【翻译】大规模软件多样性作为防御机制——Massive-Scale Software Diversity as a Defense Mechanism
大规模软件多样性作为防御机制
【文章为google-translate的直译结果,最近暂时没有时间修改翻译内容。google-translate的翻译结果中有很多明显的错误,遇到类似的问题,请读者结合英文仔细揣摩。】
ABSTRACT
摘要
We contend that the time has come to revisit the idea of software diversity for defense purposes. Four fundamental paradigm shifts that have occurred in the past decade now make it viable to distribute a unique version of every program to every user. We outline a practical approach for providing compiler-generated software diversity on a massive scale. It is based on an “App Store” containing a diversification engine (a “multicompiler”) that automatically generates a unique, but functionally identical version of every program each time that a downloader requests it. All the different versions of the same program behave in exactly the same way from the perspective of the end-user, but they implement their functionality in subtly different ways. As a result, any specific attack will succeed only on a small fraction of targets. An attacker would require a large number of different attacks and would have no way of knowing a priori which specific attack will succeed on which specific target. Hence, the cost to the attacker is raised dramatically. Equally importantly, our approach makes it much more difficult for an attacker to generate attack vectors by way of reverse engineering of security patches. An attacker requires two pieces of information to extract a vulnerability from a bug fix: the version of the program that is vulnerable and the specific patch that fixes the vulnerability. In an environment in which software is diversified and every instance of every program is unique, we can set things up so that the attacker never obtains a matching pair of vulnerable program and its corresponding bug fix that could be used to identify the vulnerability. We propose a mechanism for incremental updating of diversified software that has this property.
我们认为,现在是时候重新审视出于防御目的的软件多样性的想法了。在过去的十年中发生了四个基本的范式转换,现在可以将每个程序的唯一版本分发给每个用户。我们概述了一种大规模提供编译器生成的软件多样性的实用方法。它基于一个“ App Store”,其中包含一个多样化引擎(“多重编译器”),每次下载程序请求时,该引擎都会自动生成每个程序的唯一但功能相同的版本。从最终用户的角度来看,同一程序的所有不同版本的行为都完全相同,但是它们以不同的方式实现其功能。结果,任何特定的攻击都只会对一小部分目标成功。攻击者将需要大量不同的攻击,并且无法事先知道哪种特定攻击将在哪个特定目标上成功。因此,大大增加了攻击者的成本。同样重要的是,我们的方法使攻击者更难通过安全补丁的反向工程来生成攻击向量。攻击者需要两条信息才能从错误修复中提取漏洞:漏洞易受攻击的程序版本和漏洞修复的特定补丁。在软件多样化且每个程序的每个实例都是唯一的环境中,我们可以进行设置,以使攻击者永远不会获得匹配的易受攻击程序对及其可用于识别漏洞的错误修复程序。我们提出了一种具有这种特性的增量更新各种软件的机制。
Categories and Subject Descriptors
类别和主题描述符
C.2.4 [Computer-Communication Networks]: Distributed Systems; D.2.0 [Software Engineering]: General; D.3.4 [Programming Languages]: Processors—Compilers; K.6.5 [Management of Computing and Information Systems]: Security and Protection
C.2.4 [计算机通信网络]:分布式系统; D.2.0 [软件工程]:常规; D.3.4 [编程语言]:处理器—编译器; K.6.5 [计算和信息系统的管理]:安全性和保护
General Terms
一般条款
Design, Reliability, Security.
设计,可靠性,安全性。
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
只要不为牟利或商业利益而制作或分发副本,并且副本载有本通知和第一页的完整引用,则可免费提供允许将本作品的全部或部分制作为个人或教室使用的数字或纸质副本,以供免费使用。 。 若要进行其他复制,重新发布,在服务器上发布或重新分发到列表,则需要事先获得特定许可和/或费用。
NSPW’10, September 21–23, 2010, Concord, Massachusetts, USA.
Copyright 2010 ACM 978-1-4503-0415-3/10/09 …$10.00.
Keywords
关键词
Compiler-generated software diversity, dynamic patching of software vulnerabilities, service computing architectures, software vulnerabilities, reverse engineering of security patches.
编译器生成的软件多样性,软件漏洞的动态补丁,服务计算体系结构,软件漏洞,安全补丁的反向工程。
1. INTRODUCTION
1.引言
Open networks and the computers on them are under constant attack from a variety of adversaries. Most of these attacks are enabled by software vulnerabilities, i.e., errors in operating systems, device drivers, shared libraries, and application programs that can be exploited to perform unauthorized operations on the computers running the software. Although considerable efforts have gone into finding and eliminating such errors, and although impressive advances have been made in doing so, the complexity of today’s software systems is so great that a certain number of residual errors will probably always be present. The incidence of such errors tends to be proportional to the overall code size and decrease over time.
开放式网络及其上的计算机不断受到各种对手的攻击。 这些攻击大多数是由软件漏洞引起的,即操作系统,设备驱动程序,共享库和应用程序中的错误,这些漏洞可被利用来对运行该软件的计算机执行未经授权的操作。 尽管在发现和消除此类错误方面已经付出了巨大的努力,并且尽管这样做已经取得了令人瞩目的进步,但是当今的软件系统非常复杂,以致可能总是存在一定数量的残留错误。 此类错误的发生率往往与总代码大小成比例,并且会随着时间的流逝而减少。
The existence of residual software errors becomes a significant threat when large numbers of computers are affected by the identical vulnerability at the same time. Unfortunately, this is the situation today. We currently live in a software monoculture—for some widely used software, the identical binary code is installed on millions of computers, and sometimes even hundreds of millions. This makes it easy for an attacker (Figure 1), because the same attack vector is likely to succeed on a large number of targets [8, 19].
当大量计算机同时受到同一漏洞的影响时,残留软件错误的存在将成为严重威胁。 不幸的是,今天就是这种情况。 当前,我们生活在软件单一文化中-对于某些广泛使用的软件,相同的二进制代码已安装在数百万台计算机上,有时甚至是数亿台。 这使攻击者很容易(图1),因为相同的攻击媒介很可能在大量目标上成功[8,19]。

But what if these millions of computers were all running different versions of the software? That is, what if we could ensure that every computer runs a unique but functionally identical binary (Figure 2), so that a different attack vector is needed for different targets. All the different versions would behave in exactly the same way from the perspective of the end-user, but they would implement their functionality in subtly different ways. As a result, any specific attack would succeed only on a small fraction of systems and would no longer sweep through the whole internet. An attacker would require a large number of different attacks and would have no way of knowing a priori which specific attack should be directed at what specific target. Hence, the cost to the attacker would be raised dramatically.
但是,如果数百万台计算机都运行不同版本的软件怎么办? 也就是说,如果我们可以确保每台计算机运行唯一但功能相同的二进制文件(图2),以便对不同的目标需要不同的攻击媒介,该怎么办。 从最终用户的角度来看,所有不同版本的行为都将完全相同,但是它们将以不同的方式实现其功能。 结果,任何特定的攻击都只会在一小部分系统上成功,并且不会再席卷整个Internet。 攻击者将需要大量不同的攻击,并且无法得知先验哪种特定攻击应针对哪个特定目标。 因此,将大大提高攻击者的成本。

The idea of using software diversity as a defense mechanism is not new, but it has never been realized in practice at any significant scale. Until quite recently, it would have been prohibitively expensive to create a unique version of every program for every client.
使用软件多样性作为防御机制的想法并不是什么新鲜事,但实际上从未在任何重大规模上实现。 直到最近,为每个客户端创建每个程序的唯一版本的费用仍然过高。
In this paper, we make a passionate argument that such massive scale software diversity is now actually technically possible. We observe that this is enabled by four simultaneous paradigm shifts that are occurring just now. We present our blueprint for an architecture that provides such massive-scale software diversity. We elaborate on the problem of patching software that has been diversified. We present a list of interesting open research problems that appear in the context of massive-scale software diversity. We claim that massive-scale software diversity is a new security paradigm in itself. Finally, following a section on related work, we conclude the paper.
在本文中,我们提出了一个充满激情的论点,即从技术上来说,如此大规模的软件多样性现在实际上已成为可能。 我们观察到,这是由四个同时发生的范式转换实现的。 我们提出了可提供如此大规模软件多样性的体系结构的蓝图。 我们详细介绍了已经多样化的补丁软件问题。 我们提出了一系列有趣的开放式研究问题,这些问题在大规模软件多样性的背景下出现。 我们声称大规模软件多样性本身就是一个新的安全范例。 最后,在有关工作的一节之后,我们对本文进行了总结。
2. VULNERABILITIES, EXPLOITS AND A SOLUTION
2.漏洞,开发和解决方案
A software vulnerability by itself is merely a hazard. In order to turn such a hazard into a successful attack, an attacker needs to find a successful exploit strategy. For example, the attacker may know of a vulnerability that enables a write beyond the end of a certain buffer on the stack. But in order to exploit this known vulnerability, the attacker needs to overwrite very specific locations on the stack with very specific values.
软件漏洞本身仅是一种危害。 为了将这种危险转化为成功的攻击,攻击者需要找到成功的利用策略。 例如,攻击者可能知道一个漏洞,该漏洞使写操作超出堆栈上某个缓冲区的末尾。 但是,为了利用此已知漏洞,攻击者需要使用非常特定的值覆盖堆栈中非常特定的位置。
Operating system vendors now add elements of randomness to their systems, with the aim of making it more difficult for attackers to design a successful exploit. For example, the latest version of the Windows operating system now randomizes the starting address of the stack. Unfortunately, this has not stopped attackers from devising workarounds.
现在,操作系统供应商在其系统中添加了随机性元素,目的是使攻击者更难于设计成功的漏洞利用程序。 例如,最新版本的Windows操作系统现在可以使堆栈的起始地址随机化。 不幸的是,这并没有阻止攻击者设计解决方法。
Designing a successful exploit for a known vulnerability is not trivial, but a dedicated attacker with ample resources is likely to succeed in eventually creating an attack. In today’s world, the effort invested into designing such an exploit can be amortized by its wide applicability—since millions of users are running the identical vulnerable binary, just one successful exploit can affect all of them simultaneously.
设计成功的已知漏洞利用程序并非易事,但拥有足够资源的专门攻击者很可能最终成功地发起攻击。 在当今世界,设计这种漏洞利用所付出的努力可以因其广泛的适用性而分摊。由于数百万用户正在运行相同的易受攻击的二进制文件,因此只有一个成功的漏洞利用可以同时影响所有这些漏洞。
It is this fundamental problem that massive-scale software diversity addresses. We advocate the introduction of automated code variance techniques that result in the binary code images delivered to subsequent code consumers being subtly different. This process can be embedded seamlessly into an online software delivery system, an “App Store” (Figure 3), and thereby be made entirely transparent to the code consumer (all programs derived from the same source in this manner have the identical functionality). The mechanism can even be set up so that adding software diversity poses no extra effort to the software programmer (a compiler automatically generates the different versions without any additional human intervention). But as a result of deploying massive-scale diversity, any specific exploit will work on only a relatively small number of targets.
大规模软件多样性解决的正是这个基本问题。 我们提倡引入自动代码差异技术,以使交付给后续代码使用者的二进制代码图像略有不同。 该过程可以无缝地嵌入在线软件交付系统“ App Store”(图3)中,从而对代码使用者完全透明(以这种方式从同一源派生的所有程序都具有相同的功能)。 甚至可以设置该机制,以便增加软件的多样性不会对软件程序员造成任何额外的负担(编译器会自动生成不同的版本,而无需任何额外的人工干预)。 但是,由于部署了大规模的多样性,任何特定的利用都只能在相对较少的目标上起作用。

3. DIVERSITY REMOVES REVERSE ENGINEERING VULNERABILITIES OF SOFTWARE PATCHES
3.多样性消除了软件补丁的逆向工程漏洞
Massive-scale software diversity removes another major problem of current software monoculture: the fact that releasing a patch for a discovered vulnerability alerts adversaries about the existence of the vulnerability. It is current best practice to fix software vulnerabilities as soon as possible after they are discovered. In the desktop space, this is usually achieved by sending a “patch” to the compromised host. Such a patch contains the delta between the original (vulnerable) program and a corrected new version. Since such fixes usually apply to only a small fraction of a program, it is more efficient to send just the patch rather than sending a whole corrected program.
大规模软件的多样性消除了当前软件单一文化的另一个主要问题:发布已发现漏洞的补丁会警告对手有关漏洞的存在这一事实。 当前的最佳实践是在发现软件漏洞后尽快对其进行修复。 在桌面空间中,这通常是通过向受感染主机发送“补丁”来实现的。 这样的补丁包含原始(易受攻击的)程序和更正的新版本之间的差异。 由于此类修复程序通常仅适用于程序的一小部分,因此仅发送补丁程序而不是发送整个经过更正的程序会更有效。
In the mobile space, user-installable programs (“Apps”) are currently updated by sending complete replacement versions rather applying an incremental patch, while the mobile operating system software itself is updated using patches. As Apps on mobile devices grow, it is probably only a matter of time until the App Store frameworks of the various mobile platforms will support replacing only part of an App (via a patch) rather than downloading a wholly new App each time.
在移动空间中,当前通过发送完整的替换版本而不是应用增量补丁来更新用户可安装程序(“ Apps”),同时使用补丁来更新移动操作系统软件本身。 随着移动设备上App的增长,各个移动平台的App Store框架仅支持(通过补丁程序)替换App的一部分而不是每次都下载一个全新的App可能只是时间问题。
A bug fix (in the form of either a patch or a replacement program) gives a potential adversary information that can be used to precisely identify the vulnerability being fixed in the new version (Figure 4). A significant proportion of software exploits today are generated from reverse engineering of error fixes. As a consequence, it is imperative that updates are applied as soon as they are available. The average time lag between availability of an update and its installation on a vulnerable target is often a good predictor for overall vulnerability.
错误修复程序(以补丁程序或替换程序的形式)提供了潜在的攻击者信息,可用于精确地识别新版本中已修复的漏洞(图4)。 如今,相当大的软件漏洞利用是由错误修复程序的反向工程产生的。 因此,必须在更新可用时立即应用更新。 更新的可用性与在易受攻击的目标上安装之间的平均时间差通常可以很好地预测整个漏洞。

In this context, Apps for mobile devices are actually potentially even more vulnerable than desktop applications. This is because Apps for mobile devices tend to evolve much more quickly than traditional desktop software. For example, for many Apps in the Android Marketplace, release cycles are expressed in days rather than months. The rapid software evolution cycle is more likely to push out software that is not as mature as it should be, i.e., containing a higher proportion of residual errors than necessary. And fixing these errors in subsequent releases will give an adversary a steady stream of hints as to the location of exploitable vulnerabilities.
在这种情况下,用于移动设备的Apps实际上比台式机应用程序更容易受到攻击。 这是因为用于移动设备的Apps往往比传统的桌面软件发展得更快。 例如,对于Android Marketplace中的许多Apps,发布周期以天而不是月来表示。 快速的软件发展周期更有可能推出不如应有的成熟的软件,即,包含比必要更高比例的残留错误。 并在后续版本中修复这些错误将为攻击者提供源源不断的关于可利用漏洞的位置的提示。
Massive-scale software diversity makes it much more difficult for an attacker to generate attack vectors by way of reverse engineering of security patches (Figures 5 and 6). An attacker requires two pieces of information to extract a vulnerability from a bug fix: the version of the software that is vulnerable and the specific patch that fixes the vulnerability. In an environment in which software is diversified to an extreme degree and every instance of every piece of software is unique, we can set things up so that the attacker never obtains a matching pair of vulnerable software and its corresponding bug fix that could be used to identify the vulnerability. In Section 7 below, we outline a concrete mechanism that achieves this goal.
大规模的软件多样性使攻击者更加难以通过对安全补丁进行反向工程来生成攻击向量(图5和6)。 攻击者需要两条信息才能从漏洞修复中提取漏洞:漏洞易受攻击的软件版本和漏洞修复的特定补丁。 在软件极端多样化的环境中,每个软件的每个实例都是唯一的,我们可以进行设置,以使攻击者永远不会获得匹配的易受攻击软件对及其相应的漏洞修复程序,这些漏洞可用于 识别漏洞。 在下面的第7节中,我们概述了实现此目标的具体机制。


4. PARADIGM SHIFTS AS ENABLERS
4.范式转换为使能
Massive-scale software diversity is enabled by four fundamental paradigm shifts that have occurred almost simultaneously in the past few years. While each of these is remarkable in its own right, it is their fortuitous coincidence that is making software diversity truly scalable, affordable, and practical now. In the following, we briefly describe each of these paradigm shifts, present evidence that indicates that the shift is real, and then discuss the consequences with respect to our vision.
在过去几年中,几乎同时发生了四个基本的范式转换,从而实现了大规模软件多样性。 尽管每种功能本身都非常出色,但是正是它们的偶然巧合才使软件多样性真正真正可扩展,可负担且实用。 在下文中,我们简要描述了这些范式转换中的每一个,提供了表明该转换是真实的证据,然后讨论了关于我们愿景的后果。
4.1 Paradigm Shift One: Online Software Delivery
4.1范式转移一:在线软件交付
-
Traditional Approach:
-
传统方法:
Until quite recently, software was predominantly shipped “in boxes on a CD.” Mass production of the CDs made it impractical to give every user a different version.
直到最近,软件主要还是“装在CD上的盒子中”提供的。 CD的大量生产使得为每个用户提供不同的版本是不切实际的。
-
Paradigm Shift:
-
模式转变:
Distribution of a unique program version to each and every user becomes feasible when software is downloaded via the network rather than installed from a CD. We are just at the point when many programs are now installed only via the internet.
当通过网络下载软件而不是从CD安装软件时,向每个用户分配唯一的程序版本变得可行。 现在只有许多程序只能通过Internet安装。
-
Evidence for Paradigm Shift:
-
范式转移的证据:
The Firefox web browser has been downloaded via the internet more than one billion times.
Firefox Web浏览器已通过Internet下载超过十亿次。
-
New Approach Enabled By Paradigm Shift:
-
通过范式转换实现的新方法:
Rather than downloading the same binary to all users, it becomes possible to send each user a subtly different version with the exact same functionality. From the users’ perspective, nothing at all has changed, but for an attacker, things have become a lot more difficult.
不必将相同的二进制文件下载给所有用户,而是可以向每个用户发送功能完全相同的微妙版本。 从用户的角度来看,什么都没有改变,但是对于攻击者而言,事情变得更加困难。
4.2 Paradigm Shift Two: Ultra-Reliable Compilers
4.2范式转换二:超可靠的编译器
-
Traditional Approach:
-
传统方法:
Not so long ago, the compiler itself was often the largest and most complex software program on any given system. Hence, it wasn’t unreasonable to assume that the compiler itself might have errors. As a partial consequence, traditional software certification and testing has focused on the software binary that is the end-product of compilation. The idea of executing a binary program coming out of a compiler without any further testing of the binary itself was heresy not so very long ago.
不久前,编译器本身通常是任何给定系统上最大,最复杂的软件程序。 因此,假设编译器本身可能有错误并非没有道理。 造成部分后果的是,传统的软件认证和测试已将重点放在作为编译最终产品的软件二进制文件上。 执行编译器中的二进制程序而不对二进制本身进行任何进一步测试的想法在不久以前就很混乱。
-
Paradigm Shift:
-
模式转变:
Compilation is now a very predictable process. While almost all other software programs have grown in size and complexity, sometimes by orders of magnitude, compilers today are not orders of magnitude more complex than they were 20 years ago. Moreover, many existing compiler lines are very mature, having been refined rather than enlarged over sometimes decades. Without exaggeration, one can say that compilers are among the most reliable computer programs in existence. Even dynamic compilation is now routinely employed with extremely high reliability. Software errors that can be traced back to compiler errors are as good as unheard of. Just-in-time compilers and binary translators are now widespread, and as a result millions of users routinely execute binary code that comes straight out of a compiler, without any further testing prior to execution.
现在,编译是一个非常可预测的过程。 尽管几乎所有其他软件程序的大小和复杂性都在增长,有时甚至增加了几个数量级,但如今的编译器并不比20年前复杂得多。 而且,许多现有的编译器行已经非常成熟,在数十年的时间里一直在完善而不是扩大。 毫不夸张地说,编译器是现有的最可靠的计算机程序之一。 现在,即使采用动态编译方式,也具有很高的可靠性。 可以追溯到编译器错误的软件错误是闻所未闻的。 即时编译器和二进制翻译器现已普及,因此,数百万用户按常规执行直接从编译器中提取的二进制代码,而无需在执行之前进行任何进一步的测试。
-
Evidence for Paradigm Shift:
-
范式转移的证据:
Apple has transitioned millions of users from the PowerPC to the Intel architecture using a fully automated just-in-time compiler (binary translation engine) without any reported incidents. The reliability of these compilers is stunning, considering that they have been able to automatically translate programs of the size of the Microsoft Office suite fully unattended, without any testing of the resulting output, and on-the fly.
苹果公司已经使用全自动即时编译器(二进制翻译引擎)将数百万用户从PowerPC迁移到了英特尔架构,而没有任何事件报告。 考虑到它们能够自动转换完全无人值守的Microsoft Office套件大小的程序,而无需对结果输出进行任何测试,并且能够即时进行转换,因此它们的可靠性令人叹为观止。
-
New Approach Enabled By Paradigm Shift:
-
通过范式转换实现的新方法:
Instead of testing and certifying a software binary, it should be sufficient to certify and test a representative binary coming out of a diversifying compiler (“multicompiler”). The purpose of this testing and certification would be strictly to find errors in the program, not errors in the compiler itself. We are assuming that we can build multicompilers that have the same reliability as current unicompilers, a property that could be verified by large-scale automated regression testing comparing different diversified program versions generated by a multicompiler against binaries produced by a unicompiler. If a difference in reliability were found, we should at least be able to quantify it.
除了测试和认证软件二进制文件外,对来自多样化编译器(“ multicompiler”)的代表性二进制文件进行认证和测试也应足够。 该测试和认证的目的将严格是在程序中查找错误,而不是在编译器本身中查找错误。 我们假设我们可以构建与当前的单编译器具有相同可靠性的多编译器,可以通过大规模自动回归测试来验证该特性,该测试将多编译器生成的不同程序版本与单编译器生成的二进制文件进行比较。 如果发现可靠性差异,我们至少应该能够对其进行量化。
4.3 Paradigm Shift Three: Cloud Computing
-
Traditional Approach:
-
传统方法:
In the past, it would have been impossible to set up the infrastructure that generates a unique version of each program for each user. The cost would have been prohibitive.
过去,不可能建立为每个用户生成每个程序的唯一版本的基础结构。 费用本来是高得让人望而却步。
-
Paradigm Shift:
-
模式转变:
There are now remote computing platforms such as the Amazon Elastic Compute Cloud (EC2) that provide “cycles on demand” for a low fee. This makes it possible to scale almost instantaneously to even very large peak demands without any up-front investment.
现在,存在诸如Amazon Elastic Compute Cloud(EC2)之类的远程计算平台,它们以低廉的价格提供“按需循环”。 这使得几乎即时扩展到非常大的峰值需求成为可能,而无需任何前期投资。
-
Evidence for Paradigm Shift:
-
范式转移的证据:
Many start-up companies are using cloud computing to rapidly scale up their operations. For example, Animoto is a company that lets customers upload images and music and automatically creates customized Web-based video presentations from them. In mid-April of 2008, Animoto was hit by a viral popularity surge through Facebook. After having 5,000 new customers on average per day, they suddenly had nearly 750,000 people sign up in three days. At the peak, almost 25,000 people tried Animoto in a single hour. Using cloud computing, they were able to successfully multiply their server capacity by a factor of almost 100 virtually instantaneously [6].
许多初创公司正在使用云计算来快速扩展其业务。 例如,Animoto是一家允许客户上传图像和音乐并自动从中创建定制的基于Web的视频演示文稿的公司。 在2008年4月中旬,Animoto受到了Facebook病毒式传播热潮的打击。 在平均每天有5,000个新客户之后,三天内突然有近750,000人注册。 在高峰期,一个小时内就有近25,000人试用了Animoto。 使用云计算,他们几乎可以立即将服务器容量成功提高近100倍[6]。
-
New Approach Enabled By Paradigm Shift:
-
通过范式转换实现的新方法:
Using cloud computing, the cost per unique version of a program is essentially constant, no matter whether we are generating 1000 versions per day or 10 Million versions per day, and we can react to changing demand almost instantaneously.
使用云计算,无论我们每天生成1000个版本还是每天生成1000万个版本,程序每个唯一版本的成本本质上都是恒定的,并且我们几乎可以即时响应不断变化的需求。
4.4 Paradigm Shift Four: “Good Enough” Performance
-
Traditional Approach:
-
传统方法:
Most of our computing past has been dominated by Moore’s Law: computers were always getting faster, software kept growing more complex, and users were willing to upgrade to the newest and latest hardware to be able to run the latest software with the newest features.
过去的大多数计算都受到摩尔定律的支配:计算机一直在进步,软件一直在变得越来越复杂,用户愿意升级到最新的硬件,以便能够运行具有最新功能的最新软件。
-
Paradigm Shift:
-
模式转变:
Suddenly, performance in some domains has become “good enough.” This does not apply to every domain; for example, games are a no-table exception. But for many traditional desktop computing categories, just at the time that Moore’s Law apparently has hit a wall at which hardware manufacturers find it increasingly difficult to further raise clock frequencies, users apparently have mostly decided that they now have sufficient computing power anyway.
突然之间,某些领域的性能已变得“足够好”。 这并不适用于每个域; 例如,游戏是一个无桌子例外。 但是对于许多传统的台式机计算类别,就在摩尔定律显然触及到硬件制造商发现进一步提高时钟频率变得越来越困难之时,用户显然已经决定他们现在无论如何都具有足够的计算能力。
-
Evidence for Paradigm Shift:
-
范式转移的证据:
Microsoft has had a difficult time persuading users to upgrade from Windows XP, and fewer and fewer users see the utility of upgrading to the latest version of Microsoft Office. At the same time, a wide range of “netbooks” has appeared in the marketplace that offers noticeably less (sometimes by as much as 50%) processing performance than established hardware, and yet these inexpensive weakly-powered computers are proving to be extremely popular, because they are “good enough.”
微软一直很难说服用户从Windows XP进行升级,并且越来越少的用户看到了升级到Microsoft Office最新版本的实用程序。 同时,市场上出现了各种各样的“上网本”,其处理性能明显低于(有时高达50%)已建立的硬件,但是事实证明,这些价格低廉且功能弱的计算机非常受欢迎。 ,因为它们“足够好”。
-
New Approach Enabled By Paradigm Shift:
-
通过范式转换实现的新方法:
Because software performance is now mostly “good enough,” users are likely to accept a small performance penalty if it gives them added security. So even if a multicompiler were to create program versions that are less efficient by a small degree, say 5% to 15% less performance than the optimal version created by a unicompiler, this no longer automatically dooms the prospect of massive-scale software diversity becoming a success. Users no longer care so much about performance and may be willing to accept additional security as a welcome trade-off in return for a slight runtime cost.
由于现在软件的性能基本上“足够好”,因此,如果给用户增加了安全性,则用户可能会接受少量的性能损失。 因此,即使多编译器创建的程序版本在某种程度上效率较低,例如,性能比单编译器创建的最佳版本低5%至15%,但这不再自动注定了大规模软件多样性的前景 成功。 用户不再那么在乎性能,他们可能愿意接受额外的安全性作为折衷方案,以换取少量的运行时间成本。
5. RUNTIME COST OF ALTERNATIVE CODE PATHS
5.替代代码路径的运行时成本
So the next question to ask is: will there actually be a runtime overhead, and if yes, why and how much? Since no large-scale system such as the one we envision has been built, we cannot give a definitive answer to this question, but having significant expertise and implementation experience in the area of compiler construction, we can give an educated estimate.
因此,下一个要问的问题是:实际上会不会有运行时开销,如果是,原因和费用是多少? 由于尚未构建像我们设想的那样的大规模系统,因此我们无法对这个问题给出确切的答案,但是由于在编译器构建方面具有丰富的专业知识和实施经验,因此我们可以进行有根据的估算。
Today’s unicompilers are focused on finding the “best” of several possible binary implementations of any source construct. There are usually many alternative paths to choose from, and compilers use heuristics to choose the one that is most likely to provide the best runtime performance. Instead of choosing the “best” of the alternative paths, a multicompiler would give successive users different code paths. Some of the alternative paths will not be as optimized as the “best” one.
当今的单编译器专注于找到任何源构造的几种可能的二进制实现中的“最佳”。 通常有许多替代路径可供选择,并且编译器使用启发式方法选择最有可能提供最佳运行时性能的方法。 多编译器将选择连续的用户不同的代码路径,而不是选择替代路径的“最佳”路径。 一些替代路径不会像“最佳”路径那样优化。
The potential performance loss comes from the difference between the “best” path and an alternative path chosen by the multicompiler for the sake of implementation diversity. In many cases, there will be no performance difference at all. Very often, there are many alternative paths that have exactly the same cost. The main difference between a unicompiler and a multicompiler in these cases will be that the unicompiler always chooses the exact same path in a reproducible manner when confronted with such a choice, whereas the multicompiler will attempt to randomize among the equivalent paths.
潜在的性能损失来自“最佳”路径和多编译器为实现多样性而选择的替代路径之间的差异。 在许多情况下,根本没有性能差异。 很多时候,有很多替代路径的成本完全相同。 在这种情况下,单编译器和多编译器之间的主要区别在于,当遇到这种选择时,单编译器总是以可复制的方式选择完全相同的路径,而多编译器将尝试在等效路径之间进行随机化。
In many cases, there will be sufficiently many alternative paths that all have the “best” runtime behavior, so the multicompiler will never have to choose a path that leads to a performance degradation. But even if a sub-optimal path needs to be chosen now and then for implementation diversity, we don’t expect any significant performance loss. When we study compiler optimization results from academic conferences such as PLDI (Programming Language Design and Implementation) and CGO (Code Generation and Optimization), we find that the incremental benefit of even quite sophisticated optimizations is usually surprisingly small. In the field of compiler construction, a speedup of 3% to 5% is often already considered a significant publishable result. By some measure, this is a sign of the maturity of the field. But it also means that the difference between the “best” path and a “sub-optimal” alternative path is going to be of similar magnitude. After studying the literature on performance variations resulting from existing compiler optimizations, we expect that a slowdown of 5% is probably the maximum runtime cost that would arise out deploying “standard” compilation mechanisms to achieve code variability.
在许多情况下,会有足够多的替代路径都具有“最佳”运行时行为,因此多编译器将永远不必选择会导致性能下降的路径。但是,即使为了实现多样性而时不时地选择次优路径,我们也不会造成任何明显的性能损失。当我们研究来自PLDI(编程语言设计和实现)和CGO(代码生成和优化)等学术会议的编译器优化结果时,我们发现,即使是非常复杂的优化,其增量收益通常也令人惊讶地小。在编译器构造领域,通常将3%到5%的加速比视为重要的可发布结果。从某种程度上说,这是该领域成熟的标志。但这也意味着“最佳”路径与“次优”替代路径之间的差异将具有相似的大小。在研究了由于现有编译器优化而导致的性能变化的文献之后,我们期望将速度降低5%可能是部署“标准”编译机制以实现代码可变性所产生的最大运行时成本。
Furthermore, hardware evolution keeps diminishing the performance differential between the “best” and a “sub-optimal” code path. For example, consider the pervasive use of caches in modern processors. In conjuction with out-of-order instruction execution, this has significantly reduced the importance of a good register allocator. In many cases today, it no longer matters from a performance perspective whether a value is in a register or in the cache. But from the perspective of software diversity as seen by an attacker, this is a fundamental difference that requires a completely different plan of attack.
此外,硬件的发展不断缩小“最佳”代码路径与“次优”代码路径之间的性能差异。 例如,考虑在现代处理器中普遍使用缓存。 结合无序的指令执行,这大大降低了良好的寄存器分配器的重要性。 在当今的许多情况下,从性能角度来看,值是在寄存器中还是在缓存中都不再重要。 但是从攻击者的软件多样性的角度来看,这是一个根本的区别,需要完全不同的攻击计划。
One could of course also consider variation mechanisms that lie outside of the scope of existing compilers precisely because they clearly degrade performance. In certain high-assurance contexts, one may want to explicitly sacrifice execution performance for even greater code variability.
当然,人们也可能会考虑超出现有编译器范围之外的变量机制,因为它们显然会降低性能。 在某些高安全性的上下文中,可能希望显式牺牲执行性能,以实现更大的代码可变性。
6. COST OF COMPILERS IN THE CLOUD
6.云中的编译器成本
Cloud computing has seen explosive growth over the very recent past and is now available from many commercial providers. For example, Amazon’s Elastic Compute Cloud (EC2) is a service that provides remote rental of dedicated compute servers over the network. The service offers a selection of standardized computer configurations to choose from, so that performance is predictable, and is billed per instance-hour consumed.
云计算在最近的几年中出现了爆炸性的增长,现在可以从许多商业提供商处获得。 例如,亚马逊的Elastic Compute Cloud(EC2)是一项服务,可通过网络远程租用专用计算服务器。 该服务提供了一系列可供选择的标准化计算机配置,因此性能是可预测的,并按消耗的实例小时计费。
Running a compiler is mostly a compute-intensive medium throughput process. In order to estimate what it would cost to provide such a service “in the cloud,” we measured the time required to compile the open-source Firefox browser on a modern server dedicated exclusively to this task. We chose Firefox as our model program because on one hand we are contributors to the browser and have its complete source tree readily available, and because on the other hand, most people are familiar with Firefox no matter what platform they use in their day-to-day computing tasks. Firefox is a very substantial program; it has about 30 million lines of code. As a matter of comparison, Linux 2.6.33 (released February 2010) contains about 13 million lines of code, and Windows 7 reportedly consists of approximately 50 million lines of code.
运行编译器通常是一个计算密集型的中吞吐量过程。 为了估算“在云中”提供此类服务的成本,我们测量了在专门用于此任务的现代服务器上编译开源Firefox浏览器所需的时间。 我们选择Firefox作为我们的模型程序,是因为一方面我们是浏览器的贡献者,并且其完整的源代码树随时可用,另一方面,无论他们日常使用什么平台,大多数人都熟悉Firefox。 日计算任务。 Firefox是一个非常强大的程序。 它有大约3000万行代码。 作为比较,Linux 2.6.33(2010年2月发布)包含大约1300万行代码,而Windows 7据说包含大约5000万行代码。
The time to compile Firefox on a dedicated server is about 30 minutes. Hence, in order to create 1000 diversified instances of Firefox, we would need about 500 compute hours from a cloud computing provider.
在专用服务器上编译Firefox的时间约为30分钟。 因此,为了创建1000个多样化的Firefox实例,我们需要来自云计算提供商的大约500个计算小时。
The server we used to compile Firefox is roughly equivalent to Amazon’s “High-CPU Medium Instance” that can be rented by the hour via the EC2 service. Using Amazon’s cost estimate web page, we find that renting such a “High-CPU Medium Instance” server for a month (730 hours) with 100 GB of upload bandwidth and 200 GB of download bandwidth would cost $131.60 at early 2010 pricing levels. This translates into a price of 9 cents per build for an application the size of Firefox, a price that could easily be absorbed into the retail cost of a commercial product and that most users might be more than willing to pay to voluntarily obtain their own custom “diversified” version of an otherwise “free” product.
我们用来编译Firefox的服务器大致相当于Amazon的“ High-CPU Medium Instance”,可以通过EC2服务按小时租用。 使用亚马逊的成本估算网页,我们发现租用这种“ High-CPU Medium Instance”服务器一个月(730小时),具有100 GB的上传带宽和200 GB的下载带宽,按2010年初的价格计算,其价格为131.60美元。 这相当于Firefox大小的应用程序的每次构建价格为9美分,这个价格可以很容易地吸收到商业产品的零售成本中,并且大多数用户可能愿意为自愿获得自己的自定义而支付 否则为“免费”产品的“多样化”版本。
7. SOFTWARE UPDATES AND PATCHES
7.软件更新和补丁
An interesting problem arises from the necessity of updating software that has been diversified. In Section 3 above, we already mentioned the current practice of providing “delta only” software updates through a “patch” that modifies the binary image on the client computer from the old version to the new version. This approach is no longer so straightforward when each client computer is running a different binary. While a straightforward solution would consist of simply having each client download an entirely new diversified version of the updated software, this would often result in very voluminous downloads for only relatively small actual changes.
一个有趣的问题来自更新已经多样化的软件的必要性。 在上面的第3节中,我们已经提到了通过“补丁”提供“仅增量”软件更新的当前做法,该补丁将客户端计算机上的二进制映像从旧版本修改为新版本。 当每台客户端计算机运行不同的二进制文件时,此方法不再那么简单。 虽然一个简单的解决方案就是简单地让每个客户端下载更新后的软件的全新版本,但这通常会导致仅相对较小的实际更改就进行大量下载。
On the other hand, there must be no mechanism by which an attacker could determine which specific version of a binary is running on a client. Hence any update mechanism that transfers only the “delta” between versions must be driven by the client, in that the client communicates to the update mechanism which specific paths were chosen in the compilation of its software version, and the update mechanism then crafts an update patch specific to the particular client. Note that patch construction can yet again be farmed out to a cloud computing mechanism and is thereby almost infinitely scalable.
另一方面,攻击者必须没有机制可以确定客户端上正在运行哪个特定版本的二进制文件。 因此,任何仅在版本之间传递“增量”的更新机制都必须由客户端驱动,因为客户端会向更新机制传达在其软件版本的编译中选择了哪些特定路径的更新机制,然后由该更新机制进行更新 特定于特定客户端的补丁。 请注意,补丁构建可以再次被移植到云计算机制中,从而几乎可以无限扩展。
As a possible solution, we envisage a multicompiler that chooses a different random seed for each version it generates. The random seed drives a random number generator that in turn drives selection of code paths during compilation. The eventual delivery to the client has three components: the random seed, a unique vID identifying the version of the source program that was used for generating the diversified software binary, and the diversified binary itself (Figure 7).
作为一种可能的解决方案,我们设想一个多编译器为其生成的每个版本选择一个不同的随机种子。 随机种子驱动一个随机数生成器,该生成器又驱动编译过程中代码路径的选择。 最终交付给客户端的过程包括三个组成部分:随机种子,标识用于生成多样化软件二进制文件的源程序版本的唯一vID,以及多样化二进制文件本身(图7)。

When the client later requests an update, it returns the random seed and the source program vID to the update mechanism. The update mechanism contains a multicompiler that is run both on the new version (to be installed on the client) and on the old version currently installed on the client (identified by the vID), using the random seed to drive the diversification. This results in two Apps on the updater, a new version (to be the end result of the update on the client) and an old version (the identical App that is currently installed on the client). The updater can then compute a patch by comparing these two versions (Figure 8).
当客户端以后请求更新时,它将随机种子和源程序vID返回给更新机制。 更新机制包含一个多编译器,该编译器在新版本(要安装在客户端上)和当前安装在客户端上的旧版本(由vID标识)上运行,并使用随机种子来推动多样化。 这将在更新程序上产生两个应用程序,一个新版本(作为客户端上更新的最终结果)和一个旧版本(客户端上当前安装的相同应用程序)。 然后,更新程序可以通过比较这两个版本来计算补丁(图8)。

One could imagine even smarter ways of providing updates. For example, one could decompose the original software into “tiles” along procedure boundaries or similar compiler-related constructs. When an update occurs, a reachability analysis in the compiler would compute which of the tiles are affected by the change. When computing the patch, the multicompiler would then only need to operate on the tiles that are affected by the change, often greatly reducing the effort required for the update. The update mechanism could also make a trade-off decision between sending a full new version (at higher bandwidth costs) or computing a patch (at higher compute costs).
人们可以想象甚至更聪明的方式来提供更新。 例如,可以将原始软件沿过程边界或类似的与编译器相关的构造分解为“碎片”。 当发生更新时,编译器中的可达性分析将计算更改影响哪些图块。 在计算补丁时,多编译器仅需要对受更改影响的切片进行操作,通常会大大减少更新所需的工作量。 更新机制还可以在发送完整的新版本(以更高的带宽成本)或计算补丁(以更高的计算成本)之间做出权衡决策。
Among the more advanced open problems is the question of how one would implement remote attestation of software metrics in the absence of a fixed binary from which a hash can be computed. There are scenarios in which a client computer might want to “prove” to a remote server that it is running a specific “well known version” of a program that has not been tampered with. For instance, access to a video streaming service might require the client to “prove” that it is incapable of recording the stream. New research will be needed to answer the question of how to do this in a world in which every instance of the client software is unique.
在更高级的开放性问题中,有一个问题是,在没有固定的二进制文件(可以从中计算哈希值)的情况下,如何实现软件指标的远程证明。 在某些情况下,客户端计算机可能想向远程服务器“证明”它正在运行尚未被篡改的特定的“知名版本”程序。 例如,访问视频流服务可能需要客户端“证明”它无法记录该流。 在客户端软件的每个实例都是唯一的世界中,将需要进行新的研究来回答如何执行此操作的问题。
8. TRUSTING THE DELIVERY SYSTEM
8.信任交付系统
Users might be hesitant to download software without being able to determine whether a binary received over the network is legitimate. In the current “single version” practice, it is possible (but not customary outside specific high-assurance domains) to compute a fingerprint or checksum of a downloaded binary and compare it to the value of a “known good version.” This capability disappears when every downloaded binary is unique.
用户可能会犹豫是否下载软件,而无法确定通过网络接收的二进制文件是否合法。 在当前的“单一版本”实践中,可以(但通常不包括在特定的高保证域之外)计算已下载二进制文件的指纹或校验和,并将其与“已知良好版本”的值进行比较。 当每个下载的二进制文件都是唯一的时,此功能将消失。
One way of establishing trust in code transmitted over a network has in the past been the verification of the code itself prior to execution. For example, the Java bytecode format contains intrinsic provisions for the client to check the type safety and referential integrity of a program prior to its execution. This approach is limited to programs written in certain type-safe languages, such as Java and C#.
过去,对通过网络传输的代码建立信任的一种方法是在执行之前验证代码本身。 例如,Java字节码格式包含内在规定,供客户端在执行程序之前检查程序的类型安全性和引用完整性。 此方法仅限于使用某些类型安全的语言(例如Java和C#)编写的程序。
Interestingly, all of today’s existing “App Store” platforms have more or less abandoned the approach of code verification on the target, even in such cases where the Apps have actually been developed in type-safe languages and on-device verification would in principle be possible. Instead, code verification, if used at all, has been moved “upwards” in the delivery pipeline (Figure 9). For example, on the Android platform, Apps are developed in Java using the standard Java development toolchain. But then they are converted off-line into a type-unsafe execution format for the registerbased Dalvik virtual machine, which can be executed more efficiently than Java bytecode and is not subject to the Java licensing restrictions.
有趣的是,即使在实际使用类型安全语言开发了应用程序且原则上可以在设备上进行验证的情况下,当今所有现有的“ App Store”平台或多或少都放弃了在目标上进行代码验证的方法。 可能。 相反,如果完全使用了代码验证,则已在交付管道中“向上”移动了代码验证(图9)。 例如,在Android平台上,应用程序是使用标准Java开发工具链以Java开发的。 但是,然后将它们离线转换为基于寄存器的Dalvik虚拟机的类型不安全的执行格式,该格式可以比Java字节码更有效地执行,并且不受Java许可限制的约束。
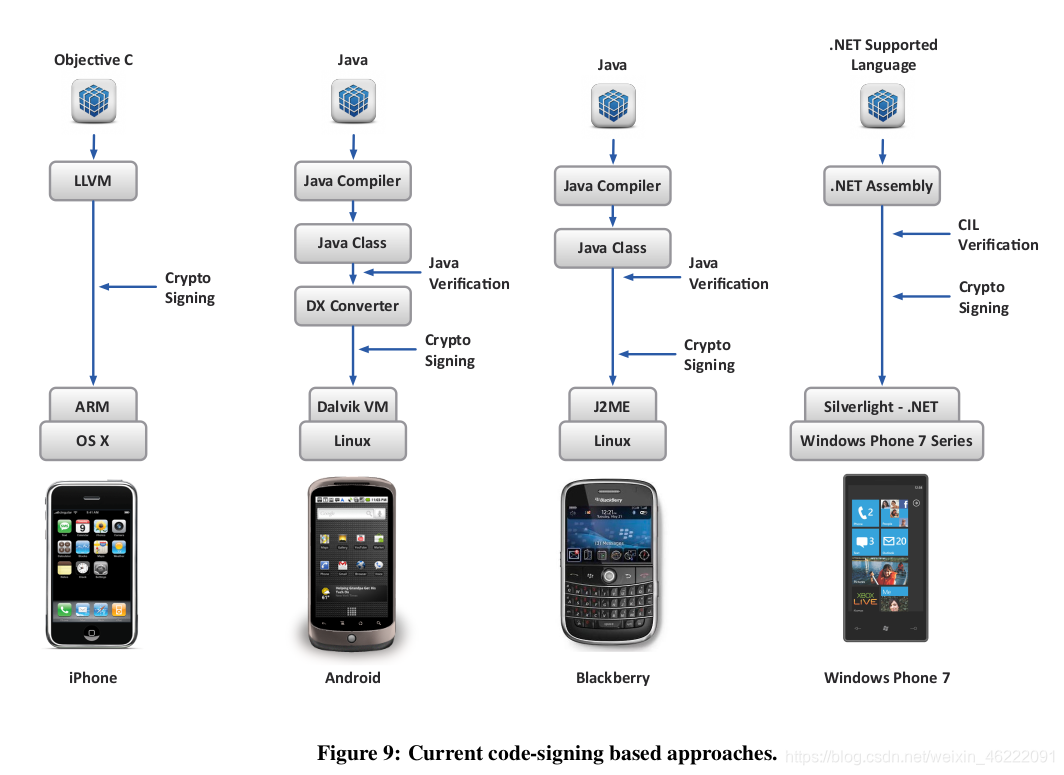
As a consequence, in most of the existing mobile device platforms, the delivery system must be trusted. In the Apple iPhone/iPad/iTunes ecosystem, developers deliver binaries in the ARM processor’s native instruction format to the App Store, while in the Android ecosystem, developers usually deliver binaries in the Dalvik virtual machine’s native bytecode format (.dx)—although apparently also some native ARM applications exist. The whole path between the developer and the eventual mobile device must be protected against tampering, which includes the necessity of having to protect the applications as they are hosted in the App Store itself.
结果,在大多数现有的移动设备平台中,传送系统必须是受信任的。 在Apple iPhone / iPad / iTunes生态系统中,开发人员将ARM处理器的本机指令格式的二进制文件交付给App Store,而在Android生态系统中,开发人员通常以Dalvik虚拟机的本机字节码格式(.dx)交付二进制文件。 还存在一些本机ARM应用程序。 开发人员与最终移动设备之间的整个路径必须受到保护,以防篡改,其中包括必须保护应用程序,因为它们托管在App Store本身中。
The software delivery system we have sketched out here follows this established “App Store” architecture and adds the variant-generating “multicompiler” as an additional step in the path from code producer to code consumer. As in the existing App Store delivery systems, our approach requires that the generated versions queued up for delivery are protected against tampering, and it requires that the delivery handshake to the target is secured (via some crypto graphic mechanism). Our approach is applicable both to executable machine code as well as to the bytecodes of virtual machines such as Dalvik.
我们在此处草绘的软件交付系统遵循已建立的“ App Store”体系结构,并添加了生成变体的“ multicompiler”,这是从代码生产者到代码使用者的另一步骤。 与现有的App Store交付系统一样,我们的方法要求保护排队等待交付的生成版本以防篡改,并且要求(通过某种加密图形机制)保护与目标的交付握手。 我们的方法既适用于可执行机器代码,也适用于虚拟机(例如Dalvik)的字节码。
Another potential issue is the reliability of the code variability generator itself. In Section 4.2 we talked of “ultra-reliable” compilers as a paradigm shift, and compilers have indeed become extremely reliable. There are many deployment scenarios today where users routinely execute code coming out of a compiler without any further testing done on the end product of compilation. On one hand, language runtimes such as the Java Virtual Machine and Microsoft’s Dot Net Common Language Runtime have provided just-in-time compilation for a decade now. On the other hand, binary translators have been deployed “under the hood” in products such as Transmeta’s family of processors (mapping x86 to a custom VLIW architecture) and Apple’s Rosetta engine (mapping PowerPC code to x86). No matter how successful and trouble-free these compilers have proven to be, it may yet present a challenge to persuade users to accept unsupervised automatic compilation without subsequent testing as an integral part of the default software delivery pipeline.
另一个潜在的问题是代码可变性生成器本身的可靠性。在第4.2节中,我们谈到了“超可靠”的编译器是范式的转变,并且编译器确实变得极其可靠。当今有许多部署方案,用户通常执行编译器中的代码,而无需在编译的最终产品上进行任何进一步的测试。一方面,诸如Java虚拟机和Microsoft的Dot Net公共语言运行时之类的语言运行时已经提供了十年的即时编译。另一方面,二进制翻译器已经“秘密地”部署在Transmeta的处理器系列(将x86映射到定制的VLIW架构)和Apple的Rosetta引擎(将PowerPC代码映射到x86)等产品的“幕后”上。不管这些编译器多么成功和无故障,要说服用户接受无监督的自动编译而没有随后的测试作为默认软件交付管道的组成部分,都可能构成挑战。
9. OPEN RESEARCH PROBLEMS
9.未解决的研究问题
Massive-scale software diversity does not yet exist. As a result, almost all questions regarding metrics, i.e., what are the costs versus the benefits of certain design choices, are completely open at this time and cannot really be answered without building an actual working system and experimenting with it. But even when it comes to the overall architecture and mechanisms, there are surprisingly many alternatives.
大规模软件的多样性尚不存在。 结果,几乎所有有关指标的问题,即成本和某些设计选择的收益是什么,在这个时候都是完全开放的,如果不构建实际的工作系统并进行试验,就无法真正回答。 但是,即使是在总体架构和机制方面,也有令人惊讶的许多替代方案。
We present some examples of interesting research questions. Most probably, these questions only scratch the surface of the design space and even more interesting ones will emerge as someone actually implements a massive-scale software diversity system.
我们提供一些有趣的研究问题的例子。 这些问题很可能只会触及设计空间的表面,而当有人实际实施大规模软件多样性系统时,还会出现更有趣的问题。
9.1 Generating Alternative Paths
9.1生成替代路径
Instead of choosing just a single “best” code path for a source construct being compiled, a multicompiler chooses among many alternative paths. At first glance, this is not very different from the activity of a traditional compiler, except that the alternatives are preserved rather than discarded in favor of the “best” one. But when digging deeper, many intriguing questions emerge. For example:
多编译器不只是为要编译的源构造选择一个“最佳”代码路径,还可以在许多替代路径中进行选择。 乍一看,这与传统编译器的活动没有太大区别,只是保留了替代方案,而不是为了“最佳”方案而丢弃了替代方案。 但是,当深入研究时,会出现许多有趣的问题。 例如:
-
How do you choose among alternative paths in such a way that the process is reproducible when needed (e.g., for generating patches), but simultaneously doesn’t give any advantage to an attacker? There are pobably even better solutions than the idea of a random seed that drives a random number generator, as outlined above in Section 7.
您如何选择备用路径,以使该过程在需要时可重复(例如,生成补丁),但同时又不会给攻击者带来任何好处? 可能有比驱动随机数生成器的随机种子的想法更好的解决方案,如上文第7节所述。
-
When there are a great many alternative paths at any choice point, can we limit the choice to only those paths that won’t incur a performance loss? How many different choices do you need at minimum to achieve the desired variability?
当在任何选择点都有很多替代路径时,我们可以将选择限制为仅那些不会造成性能损失的路径吗? 您至少需要多少个不同的选择来实现所需的可变性?
-
Some code paths are correlated. For example, choosing a certain register allocation at some choice point constrains other code paths “downstream.” How do we navigate these dependencies to ensure that sufficiently many versions can ultimately be generated?
一些代码路径是相关的。 例如,在某个选择点选择某个寄存器分配会约束其他代码路径“下游”。 我们如何导航这些依赖关系以确保最终可以生成足够多的版本?
-
Is there perhaps a trade-off between maximizing inter-version code variability (by making the path chooser take large strides) and prematurely exhausting the reachable path space? Does that suggest we should have an a priori estimate of the anticipated number of unique versions to be ultimately generated from any source program so that we can choose the correct inter-version path distance?
在最大化版本间代码的可变性(通过使路径选择器大步前进)与过早耗尽可到达的路径空间之间,可能需要权衡取舍吗? 这是否表明我们应该对任何源程序最终生成的唯一版本的预期数量进行先验估计,以便我们选择正确的版本间路径距离?
9.2 Variability Techniques Beyond Current Compilers
9.2当前编译器之外的可变性技术
There are probably diversity-enhancing techniques outside of the scope of existing compilers that could further increase the variability to an attacker without changing the functionality for the enduser. This would include mechanisms that incur more substantial runtime costs than merely not choosing the “best” path. One could probably borrow ideas from existing research on code obfuscation [4].
在现有编译器范围之外,可能还存在一些提高多样性的技术,这些技术可能会进一步增加攻击者的可变性,而无需更改最终用户的功能。 这将包括与不仅仅选择“最佳”路径相比会招致更多运行时成本的机制。 人们可能会从现有的代码混淆研究中借用一些想法[4]。
Among the techniques employed by code obfuscators is controlflow obfuscation, i.e., modifying the control flow of a program by re-distributing actions across basic blocks without changing actual program behavior. Unlike code obfuscators, we are less concerned about algorithm recapture and more focused on enhancing instruction-level code variability. As a result, a multicompiler will probably focus less on code obfuscation techniques that insert superfluous control-flow paths into a program, but it may readily employ code re-factoring strategies.
代码混淆器采用的技术之一是控制流混淆,即通过在基本块之间重新分配动作而不更改实际程序行为来修改程序的控制流。 与代码混淆器不同,我们较少关注算法重新捕获,而更着重于增强指令级代码的可变性。 结果,多编译器将可能较少关注代码混淆技术,这些技术会将多余的控制流路径插入到程序中,但是它很容易采用代码重构策略。
We envisage a scenario in which large-scale software diversification will eventually be applied to all software, including system libraries and large parts of operating systems. Not only will this mitigate attacks that are exploiting errors in the libraries and operating systems themselves, it will also help to defeat “arc injection” attacks that use existing library code sequences (“gadgets”) as stepping stones [18]. To this effect, code variability techniques will need to be engineered to prevent a canon of identical “gadgets” to exist across many diversified versions of the same library.
我们设想了一种场景,其中大规模软件多样化最终将应用于所有软件,包括系统库和操作系统的大部分。 这不仅可以缓解利用库和操作系统本身中的错误的攻击,还可以帮助克服使用现有库代码序列(“小工具”)作为垫脚石的“弧注入”攻击[18]。 为此,需要设计代码可变性技术,以防止在同一库的许多不同版本中都存在相同的“小工具”。
9.3 Systemic Properties
9.3系统性质
Assuming that a functioning multicompiler can be implemented, the research community could then leverage the vast collections of historical vulnerabilities and exploits to determine some more “systemic” unknown parameters of the proposed approach. Some example open questions of this kind include the following:
假设可以实现运行正常的多重编译器,那么研究团体可以利用大量的历史漏洞和漏洞利用来确定所提出方法的更多“系统性”未知参数。 此类公开问题示例包括:
-
Is the concept more defeatable if the variation engine is predictable? Is this approach more like cryptography, which depends on keeping a key private, even if the algorithm is known, or will knowledge of the algorithm reduce the effectiveness of the technique?
如果变异引擎是可预测的,那么这个概念是否更具可克服性? 这种方法是否更像是加密算法,即使知道算法也要依赖于保持密钥的私密性,还是对算法的了解会降低该技术的有效性?
-
Even if a flaw cannot be exploited to fully compromise a system, what does this technique do to avoid simply taking a system down (crashing it) by corrupting the stack? That is to say, can we systematically choose variations that will ensure survivability of the majority of versions, beyond merely guarding against takeover by an adversary.
即使无法利用缺陷来完全破坏系统,该技术还可以避免通过破坏堆栈而导致系统崩溃(崩溃)的情况? 也就是说,我们是否可以系统地选择能够确保大多数版本具有生存能力的变体,而不仅仅是防止对手进行收购。
-
Given how many possible vulnerabilities are likely to exist, what are the odds that there will be enough possibilities for diversity to cover all possible vulnerabilities? How much diversity is possible in comparison to the amount of code running, and the number of vulnerabilities or flaws in that code?
给定可能存在多少个漏洞,多样性有足够的可能性覆盖所有可能的漏洞的可能性是多少? 与运行的代码量以及该代码中的漏洞或缺陷数量相比,有多少多样性?
Clearly, it would be valuable to know the answers to these questions.
显然,了解这些问题的答案很有价值。
10. CLAIM OF A NEW PARADIGM
10.要求新的范式
The author hopes to have convinced the reader not only that massive-scale software diversity is now within practical reach, but also that it will usher in a new paradigm of software security. Many, if not most, of the assumptions and models underlying current computer security threats are a direct result of the existing software monoculture. Computer viruses and worms, root kits, botnets, …— the root cause for the existence of all these troubles is the fact that too many computers run the identical software binaries. Adopting a strategy of uniqueness of every single program on every single host at internet scale is something fundamentally new, a paradigm shift.
作者希望不仅使读者相信,大规模的软件多样性现在已经可以触及,而且还将带来一种新的软件安全范式。 当前计算机安全威胁所基于的许多(如果不是大多数)假设和模型是现有软件单一文化的直接结果。 计算机病毒和蠕虫,根工具包,僵尸网络等……导致所有这些问题存在的根本原因是,太多的计算机运行相同的软件二进制文件。 在互联网规模上,每台主机上的每个程序都采用唯一性策略,这从根本上来说是一种新的模式转变。
11. RELATED WORK
11.相关工作
The idea of using diversity to improve robustness has a long history in the fault tolerance community. The basic idea has been to generate multiple independent solutions to a problem (e.g., multiple versions of a software program, developed by independent teams in independent locations using even different programming languages), with the hope that they will fail independently. The expectation is then that at any given point in time, a majority of the versions will be functioning correctly [14, 1]. An abundance of evidence suggests that such n-version development techniques are more reliable, and more cost-effective, than producing one “good” version, especially in situations where the cost of failure is high [9]. This is in spite of the fact that many n-version software systems in practice exhibit a surprising amount of coincident failures of multiple supposedly independent program versions [12, 5].
在容错社区中,使用多样性提高鲁棒性的想法由来已久。 基本思想是生成针对问题的多个独立解决方案(例如,由独立团队在不同位置使用甚至不同的编程语言开发的软件程序的多个版本),希望它们将独立失败。 可以预期的是,在任何给定的时间点,大多数版本都将正常运行[14,1]。 大量证据表明,这种n版本开发技术比生产一个“好的”版本更可靠,更具成本效益,尤其是在失败成本很高的情况下[9]。 尽管有这样的事实,实际上许多n版本的软件系统在多个所谓的独立程序版本中都表现出令人惊讶的同时失败数量[12,5]。
More recently, along with a rising awareness of the threat posed by an increasingly severe computer monoculture, diversity has also been proposed as a means for improving software security. Most of the past approaches have been based on some form of obfuscation [3, 13]. Some research ideas on operating system randomization [2, 20] have since found their way into commercial operating systems. Other suggested obfuscation techniques have included load-time binary transformation [11] or even “private machine architectures” based on virtual machines [10].
最近,随着人们对日益严重的计算机单一文化所构成的威胁的认识不断提高,人们还提出了多样性作为提高软件安全性的一种手段。 过去的大多数方法都是基于某种形式的混淆[3,13]。 此后,有关操作系统随机化的一些研究思想[2,20]已经进入商业操作系统。 其他建议的混淆技术包括加载时二进制转换[11]或什至基于虚拟机的“私有计算机体系结构” [10]。
Unlike these approaches, massive-scale software diversity as presented here is not primarily focused on obfuscation. Instead, it exploits the randomness that is already inherent in compilation (in many cases, alternative paths are truly equivalent and the choice made by current unicompilers, although consistent, is algorithmically arbitrary). In this respect, the scope of this technique also goes several orders of magnitude beyond earlier work by Forrest et al. [7] that pioneered the idea of compiler-guided code variance. Thirteen years of technical innovation since that earlier work and the advent of cloud computing have changed the landscape fundamentally. It is now perfectly feasible to create a unique custom version of every program in existence for every user that wants one, and the cost estimate of 9 cents for a significant program that we gave in Section 6 is entirely realistic. Moreover, each of these unique versions is created by a full start-to-finish compilation process of the whole program, rather than merely parametrizing some part or performing only “peephole” optimizations, so that every conceivable valid permutation of the whole program is a possible option for the code variation generator.
与这些方法不同,此处介绍的大规模软件多样性并不主要集中在混淆方面。相反,它利用了编译中已经固有的随机性(在许多情况下,替代路径实际上是等效的,并且当前单编译器所做的选择尽管一致,但在算法上是任意的)。在这方面,该技术的范围也比Forrest等人的早期工作超出了几个数量级。 [7]率先提出了编译器指导的代码差异的思想。自从早期的工作和云计算的出现以来,已经进行了十三年的技术创新,从根本上改变了这种状况。现在,为每个想要一个程序的用户创建一个存在的每个程序的唯一自定义版本是完全可行的,我们在第6节中给出的一个重要程序的成本估算为9美分,这是完全现实的。而且,每个独特的版本都是通过整个程序的完整的从头到尾的编译过程来创建的,而不是仅仅对某些部分进行参数化或仅执行“窥孔”优化,因此整个程序的每个可以想到的有效置换都是代码变化生成器的可能选项。
Finally, massive-scale software diversity is related to the author’s own earlier work on combining software diversity with parallelism and checkpointing [17, 15, 16]. The earlier approach was to run several slightly different versions of the same program in lockstep on a multicore processor and monitor for differences in behavior. The main emphasis was on the monitoring and control layer: because the versions operate in lockstep but behave like just a single program, system events such as user input, file accesses and signals need to be virtualized and dispatched to the various versions at the same logical (as opposed to temporal) point. Further, the need to run the versions in lockstep with relatively small skew limits the variations that are possible between versions. The approach introduced here has no such constraints, because each version is run independently of all the others. As a consequence, far more ambitious code variations can be employed.
最后,大规模软件多样性与作者自己先前在将软件多样性与并行性和检查点相结合方面所做的工作有关[17,15,16]。 较早的方法是在多核处理器上同步运行几个略有不同版本的同一程序,并监视行为差异。 主要侧重于监视和控制层:因为这些版本以同步方式运行,但仅像一个程序一样工作,因此需要对系统事件(例如用户输入,文件访问和信号)进行虚拟化,并以相同的逻辑将其分发到各个版本 (相对于时间)点。 此外,需要以较小的偏斜同步运行版本限制了版本之间可能出现的变化。 这里介绍的方法没有这样的约束,因为每个版本都独立于所有其他版本运行。 结果,可以采用更大胆的代码变化。
12. SUMMARY AND CONCLUSION
12.总结与结论
Adopting massive-scale software diversity will have a dramatic impact on the way that software is distributed and is likely to change many of the assumptions and models underlying current threats to deployed software. When every software binary is unique, it becomes much less likely that a single attack will affect large numbers of targets simultaneously. Hence, the impact of phenomena such as “viruses” and “worms” will be greatly reduced.
采用大规模软件多样性将对软件的分发方式产生巨大影响,并且可能会改变许多对当前对已部署软件构成威胁的假设和模型。 当每个软件二进制文件都是唯一的时,一次攻击将同时影响大量目标的可能性大大降低。 因此,将大大减少诸如“病毒”和“蠕虫”之类的现象的影响。
More subtly, the distribution of unique binaries also has the effect that adversaries can no longer simply analyze their own copies of any given piece of software to find exploitable vulnerabilities, because any vulnerabilities they may find will no longer automatically translate to all other instances of the same software. Hence, even directed attacks against specific targets running some unique version of some software will become much more difficult, as long as the attacker has no way of determining which specific binary is present on what target.
更巧妙的是,分发唯一的二进制文件还具有以下效果:对手不再能够简单地分析其自己的任何给定软件副本来查找可利用的漏洞,因为他们可能发现的任何漏洞将不再自动转换为该漏洞的所有其他实例。 相同的软件。 因此,只要攻击者无法确定在哪个目标上存在哪个特定的二进制文件,即使是针对运行某些软件的某些独特版本的特定目标的定向攻击也将变得更加困难。
Finally, massive-scale software diversity makes it much more difficult for an attacker to generate attack vectors by way of reverse engineering of software updates. We have outlined a mechanism for intelligently updating software that has been diversified at internet scale.
最后,大规模的软件多样性使攻击者更难通过软件更新的反向工程来生成攻击向量。 我们概述了一种智能更新软件的机制,该机制已在Internet范围内实现了多样化。
Without doubt, the new paradigm of massive-scale software diversity will change many of the existing approaches to software security. It will make the digital domain safer. It will also be a great canvas for researchers, because it presents many challenging open problems.
毫无疑问,大规模软件多样性的新范例将改变许多现有的软件安全方法。 这将使数字域更安全。 对于研究人员来说,这也是一块不错的画布,因为它提出了许多具有挑战性的开放性问题。
13. ACKNOWLEDGEMENT
13.致谢
The artistically challenged author wants to thank Michael Bebenita for turning his rough pencil sketches into the stunning computer drawn figures you see in the paper. Thanks also go to one of the anonymous reviewers for pointing out some additional “systemic” research questions that have now been added to Section 9.3.
受到艺术挑战的作者要感谢迈克尔·贝本尼塔(Michael Bebenita)将他的粗略铅笔素描变成您在论文中看到的令人惊叹的计算机绘制的数字。 也要感谢一位匿名评论者指出了一些额外的“系统性”研究问题,这些问题现已添加到第9.3节中。
Parts of this work were supported by the United States National Science Foundation (NSF) under Grants No. CNS-0905684 and CNS-0627747. Any opinions, findings, and conclusions or recommendations expressed in this paper are those of the author and do not necessarily reflect the views of the National Science Foundation.
这项工作的一部分得到了美国国家科学基金会(NSF)的资助,资助号为CNS-0905684和CNS-0627747。 本文中表达的任何观点,发现,结论或建议均为作者的观点,不一定反映美国国家科学基金会的观点。
14. REFERENCES
14.参考资料
[1] A. Avizienis and L. Chen. On the implementation of n-version programming for software fault tolerance during execution. In IEEE COMPSAC 77, pages 149–155, 1977.
[2] M. Chew and D. Song. Mitigating buffer overflows by operating system randomization. Technical Report CMU-CS-02-197, Department of Computer Science, Carnegie Mellon University, Dec. 2002.
[3] F. Cohen. Operating system protection through program evolution. Computers and Security, 12(6):565–584, Oct. 1993.
[4] C. Collberg and J. Nagra. Surreptitious Software: Obfuscation, Watermarking, and Tamperproofing for Software Protection. Addison Wesley, 2009.
[5] D. E. Eckhardt, A. K. Caglayan, J. C. Knight, L. D. Lee, D. F. McAllister, M. A. Vouk, and J. J. P. Kelly. An experimental evaluation of software redundancy as a strategy for improving reliability. IEEE Transactions on Software Engineering, 17(7):692–702, 1991.
[6] M. Fitzgerald. Cloud computing: So you don’t have to stand still. New York Times, May 25th, 2008.
[7] S. Forrest, A. Somayaji, and D. Ackley. Building diverse computer systems. In 6th Workshop on Hot Topics in Operating Systems (HotOS-VI), pages 67–72, 1997.
[8] D. Geer, R. Bace, P. Gutmann, P. Metzger, C. P. Pfleeger, J. S. Quartermain, and B. Schneier. Cyberinsecurity: The cost of monopoly: How the dominance of Microsoft’s products poses a risk to security. Technical report, Computer and Communications Industry Association, 2003.
[9] L. Hatton. N-version design versus one good version. IEEE Software, 14(6):71–76, 1997.
[10] D. A. Holland, A. T. Lim, and M. I. Seltzer. An architecture a day keeps the hacker away. SIGARCH Computer Architecture News, 33(1):34–41, 2005.
[11] J. E. Just and M. Cornwell. Review and analysis of synthetic diversity for breaking monocultures. In 2004 ACM Workshop on Rapid Malcode (WORM ’04), pages 23–32, 2004.
[12] J. C. Knight and N. G. Leveson. An experimental evaluation of the assumption of independence in multiversion programming. IEEE Transactions on Software Engineering, 12(1):96–109, 1986.
[13] C. Pu, A. Black, C. Cowan, and J. Walpole. A specialization toolkit to increase the diversity of operating systems. In ICMAS Workshop on Immunity-Based Systems, Nara, Japan, Dec. 1996.
[14] B. Randell. System structure for software fault tolerance. IEEE Transactions on Software Engineering, 1:220–232, 1975.
[15] B. Salamat, A. Gal, and M. Franz. Reverse stack execution in a multi-variant execution environment. In 2008 Workshop on Compiler and Architectural Techniques for Application Reliability and Security (CATARS’08), June 2008.
[16] B. Salamat, A. Gal, T. Jackson, K. Manivannan, G. Wagner, and M. Franz. Multi-variant program execution: Using multi-core systems to defuse buffer-overflow vulnerabilities. In 2008 International Workshop on Multi-Core Computing Systems (MuCoCoS 2008), March 2008.
[17] B. Salamat, T. Jackson, A. Gal, and M. Franz. Intrusion detection using parallel execution and monitoring of program variants in user-space. In Eurosys 2009, April 2009.
[18] H. Shacham. The geometry of innocent flesh on the bone: Return-into-libc without function calls (on the x86). In Proceedings of CCS 2007, pages 552–61. ACM Press, Oct. 2007.
[19] M. Stamp. Risks of monoculture. Communications of the ACM, 47(3):120, 2004.
[20] J. Xu, Z. Kalbarczyk, and R. K. Iyer. Transparent runtime randomization for security. In 22nd International Symposium on Reliable Distributed Systems (SRDS’03), pages 260–269, 2003.
如若内容造成侵权/违法违规/事实不符,请联系编程学习网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
相关文章
- 6.【类与对象】
1.1 面向对象思想概述 概述 java语言是一种面向对象的程序设计语言,而面向对象思想是一种程序设计思想,我们在面向对象思想的指引下,使用Java语言去设计、开发计算机程序。这里的对象泛指现实中一切事物,每种事物都具备自己的属性和行为。面向对象思想就是在计算机程序设计…...
2024/4/24 7:38:08 - 关系的形式化 定义、概念、性质
关系的形式化定义和概念 域 域是一组具有相同数据类型的值的集合,又称为值域。 (用D表示) 域中所包含的值的个数称为域的基数(用m表示)。在关系中用域表示属性的取值范围。 笛卡尔积 定义:给定一组域D1,D2,…,Dn(它们可以包含相同的元素,即可以完全不同,也可以部分…...
2024/5/3 20:03:29 - 缓存,确实很香,却也很受伤!
缓存,确实很香,却也很受伤!缓存的使用,是一个逐渐演进的过程。 问一下你自己,最直接的使用缓存的原因是什么? 无它,唯快而已! 追溯一下自己最开始使用缓存的场景,一些数据库里存储的不变的配置信息,服务启动时,直接加载到本地公共模块,方便其它功能模块共享使用。这…...
2024/4/19 10:00:20 - XCOPY艾高贝bb2揭秘阿里百亿级云客服实时分析架构是怎么炼成的?
淘宝、天猫每天有上亿个不同的买卖家进行对话,产生百亿条聊天记录。对客服聊天记录的实时分析是实现智能客服的基础。本文主要分享云客服的整体架构,包括实时分析的场景、架构、技术难点,以及为何要从 NoSQL 迁移时序数据库和使用心得。网购催生客服职能转型如下图,是国内…...
2024/4/15 7:10:00 - FOne MOOC在线课程平台
FOne MOOC在线课程平台关于FOne MOOC系统优势相关案例 关于FOne MOOC FOne MOOC™,基于世界最大公开课开源平台OpenEdx,并为中国企业内训场景进行优化,提供高效易用的企业内训平台。 FOne MOOC™,是由富士通南大软件有限公司的技术团队经过大量的用户数据分析与长期的用户行…...
2024/4/16 19:20:36 - Redis 5.0.4配置文件redis.conf全文解读
Redis解压完毕可见目录下的redis.conf,在安装之后生成自启动脚本就有步骤是复制该配置文件到/etc/redis/目录下,话不多说,看看去:1. 头部说明头部内容说明:注意单位问题,当需要设置内存大小的时候,可使用类似1k、5GB、4M这样的常见格式,单位不区分大小写,1GB 1Gb 1gB的…...
2024/4/15 7:09:58 - spring boot使用自定义注解+AOP实现对Controller层方法的日志记录
1.创建一个spring boot项目,导入maven依赖:<dependencies><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.6</version></dependency><dependency><groupId…...
2024/4/24 7:38:05 - 电磁波传输的几种途径
一、地波传播:即沿地面传播的电磁波。随着频率的升高,其信号衰减会很快增加,因此主要是低频(LF、30-300KHz,又称长波),中频(MF、300-3000KHz,又称中波)和高频(HF、3-30MHz,又称短波)无线电的传播途径。二、空间波传播:即电磁波在空中按直线传播,它主要是甚高频(…...
2024/4/24 7:38:04 - 从事嵌入式软件开发的好处是什么
很多学员都有去了解过嵌入式,但是之后就杳无音信了,这是为什么呢?是大家对嵌入式没有信心,还是对自己没有信心呢?下面小编就来给大家介绍下从事嵌入式软件开发的好处是什么吧。 一、从事嵌入式软件开发的好处是: (1)目前国内外这方面的人都很稀缺。这一领域入门门槛较高…...
2024/4/24 7:37:58 - Matrix Derivation
Matrix Derivation 参考文献 主要参考文献 矩阵的导数与迹 矩阵、向量微分计算 次要参考文献 机器学习中常用的矩阵求导公式 矩阵求导、几种重要的矩阵及常用的矩阵求导公式 逻辑基本定义定理公式推导矩阵迹的微分(Derivative of Traces)矩阵微分的应用...
2024/4/24 7:38:14 - 装饰者模式
目录装饰者模式使用new对象方法使用function方法函数装饰能用版本装逼版本 装饰者模式 装饰者模式可以动态地给某个对象添加一些额外的职责,而不会影响从这个类中派生的其他对象。 使用new对象方法 var Plane = function() {}// 开火(基础威力) Plane.prototype.fire = func…...
2024/4/24 7:37:54 - 分销商城开发 分销系统开发 分销模式方案Java开发
一、什么是分销商城: 简单来说,就是企业利用无线裂变分销功能的商城系统来发展分销商,管理分销商销售、产品、订单、物流、客户等。如活跃在微信朋友圈中的微商城就是一种基于微信朋友圈的分销商城平台。市面上除了微分销平台,还有哪些令人眼前一亮的分销平台呢。TTSHOP分销…...
2024/4/24 7:37:53 - XCOPY艾高贝bb2阿里8年资深技术专家谈企业级互联网架构的演进之路
沈询,阿里巴巴中间件&稳定性平台资深技术专家,在淘宝工作八年间,主要负责的产品有淘宝分布式数据库(TDDL/DRDS)、分布式消息系统(Notify/ONS)等,故对整个分布式的互联网架构比较了解。本文分享围绕阿里技术架构演进及过程中遇到的问题与企业级信息系统架构的演进展开…...
2024/4/24 7:37:52 - 2020年信工所考研经验分享
文章目录2020年信工所考研经验分享考研19-20闲谈初试备考经验复试备考经验结语 2020年信工所考研经验分享 信工所考研交流群:124787063题记——选择信工所,你的考研就成功了一半。 考研19-20闲谈俗话说万事皆有因果,那么说起来当时我为什么要考研呢。我想大概主要有两个方面…...
2024/4/24 7:37:51 - UltraStudio 4K Extreme 3采集卡
描述业界新锐UltraStudio 4K Extreme 3是一款适用于PCI Express和Thunderbolt计算机的先进采集和输出方案!它采用40Gb/s炫速Thunderbolt 3技术,并搭载先进的12G‑SDI和HDMI 2.0接口,能从事高达每秒60帧的影像处理,并且配备高色深和12bit RGB,可通过其HDMI 2.0a接口实现HDR…...
2024/4/24 4:10:56 - 三维点云语义分割基础知识
三维点云语义分割基础知识1. 简介1.1 点云分割介绍1.2 三维数据表达方式1.3 点云的特点及优势2 研究现状2.1 基于人工特征和机器学习的方法2.2 基于深度学习的方法 1. 简介 1.1 点云分割介绍 点云分割,即对点云中的每个点赋予有意义的标注,标注代表可以是任何具有特定意义的…...
2024/4/24 7:37:49 - 十年磨一剑,美国巨头视频网站 Hulu 的直播系统架构实践XCOPY艾高贝bb2
Hulu 是 2007 年在美国上市的在线视频公司,提供会员制付费视频服务,商业模式与国内的爱奇艺、优酷类似。Hulu 今年 5 月发布了最新的 OTT 电视直播应用——Hulu Live TV,目标是替代传统的有线电视服务,和国内最近兴起的直播应用,比如 YY,映客等。本文主要分享 Hulu 现有视…...
2024/5/2 0:43:18 - 【FFmpeg系列】libavcodec中重要结构体作用
DATE: 2020.5.26AVCodec:视音频流对应的结构体,用于视音频编解码 AVCodecContext: 视音频流对应的结构体,用于视音频编解码 AVFrame:存储非压缩的数据(视频对应RGB/YUV像素数据,音频对应PCM采样数据) AVPacket:存储压缩数据(视频对应H.264等码流数据,音频对应AAC/MP3等…...
2024/5/2 2:28:39 - 9_03_模块和包
目标模块 包 发布模块01. 模块 1.1 模块的概念模块是 Python 程序架构的一个核心概念每一个以扩展名 py 结尾的 Python 源代码文件都是一个 模块 模块名 同样也是一个 标识符,需要符合标识符的命名规则 在模块中定义的 全局变量 、函数、类 都是提供给外界直接使用的 工具 模块…...
2024/5/1 22:38:38 - Qt之工厂模式(Factory Pattern)
工厂模式 QItemEditorFactory class Q_GUI_EXPORT QItemEditorFactory { public://按照type,创建对象,具体由创造器(QItemEditorCreatorBase)完成virtual QWidget *createEditor(QVariant::Type type, QWidget *parent) const;//向工厂注册具体对象的创造器void registerEd…...
2024/5/2 5:03:00
最新文章
- 为什么自学编程那么难?
自学编程之所以难,主要有以下几个原因: 方向难:编程行业是有分工的,有做前端网页的,有做移动端iOS、安卓的,有做后台的。对于初学者来说,选择一个适合自己的学习方向可能是一个挑战,…...
2024/5/5 13:23:47 - 梯度消失和梯度爆炸的一些处理方法
在这里是记录一下梯度消失或梯度爆炸的一些处理技巧。全当学习总结了如有错误还请留言,在此感激不尽。 权重和梯度的更新公式如下: w w − η ⋅ ∇ w w w - \eta \cdot \nabla w ww−η⋅∇w 个人通俗的理解梯度消失就是网络模型在反向求导的时候出…...
2024/3/20 10:50:27 - 整理的微信小程序日历(单选/多选/筛选)
一、日历横向多选,支持单日、双日、三日、工作日等选择 效果图 wxml文件 <view class"calendar"><view class"section"><view class"title flex-box"><button bindtap"past">上一页</button&…...
2024/5/5 8:50:30 - 【蓝桥杯嵌入式】13届程序题刷题记录及反思
一、题目分析 考察内容: led按键(短按)PWM输出(PA1)串口接收lcd显示 根据PWM输出占空比调节,高频与低频切换 串口接收(指令解析)【中断接收】 2个显示界面 led灯闪烁定时器 二…...
2024/5/5 8:29:48 - 【外汇早评】美通胀数据走低,美元调整
原标题:【外汇早评】美通胀数据走低,美元调整昨日美国方面公布了新一期的核心PCE物价指数数据,同比增长1.6%,低于前值和预期值的1.7%,距离美联储的通胀目标2%继续走低,通胀压力较低,且此前美国一季度GDP初值中的消费部分下滑明显,因此市场对美联储后续更可能降息的政策…...
2024/5/4 23:54:56 - 【原油贵金属周评】原油多头拥挤,价格调整
原标题:【原油贵金属周评】原油多头拥挤,价格调整本周国际劳动节,我们喜迎四天假期,但是整个金融市场确实流动性充沛,大事频发,各个商品波动剧烈。美国方面,在本周四凌晨公布5月份的利率决议和新闻发布会,维持联邦基金利率在2.25%-2.50%不变,符合市场预期。同时美联储…...
2024/5/4 23:54:56 - 【外汇周评】靓丽非农不及疲软通胀影响
原标题:【外汇周评】靓丽非农不及疲软通胀影响在刚结束的周五,美国方面公布了新一期的非农就业数据,大幅好于前值和预期,新增就业重新回到20万以上。具体数据: 美国4月非农就业人口变动 26.3万人,预期 19万人,前值 19.6万人。 美国4月失业率 3.6%,预期 3.8%,前值 3…...
2024/5/4 23:54:56 - 【原油贵金属早评】库存继续增加,油价收跌
原标题:【原油贵金属早评】库存继续增加,油价收跌周三清晨公布美国当周API原油库存数据,上周原油库存增加281万桶至4.692亿桶,增幅超过预期的74.4万桶。且有消息人士称,沙特阿美据悉将于6月向亚洲炼油厂额外出售更多原油,印度炼油商预计将每日获得至多20万桶的额外原油供…...
2024/5/4 23:55:17 - 【外汇早评】日本央行会议纪要不改日元强势
原标题:【外汇早评】日本央行会议纪要不改日元强势近两日日元大幅走强与近期市场风险情绪上升,避险资金回流日元有关,也与前一段时间的美日贸易谈判给日本缓冲期,日本方面对汇率问题也避免继续贬值有关。虽然今日早间日本央行公布的利率会议纪要仍然是支持宽松政策,但这符…...
2024/5/4 23:54:56 - 【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响
原标题:【原油贵金属早评】欧佩克稳定市场,填补伊朗问题的影响近日伊朗局势升温,导致市场担忧影响原油供给,油价试图反弹。此时OPEC表态稳定市场。据消息人士透露,沙特6月石油出口料将低于700万桶/日,沙特已经收到石油消费国提出的6月份扩大出口的“适度要求”,沙特将满…...
2024/5/4 23:55:05 - 【外汇早评】美欲与伊朗重谈协议
原标题:【外汇早评】美欲与伊朗重谈协议美国对伊朗的制裁遭到伊朗的抗议,昨日伊朗方面提出将部分退出伊核协议。而此行为又遭到欧洲方面对伊朗的谴责和警告,伊朗外长昨日回应称,欧洲国家履行它们的义务,伊核协议就能保证存续。据传闻伊朗的导弹已经对准了以色列和美国的航…...
2024/5/4 23:54:56 - 【原油贵金属早评】波动率飙升,市场情绪动荡
原标题:【原油贵金属早评】波动率飙升,市场情绪动荡因中美贸易谈判不安情绪影响,金融市场各资产品种出现明显的波动。随着美国与中方开启第十一轮谈判之际,美国按照既定计划向中国2000亿商品征收25%的关税,市场情绪有所平复,已经开始接受这一事实。虽然波动率-恐慌指数VI…...
2024/5/4 23:55:16 - 【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试
原标题:【原油贵金属周评】伊朗局势升温,黄金多头跃跃欲试美国和伊朗的局势继续升温,市场风险情绪上升,避险黄金有向上突破阻力的迹象。原油方面稍显平稳,近期美国和OPEC加大供给及市场需求回落的影响,伊朗局势并未推升油价走强。近期中美贸易谈判摩擦再度升级,美国对中…...
2024/5/4 23:54:56 - 【原油贵金属早评】市场情绪继续恶化,黄金上破
原标题:【原油贵金属早评】市场情绪继续恶化,黄金上破周初中国针对于美国加征关税的进行的反制措施引发市场情绪的大幅波动,人民币汇率出现大幅的贬值动能,金融市场受到非常明显的冲击。尤其是波动率起来之后,对于股市的表现尤其不安。隔夜美国股市出现明显的下行走势,这…...
2024/5/4 18:20:48 - 【外汇早评】美伊僵持,风险情绪继续升温
原标题:【外汇早评】美伊僵持,风险情绪继续升温昨日沙特两艘油轮再次发生爆炸事件,导致波斯湾局势进一步恶化,市场担忧美伊可能会出现摩擦生火,避险品种获得支撑,黄金和日元大幅走强。美指受中美贸易问题影响而在低位震荡。继5月12日,四艘商船在阿联酋领海附近的阿曼湾、…...
2024/5/4 23:54:56 - 【原油贵金属早评】贸易冲突导致需求低迷,油价弱势
原标题:【原油贵金属早评】贸易冲突导致需求低迷,油价弱势近日虽然伊朗局势升温,中东地区几起油船被袭击事件影响,但油价并未走高,而是出于调整结构中。由于市场预期局势失控的可能性较低,而中美贸易问题导致的全球经济衰退风险更大,需求会持续低迷,因此油价调整压力较…...
2024/5/4 23:55:17 - 氧生福地 玩美北湖(上)——为时光守候两千年
原标题:氧生福地 玩美北湖(上)——为时光守候两千年一次说走就走的旅行,只有一张高铁票的距离~ 所以,湖南郴州,我来了~ 从广州南站出发,一个半小时就到达郴州西站了。在动车上,同时改票的南风兄和我居然被分到了一个车厢,所以一路非常愉快地聊了过来。 挺好,最起…...
2024/5/4 23:55:06 - 氧生福地 玩美北湖(中)——永春梯田里的美与鲜
原标题:氧生福地 玩美北湖(中)——永春梯田里的美与鲜一觉醒来,因为大家太爱“美”照,在柳毅山庄去寻找龙女而错过了早餐时间。近十点,向导坏坏还是带着饥肠辘辘的我们去吃郴州最富有盛名的“鱼头粉”。说这是“十二分推荐”,到郴州必吃的美食之一。 哇塞!那个味美香甜…...
2024/5/4 23:54:56 - 氧生福地 玩美北湖(下)——奔跑吧骚年!
原标题:氧生福地 玩美北湖(下)——奔跑吧骚年!让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 让我们红尘做伴 活得潇潇洒洒 策马奔腾共享人世繁华 对酒当歌唱出心中喜悦 轰轰烈烈把握青春年华 啊……啊……啊 两…...
2024/5/4 23:55:06 - 扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!
原标题:扒开伪装医用面膜,翻六倍价格宰客,小姐姐注意了!扒开伪装医用面膜,翻六倍价格宰客!当行业里的某一品项火爆了,就会有很多商家蹭热度,装逼忽悠,最近火爆朋友圈的医用面膜,被沾上了污点,到底怎么回事呢? “比普通面膜安全、效果好!痘痘、痘印、敏感肌都能用…...
2024/5/5 8:13:33 - 「发现」铁皮石斛仙草之神奇功效用于医用面膜
原标题:「发现」铁皮石斛仙草之神奇功效用于医用面膜丽彦妆铁皮石斛医用面膜|石斛多糖无菌修护补水贴19大优势: 1、铁皮石斛:自唐宋以来,一直被列为皇室贡品,铁皮石斛生于海拔1600米的悬崖峭壁之上,繁殖力差,产量极低,所以古代仅供皇室、贵族享用 2、铁皮石斛自古民间…...
2024/5/4 23:55:16 - 丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者
原标题:丽彦妆\医用面膜\冷敷贴轻奢医学护肤引导者【公司简介】 广州华彬企业隶属香港华彬集团有限公司,专注美业21年,其旗下品牌: 「圣茵美」私密荷尔蒙抗衰,产后修复 「圣仪轩」私密荷尔蒙抗衰,产后修复 「花茵莳」私密荷尔蒙抗衰,产后修复 「丽彦妆」专注医学护…...
2024/5/4 23:54:58 - 广州械字号面膜生产厂家OEM/ODM4项须知!
原标题:广州械字号面膜生产厂家OEM/ODM4项须知!广州械字号面膜生产厂家OEM/ODM流程及注意事项解读: 械字号医用面膜,其实在我国并没有严格的定义,通常我们说的医美面膜指的应该是一种「医用敷料」,也就是说,医用面膜其实算作「医疗器械」的一种,又称「医用冷敷贴」。 …...
2024/5/4 23:55:01 - 械字号医用眼膜缓解用眼过度到底有无作用?
原标题:械字号医用眼膜缓解用眼过度到底有无作用?医用眼膜/械字号眼膜/医用冷敷眼贴 凝胶层为亲水高分子材料,含70%以上的水分。体表皮肤温度传导到本产品的凝胶层,热量被凝胶内水分子吸收,通过水分的蒸发带走大量的热量,可迅速地降低体表皮肤局部温度,减轻局部皮肤的灼…...
2024/5/4 23:54:56 - 配置失败还原请勿关闭计算机,电脑开机屏幕上面显示,配置失败还原更改 请勿关闭计算机 开不了机 这个问题怎么办...
解析如下:1、长按电脑电源键直至关机,然后再按一次电源健重启电脑,按F8健进入安全模式2、安全模式下进入Windows系统桌面后,按住“winR”打开运行窗口,输入“services.msc”打开服务设置3、在服务界面,选中…...
2022/11/19 21:17:18 - 错误使用 reshape要执行 RESHAPE,请勿更改元素数目。
%读入6幅图像(每一幅图像的大小是564*564) f1 imread(WashingtonDC_Band1_564.tif); subplot(3,2,1),imshow(f1); f2 imread(WashingtonDC_Band2_564.tif); subplot(3,2,2),imshow(f2); f3 imread(WashingtonDC_Band3_564.tif); subplot(3,2,3),imsho…...
2022/11/19 21:17:16 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机...
win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”问题的解决方法在win7系统关机时如果有升级系统的或者其他需要会直接进入一个 等待界面,在等待界面中我们需要等待操作结束才能关机,虽然这比较麻烦,但是对系统进行配置和升级…...
2022/11/19 21:17:15 - 台式电脑显示配置100%请勿关闭计算机,“准备配置windows 请勿关闭计算机”的解决方法...
有不少用户在重装Win7系统或更新系统后会遇到“准备配置windows,请勿关闭计算机”的提示,要过很久才能进入系统,有的用户甚至几个小时也无法进入,下面就教大家这个问题的解决方法。第一种方法:我们首先在左下角的“开始…...
2022/11/19 21:17:14 - win7 正在配置 请勿关闭计算机,怎么办Win7开机显示正在配置Windows Update请勿关机...
置信有很多用户都跟小编一样遇到过这样的问题,电脑时发现开机屏幕显现“正在配置Windows Update,请勿关机”(如下图所示),而且还需求等大约5分钟才干进入系统。这是怎样回事呢?一切都是正常操作的,为什么开时机呈现“正…...
2022/11/19 21:17:13 - 准备配置windows 请勿关闭计算机 蓝屏,Win7开机总是出现提示“配置Windows请勿关机”...
Win7系统开机启动时总是出现“配置Windows请勿关机”的提示,没过几秒后电脑自动重启,每次开机都这样无法进入系统,此时碰到这种现象的用户就可以使用以下5种方法解决问题。方法一:开机按下F8,在出现的Windows高级启动选…...
2022/11/19 21:17:12 - 准备windows请勿关闭计算机要多久,windows10系统提示正在准备windows请勿关闭计算机怎么办...
有不少windows10系统用户反映说碰到这样一个情况,就是电脑提示正在准备windows请勿关闭计算机,碰到这样的问题该怎么解决呢,现在小编就给大家分享一下windows10系统提示正在准备windows请勿关闭计算机的具体第一种方法:1、2、依次…...
2022/11/19 21:17:11 - 配置 已完成 请勿关闭计算机,win7系统关机提示“配置Windows Update已完成30%请勿关闭计算机”的解决方法...
今天和大家分享一下win7系统重装了Win7旗舰版系统后,每次关机的时候桌面上都会显示一个“配置Windows Update的界面,提示请勿关闭计算机”,每次停留好几分钟才能正常关机,导致什么情况引起的呢?出现配置Windows Update…...
2022/11/19 21:17:10 - 电脑桌面一直是清理请关闭计算机,windows7一直卡在清理 请勿关闭计算机-win7清理请勿关机,win7配置更新35%不动...
只能是等着,别无他法。说是卡着如果你看硬盘灯应该在读写。如果从 Win 10 无法正常回滚,只能是考虑备份数据后重装系统了。解决来方案一:管理员运行cmd:net stop WuAuServcd %windir%ren SoftwareDistribution SDoldnet start WuA…...
2022/11/19 21:17:09 - 计算机配置更新不起,电脑提示“配置Windows Update请勿关闭计算机”怎么办?
原标题:电脑提示“配置Windows Update请勿关闭计算机”怎么办?win7系统中在开机与关闭的时候总是显示“配置windows update请勿关闭计算机”相信有不少朋友都曾遇到过一次两次还能忍但经常遇到就叫人感到心烦了遇到这种问题怎么办呢?一般的方…...
2022/11/19 21:17:08 - 计算机正在配置无法关机,关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机...
关机提示 windows7 正在配置windows 请勿关闭计算机 ,然后等了一晚上也没有关掉。现在电脑无法正常关机以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!关机提示 windows7 正在配…...
2022/11/19 21:17:05 - 钉钉提示请勿通过开发者调试模式_钉钉请勿通过开发者调试模式是真的吗好不好用...
钉钉请勿通过开发者调试模式是真的吗好不好用 更新时间:2020-04-20 22:24:19 浏览次数:729次 区域: 南阳 > 卧龙 列举网提醒您:为保障您的权益,请不要提前支付任何费用! 虚拟位置外设器!!轨迹模拟&虚拟位置外设神器 专业用于:钉钉,外勤365,红圈通,企业微信和…...
2022/11/19 21:17:05 - 配置失败还原请勿关闭计算机怎么办,win7系统出现“配置windows update失败 还原更改 请勿关闭计算机”,长时间没反应,无法进入系统的解决方案...
前几天班里有位学生电脑(windows 7系统)出问题了,具体表现是开机时一直停留在“配置windows update失败 还原更改 请勿关闭计算机”这个界面,长时间没反应,无法进入系统。这个问题原来帮其他同学也解决过,网上搜了不少资料&#x…...
2022/11/19 21:17:04 - 一个电脑无法关闭计算机你应该怎么办,电脑显示“清理请勿关闭计算机”怎么办?...
本文为你提供了3个有效解决电脑显示“清理请勿关闭计算机”问题的方法,并在最后教给你1种保护系统安全的好方法,一起来看看!电脑出现“清理请勿关闭计算机”在Windows 7(SP1)和Windows Server 2008 R2 SP1中,添加了1个新功能在“磁…...
2022/11/19 21:17:03 - 请勿关闭计算机还原更改要多久,电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机怎么办...
许多用户在长期不使用电脑的时候,开启电脑发现电脑显示:配置windows更新失败,正在还原更改,请勿关闭计算机。。.这要怎么办呢?下面小编就带着大家一起看看吧!如果能够正常进入系统,建议您暂时移…...
2022/11/19 21:17:02 - 还原更改请勿关闭计算机 要多久,配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以...
配置windows update失败 还原更改 请勿关闭计算机,电脑开机后一直显示以以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧!配置windows update失败 还原更改 请勿关闭计算机&#x…...
2022/11/19 21:17:01 - 电脑配置中请勿关闭计算机怎么办,准备配置windows请勿关闭计算机一直显示怎么办【图解】...
不知道大家有没有遇到过这样的一个问题,就是我们的win7系统在关机的时候,总是喜欢显示“准备配置windows,请勿关机”这样的一个页面,没有什么大碍,但是如果一直等着的话就要两个小时甚至更久都关不了机,非常…...
2022/11/19 21:17:00 - 正在准备配置请勿关闭计算机,正在准备配置windows请勿关闭计算机时间长了解决教程...
当电脑出现正在准备配置windows请勿关闭计算机时,一般是您正对windows进行升级,但是这个要是长时间没有反应,我们不能再傻等下去了。可能是电脑出了别的问题了,来看看教程的说法。正在准备配置windows请勿关闭计算机时间长了方法一…...
2022/11/19 21:16:59 - 配置失败还原请勿关闭计算机,配置Windows Update失败,还原更改请勿关闭计算机...
我们使用电脑的过程中有时会遇到这种情况,当我们打开电脑之后,发现一直停留在一个界面:“配置Windows Update失败,还原更改请勿关闭计算机”,等了许久还是无法进入系统。如果我们遇到此类问题应该如何解决呢࿰…...
2022/11/19 21:16:58 - 如何在iPhone上关闭“请勿打扰”
Apple’s “Do Not Disturb While Driving” is a potentially lifesaving iPhone feature, but it doesn’t always turn on automatically at the appropriate time. For example, you might be a passenger in a moving car, but your iPhone may think you’re the one dri…...
2022/11/19 21:16:57