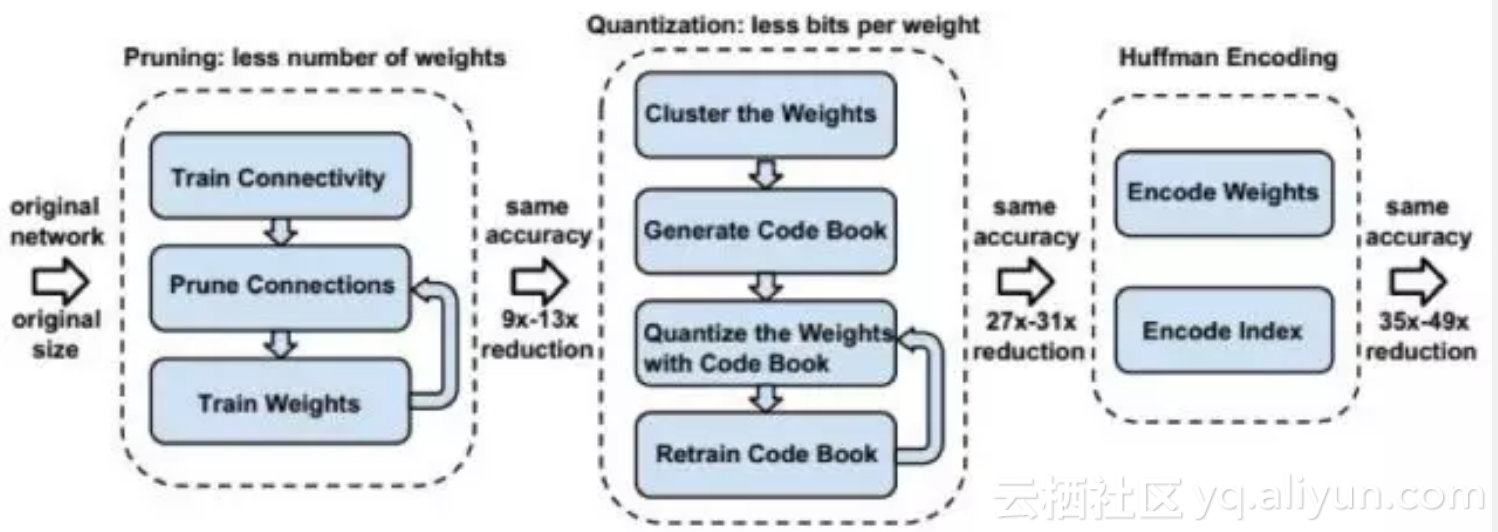
更进一步,文献[72]提出了一种称为deep compression的深度模型压缩技术,通过剪枝、量化和哈夫曼编码对模型进行压缩,而且不会影响网络的精度。整个方法分为3步,第1步对模型进行剪枝,只保留一些重要的连接。第2步通过权值量化来共享一些权值。第3步通过哈夫曼编码来进一步压缩数据。
二值化网络
将网络的权重由浮点数转换为定点数甚至是二值数据可以大幅度的提高计算的速度,减少模型的存储空间。相比浮点数的加法和乘法运算,定点数要快很多,而二值化数据的运算可以直接用位运算实现,带来的加速比更大。
文献[73]提出了一种称为二值神经网络(简称BNN)的模型。二值神经网络的权重值和激活函数都是二值化的数据,这能显著减小模型存储空间,并且加快模型的计算速度。
文献[74]提出了一种称为二值权重网络和XNOR(同或门)网络的模型,这是对卷积神经网络的二值化逼近,也是对文献[17]方法的进一步优化。
二值权重网络的权重矩阵是二值化数据,输入数据是实数。XNOR网络的卷积核、卷积层、全连接层的输入数据都是二值化的。在不损失精度的前提下,XNOR网络能够把模型的存储空间压缩为1/32,速度提升58倍。
参考文献:
[1] .LeCun, B.Boser, J.S.Denker, D.Henderson, R.E.Howard, W.Hubbard, and L.D.Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
[2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Handwritten digit recognition with a back-propagation network. In David Touretzky, editor, Advances in Neural Information Processing Systems 2 (NIPS*89), Denver, CO, 1990, Morgan Kaufman.
[3] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
[4] H. Rowley, S. Baluja, and T. Kanade. Neural Network-Based Face Detection. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE Computer Society, 1996. 203-208
[5] H. Rowley, S. Baluja, and T. Kanade. Rotation Invariant Neural Network-Based Face Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santa Barbara, CA, USA: IEEE Computer Society, 1998. 38-44
[6] S Lawrence, C L Giles, Ah Chung Tsoi, Andrew D Back.Face recognition: a convolutional neural-network approach.1997, IEEE Transactions on Neural Networks.
[7] P. Y. Simard, D. Steinkraus, and J. C. Platt, Best practices for convolutional neural networks applied to visual document analysis. in null. IEEE, 2003.
[8] X. Glorot, Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. AISTATS, 2010.
[9] Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.
[10] G.E.Hinton, N.Srivastava, A.Krizhevsky, I.Sutskever, and R.R.Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
[11] Nair, V. and Hinton. Rectified linear units improve restricted Boltzmann machines. In L. Bottou and M. Littman, editors, Proceedings of the Twenty-seventh International Conference on Machine Learning (ICML 2010).
[12] Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks. European Conference on Computer Vision, 2013.
[13] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link: http://arxiv.org/abs/1409.4842.
[14] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. 2015, computer vision and pattern recognition.
[16] Lin, Min, Qiang Chen, and Shuicheng Yan. Network in network. arXiv preprint arXiv:1312.4400
[17] Zeiler M D, Krishnan D, Taylor G W, et al. Deconvolutional networks. Computer Vision and Pattern Recognition, 2010.
[18] Stephane Mallat. Understanding deep convolutional networks. 2016, Philosophical Transactions of the Royal Society A.
[19] Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. CVPR 2015.
[20] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
[21] Ross Girshick. Fast R-CNN. 2015, international conference on computer vision.
[22] Anelia Angelova, Alex Krizhevsky, Vincent Vanhoucke, Abhijit Ogale, Dave Ferguson. Real-Time Pedestrian Detection With Deep Network Cascades.
[23] Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection. 2015, computer vision and pattern recognition
[24] Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu. DenseBox: Unifying Landmark Localization with End to End Object Detection. 2015, arXiv: Computer Vision and Pattern Recognition
[25] Shuo Yang, Ping Luo, Chen Change Loy, Xiaoou Tang. Faceness-Net: Face Detection through Deep Facial Part Responses.
[26] Yi Sun, Xiaogang Wang, Xiaoou Tang. Deep Convolutional Network Cascade for Facial Point Detection. 2013, computer vision and pattern recognition.
[27] Kobchaisawat T, Chalidabhongse T H. Thai text localization in natural scene images using Convolutional Neural Network. Asia-Pacific Signal and Information Processing Association, 2014 Annual Summit and Conference (APSIPA). IEEE, 2014: 1-7.
[28] Guo Q, Lei J, Tu D, et al. Reading numbers in natural scene images with convolutional neural networks. Security, Pattern Analysis, and Cybernetics (SPAC), 2014 International Conference on. IEEE, 2014: 48-53.
[29] Xu H, Su F. A robust hierarchical detection method for scene text based on convolutional neural networks. Multimedia and Expo (ICME), 2015 IEEE International Conference on. IEEE, 2015: 1-6.
[30] Cireşan D C, Meier U, Gambardella L M, et al. Convolutional neural network committees for handwritten character classification. Document Analysis and Recognition (ICDAR), 2011 International Conference on. IEEE, 2011: 1135-1139.
[31] Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation. Computer Vision and Pattern Recognition, 2015.
[32] I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the Importance of Initialization and Momentum in Deep Learning. Proceedings of the 30th International Conference on Machine Learning, 2013.
[33] Hyeonwoo Noh, Seunghoon Hong, Bohyung Han. Learning Deconvolution Network for Semantic Segmentation. 2015, international conference on computer vision.
[34] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.Yuille. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. 2016.
[35] Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.
[36] R. Girshick, J. Donahue, T. Darrell, J. Malik. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, May. 2015.
[37] Wei Shen, Xinggang Wang, Yan Wang, Xiang Bai, Zhijiang Zhang. DeepContour: A deep convolutional feature learned by positive-sharing loss for contour detection. 2015 computer vision and pattern recognition.
[38] Saining Xie, Zhuowen Tu. Holistically-Nested Edge Detection. 2015. international conference on computer vision.
[39] Gedas Bertasius, Jianbo Shi, Lorenzo Torresani. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection. 2015, computer vision and pattern recognition
[40] Gatys L A, Ecker A S, Bethge M. Image Style Transfer Using Convolutional Neural Networks. CVPR 2016.
[41] David Eigen, Christian Puhrsch, Rob Fergus. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. 2014, neural information processing systems.
[42] David Eigen, Rob Fergus. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. 2015, international conference on computer vision.
[43] Naiyan Wang, Dityan Yeung. Learning a Deep Compact Image Representation for Visual Tracking. 2013, neural information processing systems.
[44] Naiyan Wang, Siyi Li, Abhinav Gupta, Dityan Yeung. Transferring Rich Feature Hierarchies for Robust Visual Tracking. 2015, arXiv: Computer Vision and Pattern Recognition.
[45] Hyeonseob Nam, Bohyung Han. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. 2016, computer vision and pattern recognition.
[46] Lijun Wang, Wanli Ouyang, Xiaogang Wang, Huchuan Lu. Visual Tracking with Fully Convolutional Networks. 2015, international conference on computer vision.
[47] Chao Ma, Jiabin Huang, Xiaokang Yang, Minghsuan Yang. Hierarchical Convolutional Features for Visual Tracking. 2015, international conference on computer vision.
[48] Yuankai Qi, Shengping Zhang, Lei Qin, Hongxun Yao, Qingming Huang, Jongwoo Lim, Minghsuan. Hedged Deep Tracking. 2016, computer vision and pattern recognition.
[49] Luca Bertinetto, Jack Valmadre, Joao F Henriques, Andrea Vedaldi, Philip H S Torr. Fully-Convolutional Siamese Networks for Object Tracking. 2016, european conference on computer vision.
[50] David Held, Sebastian Thrun, Silvio Savarese. Learning to Track at 100 FPS with Deep Regression Networks. 2016, european conference on computer vision.
[51] Pengshuai Wang, Yang Liu, Yuxiao Guo, Chunyu Sun, Xin Tong. O-CNN: octree-based convolutional neural networks for 3D shape analysis. 2017, ACM Transactions on Graphics.
[52] Mengyu Chu, Nils Thuerey. Data-Driven Synthesis of Smoke Flows with CNN-based Feature Descriptors. 2017, ACM Transactions on Graphics
[53] Xiao Li, Yue Dong, Pieter Peers, Xin Tong. Modeling surface appearance from a single photograph using self-augmented convolutional neural networks. 2017, ACM Transactions on Graphics.
[54] Nima Khademi Kalantari, Ravi Ramamoorthi. Deep high dynamic range imaging of dynamic scenes. 2017, ACM Transactions on Graphics.
[55] Leon A Gatys, Alexander S Ecker, Matthias Bethge. Texture synthesis using convolutional neural networks. 2015, neural information processing systems.
[56] Omry Sendik, Daniel Cohenor. Deep Correlations for Texture Synthesis. 2017, ACM Transactions on Graphics
[57] Michael Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, Fredo Durand. Deep Bilateral Learning for Real-Time Image Enhancement. 2017, ACM Transactions on Graphics.
[58] Jonathan Tompson, Kristofer Schlachter, Pablo Sprechmann, Ken Perlin. Accelerating Eulerian Fluid Simulation With Convolutional Networks. 2016,international conference on machine learning.
[59] Peiran Ren,Yue Dong,Stephen Lin,Xin Tong,Baining Guo. Image based relighting using neural networks. 2015,international conference on computer graphics and interactive techniques.
[60] Richard zhang, Jun-Yan Zhu, Phillip Isola, XinYang Geng, Angela S. Lin, Tianhe Yu, Alexei A. Efros. Real-Time User-Guided Image Colorization with Learned Deep Priors.
[61] Yoon Kim. Convolutional Neural Networks for Sentence Classification. 2014, empirical methods in natural language processing.
[62] Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. arXiv preprint arXiv:1509.01626, 2015.
[63] Rie Johnson and Tong Zhang. Effective use of word order for text categorization with convolutional neural networks. arXiv preprint arXiv:1408.5882, 2014.
[64] Phil Blunsom, Edward Grefenstette, Nal Kalchbrenner, et al. A Convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2015.
[65] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin. Convolutional Sequence to Sequence Learning. 2017.
[66] S. Ioffe and C. Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv preprint arXiv:1502.03167 (2015).
[67] Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. The Journal of Machine Learning Research, 2011.
[68] D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
[69] T. Tieleman, and G. Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning.Technical report, 2012.
[70] M. Zeiler. ADADELTA: An Adaptive Learning Rate Method. arXiv preprint, 2012.
[71] Han, Song, Pool, Jeff, Tran, John, and Dally, William J. Learning both weights and connections for efficient neural networks. In Advances in Neural Information Processing Systems, 2015.
[72] Song Han, Huizi Mao, William J Dally. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. 2016, international conference on learning representations.
[73] Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran Elyaniv, Yoshua Bengio. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. 2016,arXiv: Learning.
[74] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, Ali Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. 2016, european conference on computer vision.
原文发布时间为:2018-05-10
本文作者:SigAI
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。
原文链接:深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 转载:CVPR 2019 论文汇总(按方向划分,0611 更新中)
原贴地址:http://bbs.cvmart.net/topics/302/cvpr2019paper#12 作为计算机视觉领域三大顶会之一,CVPR2019(2019.6.16-6.19在美国洛杉矶举办)被CVers 重点关注。目前CVPR 2019 接收结果已经出来啦,相关报道:…...
2024/4/21 1:18:24 - CVPR 2019 论文最新汇总(按方向划分,0611 更新中)
作为计算机视觉领域三大顶会之一,CVPR2019(2019.6.16-6.19在美国洛杉矶举办)被CVers 重点关注。目前CVPR 2019 接收结果已经出来啦。 CVPR2019接收论文id查看链接: http://cvpr2019.thecvf.com/files/cvpr_2019_final_accept_list.txt cvpr…...
2024/4/26 0:44:09 - CVPR2019 | 论文分类汇总
作为计算机视觉领域三大顶会之一,CVPR2019(2019.6.16-6.19在美国洛杉矶举办)被CVers 重点关注。目前CVPR 2019 接收结果已经出来啦,相关报道:1300篇!CVPR2019接收结果公布,你中了吗?…...
2024/4/21 1:18:21 - CVPR 2019 论文汇总(按方向进行论文划分)
cvpr2019 accepted papers title(官方分类,需科学前往) Github论文汇总链接(欢迎star) 论文PDF下载(更新中,提取码:osvy) 论文解读汇总 目录:(也欢迎大家推荐自己的CVP…...
2024/4/21 1:18:20 - ICCV2017 论文浏览记录(转)
mark一下,感谢作者分享! 作者将ICCV2017上的论文进行了汇总,在此记录下来,平时多注意阅读积累。 之前很早就想试着做一下试着把顶会的论文浏览一遍看一下自己感兴趣的,顺便统计一下国内高校或者研究机构的研究方向&am…...
2024/5/4 6:45:00 - 2020年 ICLR 国际会议最终接受论文(poster-paper)列表(三)
来源:AINLPer微信公众号(点击了解一下吧) 编辑: ShuYini 校稿: ShuYini 时间: 2020-02-21 2020年的ICLR会议将于今年的4月26日-4月30日在Millennium Hall, Addis Ababa ETHIOPIA(埃塞俄比亚首都亚的斯亚贝巴 千禧大厅)…...
2024/4/21 1:18:18 - CVPR2019 | 论文分类汇总(190611 更新)
原文链接:http://bbs.cvmart.net/topics/302/cvpr2019paper 本文论文链接较多,前往原文查看可以直接跳转 作为计算机视觉领域三大顶会之一,CVPR2019(2019.6.16-6.19在美国洛杉矶举办)被CVers 重点关注。目前CVPR 2019 …...
2024/5/3 1:36:28 - 历史最全DL相关书籍、课程、视频、论文、数据集、会议、框架和工具整理分享
本文整理了与深度学习、人工智能相关丰富的内容,涉及人工智能相关的思维导图 (100张AI思维导图),深度学习相关的免费在线书籍、课程、视频和讲座、论文、教程、研究人员、网站、数据集、会议、框架、工具等资源。 内容整理自网络,源地址&…...
2024/4/26 13:15:06 - 【0514 更新中】CVPR 2019 论文汇总 按方向划分
CVPR 2019 论文汇总(按方向划分,0514 更新中) 作为计算机视觉领域三大顶会之一,CVPR2019(2019.6.16-6.19在美国洛杉矶举办)被CVers 重点关注。目前CVPR 2019 接收结果已经出来啦,相关报道&#…...
2024/4/21 1:18:16 - 机器学习 机器视觉 图像处理 牛人牛站
转帖地址:http://www.guzili.com/?p42636 转贴:看到的一个来源是http://blog.sina.com.cn/s/blog_631a4cc40101d00t.html,不确定是否是最原始版本。 牛人主页(主页有很多论文代码) Serge Belongieat UC San DiegoAnt…...
2024/4/21 1:18:14 - 【今日CV 计算机视觉论文速览 第98期】Wed, 10 Apr 2019
今日CS.CV 计算机视觉论文速览 Wed, 10 Apr 2019 Totally 67 papers ?上期速览 ✈更多精彩请移步主页 Interesting: ?通用物体检测框架, 在不需要先验知识的强化下实现了横跨多个域的目标检测,这要通过引入一系列的适应层,基于序列和激活的原理和新域…...
2024/5/4 4:23:38 - 计算机视觉、模式识别、机器学习相关方向资源
牛人主页(主页有很多论文代码) Serge Belongie at UC San DiegoAntonio Torralba at MITAlexei Ffros at CMUCe Liu at Microsoft Research New EnglandVittorio Ferrari at Univ.of EdinburghKristen Grauman at UT AustinDevi Parikh at TTI-Chicago …...
2024/4/20 14:11:30 - 深度学习在CV领域的进展以及一些由深度学习演变的新技术
CV领域 1.进展:如上图所述,当前CV领域主要包括两个大的方向,”低层次的感知” 和 “高层次的认知”。 2.主要的应用领域:视频监控、人脸识别、医学图像分析、自动驾驶、 机器人、AR、VR 3.主要的技术:分类、目标检测&a…...
2024/4/20 2:21:17 - 机器学习牛人主页及相关会议,论文和期刊
国际顶级会议 AAAICIKM 2010CIKM 2011COLT 2010COLT 2011Computer Vision ResourceICJIAICMLNIPSSIGIR 2010SIGIR 2011SIGKDDSIGKDD2010 论文搜索 CV顶级会议论文下载google 学术搜索超全计算机视觉资源汇总联合参考文献 学术牛人主页 feifei li -computer visionGooglers i…...
2024/4/27 4:33:06 - 深度学习大牛的主页
深度学习大牛的主页 https://blog.csdn.net/ahayo123/article/details/18654099#commentBox 牛人主页(主页有很多论文代码) Serge Belongie at UC San Diego Antonio Torralba at MITAlexei Ffros at CMUCe Liu at Microsoft Research New EnglandVitt…...
2024/4/19 23:36:18 - ECCV 2020 Oral 论文汇总!
ECCV 2020论文已公布,本届 ECCV 共收到有效投稿5025篇,接收1361篇,其中Oral论文 104 篇,仅占 2%。本文汇总截止今日所有Oral 论文,其中已经公布完整论文的有 47 篇,按照研究方向进行了初步分类。这些论文中…...
2024/4/19 22:38:48 - 人脸识别相关资源大列表
之前逛爱可可老师微博看到的一个人脸识别资源,还是比较全面的,跟大家分享一下。 github链接:https://github.com/ChanChiChoi/awesome-Face_Recognition 作者:ChanChiChoi 原文地址:http://bbs.cvmart.net/articles/25…...
2024/4/27 15:58:20 - 【老鸟进阶】deepfacelab错误人脸图片快速处理
提取人脸后难免会有提取异常的数据,轻则污染src训练数据,重则dst合成异常。本文介绍各种异常情况以及对应解法 1. 提取到的人脸混合了多个角色 2. 提取到的人脸大小、方向异常 3. 提取到的人脸有特别模糊的人脸 4. 目标人脸没有被提取出来 1.提取到的…...
2024/4/19 21:19:57 - 【老鸟进阶】deepfacelab如何让融合更自然(二)清晰度篇
当你注意到清晰度问题时,恭喜你已经是个老鸟了。 本篇就来讲讲清晰度相关的进阶教程 清晰度通常有以下几种情况导致看上去违和 1. 视频清晰、SRC脸模糊 (常见) 2. 视频模糊、SRC脸清晰 (偶尔) 3. 视频DST人脸时而清晰时…...
2024/4/20 11:20:11 - 【新手入门】deepfacelab预训练模型的概念与用法
看了简明视频教程后,相信大家已经熟悉了软件的基本操作,现在我来通俗的讲讲大家经常说的预训练模型(神丹)是个什么神器玩意儿什么是模型?论坛里的模型均指神经网络模型神经网络模型顾名思义就像人的大脑。这么讲虽然有…...
2024/4/30 21:37:15
最新文章
- STM32——GPIO篇
技术笔记! 1. 什么是GPIO? GPIO是通用输入输出端口(General-purpose input/output)的英文简写,是所有的微控制器必不可少的外设之一,可以由STM32直接驱动从而实现与外部设备通信、控制以及采集和捕获的功…...
2024/5/4 8:21:12 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 文件输入/输出流(I/O)
文章目录 前言一、文件输入\输出流是什么?二、使用方法 1.FileInputStream与FileOutputStream类2.FileReader与FileWriter类总结 前言 对于文章I/O(输入/输出流的概述),有了下文。这篇文章将具体详细展述如何向磁盘文件中输入数据,或者读取磁…...
2024/4/30 2:44:51 - 2024免费Mac苹果解压压缩包软件BetterZip5
在2024年,对于Mac电脑用户来说,如果你想要无需解压就能快速查看压缩文档的内容,BetterZip是一个极佳的选择。这款软件不仅支持多种格式的压缩和解压,如zip、rar、7z、tar等,还具备丰富的功能和设置,包括预览…...
2024/5/2 2:34:06 - JavaEE 初阶篇-生产者与消费者模型(线程通信)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 生产者与消费者模型概述 2.0 在生产者与消费者模型中涉及的关键概念 2.1 缓冲区 2.2 生产者 2.3 消费者 2.4 同步机制 2.5 线程间通信 3.0 实现生产者与消费者模…...
2024/5/2 21:34:51 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/1 17:30:59 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/2 16:16:39 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/29 2:29:43 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/3 23:10:03 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/27 17:58:04 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/27 14:22:49 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/28 1:28:33 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/30 9:43:09 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/27 17:59:30 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/2 15:04:34 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/28 1:34:08 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/29 20:46:55 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/30 22:21:04 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/1 4:32:01 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/4 2:59:34 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/28 5:48:52 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/30 9:42:22 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/2 9:07:46 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/30 9:42:49 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57