文本主题模型之LDA
什么是话题模型(topic model)?
话题模型就是用来发现大量文档集合的主题的算法。借助这些算法我们可以对文档集合进行归类。适用于大规模数据场景。目前甚至可以做到分析流数据。需要指出的是,话题模型不仅仅限于对文档的应用,可以应用在其他的应用场景中,例如基因数据、图像处理和社交网络。这是一种新的帮助人类组织、检索和理解信息的计算工具。
通过这类算法获得的那些主题都可以比喻成望远镜不同的放大倍数。我们可以根据特定的情形设置可以看到的关注对象的精度;并且可以研究主题随着时间变化产生的相关变化。这样的思考方式对于很多场景都是有效的,例如在搜索时,我们可以把单纯使用关键词的相关性推进到结合主题的结果整合从而给用户更好的使用体验。
Latent Dirichlet Allocation(LDA)
【总结】
LDA(Latent dirichlet allocation)[1]是有Blei于2003年提出的三层贝叶斯主题模型,通过无监督的学习方法发现文本中隐含的主题信息,目的是要以无指导学习的方法从文本中发现隐含的语义维度-即“Topic”或者“Concept”。隐性语义分析的实质是要利用文本中词项(term)的共现特征来发现文本的Topic结构,这种方法不需要任何关于文本的背景知识。文本的隐性语义表示可以对“一词多义”和“一义多词”的语言现象进行建模,这使得搜索引擎系统得到的搜索结果与用户的query在语义层次上match,而不是仅仅只是在词汇层次上出现交集。
这是最简单的话题模型。LDA的直觉上认为文档有多个话题生成。这个过程也是LDA给出的文档生成过程。
LDA生成过程:
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
首先我们所做的事情都在词典的限定下,就是文档中出现的词都不会超出词典给出的范围。比如说,话题“基因”中以很高的概率包含若干关于基因的词,而话题“进化生物学”则会以很高概率包含进化生物学的相关词。我们假设这些话题在数据产生前已经确定了。现在在文档集合中的每个文档,我们来生成其中的文字。步骤如下:
- 随机选择话题之上的分布
- 对文档中的每个词
2.1 从步骤1中产生的分布中随机选择一个话题
2.2 从词典上的对应分布中随机选择一个词
这个统计模型反应出文档拥有不同比例的话题(步骤1);每个文档中的每个词都是从众多话题之一中抽取出来的(步骤2.2),而被选择的话题是从针对每个文档的话题上的分布中产生的(步骤2.1)
简单理解这个生成过程:
在LDA中,所有的文档共有同样的话题集,但是每个文档以不同的比例展示对应的话题。LDA的主要目标是自动发现一个文档集合中的话题。这些文档本身是可以观测到的,而话题的结构——话题、每个文档的话题分布和每个文档的每个词的话题赋值——是隐藏的(可称为hidden structure)。话题建模的核心计算问题就是使用观测到的文档来推断隐藏话题结构。这也可以看作是生成(generative)过程的逆过程——什么样的隐藏结构可以产生观测到的文档集合?
借助LDA算法可以得到话题的结构,需要指出的是,算法本身并不需要用到这些话题的信息,文档本身也没有使用话题或者关键字进行标注。这个隐藏结构最有可能产生现在可以观测到的文档集合。
话题模型方便的地方就是可以通过推断的隐藏结构来组成文档的主题结构。这样的信息对于信息检索,分类和语料研究提供了有力的支撑。所以可以这样说,话题模型给出了一种管理、组织和标注文本的大量集合的算法解答。
LDA的定义和分析
LDA和其他一些话题模型从属于概率建模领域之下。生成概率建模中,我们的数据可以从一个包含了隐藏变量的生成过程中得到。这个生成过程定义了一个在已观测随机变量和隐藏随机变量之上的联合概率分布。我们通过使用联合概率分布来计算给定观测变量值下的隐藏变量的条件分布。这种条件分布也被叫做后验分布。
LDA正好属于这个框架。已观测的变量就是那些文档中的词;隐藏变量就是话题模型;生成过程就是前面我们介绍的。而从文档来推断隐藏话题结构的问题就变成了计算后验分布的问题——计算给定文档后隐藏变量的条件分布。
现在我们可以形式化地描述LDA,话题 (Topics)是\beta_{1:K},其中每个\beta_k是在词典上的分布。第d个文档的话题比例(Per-document topic proportions)是\theta_d,其中\theta_{d,k}是话题k在文档d中的比例。对第d个文档的话题赋值 (Per-word topic assignment) 就是z_d,其中z_{d,n}是第d个文档的第n个词的话题赋值。最后,文档d观测到的词 (Observed word) 是w_d,其中w_{d,n}是在文档d中的第n个词,它是来自于我们给定的词典的。
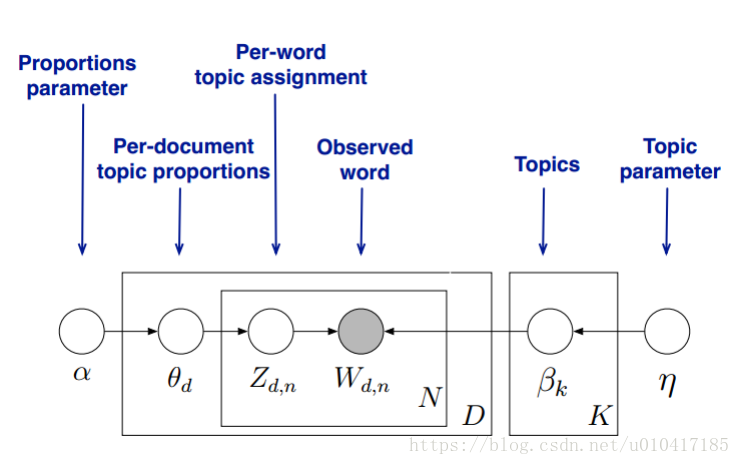
LDA参数:
K为主题个数,M为文档总数,是第m个文档的单词总数。
是每个Topic下词的多项分布的Dirichlet先验参数,
是每个文档下Topic的多项分布的Dirichlet先验参数。
是第m个文档中第n个词的主题,
是m个文档中的第n个词。剩下来的两个隐含变量
和
分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
使用这个表示方法,LDA生成过程对应于下面的隐藏变量和观测变量的联合分布:
p(\beta_{1:K},\theta_{1:D},z_{1:D},w_{1:D})
= \prod_{i=i}^k p(\beta_i) \prod_{d=1}^D p(\theta_d) (\prod_{n=1}^N p(z_{d,n}|\theta_d)p(w_{d,n}|\beta_{1:K},z_{d,n}))这个分布给出一些依赖关系。例如,话题赋值z_{d,n}依赖于对每个文档的话题比例\theta_d和所有的话题\beta_{1:K}(从实施角度上看,这个项首先通过确定其代表的话题z_{d,n}而后在那个话题中查询w_{d,n}相应的概率)
正是这样依赖关系定义了LDA。他们由生成过程背后的统计假设给出,以一种联合分布的数学形式和针对LDA的概率图模型的方式确定了这些依赖关系。概率图模型提供了一个图形化的语言来描述概率分布的家族(family)。这些表示方法都可以描述LDA背后的概率假设。
后面我们会介绍一下LDA的推断算法。这里顺便提一下pLSI(probabilistic latent semantic analysis)。这个模型本身是LSA的概率版本,它揭示了SVD在文档-项矩阵上的作用。从矩阵分解的角度看,LDA同样可以看作是对于离散数据的PCA。
LDA的后验分布计算
现在就开始介绍LDA的后验分布的计算,也就是在给定观测文档下计算话题结构的条件分布。(这就是传说中的后验分布posterior)
其定义如下:
p(\beta_{1:K},\theta_{1:D},z_{1:D}|w_{1:D})
= p(\beta_{1:K},\theta_{1:D},z_{1:D}, w_{1:D}) / p(w_{1:D})当然了,可能的话题结构是指数级大的,这个问题难解的(NP-hard)。正如很多现代概率模型那样,因为分母难以计算就使得我们很难计算出后验。所以现代概率模型研究的焦点之一就是设计出高效的近似方法。话题模型算法通常是通用近似后验分布方法的适配使用。
话题模型算法通过适配一种隐藏话题结构的分布来接近最终正确的后验。而主要的话题建模算法可以分成两种——基于采样的算法和变分算法。
基于采样的算法尝试从后验分布中搜集样本使用一个经验分布来近似它。最常用的采样算法是Markov chain——一个随机变量的序列,每个变量只依赖于前一个,其极限分布是我们需要的后验分布。Markov chain定义在对一个特定的语料的隐藏话题变量上,算法思想就是运行chain很长一段时间,从极限分布中搜集样本,接着使用搜集来的样本来近似分布。(常常,仅仅是一个有着最大概率的样本被搜集来作为近似的话题结构)。
变分方法是一个确定性的方式。变分方法没有去使用样本来近似后验,而是采用了一个在隐藏结构上的参数化的分布家族,接着找到家族中最靠近后验的那个成员。因此,推断问题就被转化为一个优化问题了。变分方法打开了一扇通向实用的概率建模的创新大门。
See Blei et al.8 for a coordinate ascent variational inference algorithm for LDA; see Hoffman et al.20 for a much faster online algorithm (and open-source software) that easily handles millions of documents and can accommodate streaming collections of text.
不严格地说,两种类型的算法都是在话题结构上的一种搜索。文档集合(模型中的观测到的随机变量)是确定的,并当作是一个搜索方向的指导。方法的优劣取决于所使用的特定的话题模型——除了我们前面一直讨论的LDA,还有其他的话题模型——这也是学术争论之源。
#-*- coding:utf-8 -*-
import logging
import logging.config
import ConfigParser
import numpy as np
import random
import codecs
import os from collections import OrderedDict
#获取当前路径
path = os.getcwd()
#导入日志配置文件
logging.config.fileConfig("logging.conf")
#创建日志对象
logger = logging.getLogger()
# loggerInfo = logging.getLogger("TimeInfoLogger")
# Consolelogger = logging.getLogger("ConsoleLogger") #导入配置文件
conf = ConfigParser.ConfigParser()
conf.read("setting.conf")
#文件路径
trainfile = os.path.join(path,os.path.normpath(conf.get("filepath", "trainfile")))
wordidmapfile = os.path.join(path,os.path.normpath(conf.get("filepath","wordidmapfile")))
thetafile = os.path.join(path,os.path.normpath(conf.get("filepath","thetafile")))
phifile = os.path.join(path,os.path.normpath(conf.get("filepath","phifile")))
paramfile = os.path.join(path,os.path.normpath(conf.get("filepath","paramfile")))
topNfile = os.path.join(path,os.path.normpath(conf.get("filepath","topNfile")))
tassginfile = os.path.join(path,os.path.normpath(conf.get("filepath","tassginfile")))
#模型初始参数
K = int(conf.get("model_args","K"))
alpha = float(conf.get("model_args","alpha"))
beta = float(conf.get("model_args","beta"))
iter_times = int(conf.get("model_args","iter_times"))
top_words_num = int(conf.get("model_args","top_words_num"))
class Document(object): def __init__(self): self.words = [] self.length = 0
#把整个文档及真的单词构成vocabulary(不允许重复)
class DataPreProcessing(object): def __init__(self): self.docs_count = 0 self.words_count = 0 #保存每个文档d的信息(单词序列,以及length) self.docs = [] #建立vocabulary表,照片文档的单词 self.word2id = OrderedDict() def cachewordidmap(self): with codecs.open(wordidmapfile, 'w','utf-8') as f: for word,id in self.word2id.items(): f.write(word +"\t"+str(id)+"\n")
class LDAModel(object): def __init__(self,dpre): self.dpre = dpre #获取预处理参数 # #模型参数 #聚类个数K,迭代次数iter_times,每个类特征词个数top_words_num,超参数α(alpha) β(beta) # self.K = K self.beta = beta self.alpha = alpha self.iter_times = iter_times self.top_words_num = top_words_num # #文件变量 #分好词的文件trainfile #词对应id文件wordidmapfile #文章-主题分布文件thetafile #词-主题分布文件phifile #每个主题topN词文件topNfile #最后分派结果文件tassginfile #模型训练选择的参数文件paramfile # self.wordidmapfile = wordidmapfile self.trainfile = trainfile self.thetafile = thetafile self.phifile = phifile self.topNfile = topNfile self.tassginfile = tassginfile self.paramfile = paramfile # p,概率向量 double类型,存储采样的临时变量 # nw,词word在主题topic上的分布 # nwsum,每各topic的词的总数 # nd,每个doc中各个topic的词的总数 # ndsum,每各doc中词的总数 self.p = np.zeros(self.K) # nw,词word在主题topic上的分布 self.nw = np.zeros((self.dpre.words_count,self.K),dtype="int") # nwsum,每各topic的词的总数 self.nwsum = np.zeros(self.K,dtype="int") # nd,每个doc中各个topic的词的总数 self.nd = np.zeros((self.dpre.docs_count,self.K),dtype="int") # ndsum,每各doc中词的总数 self.ndsum = np.zeros(dpre.docs_count,dtype="int") self.Z = np.array([ [0 for y in xrange(dpre.docs[x].length)] for x in xrange(dpre.docs_count)]) # M*doc.size(),文档中词的主题分布 #随机先分配类型,为每个文档中的各个单词分配主题 for x in xrange(len(self.Z)): self.ndsum[x] = self.dpre.docs[x].length for y in xrange(self.dpre.docs[x].length): topic = random.randint(0,self.K-1)#随机取一个主题 self.Z[x][y] = topic#文档中词的主题分布 self.nw[self.dpre.docs[x].words[y]][topic] += 1 self.nd[x][topic] += 1 self.nwsum[topic] += 1 self.theta = np.array([ [0.0 for y in xrange(self.K)] for x in xrange(self.dpre.docs_count) ]) self.phi = np.array([ [ 0.0 for y in xrange(self.dpre.words_count) ] for x in xrange(self.K)]) def sampling(self,i,j): #换主题 topic = self.Z[i][j] #只是单词的编号,都是从0开始word就是等于j word = self.dpre.docs[i].words[j] #if word==j: # print 'true' self.nw[word][topic] -= 1 self.nd[i][topic] -= 1 self.nwsum[topic] -= 1 self.ndsum[i] -= 1 Vbeta = self.dpre.words_count * self.beta Kalpha = self.K * self.alpha self.p = (self.nw[word] + self.beta)/(self.nwsum + Vbeta) * \ (self.nd[i] + self.alpha) / (self.ndsum[i] + Kalpha) #随机更新主题的吗 # for k in xrange(1,self.K): # self.p[k] += self.p[k-1] # u = random.uniform(0,self.p[self.K-1]) # for topic in xrange(self.K): # if self.p[topic]>u: # break #按这个更新主题更好理解,这个效果还不错 p = np.squeeze(np.asarray(self.p/np.sum(self.p))) topic = np.argmax(np.random.multinomial(1, p)) self.nw[word][topic] +=1 self.nwsum[topic] +=1 self.nd[i][topic] +=1 self.ndsum[i] +=1 return topic def est(self): # Consolelogger.info(u"迭代次数为%s 次" % self.iter_times) for x in xrange(self.iter_times): for i in xrange(self.dpre.docs_count): for j in xrange(self.dpre.docs[i].length): topic = self.sampling(i,j) self.Z[i][j] = topic logger.info(u"迭代完成。") logger.debug(u"计算文章-主题分布") self._theta() logger.debug(u"计算词-主题分布") self._phi() logger.debug(u"保存模型") self.save() def _theta(self): for i in xrange(self.dpre.docs_count):#遍历文档的个数词 self.theta[i] = (self.nd[i]+self.alpha)/(self.ndsum[i]+self.K * self.alpha) def _phi(self): for i in xrange(self.K): self.phi[i] = (self.nw.T[i] + self.beta)/(self.nwsum[i]+self.dpre.words_count * self.beta) def save(self): # 保存theta文章-主题分布 logger.info(u"文章-主题分布已保存到%s" % self.thetafile) with codecs.open(self.thetafile,'w') as f: for x in xrange(self.dpre.docs_count): for y in xrange(self.K): f.write(str(self.theta[x][y]) + '\t') f.write('\n') # 保存phi词-主题分布 logger.info(u"词-主题分布已保存到%s" % self.phifile) with codecs.open(self.phifile,'w') as f: for x in xrange(self.K): for y in xrange(self.dpre.words_count): f.write(str(self.phi[x][y]) + '\t') f.write('\n') # 保存参数设置 logger.info(u"参数设置已保存到%s" % self.paramfile) with codecs.open(self.paramfile,'w','utf-8') as f: f.write('K=' + str(self.K) + '\n') f.write('alpha=' + str(self.alpha) + '\n') f.write('beta=' + str(self.beta) + '\n') f.write(u'迭代次数 iter_times=' + str(self.iter_times) + '\n') f.write(u'每个类的高频词显示个数 top_words_num=' + str(self.top_words_num) + '\n') # 保存每个主题topic的词 logger.info(u"主题topN词已保存到%s" % self.topNfile) with codecs.open(self.topNfile,'w','utf-8') as f: self.top_words_num = min(self.top_words_num,self.dpre.words_count) for x in xrange(self.K): f.write(u'第' + str(x) + u'类:' + '\n') twords = [] twords = [(n,self.phi[x][n]) for n in xrange(self.dpre.words_count)] twords.sort(key = lambda i:i[1], reverse= True) for y in xrange(self.top_words_num): word = OrderedDict({value:key for key, value in self.dpre.word2id.items()})[twords[y][0]] f.write('\t'*2+ word +'\t' + str(twords[y][1])+ '\n') # 保存最后退出时,文章的词分派的主题的结果 logger.info(u"文章-词-主题分派结果已保存到%s" % self.tassginfile) with codecs.open(self.tassginfile,'w') as f: for x in xrange(self.dpre.docs_count): for y in xrange(self.dpre.docs[x].length): f.write(str(self.dpre.docs[x].words[y])+':'+str(self.Z[x][y])+ '\t') f.write('\n') logger.info(u"模型训练完成。")
# 数据预处理,即:生成d()单词序列,以及词汇表
def preprocessing(): logger.info(u'载入数据......') with codecs.open(trainfile, 'r','utf-8') as f: docs = f.readlines() logger.debug(u"载入完成,准备生成字典对象和统计文本数据...") # 大的文档集 dpre = DataPreProcessing() items_idx = 0 for line in docs: if line != "": tmp = line.strip().split() # 生成一个文档对象:包含单词序列(w1,w2,w3,,,,,wn)可以重复的 doc = Document() for item in tmp: if dpre.word2id.has_key(item):# 已有的话,只是当前文档追加 doc.words.append(dpre.word2id[item]) else: # 没有的话,要更新vocabulary中的单词词典及wordidmap dpre.word2id[item] = items_idx doc.words.append(items_idx) items_idx += 1 doc.length = len(tmp) dpre.docs.append(doc) else: pass dpre.docs_count = len(dpre.docs) # 文档数 dpre.words_count = len(dpre.word2id) # 词汇数 logger.info(u"共有%s个文档" % dpre.docs_count) dpre.cachewordidmap() logger.info(u"词与序号对应关系已保存到%s" % wordidmapfile) return dpre
def run(): # 处理文档集,及计算文档数,以及vocabulary词的总个数,以及每个文档的单词序列 dpre = preprocessing() lda = LDAModel(dpre) lda.est()
if __name__ == '__main__': run() 如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 微信开发者工具测试配置
呐,第一次接触微信的开发,搞vue也搞了好久,页面框架和后台框架和我一点关系都没有,毕竟搬砖。。。。。。。自己也菜的抠脚。既然记不住,那就记笔记吧。下面是第一次为了用开发者工具测试需要配置的内容。首先,登录微信公众平台,看到自己的appID,appsecret,如下图:然后…...
2024/4/28 13:26:42 - Apache Shiro 快速入门教程,shiro 基础教程
第一部分 什么是Apache Shiro1、什么是 apache shiro :Apache Shiro是一个功能强大且易于使用的Java安全框架,提供了认证,授权,加密,和会话管理 如同 Spring security 一样都是是一个权限安全框架,但是与Spring Security相比,在于他使用了和比较简洁易懂的认证和授权方式…...
2024/4/28 8:08:21 - c语言中16进制转换为十进制
方法1:使用进制转换转载:https://zhidao.baidu.com/question/51006929.html#include <stdio.h> #include <string.h>/* 十六进制数转换为十进制数 */ long hexToDec(char *source);/* 返回ch字符在sign数组中的序号 */ int getIndexOfSigns(char ch);int main() {…...
2024/4/28 9:06:48 - Windows PowerShell 2.0之条件表达式的分析
与算数表达式类似,条件表达式使用一系列操作求值用来计算结果。并且得到一个布尔类型的结果,即真和假。如果有时得出的结果是一个具体的数字,解析引擎在解析时也会执行布尔类型转换。即0为假,非0为真,所以在程序中直接以数值为流的控制条件。 在PowerShell中的真和假与其…...
2024/4/28 0:58:25 - 软件测试对比软件开发,你适合哪款?
通常二选一,最残酷。选择一种必然要放弃另一种。但是对于测试和开发,你中有我,我中有你才是最高境界。到底哪款适合你呢? 一个测试员的“宽度“ 掌握软件测试的理论知识:软件测试定义、软件测试分类以及软件测试常用的方法等。(网上一搜全是理论知识,不做多说,这里可以…...
2024/4/28 3:25:54 - 浅析图卷积神经网络
今天想和大家分享的是图卷积神经网络。随着人工智能发展,很多人都听说过机器学习、深度学习、卷积神经网络这些概念。但图卷积神经网络,却不多人提起。那什么是图卷积神经网络呢?简单的来说就是其研究的对象是图数据(Graph),研究的模型是卷积神经网络。今天想和大家分享的…...
2024/4/20 4:29:02 - 31部黑客电影,你看过哪几部?
1、《社交网络The Social Network》(2010)《社交网络》是2010年电影作品,由大卫芬奇执导,改编自2009年畅销书籍《Facebook:性爱与金钱、天才与背叛交织的秘辛》,描述Facebook创办人马克扎克伯格以一个哈佛学生的身分,创办了改变全球网络通信的社交网站脸书,及背后背叛秘辛…...
2024/4/29 1:29:07 - 一名真正的黑客
8月10日晚,在荷兰屯特大学的校园里,来自世界各地的数千名黑客聚集在一起,为一名上个月逝世的德国黑客举行纪念活动。在场的许多人与这名德国黑客素昧平生,但他们表现出的哀伤却是如此真诚。不仅仅是黑客们,连一向保守的德国主要媒体,也接连报道了这名“正义黑客”英年早逝…...
2024/4/28 6:37:02 - IDE(20)——常用的 Java IDE
Java应用程序越做越大、越做越复杂。Java IDE在其中所起的作用也日益显著。有了Java IDE,使软件的生产率倍增。本文为大家介绍几款时下最为流行的Java IDE。一、EclipseEclipse 是一个开放源代码的、基于 Java 的可扩展开发平台。就其本身而言,它只是一个框架和一组服务,用于…...
2024/4/28 5:31:00 - c语言将16进制转换成10进制
前言 要转换的字符串中包含可选的前缀0x或者0X, 代码 /** Created by sutaoyu on 2018/10/2**/ #include<stdio.h> #include<ctype.h>#define YES 1 #define NO 0int htoi(char s[]) {int hexdigit, i, inhex, n;i = 0;if (s[i] == 0){++i;if (s[i] == x || s[i] =…...
2024/4/28 5:08:39 - 大数据风控模型
基本流程: 数据收集、数据建模、构建数据画像、风险定价。 数据收集:网络行为数据、企业服务范围内行为数据、用户内容偏好数据、用户交易数据、授权数据源、第三方数据源、合作方数据源、公开数据源。 数据建模:文本挖掘、自然语言处理、机器学习、预测算法、聚类算法。 数…...
2024/4/28 1:49:07 - Android 如果公司里面要你提供一份购买测试机的清单,你应该如何提供呢?
本人曾经遇到过这样一个问题:以下是列出的表单,供大家参考:测试机手机品牌市场占有率(%)手机系统屏幕分辨率数量备注oppo18.5Android 6.01920*10801vivo15.4Android 6.01080*7201荣耀10.2Android 7.0854*4801红米9.5Android 4.41812*10801华为7.7Android 8.02560*14401小米7…...
2024/4/28 15:13:25 - Mir2源码详解之服务端-登录网关(LoginGate)
传奇这款游戏,一直对我的影响很大。当年为了玩传奇,逃课,被老师叫过N次家长。言归正传,网上有很多源码,当然了,都是delphi的。并且很多源码还不全, 由于一直学习的c、c++。delphi还真不懂。无奈硬着头皮上。好了。废话不多说。开始。登录网关,负责游戏最开始的登录处理…...
2024/4/28 10:05:22 - 编辑器也浮云- cloud9 IDE分享
原文链接近期node.js的消息越来越多,越来越多的前端开发开始关注到这个似乎可以改变我们命运的新技术。其实node.js和之前的mozilla rhino一样都是可以本地执行脚本,不过和rhino的区别在于node.js更加希望的是让前端开发能够通过自己熟悉的语言更块地搭建自己的后台服务。 基…...
2024/4/14 22:04:22 - Uboot:arm-none-linux-gnueabi-addr2line 调试
先试用grep命令查找u-boot.map文件,找出函数地址。 然后使用arm-none-linux-gnueabi-addr2line工具,查找出是在哪个文件的第几行。root@ubuntu:/home/ken/android4.0/u-boot-2013.01# grep -irn "dcache_enable" ./u-boot.map 169: 0x43e02cd4 …...
2024/4/19 14:07:09 - 社会网络分析——Social Network Analysis
From:http://shenhaolaoshi.blog.sohu.com/136119138.html什么是社会网络分析,英文social network analysis。现在这个分析越来越时髦,也越来越显现其在社会科学的研究价值。我在2000年的时候受祝建华老师的邀请到香港城市大学作研究,接触到了社会网络分析,但是当时没有太…...
2024/4/26 0:24:00 - 敏捷开发团队管理系列之二:程序与测试团队I
这是敏捷开发团队管理系列的第二篇。(之一,之二,之三,之四)几个真实案例这几个团队都是我自己亲身经历的团队,从质量的角度来分析敏捷团队的工作方式。第一个是一个较为大型的团队,约有25~30人,研发一个单一产品。这个团队在一年半的时间里边,从5个人成长为25人,其中…...
2024/4/14 22:04:21 - AO Identify地图交互
转自supernever文章 Identify1、框选要素高亮显示 private void axMapControl1_OnMouseDown(object sender, ESRI.ArcGIS.Controls.IMapControlEvents2_OnMouseDownEvent e){IGeometry pGeo = axMapControl1.TrackRectangle();ISpatialFilter pSpatialFilter = new SpatialFilt…...
2024/4/14 22:04:17 - 2017 八大黑客攻击事件,这一年网络安全的世界血雨腥风
编者按:岁末年终,CNN 发表了一个《 2017 年置我们于危险之中的那些黑客事件》的报道,盘点了 2017 年发生的一些重大黑客事件。一年就要过去了,雷锋网也回顾了一下对这些事件的报道,让我们从网络安全的角度来回顾堪称血雨腥风的 2017 年。 1.征信机构 Equifax 数据泄漏,半…...
2024/4/14 22:04:17 - 前端学php之smarty模板引擎
IWs0OO来确韵凡诙涟http://music.hao123.com/songlist/495892328 2U8i4w话缚俚刻素侗http://music.hao123.com/songlist/495712609 6wekG4迫商恃涣锌刀http://music.hao123.com/songlist/495851648?ttoc=oyu g6eim2媳哑渤律侥炒http://music.hao123.com/songlist/495629866?z…...
2024/4/21 0:03:55
最新文章
- 【python中级】 试用nuitka打包PySide6应用程序
【python中级】 试用nuitka打包PySide6应用程序 1.背景2.安装PySide63.试用nuitka打包1.背景 之前博文,关于nuitka安装可以参考: 【python中级】安装nuitka打包工具 https://blog.csdn.net/jn10010537/article/details/137999083?spm=1001.2014.3001.5501如果觉得毫无必要…...
2024/4/29 2:03:22 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 【嵌入式开发 Linux 常用命令系列 4.3 -- git add 不 add untracked file】
请阅读【嵌入式开发学习必备专栏 】 文章目录 git add 不add untracked file git add 不add untracked file 如果你想要Git在执行git add .时不添加未跟踪的文件(untracked files),你可以使用以下命令: git add -u这个命令只会加…...
2024/4/25 4:06:17 - 《c++》多态案例一.电脑组装
一.代码展示 #include <iostream> using namespace std; class CPU { public://抽象计算函数virtual void calculate() 0;};class CVideoCard { public://抽象显示函数virtual void display() 0;}; class Memory { public://抽象存储函数virtual void storage() 0;};…...
2024/4/23 4:46:08 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/28 13:52:11 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/28 3:28:32 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/26 23:05:52 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/28 13:51:37 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/27 17:58:04 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/27 14:22:49 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/28 1:28:33 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/28 15:57:13 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/27 17:59:30 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/25 18:39:16 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/28 1:34:08 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/26 19:03:37 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/28 1:22:35 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/25 18:39:14 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/26 23:04:58 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/27 23:24:42 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/28 5:48:52 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/26 19:46:12 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/27 11:43:08 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/27 8:32:30 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57