使用Python和Numpy构建神经网络模型
一:波士顿房价预测任务
上一节我们初步认识了神经网络的基本概念(如神经元、多层连接、前向计算、计算图)和模型结构三要素(模型假设、评价函数和优化算法)。本节将以“波士顿房价”任务为例,向读者介绍使用Python语言和Numpy库来构建神经网络模型的思考过程和操作方法。
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
图1:波士顿房价影响因素示意图
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
1:线性回归模型
假设房价和各影响因素之间能够用线性关系来描述:
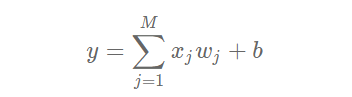
模型的求解即是通过数据拟合出每个w和b。其中,wj和b分别表示该线性模型的权重和偏置。一维情况下,wj 和 b 是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
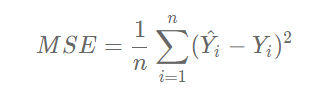
思考:
为什么要以均方误差作为损失函数?即将模型在每个训练样本上的预测误差加和,来衡量整体样本的准确性。这是因为损失函数的设计不仅仅要考虑“合理性”,同样需要考虑“易解性”,这个问题在后面的内容中会详细阐述。
2:线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络),如 图2 所示。
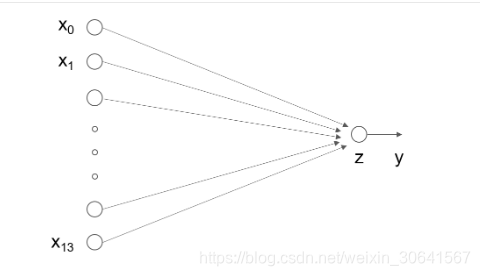
图2:线性回归模型的神经网络结构
二:构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了实现模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。

图3:构建神经网络/深度学习模型的基本步骤
正是由于深度学习的建模和训练的过程存在通用性,在构建不同的模型时,只有模型三要素不同,其它步骤基本一致,深度学习框架才有用武之地。
1:数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
说明:
本教程中的代码都可以在AIStudio上直接运行,Print结果都是基于程序真实运行的结果。
由于是真实案例,代码之前存在依赖关系,因此需要读者逐条、全部运行,否则会导致Print时报错。
2:读入数据
通过如下代码读入数据,了解下波士顿房价的数据集结构,数据存放在本地目录下housing.data文件中。
# 导入包
import numpy as np
import json
# 读入数据
filedata ="/home/aistudio/data/data2943/housing.data"
data=np.fromfile(filedata)
print(data)
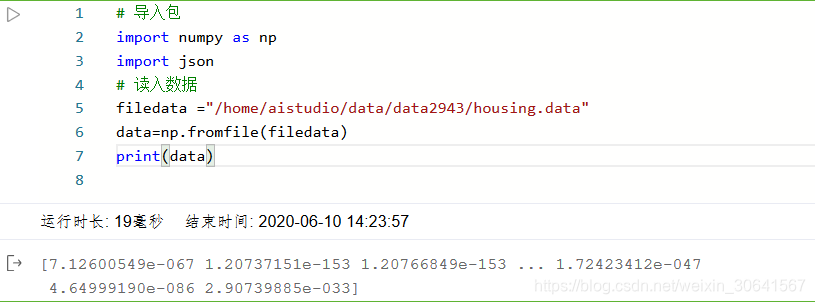
3:数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 查看数据
x = data[0]
print(x.shape)
print(x)
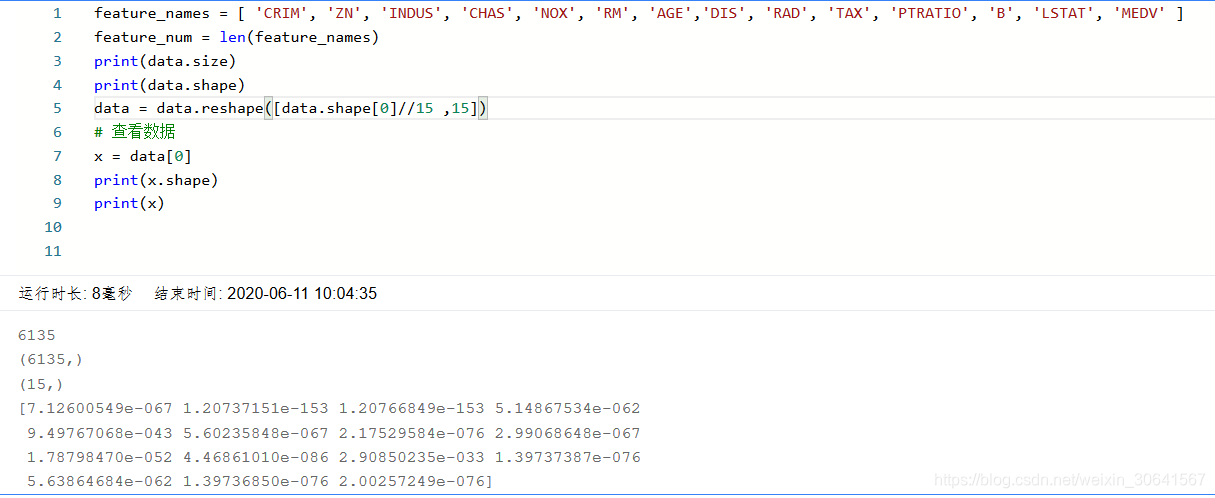
4:数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。为什么要对数据集进行拆分,而不能直接应用于模型训练呢?这与学生时代的授课和考试关系比较类似,如 图4 所示。
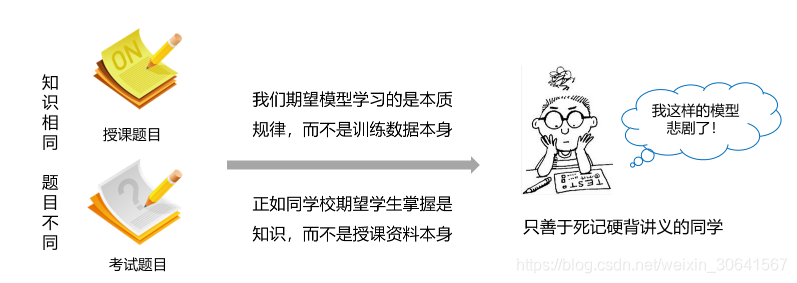
图4:训练集和测试集拆分的意义
上学时总有一些自作聪明的同学,平时不认真学习,考试前临阵抱佛脚,将习题死记硬背下来,但是成绩往往并不好。因为学校期望学生掌握的是知识,而不仅仅是习题本身。另出新的考题,才能鼓励学生努力去掌握习题背后的原理。同样我们期望模型学习的是任务的本质规律,而不是训练数据本身,模型训练未使用的数据,才能更真实的评估模型的效果。
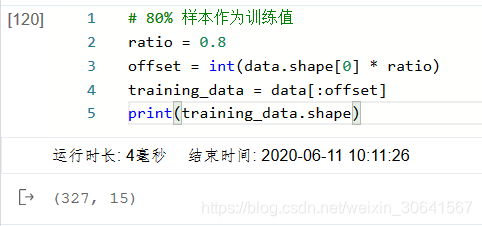
在本案例中,我们将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
5:数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), training_data.sum(axis=0)/training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):#print(maximums[i], minimums[i], avgs[i])data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])

6::封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,代码如下。
def load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算train数据集的最大值,最小值,平均值maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]# 对数据进行归一化处理for i in range(feature_num):#print(maximums[i], minimums[i], avgs[i])data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data
# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 查看数据
print(x[0])
print(y[0])
[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923]
[-0.00390539]
7:模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征x有13个分量,y有1个分量,那么参数权重的形状(shape)是13×1。假设我们以如下任意数字赋值参数做初始化:
![w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]w=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]](https://img-blog.csdnimg.cn/20200611102529782.png)
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1])
取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w)
print(t)
[0.03395597]
完整的线性回归公式,还需要初始化偏移量bbb,同样随意赋初值-0.2。那么,线性回归模型的完整输出是z=t+bz=t+bz=t+b,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2
z = t + b
print(z)
[-0.16604403]
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数www和bbb。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,# 此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn z
基于Network类的定义,模型的计算过程如下所示。
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
[-0.63182506]
8:训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算x1
表示的影响因素所对应的房价应该是zzz, 但实际数据告诉我们房价是yyy。这时我们需要有某种指标来衡量预测值zzz跟真实值yyy之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
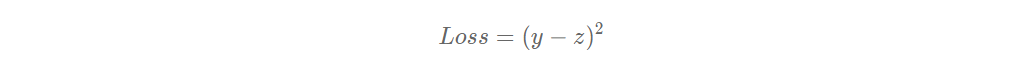
上式中的Loss(简记为: L)通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数,在后续的章节中会更详细的介绍。对一个样本计算损失的代码实现如下:
Loss = (y1 - z)*(y1 - z)
print(Loss)
[0.39428312]
因为计算损失时需要把每个样本的损失都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数N。
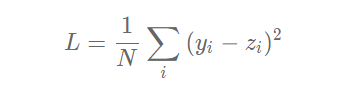
在Network类下面添加损失函数的计算过程如下:
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ycost = error * errorcost = np.mean(cost)return cost
使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量xxx, www,bbb, zzz, errorerrorerror等均是向量。以变量xxx为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print('loss:', loss)
predict: [[-0.63182506][-0.55793096][-1.00062009]]
loss: 0.7229825055441156
9:训练过程
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数w和b的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数Loss尽可能的小,也就是说找到一个参数解w和b使得损失函数取得极小值。
我们先做一个小测试:如 图5 所示,基于微积分知识,求一条曲线在某个点的斜率等于函数该点的导数值。那么大家思考下,当处于曲线的极值点时,该点的斜率是多少?
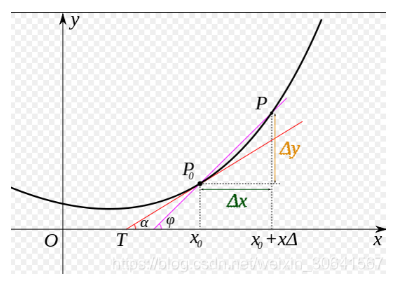
图5:曲线斜率等于导数值
这个问题并不难回答,处于曲线极值点时的斜率为0,即函数在极值点处的导数为0。那么,让损失函数取极小值的www和bbb应该是下述方程组的解:
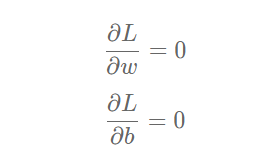
将样本数据(x,y)(x, y)(x,y)带入上面的方程组中即可求解出www和bbb的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
10:梯度下降法
在现实中存在大量的函数正向求解容易,反向求解较难,被称为单向函数。这种函数在密码学中有大量的应用,密码锁的特点是可以迅速判断一个密钥是否是正确的(已知x,求y很容易),但是即使获取到密码锁系统,无法破解出正确的密钥是什么(已知y,求x很难)。
这种情况特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出$Loss&导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以“从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点”实现。这种方法笔者个人称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
训练的关键是找到一组(w,b),使得损失函数LLL取极小值。我们先看一下损失函数L只随两个参数w5
变化时的简单情形,启发下寻解的思路。
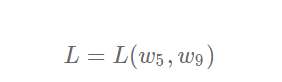

net = Network(13)
losses = []
#只画出参数w5和w9在区间[-160, 160]的曲线部分,以及包含损失函数的极值
w5 = np.arange(-160.0, 160.0, 1.0)
w9 = np.arange(-160.0, 160.0, 1.0)
losses = np.zeros([len(w5), len(w9)])#计算设定区域内每个参数取值所对应的Loss
for i in range(len(w5)):for j in range(len(w9)):net.w[5] = w5[i]net.w[9] = w9[j]z = net.forward(x)loss = net.loss(z, y)losses[i, j] = loss#使用matplotlib将两个变量和对应的Loss作3D图
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)w5, w9 = np.meshgrid(w5, w9)ax.plot_surface(w5, w9, losses, rstride=1, cstride=1, cmap='rainbow')
plt.show()
需要说明的是:为什么这里我们选择w5和w9来画图?这是因为选择这两个参数的时候,可比较直观的从损失函数的曲面图上发现极值点的存在。其他参数组合,从图形上观测损失函数的极值点不够直观。
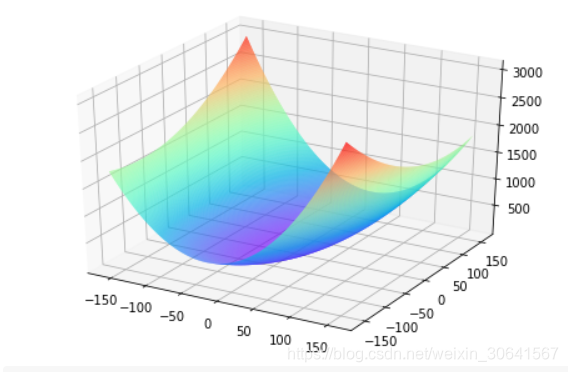
观察上述曲线呈现出“圆滑”的坡度,这正是我们选择以均方误差作为损失函数的原因之一。图6 呈现了只有一个参数维度时,均方误差和绝对值误差(只将每个样本的误差累加,不做平方处理)的损失函数曲线图。
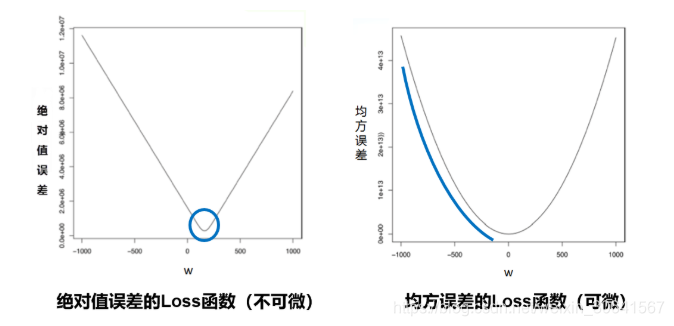
图6:均方误差和绝对值误差损失函数曲线图
由此可见,均方误差表现的“圆滑”的坡度有两个好处:
- 曲线的最低点是可导的。
- 越接近最低点,曲线的坡度逐渐放缓,有助与基于当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而这两个特性绝对值误差是不具备的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
现在我们要找出一组[w5,w9]的值,使得损失函数最小,实现梯度下降法的方案如下:
- 步骤1:随机的选一组初始值,例如:[w5,w9]=[−100.0,−100.0]
- 步骤2:选取下一个点[w5′,w9′],使得L(w5′,w9′)<L(w5,w9)
- 步骤3:重复步骤2,直到损失函数几乎不再下降。
如何选择[w5′,w9′]是至关重要的,第一要保证L是下降的,第二要使得下降的趋势尽可能的快。微积分的基础知识告诉我们,沿着梯度的反方向,是函数值下降最快的方向,如 图7 所示。简单理解,函数在某一个点的梯度方向是曲线斜率最大的方向,但梯度方向是向上的,所以下降最快的是梯度的反方向。
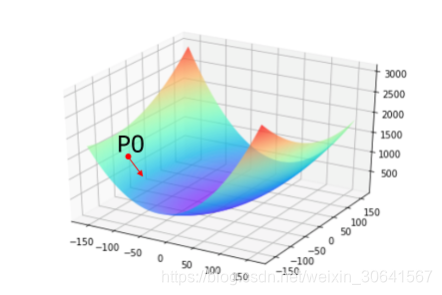
图7:梯度下降方向示意图
11:计算梯度
上面我们讲过了损失函数的计算方法,这里稍微加以改写。为了梯度计算更加简洁,引入因子1/2
,定义损失函数如下:
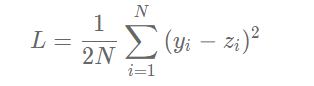
其中zi是网络对第i个样本的预测值:
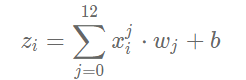
梯度的定义:
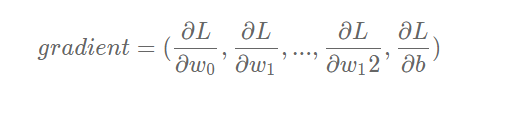
可以计算出LLL对www和bbb的偏导数:
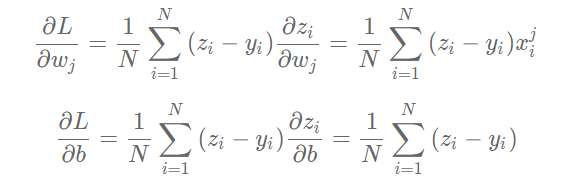
从导数的计算过程可以看出,因子1/2 被消掉了,这是因为二次函数求导的时候会产生因子222,这也是我们将损失函数改写的原因。
下面我们考虑只有一个样本的情况下,计算梯度:
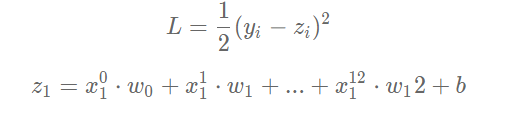
可以计算出L对w和b的偏导数:
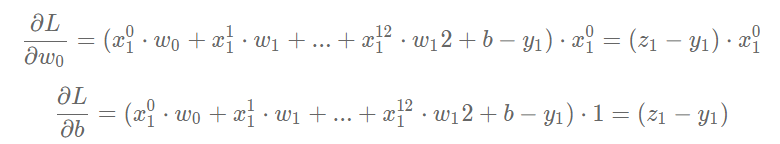
可以通过具体的程序查看每个变量的数据和维度。
x1 = x[0]
y1 = y[0]
z1 = net.forward(x1)
print('x1 {}, shape {}'.format(x1, x1.shape))
print('y1 {}, shape {}'.format(y1, y1.shape))
print('z1 {}, shape {}'.format(z1, z1.shape))
x1 [-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923], shape (13,)
y1 [-0.00390539], shape (1,)
z1 [-12.05947643], shape (1,)
按上面的公式,当只有一个样本时,可以计算某个wj,比如w0的梯度。
gradient_w0 = (z1 - y1) * x1[0]
print('gradient_w0 {}'.format(gradient_w0))
gradient_w0 [0.25875126]
同样我们可以计算w1的梯度。
gradient_w1 = (z1 - y1) * x1[1]
print('gradient_w1 {}'.format(gradient_w1))
gradient_w1 [-0.45417275]
依次计算w2的梯度。
gradient_w2= (z1 - y1) * x1[2]
print('gradient_w1 {}'.format(gradient_w2))
gradient_w1 [3.44214394]
聪明的读者可能已经想到,写一个for循环即可计算从w0到w12的所有权重的梯度,该方法读者可以自行实现。
12:使用Numpy进行梯度计算
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用(z1 - y1) * x1,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
gradient_w = (z1 - y1) * x1
print('gradient_w_by_sample1 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample1 [ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.625819172.12068622], gradient.shape (13,)
输入数据中有多个样本,每个样本都对梯度有贡献。如上代码计算了只有样本1时的梯度值,同样的计算方法也可以计算样本2和样本3对梯度的贡献。
x2 = x[1]
y2 = y[1]
z2 = net.forward(x2)
gradient_w = (z2 - y2) * x2
print('gradient_w_by_sample2 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample2 [ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.792360812.11028056], gradient.shape (13,)
x3 = x[2]
y3 = y[2]
z3 = net.forward(x3)
gradient_w = (z3 - y3) * x3
print('gradient_w_by_sample3 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample3 [ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.933029470.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.466952292.39363651], gradient.shape (13,)
可能有的读者再次想到可以使用for循环把每个样本对梯度的贡献都计算出来,然后再作平均。但是我们不需要这么做,仍然可以使用Numpy的矩阵操作来简化运算,如3个样本的情况。
# 注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)print('x {}, shape {}'.format(x3samples, x3samples.shape))
print('y {}, shape {}'.format(y3samples, y3samples.shape))
print('z {}, shape {}'.format(z3samples, z3samples.shape))
x [[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.046348170.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112-0.17590923][-0.02122729 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.01684060.14904763 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.0519112-0.06111894][-0.02122751 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.1632288-0.03426854 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.03943037-0.20212336]], shape (3, 13)
y [[-0.00390539][-0.05723872][ 0.23387239]], shape (3, 1)
z [[-12.05947643][-34.58467747][-11.60858134]], shape (3, 1)
上面的x3samples, y3samples, z3samples的第一维大小均为3,表示有3个样本。下面计算这3个样本对梯度的贡献。
gradient_w = (z3samples - y3samples) * x3samples
print('gradient_w {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w [[ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.625819172.12068622][ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.792360812.11028056][ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.933029470.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.466952292.39363651]], gradient.shape (3, 13)
此处可见,计算梯度gradient_w的维度是3×13,并且其第1行与上面第1个样本计算的梯度gradient_w_by_sample1一致,第2行与上面第2个样本计算的梯度gradient_w_by_sample1一致,第3行与上面第3个样本计算的梯度gradient_w_by_sample1一致。这里使用矩阵操作,可能更加方便的对3个样本分别计算各自对梯度的贡献。
那么对于有N个样本的情形,我们可以直接使用如下方式计算出所有样本对梯度的贡献,这就是使用Numpy库广播功能带来的便捷。 小结一下这里使用Numpy库的广播功能:
-
一方面可以扩展参数的维度,代替for循环来计算1个样本对从w0 到w12 的所有参数的梯度。
-
另一方面可以扩展样本的维度,代替for循环来计算样本0到样本403对参数的梯度。
z = net.forward(x)gradient_w = (z - y) * xprint('gradient_w shape {}'.format(gradient_w.shape))print(gradient_w)gradient_w shape (404, 13)[[ 0.25875126 -0.45417275 3.44214394 ... 3.49642036 -0.625819172.12068622][ 0.7329239 4.91417754 3.33394253 ... 0.83100061 -1.792360812.11028056][ 0.25138584 1.68549775 1.14349809 ... 0.28502219 -0.466952292.39363651]...[ 14.70025543 -15.10890735 36.23258734 ... 24.54882966 5.5107112226.26098922][ 9.29832217 -15.33146159 36.76629344 ... 24.91043398 -1.2756492326.61808955][ 19.55115919 -10.8177237 25.94192351 ... 17.5765494 3.9455766117.64891012]]
上面gradient_w的每一行代表了一个样本对梯度的贡献。根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
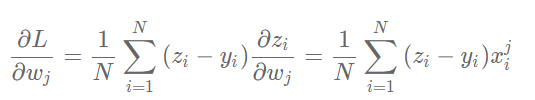
我们也可以使用Numpy的均值函数来完成此过程:
# axis = 0 表示把每一行做相加然后再除以总的行数
gradient_w = np.mean(gradient_w, axis=0)
print('gradient_w ', gradient_w.shape)
print('w ', net.w.shape)
print(gradient_w)
print(net.w)
gradient_w (13,)
w (13, 1)
[ 1.59697064 -0.92928123 4.72726926 1.65712204 4.96176389 1.180684544.55846519 -3.37770889 9.57465893 10.29870662 1.3900257 -0.301522151.09276043]
[[ 1.76405235e+00][ 4.00157208e-01][ 9.78737984e-01][ 2.24089320e+00][ 1.86755799e+00][ 1.59000000e+02][ 9.50088418e-01][-1.51357208e-01][-1.03218852e-01][ 1.59000000e+02][ 1.44043571e-01][ 1.45427351e+00][ 7.61037725e-01]]
我们使用numpy的矩阵操作方便的完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而w的维度是(13, 1)。导致该问题的原因是使用np.mean函数的时候消除了第0维。为了加减乘除等计算方便,gradient_w和w必须保持一致的形状。因此我们将gradient_w的维度也设置为(13, 1),代码如下:
gradient_w = gradient_w[:, np.newaxis]
print('gradient_w shape', gradient_w.shape)
gradient_w shape (13, 1)
综合上面的讨论,计算梯度的代码如下所示。
z = net.forward(x)
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_w
array([[ 1.59697064], [-0.92928123], [ 4.72726926], [ 1.65712204], [ 4.96176389], [ 1.18068454], [ 4.55846519], [-3.37770889], [ 9.57465893], [10.29870662], [ 1.3900257 ], [-0.30152215], [ 1.09276043]])
上述代码非常简洁的完成了www的梯度计算。同样,计算bbb的梯度的代码也是类似的原理。
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
# 此处b是一个数值,所以可以直接用np.mean得到一个标量
gradient_b
-1.0918438870293816e-13
将上面计算w和b的梯度的过程,写成Network类的gradient函数,代码如下所示。
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b)return gradient_w, gradient_b
# 调用上面定义的gradient函数,计算梯度
# 初始化网络,
net = Network(13)
# 设置[w5, w9] = [-100., +100.]
net.w[5] = -100.0
net.w[9] = -100.0z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-100.0, -100.0], loss 686.3005008179159
gradient [-0.850073323995813, -6.138412364807849]
13:确定损失函数更小的点
下面我们开始研究更新梯度的方法。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1
# 定义移动步长 eta
eta = 0.1
# 更新参数w5和w9
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
# 重新计算z和loss
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-99.91499266760042, -99.38615876351922], loss 678.6472185028845
gradient [-0.8556356178645292, -6.0932268634065805]
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句: net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适。
如 图8 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
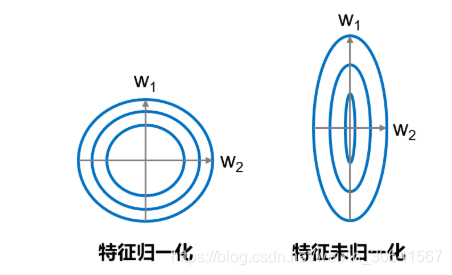
图8:未归一化的特征,会导致不同特征维度的理想步长不同
14:代码封装Train函数
将上面的循环的计算过程封装在train和update函数中,代码如下所示。
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights,1)self.w[5] = -100.self.w[9] = -100.self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, graident_w5, gradient_w9, eta=0.01):net.w[5] = net.w[5] - eta * gradient_w5net.w[9] = net.w[9] - eta * gradient_w9def train(self, x, y, iterations=100, eta=0.01):points = []losses = []for i in range(iterations):points.append([net.w[5][0], net.w[9][0]])z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)gradient_w5 = gradient_w[5][0]gradient_w9 = gradient_w[9][0]self.update(gradient_w5, gradient_w9, eta)losses.append(L)if i % 50 == 0:print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))return points, losses# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
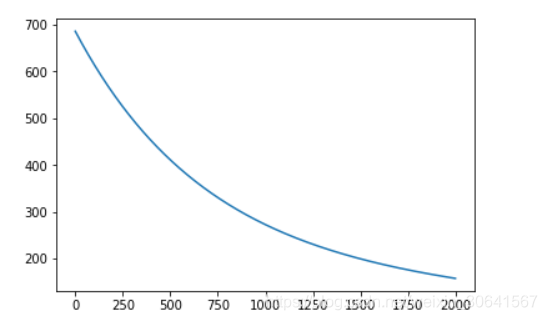
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 0, point [-99.99144364382136, -99.93861587635192], loss 686.3005008179159
iter 50, point [-99.56362583488914, -96.92631128470325], loss 649.221346830939
iter 100, point [-99.13580802595692, -94.02279509580971], loss 614.6970095624063
iter 150, point [-98.7079902170247, -91.22404911807594], loss 582.543755023494
iter 200, point [-98.28017240809248, -88.52620357520894], loss 552.5911329872217
iter 250, point [-97.85235459916026, -85.9255316243737], loss 524.6810152322887
iter 300, point [-97.42453679022805, -83.41844407682491], loss 498.6667034691001
iter 350, point [-96.99671898129583, -81.00148431353688], loss 474.4121018974464
iter 400, point [-96.56890117236361, -78.67132338862874], loss 451.7909497114133
iter 450, point [-96.14108336343139, -76.42475531364933], loss 430.68610920670284
iter 500, point [-95.71326555449917, -74.25869251604028], loss 410.988905460488
iter 550, point [-95.28544774556696, -72.17016146534513], loss 392.5985138460824
iter 600, point [-94.85762993663474, -70.15629846096763], loss 375.4213919156372
iter 650, point [-94.42981212770252, -68.21434557551346], loss 359.3707524354014
iter 700, point [-94.0019943187703, -66.34164674796719], loss 344.36607459115214
iter 750, point [-93.57417650983808, -64.53564402117185], loss 330.33265059761464
iter 800, point [-93.14635870090586, -62.793873918279786], loss 317.2011651461846
iter 850, point [-92.71854089197365, -61.11396395304264], loss 304.907305311265
iter 900, point [-92.29072308304143, -59.49362926899678], loss 293.3913987080144
iter 950, point [-91.86290527410921, -57.930669402782904], loss 282.5980778542974
iter 1000, point [-91.43508746517699, -56.4229651670156], loss 272.47596883802515
iter 1050, point [-91.00726965624477, -54.968475648286564], loss 262.9774025287022
iter 1100, point [-90.57945184731255, -53.56523531604897], loss 254.05814669965383
iter 1150, point [-90.15163403838034, -52.21135123828792], loss 245.67715754581488
iter 1200, point [-89.72381622944812, -50.90500040003218], loss 237.796349191773
iter 1250, point [-89.2959984205159, -49.6444271209092], loss 230.3803798866218
iter 1300, point [-88.86818061158368, -48.42794056808474], loss 223.3964536766492
iter 1350, point [-88.44036280265146, -47.2539123610643], loss 216.81413643451378
iter 1400, point [-88.01254499371925, -46.12077426496303], loss 210.60518520483126
iter 1450, point [-87.58472718478703, -45.027015968976976], loss 204.74338990147896
iter 1500, point [-87.15690937585481, -43.9711829469081], loss 199.20442646183588
iter 1550, point [-86.72909156692259, -42.95187439671279], loss 193.96572062803054
iter 1600, point [-86.30127375799037, -41.96774125615467], loss 189.00632158541163
iter 1650, point [-85.87345594905815, -41.017484291751295], loss 184.3067847442463
iter 1700, point [-85.44563814012594, -40.0998522583068], loss 179.84906300239203
iter 1750, point [-85.01782033119372, -39.21364012642417], loss 175.61640587468244
iter 1800, point [-84.5900025222615, -38.35768737548557], loss 171.59326591927967
iter 1850, point [-84.16218471332928, -37.530876349682856], loss 167.76521193253296
iter 1900, point [-83.73436690439706, -36.73213067476985], loss 164.11884842217898
iter 1950, point [-83.30654909546485, -35.96041373329276], loss 160.64174090423475
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, x, y, iterations=100, eta=0.01):losses = []for i in range(iterations):z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(L)if (i+1) % 10 == 0:print('iter {}, loss {}'.format(i, L))return losses# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 9, loss 1.8984947314576224
iter 19, loss 1.8031783384598725
iter 29, loss 1.7135517565541092
iter 39, loss 1.6292649416831264
iter 49, loss 1.5499895293373231
iter 59, loss 1.4754174896452612
iter 69, loss 1.4052598659324693
iter 79, loss 1.3392455915676864
iter 89, loss 1.2771203802372915
iter 99, loss 1.218645685090292
iter 109, loss 1.1635977224791534
iter 119, loss 1.111766556287068
iter 129, loss 1.0629552390811503
iter 139, loss 1.0169790065644477
iter 149, loss 0.9736645220185994
iter 159, loss 0.9328491676343147
iter 169, loss 0.8943803798194307
iter 179, loss 0.8581150257549611
iter 189, loss 0.8239188186389669
iter 199, loss 0.7916657692169988
iter 209, loss 0.761237671346902
iter 219, loss 0.7325236194855752
iter 229, loss 0.7054195561163928
iter 239, loss 0.6798278472589763
iter 249, loss 0.6556568843183528
iter 259, loss 0.6328207106387195
iter 269, loss 0.6112386712285092
iter 279, loss 0.59083508421862
iter 289, loss 0.5715389327049418
iter 299, loss 0.5532835757100347
iter 309, loss 0.5360064770773406
iter 319, loss 0.5196489511849665
iter 329, loss 0.5041559244351539
iter 339, loss 0.48947571154034963
iter 349, loss 0.47555980568755696
iter 359, loss 0.46236268171965056
iter 369, loss 0.44984161152579916
iter 379, loss 0.43795649088328303
iter 389, loss 0.4266696770400226
iter 399, loss 0.41594583637124666
iter 409, loss 0.4057518014851036
iter 419, loss 0.3960564371908221
iter 429, loss 0.38683051477942226
iter 439, loss 0.3780465941011246
iter 449, loss 0.3696789129556087
iter 459, loss 0.3617032833413179
iter 469, loss 0.3540969941381648
iter 479, loss 0.3468387198244131
iter 489, loss 0.3399084348532937
iter 499, loss 0.33328733333814486
iter 509, loss 0.3269577537166779
iter 519, loss 0.32090310808539985
iter 529, loss 0.3151078159144129
iter 539, loss 0.30955724187078903
iter 549, loss 0.3042376374955925
iter 559, loss 0.2991360864954391
iter 569, loss 0.2942404534243286
iter 579, loss 0.2895393355454012
iter 589, loss 0.28502201767532415
iter 599, loss 0.28067842982626157
iter 609, loss 0.27649910747186535
iter 619, loss 0.2724751542744919
iter 629, loss 0.2685982071209627
iter 639, loss 0.26486040332365085
iter 649, loss 0.2612543498525749
iter 659, loss 0.2577730944725093
iter 669, loss 0.2544100986669443
iter 679, loss 0.2511592122380609
iter 689, loss 0.2480146494787638
iter 699, loss 0.24497096681926708
iter 709, loss 0.2420230418567802
iter 719, loss 0.23916605368251415
iter 729, loss 0.23639546442555454
iter 739, loss 0.23370700193813704
iter 749, loss 0.2310966435515475
iter 759, loss 0.2285606008362593
iter 769, loss 0.22609530530403904
iter 779, loss 0.22369739499361888
iter 789, loss 0.2213637018851542
iter 799, loss 0.21909124009208833
iter 809, loss 0.21687719478222933
iter 819, loss 0.21471891178284025
iter 829, loss 0.21261388782734392
iter 839, loss 0.2105597614038757
iter 849, loss 0.20855430416838638
iter 859, loss 0.20659541288730932
iter 869, loss 0.20468110187697833
iter 879, loss 0.2028094959090178
iter 889, loss 0.20097882355283644
iter 899, loss 0.19918741092814596
iter 909, loss 0.19743367584210875
iter 919, loss 0.1957161222872899
iter 929, loss 0.19403333527807176
iter 939, loss 0.19238397600456975
iter 949, loss 0.19076677728439412
iter 959, loss 0.1891805392938162
iter 969, loss 0.18762412556104593
iter 979, loss 0.18609645920539716
iter 989, loss 0.18459651940712488
iter 999, loss 0.18312333809366155
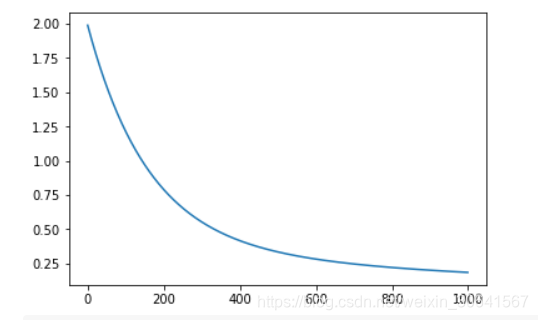
15:随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗的说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- min-batch:每次迭代时抽取出来的一批数据被称为一个min-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮的训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
16:数据处理代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
# 获取数据
train_data, test_data = load_data()
train_data.shape
(404, 14)
train_data中一共包含404条数据,如果batch_size=10,即取前0-9号样本作为第一个mini-batch,命名train_data1。
train_data1 = train_data[0:10]
train_data1.shape
(10, 14)
使用train_data1的数据(0-9号样本)计算梯度并更新网络参数。
net = Network(13)
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss
[0.9001866101467375]
再取出10-19号样本作为第二个mini-batch,计算梯度并更新网络参数。
train_data2 = train_data[10:19]
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss
[0.8903272433979657]
按此方法不断的取出新的mini-batch,并逐渐更新网络参数。
接下来,将train_data分成大小为batch_size的多个mini_batch,如下代码所示:将train_data分成 104/40+1=41 个 mini_batch了,其中前40个mini_batch,每个均含有10个样本,最后一个mini_batch只含有4个样本。
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
print('total number of mini_batches is ', len(mini_batches))
print('first mini_batch shape ', mini_batches[0].shape)
print('last mini_batch shape ', mini_batches[-1].shape)
total number of mini_batches is 41
first mini_batch shape (10, 14)
last mini_batch shape (4, 14)
另外,我们这里是按顺序取出mini_batch的,而SGD里面是随机的抽取一部分样本代表总体。为了实现随机抽样的效果,我们先将train_data里面的样本顺序随机打乱,然后再抽取mini_batch。随机打乱样本顺序,需要用到np.random.shuffle函数,下面先介绍它的用法。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
print('before shuffle', a)
np.random.shuffle(a)
print('after shuffle', a)
before shuffle [ 1 2 3 4 5 6 7 8 9 10 11 12]
after shuffle [ 7 2 11 3 8 6 12 1 4 5 10 9]
多次运行上面的代码,可以发现每次执行shuffle函数后的数字顺序均不同。 上面举的是一个1维数组乱序的案例,我们在观察下2维数组乱序后的效果。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
a = a.reshape([6, 2])
print('before shuffle\n', a)
np.random.shuffle(a)
print('after shuffle\n', a)
before shuffle[[ 1 2][ 3 4][ 5 6][ 7 8][ 9 10][11 12]]
after shuffle[[ 1 2][ 3 4][ 5 6][ 9 10][11 12][ 7 8]]
观察运行结果可发现,数组的元素在第0维被随机打乱,但第1维的顺序保持不变。例如数字2仍然紧挨在数字1的后面,数字8仍然紧挨在数字7的后面,而第二维的[3, 4]并不排在[1, 2]的后面。将这部分实现SGD算法的代码集成到Network类中的train函数中,最终的完整代码如下。
# 获取数据
train_data, test_data = load_data()# 打乱样本顺序
np.random.shuffle(train_data)# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]# 创建网络
net = Network(13)# 依次使用每个mini_batch的数据
for mini_batch in mini_batches:x = mini_batch[:, :-1]y = mini_batch[:, -1:]loss = net.train(x, y, iterations=1)
17:训练过程代码修改
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
1:第一层循环,代表样本集合要被训练遍历几次,称为“epoch”,代码如下:
for epoch_id in range(num_epoches):
2:第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”,
代码如下:for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数,这与大家之前所学是一致的,代码如下:
x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x) #前向计算loss = self.loss(a, y) #计算损失gradient_w, gradient_b = self.gradient(x, y) #计算梯度self.update(gradient_w, gradient_b, eta) #更新参数
将两部分改写的代码集成到Network类中的train函数中,最终的实现如下。
import numpy as npclass Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子#np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)N = x.shape[0]gradient_w = 1. / N * np.sum((z-y) * x, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = 1. / N * np.sum(z-y)return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, training_data, num_epoches, batch_size=10, eta=0.01):n = len(training_data)losses = []for epoch_id in range(num_epoches):# 在每轮迭代开始之前,将训练数据的顺序随机的打乱,# 然后再按每次取batch_size条数据的方式取出np.random.shuffle(training_data)# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]for iter_id, mini_batch in enumerate(mini_batches):#print(self.w.shape)#print(self.b)x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x)loss = self.loss(a, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(loss)print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss))return losses# 获取数据
train_data, test_data = load_data()# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
Epoch 0 / iter 0, loss = 0.6273
Epoch 0 / iter 1, loss = 0.4835
Epoch 0 / iter 2, loss = 0.5830
Epoch 0 / iter 3, loss = 0.5466
Epoch 0 / iter 4, loss = 0.2147
Epoch 1 / iter 0, loss = 0.6645
Epoch 1 / iter 1, loss = 0.4875
Epoch 1 / iter 2, loss = 0.4707
Epoch 1 / iter 3, loss = 0.4153
Epoch 1 / iter 4, loss = 0.1402
Epoch 2 / iter 0, loss = 0.5897
Epoch 2 / iter 1, loss = 0.4373
Epoch 2 / iter 2, loss = 0.4631
Epoch 2 / iter 3, loss = 0.3960
Epoch 2 / iter 4, loss = 0.2340
Epoch 3 / iter 0, loss = 0.4139
Epoch 3 / iter 1, loss = 0.5635
Epoch 3 / iter 2, loss = 0.3807
Epoch 3 / iter 3, loss = 0.3975
Epoch 3 / iter 4, loss = 0.1207
Epoch 4 / iter 0, loss = 0.3786
Epoch 4 / iter 1, loss = 0.4474
Epoch 4 / iter 2, loss = 0.4019
Epoch 4 / iter 3, loss = 0.4352
Epoch 4 / iter 4, loss = 0.0435
Epoch 5 / iter 0, loss = 0.4387
Epoch 5 / iter 1, loss = 0.3886
Epoch 5 / iter 2, loss = 0.3182
Epoch 5 / iter 3, loss = 0.4189
Epoch 5 / iter 4, loss = 0.1741
Epoch 6 / iter 0, loss = 0.3191
Epoch 6 / iter 1, loss = 0.3601
Epoch 6 / iter 2, loss = 0.4199
Epoch 6 / iter 3, loss = 0.3289
Epoch 6 / iter 4, loss = 1.2691
Epoch 7 / iter 0, loss = 0.3202
Epoch 7 / iter 1, loss = 0.2855
Epoch 7 / iter 2, loss = 0.4129
Epoch 7 / iter 3, loss = 0.3331
Epoch 7 / iter 4, loss = 0.2218
Epoch 8 / iter 0, loss = 0.2368
Epoch 8 / iter 1, loss = 0.3457
Epoch 8 / iter 2, loss = 0.3339
Epoch 8 / iter 3, loss = 0.3812
Epoch 8 / iter 4, loss = 0.0534
Epoch 9 / iter 0, loss = 0.3567
Epoch 9 / iter 1, loss = 0.4033
Epoch 9 / iter 2, loss = 0.1926
Epoch 9 / iter 3, loss = 0.2803
Epoch 9 / iter 4, loss = 0.1557
Epoch 10 / iter 0, loss = 0.3435
Epoch 10 / iter 1, loss = 0.2790
Epoch 10 / iter 2, loss = 0.3456
Epoch 10 / iter 3, loss = 0.2076
Epoch 10 / iter 4, loss = 0.0935
Epoch 11 / iter 0, loss = 0.3024
Epoch 11 / iter 1, loss = 0.2517
Epoch 11 / iter 2, loss = 0.2797
Epoch 11 / iter 3, loss = 0.2989
Epoch 11 / iter 4, loss = 0.0301
Epoch 12 / iter 0, loss = 0.2507
Epoch 12 / iter 1, loss = 0.2563
Epoch 12 / iter 2, loss = 0.2971
Epoch 12 / iter 3, loss = 0.2833
Epoch 12 / iter 4, loss = 0.0597
Epoch 13 / iter 0, loss = 0.2827
Epoch 13 / iter 1, loss = 0.2094
Epoch 13 / iter 2, loss = 0.2417
Epoch 13 / iter 3, loss = 0.2985
Epoch 13 / iter 4, loss = 0.4036
Epoch 14 / iter 0, loss = 0.3085
Epoch 14 / iter 1, loss = 0.2015
Epoch 14 / iter 2, loss = 0.1830
Epoch 14 / iter 3, loss = 0.2978
Epoch 14 / iter 4, loss = 0.0630
Epoch 15 / iter 0, loss = 0.2342
Epoch 15 / iter 1, loss = 0.2780
Epoch 15 / iter 2, loss = 0.2571
Epoch 15 / iter 3, loss = 0.1838
Epoch 15 / iter 4, loss = 0.0627
Epoch 16 / iter 0, loss = 0.1896
Epoch 16 / iter 1, loss = 0.1966
Epoch 16 / iter 2, loss = 0.2018
Epoch 16 / iter 3, loss = 0.3257
Epoch 16 / iter 4, loss = 0.1268
Epoch 17 / iter 0, loss = 0.1990
Epoch 17 / iter 1, loss = 0.2031
Epoch 17 / iter 2, loss = 0.2662
Epoch 17 / iter 3, loss = 0.2128
Epoch 17 / iter 4, loss = 0.0133
Epoch 18 / iter 0, loss = 0.1780
Epoch 18 / iter 1, loss = 0.1575
Epoch 18 / iter 2, loss = 0.2547
Epoch 18 / iter 3, loss = 0.2544
Epoch 18 / iter 4, loss = 0.2007
Epoch 19 / iter 0, loss = 0.1657
Epoch 19 / iter 1, loss = 0.2000
Epoch 19 / iter 2, loss = 0.2045
Epoch 19 / iter 3, loss = 0.2524
Epoch 19 / iter 4, loss = 0.0632
Epoch 20 / iter 0, loss = 0.1629
Epoch 20 / iter 1, loss = 0.1895
Epoch 20 / iter 2, loss = 0.2523
Epoch 20 / iter 3, loss = 0.1896
Epoch 20 / iter 4, loss = 0.0918
Epoch 21 / iter 0, loss = 0.1583
Epoch 21 / iter 1, loss = 0.2322
Epoch 21 / iter 2, loss = 0.1567
Epoch 21 / iter 3, loss = 0.2089
Epoch 21 / iter 4, loss = 0.2035
Epoch 22 / iter 0, loss = 0.2273
Epoch 22 / iter 1, loss = 0.1427
Epoch 22 / iter 2, loss = 0.1712
Epoch 22 / iter 3, loss = 0.1826
Epoch 22 / iter 4, loss = 0.2878
Epoch 23 / iter 0, loss = 0.1685
Epoch 23 / iter 1, loss = 0.1622
Epoch 23 / iter 2, loss = 0.1499
Epoch 23 / iter 3, loss = 0.2329
Epoch 23 / iter 4, loss = 0.1486
Epoch 24 / iter 0, loss = 0.1617
Epoch 24 / iter 1, loss = 0.2083
Epoch 24 / iter 2, loss = 0.1442
Epoch 24 / iter 3, loss = 0.1740
Epoch 24 / iter 4, loss = 0.1641
Epoch 25 / iter 0, loss = 0.1159
Epoch 25 / iter 1, loss = 0.2064
Epoch 25 / iter 2, loss = 0.1690
Epoch 25 / iter 3, loss = 0.1778
Epoch 25 / iter 4, loss = 0.0159
Epoch 26 / iter 0, loss = 0.1730
Epoch 26 / iter 1, loss = 0.1861
Epoch 26 / iter 2, loss = 0.1387
Epoch 26 / iter 3, loss = 0.1486
Epoch 26 / iter 4, loss = 0.1090
Epoch 27 / iter 0, loss = 0.1393
Epoch 27 / iter 1, loss = 0.1775
Epoch 27 / iter 2, loss = 0.1564
Epoch 27 / iter 3, loss = 0.1245
Epoch 27 / iter 4, loss = 0.7611
Epoch 28 / iter 0, loss = 0.1470
Epoch 28 / iter 1, loss = 0.1211
Epoch 28 / iter 2, loss = 0.1285
Epoch 28 / iter 3, loss = 0.1854
Epoch 28 / iter 4, loss = 0.5240
Epoch 29 / iter 0, loss = 0.1740
Epoch 29 / iter 1, loss = 0.0898
Epoch 29 / iter 2, loss = 0.1392
Epoch 29 / iter 3, loss = 0.1842
Epoch 29 / iter 4, loss = 0.0251
Epoch 30 / iter 0, loss = 0.0978
Epoch 30 / iter 1, loss = 0.1529
Epoch 30 / iter 2, loss = 0.1640
Epoch 30 / iter 3, loss = 0.1503
Epoch 30 / iter 4, loss = 0.0975
Epoch 31 / iter 0, loss = 0.1399
Epoch 31 / iter 1, loss = 0.1595
Epoch 31 / iter 2, loss = 0.1209
Epoch 31 / iter 3, loss = 0.1203
Epoch 31 / iter 4, loss = 0.2008
Epoch 32 / iter 0, loss = 0.1501
Epoch 32 / iter 1, loss = 0.1310
Epoch 32 / iter 2, loss = 0.1065
Epoch 32 / iter 3, loss = 0.1489
Epoch 32 / iter 4, loss = 0.0818
Epoch 33 / iter 0, loss = 0.1401
Epoch 33 / iter 1, loss = 0.1367
Epoch 33 / iter 2, loss = 0.0970
Epoch 33 / iter 3, loss = 0.1481
Epoch 33 / iter 4, loss = 0.0711
Epoch 34 / iter 0, loss = 0.1157
Epoch 34 / iter 1, loss = 0.1050
Epoch 34 / iter 2, loss = 0.1378
Epoch 34 / iter 3, loss = 0.1505
Epoch 34 / iter 4, loss = 0.0429
Epoch 35 / iter 0, loss = 0.1096
Epoch 35 / iter 1, loss = 0.1279
Epoch 35 / iter 2, loss = 0.1715
Epoch 35 / iter 3, loss = 0.0888
Epoch 35 / iter 4, loss = 0.0473
Epoch 36 / iter 0, loss = 0.1350
Epoch 36 / iter 1, loss = 0.0781
Epoch 36 / iter 2, loss = 0.1458
Epoch 36 / iter 3, loss = 0.1288
Epoch 36 / iter 4, loss = 0.0421
Epoch 37 / iter 0, loss = 0.1083
Epoch 37 / iter 1, loss = 0.0972
Epoch 37 / iter 2, loss = 0.1513
Epoch 37 / iter 3, loss = 0.1236
Epoch 37 / iter 4, loss = 0.0366
Epoch 38 / iter 0, loss = 0.1204
Epoch 38 / iter 1, loss = 0.1341
Epoch 38 / iter 2, loss = 0.1109
Epoch 38 / iter 3, loss = 0.0905
Epoch 38 / iter 4, loss = 0.3906
Epoch 39 / iter 0, loss = 0.0923
Epoch 39 / iter 1, loss = 0.1094
Epoch 39 / iter 2, loss = 0.1295
Epoch 39 / iter 3, loss = 0.1239
Epoch 39 / iter 4, loss = 0.0684
Epoch 40 / iter 0, loss = 0.1188
Epoch 40 / iter 1, loss = 0.0984
Epoch 40 / iter 2, loss = 0.1067
Epoch 40 / iter 3, loss = 0.1057
Epoch 40 / iter 4, loss = 0.4602
Epoch 41 / iter 0, loss = 0.1478
Epoch 41 / iter 1, loss = 0.0980
Epoch 41 / iter 2, loss = 0.0921
Epoch 41 / iter 3, loss = 0.1020
Epoch 41 / iter 4, loss = 0.0430
Epoch 42 / iter 0, loss = 0.0991
Epoch 42 / iter 1, loss = 0.0994
Epoch 42 / iter 2, loss = 0.1270
Epoch 42 / iter 3, loss = 0.0988
Epoch 42 / iter 4, loss = 0.1176
Epoch 43 / iter 0, loss = 0.1286
Epoch 43 / iter 1, loss = 0.1013
Epoch 43 / iter 2, loss = 0.1066
Epoch 43 / iter 3, loss = 0.0779
Epoch 43 / iter 4, loss = 0.1481
Epoch 44 / iter 0, loss = 0.0840
Epoch 44 / iter 1, loss = 0.0858
Epoch 44 / iter 2, loss = 0.1388
Epoch 44 / iter 3, loss = 0.1000
Epoch 44 / iter 4, loss = 0.0313
Epoch 45 / iter 0, loss = 0.0896
Epoch 45 / iter 1, loss = 0.1173
Epoch 45 / iter 2, loss = 0.0916
Epoch 45 / iter 3, loss = 0.1043
Epoch 45 / iter 4, loss = 0.0074
Epoch 46 / iter 0, loss = 0.1008
Epoch 46 / iter 1, loss = 0.0915
Epoch 46 / iter 2, loss = 0.0877
Epoch 46 / iter 3, loss = 0.1139
Epoch 46 / iter 4, loss = 0.0292
Epoch 47 / iter 0, loss = 0.0679
Epoch 47 / iter 1, loss = 0.0987
Epoch 47 / iter 2, loss = 0.0929
Epoch 47 / iter 3, loss = 0.1098
Epoch 47 / iter 4, loss = 0.4838
Epoch 48 / iter 0, loss = 0.0693
Epoch 48 / iter 1, loss = 0.1095
Epoch 48 / iter 2, loss = 0.1128
Epoch 48 / iter 3, loss = 0.0890
Epoch 48 / iter 4, loss = 0.1008
Epoch 49 / iter 0, loss = 0.0724
Epoch 49 / iter 1, loss = 0.0804
Epoch 49 / iter 2, loss = 0.0919
Epoch 49 / iter 3, loss = 0.1233
Epoch 49 / iter 4, loss = 0.1849
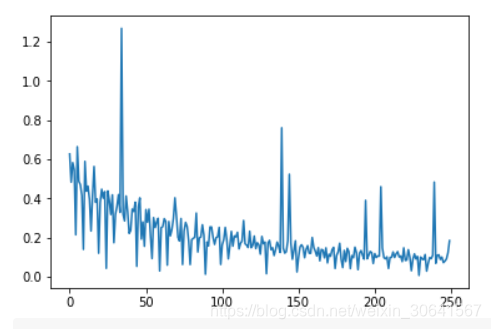
说明:
由于房价预测的数据量过少,所以难以感受到随机梯度下降带来的性能提升。
总结
本节,我们详细讲解了如何使用Numpy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
- 构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
- 随机选择初始点,建立梯度的计算方法和参数更新方式。
- 从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
基本知识
- 求导的链式法则
链式法则是微积分中的求导法则,用于求一个复合函数的导数,是在微积分的求导运算中一种常用的方法。复合函数的导数将是构成复合这有限个函数在相应点的导数的乘积,就像锁链一样一环套一环,故称链式法则。如 图9 所示,如果求最终输出对内层输入(第一层)的梯度,等于外层梯度(第二层)乘以本层函数的梯度。

图9:求导的链式法则
- 计算图的概念
(1)为何是反向计算梯度?即梯度是由网络后端向前端计算。当前层的梯度要依据处于网络中后一层的梯度来计算,所以只有先算后一层的梯度才能计算本层的梯度。
(2)案例:购买苹果产生消费的计算图。假设一家商店9折促销苹果,每个的单价100元。计算一个顾客总消费的结构如 图10 所示。
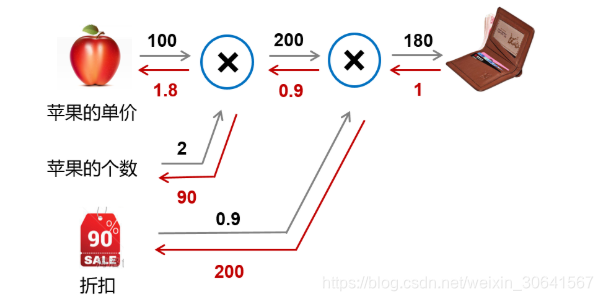
图10:购买苹果所产生的消费计算图
- 前向计算过程:以黑色箭头表示,顾客购买了2个苹果,再加上九折的折扣,一共消费10020.9=180元。
- 后向传播过程:以红色箭头表示,根据链式法则,本层的梯度计算 * 后一层传递过来的梯度,所以需从后向前计算。
最后一层的输出对自身的求导为1。导数第二层根据 图11 所示的乘法求导的公式,分别为0.91和2001。同样的,第三层为100 * 0.9=90,2 * 0.9=1.8。
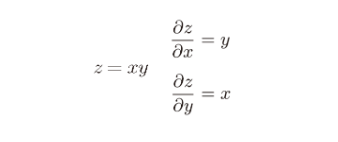
图11:乘法求导的公式
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 成功的Git分支模型
目录为什么要git?分散但集中主要分支支持分支功能分支发布分支修补程序分支总结在这篇文章中,我介绍了大约一年前我为一些项目(工作和私人)介绍的开发模型,结果证明非常成功。我一直想写一段时间,但是我从来没有真正找到时间这么做,直到现在。我不会谈论任何项目的细节,…...
2024/4/24 12:39:41 - 算法竞赛资料整理分享
算法竞赛资料分享🤹🏼♀️ 因为准备实习👔,今天早上整理了一下算法的课件、书籍、论文、习题不管是准备校招,进BAT🚀; 还是自学算法竞赛💼; 或者单纯的课外拓展🤷;对程序员👔而言,算法学习都是有必要的,只是可能要求深浅不同,所以,开始学起来吧🌈~…...
2024/4/24 12:39:41 - 微服务架构,多“微”才合适?【云图智联】
随着数据量、并发量、业务复杂度的增长,互联网架构会出现以下问题:代码到处拷贝底层复杂性扩散基础库(so/jar/dll)耦合SQL质量得不到保障,业务相互影响数据库耦合 “服务化”是一个很好的解决上述痛点的方案。那么问题来了,微服务架构多“微”才合适?行业内有这样四类常见…...
2024/4/24 12:39:43 - Druid监控配置相关说明
在springboot 2.x 直接在yml配置类中配置filters: stat,wall #说明: stat用于监控--wall用于防火墙#启用sql监控 druid:stat-view-servlet:url-pattern: /druid/* #web访问路径allow: localhost #允许访问的ip,不配置默认所有地址都可以访问login-username: admin #…...
2024/4/24 12:39:38 - 读书笔记——潜规则
知道潜规则这边书,来自B站半佛老师的推荐。看过以后,才发现这本书已经出版近20年了。书中举例了很多中国历史上的”潜规则“。核心论述观点是,每个人都在为了自己计算着,趋利避害的行使着潜规则。 书中有一个章节名为”新官堕落定律“,由于看书过程是分散到一周的时…...
2024/4/24 12:39:37 - freemarker使用ftl生成word
使用freemarker生成word相对来说是一种比较简单的方式,下面来说说使用ftl生成word的方法。代码和ftl存放地址:1、编写需要生成的word模板,如下图2、将需要替换的内容修改为参数形式,如下图3、将word另存为xml,格式化,并将错乱的参数修改正确,如下图修改后的参数,如下图…...
2024/4/24 12:39:36 - linux解决部分命令tab键补齐失败方法
CentOS在最小化安装时,没有安装自动补全的包,需要手动安装。 yum -y install bash-completion 安装好后,重新登陆即可(刷新bash环境)...
2024/4/15 4:27:41 - LeetCode 279. Perfect Squares
原题目:https://leetcode-cn.com/problems/perfect-squares/思路一:进行广度优先遍历,先创建完全平方数数组sq,对于一层中的元素依次和数组sq的元素进行比较。1、如果元素等于sq的元素:说明找到了答案2、如果元素小于sq的元素,跳过3、如果元素大于sq的元素,相减进入队列…...
2024/4/18 5:56:07 - 跟汤老师学Java笔记:练习:for循环
跟汤老师学Java笔记:练习:for循环 完成:第一遍 1.怎么选择for循环还是while循环? 循环次数确定时一般使用for循环 循环次数不确定时一般使用while和do…while循环 2.任意输入整数,根据这个值输出加法表 0+5=5 1+4=5 2+3=5 4+1=5 5+0=5 package season5;import java.util.S…...
2024/4/15 4:27:39 - Codeup——581 | 问题 E: Problem B
题目描述 请写一个程序,对于一个m行m列的(1<m<10)的方阵,求其每一行,每一列及主对角线元素之和,最后按照从大到小的顺序依次输出。 输入 共一组数据,输入的第一行为一个正整数,表示m,接下来的m行,每行m个整数表示方阵元素。 输出 从大到小排列的一行整数,每个…...
2024/4/15 4:27:38 - Android开发技术之——使用ROOM数据库
第一、添加相应依赖 在应用或模块的 build.gradle 文件中添加所需工件的依赖项: dependencies {def room_version = "2.2.5"implementation "androidx.room:room-runtime:$room_version"annotationProcessor "androidx.room:room-compiler:$room_ver…...
2024/4/24 12:39:35 - finder个人收藏和前往文件夹
finder的一些用法工具/原料mac方法/步骤前往文件夹:finder默认不能直接点击一些特殊的目录,可以通过跳转到功能来打开相应的文件夹2个人收藏:如果某一个文件目录,经常用到,可以将它拖到个人收藏中,方便使用,也节省时间。...
2024/4/24 12:39:34 - Swift的属性
属性分类 在Swift中, 严格意义上来讲属性可以分为两大类: 实例属性和类型属性实例属性(Instance Property): 只能通过实例去访问的属性存储实例属性(Stored Instance Property): 存储在市里的内存中, 每个实例都只有一份计算实例属性(Computed Instance Property) 类型属性(Typ…...
2024/4/24 12:39:33 - 数据分页 mongoose-sex-page
const page = req.query.page;// page 指定当前页// suze 指定每页显示的数据条数// display 指定客户端要显示的页码数量// exec 向数据库中发送查询请求// 查询所有文章数据let articles = await pagination(Article).page(page).size(2).display(3).populate(author).exec()…...
2024/4/24 12:39:32 - Maven介绍以及运用
介绍:Maven是一个项目管理工具,它包含了一个项目对象模型 (Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑。当你使用Ma…...
2024/4/24 12:39:31 - Jupyter Notebook详细教程(下)
实例分析 现在我们已经看了一个 Jupyter Notebook,是时候看看它们在实践中使用了,这应该会让你更清楚地了解它们为什么那么受欢迎。现在是时候开始使用前面提到的财富 500 数据集了。请记住,我们的目标是了解美国最大公司的利润在历史上是如何变化的。 值得注意的是,每个人…...
2024/4/24 12:39:38 - Fastdfs_5.08 + nginx_14.0 集群部署
Fastdfs_5.08 + nginx_14.0 集群部署服务器规划:一、所有tracker和storage节点都要执行:二、配置tracker服务器三、配置storage服务器四、文件上传测试(ip01)五、在所有storage节点安装fastdfs-nginx-module六、验证:通过浏览器访问测试时上传的文件七、Java API 客户端配…...
2024/4/24 12:39:30 - Axure 9.0.0.3701 授权码
产品经理主力工具 Axure 在2020年5月26日更新了最新的 3701 版本,具体更新如下:很多小伙伴在更新后会出现之前的授权无法使用的情况,如果出现这种情况大家可以通过在产品栈查找相对应的版本进行获取最新的授权码。获取地址:https://7rp.cn/1174...
2024/4/24 12:39:33 - MFC如何拆分窗口
基于MFC单文档,MFC标准,CFormView 自定义类CuserTreeView,继承于CTreeView,用于显示用户信息,自定义类CMedicineView,继承于CListView,用于显示药品信息框架相当于容器,视图放在容器中。拆分窗口应该放在框架类中,重写OnCreateClient()函数工程建好之后在点击项目->属…...
2024/4/24 12:39:27 - Swift之默认与自定义构造函数
引入:不给存储属性赋值,报错 定义类属性不报错,结构体的实例时必须为所有的存储属性设置一个合适的初始值 要不报错有3种可选方式: 1 可选型 2 直接定义的时候初始化,直接 = 3 构造函数中初始化 知识点一:构造函数的作用 1、构造函数用于初始化一个类的实例(创建对象) …...
2024/4/24 12:39:35
最新文章
- 【spring6】Bean的生命周期
1.Bean的生命周期之5步 Bean生命周期的管理,可以参考Spring的源码:AbstractAutowireCapableBeanFactory类的doCreateBean()方法 Bean生命周期可以粗略的划分为五大步: 1)实例化Bean 2)Bean属性赋值 3)初始化…...
2024/4/26 16:12:21 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 方案分享 | 嵌入式指纹方案
随着智能设备的持续发展,指纹识别技术成为了现在智能终端市场和移动支付市场中占有率最高的生物识别技术。凭借高识别率、短耗时等优势,被广泛地运用在智能门锁、智能手机、智能家居等设备上。 我们推荐的品牌早已在2015年进入指纹识别应用领域ÿ…...
2024/4/23 6:15:34 - 自定义OPPO-r9s的kernel内核,并开启安卓支持docker
0. 版本说明 本文提供了OPPO手机r9s的内核编译方法,并开机支持docker。用的是开源lineage14.1的rom。 我这边基于开源lineage14.1,打了一个docker内核编译镜像(17380582683/r9s),大家可以在容器里,手动打出完整的rom包zip文件。…...
2024/4/23 2:13:16 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/4/25 11:51:20 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/4/25 18:39:24 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/4/25 18:38:39 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/4/25 18:39:23 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/4/25 18:39:22 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/4/25 18:39:22 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/4/25 18:39:20 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/4/25 16:48:44 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/4/26 16:00:35 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/4/25 18:39:16 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/4/25 18:39:16 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/4/25 0:00:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/4/25 4:19:21 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/4/25 18:39:14 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/4/25 18:39:12 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/4/25 2:10:52 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/4/25 18:39:00 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/4/25 13:19:01 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/4/25 18:38:58 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/4/25 18:38:57 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57